Всем привет. Этот пост о том, как спонтанный эксперимент и несколько часов, проведенных в серверной, помогли получить интересные результаты по производительности решения ViPNet Custom 4.3 в версии для Windows.

Вам уже интересно? Тогда загляните под кат.
1. Вводная
Изначально данное тестирование было просто внутренним собственным экспериментом. Но так как, на наш взгляд результаты получились достаточно интересными, мы решили опубликовать, полученные данные.
Что такое ПО ViPNet Custom? Если кратко, то это комплекс межсетевого экранирования и шифрования, разработанный компанией «ИнфоТеКС» в соответствии с требованиями ФСБ и ФСТЭК России.
На момент тестирования решения отсутствовали какие-либо данные о замерах производительности программного варианта ViPNet Custom на различных конфигурациях. Интересно было сравнить результаты программной реализации ViPNet Custom с аппаратной реализацией ViPNet Coordinator HW1000/HW2000, производительность которых известна и задокументирована вендором.
2. Описание первоначального стенда
Согласно данным с сайта infotecs.ru ОАО «ИнфоТеКС» наиболее мощные конфигурации платформ HW имеют следующие характеристики:
К сожалению, каких-либо дополнительных сведений об условиях тестирования предоставлено не было.
Первоначально мы получили доступ к оборудованию со следующими характеристиками:
1) IBM system x3550 M4 2 x E5-2960v2 10 core 64 GB RAM;
2) Fujitsu TX140 S1 E3-1230v2 4 core 16GB RAM.
Использование сервера Fujitsu в эксперименте было поставлено под сомнение… Желанию сразу штурмовать 10GbE помешало отсутствие сети на оборудовании, поэтому мы решили оставить его, как начальную отправную точку.
На IBM мы организовали 2 виртуальных сервера с виртуальным 10-гигабитным свитчем на базе платформы ESX 6.0u1b и после оценили общую производительность двух виртуальных машин.
Описание стенда:
1. Сервер IBM system x3550 M4 2 x E5-2960v2 10 core 64 GB RAM, ESXi 6.0u1.
Для каждой виртуальной машины (VM) выделен один физический процессор с 10 ядрами.
VM1: Windows 2012 R2 (VipNet Coordinator 4.3_(1.33043) ):
• 1 CPU 10 core;
• 8GB RAM.
VM2: Windows 8.1 (ViPNet Client 4.3_(1.33043) ):
• 1 CPU 10 core;
• 8GB RAM.
VM подключены к виртуальному коммутатору 10Gbps, установлен MTU 9000.
2. Сервер Fujitsu TX140 S1 E3-1230v2 4 core 16Gb RAM, Windows 2012 R2, ViPNet Client 4.3_(1.33043).
Физические серверы IBM и Fujitsu соединены гигабитной сетью с MTU 9000. Hyper Threading отключен на обоих серверах. В качестве нагрузочного ПО использовался Iperf3.
Схема стенда представлена на рисунке 1.
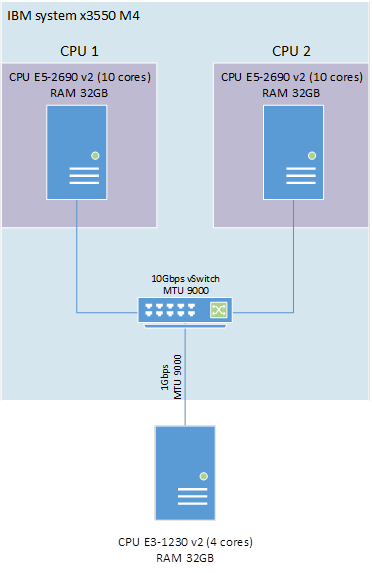
Рисунок 1 — Схема организации стенда тестирования
3. Первый этап тестирования
К сожалению, подготовка этой статьи началась уже после проведения всех тестов, поэтому для данного раздела скриншоты результатов, кроме финального, не сохранились.
3.1. Тест №1
Сначала оценим, сможем ли мы обеспечить пропускную способность сети 1 Gb/s. Для этого нагрузим виртуальный координатор VM1 Windows 2012 R2 (ViPNet Coordinator 4.3) и физический сервер Fujitsu TX140 S1.
На стороне VM1 Iperf3 запущен в режиме сервера.
На стороне сервера Fujitsu Iperf3 запущен с параметрами
Iperf.exe –c IP_сервера –P4 –t 100,
где параметр –P4 указывает количество потоков на сервере, равное количеству ядер.
Тест проводился три раза. Результаты приведены в таблице 1.
Таблица 1. Результат теста №1
По результатам сделаны следующие выводы:
1) процессор E3-1230v2 в задаче шифрования может обеспечить пропускную способность сети 1Gb/s;
2) виртуальный координатор загружен менее чем на 25%;
3) при аналогичном процессоре, официальная производительность ViPNet Coordinator HW1000 превышена практически в 4 раза.
