Недавно я рассказал, как с помощью типовых рецептов увеличить производительность SQL-запросов «на чтение» из PostgreSQL-базы. Сегодня же речь пойдет о том, как можно сделать более эффективной запись в БД без использования каких-либо «крутилок» в конфиге — просто правильно организовав потоки данных.

Статья про то, как и зачем стоит организовывать прикладное секционирование «в теории» уже была, здесь же речь пойдет о практике применения некоторых подходов в рамках нашего сервиса мониторинга сотен PostgreSQL-серверов.
Изначально, как и всякий MVP, наш проект стартовал под достаточно небольшой нагрузкой — мониторинг осуществлялся только для десятка наиболее критичных серверов, все таблицы были относительно компактны… Но время шло, отслеживаемых хостов становилось все больше, и попытавшись в очередной раз что-то сделать с одной из таблиц размером 1.5TB, мы поняли, что жить так дальше хоть и можно, но очень уж неудобно.
Времена были почти что былинные, актуальными были разные варианты PostgreSQL 9.x, поэтому все секционирование пришлось делать «вручную» — через наследование таблиц и триггеры роутинга с динамическим
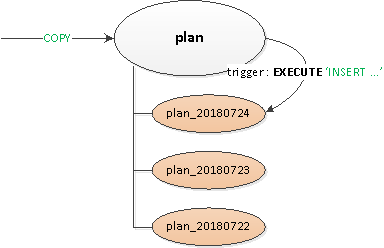
Получившееся решение оказалось достаточно универсальным, чтобы можно было странслировать его на все таблицы:
Но секционирование через наследование было исторически не очень приспособлено для работы с активным потоком записи или большим количеством секций-потомков. Например, можно вспомнить, что алгоритм выбора нужной секции имел квадратичную сложность, что при 100+ секциях работает, сами понимаете как…
В PG10 эту ситуацию сильно оптимизировали, реализовав поддержку нативного секционирования. Поэтому мы сходу попробовали его применить сразу после миграции хранилища, но…
Как выяснилось после перекапывания мануала, нативно секционированная таблица в этой версии:
Больно получив по лбу граблями, мы поняли, что без модификации приложения обойтись не удастся, и отложили дальнейшие исследования на полгода.
Итак, мы начали решать возникшие проблемы по очереди:
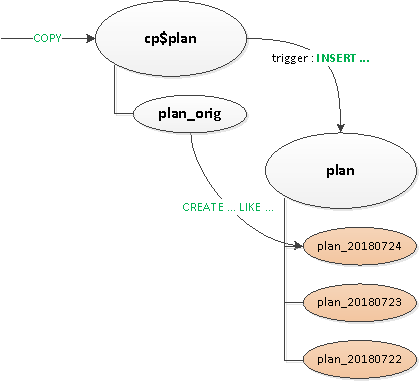
Наконец, после всего этого, уже нативно отсекционировали основную таблицу. Создание новой секции пока так и осталось на совести приложения.
Как и в любой аналитической системе, у нас тоже были «факты» и «разрезы» (словари). В нашем случае, в этом качестве выступали, например, тело «шаблона» однотипных медленных запросов или текст самого запроса.
«Факты» у нас были отсекционированы по дням уже давно, поэтому мы спокойно удаляли устаревшие секции, и они нам не мешали (логи же!). А вот со словарями получилась беда…
Не сказать, что их оказалось очень много, но примерно на 100TB «фактов» получился словарь на 2.5TB. Из такой таблицы удобно ничего не поудаляешь, не сожмешь за адекватное время, да и запись в нее постепенно становилась все медленнее.
