
В 2018 году в профессиональных кругах и на тематических конференциях, посвященных AI, появилось понятие MLOps, которое быстро закрепилось в отрасли и сейчас развивается как самостоятельное направление. В перспективе MLOps может стать одной из наиболее востребованных сфер в IT. Что же это такое и с чем его едят, разбираемся под катом.

MLOps (объединение технологий и процессов машинного обучения и подходов к внедрению разработанных моделей в бизнес-процессы) — это новый способ сотрудничества между представителями бизнеса, учеными, математиками, специалистами в области машинного обучения и IT-инженерами при создании систем искусственного интеллекта.
Иными словами, это способ превращения методов и технологий машинного обучения в полезный инструмент для решений задач бизнеса.
Нужно понимать, что цепочка продуктивизации начинается задолго до разработки модели. Ее первым шагом является определение задачи бизнеса, гипотезы о ценности, которую можно извлечь из данных, и бизнес-идеи по ее применению.
Само понятие MLOps возникло как аналогия понятия DevOps применительно к моделям и технологиям машинного обучения. DevOps — это подход к разработке ПО, позволяющий повысить скорость внедрения отдельных изменений при сохранении гибкости и надежности с помощью ряда подходов, среди которых непрерывная разработка, разделение функций на ряд независимых микросервисов, автоматизированное тестирование и деплоймент отдельных изменений, глобальный мониторинг работоспособности, система оперативного реагирования на выявленные сбои и др.
DevOps определил жизненный цикл программного обеспечения и в сообществе специалистов возникла идея использовать ту же методику применительно к большим данным. DataOps — попытка адаптировать и расширить методику с учетом особенностей хранения, передачи и обработки больших массивов данных в разнообразных и взаимодействующих друг с другом платформах.
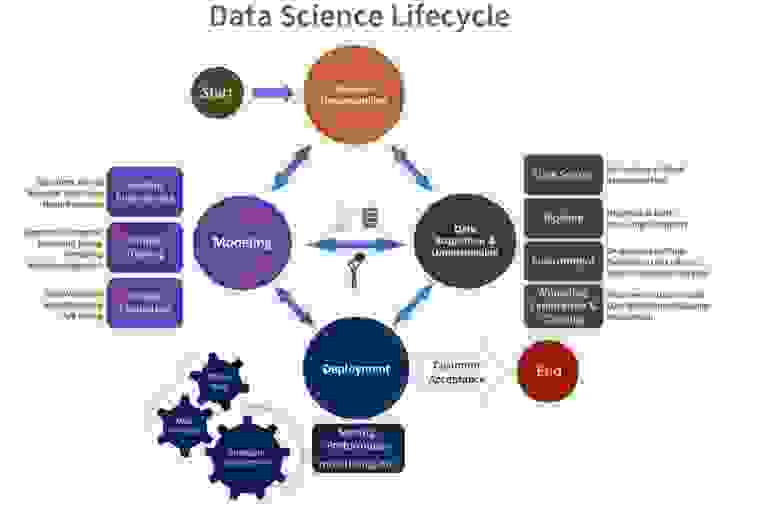
С появлением определенной критической массы моделей машинного обучения, внедренных в бизнес-процессы предприятий, было замечено сильное сходство жизненного цикла математических моделей машинного обучения и жизненного цикла ПО. Разница только в том, что алгоритмы моделей создаются с помощью инструментов и методов машинного обучения. Поэтому естественным образом возникла идея применить и адаптировать для моделей машинного обучения уже известные подходы к разработке ПО. Таким образом, в жизненном цикле моделей машинного обучения можно выделить следующие ключевые этапы:
Когда в процессе эксплуатации возникает необходимость изменить или дообучить модель на новых данных, цикл запускается заново — модель дорабатывается, тестируется, и деплоится новая версия.
В этом жизненном цикле выглядит логичным использование DevOps-инструментов: автоматизированное тестирование, деплоймент и мониторинг, оформление расчета моделей в виде отдельных микросервисов. Но есть и ряд особенностей, которые препятствуют прямому применению этих инструментов без дополнительной ML-обвязки.
