
Вы наверняка знакомы с ситуацией, когда при обращении в какую-либо крупную организацию приходится подавать целый пакет документов, точнее пакет их сканов. И это в век «цифры»! Теперь посмотрите на это глазами второй стороны и представьте, что у вас миллионы таких заявок со сканами, и они… не содержат информации о границах документов. Апокалипсис? Всё придётся сегментировать вручную? К счастью, существуют алгоритмы автоматической сегментации потоков многостраничных документов. Здесь мы расскажем о новом подходе в сегментации с использованием модели BERT.
Итак, потоки необходимо разделить на отдельные документы — сегментировать, чтобы далее с ними было удобно работать. После сегментации разделённые документы, как правило, добавляются в систему документооборота. Поэтому часто вместе с задачей сегментации возникает задача классификации документов — присвоение документу метки одного из конечных наборов классов, что упрощает дальнейшую навигацию в системе документооборота.
В классификации документов модель BERT (Bidirectional Encoder Representations for Transformers) уже применялась ранее. Но для задачи сегментации, насколько нам известно, это первая работа с использованием этой языковой модели.

Кстати, задача сегментации потоков актуальна не только в банковской деятельности. Ее решают везде, где приходится иметь дело с потоками документов, например: в оцифровке крупных архивов документов, в digital-mailroom при оцифровке бумажной почты.
Как это работает
Cегментация потоков документов (Page Stream Segmentation — PSS) и сопутствующая задача классификации (Document Image Classification — DIC) исследовались многими авторами. В работе Wiedemann, Heyer (2019) сделан обзор многих таких исследований, и среди них выделены два подхода к PSS и DIC: с помощью системы правил (Rule-Based Systems — RBS) и с применением машинного обучения.
Системы RBS (Karpinski and Belaid, 2016; Hamdi at el. 2017) подразумевают выделение из распознанного текста с помощью регулярных выражений специальных дескрипторов, определяющих границы документов в потоке. Дескрипторами могут быть приветственные фразы, названия частотных сущностей, номера страниц, layout-признаки: размеры шрифтов, расположение сущностей на странице и др. RBS может оказаться довольно эффективным для однородных (homogeneous) датасетов с хорошим качеством сканов и определённой структурой документов, встречающихся, в частности, в бизнес-документации (счета, накладные, письма и т. п.). Но для RBS необходимо составлять вручную правила для выделения дескрипторов, что является несомненным минусом на датасетах с сильно разрозненными тематиками (heterogeneous datasets).
Подходы с применением машинного обучения (Rusinol at el. 2014; Daher, Belaid, 2014; Agin at el. 2015) и глубокого машинного обучения (Harley at el. 2015; Noce at el. 2016; Gallo at el. 2016; Wiedemann, Heyer, 2019) кажутся более привлекательными, поскольку не требуют глубокого погружения в суть текстов документов, как в RBS. Обучение в этих подходах в основном проводится на текстовых и визуальных признаках и их комбинациях. Также применяется объединение (fusion) отдельных моделей на текстовых и визуальных признаках, когда одна модель может уточнить результат другой модели и в итоге улучшить общий результат.
В работе Harley at el. (2015) для классификации документов из датасета RVL-CDIP, введённого в этой же работе, используются глубокие свёрточные нейросети CNN на визуальных признаках. В работах Noce at el. (2016) и Gallo at el. (2016) для классификации документов применяются нейросети и трансфер-лёрнинг. В работе Gallo at el. (2016) классификация (DIC) строится только на визуальных признаках, но для повышения качества используются признаки соседних страниц. При этом автоматически решается задача сегментации (PSS): если предсказанный класс текущей страницы отличается от класса предыдущей, значит, начался новый документ. Стоит отметить, что сегментация (PSS) на основе классификации (DIC) имеет большой недостаток: она не разделяет документы одного и того же класса. Если в датасете сильно доминирует какой-либо класс, то сегментация (PSS) на основе классификации (DIC) практически бесполезна, поскольку уже разделённые потоки одного класса необходимо повторно разделять.
