
В начале этого года Тензор проводил митап в городе Иваново, на котором я выступил с докладом про эксперименты с фаззинг-тестированием интерфейса. Тут расшифровка этого доклада.
Когда обезьяны заменят всех QA? Можно ли отказаться от ручного тестирования и UI автотестов, заменив их фаззингом? Как будет выглядеть полная диаграмма состояний и переходов для простого TODO приложения? Пример реализации и о том, как работает такой фаззинг далее под катом.
Всем привет! Меня зовут Докучаев Сергей. Последние 7 лет я занимаюсь тестированием во всех его проявлениях в компании Тензор.

У нас более 400 человек отвечают за качество выпускаемых продуктов. 60 из них занимаются автоматизацией, тестированием безопасности и производительности. Для того, чтобы поддерживать десятки тысяч E2E тестов, контролировать показатели производительности сотен страниц и выявлять уязвимости в промышленном масштабе — нужно применять инструменты и методы, проверенные временем и ни раз испытанные в бою.

И, как правило, на конференциях рассказывают именно о таких кейсах. Но кроме этого существует много всего интересного, что в промышленных масштабах пока сложно применить. Вот про это интересное и поговорим.

В фильме «Матрица» в одной из сцен Морфеус предлагает Нео выбрать красную или синюю таблетку. Томас Андерсон работал программистом и мы помним какой выбор он сделал. Будь он отъявленным тестировщиком — слопал бы обе таблетки, чтобы посмотреть, как система поведёт себя в нестандартных условиях.
Комбинировать ручное тестирование и автотесты стало практически стандартом. Разработчики лучше всего знают как устроен их код и пишут юнит-тесты, функциональные тестировщики проверяют новый или часто меняющийся функционал, а весь регресс уходит к разнообразным автотестам.
Однако, в создании и поддержке автотестов внезапно не так много авто- и довольно много ручной работы:
- Нужно придумать что и как протестировать.
- Нужно найти элементы на странице, вбить нужные локаторы в Page Objects.
- Написать и отладить код.
- При любых изменениях — актуализировать сценарий. Причём если функционал/интерфейс очень часто меняются, то автотесты оказываются не у дел, а ROI стремится к нулю.
К счастью, в мире тестирования существует ни две и не три таблетки. А целая россыпь: манки-тестирование, формальные методы, фаззинг-тестирование, решения на основе AI. И ещё больше их комбинаций.

Утверждение, что любая обезьяна, которая будет бесконечно долго печатать на пишущей машинке, сможет напечатать любой наперёд заданный текст, прижилось и в тестировании. Звучит неплохо, можем заставить одну программу бесконечно кликать по экрану в рандомных местах и в конечном итоге сможем найти все ошибки.
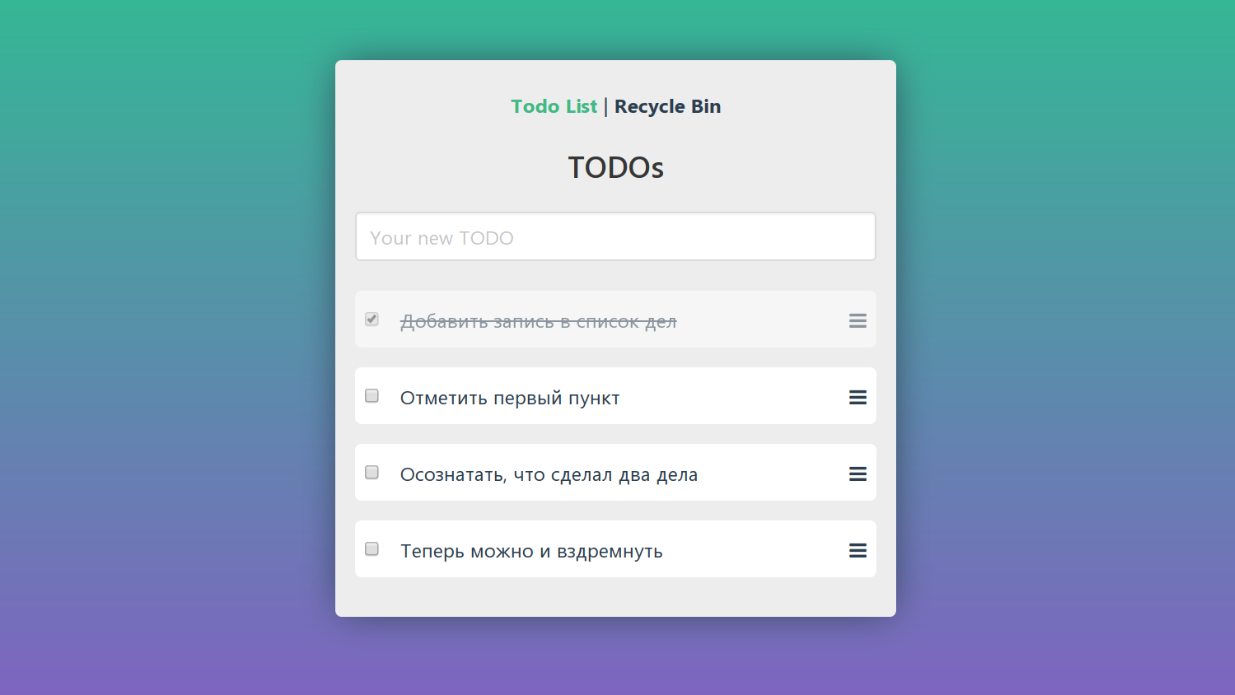
Допустим сделали мы такой TODO и хотим его проверить. Берём подходящий сервис или инструмент и видим обезьянок в действии:
По такому же принципу мой кот как-то, полежав на клавиатуре, безвозвратно сломал презентацию и её пришлось делать заново:

Удобно, когда после 10 действий приложение выбрасывает исключение. Тут наша обезьянка сразу понимает, что произошла ошибка, а мы по логам можем понять хотя бы приблизительно, как она повторяется. А что если ошибка произошла после 100К случайных кликов и выглядит как валидный ответ? Единственным значимым плюсом этого подхода является максимальная простота — ткнул кнопку и готово.

Противоположностью такого подхода являются формальные методы.

Это фотография Нью-Йорка в 2003 году. Одно из самых ярких и многолюдных мест на планете, Таймс-сквер, освещают только фары, проезжающих мимо машин. В тот год миллионы жителей Канады и США на три дня оказались в каменном веке из-за каскадного отключения электростанций. Одной из ключевых причин произошедшего оказалась race condition ошибка в ПО.
Критичные к ошибкам системы требуют особого подхода. Методы, которые опираются не на интуицию и навыки, а на математику называют формальными. И в отличии от тестирования они позволяют доказать, что в коде отсутствуют ошибки. Создавать модели гораздо сложнее, чем писать код, который они призваны проверить. А их использование больше похоже на доказательство теоремы на лекции по матанализу.