Если исходить из полученных данных, то видно, что сервер Fujitsu TX140 S1 достиг своей максимальной производительности. Поэтому дальнейшее тестирование будем проводить только с виртуальными машинами.
3.2. Тест №2
Вот и пришло время больших скоростей. Протестируем виртуальный координатор VM1 Windows 2012 R2 (ViPNet Coordinator 4.3) и VM2 Windows 8.1 (ViPNet Client 4.3).
На стороне VM1 Iperf3 запущен в режиме сервера.
На стороне сервера VM2 Iperf3 запущен с параметрами
Iperf.exe –c IP_сервера –P10 –t 100,
где параметр –P10 указывает количество потоков на сервере, равное количеству ядер.
Тест проводился три раза. Результаты приведены в таблице 2
Таблица 2. Результат теста №2
Как видно, результаты не сильно отличаются от предыдущих. Тест был выполнен ещё несколько раз со следующими изменениями:
• серверная часть iperf перенесена на VM2;
• заменена гостевая ОС на VM2 на Windows Server 2012 R2 с ViPNet Coordinator 4.3;
Во всех протестированных комбинациях результаты оставались одинаковыми в рамках погрешности.
Появилось понимание, что, вероятнее всего, имеется встроенное ограничение в самом ПО ViPNet.
После нескольких вариантов тестирования, выяснилось, что при запуске Iperf3 с параметрами
Iperf.exe –c IP_сервера –P4 –t 100
пропускная способность стала практически аналогичной, достигнутой ранее, на сервере Fujitsu.
При этом максимально загруженными стали 4 ядра процессора – ровно 25% от его мощности.
Полученные результаты окончательно убедили в том, что ограничение присутствует. Результаты направлены производителю с запросом вариантов решения проблемы.
4. Продолжение эксперимента
В скором времени был получен ответ от производителя:
«Количеством процессоров можно управлять значением ключа HKLM\System\CurrentControlSet\Control\Infotecs\Iplir, в нем значение ThreadCount. Если значение -1 или не задано, то количество потоков выбирается равным количеству процессоров, но не более 4. Если установлено какое-то значение, то выбирается количество потоков, равное этому значению».
Что ж, догадка была верна. Настроим стенд на максимальную производительность, установив значение параметра ThreadCount равное 10 на обеих виртуальных машинах.
4.1. Тест №3
После внесения всех необходимых изменений снова запускаем Iperf.
На стороне VM1 Iperf3 запущен в режиме сервера. На стороне сервера VM2 Iperf3 запущен с параметрами
Iperf.exe –c IP_сервера –P10 –t 100,
где параметр –P10 указывает количество потоков на сервере, равное количеству ядер.
Тест проводился три раза. Результаты приведены в таблице 3 и рисунках 2-3
Таблица 3. Результат теста №3
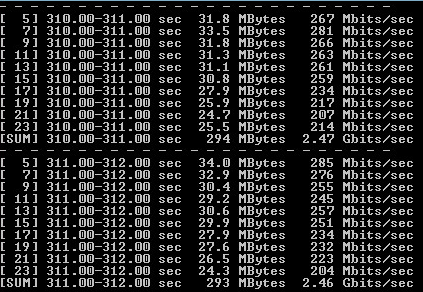
Рисунок 2 — Вывод iPerf3 на VM1 Windows 2012 R2 (ViPNet Coordinator 4.3)
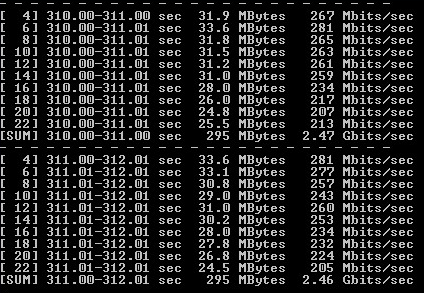
Рисунок 3 — Вывод iPerf3 на VM2 Windows 8.1 (ViPNet Client 4.3)
По результатам сделаны следующие выводы:
1) внесенные изменения позволили достигнуть максимальной производительности шифрования при полной утилизации процессора;
2) суммарную производительность при использовании двух Xeon E5-2960v2 можно считать равной 5 Gbps;
3) при учете общей производительности двух процессоров полученная производительность шифрования в 2 раза перекрывает официальные результаты ViPNet Coordinator HW2000.
Полученные результаты только подогревали интерес, что можно получить ещё больше. К счастью, получилось получить доступ к более мощному оборудованию.
Так же стоит отметить, что в ходе тестирования не было обнаружено разницы в пропускной способности между ViPNet Client и ViPNet Coordinator.
5. Второй этап тестирования
Для дальнейших изысканий в вопросе производительности программной части ПО ViPNet, мы получили доступ к двум отдельным блейд-серверам со следующими характеристиками:
• CPU 2 x E5-2690v2 10 core;
• ESXi 6.0u1.
Каждая виртуальная машина расположена на своем отдельном «лезвии».
