Мы давно ищем идеальный ETL инструмент для наших проектов. Ни один из существующих инструментов нас полностью не удовлетворял, и мы попробовали собрать из open-source компонентов идеальный инструмент для извлечения и обработки данных. Кажется, у нас это получилось! По крайней мере, уже многие аналитики попробовали эту технологию и отзываются очень позитивно. Сборку мы назвали ViXtract и опубликовали на GitHub под BSD лицензией. Под катом — рассуждения о том, каким должен быть идеальный ETL, рассказ о том, почему его лучше делать на Python (и почему это совсем не сложно) и примеры решения реальных задач на ViXtract. Приглашаю всех заинтересованных к дискуссии, обсуждению, использованию и развитию нового решения для старых проблем!
Визуализация результатов анализа — это очень важно, но роль загрузки данных нельзя недооценивать. За последние 5 лет, которые я занимаюсь BI (как с технической, так и с бизнесовой стороны), я провел более 500 интервью с клиентами, на которых мы обсуждали задачи и потребности конкретных компаний. И в большинстве из них мои собеседники подчеркивали, что визуализация — это очень нужная и полезная вещь, но самые большие проблемы и трудозатраты возникают при загрузке и очистке данных.
Мы в Visiology в основном работаем с крупными предприятиями, промышленностью и госорганизациями, но в разговорах с коллегами я убедился, что проблемы везде одни и те же. Аналитики могут уделить анализу и визуализации только 20% своего времени, потому что 80% уходит на преобразование, очистку, выгрузку и сверку данных. Чтобы эффективно решать эту проблему, мы постоянно ищем новые методы и инструменты работы с данными, тестируем, пробуем на реальных задачах. Что же мы называем идеальным ETL инструментом?
Итак, вот 5 основных критериев, которым должен соответствовать идеальный ETL (Extract-Transform-Load) инструмент:
ETL-инструмент должен быть простым в освоении. Речь не о том, что с ним должны уметь работать совсем неопытные люди. Просто специалист не должен тратить полжизни на изучение нового ПО, а просто взять и практически сразу начать работать с ним.
В нём должно быть предусмотрено максимальное количество готовых коннекторов. Ведь в сущности, мы все пользуемся плюс-минус одними и теми же системами: от 1С до SAP, Oracle, AmoCRM, Google Analytics. И никто не хочет программировать коннекторы к ним с нуля.
Инструмент должен быть универсальным и работать с разными BI системами. Это облегчает переход аналитиков и разработчиков из одной компании в другую — если на прошлом месте работы, например, использовали QlikView, а на новом — Visiology, желательно сохранить возможность пользоваться тем же ETL-инструментом.
ETL не должен ограничивать развитие аналитики. Увы, очень у многих ETL-инструментов есть критическая проблема — в них несложно реализовать простенькие вещи, но для более сложных задач приходится искать новый инструмент, который сможет расти вместе с тобой.
Наконец, естественное желание — получить недорогой (а лучше — полностью бесплатный) инструмент, причем не только на время “пробного периода”, а насовсем, чтобы пользоваться им без ограничений.
Что может предложить нам рынок?
В поиске ответа на этот вопрос для себя самих и для наших клиентов. мы отметили на диаграмме наиболее известные решения, подходящие для этой задачи. Они расположены от бесплатных к дорогим, от простых до корпоративных систем Enterprise-класса.
