
Это скорее не статья, а небольшая заметка о некоторых особенностях работы с большими таблицами в MySQL.
Причиной написания стало вроде бы будничное добавление новой колонки в таблицу. Но все оказалось не так просто, как предполагалось.
Итак, как-то вечерком, дабы не тревожить наших дорогих заказчиков, понадобилось нам добавить колонку в таблицу.
Чтобы было понятнее, характеристики таблицы и базы:
- размер таблицы 110Gb
- число строк: 7.5 млн
- storage engine: InnoDB
- есть два sql-сервера, соединенных по схеме master-slave, при этом master — на SSD, а slave — на HDD
Вроде бы очевидное решение для добавления колонки — Alter Table.
alter table table_name add source varchar(32)Им мы и воспользовались (да, мы понимали, что это плохо, но в данном конкретном случае риски были минимальны).
Результаты оказались довольно неприятными:
- на мастере процесс добавления колонки шел около часа (!)
- на слейве он начался после окончания процесса на мастере и продолжался около 8 часов (!!)
- во время выполнения alter table на слейве полностью остановилась репликация данных (!!!)
Но нет худа без добра: небольшой бонус оказался в том, что после добавления колонки размер таблицы уменьшился на 10%.
На графиках ниже это наглядно видно.
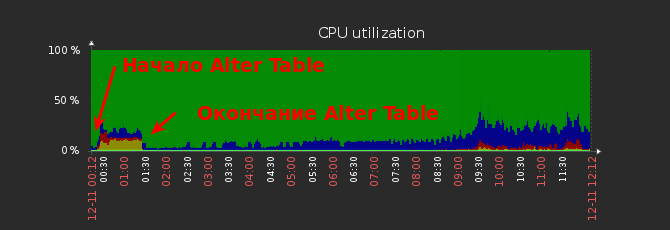
График загрузки CPU на мастере.

График загрузки CPU на слейве.

Отставание репликации.
Какие неприятности ждут тех, кто делает это на боевых таблицах?
Во-первых, на время выполнения Alter Table нельзя писать данные в таблицу (но можно читать). На самом деле это зависит от версии MySQL, в последних это не так, но тем не менее надо понимать, на что способна именно Ваша версия, дабы избежать неприятностей.
Соответственно, если таблица большая, то время недоступности будет значительным (как у нас, при использовании SSD это заняло час, а на обычном диске — 8 часов), что вряд ли ожидают Ваши заказчики.
Во-вторых, как в нашем случае, на время выполнения Alter Table на слейве полностью остановилась синхронизация всех таблиц, а не только той, которую мы изменяли. Поэтому в случае, если у Вас данные на втором сервере критичны и должны быть свежими — Вы рискуете остаться без обновлений со всеми вытекающими последствиями.
Еще один неочевидный момент, с которым мы столкнулись во время добавления колонки (но это было в другой раз) — на диске нужно дополнительное место.
Дело в том, что некоторые изменения таблиц пересоздают таблицу с нуля, поэтому места нужно не меньше, чем уже существующая таблица. Для больших таблиц, соответственно, места нужно, мягко говоря, немало. Согласно документации, временная таблица создается в том же каталоге, что и оригинальная.
Кроме того, во время выполнения всяких Alter Table все изменения записываются в лог-файл, чтобы после изменений накатить данные за то время, в течение которого проводилась операция. И тут тоже может ждать неприятный сюрприз: если таблица изменяется долго, а объем операций большой, то может закончится не только место на диске, но и превыситься лимит на размер файла, указанный в настройках SQL. В любом случае Вас ожидает «the online DDL operation fails, and uncommitted concurrent DML operations are rolled back».
Мы столкнулись с тем, что каталог для временных файлов был маловат, в результате пришлось переопределить innodb_tmpdir.
Посмотреть, куда указывает переменная в данный момент, можно так:
select @@GLOBAL.innodb_tmpdir;Имейте ввиду, что размер временного каталога также может быть нужен размером с таблицу + индексы. В общем, запасайтесь местом.
Дабы не повторять документацию, более детально читайте по ссылке https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-space-requirements.html
А как же делать надо? На самом деле нет единого рецепта на все случаи жизни.
Один из возможных вариантов, как делаем мы для таблиц, которые не критичны на обновление:
- Создаем новую таблицу с нужной структурой
- Заполняем поля из старой таблицы
- Удаляем или переименовываем старую таблицу
- Переименовываем новую
Повторюсь, что это работает для не критичных к обновлению таблиц. И при этом позволяет избежать блокировки репликации. При этом надо учитывать, что заполнение новой таблицы надо делать так, чтобы давать возможность продолжать репликацию, а поскольку она проходит последовательно, то нельзя обойтись одним sql-выражением, надо разбивать на несколько маленьких запросов, между выполнениями которых будет проходить репликация других данных. В других случаях возможны другие варианты, может быть кто-нибудь поделится в комментариях.
UPD. Пользователь syavadee посоветовал использовать percona online schema change. По сути она реализует описанный выше алгоритм с дополнительными плюшками.
UPD. Пользователь arheops рекомендует включить parallel replication/gtid для решения проблем с репликацией.
Ну и попутно, иногда, чтобы понять, насколько большая таблица и сколько в ней строк, нужно, как учат, сделать
select count(*) from table_nameНо на больших и нагруженных таблицах это тоже не самая быстрая операция, особенно когда у вас с пол миллиона строк и больше.
Поэтому для примерной оценки объема можно воспользоваться следующим способом:
SHOW TABLE STATUS FROM express where name='table_name'К сожалению, на движке InnoDB полученный размер может отличаться процентов на 50 (в нашем случае с таблицей выше реальное число записей порядка 7.5 млн, а указанный способ показал только 5 млн), но для ориентировочной оценки это вполне подходит.
На этом все, надеюсь, заметка кому-то поможет избежать больших неприятностей с якобы безобидными командами SQL.
