Вы можете спросить: почему эти полумагические модели машинного обучения работают так хорошо? Короткий ответ: эти модели чрезвычайно сложны и обучаются на огромном количестве данных. На самом деле, Lambda Labs недавно подсчитала, что для обучения GPT-3 на одном GPU потребовалось бы 4,6 миллиона долларов — если бы такое было возможно.
Такие платформы, как PyTorch и Tensorflow, могут обучать эти огромные модели, потому что распределяют рабочую нагрузку по сотням (или тысячам) GPU одновременно. К сожалению, этим платформам требуется идентичность графических процессоров (они должны иметь одинаковую память и вычислительную производительность). Но многие организации не имеют тысячи одинаковых GPU. Малые и средние организации покупают разные компьютерные системы, что приводит к неоднородной инфраструктуре, которую нелегко адаптировать для вычисления больших моделей. В этих условиях обучение моделей даже среднего размера может занимать недели или даже месяцы. Если не принять меры, университеты и другие небольшие организации рискуют потерять конкурентоспособность в погоне за разработкой новых, лучших моделей машинного обучения. Но это можно исправить.
В этом посте представлена предыстория и практические шаги по обучению BERT с нуля в университете с использованием пакета HetSeq. Это адаптация популярного пакета PyTorch, которая предоставляет возможность обучать большие модели нейронных сетей на гетерогенной инфраструктуре.

Чтобы исправить эту ситуацию, мы недавно выпустили программный пакет под названием HetSeq — адаптацию популярного пакета PyTorch, которая предоставляет возможность обучать большие модели нейронных сетей на гетерогенной инфраструктуре.
Эксперименты показывают, что систему на базе BERT можно за день обучить с помощью более чем 8 GPU, большинство из которых нам пришлось «позаимствовать» в неработающих лабораториях. Прежде чем мы представим HetSeq, нужна небольшая предыстория.
Обучение на одном GPU
Этот код показывает этап обучения базовой модели контролируемого обучения на фреймворке нейронных сетей. Учитывая некоторую архитектуру, эта задача оптимизирует параметры модели через SGD на функции потерь между предсказанными экземплярами и наблюдаемой истиной.
Фактически процесс обучения состоит из четырёх отдельных этапов: (1) загрузка данных, (2) прямой проход, (3) обратный проход, (4) обновление.
При единственном GPU первые существующие параметры модели (которые изначально случайны) и данные передаются на графический процессор, и это первое, что происходит. Как правило, набор данных содержит большое количество обучающих экземпляров, которые не умещаются на одном графическом процессоре. В этом общем случае мы разделяем набор данных на несколько пакетов и загружаем их по одному.
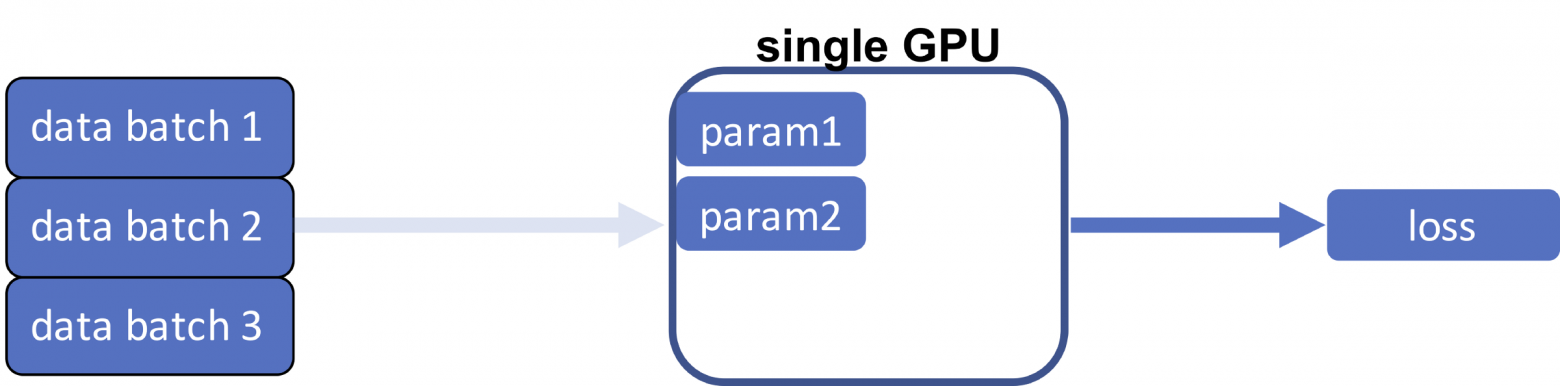
Прямой проход с одним GPU
Следующий шаг — вычисление функции потерь. Для этого пакет данных передаётся через модель (отсюда и название — «прямой проход») и сравнивается с метками обучения наблюдаемой истины. В блоке прямой проход состоит из двух этапов: генерации спрогнозированной метки (вывод) и измерения разницы (потери) между выводом и целью.