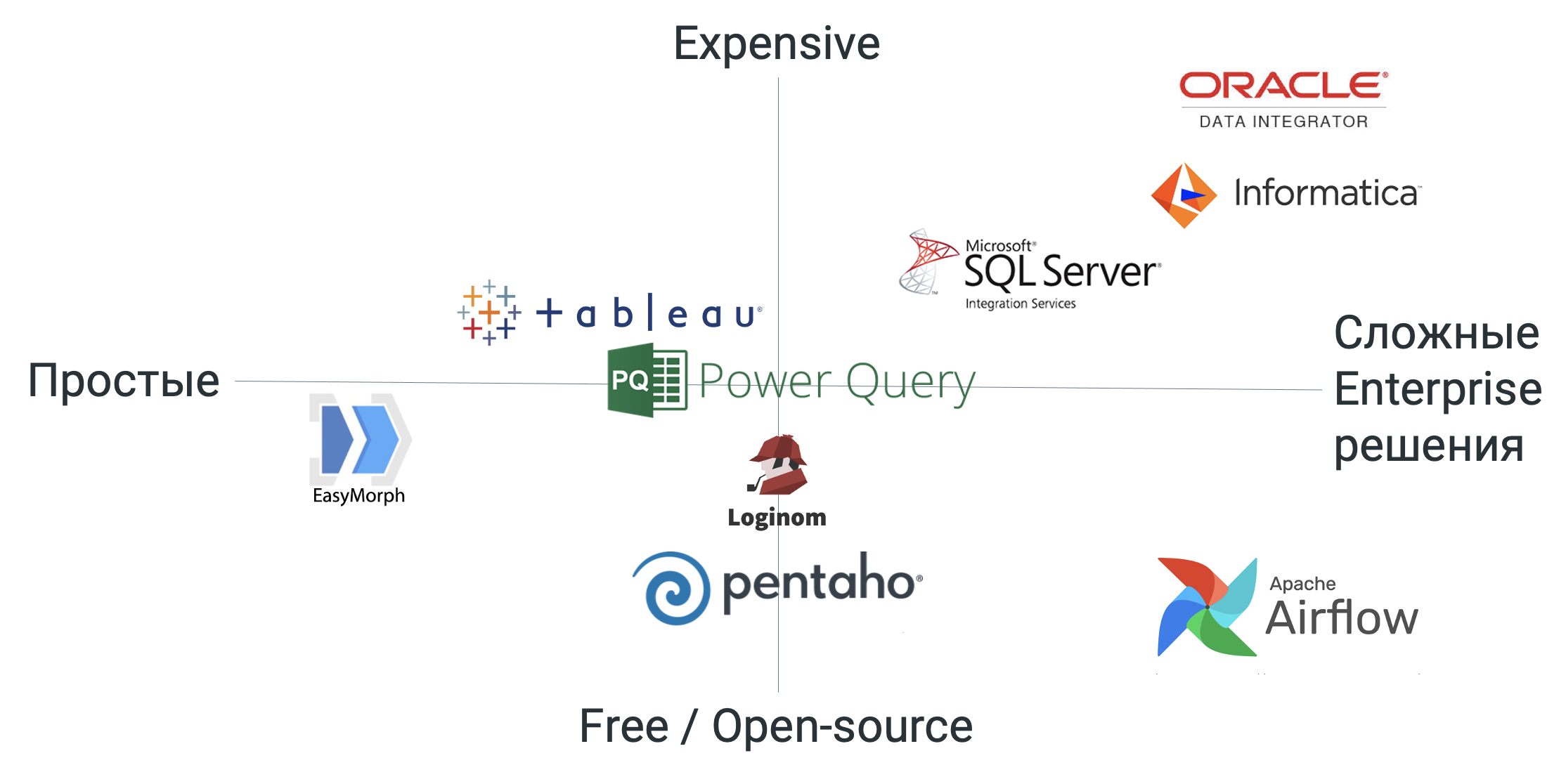
В категории наиболее сложных и дорогих систем доминируют Oracle и Informatica. Microsoft SSIS — чуть более демократичный. Рядом с ними — Apache Airflow. Это открытый продукт, не требующий оплаты, но зато кривая входа для него оказывается довольно крутой. Кроме этого существуют ETL-инструменты, встроенные или связанные с конкретными BI-системами. В их число входят, например, Tableau Prep или Power Query, который используется совместно с Power BI. В числе бесплатных и демократичных решений — Pentaho Data Integration, бывший Kettle, и Loginom.
Но, увы, ни одна из этих систем не удовлетворяет перечисленным 5 критериям. Oracle и Informatica оказываются слишком дорогими и сложными. С Airflow не так уж просто сразу начать работать. EasyMorph не дотягивает по функциональности, а все инструменты, оказавшиеся в центре нашей диаграммы, прекрасно работают, но не являются универсальными. Фактически, я называл бы достаточно сбалансированными решениями Loginom и Pentaho, но тут возникает ещё один важный момент, о котором обязательно нужно поговорить.
Визуальный или скриптовый ETL?
Если копнуть глубже, то все эти (и другие) ETL-инструменты можно разбить на два больших класса — визуальные и скриптовые. Визуальный ETL позволяет делать схемы из готовых блоков, а скриптовый позволяет задавать параметры на специальном языке программирования, уже оптимизированном для обработки данных.
Выбор между визуальным и скриптовым ETL — это настоящий холивар, достойный противостояния «Android vs iOS». Лично я отношусь к той категории, которая считает, что за скриптовыми ETL — будущее. Конечно, визуальный ETL имеет свои преимущества — это наглядность и простота, но только на первом этапе. Как только возникает потребность сделать что-то сложное, картинки становятся слишком запутанными, и мы все равно начинаем писать код. А поскольку в визуальных ETL нет отладчиков и других полезных примочек для кодинга, делать это приходится в откровенно неудобных условиях.