В качестве примера, на котором мы продемонстрируем применение подхода MLOps, возьмем ставшую классической задачу роботизации чата поддержки банковского (или любого другого) продукта. Обычно бизнес-процесс поддержки с помощью чата выглядит следующим образом: клиент вводит в чате сообщение с вопросом и получает ответ специалиста в рамках заранее определенного дерева диалогов. Задача автоматизации такого чата обычно решается с помощью экспертно определенных наборов правил, очень трудоемких в разработке и сопровождении. Эффективность такой автоматизации, в зависимости от уровня сложности задачи, может составлять 20–30%. Естественно, возникает идея, что более выгодным является внедрение модуля искусственного интеллекта — модели, разработанной с помощью машинного обучения, которая:
Как заставить такую продвинутую модель работать?
Как и при решении любой другой задачи, прежде чем разрабатывать такой модуль, необходимо определить бизнес-процесс и формально описать конкретную задачу, которую мы будем решать с применением метода машинного обучения. В этой точке и начинается процесс операционализации, обозначенный в аббревиатуре Ops.
Следующим шагом специалист Data science в сотрудничестве с инженером по данным проверяет доступность и достаточность данных и гипотезу бизнеса о работоспособности бизнес-идеи, разрабатывая прототип модели и проверяя ее фактическую эффективность. Только после подтверждения бизнесом может начинаться переход от разработки модели к встраиванию ее в системы, выполняющие конкретный бизнес-процесс. Сквозное планирование внедрения, глубокое понимание на каждом этапе, как модель будет использоваться и какой экономический эффект она принесет, является основополагающим моментом в процессах внедрения подходов MLOps в технологический ландшафт компании.
С развитием технологий ИИ лавинообразно увеличивается количество и разнообразие задач, которые могут быть решены при помощи машинного обучения. Каждый такой бизнес-процесс — это экономия компании за счет автоматизации труда сотрудников массовых позиций (колл-центр, проверка и сортировка документов и т. п.), это расширение клиентской базы за счет добавления новых привлекательных и удобных функций, экономия средств за счет оптимального их использования и перераспределения ресурсов и многое другое. В конечном счете любой процесс ориентирован на создание ценности и, как следствие, должен приносить определенный экономический эффект. Здесь очень важно четко сформулировать бизнес-идею и рассчитать предполагаемую прибыль от внедрения модели в общей структуре создания ценности компании. Случаются ситуации, когда внедрение модели не оправдывает себя, и время, затраченное специалистами по машинному обучению, обходится гораздо дороже, нежели рабочее место оператора, выполняющего эту задачу. Именно поэтому такие случаи необходимо стараться выявлять на ранних этапах создания систем ИИ.
Следовательно, прибыль модели начинают приносить только тогда, когда в процессе MLOps была верно сформулирована бизнес-задача, расставлены приоритеты и на ранних этапах разработки сформулирован процесс внедрения модели в систему.
Исчерпывающий ответ на принципиальный вопрос бизнеса о том, насколько ML-модели применимы для решения задач, общий вопрос доверия к ИИ — это один из ключевых вызовов в процессе развития и внедрения подходов MLOps. Первоначально бизнес скептически воспринимает внедрение машинного обучения в процессы — сложно полагаться на модели в тех местах, где ранее, как правило, работали люди. Для бизнеса программы представляются «черным ящиком», релевантность ответов которого еще надо доказать. Кроме того, в банковской деятельности, в бизнесе операторов связи и других существуют жесткие требования государственных регуляторов. Аудиту подвергаются все системы и алгоритмы, которые внедрены в банковские процессы. Чтобы решить эту задачу, доказать бизнесу и регуляторам обоснованность и корректность ответов искусственного интеллекта, вместе с моделью внедряются средства мониторинга. Кроме того, существует процедура независимой валидации, обязательная для регуляторных моделей, которая соответствует требованиям ЦБ. Независимая экспертная группа проводит аудит результатов, полученных моделью с учетом входных данных.
Второй вызов — оценка и учет модельных рисков при внедрении модели машинного обучения. Если даже человек не может со стопроцентной уверенностью ответить на вопрос, белым было то самое платье или голубым, то и искусственный интеллект тоже имеет право на ошибку. Также стоит учесть, что со временем данные могут меняться, и моделям необходимо дообучаться, чтобы выдавать достаточно точный результат. Чтобы бизнес-процесс не пострадал, необходимо управлять модельными рисками и отслеживать работу модели, регулярно дообучая ее на новых данных.