Вычисленная на предыдущем шаге потеря определяет, насколько нужно изменить параметры модели; это называется градиентом, который применяется к архитектуре нейронной сети в обратном направлении (отсюда название — обратный проход, или обратное распространение).

Параметры обновления с единственным GPU
Помните, что цель всего процесса — оптимизировать параметры модели так, чтобы при передаче данных по ним они минимизировали потери. Поэтому важно, чтобы параметры модели обновлялись в соответствии со значениями градиента.
В целом одна итерация загрузки данных, прямой проход одного экземпляра данных, затем обратный проход, а затем обновление параметра называются одним шагом. Как только все пакеты данных во всем наборе обработаны, мы говорим, что завершена одна эпоха. Наконец, было показано, что скорость обучения должна изменяться по мере увеличения количества эпох.
Поскольку пакеты данных независимы друг от друга, довольно просто распараллелить этот процесс, отправив разные пакеты данных на разные GPU. Затем, если мы сможем каким-то образом объединить вычисленные потери и синхронизировать обновлённые параметры модели, тогда получится сделать обучение намного быстрее.
Класс параллельного распределения данных
Это не новая идея. В PyTorch мы используем для модели модуль torch.nn.parallel.DistributedDataParallel (DDP) вместо модуля torch.nn.Module. Каждый GPU — это отдельный процесс, и связь между ними осуществляется с помощью стандартного IPC. Но это ещё не всё. Четыре шага требуют некоторой настройки.
С помощью DDP мы разделяем каждый пакет данных на множество различных GPU — столько, сколько у нас есть. В этом случае очень важно, чтобы у каждого графического процессора были одинаковые параметры модели.
Это основная идея параллельного распределения данных (DDP): каждый GPU имеет идентичные параметры модели, но одновременно обрабатывает разные пакеты данных.
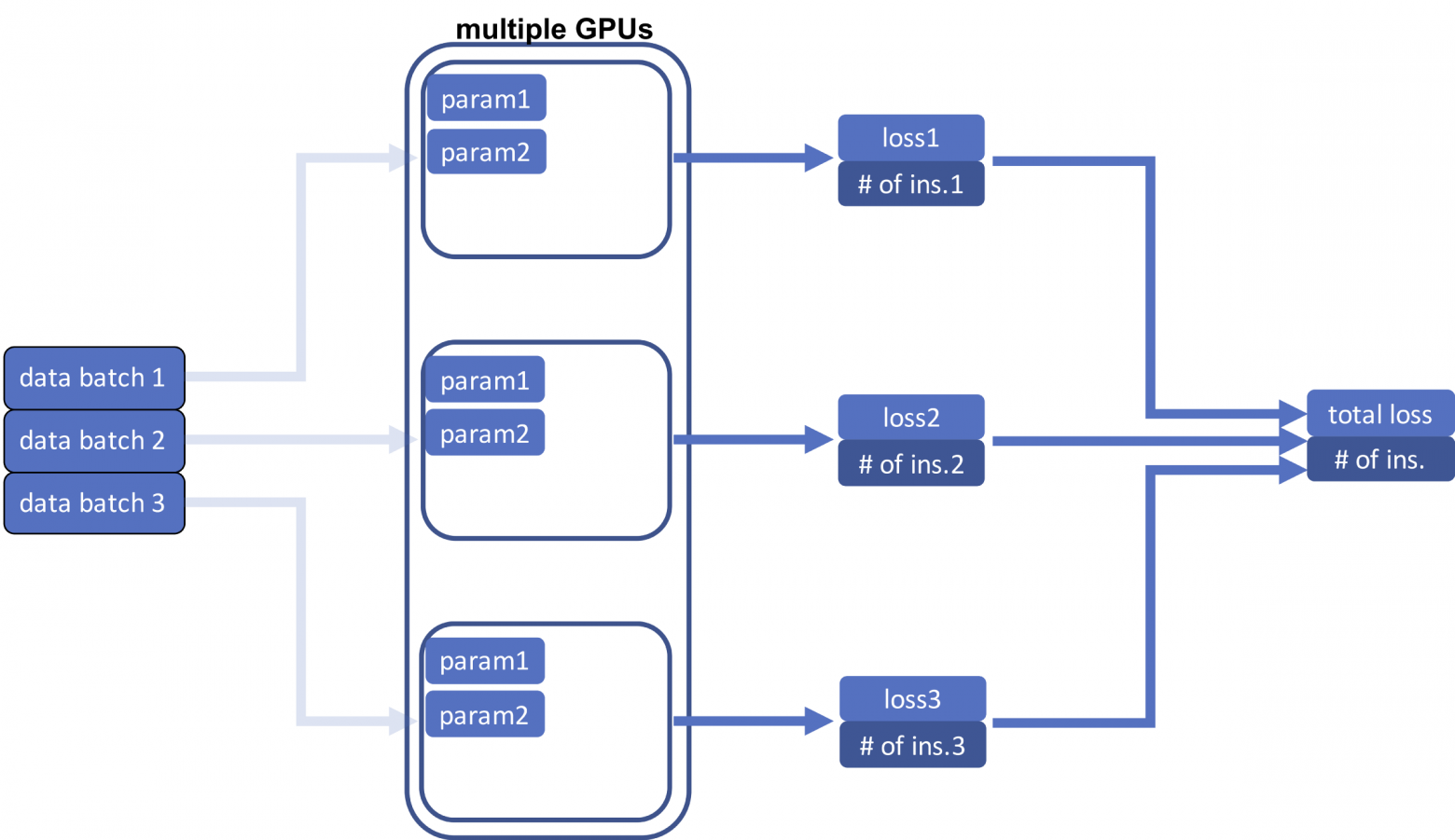
Прямой проход с несколькими GPU
После загрузки разных пакетов данных в разные процессоры следующий шаг — выполнение прямого прохода и вычисление функций потерь. В отличие от случая с одним процессором теперь нам нужно вычислить общую потерю всех пакетов данных, то есть сумму всех потерь для всех процессоров. Потому что наша цель — вычислить среднюю потерю для шага в обратном направлении. Важно в окончательный результат вывести количество экземпляров (входов). Суммируем потери, а также количество экземпляров.