На слайде часть модели алгоритма двух рукопожатий, написанной на языке TLA+. Думаю для всех очевидно, что использование этих инструментов при проверке формочек на сайте сравни постройке Боинга 787 для проверки аэродинамических свойств кукурузника.

Даже в традиционно критичных к ошибкам медицинской, аэрокосмической и банковской отраслях очень редко прибегают к такому способу тестирования. Но сам подход незаменим, если цена любой ошибки исчисляется миллионами долларов или человеческими жизнями.
Фаззинг тестирование сейчас чаще всего рассматривается в контексте тестирования безопасности. И типовую схему, демонстрирующую такой подход, возьмём из OWASP гайда:

Тут у нас есть сайт, который требуется протестировать, есть БД с тестовыми данными и инструменты, при помощи которых будем отправлять указанные данные на сайт. Вектора представляют из себя обычные строки, которые были получены опытным путём. Такие строки с наибольшей вероятностью могут привести к обнаружению уязвимости. Это как та кавычка, которую многие на автомате ставят на место числа в URL из адресной строки.
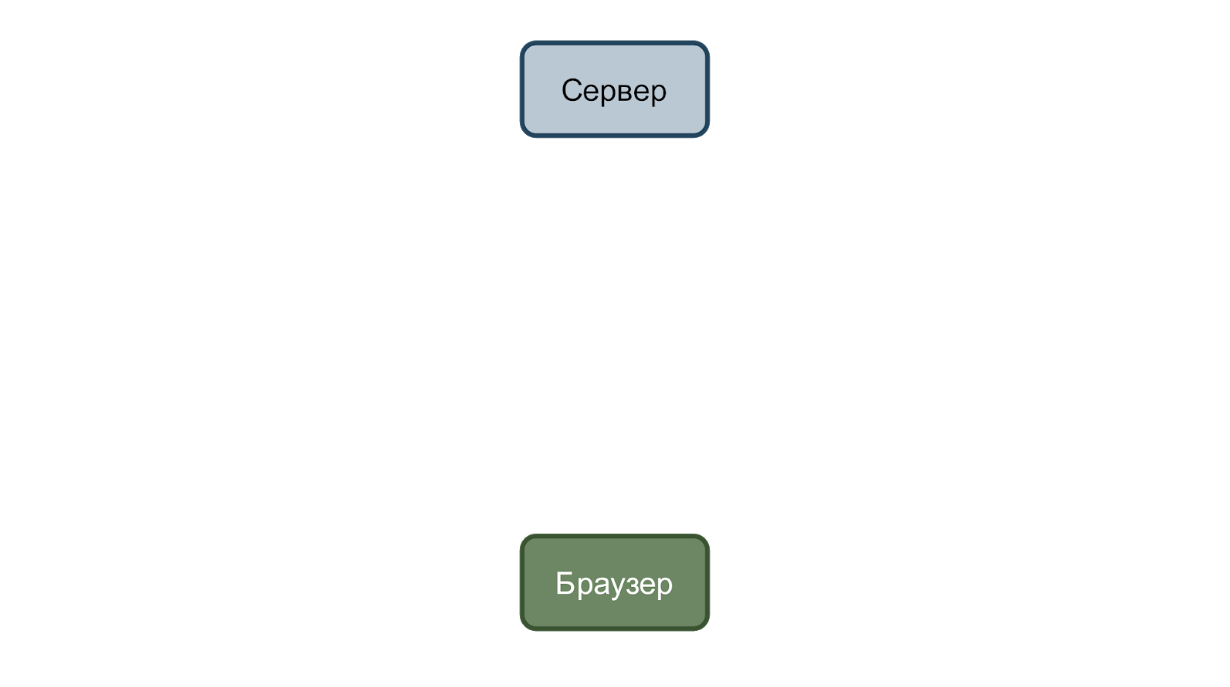
В простейшем случае у нас есть сервис, который принимает запросы и браузер, который их отправляет. Рассмотрим кейс с изменением даты рождения пользователя.

Пользователь вводит новую дату и нажимает кнопку “Сохранить”. На сервер улетает запрос, с данными в json формате.
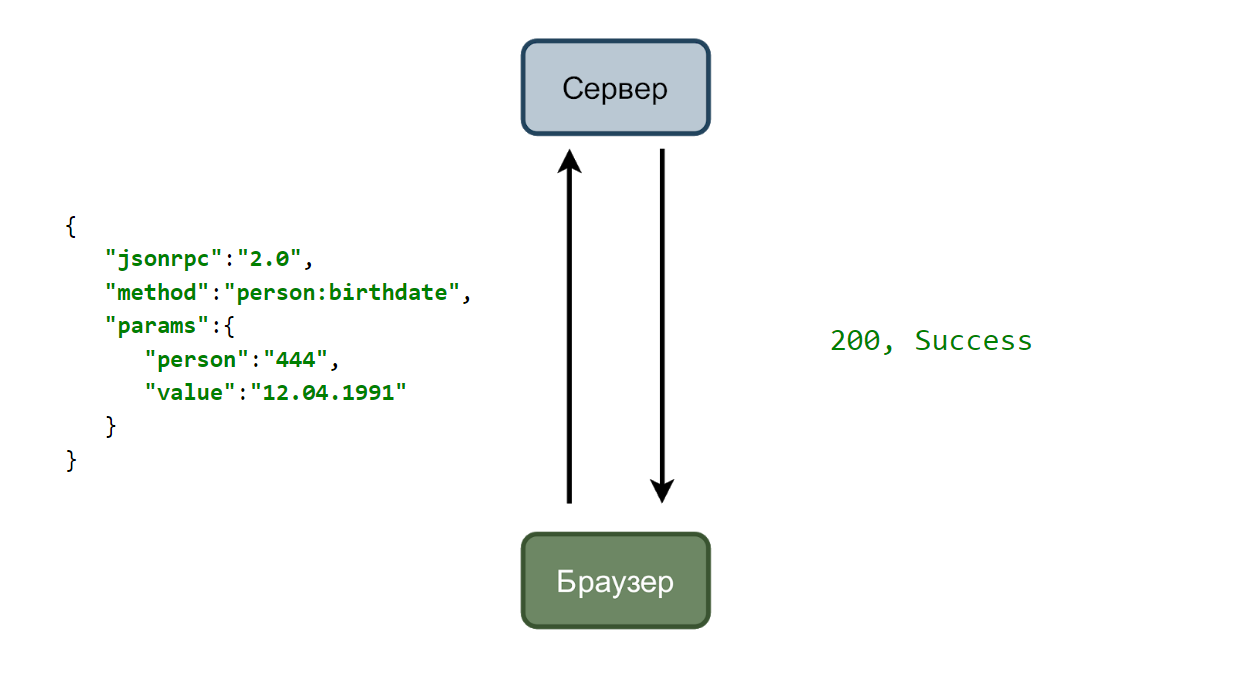
И если всё хорошо, то сервис отвечает двухсотым кодом.

