
Проблемы в производственной среде — это всегда беда. Происходят именно тогда, когда уходишь домой, а причина всегда кажется глупой. Недавно у нас на узлах в кластере Kubernetes закончилась память, правда узел тут же восстановился, без видимых прерываний. Сегодня мы расскажем об этом случае, о том, какой урон мы понесли и как намерены избегать подобной проблемы в будущем.
Случай первый
Суббота, 15 июня 2019 г., 17:12
Blue Matador (да, мы мониторим сами себя!) создает оповещение: событие на одном из узлов в продакшен-кластере Kubernetes — SystemOOM.
17:16
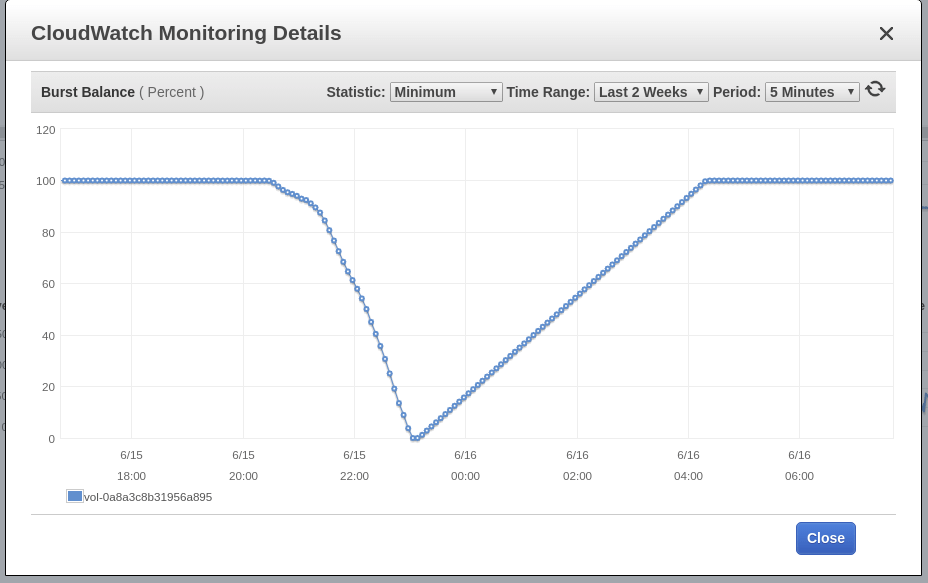
Blue Matador создает предупреждение: низкий уровень EBS Burst Balance в корневом томе узла — того, где имело место событие SystemOOM. И хотя предупреждение о Burst Balance пришло после оповещения о SystemOOM, фактические данные CloudWatch показывают, что Burst Balance достиг минимального уровня в 17:02. Причина задержки в том, что метрики EBS постоянно отстают на 10-15 минут, и наша система не отлавливает все события в режиме реального времени.
17:18
Вот сейчас я и увидел оповещение и предупреждение. Быстро выполняю kubectl get pods, чтобы посмотреть, какой ущерб мы понесли, и с удивлением обнаруживаю, что pod'ов в приложении умерло ровно 0. Выполняю kubectl top nodes, но и эта проверка показывает, что у подозреваемого узла неполадки с памятью; правда, он уже восстановился и памяти использует примерно 60%. Время 5 вечера, и крафтовый пивасик уже греется. Убедившись, что узел работоспособен и ни один pod не пострадал, я решил, что произошла случайность. Если что, разберусь в понедельник.
Вот наша с СТО переписка в Slack за тот вечер:

Случай второй
Суббота, 16 июня 2019 г., 18:02
Blue Matador генерирует оповещение: событие уже на другом узле, тоже SystemOOM. Должно быть, СТО в этот момент как раз смотрел в экран смартфона, потому что написал мне и заставил немедленно заняться событием, сам-де не может включить компьютер (не пора ли снова переустановить Windows?). И снова с виду все нормально. Ни один pod не убит, а узел едва ли потребляет 70% памяти.
18:06
Blue Matador снова генерирует предупреждение: EBS Burst Balance. Второй раз за сутки, а значит, на тормозах я эту проблему спустить не могу. В CloudWatch без изменений, Burst Balance отклонился от нормы за 2 с лишним часа до того, как обозначилась проблема.
18:11
Захожу в Datalog и просматриваю данные по потреблению памяти. Вижу, что прямо перед самым событием SystemOOM, подозреваемый узел и правда забрал много памяти. След ведет к нашим fluentd-sumologic pod'ам.