В работах Daher, Belaid (2014), Agin at el. (2015), Hamdi at el. (2018), Wiedemann, Heyer (2019) для нахождения границ документов в потоках довольно эффективно используется бинарная классификация: для каждой пары соседних страниц из потока модель предсказывает, является ли следующая страница в паре продолжением документа (SD — same document) или начался новый документ (ND — New Document). В работе Wiedemann, Heyer (2019) задача PSS решается с помощью бинарной классификации (SD/ND) с использованием комбинации текстовых и визуальных признаков и с применением глубоких нейросетей.
В нашей работе мы также будем использовать бинарную классификацию для определения границ документов в потоке. Причём для пары соседних страниц мы будем генерировать текстовые признаки с помощью модели BERT.
Идея использования модели BERT в задаче сегментации
Модели машинного обучения на основе BERT получили большую популярность, поскольку с их помощью были улучшены, и порой существенно, оценки качества многих задач NLP (Natural Language Processing).
Модель BERT сначала предобучают на широких корпусах текстов, а затем используют для решения конкретных задач, в том числе и на небольших датасетах. Во время предобучения модель решает две задачи: MLM (Masked Language Model) и NSP (Next Sentence Prediction). В задаче MLM случайно метится (маскируется) определённая доля токенов (слов или частей слов) входной последовательности, и задача состоит в том, чтобы восстановить значения токенов, которые были замаскированы. Задача NSP — это бинарная классификация на парах предложений (или спанов текстов), когда нужно предсказать, является ли второе предложение (или спан текста) логичным продолжением первого. При решении конкретных задач предобученный BERT используют для трансфер лёрнинга, извлекая признаки из текста. В случае файн-тюнинга модель BERT обучают в составе специализированной модели, решающей конечную задачу. Более подробно о принципах построения этой модели мы рассказывали в нашем предыдущем посте о классификации документов.
Касательно нашей задачи: зачастую начало текста текущей страницы многостраничного документа является логичным продолжением конца текста предыдущей страницы, и модель BERT, предобученная на задаче NSP, может улавливать сложные контекстные зависимости этих кусков текстов. Мы предполагаем, что сможем извлекать с помощью BERT сильные текстовые признаки на парах страниц для бинарной классификации (SD/ND).
Генерация входов модели
Мы будем решать задачу сегментации PSS на нашем закрытом датасете (Documents for Credit Dataset — DCD), составленном из документов, предоставляемых компаниями для получения кредита в Банке ВТБ.
DCD был накоплен за продолжительный период. Сканирование документов проводилось потоками, как правило, один поток — это набор документов от одной компании. Потоки сегментировались в полуавтоматическом режиме. DCD включает около 63 тыс. уже сегментированных одностраничных и многостраничных документов, суммарно около 232 тыс. страниц.
Бизнес-подразделениями банка были выделены около 300 категорий документов. Из них 10 базовых категорий: договор аренды, выписка из реестра участников, устав компании, свидетельство о постановке на учет в налоговом органе, вопросник для юридических лиц, паспорт РФ, лист записи ЕГРЮЛ, свидетельство о государственной регистрации юридического лица, приказы/распоряжения, решения/протоколы, а другие менее значимые документы отнесем к категории «Иное».
Поскольку у нас не так много оригинальных неразделённых потоков (метки принадлежности к потокам не сохранялись после разделения), мы вынуждены были генерировать потоки заново из уже сегментированных документов, чтобы они были приближены по составу к потокам, поступающим на сегментацию:
- Каждый поток должен содержать по одному документу из каждой базовой категории.
- Каждый поток должен содержать три документа из категории «Иное».
- К 2 % потоков из каждой выборки добавляются ещё по два документа из каждого базового класса.