Вроде словарь… в нем каждая запись должна быть представлена ровно один раз… и это правильно, но!.. Никто не мешает нам иметь по отдельному словарю на каждый день! Да, это приносит определенную избыточность, зато позволяет:
В результате всего комплекса мероприятий нагрузка по CPU сократилась на ~30%, по диску — на ~50%:
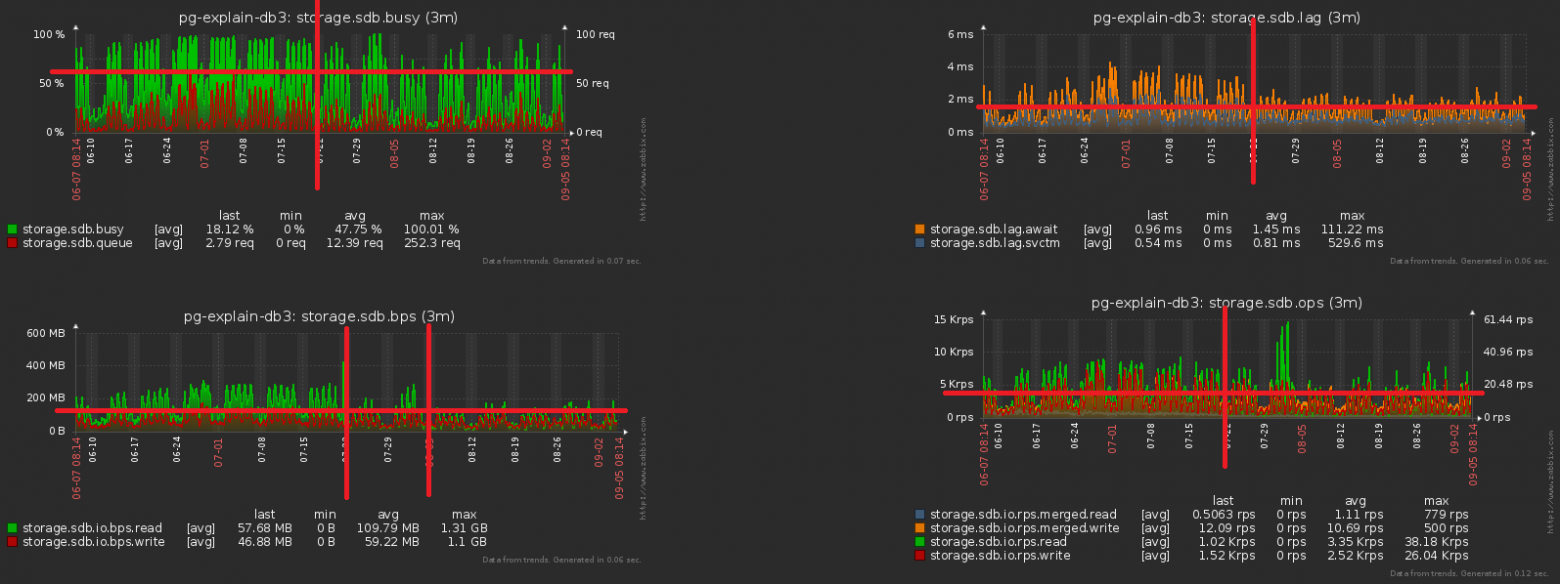
При этом мы продолжили писать в базу ровно то же самое, просто с меньшей нагрузкой.
Итак, мы остановились на том, что у нас на каждый день есть своя секция с данными. Собственно,
Поскольку все отчеты в нашем сервисе строятся в разрезе конкретной даты, то и индексы еще с «несекционированных времен» для них были все типа (Сервер, Дата, Шаблон плана), (Сервер, Дата, Узел плана), (Дата, Класс ошибки, Сервер),…
Но теперь на каждой секции живут свои экземпляры каждого такого индекса… И в рамках каждой секции дата — константа… Получается, что теперь мы в каждый такой индекс банально вписываем константу в качестве одного из полей, что делает больше и его объем, и время поиска по нему, но не приносит никакого результата. Сами себе оставили грабли, упс…

Направление оптимизации очевидно — просто убираем поле с датой из всех индексов на секционированных таблицах. При наших объемах выигрыш — порядка 1TB/неделю!