VM1: Windows 2012 R2 (ViPNet Client 4.3_(1.33043) ):
• 2 CPU 20 core;
• 32 GB RAM.
VM2: Windows 2012 R2 (ViPNet Client 4.3_(1.33043) ):
• 2 CPU 20 core;
• 32 GB RAM.
Сетевое соединение между виртуальными машинами осуществляется через интреконнект блейд-сервера с пропускной способностью 10 Gbps с MTU 9000. Hyper Threading отключен на обоих серверах.
Для имитации нагрузки использовалось программное обеспечение iPerf3 и, дополнительно, Ntttcp со следующими основными параметрами:
1) на принимающей стороне:
Iperf.exe –s;
на передающей стороне:
Iperf.exe –cserver_ip –P20 –t100;
2) на принимающей стороне:
NTttcp.exe -r -wu 5 -cd 5 -m 20,*,self_ip -l 64k -t 60 -sb 128k -rb 128k;
на передающей стороне:
NTttcp.exe -s -wu 5 -cd 5 -m 20,*,server_ip -l 64k -t 60 -sb 128k -rb 128k.
Схема организации стенда представлена на рисунке 4.
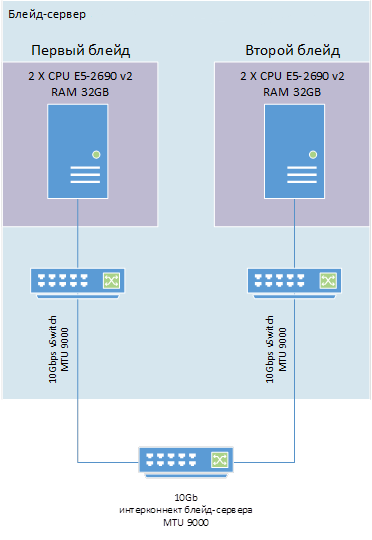
Рисунок 4 — Схема организации стенда тестирования
5.1. Тест №4
Для начала проведем проверку пропускной способности сети без шифрования. ПО ViPNet не установлено.
Тест проводился три раза. Результаты приведены в таблице 4 и рисунках 5-6.
Таблица 4. Результат теста №4
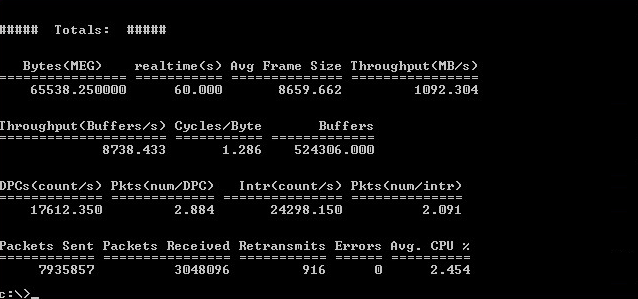
Рисунок 5 — Результат тестирования Ntttcp без шифрования
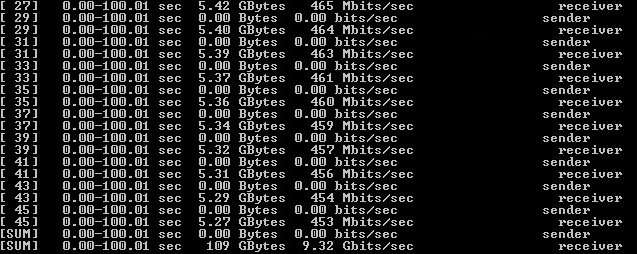
Рисунок 6 — Результат тестирования Iperf без шифрования
По результатам были сделаны следующие выводы:
1) была достигнута пропускная способность сети в 10 Gbps;
2) имеется разница в результатах ПО для тестирования. Далее для достоверности результаты будут публиковаться как для Iperf, так и для Ntttcp.
5.2. Тест №5
Установим значение параметра ThreadCount равное 20 на обоих виртуальных машинах и замерим результаты.
Тест проводился три раза. Результаты приведены в таблице 5 и рисунках 7-8.
Таблица 5 – Результат теста №5
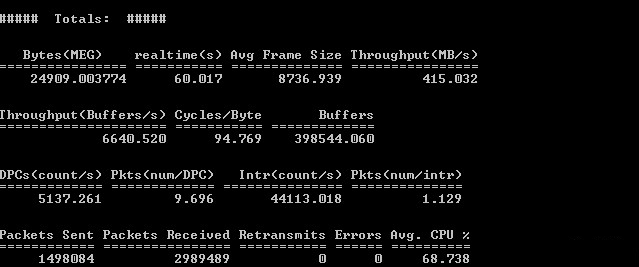
Рисунок 7 — Результат тестирования Ntttcp с шифрованием
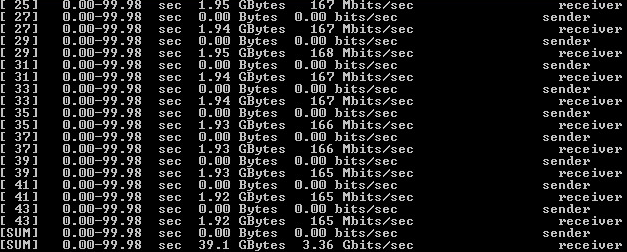
Рисунок 8 — Результат тестирования Iperf с шифрованием
По результатам были сделаны следующие выводы:
1) на единичном сервере была превышена теоретическая производительность ViPNet Coordinator HW2000;
2) не была достигнута теоретическая производительность в 5 Gbps;
3) загрузка CPU не достигла 100%;
4) сохраняется разница в результатах ПО для тестирования, но, на данный момент, она минимальна.
