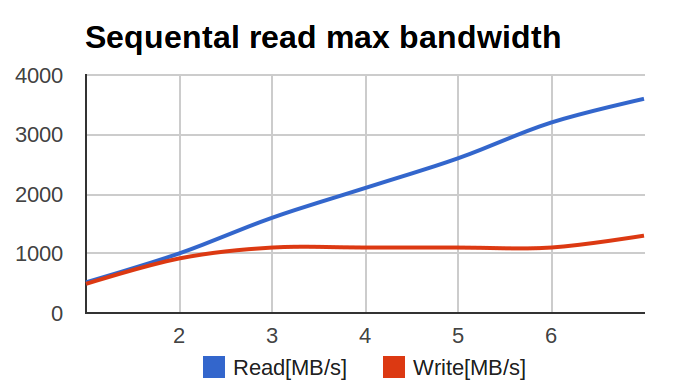
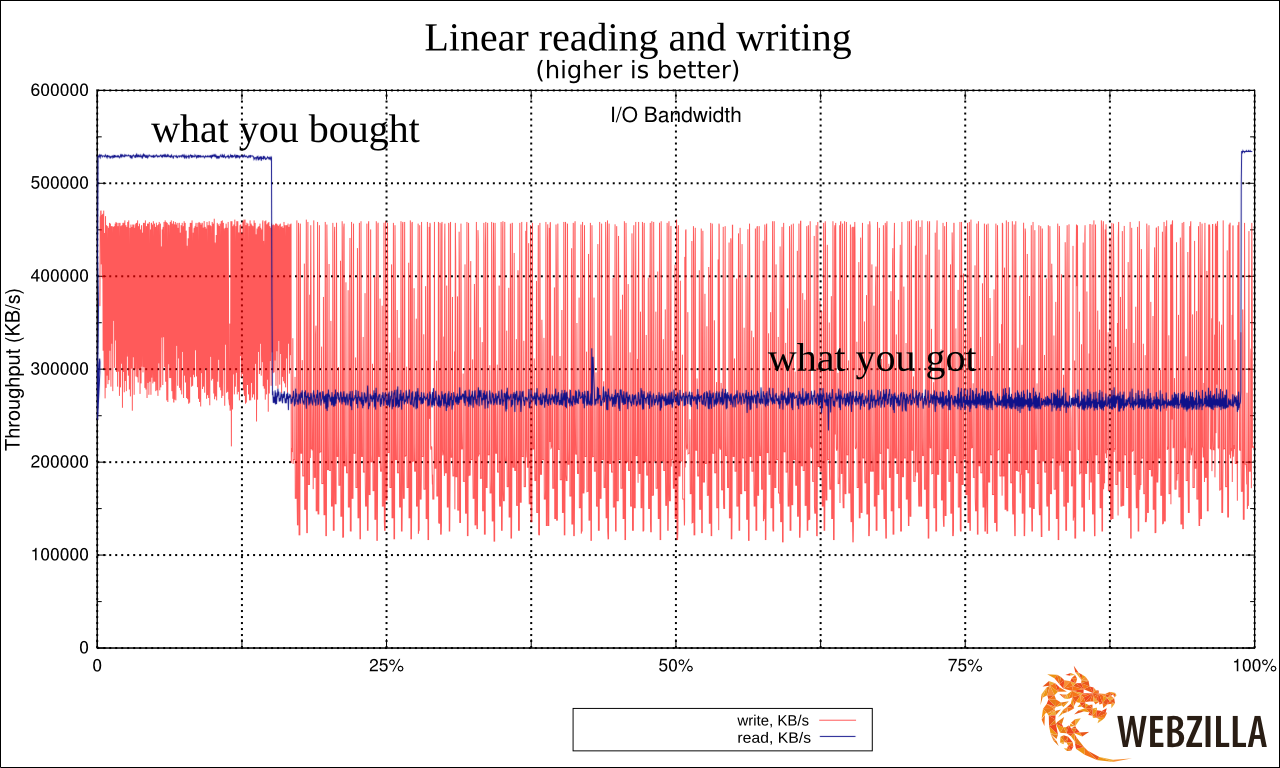
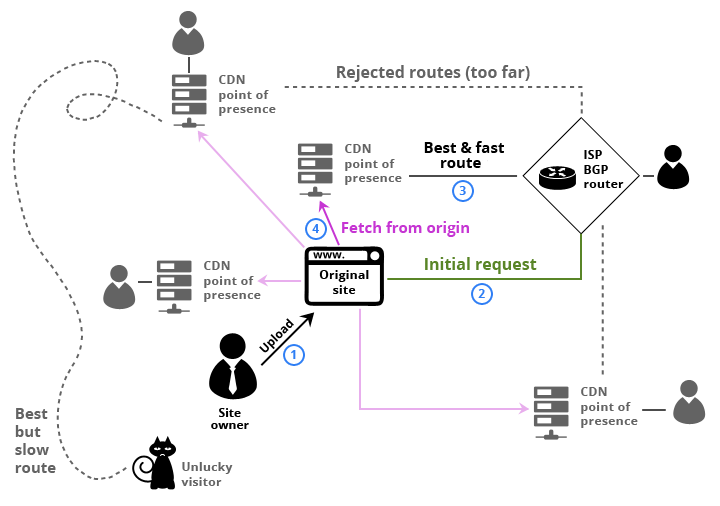
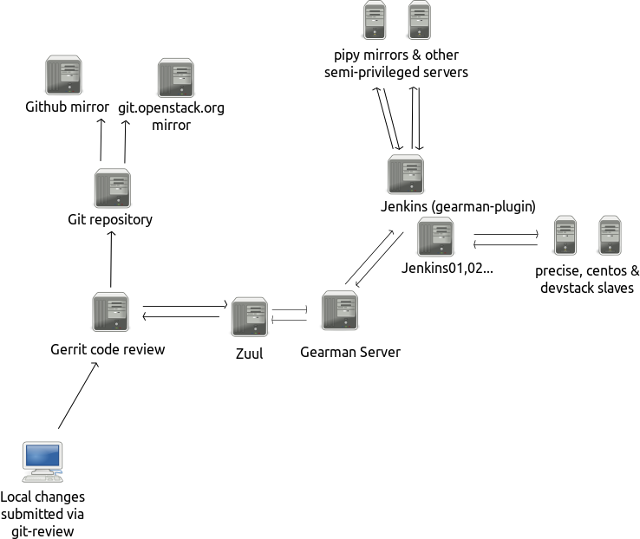
Среди всех служебных обязанностей системного администратора, самой интересной, сложной и продуктивной, на мой взгляд, является детективная работа по мотивам случившегося «инцидента». При этом, в отличие от реальной криминологии, системный администратор сам себе одновременно и детектив, и эксперт по вещественным доказательствам.
Я сейчас исключаю из рассмотрения инциденты с осмысленным злым умыслом, это отдельный топик. Речь про стихийные проблемы (сервер упал/завис, виртуальная машина начала тормозить а потом перестала, приложение потеряло 100500 транзакций и считает, что всё хорошо).
Иногда она тривиальная («самопроизвольно перезагрузился сервер», или «упал самолёт»). Иногда она крайне трудная для объяснения («клиенты жалуются что у не получается поменять регион», при этом все сотрудники с клиентскими аккаунтами регион поменять могут). Чаще всего, чем дальше от системного администратора источник жалобы, тем более размытой становится жалоба: «клиент говорит, что после заказа в интернет-магазине плюшевого медведя он не может поменять регион на IE7 при использовании LTE-коннекта через USB-модем, а ещё он получает 500ую ошибку при попытке отменить операцию и нажатии „назад“).
Ещё более сложным является случай, когда несколько проблем сливаются вместе: „сервер внезапно перезагрузился, а на другом сервере был таймаут работы с базой данных, а клиенты в это время писали, что у них не грузятся картинки“. Сколько тут проблем? Одна, две, три, а может и больше? Какие из проблем надо молча объединить (база данных и отсутствие картинок), а какие надо учитывать раздельно? А если в этот момент ещё придёт жалоба, что пользователь не может залогиниться в систему — это обычное „забыл пароль“ или тоже симптом? А если таких пользователей два? Или кто-то мимоходом говорит, „что-то у меня почта не проходит“?