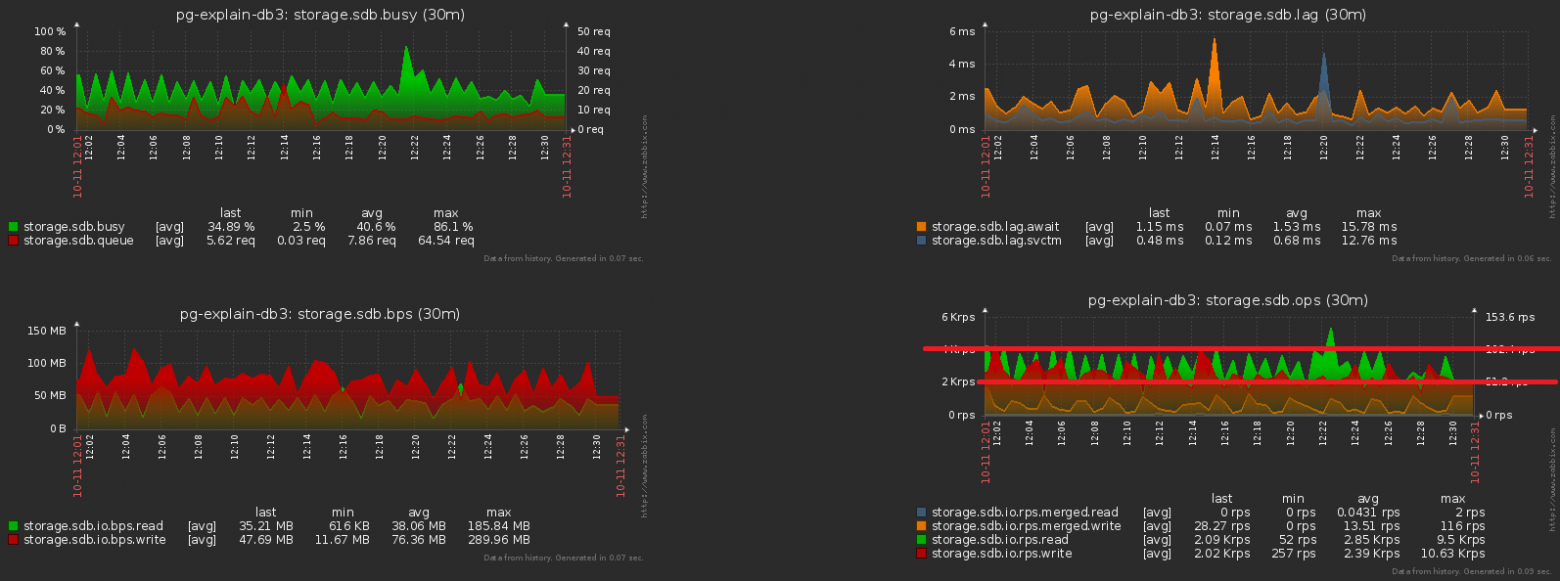
А теперь давайте заметим, что этот терабайт еще надо было как-то записать. То есть мы еще и диск должны теперь грузить меньше! На этой картинке хорошо виден полученный эффект от проведенной чистки, которой мы посвятили неделю:

Одна из больших бед нагруженных систем — это избыточная синхронизация каких-то операций того не требующих. Иногда «потому что не заметили», иногда «так было проще», но рано или поздно приходится от нее избавляться.
Приближаем предыдущую картинку — и видим, что диск у нас «качает» по нагрузке с двукратной амплитудой между соседними отсчетами, чего явно «статистически» не должно быть при таком количестве операций:
Добиться этого достаточно просто. У нас на мониторинг было заведено уже почти 1000 серверов, каждый обрабатывается отдельным логическим потоком, а каждый поток сбрасывает накопленную информацию для отправки в базу с определенной периодичностью, примерно так:
Проблема тут кроется ровно в том, что все потоки стартуют примерно в одно время, поэтому моменты отправки у них почти всегда совпадают «до точки». Упс №2…
К счастью, правится это достаточно легко, добавлением «случайной» разбежки по времени:
#4. Кэшируем, что
Третья традиционная проблема highload — отсутствие кэша там, где он мог бы быть.