Исходя из того, что процессоры не серверах не были полностью утилизированы, обратим внимание на ограничение со стороны драйвера ViPNet на одновременное количество потоков шифрования.
Для проверки ограничения посмотрим загрузку одного ядра процессора при операции шифрования.
Тест №6
В данном тесте будем использовать только Iperf, так как, по результатам предыдущих тестов, он дает большую нагрузку процессор, с параметрами
Iperf.exe –cIP_server –P1 –t100.
На каждом сервере через реестр ограничим ViPNet на использование одного ядра при операции шифрования.
Тест проводился три раза. Результаты приведены на рисунках 9-10.

Рисунок 9 — Утилизация одного ядра при операции шифрования
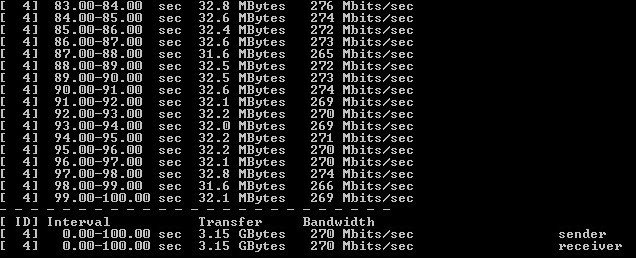
Рисунок 10 — Результат тестирования Iperf с шифрованием при загрузке одного ядра
По результатам были сделаны следующие выводы:
1) единичное ядро было загружено на 100%;
2) исходя из загрузки одного ядра, 20 ядер должны давать теоретическую производительность в 5.25 Gbps;
3) исходя из загрузки одного ядра, ПО ViPNet имеет ограничение в 14 ядер.
Для проверки ограничений на ядра проведем ещё один тест с задействованными 14 ядрами на процессоре.
Тест №7
Тестирование с шифрованием с 14 ядрами.
В данном тесте будем использовать только Iperf с параметрами
Iperf.exe –cIP_server –P12 –t100.
На каждом сервере через реестр ограничим ViPNet на использование не более 14 ядер при операции шифрования.
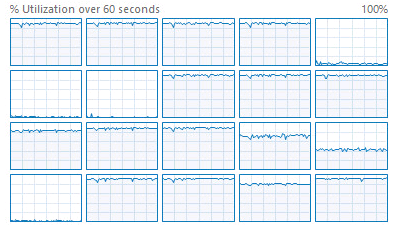
Рисунок 11 — Утилизация 14 ядер при операции шифрования
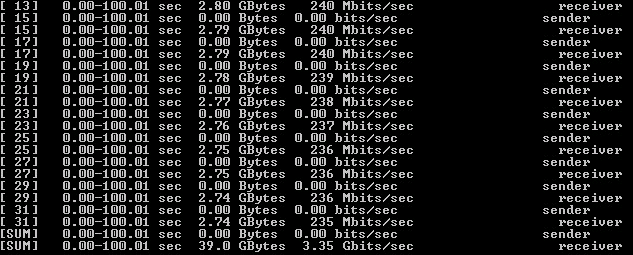
Рисунок 12 — Результат тестирования Iperf с шифрованием при загрузке 14 ядер
По результату сделаны выводы:
1) были загружены все 14 ядер;
2) производительность аналогична варианту с 20 ядрами;
3) имеется лимит в 14 ядер при многопоточной операции шифрования.
Результаты тестов были направлены производителю с запросом вариантов решения проблемы.
6. Заключение
Через некоторое время был получен ответ производителя:
«Использование более четырех ядер на координаторе Windows является недокументированной возможностью, и ее правильная работа не проверяется и не гарантируется».
Думаю, на этом тестирование можно закончить.
Почему же программный вариант довольно сильно вырвался вперед в результатах тестирования?
Скорее всего причин несколько:
1) Старые результаты тестирования. На новых прошивках, по неофициальным данным, производительность HW сильно подросла;
2) Недокументированные условия тестирования.
3) Не стоит забывать, что для получения максимального результата использовалась недокументированная возможность.
Остались вопросы? Задавайте их в комментариях.
Андрей Куртасанов, Softline

Вам уже интересно? Тогда загляните под кат.
1. Вводная
Изначально данное тестирование было просто внутренним собственным экспериментом. Но так как, на наш взгляд результаты получились достаточно интересными, мы решили опубликовать, полученные данные.
