Для пользователя наш СБИС представляется единой системой управления бизнесом, но внутри состоит из множества взаимодействующих сервисов. И чем их становится больше — тем выше вероятность возникновения каких-то неприятностей, которые необходимо вовремя отлавливать, исследовать и пресекать.
Поэтому, когда на каком-то из тысяч подконтрольных серверов случается аномальное потребление ресурсов (CPU, памяти, диска, сети, ...), возникает потребность разобраться «кто виноват, и что делать».
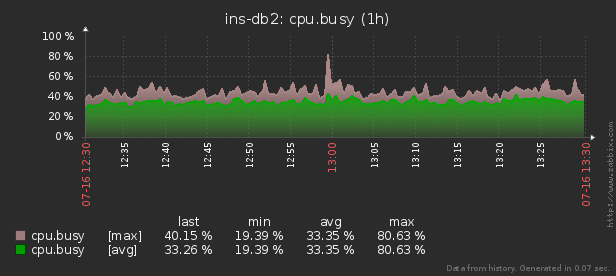
Для оперативного мониторинга использования ресурсов Linux-сервера «в моменте» существует утилита pidstat. То есть если пики нагрузки периодичны — их можно «высидеть» прямо в консоли. Но мы-то хотим эти данные анализировать постфактум, пытаясь найти процесс, создавший максимальную нагрузку на ресурсы.
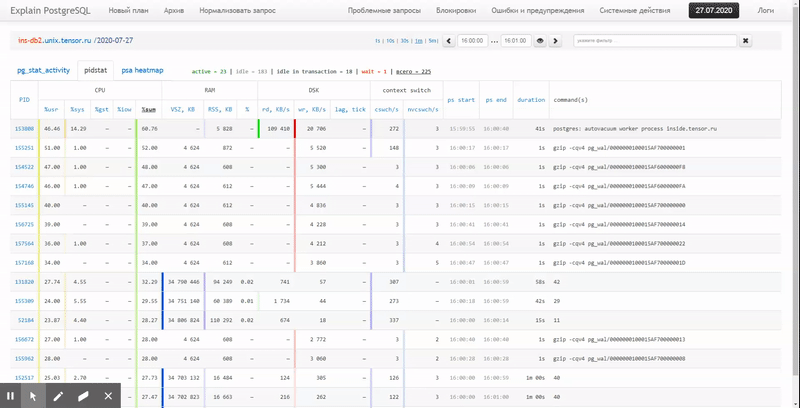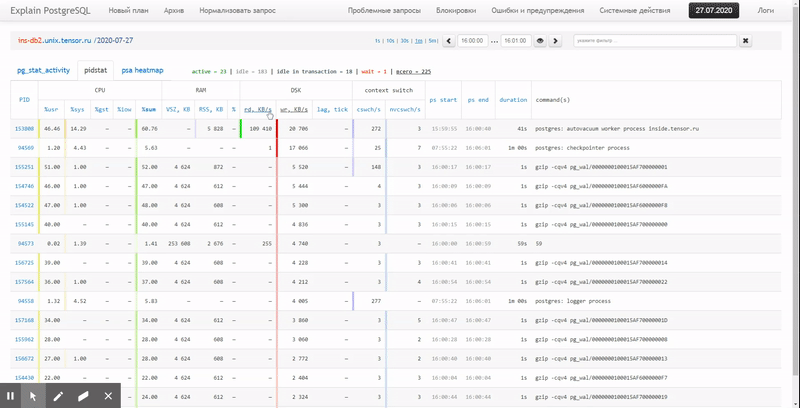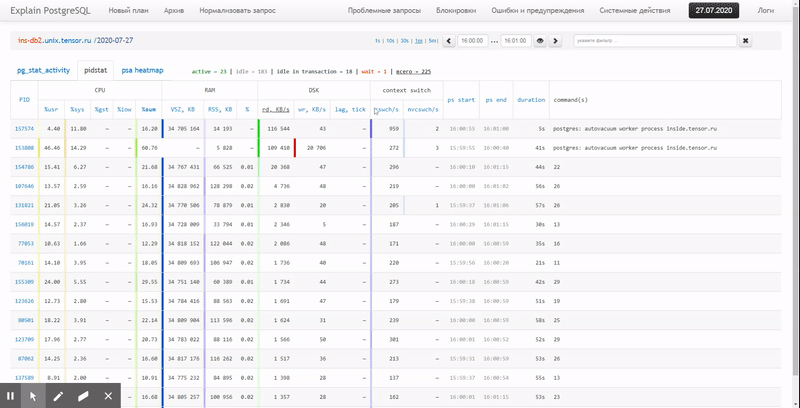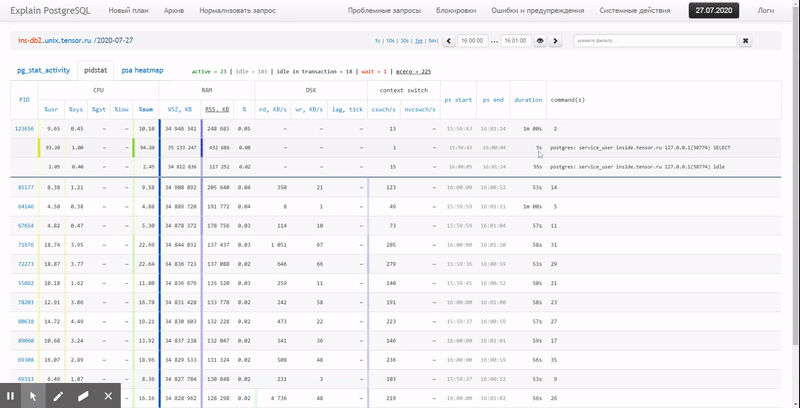
То есть хочется иметь возможность смотреть по ранее собранным данным разные красивые отчеты с группировкой и детализацией на интервале типа таких:
В этой статье рассмотрим, как все это можно экономично расположить в БД, и как максимально эффективно собрать по этим данным отчет с помощью оконных функций и GROUPING SETS.
Сначала посмотрим, что за данные мы можем извлечь, если брать «все по максимуму»:
Все эти значения делятся на несколько классов. Некоторые из них меняются постоянно (активность CPU и диска), другие — редко (выделение памяти), а Command — не только редко меняется в рамках одного процесса, но еще и регулярно повторяется на разных PID.