Например, мы сделали возможность анализа в разрезе узлов плана (все эти
Нет, конечно, в базу ничего повторно не пишется, это отсекает триггер с
Разница по количеству отправляемых в базу записей до/после включения кэширования — очевидна:
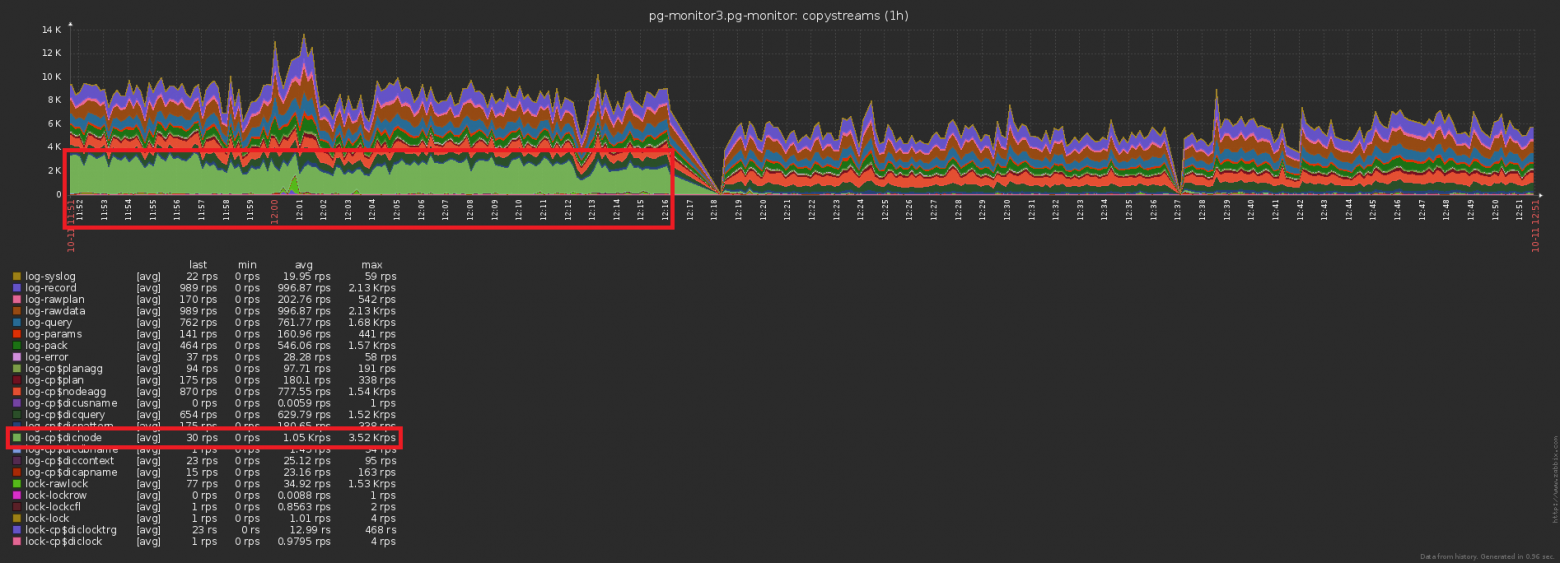
А это — сопутствующее падение нагрузки на хранилище:

«Терабайт-в-сутки» только звучит страшно. Если вы все делаете правильно, то это всего лишь 2^40 байт / 86400 секунд = ~12.5MB/s, что держали даже настольные IDE-винты. :)
А если серьезно, то даже при десятикратном «перекосе» нагрузки в течение суток, вы спокойно можете уложиться в возможности современных SSD.


#1. Секционирование
Статья про то, как и зачем стоит организовывать прикладное секционирование «в теории» уже была, здесь же речь пойдет о практике применения некоторых подходов в рамках нашего сервиса мониторинга сотен PostgreSQL-серверов.
«Дела давно минувших дней...»
Изначально, как и всякий MVP, наш проект стартовал под достаточно небольшой нагрузкой — мониторинг осуществлялся только для десятка наиболее критичных серверов, все таблицы были относительно компактны… Но время шло, отслеживаемых хостов становилось все больше, и попытавшись в очередной раз что-то сделать с одной из таблиц размером 1.5TB, мы поняли, что жить так дальше хоть и можно, но очень уж неудобно.
Времена были почти что былинные, актуальными были разные варианты PostgreSQL 9.x, поэтому все секционирование пришлось делать «вручную» — через наследование таблиц и триггеры роутинга с динамическим
EXECUTE.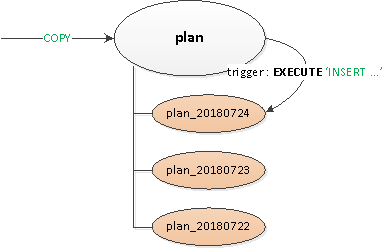
Получившееся решение оказалось достаточно универсальным, чтобы можно было странслировать его на все таблицы:
- Была объявлена пустая «заголовочная» родительская таблица, на которой описывались все нужные индексы и триггеры.