Что такое ПО ViPNet Custom? Если кратко, то это комплекс межсетевого экранирования и шифрования, разработанный компанией «ИнфоТеКС» в соответствии с требованиями ФСБ и ФСТЭК России.
На момент тестирования решения отсутствовали какие-либо данные о замерах производительности программного варианта ViPNet Custom на различных конфигурациях. Интересно было сравнить результаты программной реализации ViPNet Custom с аппаратной реализацией ViPNet Coordinator HW1000/HW2000, производительность которых известна и задокументирована вендором.
2. Описание первоначального стенда
Согласно данным с сайта infotecs.ru ОАО «ИнфоТеКС» наиболее мощные конфигурации платформ HW имеют следующие характеристики:
| Тип | Платформа | Процессор | Пропускная способность |
|---|---|---|---|
| HW1000 Q2 | AquaServer T40 S44 | Intel Core i5-750 | До 280 Mb/s |
| HW2000 Q3 | AquaServer T50 D14 | Intel Xeon E5-2620 v2 | До 2.7 Gb/s |
К сожалению, каких-либо дополнительных сведений об условиях тестирования предоставлено не было.
Первоначально мы получили доступ к оборудованию со следующими характеристиками:
1) IBM system x3550 M4 2 x E5-2960v2 10 core 64 GB RAM;
2) Fujitsu TX140 S1 E3-1230v2 4 core 16GB RAM.
Использование сервера Fujitsu в эксперименте было поставлено под сомнение… Желанию сразу штурмовать 10GbE помешало отсутствие сети на оборудовании, поэтому мы решили оставить его, как начальную отправную точку.
На IBM мы организовали 2 виртуальных сервера с виртуальным 10-гигабитным свитчем на базе платформы ESX 6.0u1b и после оценили общую производительность двух виртуальных машин.
Описание стенда:
1. Сервер IBM system x3550 M4 2 x E5-2960v2 10 core 64 GB RAM, ESXi 6.0u1.
Для каждой виртуальной машины (VM) выделен один физический процессор с 10 ядрами.
VM1: Windows 2012 R2 (VipNet Coordinator 4.3_(1.33043) ):
• 1 CPU 10 core;
• 8GB RAM.
VM2: Windows 8.1 (ViPNet Client 4.3_(1.33043) ):
• 1 CPU 10 core;
• 8GB RAM.
VM подключены к виртуальному коммутатору 10Gbps, установлен MTU 9000.
2. Сервер Fujitsu TX140 S1 E3-1230v2 4 core 16Gb RAM, Windows 2012 R2, ViPNet Client 4.3_(1.33043).
Физические серверы IBM и Fujitsu соединены гигабитной сетью с MTU 9000. Hyper Threading отключен на обоих серверах. В качестве нагрузочного ПО использовался Iperf3.
Схема стенда представлена на рисунке 1.
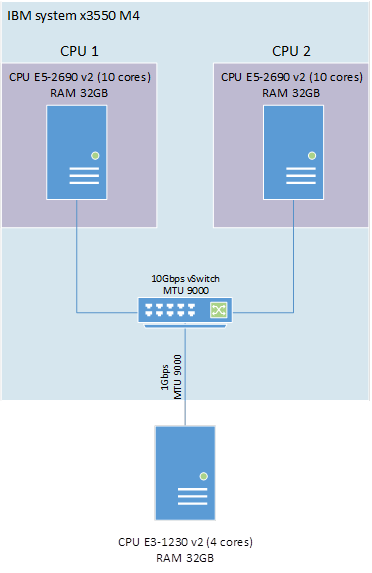
Рисунок 1 — Схема организации стенда тестирования
3. Первый этап тестирования
К сожалению, подготовка этой статьи началась уже после проведения всех тестов, поэтому для данного раздела скриншоты результатов, кроме финального, не сохранились.
3.1. Тест №1
Сначала оценим, сможем ли мы обеспечить пропускную способность сети 1 Gb/s. Для этого нагрузим виртуальный координатор VM1 Windows 2012 R2 (ViPNet Coordinator 4.3) и физический сервер Fujitsu TX140 S1.
На стороне VM1 Iperf3 запущен в режиме сервера.
На стороне сервера Fujitsu Iperf3 запущен с параметрами
Iperf.exe –c IP_сервера –P4 –t 100,
где параметр –P4 указывает количество потоков на сервере, равное количеству ядер.
Тест проводился три раза. Результаты приведены в таблице 1.
Таблица 1. Результат теста №1
| Хост | Загрузка CPU | Достигнутая нагрузка | Канал |
|---|---|---|---|
| VM1 Windows 2012 R2 (ViPNet Coordinator 4.3) | <25% | 972 Mbps | 1Gbps |
| Fujitsu TX140 S1 | 100% | 972 Mbps | 1Gbps |
По результатам сделаны следующие выводы:
1) процессор E3-1230v2 в задаче шифрования может обеспечить пропускную способность сети 1Gb/s;
2) виртуальный координатор загружен менее чем на 25%;
3) при аналогичном процессоре, официальная производительность ViPNet Coordinator HW1000 превышена практически в 4 раза.