С json’ами удобно работать программно и мы можем научить наш инструмент для фаззинга находить и определять даты в передаваемых данных. И он начнёт подставлять различные значения вместо них, например будет передавать несуществующий месяц.

И если мы в ответ вместо сообщения о невалидной дате получили исключение, то фиксируем ошибку.
Фаззить API несложная задача. Вот у нас передаваемые параметры в json’е, вот мы отправляем запрос, получаем ответ и анализируем его. А как быть с GUI?
Вновь рассмотрим программу из примера про манки-тестирование. В ней можно добавлять новые задачи, отмечать выполненные, удалять и просматривать корзину.
Если заняться декомпозицией, то мы увидим, что интерфейс — это не единый монолит, он тоже состоит из отдельных элементов:
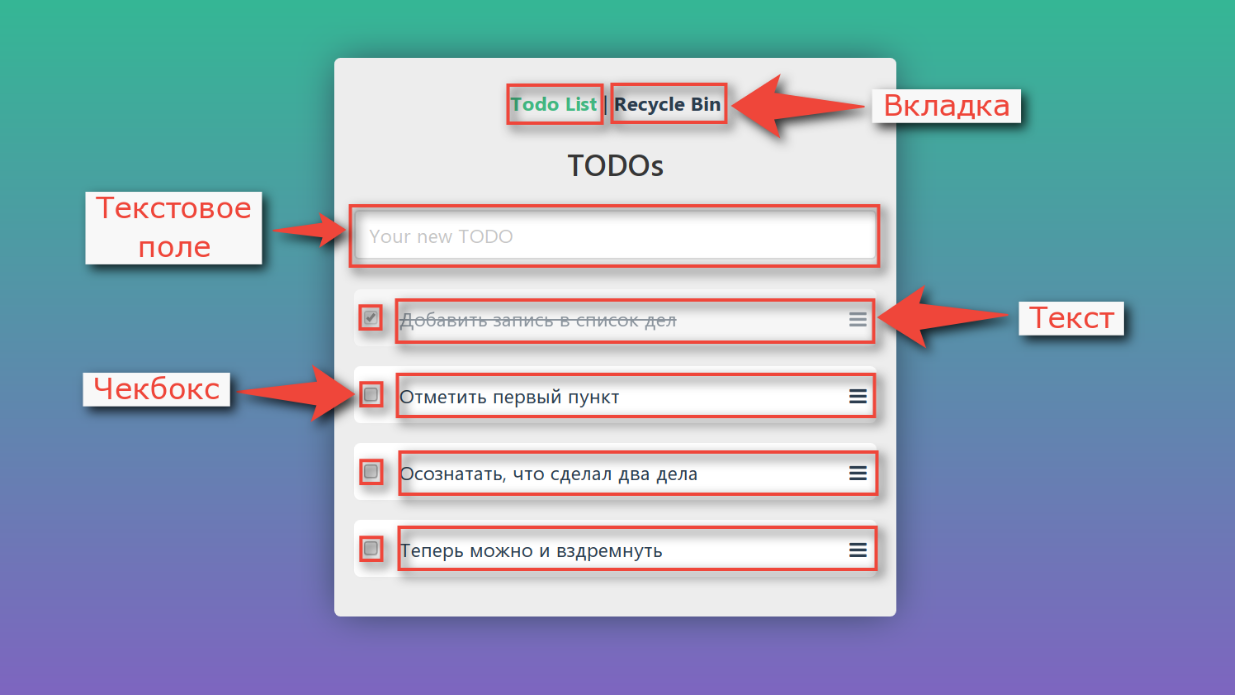
С каждым из контролов мы можем сделать не так-то и много. У нас есть мышка с двумя кнопками, колёсиком и клавиатура. Можно кликать по элементу, наводить на него курсор мыши, в текстовые поля можно вводить текст.
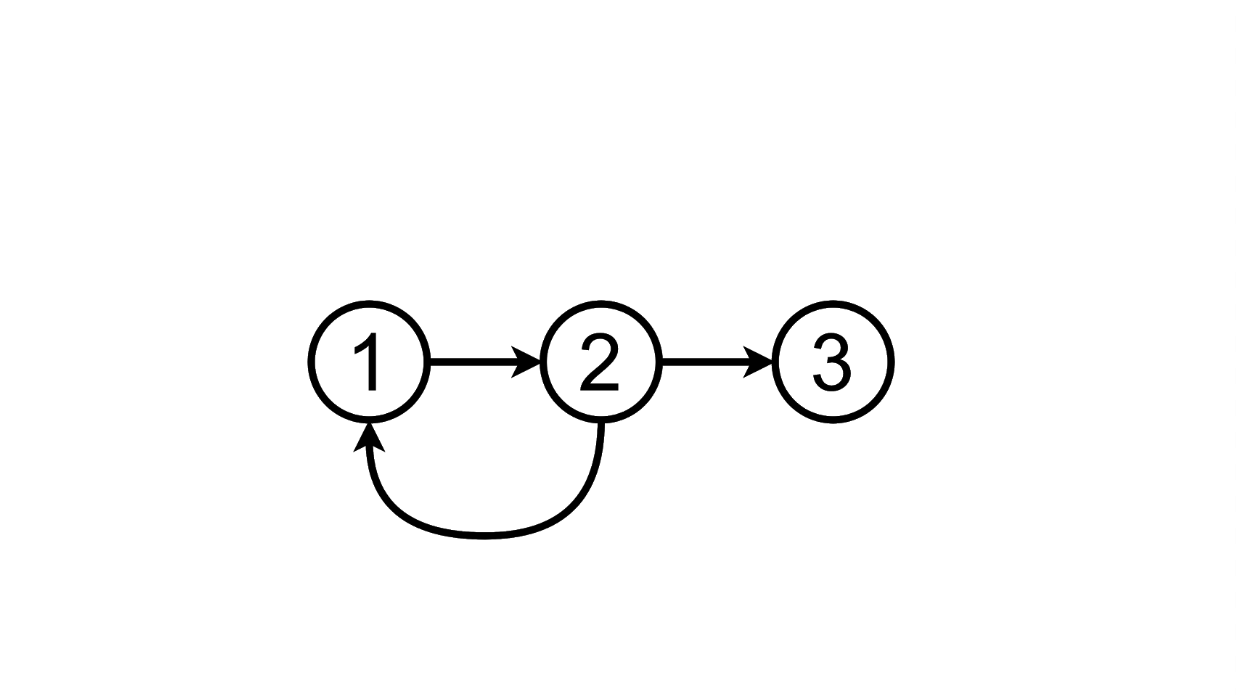
Если мы введём в текстовое поле какой-то текст и нажмём Enter, то наша страница перейдёт из одного состояния в другое:
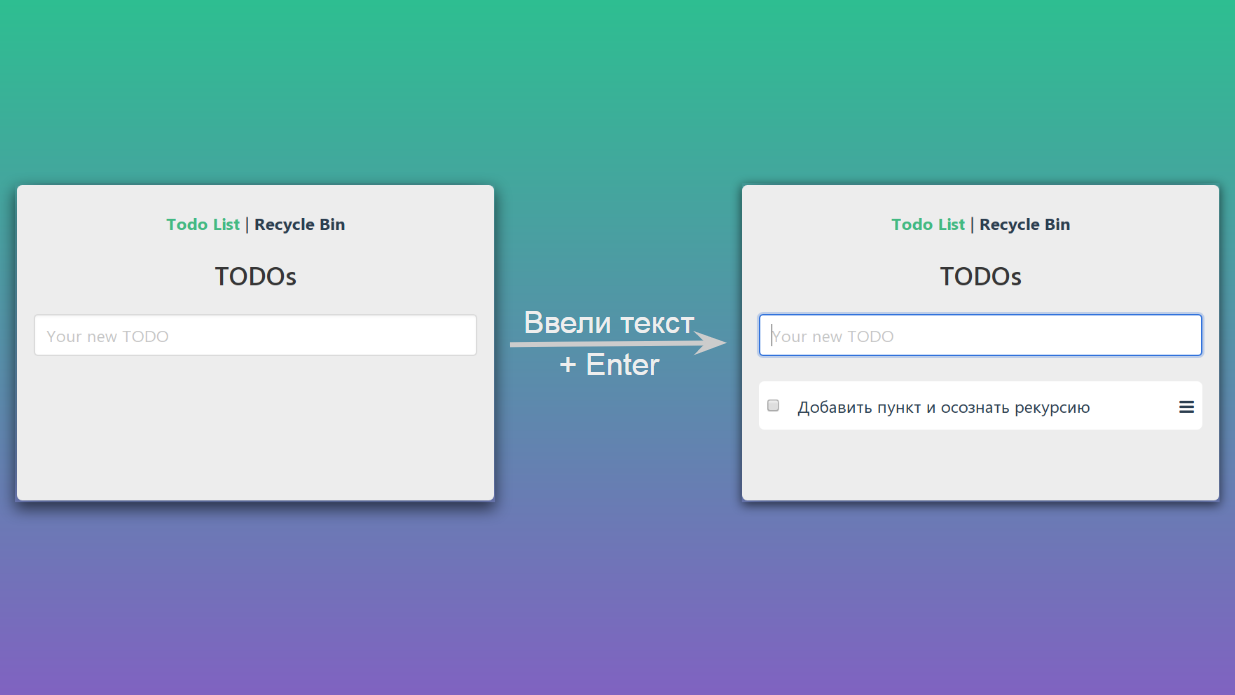
Схематически это можно изобразить вот так:

Из этого состояния мы можем перейти в третье добавив ещё одну задачу в список:
А можем удалить добавленную задачу, вернувшись в первое состояние:
Или кликнуть по надписи TODOs и остаться во втором состоянии:
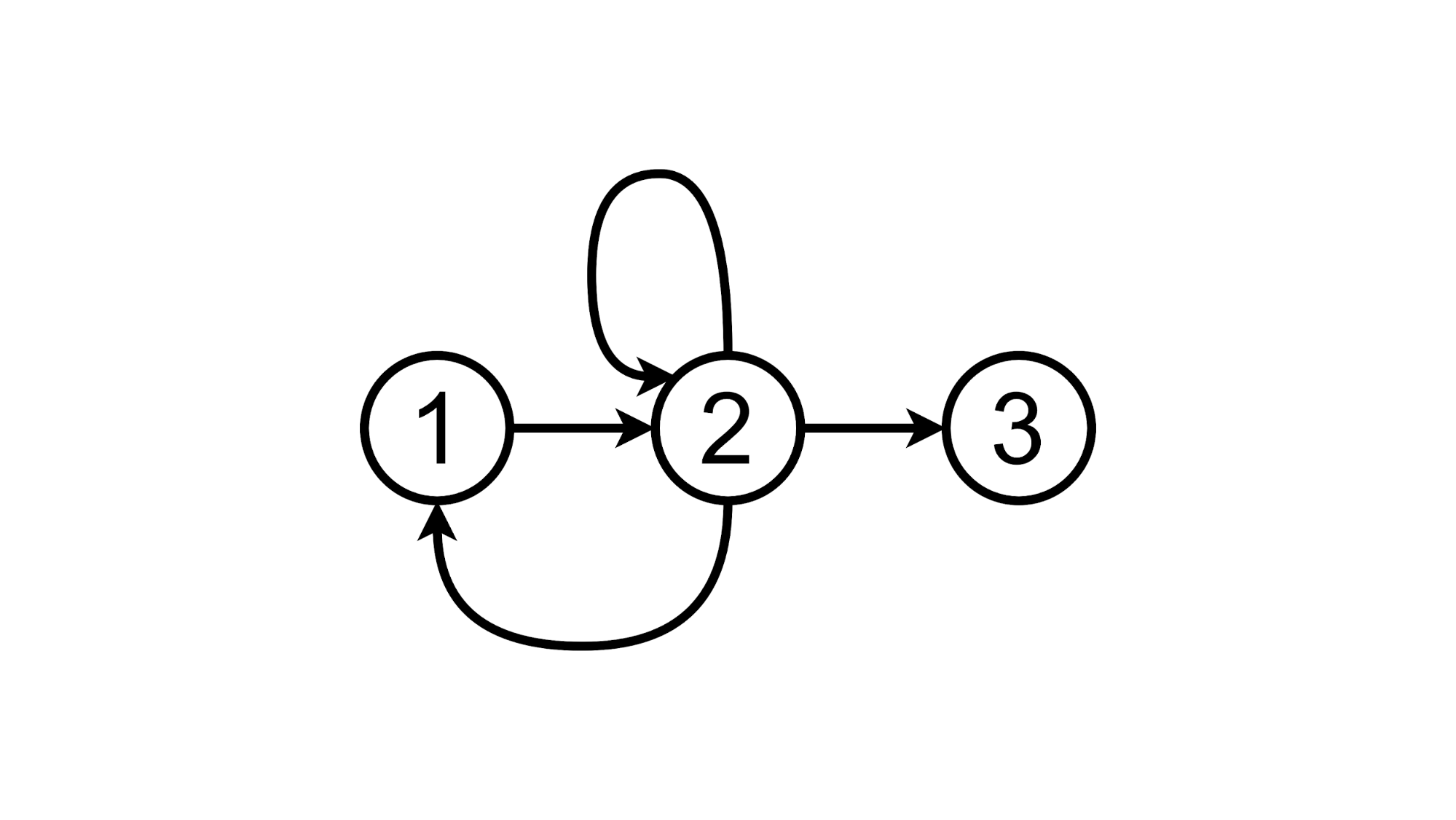
А теперь попробуем реализовать Proof-of-Concept такого подхода.