- 81 % одно- и многостраничных документов датасета использовались для генерации потоков Train, 9 % — для генерации потоков Dev, и 10 % — для генерации потоков Test.
- Для формирования потока отдельные документы внутри потока перемешиваются случайным образом с сохранением порядка страниц внутри документа.
Согласно этим правилам мы сгенерировали 10 000 потоков для Train, 2 000 потоков для Dev, 2 000 потоков для Test.
Потоки из Train мы случайным образом перемешали, выставили потоки друг за другом и получили один длинный поток, в котором пары соседних страниц (вернее, извлечённые из них признаки) и их метки (Same Document или New Document) будут, соответственно, входами и целевыми метками нашей будущей модели бинарной классификации. Аналогично из потоков получаем входы и целевые метки для Dev и Test.
| Document lengths (pages) | Train | Test | Dev |
| 1 | 24953 | 3075 | 2752 |
| 2 | 10170 | 1251 | 1135 |
| 3 | 3680 | 452 | 422 |
| 4 | 2549 | 310 | 279 |
| 5 | 1857 | 221 | 187 |
| 6 | 1246 | 165 | 153 |
| 7 | 895 | 116 | 105 |
| 8 | 912 | 89 | 98 |
| 9 | 968 | 120 | 92 |
| >=10 | 4453 | 536 | 515 |
| Single-page documents | 24953 (48%) | 3075 (49%) | 2752 (48%) |
| Multi-page documents | 26730 (52%) | 3260 (51%) | 2986 (52%) |
| Total documents | 51683 | 6335 | 5738 |
| Total pages | 188504 | 22553 | 21022 |
| # new document (gen. pairs) | 133539 (49%) | 26879 (62%) | 26879 (64%) |
| # same document (gen. pairs) | 136817 (51%) | 16218 (38%) | 15284 (36%) |
Наш подход
Для решения задачи сегментации PSS мы будем использовать бинарную классификацию SD (same document) и ND (new document), описанную выше во введении. В качестве признаков наша модель получает эмбеддинг пары соседних страниц, составленный из визуальных эмбеддингов каждой из страниц, и одного общего текстового эмбеддинга, полученного сразу для пары. Число пар страниц по каждой выборке Train/Dev/Test можно посмотреть в таблице 1.
Визуальный эмбеддинг каждой страницы — вектор длины 512 — мы получаем как выход предпоследнего слоя CNN ResNet34, He at al. (2015).
Текстовый эмбеддинг, общий для пары страниц, получаем с помощью модели RuBERT (Russian, cased, 12-layer, 768-hidden, 12-heads, 180M parameters) от DeepPavlov. Для этого на вход модели подаем вектор из 512 токенов следующего вида: на первом месте — CLS-токен, потом N (информационных) токенов, соответствующих спану текста конца первой страницы из пары, далее (разделяющий) SEP-токен, потом M (информационных) токенов, соответствующих спану текста начала второй страницы из пары, и потом снова SEP-токен. Суммарное число информационных токенов, которое можно разместить во входном векторе, не более 509: N + M <= 509. Мы хотим как можно эффективнее использовать возможности модели BERT, поэтому стремимся максимально заполнить входной вектор модели токенами.