Если исходить из полученных данных, то видно, что сервер Fujitsu TX140 S1 достиг своей максимальной производительности. Поэтому дальнейшее тестирование будем проводить только с виртуальными машинами.
3.2. Тест №2
Вот и пришло время больших скоростей. Протестируем виртуальный координатор VM1 Windows 2012 R2 (ViPNet Coordinator 4.3) и VM2 Windows 8.1 (ViPNet Client 4.3).
На стороне VM1 Iperf3 запущен в режиме сервера.
На стороне сервера VM2 Iperf3 запущен с параметрами
Iperf.exe –c IP_сервера –P10 –t 100,
где параметр –P10 указывает количество потоков на сервере, равное количеству ядер.
Тест проводился три раза. Результаты приведены в таблице 2
Таблица 2. Результат теста №2
| Хост | Загрузка CPU | Достигнутая нагрузка | Канал |
|---|---|---|---|
| VM1 Windows 2012 R2 (ViPNet Coordinator 4.3) | 25-30% | 1.12 Gbps | 10 Gbps |
| VM2 Windows 8.1 (ViPNet Client 4.3) | 25-30% | 1.12 Gbps | 10 Gbps |
Как видно, результаты не сильно отличаются от предыдущих. Тест был выполнен ещё несколько раз со следующими изменениями:
• серверная часть iperf перенесена на VM2;
• заменена гостевая ОС на VM2 на Windows Server 2012 R2 с ViPNet Coordinator 4.3;
Во всех протестированных комбинациях результаты оставались одинаковыми в рамках погрешности.
Появилось понимание, что, вероятнее всего, имеется встроенное ограничение в самом ПО ViPNet.
После нескольких вариантов тестирования, выяснилось, что при запуске Iperf3 с параметрами
Iperf.exe –c IP_сервера –P4 –t 100
пропускная способность стала практически аналогичной, достигнутой ранее, на сервере Fujitsu.
При этом максимально загруженными стали 4 ядра процессора – ровно 25% от его мощности.
Полученные результаты окончательно убедили в том, что ограничение присутствует. Результаты направлены производителю с запросом вариантов решения проблемы.
4. Продолжение эксперимента
В скором времени был получен ответ от производителя:
«Количеством процессоров можно управлять значением ключа HKLM\System\CurrentControlSet\Control\Infotecs\Iplir, в нем значение ThreadCount. Если значение -1 или не задано, то количество потоков выбирается равным количеству процессоров, но не более 4. Если установлено какое-то значение, то выбирается количество потоков, равное этому значению».
Что ж, догадка была верна. Настроим стенд на максимальную производительность, установив значение параметра ThreadCount равное 10 на обеих виртуальных машинах.
4.1. Тест №3
После внесения всех необходимых изменений снова запускаем Iperf.
На стороне VM1 Iperf3 запущен в режиме сервера. На стороне сервера VM2 Iperf3 запущен с параметрами
Iperf.exe –c IP_сервера –P10 –t 100,
где параметр –P10 указывает количество потоков на сервере, равное количеству ядер.
Тест проводился три раза. Результаты приведены в таблице 3 и рисунках 2-3
Таблица 3. Результат теста №3
| Хост | Загрузка CPU | Достигнутая нагрузка | Канал |
|---|---|---|---|
| VM1 Windows 2012 R2 (ViPNet Coordinator 4.3) | 100% | 2,47 Gbps | 10 Gbps |
| VM2 Windows 8.1 (ViPNet Client 4.3) | 100% | 2,47 Gbps | 10 Gbps |
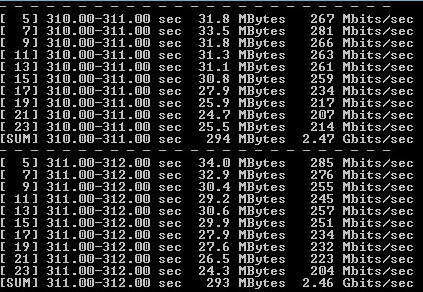
Рисунок 2 — Вывод iPerf3 на VM1 Windows 2012 R2 (ViPNet Coordinator 4.3)
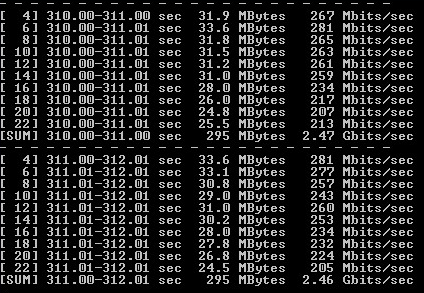
Рисунок 3 — Вывод iPerf3 на VM2 Windows 8.1 (ViPNet Client 4.3)
По результатам сделаны следующие выводы:
1) внесенные изменения позволили достигнуть максимальной производительности шифрования при полной утилизации процессора;
2) суммарную производительность при использовании двух Xeon E5-2960v2 можно считать равной 5 Gbps;
3) при учете общей производительности двух процессоров полученная производительность шифрования в 2 раза перекрывает официальные результаты ViPNet Coordinator HW2000.
