Я уже рассказывал про сервис мониторинга запросов к PostgreSQL, для которого мы реализовали онлайн-коллектор серверных логов, чья основная задача — одновременно принимать потоки логов сразу с большого количества хостов, быстро их разбирать на строки, группировать в пакеты по определенным правилам, обрабатывать и записывать результат в PostgreSQL-хранилище.

В нашем случае речь идет о нескольких сотнях серверов и миллионах запросов и планов, которые генерируют больше 100GB логов в день. Поэтому было совсем неудивительно, когда мы обнаружили, что львиная доля ресурсов тратится именно на две эти операции: разбор на строки и запись в базу.
Мы погрузились в недра профайлера и обнаружили некоторые особенности работы с
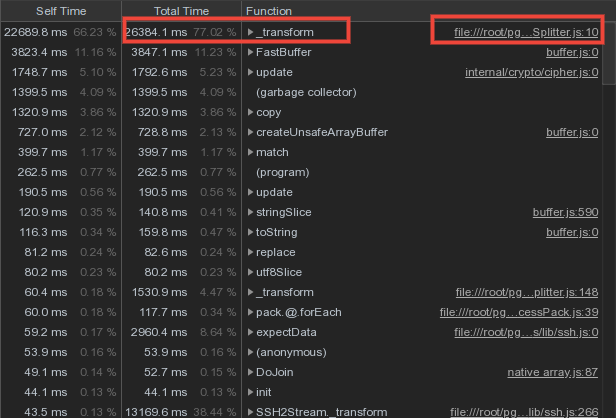
Большая часть процессорного времени тратилась на обработку входящего лог-потока, что вполне понятно. Но что было непонятно — ресурсоемкость примитивной «нарезки» входящего потока бинарных блоков на строки по

Внимательный разработчик сразу заметит тут не особо эффективный побайтовый цикл по входящему буферу. Ну а поскольку строка может быть «разорвана» между соседними блоками, то присутствует и функционал «прицепления хвоста», оставшегося от предыдущего обработанного блока.
Беглый обзор имеющихся решений вывел нас на штатный модуль readline ровно с необходимым нам функционалом нарезки на строки:

После его внедрения «нарезка» из топа профайлера ушла в глубину:

Но, как выяснилось, внутри себя readline принудительно приводит строку в UTF-8, чего нельзя делать, если у записи лога (запроса, плана, текста ошибки) другая исходная кодировка.
Ведь даже на одном PostgreSQL-сервере может быть одновременно активно несколько баз, каждая из которых формирует вывод в общий серверный лог именно в своей оригинальной кодировке. В результате, обладатели баз на win-1251 (иногда удобно применять ради экономии дискового пространства, если «честный» многобайтовый UNICODE не нужен) смогли наблюдать у себя планы с примерно такими «русскими» названиями таблиц и индексов:

Беда-беда… Придется все таки делать нарезку самостоятельно, но уже с оптимизациями типа

Вроде все хорошо, в тестовом контуре нагрузка не выросла, win1251-названия починились, выкатываем на бой… Та-дам! CPU usage периодически пробивает потолок в 100%:

Как же так?.. Оказывается, во всем виноват
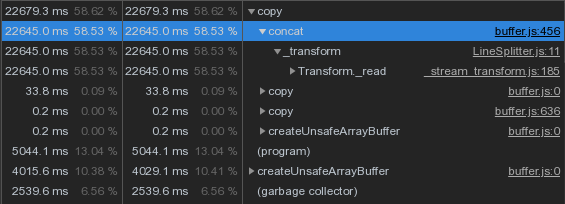
Но ведь у нас склейка идет только при переходе строки через блок, а их не должно быть много — правда-правда?.. Ну, почти. Только вот иногда приходят «строки» из нескольких сотен 16KB-сегментов:

Спасибо коллегам-разработчикам, которые позаботились такое сгенерировать. Случается оно «редко, но метко», поэтому увидеть заранее в тестовом контуре не удалось.
Понятно, что подклейка несколько сотен раз к буферу на несколько мегабайт мелких кусочков — прямой путь в бездну переаллокаций памяти с выеданием ресурсов CPU, что мы и пронаблюдали. Так а давайте просто не будем клеить, пока строка не кончилась совсем. Просто будем складывать «кусочки» в массив, пока не настанет пора отдать всю строку «наружу»:

Теперь нагрузка снова вернулась к показателям, которые давал readline.
Многие, кто писал на языках с динамическим выделением памяти, в курсе, что одна из наиболее неприятных «убийц производительности» — это фоновая активность «сборщика мусора» (Garbage Collector, GC), который сканирует созданные в памяти объекты и удаляет те, которые больше никому не требуются. Настигла эта неприятность и нас — в какой-то момент мы начали замечать, что активности GC как-то слишком уж много, и не к месту.
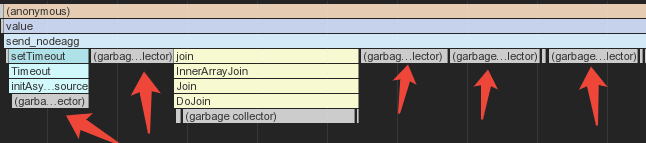
Традиционные «крутилки» не особо помогали… «Если ничего не помогает — сделай дамп!» И народная мудрость не подвела — мы увидели тучу Buffer по 8360 байт общим размером на 520MB…