Для простоты давайте ограничимся одной метрикой каждого «класса», которые мы будем сохранять: %CPU, RSS и Command.
Раз мы заведомо знаем, что Command регулярно повторяется — просто вынесем его в отдельную таблицу-словарь, где UUID-ключом будет выступать MD5-хэш:
А для самих данных нам подойдет таблица такого вида:
Обращу внимание, что раз %CPU приходит к нам всегда с точностью 2 знаков после запятой и заведомо не превышает 100.00, то мы спокойно можем домножить его на 100 и положить в
Чтобы сэкономить производительность дисковой подсистемы нашей базы и занимаемый базой объем, постараемся как можно больше данных представить в виде NULL — их хранение практически «бесплатно», поскольку занимает лишь бит в заголовке записи.
Получается картинка вроде такой, если смотреть на нее в разрезе конкретного PID:

Понятно, что если у нас процесс начал выполнять другую команду, то значение используемой памяти тоже наверняка окажется не таким, как раньше — поэтому договоримся, что при смене CMD значение RSS тоже будем фиксировать, независимо от предыдущего значения.
То есть у записи с заполненным значением CMD заполнено и значение RSS. Запомним этот момент, он нам еще пригодится.
Давайте теперь соберем запрос, который покажет нам потребителей ресурсов конкретного хоста на определенном временном интервале.
Но сделаем это сразу с минимальным использованием ресурсов — примерно как в статье про SELF JOIN и оконные функции.