Но после первой стадии недоверия начинает проявляться обратный эффект. Чем больше моделей успешно внедряется в процессы, тем больше у бизнеса растет аппетит к использованию искусственного интеллекта — находятся новые и новые задачи, которые можно решить методами машинного обучения. Каждая задача запускает целый процесс, требующий тех или иных компетенций:
Весь цикл требует большого количества высококвалифицированных специалистов. В определенной точке развития и степени проникновения ML-моделей в бизнес-процессы оказывается, что линейно масштабировать число специалистов пропорционально росту количества задач становится дорого и неэффективно. Поэтому возникает вопрос автоматизации процесса MLOps — определение нескольких стандартных классов задач машинного обучения, разработка типовых пайплайнов обработки данных и дообучения моделей. В идеальной картине для решения таких задач требуются профессионалы, одинаково хорошо владеющие компетенциями на стыке BigData, Data Science, DevOps и IT. Поэтому самая большая проблема в индустрии Data Science и самый большой вызов при организации процессов MLOps — это отсутствие такой компетенции на имеющемся рынке подготовки кадров. Специалисты, удовлетворяющие таким требованиям, в настоящий момент единичны на рынке труда и ценятся на вес золота.
В теории все задачи MLOps можно решать классическими инструментами DevOps и не прибегать к специализированному расширению ролевой модели. Тогда, как мы уже отметили выше, дата-сайентист должен быть не только математиком и специалистом по аналитике данных, но и гуру всего пайплайна — на его плечи ложится разработка архитектуры, программирование моделей на нескольких языках в зависимости от архитектуры, подготовка витрины данных и деплоймент самого приложения. Однако создание технологической обвязки, реализуемой в сквозном процессе MLOps, занимает до 80% трудозатрат, а это значит, что квалифицированный математик, которым является качественный Data Scientist, будет только 20% времени посвящать своей специальности. Поэтому разграничение ролей специалистов, осуществляющих процесс внедрения моделей машинного обучения, становится жизненно необходимым.
Насколько детально должны разграничиваться роли, зависит от масштабов предприятия. Одно дело, когда в стартапе один специалист, труженик на запасе энергетиков, сам себе и инженер, и архитектор, и DevOps. Совсем другое дело, когда на крупном предприятии все процессы разработки моделей сконцентрированы на нескольких Data Science специалистах высокого уровня, в то время как программист или специалист по работе с базами данных — более распространенная и менее дорогая компетенция на рынке труда — может взять на себя большую часть рутинных задач.
Таким образом, от того, где же проходит граница в выборе специалистов для обеспечения процесса MLOps и как организован процесс операционализации разрабатываемых моделей, напрямую зависит скорость и качество разрабатываемых моделей, производительность команды и микроклимат в ней.
Мы не так давно начали строить структуру компетенций и процессы MLOps. Но уже сейчас в стадии тестирования MVP находятся наши проекты по управлению жизненным циклом моделей и по применению моделей как сервис.
Также мы определили оптимальную для крупного предприятия структуру компетенций и организационную структуру взаимодействия между всеми участниками процесса. Были организованы Agile-команды, решающие задачи для всего спектра бизнес-заказчиков, а также налажен процесс взаимодействия с проектными командами по созданию платформ, инфраструктуры, которая является фундаментом строящегося здания MLOps.
MLOps — развивающееся направление, которое испытывает нехватку компетенций и в будущем наберет обороты. А пока лучше всего отталкиваться от наработок и практик DevOps. Основной целью MLOps является более эффективное использование ML-моделей для решения задач бизнеса. Но при этом возникает множество вопросов:
От ответов на эти вопросы во многом будет зависеть, насколько быстро MLOps раскроет свой потенциал полностью.

Что такое MLOps
MLOps (объединение технологий и процессов машинного обучения и подходов к внедрению разработанных моделей в бизнес-процессы) — это новый способ сотрудничества между представителями бизнеса, учеными, математиками, специалистами в области машинного обучения и IT-инженерами при создании систем искусственного интеллекта.
Иными словами, это способ превращения методов и технологий машинного обучения в полезный инструмент для решений задач бизнеса.
Нужно понимать, что цепочка продуктивизации начинается задолго до разработки модели. Ее первым шагом является определение задачи бизнеса, гипотезы о ценности, которую можно извлечь из данных, и бизнес-идеи по ее применению.