Для работы с браузером возьмём chromedriver, работать с диаграммой состояний и переходов будем через python библиотеку NetworkX, а рисовать будем через yEd.

Запускаем браузер, создаём инстанс графа, в котором между двумя вершинами может быть множество связей с разной направленностью. И открываем наше приложение.

Теперь мы должны описать состояние приложения. Из-за алгоритма сжатия изображения, мы можем использовать размер картинки в формате PNG как идентификатор состояния и через метод __eq__ реализовать сравнение этого состояния с другими. Через атрибут iterated мы фиксируем, что были прокликаны все кнопки, введены значения во все поля в этом состоянии, чтобы исключить повторную обработку.

Пишем основной алгоритм, который будет обходить всё приложение. Тут мы фиксируем первое состояние в графе, в цикле прокликиваем все элементы в этом состоянии и фиксируем образующиеся состояния. Далее выбираем следующее не обработанное состояние и повторяем действия.

При фаззинге текущего состояния мы должны каждый раз возвращаться в это состояние из нового. Для этого мы используем функцию nx.shortest_path, которая вернёт список элементов, которые нужно прокликать, чтобы перейти из базового состояния в текущее.
Для того, чтобы дождаться окончания реакции приложения на наши действий в функции wait используется Network Long Task API, показывающий занят ли JS какой-либо работой.
Вернёмся к нашему приложению. Исходное состояние имеет следующий вид:
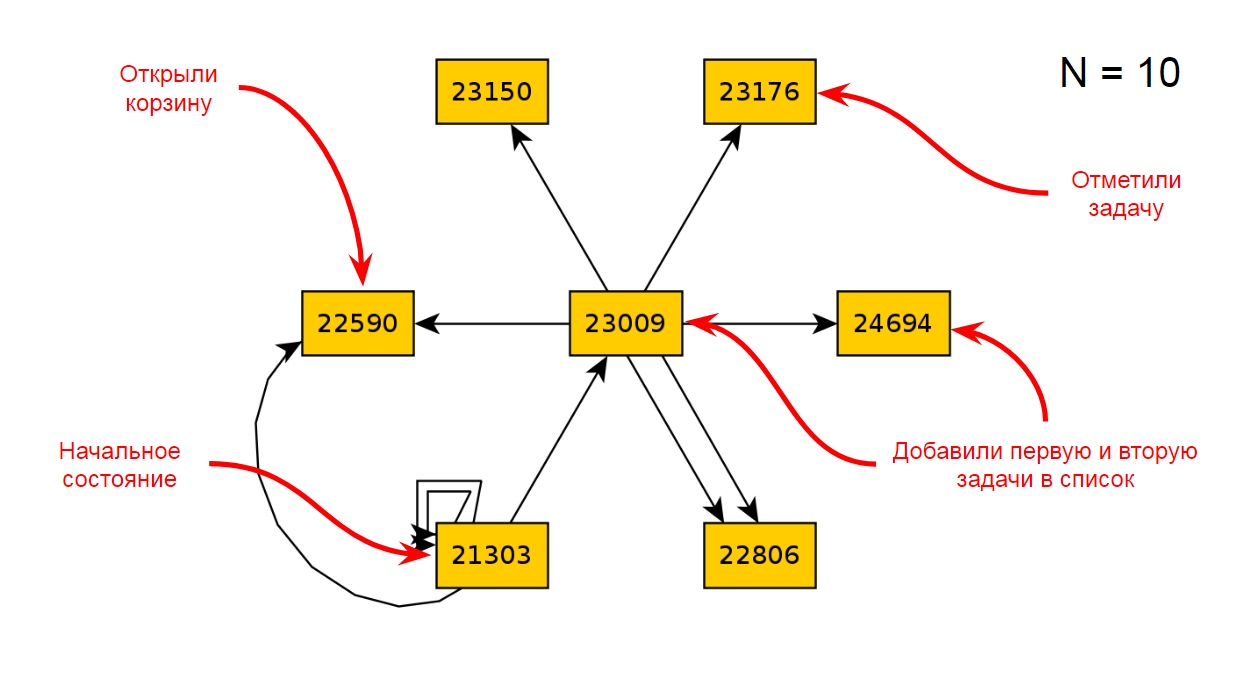
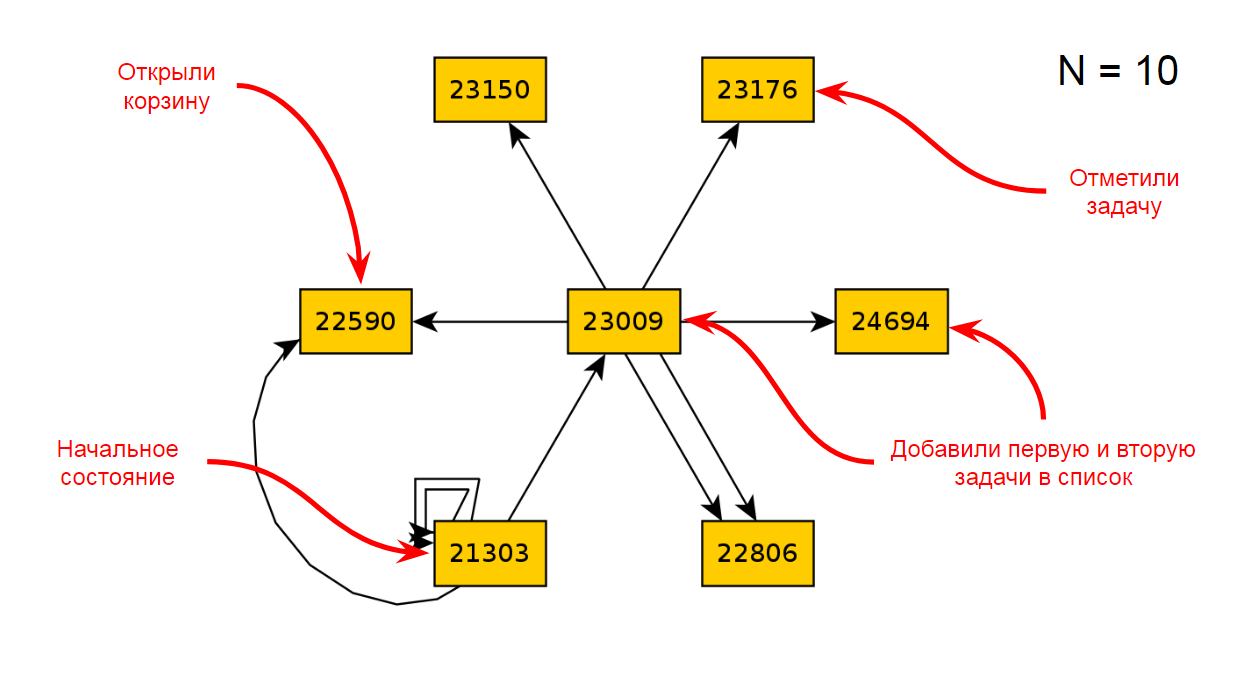
После десяти итераций по приложению мы получим такую диаграмму состояний и переходов:
Через 22 итерации вот такой вид:
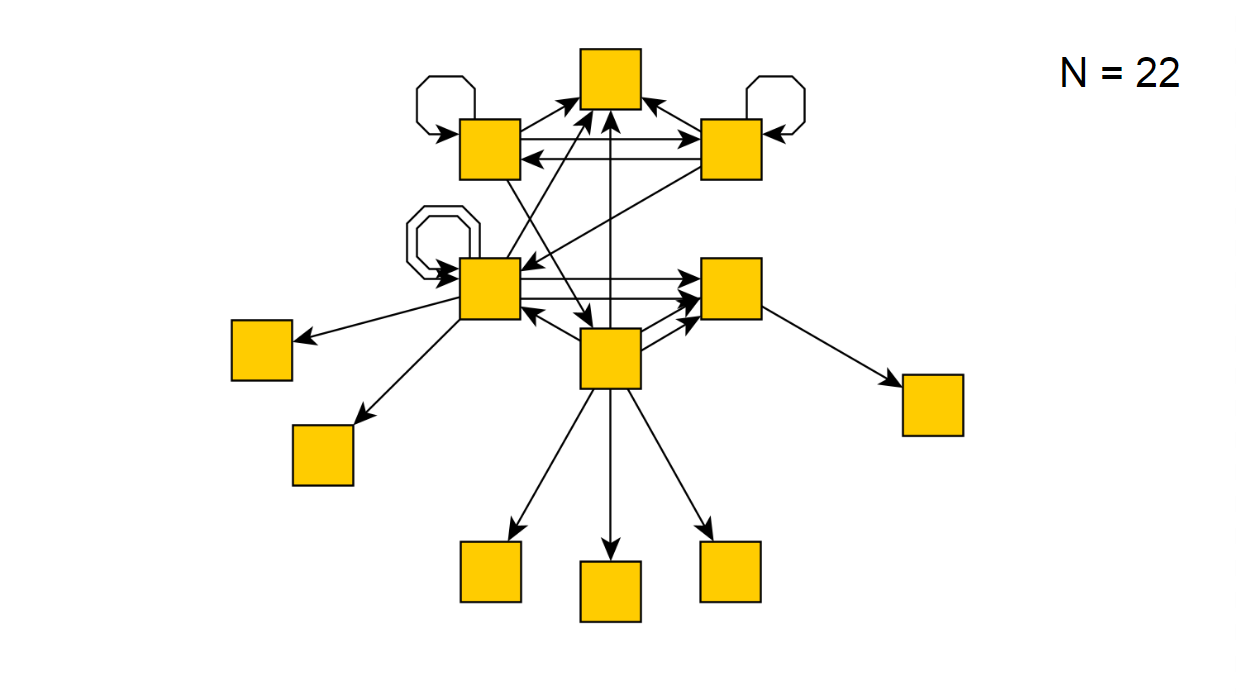
Если же запустить наш скрипт на несколько часов, то он внезапно сообщит, что обошёл все возможные состояния, получив следующую диаграмму:

Так, с простым демонстрационным приложением мы справились. А что будет, если натравить этот скрипт на реальное веб-приложение. А будет хаос:
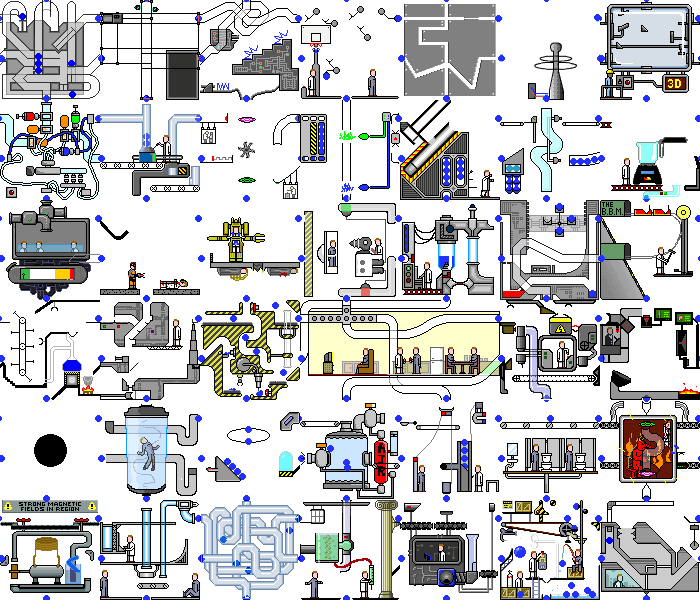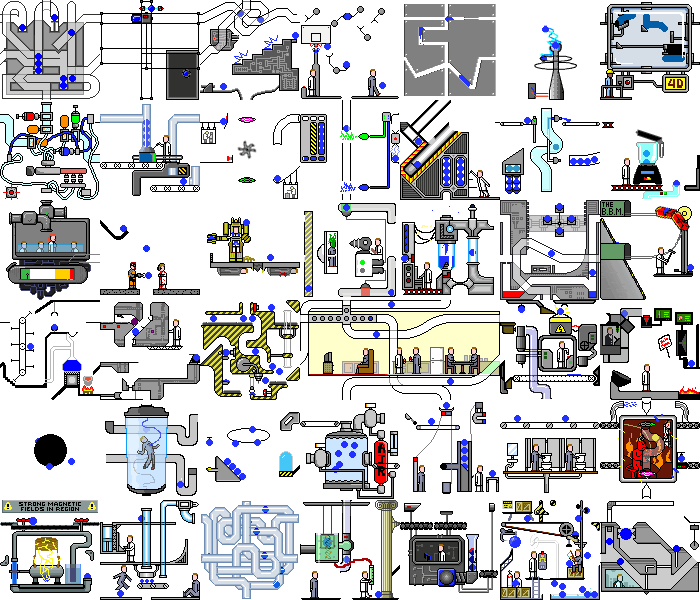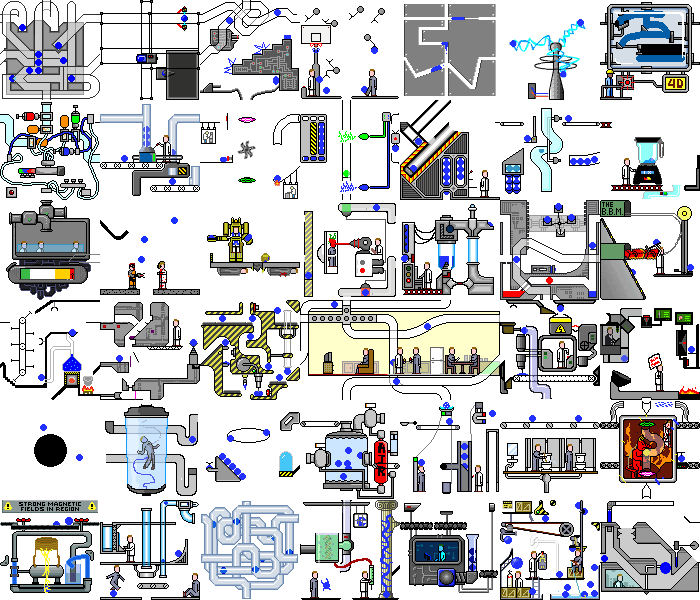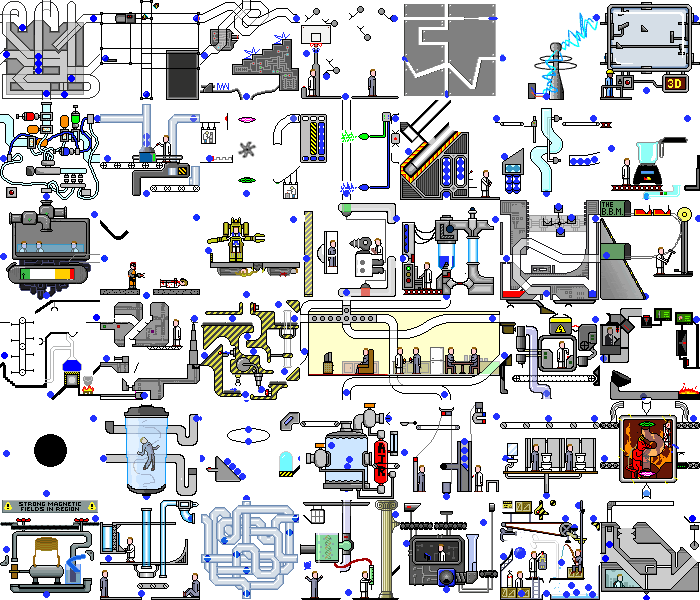
Мало того, что на бэкенде происходят изменения, сама по себе страница постоянно перерисывается при реакции на таймеры или события, при выполнении одних и тех же действий мы можем получить разные состояния. Но даже в таких приложениях можно найти куски функционала, с которыми наш скрипт может справиться без значительных доработок.
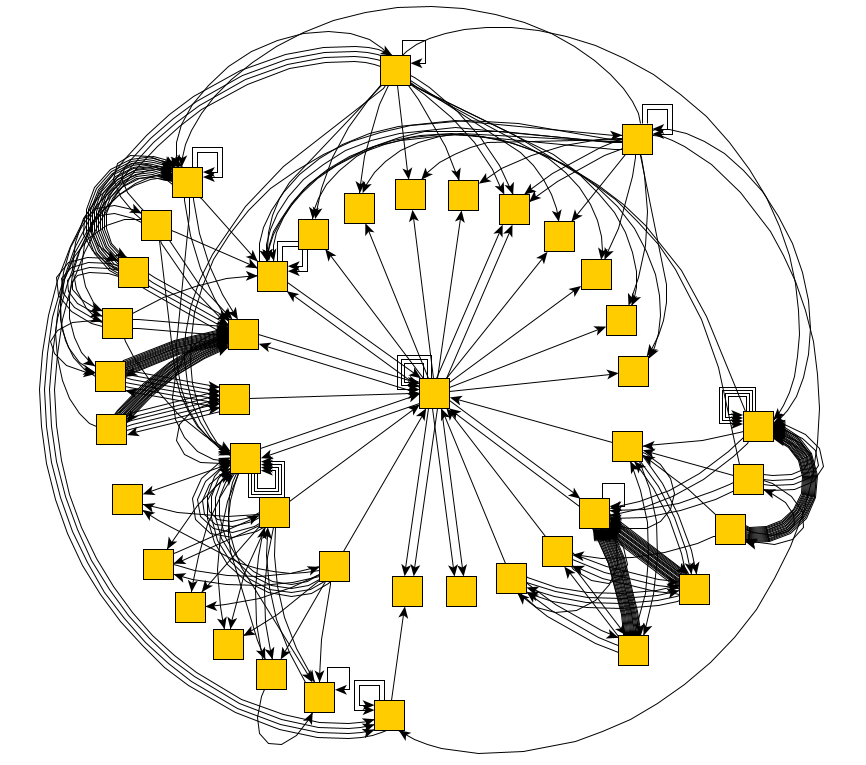
Возьмём для испытаний страницу аутентификации СБИС:

И для неё достаточно быстро получилось построить полную диаграмму состояний и переходов:

Отлично! Теперь мы можем обходить все состояния приложения. И чисто в теории найти все ошибки, которые зависят от действий. Но как научить программу понимать, что перед ней ошибка?
В тестировании ответы программы всегда сравниваются с неким эталоном, называемым оракулом. Им может быть ТЗ, макеты, аналоги программы, прошлые версии, опыт тестировщика, формальные требования, тест-кейсы и т.д. Часть этих оракулов мы также можем использовать в нашем инструменте.