Чтобы не указывать значения параметров отчета (или $1/$2) в нескольких местах по ходу SQL-запроса, выделим CTE из единственного json-поля, в котором по ключам находятся эти самые параметры:
Поскольку никаких сложных агрегатов мы не придумывали, единственный способ проанализировать данные — прочитать их. Для этого нам понадобится очевидный индекс:
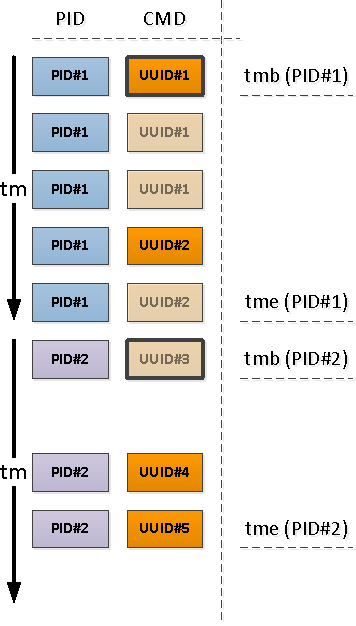
Для каждого найденного PID определим интервал его активности и возьмем CMD с первой записи на этом интервале.
Для этого воспользуемся уникализацией через
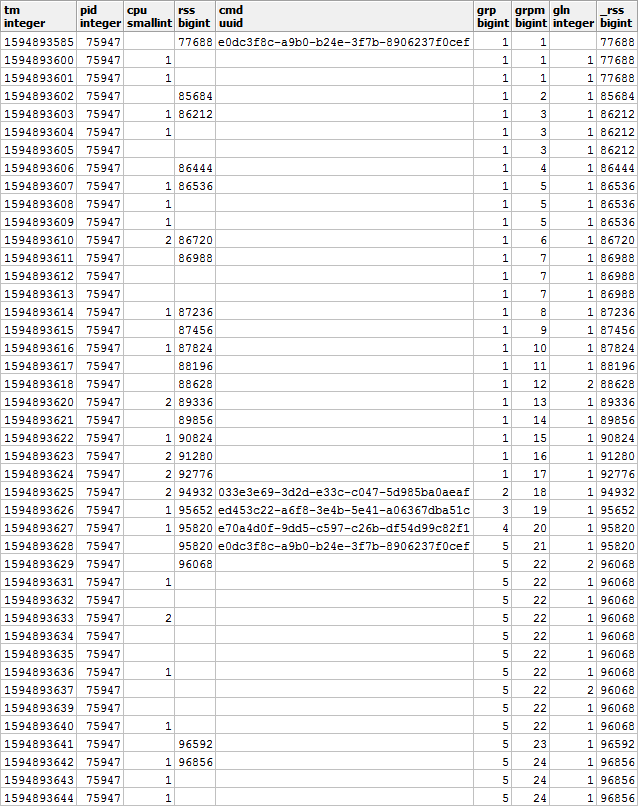
Заметим, что относительно начала нашего интервала первой попавшейся записью может оказаться как та, которая уже имеет заполненное поле CMD (PID#1 на картинке выше), так и с NULL'ом, обозначающим продолжение заполненного «выше» по хронологии значения (PID#2).
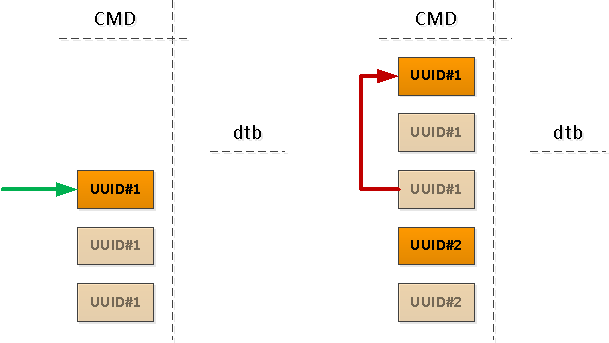
Те из PID, которые остались без CMD в результате предыдущей операции, начались раньше начала нашего интервала — значит, эти «начала» надо найти:
Поскольку мы точно знаем, что очередной сегмент активности начинается с заполненного значения CMD (а там и заполненный RSS, значит), тут нам поможет условный индекс:
Если мы хотим (а мы — хотим) знать время окончания активности сегмента, то уже для каждого PID придется воспользоваться «двухходовкой» для определения нижней границы.