Полученные результаты только подогревали интерес, что можно получить ещё больше. К счастью, получилось получить доступ к более мощному оборудованию.
Так же стоит отметить, что в ходе тестирования не было обнаружено разницы в пропускной способности между ViPNet Client и ViPNet Coordinator.
5. Второй этап тестирования
Для дальнейших изысканий в вопросе производительности программной части ПО ViPNet, мы получили доступ к двум отдельным блейд-серверам со следующими характеристиками:
• CPU 2 x E5-2690v2 10 core;
• ESXi 6.0u1.
Каждая виртуальная машина расположена на своем отдельном «лезвии».
VM1: Windows 2012 R2 (ViPNet Client 4.3_(1.33043) ):
• 2 CPU 20 core;
• 32 GB RAM.
VM2: Windows 2012 R2 (ViPNet Client 4.3_(1.33043) ):
• 2 CPU 20 core;
• 32 GB RAM.
Сетевое соединение между виртуальными машинами осуществляется через интреконнект блейд-сервера с пропускной способностью 10 Gbps с MTU 9000. Hyper Threading отключен на обоих серверах.
Для имитации нагрузки использовалось программное обеспечение iPerf3 и, дополнительно, Ntttcp со следующими основными параметрами:
1) на принимающей стороне:
Iperf.exe –s;
на передающей стороне:
Iperf.exe –cserver_ip –P20 –t100;
2) на принимающей стороне:
NTttcp.exe -r -wu 5 -cd 5 -m 20,*,self_ip -l 64k -t 60 -sb 128k -rb 128k;
на передающей стороне:
NTttcp.exe -s -wu 5 -cd 5 -m 20,*,server_ip -l 64k -t 60 -sb 128k -rb 128k.
Схема организации стенда представлена на рисунке 4.
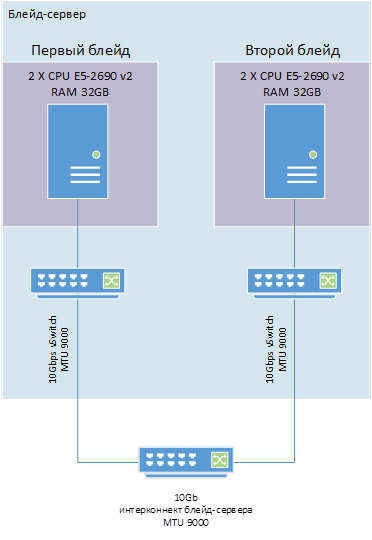
Рисунок 4 — Схема организации стенда тестирования
5.1. Тест №4
Для начала проведем проверку пропускной способности сети без шифрования. ПО ViPNet не установлено.
Тест проводился три раза. Результаты приведены в таблице 4 и рисунках 5-6.
Таблица 4. Результат теста №4
| Хост | Загрузка CPU | Достигнутая нагрузка | Канал |
|---|---|---|---|
| Ntttcp | 2,5% | 8,5 Gbps | 10 Gbps |
| Iperf | 4% | 9,3 Gbps | 10 Gbps |

Рисунок 5 — Результат тестирования Ntttcp без шифрования
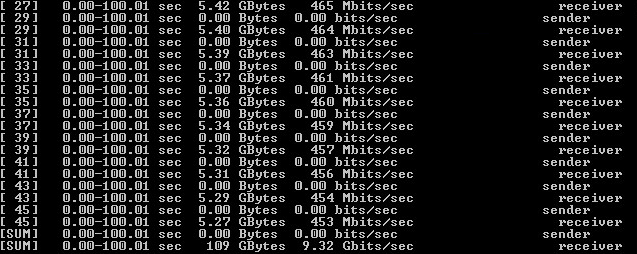
Рисунок 6 — Результат тестирования Iperf без шифрования
По результатам были сделаны следующие выводы:
1) была достигнута пропускная способность сети в 10 Gbps;
2) имеется разница в результатах ПО для тестирования. Далее для достоверности результаты будут публиковаться как для Iperf, так и для Ntttcp.
5.2. Тест №5
Установим значение параметра ThreadCount равное 20 на обоих виртуальных машинах и замерим результаты.
Тест проводился три раза. Результаты приведены в таблице 5 и рисунках 7-8.