Pentaho и Loginom относятся к визуальному типу. Я считаю, что это очень хорошие системы для своих задач, и если вы сторонник визуальной ETL — на них можно остановиться. Но я всё-таки всегда делаю выбор в пользу скриптового подхода, потому что он позволяет задавать параметры без графических ограничений, и с ним можно значительно ускорить работу — когда ты уже в этом разобрался.
Конечно, стоит учитывать, что все ETL-инструменты тяготеют к смешанному варианту работы, когда либо визуальный дополняется кодом, либо код дополняется визуальными. Но всё равно в ДНК системы может быть что-то одно. И если мы хотим получить хороший скриптовый ETL, нужно ответить на вопрос — каким он должен быть?
Скриптовый - значит, должен быть основан на Python!
Если мы хотим, чтобы ETL был открытым, бесплатным и уже с экосистемой, значит инструмент должен быть на Python. Почему? Потому что, во-первых, Python — это простой язык, сейчас даже дети учатся программировать на Python чуть ли ни с первого класса. Например, в “Алгоритмике” начинают курс программирования именно с Python, а не с Basic или визуального языка Google. Так что подрастающее поколение разработчиков уже знакомо с ним. Во-вторых, огромная экосистема готовых технологий и библиотек уже создана: от каких-то банальных коннекторов до очень серьёзных вещей, связанных с Data Science и так далее. Можно начинать развиваться в этом направлении: здесь ограничений никаких нет.
Конечно, у Python есть и минусы. При столкновении с экосистемой “один на один” будет серьёзная кривая входа. Новичкам разбираться с темой оказывается достаточно сложно. Как минимум, нужно иметь компетенции по работе с Linux, и это для многих сразу становится стоп-фактором. Именно поэтому нам часто говорят: «Нет, мы хотим что-нибудь простое, готовое, с Python мы разбираться не готовы».
Решение = JupyterHub + PETL + Cronicle
Но поскольку во всём остальном готовый инструмент на Python получается хорош, для решения проблемы входа мы подобрали набор технологий, которые помогают упростить работу с системой. Это уже доказавшие свою эффективность зрелые open-source решения, которые можно запросто объединить и использовать:
JupyterHub — интерактивная среда выполнения Python-кода. По сути, это среда разработки, которая позволяет работать с кодом в интерактивном режиме. Она очень удобна для тех, кто не является профессиональным разработчиком, не накопил готовых навыков программирования на уровне спинномозговых рефлексов. JupyterHub помогает, когда ты разбираешься с кодом, пробуешь что-то новое, экспериментируешь.
Библиотека PETL была разработана на Python специально для обработки данных. Она берёт на себя огромное количество рутинных задач, например, разбор CSV файлов различных форматов или создание схемы в БД при выгрузке данных.
Cronicle — удобный и функциональный планировщик, который позволяет легко автоматизировать выполнение задач по обработке данных, отслеживать статистику, выстраивать цепочки, настраивать оповещения и так далее.
Чтобы всем этим было проще пользоваться, мы объединили три инструмента в ViXtract. Речь идет о сборке набора open-source технологий, которая позволяет легко установить решение одной командой и использовать ETL, не заморачиваясь по поводу Linux, по поводу прав, нюансов интеграций и других тонкостей.
Кроме трех основных, сборка включает в себя вспомогательные технические компоненты, такие как PostgreSQL для хранения обработанных данных и Nginx для организации веб-доступа. Кроме этого в дистрибутиве есть уроки и туториалы, в том числе, готовые примеры интеграций, с которых можно начать работу. В планах — добавить в пакет обучающие видеоролики, и я надеюсь, что вы тоже захотите подключиться к этому проекту, ведь ViXtract — это полностью открытый продукт, выпущенный под open-source лицензией.
И ещё несколько слов о самой оболочке
Давайте посмотрим на интерфейс нашего инструмента. На стартовой странице находятся кнопки запуска редактора, планировщика и переходы на полезные ресурсы — сайт, telegram-канал, сообщество и библиотека PETL. Это документация, в которой описаны все функции преобразования, загрузки файлов. Когда вы начинаете работать с ViXtract, эту страницу логично держать всё время под рукой. Сейчас документация на английском, но одно из направлений развития — это перевод всего набора информации на русский язык.
В ViXtract имеется сразу несколько ядер (aka настроенных окружений). Например, одно из них можно использовать для разработки, а другое — для продуктива. Таким образом, вы можете установить много различных библиотек в одном окружении, а для продуктива оставить только проверенные. Окружения можно легко добавлять и изменять, а если вам интересно узнать о самом процессе работы с данными через ViXTract, вы всегда можете задать вопрос в Telegram сообществе ViXtract.

В интерфейсе Jupyter можно сформулировать задачу на преобразование данных. Для этого мы просто создаем тетрадку (набор коротких блоков кода, которые можно запускать интерактивно) и загружаем при необходимости исходные файлы данных.