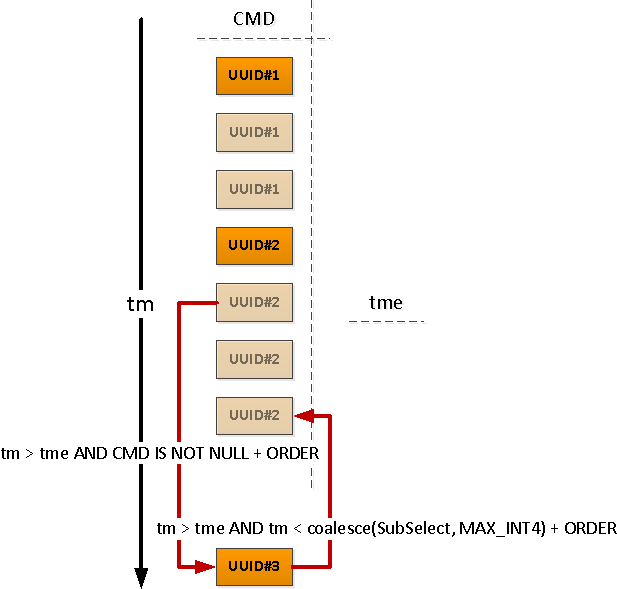
Замечу, что мы отбирали в
Причем по CMD и RSS группы будут независимы друг от друга, поэтому могут выглядеть примерно так:

Заполним пропуски по RSS и посчитаем продолжительность каждого отрезка, чтобы корректно учесть распределение нагрузки по времени:
Поскольку мы хотим увидеть в результате одновременно и сводную информацию по всему процессу, и его детализацию по разным сегментам активности, воспользуемся группировкой сразу по нескольким наборам ключей с помощью GROUPING SETS:
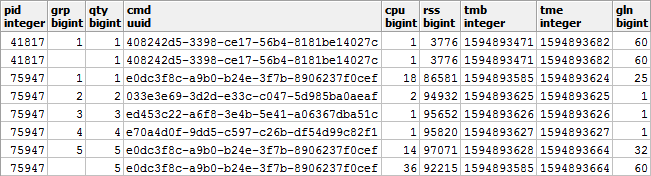
Создаем «словарь» CMD для всех найденных сегментов:
А теперь используем его вместо
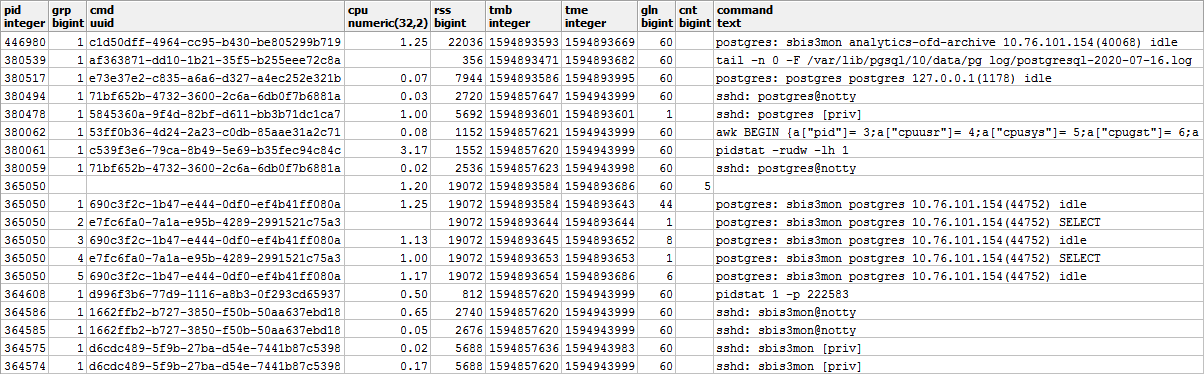
Напоследок убедимся, что весь наш запрос при выполнении оказался достаточно легковесным:

[посмотреть на explain.tensor.ru]
Всего 44ms и 33MB данных прочитано!
Поэтому, когда на каком-то из тысяч подконтрольных серверов случается аномальное потребление ресурсов (CPU, памяти, диска, сети, ...), возникает потребность разобраться «кто виноват, и что делать».