Мы используем средние потери для получения градиентов параметров модели при обратном проходе. Прежде чем начать, необходимо сообщить о средних потерях на разные GPU, чтобы параметры модели могли оставаться синхронизированными. Как только одни и те же параметры на разных графических процессорах получают свои градиенты, выполняется синхронизация последних, чтобы они были одинаковы.
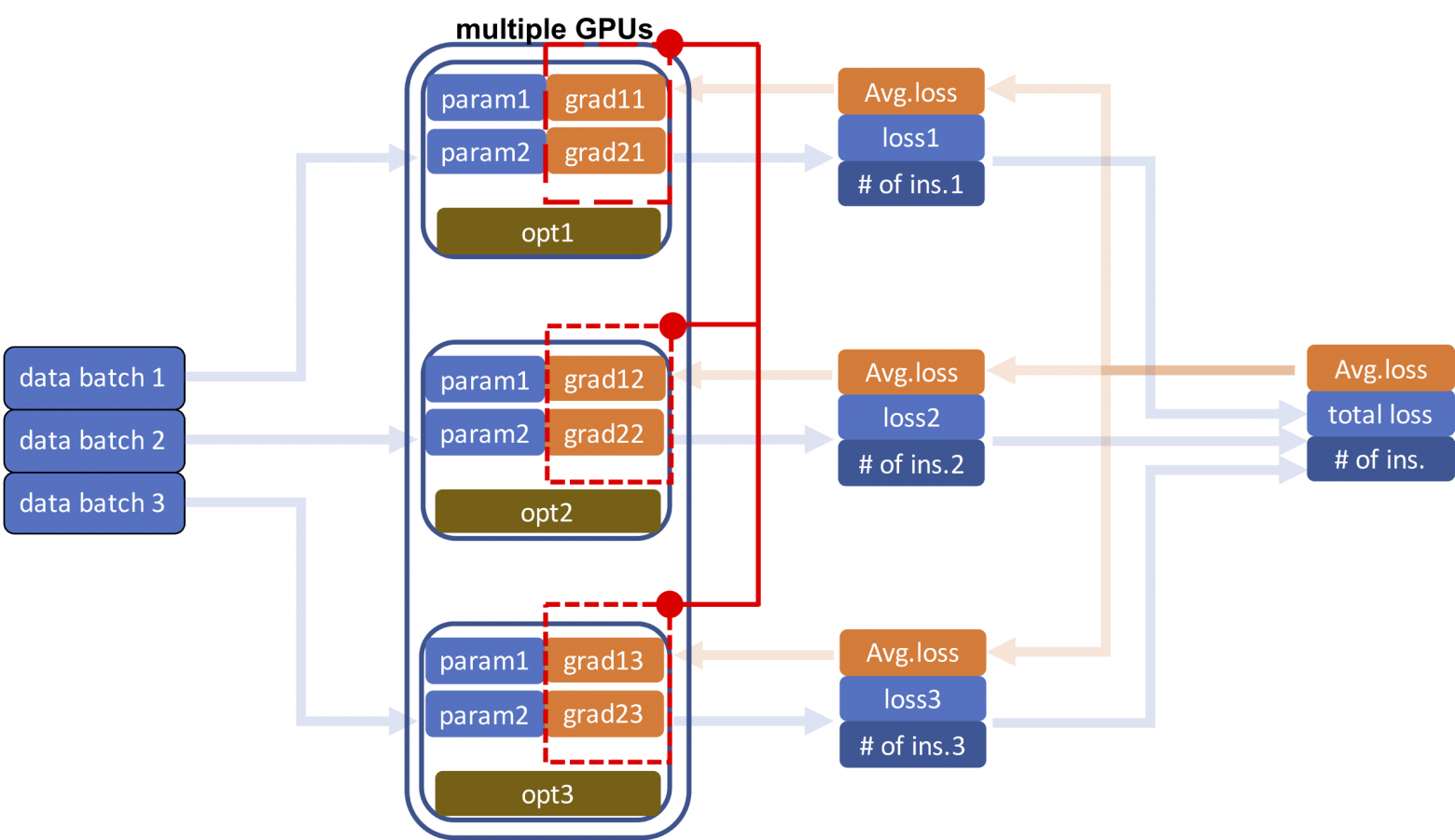
Синхронизация градиента
После синхронизации градиентов мы можем обновлять параметры модели параллельно, используя отдельные оптимизаторы на каждом процессоре.