Причем порождены они внутри CopyBinaryStream — ситуация начала проясняться…
Чтобы уменьшить объем передаваемого на БД трафика, мы используем бинарный формат COPY. Фактически, для каждой записи нужно в поток отправить буфер, состоящий из «кусочков» — количества полей в записи (2 байта) и дальше бинарного представления значения каждого из столбцов (4 байта на ID типа + данные).
Поскольку «суммарно» такая строка таблицы почти всегда имеет переменную длину, то сразу выделять буфер фиксированной длины — не вариант, переаллокации при нехватке размера легко «доедят» производительность, уже прошли выше. Значит, тоже стоит «клеить из кусочков» с помощью
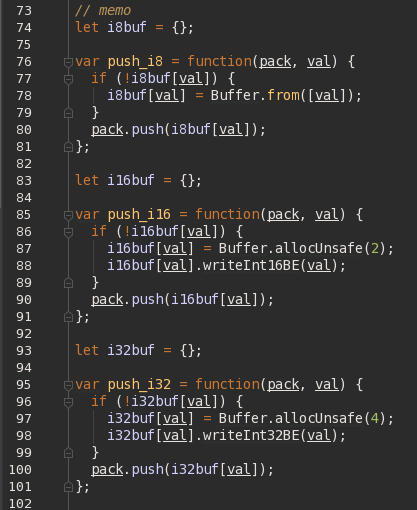
Ну а раз у нас многие кусочки повторяются снова и снова (например, количество полей в записях одной и той же таблицы) — давайте будем просто их запоминать, а потом брать уже готовые, сгенерированные однократно при первом обращении. Исходя из COPY-формата вариантов достаточно немного — типовые кусочки бывают по 1, 2 или 4 байта:
И… бам, прилетели грабли!

То есть да, каждый раз при создании Buffer по-умолчанию выделяется кусок памяти 8KB, чтобы создаваемые подряд небольшие буферы можно было складывать «рядом» в уже выделенной памяти. А наше выделение срабатывало «по требованию», и оказывалось совсем не «рядом» — поэтому каждый наш буфер на 1-2-4 байта физически занимал 8KB + заголовок — вот они, наши 520MB!
Хм… А зачем нам вообще ждать, пока потребуется тот или иной 1/2-байтовый буфер? С 4-байтовыми тема отдельная, но этих-то разных возможных вариантов всего 256 + 65536. Так давайте нагенерим их подряд все сразу! Заодно и условие существования из каждой проверки спилим — еще и работать станет быстрее, поскольку инициализация проводится только при старте процесса.
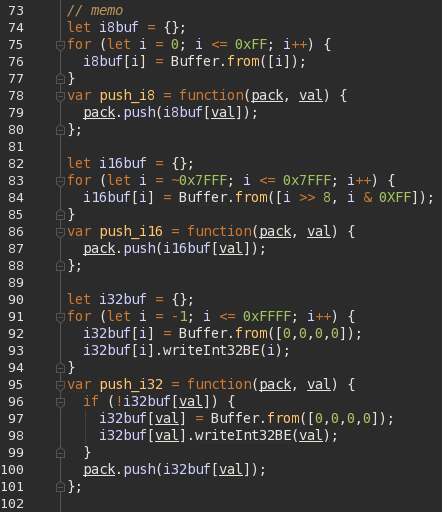
То есть кроме 1/2-байтовых буферов сразу инициализируем и самые ходовые значения (нижние 2 байта и -1) для 4-байтовых. И — это помогло, всего 10MB вместо 520MB!


В нашем случае речь идет о нескольких сотнях серверов и миллионах запросов и планов, которые генерируют больше 100GB логов в день. Поэтому было совсем неудивительно, когда мы обнаружили, что львиная доля ресурсов тратится именно на две эти операции: разбор на строки и запись в базу.
Мы погрузились в недра профайлера и обнаружили некоторые особенности работы с
Buffer в Node.js, знание которых может сильно сэкономить ваше время и серверные ресурсы.Процессорная нагрузка

Большая часть процессорного времени тратилась на обработку входящего лог-потока, что вполне понятно. Но что было непонятно — ресурсоемкость примитивной «нарезки» входящего потока бинарных блоков на строки по
\r\n:
Внимательный разработчик сразу заметит тут не особо эффективный побайтовый цикл по входящему буферу. Ну а поскольку строка может быть «разорвана» между соседними блоками, то присутствует и функционал «прицепления хвоста», оставшегося от предыдущего обработанного блока.
Пробуем readline
Беглый обзор имеющихся решений вывел нас на штатный модуль readline ровно с необходимым нам функционалом нарезки на строки:

После его внедрения «нарезка» из топа профайлера ушла в глубину:

Но, как выяснилось, внутри себя readline принудительно приводит строку в UTF-8, чего нельзя делать, если у записи лога (запроса, плана, текста ошибки) другая исходная кодировка.
Ведь даже на одном PostgreSQL-сервере может быть одновременно активно несколько баз, каждая из которых формирует вывод в общий серверный лог именно в своей оригинальной кодировке. В результате, обладатели баз на win-1251 (иногда удобно применять ради экономии дискового пространства, если «честный» многобайтовый UNICODE не нужен) смогли наблюдать у себя планы с примерно такими «русскими» названиями таблиц и индексов:

Дорабатываем велосипед
Беда-беда… Придется все таки делать нарезку самостоятельно, но уже с оптимизациями типа
Buffer.indexOf() вместо «побайтного» сканирования:
Вроде все хорошо, в тестовом контуре нагрузка не выросла, win1251-названия починились, выкатываем на бой… Та-дам! CPU usage периодически пробивает потолок в 100%:

Как же так?.. Оказывается, во всем виноват
Buffer.concat, которым мы «подклеиваем хвост», оставшийся от предыдущего блока:
Но ведь у нас склейка идет только при переходе строки через блок, а их не должно быть много — правда-правда?.. Ну, почти. Только вот иногда приходят «строки» из нескольких сотен 16KB-сегментов:

Спасибо коллегам-разработчикам, которые позаботились такое сгенерировать. Случается оно «редко, но метко», поэтому увидеть заранее в тестовом контуре не удалось.
Понятно, что подклейка несколько сотен раз к буферу на несколько мегабайт мелких кусочков — прямой путь в бездну переаллокаций памяти с выеданием ресурсов CPU, что мы и пронаблюдали. Так а давайте просто не будем клеить, пока строка не кончилась совсем. Просто будем складывать «кусочки» в массив, пока не настанет пора отдать всю строку «наружу»:

Теперь нагрузка снова вернулась к показателям, которые давал readline.
Потребление памяти
Многие, кто писал на языках с динамическим выделением памяти, в курсе, что одна из наиболее неприятных «убийц производительности» — это фоновая активность «сборщика мусора» (Garbage Collector, GC), который сканирует созданные в памяти объекты и удаляет те, которые больше никому не требуются. Настигла эта неприятность и нас — в какой-то момент мы начали замечать, что активности GC как-то слишком уж много, и не к месту.

Традиционные «крутилки» не особо помогали… «Если ничего не помогает — сделай дамп!» И народная мудрость не подвела — мы увидели тучу Buffer по 8360 байт общим размером на 520MB…

Причем порождены они внутри CopyBinaryStream — ситуация начала проясняться…
COPY… FROM STDIN WITH BINARY
Чтобы уменьшить объем передаваемого на БД трафика, мы используем бинарный формат COPY. Фактически, для каждой записи нужно в поток отправить буфер, состоящий из «кусочков» — количества полей в записи (2 байта) и дальше бинарного представления значения каждого из столбцов (4 байта на ID типа + данные).
Поскольку «суммарно» такая строка таблицы почти всегда имеет переменную длину, то сразу выделять буфер фиксированной длины — не вариант, переаллокации при нехватке размера легко «доедят» производительность, уже прошли выше. Значит, тоже стоит «клеить из кусочков» с помощью
Buffer.concat().memo
Ну а раз у нас многие кусочки повторяются снова и снова (например, количество полей в записях одной и той же таблицы) — давайте будем просто их запоминать, а потом брать уже готовые, сгенерированные однократно при первом обращении. Исходя из COPY-формата вариантов достаточно немного — типовые кусочки бывают по 1, 2 или 4 байта:

И… бам, прилетели грабли!

То есть да, каждый раз при создании Buffer по-умолчанию выделяется кусок памяти 8KB, чтобы создаваемые подряд небольшие буферы можно было складывать «рядом» в уже выделенной памяти. А наше выделение срабатывало «по требованию», и оказывалось совсем не «рядом» — поэтому каждый наш буфер на 1-2-4 байта физически занимал 8KB + заголовок — вот они, наши 520MB!
smart memo
Хм… А зачем нам вообще ждать, пока потребуется тот или иной 1/2-байтовый буфер? С 4-байтовыми тема отдельная, но этих-то разных возможных вариантов всего 256 + 65536. Так давайте нагенерим их подряд все сразу! Заодно и условие существования из каждой проверки спилим — еще и работать станет быстрее, поскольку инициализация проводится только при старте процесса.

То есть кроме 1/2-байтовых буферов сразу инициализируем и самые ходовые значения (нижние 2 байта и -1) для 4-байтовых. И — это помогло, всего 10MB вместо 520MB!