Загрузка данных
PETL поддерживает множество источников данных, мы рассмотрим несколько типовых примеров. Эти же примеры доступны в виде готовых тетрадок на GitHub или в установленном ViXtract, там их можно попробовать.
Загрузка из xlsx-файла
Использование открытых источников через API
Работа с базой данных
Данные из xlsx-файла
Рассмотрим работу с petl на наборе результатов летних олимпиад по странам. Нам понадобится файл datasets/summer_olympics.xlsx, посмотрим на первые строки, пока не сохраняя таблицу в переменную.
etl.fromxlsx('datasets/summer_olympics.xlsx')
Видим, что данные загрузились без ошибок, однако заголовки столбцов не определились, потому что в начале файла есть лишняя пустая строка. Исправим это, используя функцию skip и поместим результат в переменную olympics
olympics = etl.fromxlsx('datasets/summer_olympics.xlsx').skip(1)
Теперь заголовки у столбцов корректные, однако не достаточно информативны, исправим это, задав заголовки вручную.
olympics2 = olympics.setheader(['country','games','gold','silver','bronze'])
Мы начали выстраивать цепочку преобразования таблицы, это удобно, так как можно просмотреть результат работы на каждом этапе. Иногда, наоборот, удобнее объединить цепочку сразу в одной команде. Например, совместим изменение заголовка с сортировкой по количеству золотых медалей.
olympics2 = olympics.setheader(['country','games','gold','silver','bronze']).sort('gold', reverse=True)
Теперь мы можем посчитать общее количество медалей и сохранить его в новом столбце, используя функцию addfield.
Мы также применим мощный инструмент Python - Анонимные функции. Анонимная функция (функция без имени) - это запись вида lambda x: <функция от x>. Читается как: "То, что было подано на вход этого выражения, будет положено в x, а результатом исполнения будет <функция от x>. В PETL это часто применяется, чтобы выполнить быстрое преобразования значения какого-либо из полей. Например, если нужно все значения таблицы table в поле field умножить на два, это можно написать как table.convert('field', lambda x : x * 2). В примере ниже функция применяется не к отдельным значениям, а к строке целиком.
olympics2.addfield('total', lambda row : row['gold'] + row['silver'] + row['bronze'])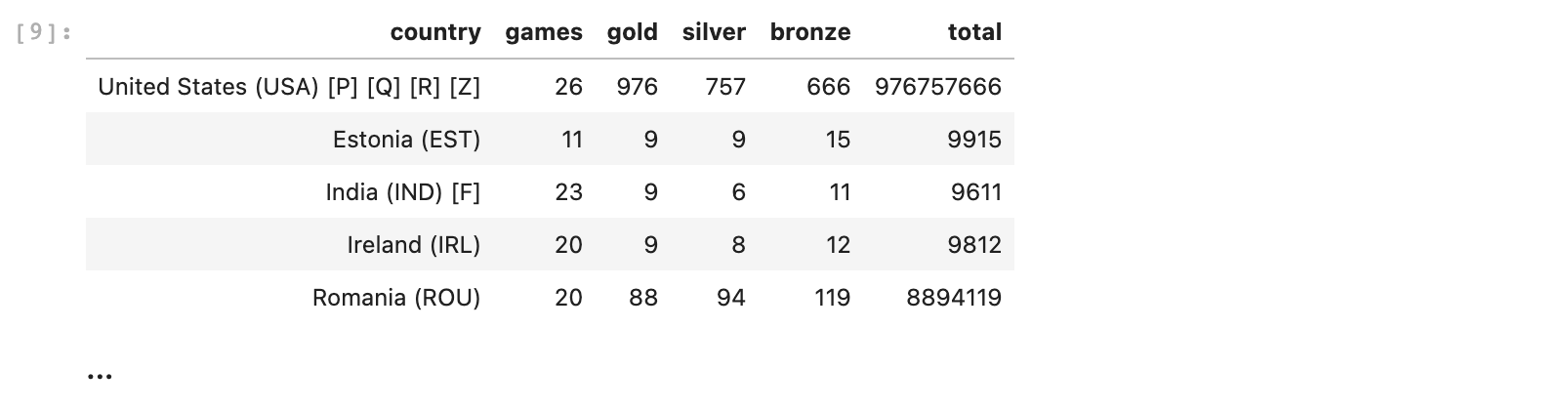
Вместо того, чтобы получить суммы, мы просто склеили значения. Чтобы такого не происходило, будем преобразовывать формат данных в целочисленные. Выясним, какая страна смогла набрать наибольшее число медалей, отсортировав сразу таблицу по новому столбцу по убыванию, с помощью функции sort. Также используем символ \, чтобы разбить команду на несколько строк для улучшения читаемости.
olympics3 = olympics2\
.addfield('total', lambda x: int(x['gold']) + int(x['silver']) + int(x['bronze']))\
.sort('total', reverse=True)
Видим, что в таблице есть сумма по всем странам, что нас не интересует в данной задаче. Можем выбрать из таблицы все строки, кроме строки со значением country == Totals. Воспользуемся функцией select.