Следующий шаг обучения обычно можно начинать сразу. Однако, поскольку почти все параметры «плавают» и в некоторых GPU может возникать ошибка вычислений, особенно когда выполняется много шагов обучения, мы иногда синхронизируем параметры в начале или в конце шага.
Эти изменения отражены в следующем псевдокоде. Примечательно, что функцию принимает идентификатор устройства (т. е. идентификатор GPU), модель должна выполнять синхронизацию параметров перед каждым прямым проходом, функция потерь должна усредняться перед обратным проходом, и, наконец, градиенты должны быть усреднены перед обновлением параметров модели.
Обучение на нескольких GPU
До сих пор мы говорили о том, как использовать несколько GPU на одном узле. Это здорово, но не приведёт далеко. Если мы хотим по-настоящему масштабироваться, нам нужно распределить рабочую нагрузку между несколькими узлами, каждый из которых имеет несколько процессоров.
К счастью, тот же механизм, который используется для адресации процессоров на одном узле, можно распространить на несколько узлов. Вы можете просто установить индекс узла, то есть параметр rank в функции init_process_group глобально, чтобы каждый GPU имел уникальный идентификатор относительно всех узлов.
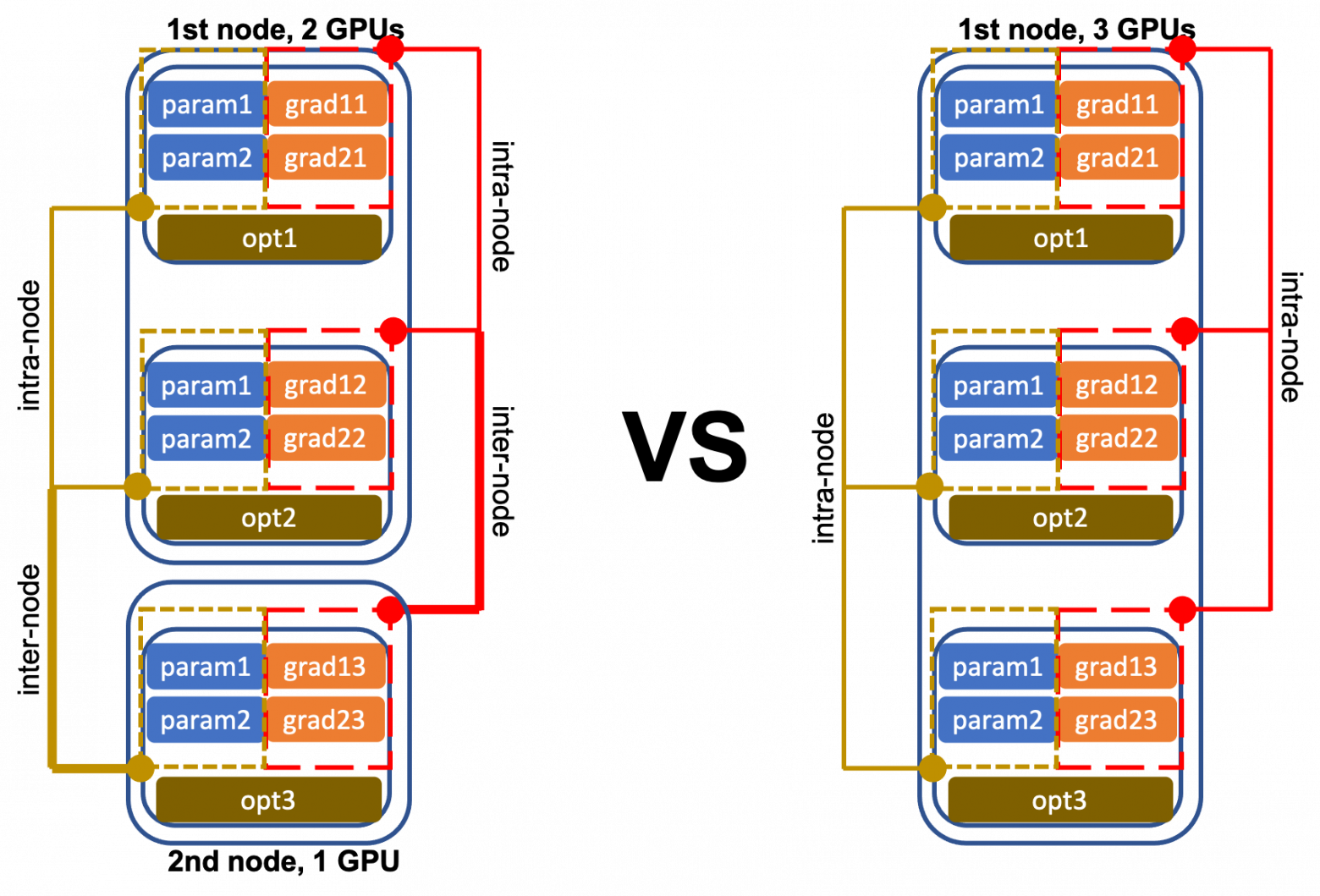
Внутриузловая и межузловая коммуникация
Когда у вас есть несколько узлов с несколькими процессорами, связь должна быть налажена между процессорами на одном узле и между разными узлами, чтобы во время процедуры обучения совместно использовать вычисленные градиенты и обновления параметров.