Само понятие MLOps возникло как аналогия понятия DevOps применительно к моделям и технологиям машинного обучения. DevOps — это подход к разработке ПО, позволяющий повысить скорость внедрения отдельных изменений при сохранении гибкости и надежности с помощью ряда подходов, среди которых непрерывная разработка, разделение функций на ряд независимых микросервисов, автоматизированное тестирование и деплоймент отдельных изменений, глобальный мониторинг работоспособности, система оперативного реагирования на выявленные сбои и др.
DevOps определил жизненный цикл программного обеспечения и в сообществе специалистов возникла идея использовать ту же методику применительно к большим данным. DataOps — попытка адаптировать и расширить методику с учетом особенностей хранения, передачи и обработки больших массивов данных в разнообразных и взаимодействующих друг с другом платформах.
С появлением определенной критической массы моделей машинного обучения, внедренных в бизнес-процессы предприятий, было замечено сильное сходство жизненного цикла математических моделей машинного обучения и жизненного цикла ПО. Разница только в том, что алгоритмы моделей создаются с помощью инструментов и методов машинного обучения. Поэтому естественным образом возникла идея применить и адаптировать для моделей машинного обучения уже известные подходы к разработке ПО. Таким образом, в жизненном цикле моделей машинного обучения можно выделить следующие ключевые этапы:
- определение бизнес-идеи;
- обучение модели;
- тестирование и внедрение модели в бизнес-процесс;
- эксплуатация модели.
Когда в процессе эксплуатации возникает необходимость изменить или дообучить модель на новых данных, цикл запускается заново — модель дорабатывается, тестируется, и деплоится новая версия.
Отступление. Почему дообучить, а не переобучить? Термин «переобучение модели» имеет двоякое толкование: среди специалистов он означает дефект модели, когда модель хорошо предсказывает, фактически повторяет прогнозируемый параметр на обучающей выборке, но гораздо хуже работает на внешней выборке данных. Естественно, такая модель является браком, поскольку данный дефект не позволяет ее применять.
В этом жизненном цикле выглядит логичным использование DevOps-инструментов: автоматизированное тестирование, деплоймент и мониторинг, оформление расчета моделей в виде отдельных микросервисов. Но есть и ряд особенностей, которые препятствуют прямому применению этих инструментов без дополнительной ML-обвязки.

Как заставить модели работать и приносить прибыль
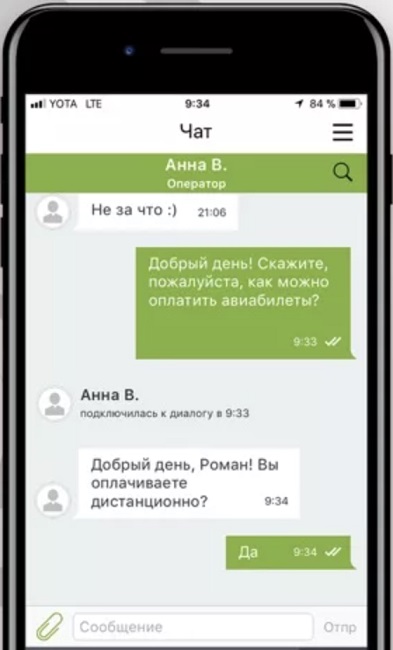
В качестве примера, на котором мы продемонстрируем применение подхода MLOps, возьмем ставшую классической задачу роботизации чата поддержки банковского (или любого другого) продукта. Обычно бизнес-процесс поддержки с помощью чата выглядит следующим образом: клиент вводит в чате сообщение с вопросом и получает ответ специалиста в рамках заранее определенного дерева диалогов. Задача автоматизации такого чата обычно решается с помощью экспертно определенных наборов правил, очень трудоемких в разработке и сопровождении. Эффективность такой автоматизации, в зависимости от уровня сложности задачи, может составлять 20–30%. Естественно, возникает идея, что более выгодным является внедрение модуля искусственного интеллекта — модели, разработанной с помощью машинного обучения, которая:
- способна обработать без участия оператора большее количество запросов (в зависимости от темы, в некоторых случаях эффективность может достигать 70–80%);
- лучше адаптируется под нестандартные формулировки в диалоге — умеет определять интент, реальное желание пользователя по не четко сформулированному запросу;
- умеет определять, когда ответ модели адекватен, а когда в качестве «осознанности» этого ответа есть сомнения и нужно задать дополнительный уточняющий вопрос или переключиться на оператора;
- может быть дообучена автоматизированно (вместо группы разработчиков, постоянно адаптирующих и корректирующих сценарии ответов, модель дообучает специалист по Data Science, применяя соответствующие библиотеки машинного обучения).