Кроме того, дополнительно рассчитаем новый показатель - результативность страны, определив её как среднее число медалей за игру.
olympics4 = olympics3\
.select(lambda x: x.country != 'Totals')\
.addfield('effectiveness', lambda x: round(x['total'] / float(x['games']), 2))
Сохраним полученные результаты в новый xlsx-файл.
olympics4.toxlsx('olympics.xlsx')Готово! Теперь обработанный файл можно скачать или загрузить в BI-систему.
Данные из открытого источника рынка акций
Рассмотрим немного более продвинутый пример - получение данных из веб-сервиса по API. Это также делается очень просто с использованием библиотеки requests
response = requests.get('https://www.quandl.com/api/v3/datasets/WIKI/AAPL.json?start_date=2017-05-01&end_date=2017-07-01')Посмотрим, что мы получили в ответ. Мы увидим данные в формате JSON, которые нужно будет промотать до конца
stock_prices_json = response.json()
stock_prices_json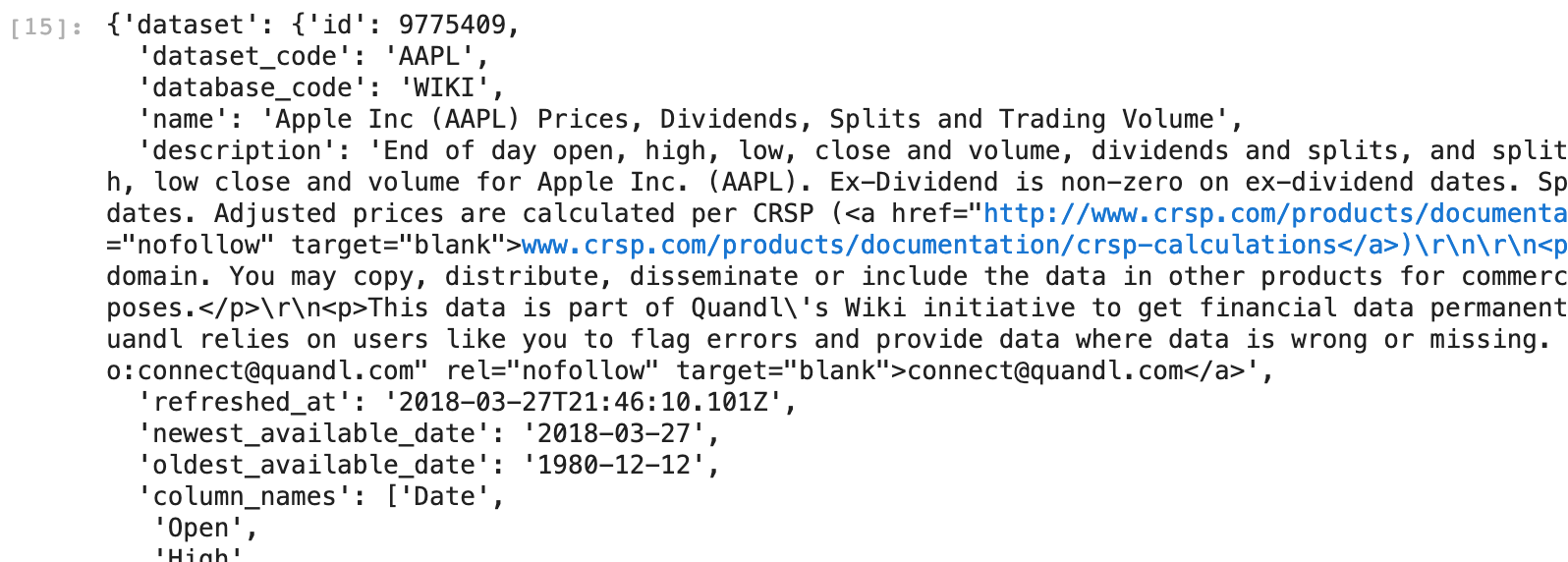
Видим, что в полученном JSON сама таблица с данными лежит в разделе dataset. Посмотрим, какие в ней есть поля.