Конечно, межузловая связь намного медленнее, чем внутриузловая. А совместное использование градиентов и обновлений параметров превращается в полный беспорядок, когда узлы и GPU не идентичны — как в случае, когда у вас нет миллиарда долларов, которые можно потратить на центр обработки данных с настраиваемым вычислительным оборудованием.
В большинстве университетских вычислительных центров различные исследовательские лаборатории совместно используют свои вычислительные ресурсы. Существуют разные модели того, как это делается, но обычно ИТ-администраторы берут на себя значительный контроль над системами и не позволяют учёным устанавливать (обновлять или удалять обновления) необходимого программного обеспечения.
Это означает, что если необходимо обучить большую модель, то некоторым бедным аспирантам необходимо привести алгоритм обучения в соответствие с инфраструктурой. А это сложно по нескольким причинам:
Из-за этих проблем мы создали общую систему, которая охватывает все сложные части DDP: разделение данных, совместимость и настраиваемость, и развернули эту систему в Нотр-Даме.
Мы называем эту систему HetSeq. Она была адаптирована из популярного пакета PyTorch и обеспечивает возможность обучения больших моделей нейронных сетей в гетерогенной инфраструктуре. Её можно легко настроить через общую файловую систему без дополнительных пакетов и административных привилегий. Вот как обучать BERT с помощью HetSeq.
Начнём с Anaconda. Создадим виртуальную среду и установим Python.
Затем мы установим пакеты и привязки HetSeq: загрузим HetSeq с GitHub, установим пакеты из requirements.txt, а также HetSeq и биндинги из setup.py.
Последний шаг перед обучением — это загрузка файлов данных BERT, включая корпус обучения, конфигурацию модели и словарь BPE отсюда. Загрузите DATA.zip, распакуйте его и поместите в каталог preprocessing/.
Крутая вещь в HetSeq: она абстрагирует все детали о распределённой обработке. Таким образом, код обучения для 100 GPU почти такой же, как для одного! Давайте попробуем!
В этом случае предположим, что у нас есть два вычислительных узла.
На первом узле:
На втором узле:
Два блока кода работают на двух разных узлах. Адрес TCP/IP должен быть установлен как один из IP-адресов узла. Как только они будут запущены, вы сможете наблюдать за выполнением кода на 8 процессорах и 2 разных узлах!
Так насколько хорошо это работает? Мы провели несколько экспериментов (подробности тут) над различными однородными (гомогенными, hom) и неоднородными (гетерогенными, het) установками.
В общей сложности мы смогли управлять 32 GPU в 8 неоднородных узлах, сокращая время обучения языковой модели BERT с семи дней до примерно одного дня.

Структура пакета HetSeq
Пакет HetSeq содержит три основных модуля, показанных на рисунке слева: train.py, task.py и controller.py для координации основных компонентов, показанных справа. Модуль train.py инициализирует распределённую систему и её различные компоненты.
Модуль task.py определяет функции модели, набора данных, загрузчика данных и оптимизатора; он также выполняет функции прямого и обратного распространения. Модуль controller.py действует как главный контроллер обучения. Он работает как модель, оптимизатор и планировщик скорости обучения; загружает и сохраняет чекпоинты, сообщает о потере и обновляет параметры.
Но я хочу обучить не BERT!