Для оперативного мониторинга использования ресурсов Linux-сервера «в моменте» существует утилита pidstat. То есть если пики нагрузки периодичны — их можно «высидеть» прямо в консоли. Но мы-то хотим эти данные анализировать постфактум, пытаясь найти процесс, создавший максимальную нагрузку на ресурсы.
То есть хочется иметь возможность смотреть по ранее собранным данным разные красивые отчеты с группировкой и детализацией на интервале типа таких:
В этой статье рассмотрим, как все это можно экономично расположить в БД, и как максимально эффективно собрать по этим данным отчет с помощью оконных функций и GROUPING SETS.
Сначала посмотрим, что за данные мы можем извлечь, если брать «все по максимуму»:
pidstat -rudw -lh 1| Time | UID | PID | %usr | %system | %guest | %CPU | CPU | minflt/s | majflt/s | VSZ | RSS | %MEM | kB_rd/s | kB_wr/s | kB_ccwr/s | cswch/s | nvcswch/s | Command |
| 1594893415 | 0 | 1 | 0.00 | 13.08 | 0.00 | 13.08 | 52 | 0.00 | 0.00 | 197312 | 8512 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 7.48 | /usr/lib/systemd/systemd --switched-root --system --deserialize 21 |
| 1594893415 | 0 | 9 | 0.00 | 0.93 | 0.00 | 0.93 | 40 | 0.00 | 0.00 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 350.47 | 0.00 | rcu_sched |
| 1594893415 | 0 | 13 | 0.00 | 0.00 | 0.00 | 0.00 | 1 | 0.00 | 0.00 | 0 | 0 | 0.00 | 0.00 | 0.00 | 0.00 | 1.87 | 0.00 | migration/11.87 |
Все эти значения делятся на несколько классов. Некоторые из них меняются постоянно (активность CPU и диска), другие — редко (выделение памяти), а Command — не только редко меняется в рамках одного процесса, но еще и регулярно повторяется на разных PID.
Структура базы
Для простоты давайте ограничимся одной метрикой каждого «класса», которые мы будем сохранять: %CPU, RSS и Command.
Раз мы заведомо знаем, что Command регулярно повторяется — просто вынесем его в отдельную таблицу-словарь, где UUID-ключом будет выступать MD5-хэш:
CREATE TABLE diccmd(
cmd
uuid
PRIMARY KEY
, data
varchar
);А для самих данных нам подойдет таблица такого вида:
CREATE TABLE pidstat(
host
uuid
, tm
integer
, pid
integer
, cpu
smallint
, rss
bigint
, cmd
uuid
);Обращу внимание, что раз %CPU приходит к нам всегда с точностью 2 знаков после запятой и заведомо не превышает 100.00, то мы спокойно можем домножить его на 100 и положить в
smallint. С одной стороны, это избавит нас от проблем точности учета при операциях, с другой — все-таки лучше хранить только 2 байта по сравнению с 4 байтами real или 8 байтами double precision.Подробнее о способах эффективной упаковки записей в PostgreSQL-хранилище можно прочитать в статье «Экономим копеечку на больших объемах», а про увеличение пропускной способности базы на запись — в «Пишем на субсветовой: 1 host, 1 day, 1TB».
«Бесплатное» хранение NULL'ов
Чтобы сэкономить производительность дисковой подсистемы нашей базы и занимаемый базой объем, постараемся как можно больше данных представить в виде NULL — их хранение практически «бесплатно», поскольку занимает лишь бит в заголовке записи.
Подробнее с внутренней механикой представления записей в PostgreSQL можно ознакомиться в докладе Николая Шаплова на PGConf.Russia 2016 «Что у него внутри: хранение данных на низком уровне». Конкретно хранению NULL посвящен слайд #16.Снова внимательно посмотрим на виды наших данных:
- CPU/DSK
Меняется постоянно, но очень часто обращается в ноль — так что выгодно писать в базу NULL вместо 0. - RSS/CMD
Меняется достаточно редко — поэтому будем писать NULL вместо повторов в рамках одного и того же PID.