- Запись с точки зрения клиента производилась в «корневую» таблицу, а внутри с помощью триггера роутинга
BEFORE INSERTзапись «физически» вставлялась в нужную секцию. Если такой еще не было — мы ловили исключение и ... - … с помощью
CREATE TABLE ... (LIKE ... INCLUDING ...)по шаблону родительской таблицы создавалась секция с ограничением на нужную дату, чтобы при извлечении данных чтение производилось только в ней.
PG10: первая попытка
Но секционирование через наследование было исторически не очень приспособлено для работы с активным потоком записи или большим количеством секций-потомков. Например, можно вспомнить, что алгоритм выбора нужной секции имел квадратичную сложность, что при 100+ секциях работает, сами понимаете как…
В PG10 эту ситуацию сильно оптимизировали, реализовав поддержку нативного секционирования. Поэтому мы сходу попробовали его применить сразу после миграции хранилища, но…
Как выяснилось после перекапывания мануала, нативно секционированная таблица в этой версии:
- не поддерживает описание индексов
- не поддерживает на ней триггеров
- не может быть сама ничьим «потомком»
- не поддерживает
INSERT ... ON CONFLICT - не умеет порождать секцию автоматически
Больно получив по лбу граблями, мы поняли, что без модификации приложения обойтись не удастся, и отложили дальнейшие исследования на полгода.
PG10: второй шанс
Итак, мы начали решать возникшие проблемы по очереди:
- Поскольку триггеры и
ON CONFLICTнам оказались кое-где все-таки нужны, для их отработки сделали промежуточную прокси-таблицу. - Избавились от «роутинга» в триггерах — то есть от
EXECUTE. - Вынесли отдельно таблицу-шаблон со всеми индексами, чтобы они даже не присутствовали на прокси-таблице.

Наконец, после всего этого, уже нативно отсекционировали основную таблицу. Создание новой секции пока так и осталось на совести приложения.
«Пилим» словари
Как и в любой аналитической системе, у нас тоже были «факты» и «разрезы» (словари). В нашем случае, в этом качестве выступали, например, тело «шаблона» однотипных медленных запросов или текст самого запроса.
«Факты» у нас были отсекционированы по дням уже давно, поэтому мы спокойно удаляли устаревшие секции, и они нам не мешали (логи же!). А вот со словарями получилась беда…
Не сказать, что их оказалось очень много, но примерно на 100TB «фактов» получился словарь на 2.5TB. Из такой таблицы удобно ничего не поудаляешь, не сожмешь за адекватное время, да и запись в нее постепенно становилась все медленнее.
Вроде словарь… в нем каждая запись должна быть представлена ровно один раз… и это правильно, но!.. Никто не мешает нам иметь по отдельному словарю на каждый день! Да, это приносит определенную избыточность, зато позволяет:
- писать/читать быстрее за счет меньшего размера секции
- потреблять меньше памяти за счет работы с более компактными индексами
- хранить меньше данных за счет возможности быстрого удаления устаревших
В результате всего комплекса мероприятий нагрузка по CPU сократилась на ~30%, по диску — на ~50%:

При этом мы продолжили писать в базу ровно то же самое, просто с меньшей нагрузкой.
#2. Эволюция и рефакторинг БД
Итак, мы остановились на том, что у нас на каждый день есть своя секция с данными. Собственно,
CHECK (dt = '2018-10-12'::date) — и есть ключ секционирования и условие попадания записи в конкретную секцию.Поскольку все отчеты в нашем сервисе строятся в разрезе конкретной даты, то и индексы еще с «несекционированных времен» для них были все типа (Сервер, Дата, Шаблон плана), (Сервер, Дата, Узел плана), (Дата, Класс ошибки, Сервер),…
Но теперь на каждой секции живут свои экземпляры каждого такого индекса… И в рамках каждой секции дата — константа… Получается, что теперь мы в каждый такой индекс банально вписываем константу в качестве одного из полей, что делает больше и его объем, и время поиска по нему, но не приносит никакого результата. Сами себе оставили грабли, упс…

Направление оптимизации очевидно — просто убираем поле с датой из всех индексов на секционированных таблицах. При наших объемах выигрыш — порядка 1TB/неделю!