Рассмотрим последний паттерн “а раньше было по-другому”. Автотесты ведь регрессионным тестированием занимаются.
Вернёмся к графу после 10 итерации по TODO:
Сломаем код, который отвечает за открытие корзины и вновь прогоним 10 итераций:
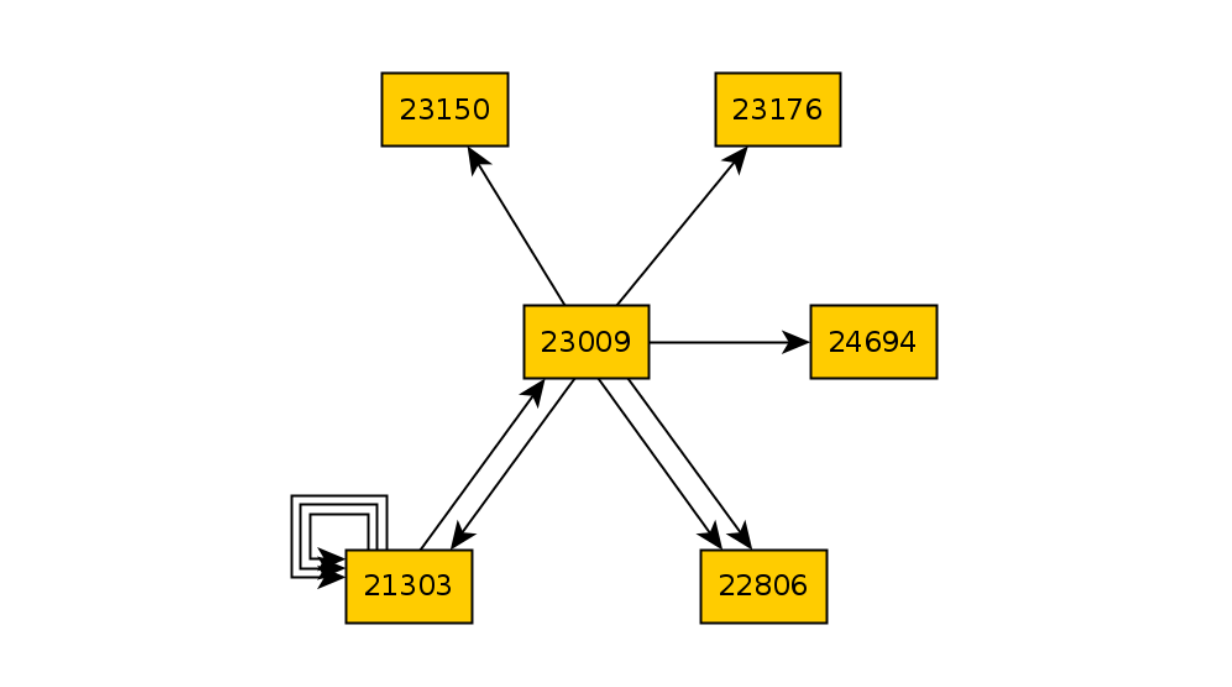
А далее сравним два графа и найдём разницу в состояниях:
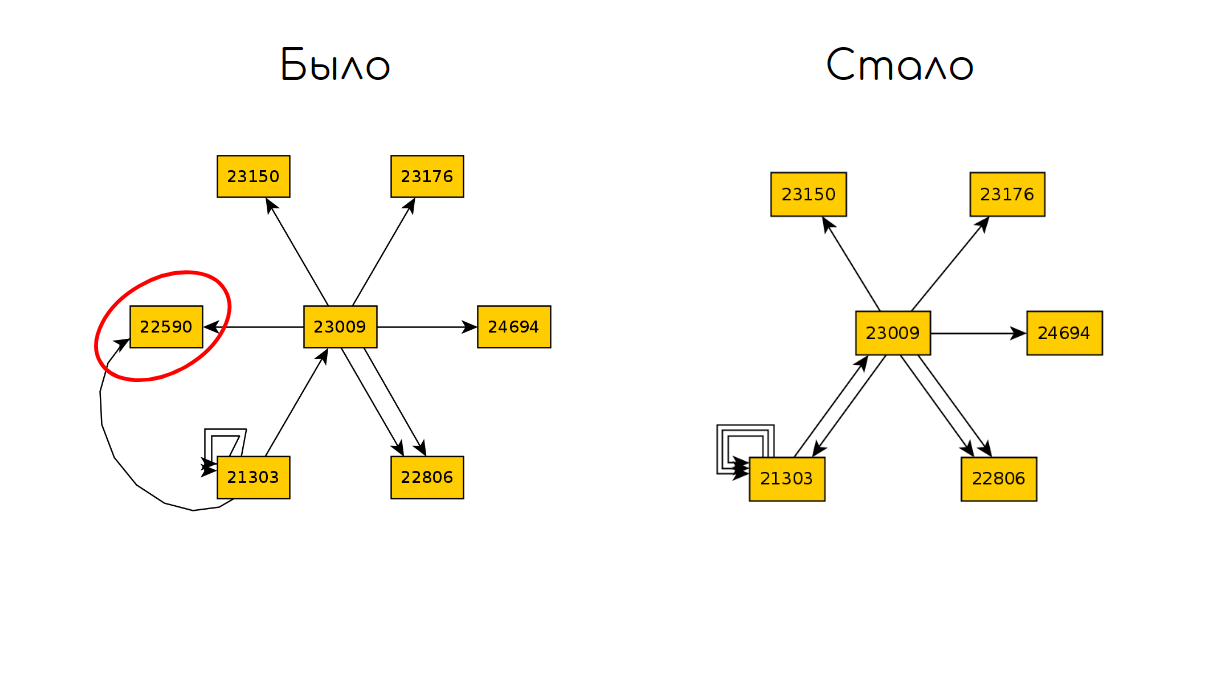
Можем подвести итог для данного подхода:

В текущем виде этот приём можно использовать для тестирования небольшого приложения и выявления очевидных или регрессионных ошибок. Для того, чтобы методика взлетела для больших приложений с нестабильным GUI потребуются значительные доработки.
Весь исходный код и список использованных материалов можно найти в репозитории: https://github.com/svdokuchaev/venom. Тем, кто хочет разобраться с применением фаззинга в тестировании, очень рекомендую The Fuzzing Book. Там в одной из частей описан такой же подход к фаззингу простых html форм.