Получается картинка вроде такой, если смотреть на нее в разрезе конкретного PID:

Понятно, что если у нас процесс начал выполнять другую команду, то значение используемой памяти тоже наверняка окажется не таким, как раньше — поэтому договоримся, что при смене CMD значение RSS тоже будем фиксировать, независимо от предыдущего значения.
То есть у записи с заполненным значением CMD заполнено и значение RSS. Запомним этот момент, он нам еще пригодится.
Собираем красивый отчет
Давайте теперь соберем запрос, который покажет нам потребителей ресурсов конкретного хоста на определенном временном интервале.
Но сделаем это сразу с минимальным использованием ресурсов — примерно как в статье про SELF JOIN и оконные функции.
Использование входящих параметров
Чтобы не указывать значения параметров отчета (или $1/$2) в нескольких местах по ходу SQL-запроса, выделим CTE из единственного json-поля, в котором по ключам находятся эти самые параметры:
-- сохраняем параметры отчета
WITH args AS (
SELECT
json_object(
ARRAY[
'dtb'
, extract('epoch' from '2020-07-16 10:00'::timestamp(0)) -- переводим timestamp в integer
, 'dte'
, extract('epoch' from '2020-07-16 10:01'::timestamp(0))
, 'host'
, 'e828a54d-7e8a-43dd-b213-30c3201a6d8e' -- это у нас uuid
]::text[]
)
)
Извлекаем «сырые» данные
Поскольку никаких сложных агрегатов мы не придумывали, единственный способ проанализировать данные — прочитать их. Для этого нам понадобится очевидный индекс:
CREATE INDEX ON pidstat(host, tm);-- извлекаем "сырые" данные
, src AS (
SELECT
*
FROM
pidstat
WHERE
host = ((TABLE args) ->> 'host')::uuid AND
tm >= ((TABLE args) ->> 'dtb')::integer AND
tm < ((TABLE args) ->> 'dte')::integer
)
Группировка по ключу анализа
Для каждого найденного PID определим интервал его активности и возьмем CMD с первой записи на этом интервале.
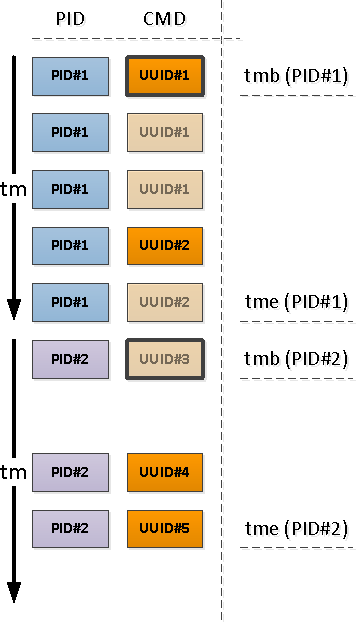
Для этого воспользуемся уникализацией через
DISTINCT ON и оконными функциями:-- группировка по ключу анализа
, pidtm AS (
SELECT DISTINCT ON(pid)
host
, pid
, cmd
, min(tm) OVER(w) tmb -- начало активности процесса на интервале
, max(tm) OVER(w) tme -- завершение активности
FROM
src
WINDOW
w AS(PARTITION BY pid)
ORDER BY
pid
, tm
)
Границы активности процесса
Заметим, что относительно начала нашего интервала первой попавшейся записью может оказаться как та, которая уже имеет заполненное поле CMD (PID#1 на картинке выше), так и с NULL'ом, обозначающим продолжение заполненного «выше» по хронологии значения (PID#2).
Те из PID, которые остались без CMD в результате предыдущей операции, начались раньше начала нашего интервала — значит, эти «начала» надо найти:

Поскольку мы точно знаем, что очередной сегмент активности начинается с заполненного значения CMD (а там и заполненный RSS, значит), тут нам поможет условный индекс:
CREATE INDEX ON pidstat(host, pid, tm DESC) WHERE cmd IS NOT NULL;-- определяем начало активности каждого "неопределившегося" процесса
, precmd AS (
SELECT
t.host
, t.pid
, c.tm
, c.rss
, c.cmd
FROM
pidtm t
, LATERAL(
SELECT
*
FROM
pidstat -- увы, SELF JOIN не избежать
WHERE
(host, pid) = (t.host, t.pid) AND
tm < t.tmb AND
cmd IS NOT NULL -- садимся на условный индекс
ORDER BY
tm DESC
LIMIT 1
) c
WHERE
t.cmd IS NULL -- только для "неопределившихся"
)
Если мы хотим (а мы — хотим) знать время окончания активности сегмента, то уже для каждого PID придется воспользоваться «двухходовкой» для определения нижней границы.