А теперь давайте заметим, что этот терабайт еще надо было как-то записать. То есть мы еще и диск должны теперь грузить меньше! На этой картинке хорошо виден полученный эффект от проведенной чистки, которой мы посвятили неделю:
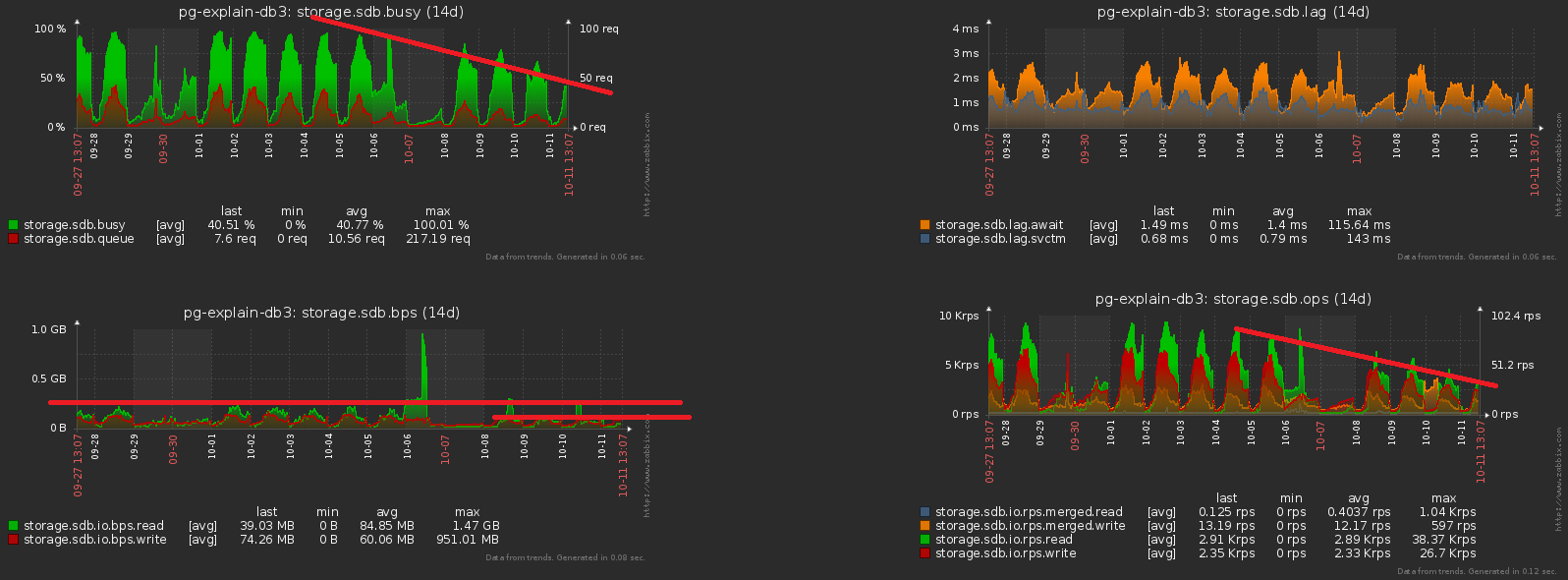
#3. «Размазываем» пиковую нагрузку
Одна из больших бед нагруженных систем — это избыточная синхронизация каких-то операций того не требующих. Иногда «потому что не заметили», иногда «так было проще», но рано или поздно приходится от нее избавляться.