stock_prices_json['dataset'].keys()
Нас интересуют два поля ответа: column_names, который мы будем использовать в качестве заголовков таблицы, и data, содержащий все необходимые данные построчно. Для преобразования данных из объекта dict в таблицу petl сделаем следующее:
Транспонируем содержимое
data, чтобы превратить строки в столбцыИспользуем
column_namesв качестве значения параметраheaderфункцииfromcolumns
stock_prices = etl.fromcolumns(stock_prices_json['dataset']['data']).skip(1)\
.transpose()\
.setheader(stock_prices_json['dataset']['column_names'])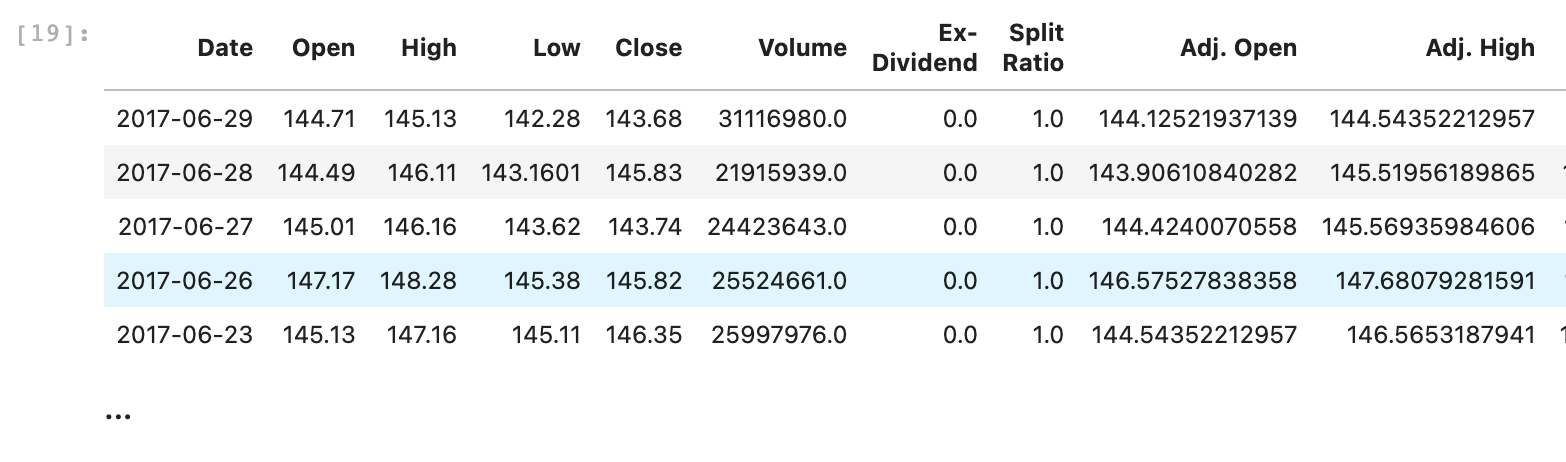
Уберём часть столбцов, все, содержащие 'Adj', переведём все значения в числа (где это возможно), вычислим разницу курса на определённую дату.
В этом примере мы используем List comprehension, инструмент Python, который позволяет делать довольно сложные преобразования в наглядном функциональном стиле и без циклов.
List comprehension - это запись вида (<функция от x> for x in <список> if <условие от x), которая читается как: "Возьми все элементы из <список>, отбери те их них, для которых истинно <условие от x>, выполни над каждым <функция от x> и верни результаты в виде списка. Например, есть массив чисел arr и нужно отобрать из него четные числа и разделить их на 4. Это можно записать как (x/4 for x in arr if x % 2 == 0)
stock_prices2 = stock_prices\
.cutout(*(x for x in stock_prices.fieldnames() if 'Adj' in x))\
.convertnumbers()\
.addfield('Difference', lambda row: round(row.Close - row.Open, 2))
stock_prices2
Сохраним полученную табличку в csv-файл.
stock_prices2.tocsv('stock.csv')Через несколько секунд созданный файл появится в панели файлов слева, и вы сможете просмотреть или скачать его.
Данные из БД (PostgreSQL)
В состав ViXtract входит предустановленная СУБД PostgreSQL, её удобно использовать как промежуточное хранилище данных, из которого их уже забирает BI-система. Похожие подходы могут быть использованы и с любой другой СУБД.
Рассмотрим следующий пример.