Аналогичную методику мы уже использовали в статье «PostgreSQL Antipatterns: навигация по реестру».

-- определяем момент окончания активности сегмента
, pstcmd AS (
SELECT
host
, pid
, c.tm
, NULL::bigint rss
, NULL::uuid cmd
FROM
pidtm t
, LATERAL(
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
tm < coalesce((
SELECT
tm
FROM
pidstat
WHERE
(host, pid) = (t.host, t.pid) AND
tm > t.tme AND
cmd IS NOT NULL
ORDER BY
tm
LIMIT 1
), x'7fffffff'::integer) -- MAX_INT4
ORDER BY
tm DESC
LIMIT 1
) c
)
JSON-конвертация форматов записей
Замечу, что мы отбирали в
precmd/pstcmd только те поля, которые влияют на последующие строки, а всякие CPU/DSK, которые меняются постоянно — нет. Поэтому формат записей в исходной таблице и этих CTE у нас расходится. Не беда!- row_to_json — превращаем каждую запись с полями в json-объект
- array_agg — собираем все записи в '{...}'::json[]
- array_to_json — преобразуем массив-из-JSON в JSON-массив '[...]'::json
- json_populate_recordset — генерируем из JSON-массива выборку заданной структуры
Тут мы используем именно однократный вызовСклеиваем найденные «начала» и «концы» в общую кучу и добавляем к исходному набору записей:json_populate_recordsetвместо множественногоjson_populate_record, потому что это банально быстрее в разы.
-- склеиваем все
, uni AS (
TABLE src
UNION ALL
SELECT
*
FROM
json_populate_recordset( -- развернули в полный
NULL::pidstat
, (
SELECT
array_to_json(array_agg(row_to_json(t))) -- свернули сокращенный формат
FROM
(
TABLE precmd
UNION ALL
TABLE pstcmd
) t
)
)
)
Заполняем NULL-пропуски повторов
Воспользуемся моделью, рассмотренной в статье «SQL HowTo: собираем «цепочки» с помощью window functions».Сначала выделим группы «повторов»:
-- выделение групп
, grp AS (
SELECT
*
, count(*) FILTER(WHERE cmd IS NOT NULL) OVER(w) grp -- группы по CMD
, count(*) FILTER(WHERE rss IS NOT NULL) OVER(w) grpm -- группы по RSS
FROM
uni
WINDOW
w AS(PARTITION BY pid ORDER BY tm)
)
Причем по CMD и RSS группы будут независимы друг от друга, поэтому могут выглядеть примерно так:
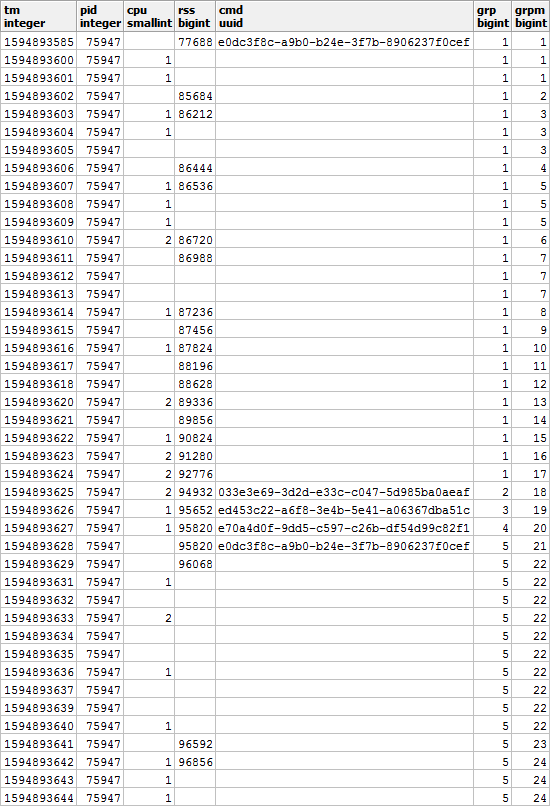
Заполним пропуски по RSS и посчитаем продолжительность каждого отрезка, чтобы корректно учесть распределение нагрузки по времени:
-- заполняем пропуски
, rst AS (
SELECT
*
, CASE
WHEN least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) >= greatest(tm, ((TABLE args) ->> 'dtb')::integer) THEN
least(coalesce(lead(tm) OVER(w) - 1, tm), ((TABLE args) ->> 'dte')::integer - 1) - greatest(tm, ((TABLE args) ->> 'dtb')::integer) + 1