Нет проблем. Вы можете использовать HetSeq с любой другой моделью. Но вам нужно определить новую задачу с соответствующей моделью, набором данных, оптимизатором. и планировщиком скорости обучения. Есть пример MNIST со всеми расширенными классами. Предварительно определённые оптимизаторы, планировщики скорости обучения, наборы данных и модели могут быть повторно использованы в других приложениях. Для получения дополнительной информации ознакомьтесь с пакетом HetSeq и документацией.

Такие платформы, как PyTorch и Tensorflow, могут обучать эти огромные модели, потому что распределяют рабочую нагрузку по сотням (или тысячам) GPU одновременно. К сожалению, этим платформам требуется идентичность графических процессоров (они должны иметь одинаковую память и вычислительную производительность). Но многие организации не имеют тысячи одинаковых GPU. Малые и средние организации покупают разные компьютерные системы, что приводит к неоднородной инфраструктуре, которую нелегко адаптировать для вычисления больших моделей. В этих условиях обучение моделей даже среднего размера может занимать недели или даже месяцы. Если не принять меры, университеты и другие небольшие организации рискуют потерять конкурентоспособность в погоне за разработкой новых, лучших моделей машинного обучения. Но это можно исправить.
В этом посте представлена предыстория и практические шаги по обучению BERT с нуля в университете с использованием пакета HetSeq. Это адаптация популярного пакета PyTorch, которая предоставляет возможность обучать большие модели нейронных сетей на гетерогенной инфраструктуре.
Чтобы исправить эту ситуацию, мы недавно выпустили программный пакет под названием HetSeq — адаптацию популярного пакета PyTorch, которая предоставляет возможность обучать большие модели нейронных сетей на гетерогенной инфраструктуре.
Эксперименты показывают, что систему на базе BERT можно за день обучить с помощью более чем 8 GPU, большинство из которых нам пришлось «позаимствовать» в неработающих лабораториях. Прежде чем мы представим HetSeq, нужна небольшая предыстория.
Типовое обучение нейронной сети
def train(args):
# main components
dataset = Dataset()
dataloader = DataLoader(dataset)
model = Model()
loss_ = Loss()
optimizer = Optimizer(model.parameters())
# specify the GPU and transfer model to the GPU
device = Device()
model.to(device)
model.train()
# actual training loops
for epoch in range(1, Max_Epoch):
for (data, target) in dataloader:
data, target = data.to(device), target.to(device) # **load input data and target to GPU**
optimizer.zero_grad()
output = model(data) # **forward compute the output of model given input data**
loss = loss_(output, target) # **forward process to compute the real loss function**
loss.backward() # **backward process to obtain the**
optimizer.step() # **update parameters**
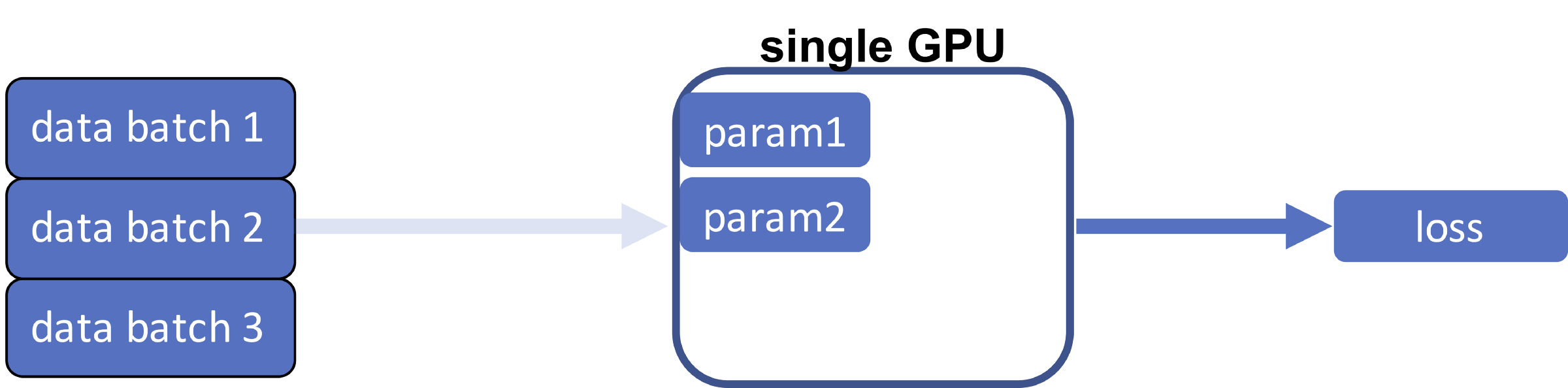
Обучение на одном GPU
Этот код показывает этап обучения базовой модели контролируемого обучения на фреймворке нейронных сетей. Учитывая некоторую архитектуру, эта задача оптимизирует параметры модели через SGD на функции потерь между предсказанными экземплярами и наблюдаемой истиной.
Фактически процесс обучения состоит из четырёх отдельных этапов: (1) загрузка данных, (2) прямой проход, (3) обратный проход, (4) обновление.