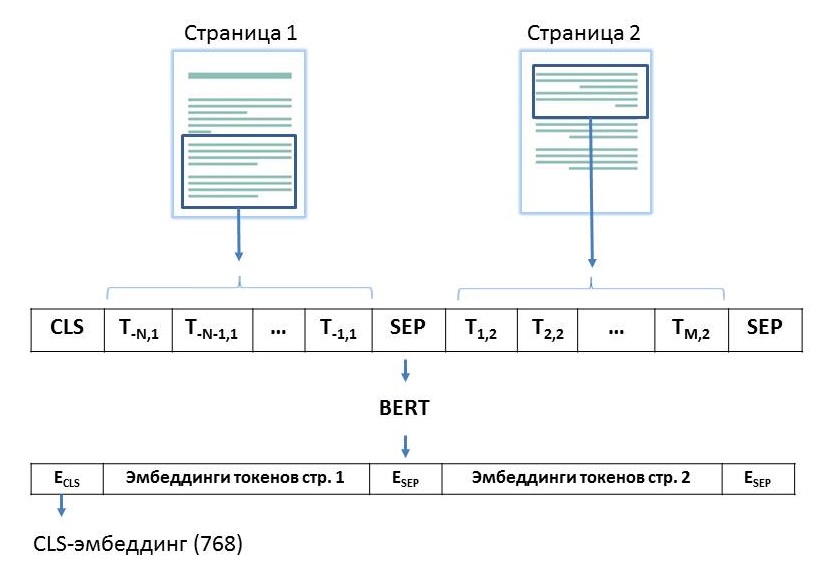
Схема получения текстовых признаков для пары страниц. Ti,j — токен с номером i в тексте страницы j. Для удобства отображения отсчёт токенов страницы 1 идёт с конца.
Поскольку RuBERT предобучен на задачу NSP, то CLS-эмбеддинг (вектор длины 768) должен содержать в себе наиболее полную информацию, является ли второй текст логическим продолжением первого. Его и возьмём в качестве общего эмбеддинга для пары страниц.
Бейслайн
Итак, для каждой пары страниц два визуальных эмбеддинга (два вектора длины 512) и один текстовый эмбеддинг (вектор длины 768) объединяются в один общий визуально-текстовый эмбеддинг (вектор длины 1792). Далее на таких эмбеддингах строится бинарная классификация SD (Same Document) / ND (New Document) на основе MLP (Multi Layer Perceptron) с одним скрытым слоем нейронов длины 896, dropuout — 0.3. Это наш бейслайн.

Общая схема модели
Основная модель
Следующим шагом мы провели дообучение (further-pretraining) модели RuBERT на обеих задачах MLM и NSP на нашем датасете DCD. Повторно сняли визуально-текстовые признаки, как в бейслайн, и на них построили бинарную классификацию на основе модели MLP с одним скрытым слоем нейронов длины 896 и dropout 0.3. В итоге получили основную модель улучшенного качества.
Результаты и их обсуждение
| Число пар | Accuracy | Kappa | |
| 43097 | 0.9669 | 0.9294 | |
| Пары хотя бы c одним одностр. док-м | 19188 | 0.9771 | - |
| Пары с обеими страницами из многостр. док-тов | 23909 | 0.9587 | 0.9072 |
| Число пар | Accuracy | Kappa | |
| 43097 | 0.9819 | 0.9615 | |
| Пары хотя бы c одним одностр. док-м | 19188 | 0.9898 | - |
| Пары c обеими страницами из многостр. док-тов | 23909 | 0.9756 | 0.9450 |
Даже без дообучения Бейслайн даёт приемлемое качество 0.9669. А после дообучения модели BERT, как и ожидалось, качество ещё немного повысилось до 0.9819.
Конечно же можно и дальше улучшать нашу модель. Идей по дальнейшей оптимизации довольно много, например: можно провести файн-тюнинг RuBERT на нашей задаче, дообучить ResNet34 (или другую CNN) на широком корпусе корпоративных документов, можно попробовать добавлять к текстовым эмбеддингам токенов их 2-d позиционирование на странице, как это делают авторы модели LayoutLM для одностраничной классификации и т.п. Но мы в данной статье преследовали цель — показать саму идею нашего подхода к сегментации, когда относительно легко извлекается выгода из "сильной" модели BERT.
Заключение
Задача сегментации набирает популярность, и назрела необходимость в составлении общедоступного и достаточно большого датасета на английском языке, содержащего несколько десятков тысяч многостраничных документов, на котором можно будет объективно сравнивать оценки нашего и других подходов.