Ясно видно резко отклонение в потреблении памяти, примерно в то же время, когда случились события SystemOOM. Мой вывод: именно эти pоd'ы и забирали всю память, а когда случилось SystemOOM, Kubernetes понял, что эти pod'ы можно убить и запустить заново, чтобы вернуть нужную память, не затронув другие мои pod'ы. Какой ты молодец, Kubernetes!
Так почему я не увидел этого еще в субботу, когда разбирался, какие pod'ы перезапустились? Дело в том, что fluentd-sumologic pod'ы я запускаю в отдельном неймспейсе и в спешке просто не додумался в него заглянуть.
Вывод 1: Когда ищете перезапустившиеся pod'ы, проверяйте все неймспейсы.
Получив эти данные, я подсчитал, что в ближайшие сутки память на других узлах не закончится, однако пошел дальше и перезапустил все sumologic pod'ы, чтобы они начали работать с низким потреблением памяти. Следующим утром на скорую руку планирую, как бы встроить работу над проблемой в план на неделю и при этом не слишком загрузить воскресный вечер.
23:00
Посмотрел очередную серию "Черного зеркала" (мне, кстати, понравилась Майли) и решил глянуть, как там дела у кластера. Потребление памяти в норме, так что смело оставляю все как есть на ночь.
Починка
В понедельник выкроил время на эту проблему. Уж больно не охота возиться с ней каждый вечер. Что мне известно на данный момент:
- Fluentd-sumologic контейнеры сожрали уйму памяти;
- Событию SystemOOM предшествует высокая дисковая активность, но какая именно — не знаю.
Сперва я думал, что fluentd-sumologic контейнеры принимаются кушать память при внезапном наплыве логов. Однако, проверив Sumologic, я увидел, что логи использовались стабильно, и в то же время, когда возникали неполадки, увеличения в данных логов не происходило.
Немного погуглив, я нашел вот эту задачу на github, в которой предлагется скорректировать некоторые настройки Ruby — чтобы снизить потребление памяти. Я решил попробовать, добавил переменную среды в спецификации pod'а и запустил его:
env:
- name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR
value: "0.9"Проглядывая манифест fluentd-sumologic, я заметил, что не определил запросы на ресурсы и ограничения. Начинаю подозревать, что фикс RUBY_GCP_HEAP сотворит какое-нибудь чудо, так что сейчас есть смысл задать ограничения потребления памяти. Даже если не устраню неполадки с памятью, то получится хотя бы ограничить ее потребление этим набором pod'ов. Используя kubectl top pods | grep fluentd-sumologic, я уже знаю, сколько ресурсов затребовать:
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "1024Mi"
cpu: "250m"Вывод 2: Задавайте ограничения по ресурсам, особенно для сторонних приложений.
Проверка исполнения
Спустя несколько дней подтверждаю, что вышеназванная метода работает. Потребление памяти было стабильным, и — никаких неполадок ни с одним компонентом Kubernetes, EC2 и EBS. Теперь ясно, как важно определять запросы на ресурсы и ограничения для всех запускаемых мною pod'ов, и вот что предстоит сделать: применить некое сочетание ограничений по ресурсам по умолчанию и квот на ресурсы.
Последняя неразгаданная тайна — EBS Burst Balance, который совпал с событием SystemOOM. Я знаю, что когда памяти мало, ОС использует область подкачки, чтобы не остаться совсем без памяти. Но я-то не вчера родился и в курсе, что Kubernetes даже не запустится на серверах, где активирован файл подкачки. Просто желая удостовериться, я залез на свои узлы через SSH — проверить, не активирован ли файл подкачки; я использовал как свободную память, так и ту, что в области подкачки. Файл не был активирован.
А раз подкачка не при делах, больше у меня зацепок относительно того, что вызвало рост потоков ввода-вывода, из-за чего на узле чуть не закончилась память, нет. Вообще, у меня есть догадка: сам fluentd-sumologic pod в это время писал уйму журнальных сообщений, возможно даже, журнальное сообщение, связанное с настройкой Ruby GC. Возможно также, есть другие источники Kubernetes или journald сообщений, которые становятся не в меру продуктивны, когда память заканчивается, а я их отсеял, пока настраивал fluentd. К несчастью, у меня больше нет доступа к файлам логов, записанных непосредственно перед тем, как случилась неисправность, и сейчас никак не копнуть глубже.
Вывод 3: Пока возможность есть, копайте глубже при анализе первопричин, какой бы проблемой ни занимались.
Заключение
И хотя я не докопался до первопричин, уверен, они не нужны, чтобы предотвратить те же неисправности в будущем. Время — деньги, а я и так слишком долго возился, а после еще писал для вас этот пост. И раз уж мы используем Blue Matador, подобные неисправности у нас разбираются очень подробно, поэтому я позволяю себе спускать кое-что на тормозах, не отвлекаясь от основного проекта.