1. Загрузка данных
При единственном GPU первые существующие параметры модели (которые изначально случайны) и данные передаются на графический процессор, и это первое, что происходит. Как правило, набор данных содержит большое количество обучающих экземпляров, которые не умещаются на одном графическом процессоре. В этом общем случае мы разделяем набор данных на несколько пакетов и загружаем их по одному.
Прямой проход с одним GPU
2. Прямой проход
Следующий шаг — вычисление функции потерь. Для этого пакет данных передаётся через модель (отсюда и название — «прямой проход») и сравнивается с метками обучения наблюдаемой истины. В блоке прямой проход состоит из двух этапов: генерации спрогнозированной метки (вывод) и измерения разницы (потери) между выводом и целью.
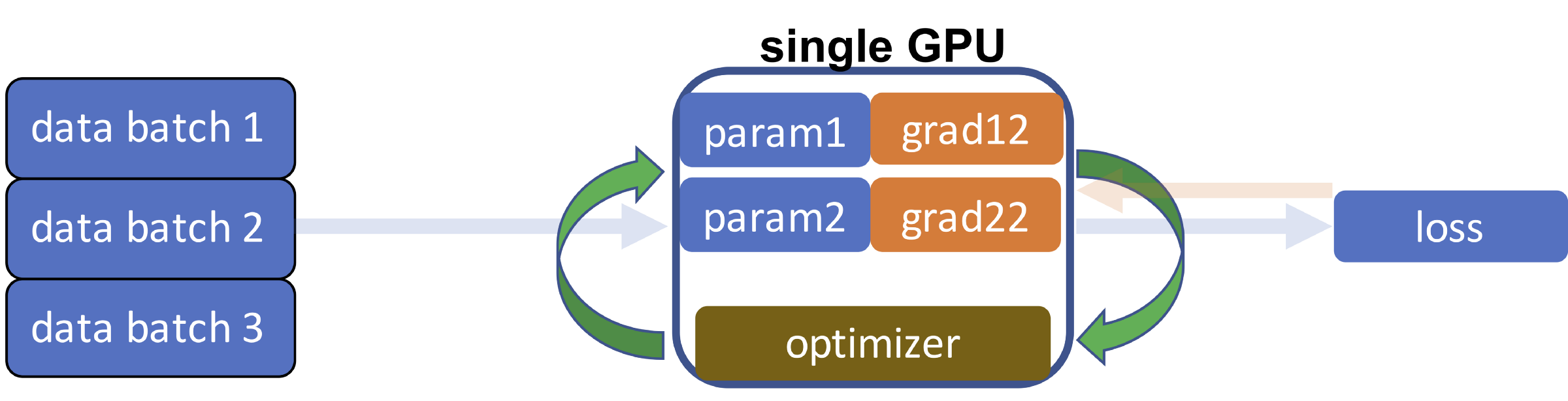
3. Обратный проход
Вычисленная на предыдущем шаге потеря определяет, насколько нужно изменить параметры модели; это называется градиентом, который применяется к архитектуре нейронной сети в обратном направлении (отсюда название — обратный проход, или обратное распространение).
Параметры обновления с единственным GPU
4. Обновление
Помните, что цель всего процесса — оптимизировать параметры модели так, чтобы при передаче данных по ним они минимизировали потери. Поэтому важно, чтобы параметры модели обновлялись в соответствии со значениями градиента.
Краткое описание этапов обучения
В целом одна итерация загрузки данных, прямой проход одного экземпляра данных, затем обратный проход, а затем обновление параметра называются одним шагом. Как только все пакеты данных во всем наборе обработаны, мы говорим, что завершена одна эпоха. Наконец, было показано, что скорость обучения должна изменяться по мере увеличения количества эпох.
Что делать, если у нас несколько GPU?
Поскольку пакеты данных независимы друг от друга, довольно просто распараллелить этот процесс, отправив разные пакеты данных на разные GPU. Затем, если мы сможем каким-то образом объединить вычисленные потери и синхронизировать обновлённые параметры модели, тогда получится сделать обучение намного быстрее.
def torch.nn.parallel.DistributedDataParallel(
module, # pre-defined model
device_ids=None, # input device_ids
output_device=None, # output device_ids, in our case, input device = output device = single GPU
dim=0,
broadcast_buffers=True, # set to False in our implementation
process_group=None, # Core part
bucket_cap_mb=25,
find_unused_parameters=False,
check_reduction=False
)
view rawКласс параллельного распределения данных
Это не новая идея. В PyTorch мы используем для модели модуль torch.nn.parallel.DistributedDataParallel (DDP) вместо модуля torch.nn.Module. Каждый GPU — это отдельный процесс, и связь между ними осуществляется с помощью стандартного IPC. Но это ещё не всё. Четыре шага требуют некоторой настройки.