Как заставить такую продвинутую модель работать?
Как и при решении любой другой задачи, прежде чем разрабатывать такой модуль, необходимо определить бизнес-процесс и формально описать конкретную задачу, которую мы будем решать с применением метода машинного обучения. В этой точке и начинается процесс операционализации, обозначенный в аббревиатуре Ops.
Следующим шагом специалист Data science в сотрудничестве с инженером по данным проверяет доступность и достаточность данных и гипотезу бизнеса о работоспособности бизнес-идеи, разрабатывая прототип модели и проверяя ее фактическую эффективность. Только после подтверждения бизнесом может начинаться переход от разработки модели к встраиванию ее в системы, выполняющие конкретный бизнес-процесс. Сквозное планирование внедрения, глубокое понимание на каждом этапе, как модель будет использоваться и какой экономический эффект она принесет, является основополагающим моментом в процессах внедрения подходов MLOps в технологический ландшафт компании.
С развитием технологий ИИ лавинообразно увеличивается количество и разнообразие задач, которые могут быть решены при помощи машинного обучения. Каждый такой бизнес-процесс — это экономия компании за счет автоматизации труда сотрудников массовых позиций (колл-центр, проверка и сортировка документов и т. п.), это расширение клиентской базы за счет добавления новых привлекательных и удобных функций, экономия средств за счет оптимального их использования и перераспределения ресурсов и многое другое. В конечном счете любой процесс ориентирован на создание ценности и, как следствие, должен приносить определенный экономический эффект. Здесь очень важно четко сформулировать бизнес-идею и рассчитать предполагаемую прибыль от внедрения модели в общей структуре создания ценности компании. Случаются ситуации, когда внедрение модели не оправдывает себя, и время, затраченное специалистами по машинному обучению, обходится гораздо дороже, нежели рабочее место оператора, выполняющего эту задачу. Именно поэтому такие случаи необходимо стараться выявлять на ранних этапах создания систем ИИ.
Следовательно, прибыль модели начинают приносить только тогда, когда в процессе MLOps была верно сформулирована бизнес-задача, расставлены приоритеты и на ранних этапах разработки сформулирован процесс внедрения модели в систему.
Новый процесс – новые вызовы
Исчерпывающий ответ на принципиальный вопрос бизнеса о том, насколько ML-модели применимы для решения задач, общий вопрос доверия к ИИ — это один из ключевых вызовов в процессе развития и внедрения подходов MLOps. Первоначально бизнес скептически воспринимает внедрение машинного обучения в процессы — сложно полагаться на модели в тех местах, где ранее, как правило, работали люди. Для бизнеса программы представляются «черным ящиком», релевантность ответов которого еще надо доказать. Кроме того, в банковской деятельности, в бизнесе операторов связи и других существуют жесткие требования государственных регуляторов. Аудиту подвергаются все системы и алгоритмы, которые внедрены в банковские процессы. Чтобы решить эту задачу, доказать бизнесу и регуляторам обоснованность и корректность ответов искусственного интеллекта, вместе с моделью внедряются средства мониторинга. Кроме того, существует процедура независимой валидации, обязательная для регуляторных моделей, которая соответствует требованиям ЦБ. Независимая экспертная группа проводит аудит результатов, полученных моделью с учетом входных данных.
Второй вызов — оценка и учет модельных рисков при внедрении модели машинного обучения. Если даже человек не может со стопроцентной уверенностью ответить на вопрос, белым было то самое платье или голубым, то и искусственный интеллект тоже имеет право на ошибку. Также стоит учесть, что со временем данные могут меняться, и моделям необходимо дообучаться, чтобы выдавать достаточно точный результат. Чтобы бизнес-процесс не пострадал, необходимо управлять модельными рисками и отслеживать работу модели, регулярно дообучая ее на новых данных.