END gln -- продолжительность сегмента от предыдущей записи или начала интервала
, first_value(rss) OVER(PARTITION BY pid, grpm ORDER BY tm) _rss -- заполнение пропусков по RSS
FROM
grp
WINDOW
w AS(PARTITION BY pid, grp ORDER BY tm)
)
Мультигруппировка с помощью GROUPING SETS
Поскольку мы хотим увидеть в результате одновременно и сводную информацию по всему процессу, и его детализацию по разным сегментам активности, воспользуемся группировкой сразу по нескольким наборам ключей с помощью GROUPING SETS:
-- мультигруппировка
, gs AS (
SELECT
pid
, grp
, max(grp) qty -- количество сегментов активности по PID
, (array_agg(cmd ORDER BY tm) FILTER(WHERE cmd IS NOT NULL))[1] cmd -- "должен остаться только один"
, sum(cpu) cpu
, avg(_rss)::bigint rss
, min(tm) tmb
, max(tm) tme
, sum(gln) gln
FROM
rst
GROUP BY
GROUPING SETS((pid, grp), pid)
)
Вариант использования (array_agg(... ORDER BY ..) FILTER(WHERE ...))[1] позволяет нам прямо при группировке, без дополнительных телодвижений получить первое непустое (даже если оно не самое первое) значение из всего набора.Вариант получения сразу нескольких разрезов целевой выборки очень удобен для формирования различных отчетов с детализацией, чтобы все детализирующие данные не надо было перестраивать, а чтобы в UI они попадали вместе с основной выборкой.Словарь вместо JOIN
Создаем «словарь» CMD для всех найденных сегментов:
Подробнее про методику «ословаривания» можно прочесть в статье «PostgreSQL Antipatterns: ударим словарем по тяжелому JOIN».
-- словарь CMD
, cmdhs AS (
SELECT
json_object(
array_agg(cmd)::text[]
, array_agg(data)
)
FROM
diccmd
WHERE
cmd = ANY(ARRAY(
SELECT DISTINCT
cmd
FROM
gs
WHERE
cmd IS NOT NULL
))
)
А теперь используем его вместо
JOIN, получая финальные «красивые» данные:
SELECT
pid
, grp
, CASE
WHEN grp IS NOT NULL THEN -- это "сегмент" активности
cmd
END cmd
, (nullif(cpu::numeric / gln, 0))::numeric(32,2) cpu -- приводим CPU к "средней" нагрузке
, nullif(rss, 0) rss
, tmb -- верхняя граница активности
, tme -- нижняя граница активности
, gln -- продолжительность активности
, CASE
WHEN grp IS NULL THEN -- это весь процесс
qty
END cnt
, CASE
WHEN grp IS NOT NULL THEN
(TABLE cmdhs) ->> cmd::text -- извлекаем данные из словаря
END command
FROM
gs
WHERE
grp IS NOT NULL OR -- это запись "сегмента"
qty > 1 -- или в процессе больше одного сегмента
ORDER BY
pid DESC
, grp NULLS FIRST;
Напоследок убедимся, что весь наш запрос при выполнении оказался достаточно легковесным:

[посмотреть на explain.tensor.ru]
Всего 44ms и 33MB данных прочитано!