Приближаем предыдущую картинку — и видим, что диск у нас «качает» по нагрузке с двукратной амплитудой между соседними отсчетами, чего явно «статистически» не должно быть при таком количестве операций:
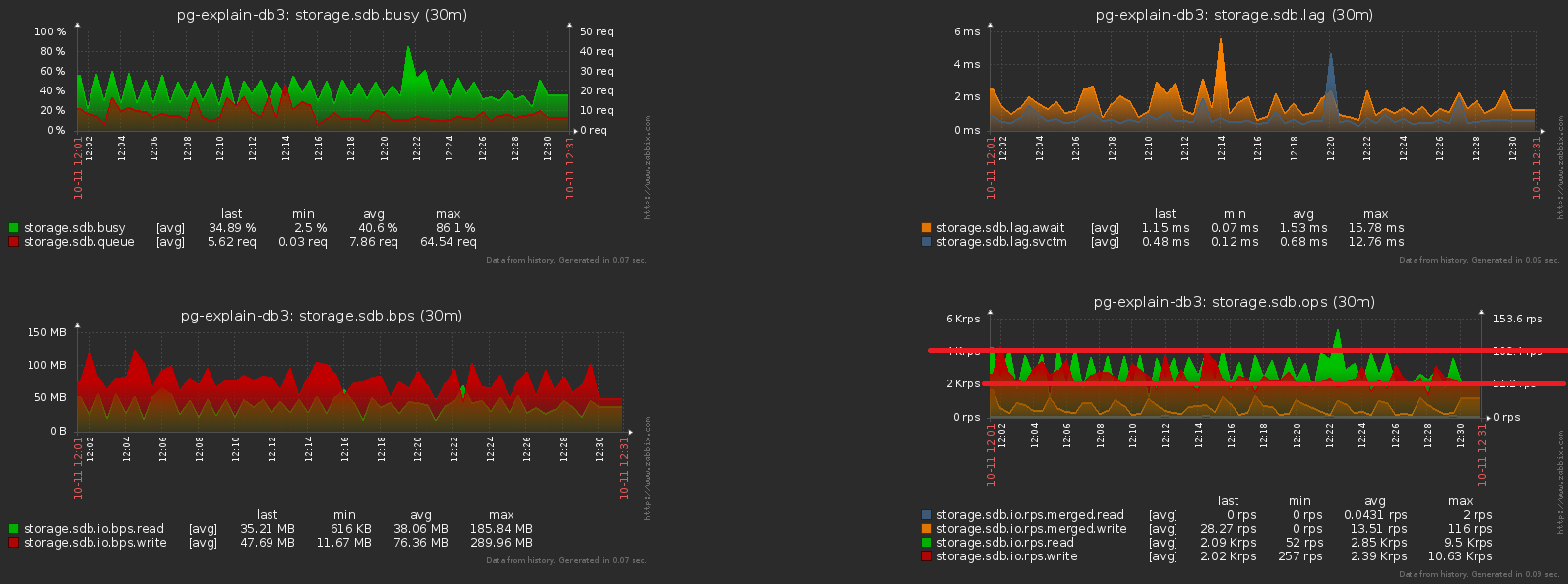
Добиться этого достаточно просто. У нас на мониторинг было заведено уже почти 1000 серверов, каждый обрабатывается отдельным логическим потоком, а каждый поток сбрасывает накопленную информацию для отправки в базу с определенной периодичностью, примерно так:
setInterval(sendToDB, interval)Проблема тут кроется ровно в том, что все потоки стартуют примерно в одно время, поэтому моменты отправки у них почти всегда совпадают «до точки». Упс №2…
К счастью, правится это достаточно легко, добавлением «случайной» разбежки по времени:
setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))#4. Кэшируем, что нужно можно
Третья традиционная проблема highload — отсутствие кэша там, где он мог бы быть.
Например, мы сделали возможность анализа в разрезе узлов плана (все эти
Seq Scan on users), но сразу подумать, что они, в массе, одинаковые — забыли.Нет, конечно, в базу ничего повторно не пишется, это отсекает триггер с
INSERT ... ON CONFLICT DO NOTHING. Но до базы-то эти данные долетают все равно, да еще и лишнее чтение для проверки конфликта делать приходится. Упс №3…Разница по количеству отправляемых в базу записей до/после включения кэширования — очевидна:
А это — сопутствующее падение нагрузки на хранилище:

Итого
«Терабайт-в-сутки» только звучит страшно. Если вы все делаете правильно, то это всего лишь 2^40 байт / 86400 секунд = ~12.5MB/s, что держали даже настольные IDE-винты. :)
А если серьезно, то даже при десятикратном «перекосе» нагрузки в течение суток, вы спокойно можете уложиться в возможности современных SSD.