Доступны данные о состояниях различных типов транспортных средств. В базе есть 2 таблицы:
status_tsсодержит информацию о состояниях различных ТСts_typesсодержит наименования типов ТС
Необходимо подготовить таблицу, содержащую валидные данные по бульдозерам:
В данных не должно быть пропусков
Время указано в формате datetime
Кроме данных по бульдозерам других нет
Все состояния, кроме отсутствия данных
Для каждого состояния рассчитана продолжительность
statuses = etl.fromdb(connection, 'SELECT * FROM status_ts')
ts_types = etl.fromdb(connection, 'SELECT * FROM ts_types')
# Вспомогательные функции
# Определяем фильтр для исключения строк с пустыми значениями
row_without_nones = lambda x: all(x[field] != '' for field in statuses.fieldnames())
# Перевод отметки времени в формат datetime
to_datetime = lambda x: dt.fromtimestamp(int(x))Чтобы исключить строки с пропусками, используем функцию select и определенный выше фильтр row_without_nones
statuses.select(row_without_nones)
Переведём столбцы со временем в требуемый формат. Для этого необходимо воспользоваться функцией convert. Сразу можем добавить расчёт продолжительности функцией addfield.
statuses.\
convert('Начало', to_datetime).\
convert('Окончание', to_datetime).\
addfield('Продолжительность', lambda x: x['Окончание'] - x['Начало'])
Объединим обе таблицы и выберем данные только по бульдозерам, сразу уберём строки с состоянием "Отсутствие данных".
statuses.\
join(ts_types, lkey='id ТС', rkey='id').\
select(lambda x: 'Бульдозер' in x['Тип ТС'] and x['Состояние'] != 'Отсутствие данных')Все перечисленные операции можно произвести за раз, сформируем цепочку функций. Заметим, что столбец id ТС уже не требуется, его можно убрать функцией cutout.
В дополнение ко всему отсортируем таблицу по времени начала состояний, применив sort.
result = statuses.\
join(ts_types, lkey='id ТС', rkey='id').\
select(lambda x: 'Бульдозер' in x['Тип ТС'] and x['Состояние'] != 'Отсутствие данных').\
select(row_without_nones).\
convert('Начало', to_datetime).\
convert('Окончание', to_datetime).\
addfield('Продолжительность', lambda x: x['Окончание'] - x['Начало']).\
convert('Начало', str).convert('Окончание', str).convert('Продолжительность', str).\
cutout('id ТС').\
sort('Начало')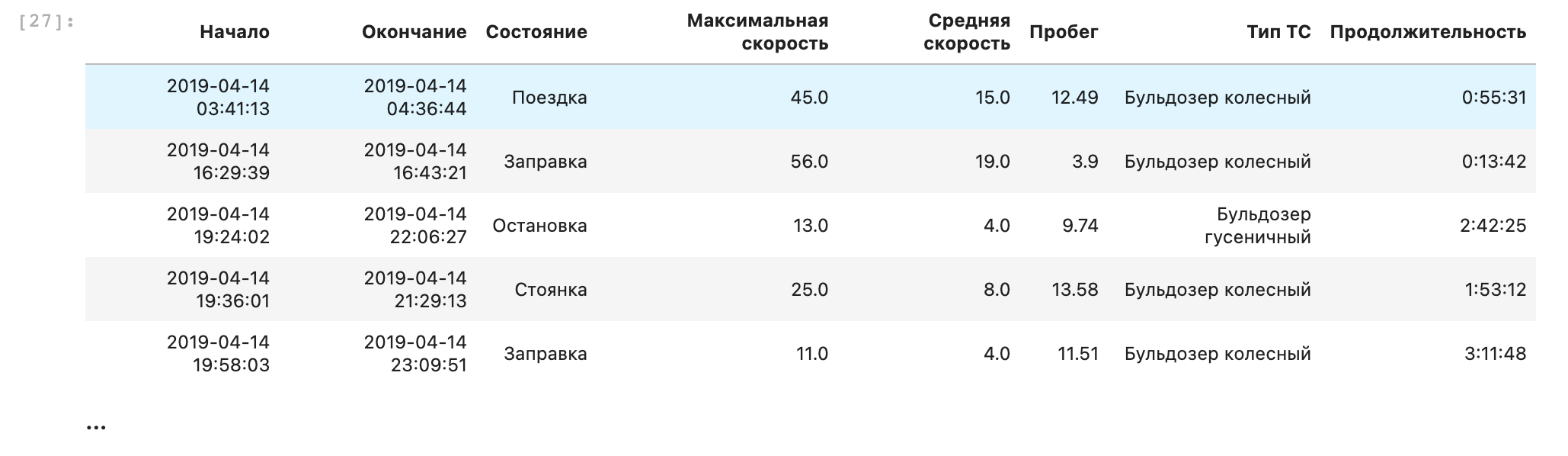
# Импортируем библиотеку, позволяющую создавать таблицы в БД
import sqlalchemy as db
# Подготовим подключение
_user = 'demo'
_pass = 'demo'
_host = 'localhost'
_port = 5432
target_db = db.create_engine(f"postgres://{_user}:{_pass}@{_host}:{_port}/etl")
# Пробуем пересоздать таблицу (удалить и создать заново). Если таблицы нет - просто создаем новую.
try:
result.todb(target_db, 'status_cleaned', create=True, drop=True, sample=0)
except:
result.todb(target_db, 'status_cleaned', create=True, sample=0)Проверим, что таблица создалась. Обратите внимание, что схема таблицы (типы полей, их названия и так далее) была создана полностью автоматически.