Таблица 5 – Результат теста №5
| Хост | Загрузка CPU | Достигнутая нагрузка | Канал |
|---|---|---|---|
| Ntttcp | 74-76% | 3,24 Gbps | 10 Gbps |
| Iperf | 68-71% | 3,36 Gbps | 10 Gbps |
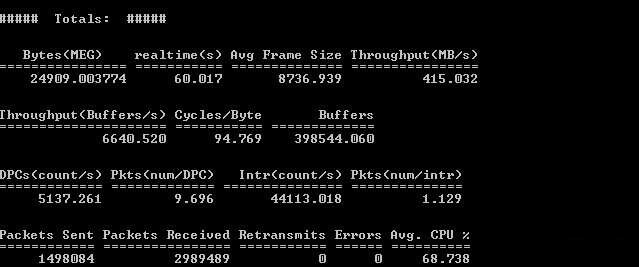
Рисунок 7 — Результат тестирования Ntttcp с шифрованием

Рисунок 8 — Результат тестирования Iperf с шифрованием
По результатам были сделаны следующие выводы:
1) на единичном сервере была превышена теоретическая производительность ViPNet Coordinator HW2000;
2) не была достигнута теоретическая производительность в 5 Gbps;
3) загрузка CPU не достигла 100%;
4) сохраняется разница в результатах ПО для тестирования, но, на данный момент, она минимальна.
Исходя из того, что процессоры не серверах не были полностью утилизированы, обратим внимание на ограничение со стороны драйвера ViPNet на одновременное количество потоков шифрования.
Для проверки ограничения посмотрим загрузку одного ядра процессора при операции шифрования.
Тест №6
В данном тесте будем использовать только Iperf, так как, по результатам предыдущих тестов, он дает большую нагрузку процессор, с параметрами
Iperf.exe –cIP_server –P1 –t100.
На каждом сервере через реестр ограничим ViPNet на использование одного ядра при операции шифрования.
Тест проводился три раза. Результаты приведены на рисунках 9-10.

Рисунок 9 — Утилизация одного ядра при операции шифрования
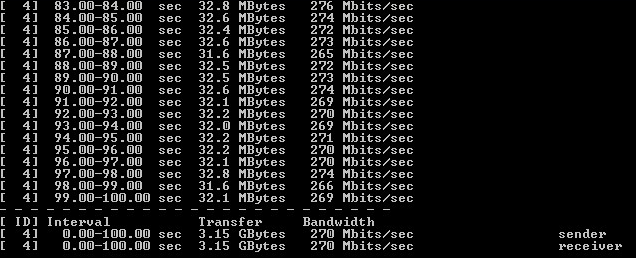
Рисунок 10 — Результат тестирования Iperf с шифрованием при загрузке одного ядра
По результатам были сделаны следующие выводы:
1) единичное ядро было загружено на 100%;
2) исходя из загрузки одного ядра, 20 ядер должны давать теоретическую производительность в 5.25 Gbps;
3) исходя из загрузки одного ядра, ПО ViPNet имеет ограничение в 14 ядер.
Для проверки ограничений на ядра проведем ещё один тест с задействованными 14 ядрами на процессоре.
Тест №7
Тестирование с шифрованием с 14 ядрами.
В данном тесте будем использовать только Iperf с параметрами
Iperf.exe –cIP_server –P12 –t100.
На каждом сервере через реестр ограничим ViPNet на использование не более 14 ядер при операции шифрования.
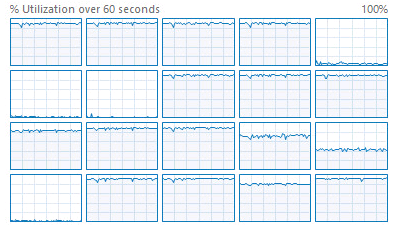
Рисунок 11 — Утилизация 14 ядер при операции шифрования
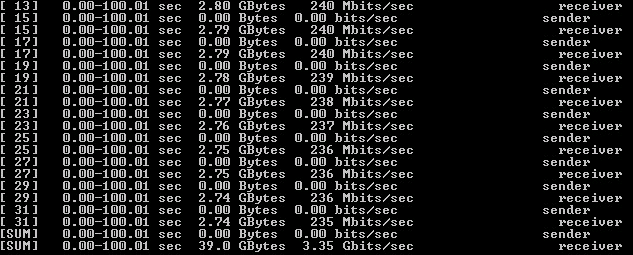
Рисунок 12 — Результат тестирования Iperf с шифрованием при загрузке 14 ядер
По результату сделаны выводы:
1) были загружены все 14 ядер;
2) производительность аналогична варианту с 20 ядрами;
3) имеется лимит в 14 ядер при многопоточной операции шифрования.
Результаты тестов были направлены производителю с запросом вариантов решения проблемы.
6. Заключение
Через некоторое время был получен ответ производителя:
«Использование более четырех ядер на координаторе Windows является недокументированной возможностью, и ее правильная работа не проверяется и не гарантируется».
Думаю, на этом тестирование можно закончить.
Почему же программный вариант довольно сильно вырвался вперед в результатах тестирования?
Скорее всего причин несколько:
1) Старые результаты тестирования. На новых прошивках, по неофициальным данным, производительность HW сильно подросла;
2) Недокументированные условия тестирования.
3) Не стоит забывать, что для получения максимального результата использовалась недокументированная возможность.
Остались вопросы? Задавайте их в комментариях.
Андрей Куртасанов, Softline