Но после первой стадии недоверия начинает проявляться обратный эффект. Чем больше моделей успешно внедряется в процессы, тем больше у бизнеса растет аппетит к использованию искусственного интеллекта — находятся новые и новые задачи, которые можно решить методами машинного обучения. Каждая задача запускает целый процесс, требующий тех или иных компетенций:
- дата-инженеры подготавливают и обрабатывают данные;
- дата-сайентисты применяют инструменты машинного обучения и разрабатывают модель;
- IT внедряют модель в систему;
- ML-инженер определяет, как эту модель корректно встроить в процесс, какой IT-инструментарий использовать в зависимости от требований к режиму применения модели с учетом потока обращений, времени ответа и т.п.
- ML-архитектор проектирует, как физически можно реализовать программный продукт в промышленной системе.
Весь цикл требует большого количества высококвалифицированных специалистов. В определенной точке развития и степени проникновения ML-моделей в бизнес-процессы оказывается, что линейно масштабировать число специалистов пропорционально росту количества задач становится дорого и неэффективно. Поэтому возникает вопрос автоматизации процесса MLOps — определение нескольких стандартных классов задач машинного обучения, разработка типовых пайплайнов обработки данных и дообучения моделей. В идеальной картине для решения таких задач требуются профессионалы, одинаково хорошо владеющие компетенциями на стыке BigData, Data Science, DevOps и IT. Поэтому самая большая проблема в индустрии Data Science и самый большой вызов при организации процессов MLOps — это отсутствие такой компетенции на имеющемся рынке подготовки кадров. Специалисты, удовлетворяющие таким требованиям, в настоящий момент единичны на рынке труда и ценятся на вес золота.
К вопросу о компетенциях
В теории все задачи MLOps можно решать классическими инструментами DevOps и не прибегать к специализированному расширению ролевой модели. Тогда, как мы уже отметили выше, дата-сайентист должен быть не только математиком и специалистом по аналитике данных, но и гуру всего пайплайна — на его плечи ложится разработка архитектуры, программирование моделей на нескольких языках в зависимости от архитектуры, подготовка витрины данных и деплоймент самого приложения. Однако создание технологической обвязки, реализуемой в сквозном процессе MLOps, занимает до 80% трудозатрат, а это значит, что квалифицированный математик, которым является качественный Data Scientist, будет только 20% времени посвящать своей специальности. Поэтому разграничение ролей специалистов, осуществляющих процесс внедрения моделей машинного обучения, становится жизненно необходимым.
Насколько детально должны разграничиваться роли, зависит от масштабов предприятия. Одно дело, когда в стартапе один специалист, труженик на запасе энергетиков, сам себе и инженер, и архитектор, и DevOps. Совсем другое дело, когда на крупном предприятии все процессы разработки моделей сконцентрированы на нескольких Data Science специалистах высокого уровня, в то время как программист или специалист по работе с базами данных — более распространенная и менее дорогая компетенция на рынке труда — может взять на себя большую часть рутинных задач.
Таким образом, от того, где же проходит граница в выборе специалистов для обеспечения процесса MLOps и как организован процесс операционализации разрабатываемых моделей, напрямую зависит скорость и качество разрабатываемых моделей, производительность команды и микроклимат в ней.
Что уже сейчас сделано нашей командой
Мы не так давно начали строить структуру компетенций и процессы MLOps. Но уже сейчас в стадии тестирования MVP находятся наши проекты по управлению жизненным циклом моделей и по применению моделей как сервис.
Также мы определили оптимальную для крупного предприятия структуру компетенций и организационную структуру взаимодействия между всеми участниками процесса. Были организованы Agile-команды, решающие задачи для всего спектра бизнес-заказчиков, а также налажен процесс взаимодействия с проектными командами по созданию платформ, инфраструктуры, которая является фундаментом строящегося здания MLOps.
Вопросы на будущее
MLOps — развивающееся направление, которое испытывает нехватку компетенций и в будущем наберет обороты. А пока лучше всего отталкиваться от наработок и практик DevOps. Основной целью MLOps является более эффективное использование ML-моделей для решения задач бизнеса. Но при этом возникает множество вопросов:
- Как сократить время для запуска моделей в производство?
- Как уменьшить бюрократические трения между командами разных компетенций и повысить нацеленность на сотрудничество?
- Как отслеживать модели, управлять версиями и организовывать эффективный мониторинг?
- Как создать действительно циклический жизненный цикл для современной модели ML?
- Как стандартизировать процесс машинного обучения?
От ответов на эти вопросы во многом будет зависеть, насколько быстро MLOps раскроет свой потенциал полностью.