etl.fromdb(connection, 'SELECT * FROM status_cleaned')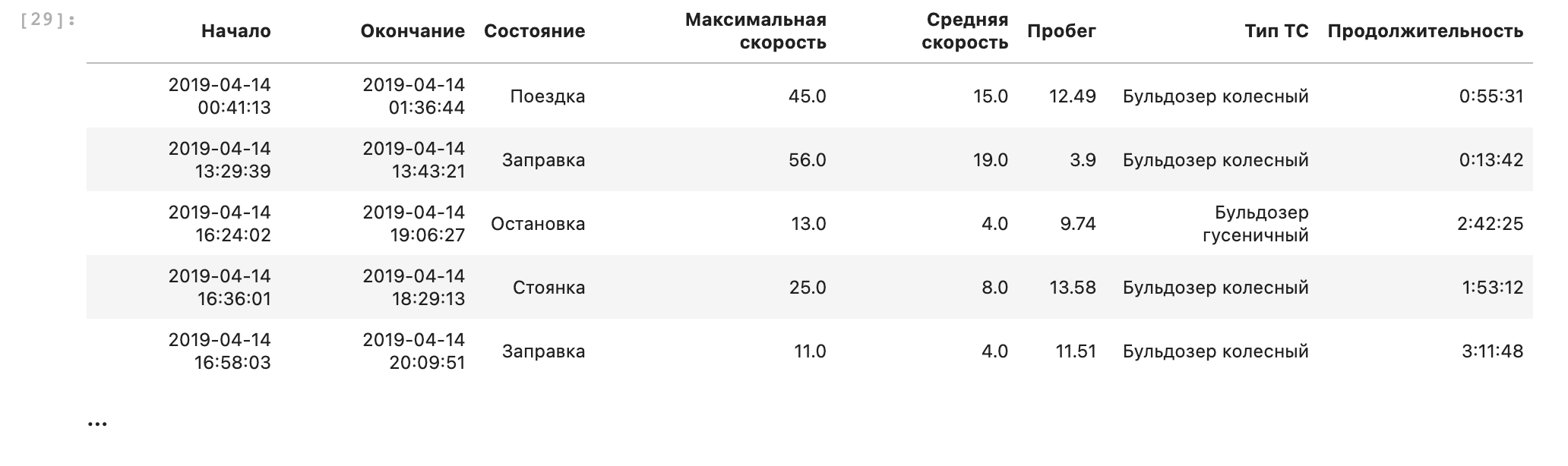
Так мы не зря выбрали Python?
Я по-прежнему часто слышу мнение: “Python, вся эта экосистема — это ужас какой-то, это что-то необъятное!”. Но на самом деле для того, чтобы выгружать данные, требуется лишь небольшое подмножество этого Python, примерно такое же, как с любым другим ETL-инструментом. Когда вы разберетесь с теми функциями, которые действительно нужны, появляется возможность развиваться дальше, переходить к обработке больших данных, потому что все стеки Big Data уже имеют обёртки на Python — качественные, нативные и удобные. А те технологии, которые используются в ViXtract, применяются и для обработки больших данных, за исключением, может быть, PETL, который ориентирован на средние объёмы информации.
Кстати, продвинутая аналитика и Data Science тоже строятся на экосистеме Python. И если что-то было предварительно создано на Python, результаты можно легко передать разработчику уже для внедрения в продуктив. Другими словами, проведенная в ViXtract работа на Python может быть дальше использована в AirFlow для развития в Enterprise-системе. Возможно, разработчику нужно будет переписать код в соответствии со стандартами продуктива, но затраты на коммуникации уменьшаются на порядок.
В ходе нашего Beta-тестирования ViXtract аналитики начали сами решать задачи по загрузке данных из разных источников и их очистке. Раньше эти люди предпочитали написать задачу и отдать её разработчикам — мол, пусть готово будет через неделю, но зато без проблем. А сейчас они могут сами сделать все необходимое за полчаса. И мне хотелось бы, чтобы вы тоже оценили ViXtract, оставили свое мнение о нём, а может быть — подключились к разработке этого инструмента. Так что если вам тоже интересна эта тема, подписывайтесь на наш блог и подключайтесь к обсуждению.
Сайт ViXtract, на котором можно посмотреть видео-демонстрацию и попробовать ViXtract без установки на свой сервер