Подсознательно в момент начала проблем, каждая новая жалоба тут же объединяется с существующими (и может завести не туда), плюс резко увеличивает стресс из-за того, что приходится думать не о трёх симптомах, а о восьми, например. А в голове хорошо только семь удерживаются. Но в то же время в моей практике бывало так, что пришедший „новый“ симптом с лёгкостью приводил к сути проблемы и её устранению…… за вычетом того, что серьёзная проблема (с которой всё началось) не имеет никакого отношения к радостно и быстро починенной ерунде. А время потрачено.
Простого совета для такой ситуации нет. В сложных ситуациях я обычно выписываю всё, что слышу и замечаю, не анализируя, но фиксируя время.
То есть журнал (в sticky notes) выглядит так:
Не стоит увлекаться (не время печатать), но симптомы стоит выписывать. Один это случай или несколько, важные это симптомы или нет, станет понятно потом. Я обычно начинаю выписывать примерно после третьего отвлекающего обращения.
Вторым аспектом проблемы является доказательство существования проблемы. Самая ненавистная фраза, которой не удаётся избежать:
Я сейчас исключаю из рассмотрения инциденты с осмысленным злым умыслом, это отдельный топик. Речь про стихийные проблемы (сервер упал/завис, виртуальная машина начала тормозить а потом перестала, приложение потеряло 100500 транзакций и считает, что всё хорошо).
Суть происшествия
Иногда она тривиальная («самопроизвольно перезагрузился сервер», или «упал самолёт»). Иногда она крайне трудная для объяснения («клиенты жалуются что у не получается поменять регион», при этом все сотрудники с клиентскими аккаунтами регион поменять могут). Чаще всего, чем дальше от системного администратора источник жалобы, тем более размытой становится жалоба: «клиент говорит, что после заказа в интернет-магазине плюшевого медведя он не может поменять регион на IE7 при использовании LTE-коннекта через USB-модем, а ещё он получает 500ую ошибку при попытке отменить операцию и нажатии „назад“).
Ещё более сложным является случай, когда несколько проблем сливаются вместе: „сервер внезапно перезагрузился, а на другом сервере был таймаут работы с базой данных, а клиенты в это время писали, что у них не грузятся картинки“. Сколько тут проблем? Одна, две, три, а может и больше? Какие из проблем надо молча объединить (база данных и отсутствие картинок), а какие надо учитывать раздельно? А если в этот момент ещё придёт жалоба, что пользователь не может залогиниться в систему — это обычное „забыл пароль“ или тоже симптом? А если таких пользователей два? Или кто-то мимоходом говорит, „что-то у меня почта не проходит“?
Подсознательно в момент начала проблем, каждая новая жалоба тут же объединяется с существующими (и может завести не туда), плюс резко увеличивает стресс из-за того, что приходится думать не о трёх симптомах, а о восьми, например. А в голове хорошо только семь удерживаются. Но в то же время в моей практике бывало так, что пришедший „новый“ симптом с лёгкостью приводил к сути проблемы и её устранению…… за вычетом того, что серьёзная проблема (с которой всё началось) не имеет никакого отношения к радостно и быстро починенной ерунде. А время потрачено.
Простого совета для такой ситуации нет. В сложных ситуациях я обычно выписываю всё, что слышу и замечаю, не анализируя, но фиксируя время.
То есть журнал (в sticky notes) выглядит так:
- Мониторинг сработал на srv1 (22:05)
- (имя) сказал про проблемы с почтой (22:07)
- Не могу залогиниться на srv12 (22:08)/refused — Зашёл 22:16, dmesg чисто, аптайм большой
- Не могу залогиниться на srv13 (22:10) (timeout) — отвалился офисный wifi (22:11)
- Не открывается панель (22:12)
- Саппорт пишет, что клиент жалуется, что ничего не работает, 22:15
Не стоит увлекаться (не время печатать), но симптомы стоит выписывать. Один это случай или несколько, важные это симптомы или нет, станет понятно потом. Я обычно начинаю выписывать примерно после третьего отвлекающего обращения.
Вторым аспектом проблемы является доказательство существования проблемы. Самая ненавистная фраза, которой не удаётся избежать:
У меня всё работает
После того, как Энийские Авиалинии пожаловались производителю на то, что самолёты иногда падают, разработчик проверил, что самолёты взлетают/садятся и закрыл тикет с 'Unable to reproduce'. Сотрудники поддержки Энийских Авиалиний продолжают собирать статистику по падению самолётов и пытаются научиться воспроизводить падение в лабораторных условиях.