1. Загрузка данных с помощью DDP
С помощью DDP мы разделяем каждый пакет данных на множество различных GPU — столько, сколько у нас есть. В этом случае очень важно, чтобы у каждого графического процессора были одинаковые параметры модели.
Это основная идея параллельного распределения данных (DDP): каждый GPU имеет идентичные параметры модели, но одновременно обрабатывает разные пакеты данных.
Прямой проход с несколькими GPU
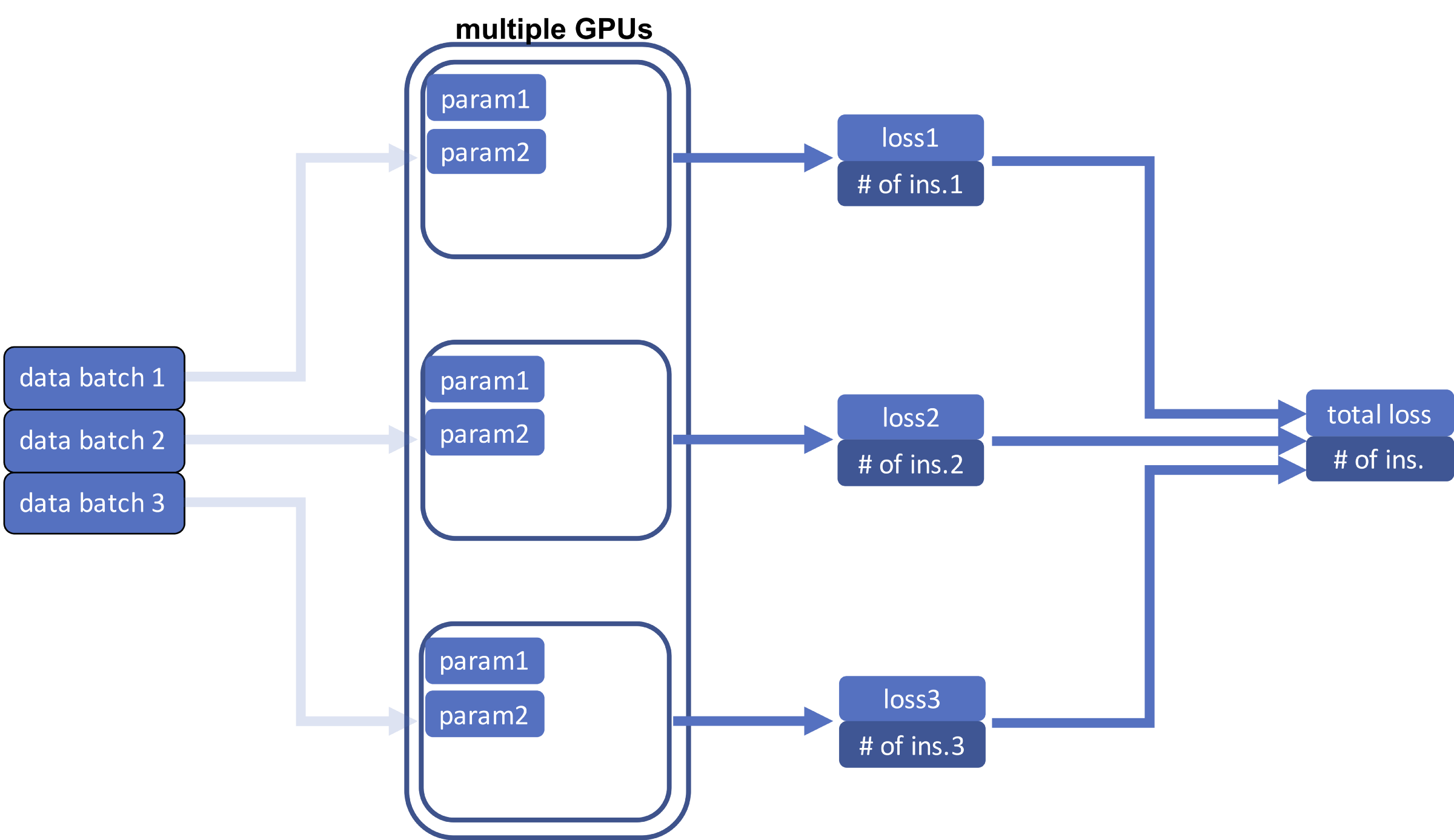
2. Прямой проход с DDP
После загрузки разных пакетов данных в разные процессоры следующий шаг — выполнение прямого прохода и вычисление функций потерь. В отличие от случая с одним процессором теперь нам нужно вычислить общую потерю всех пакетов данных, то есть сумму всех потерь для всех процессоров. Потому что наша цель — вычислить среднюю потерю для шага в обратном направлении. Важно в окончательный результат вывести количество экземпляров (входов). Суммируем потери, а также количество экземпляров.
3. Обратный проход с DDP
Мы используем средние потери для получения градиентов параметров модели при обратном проходе. Прежде чем начать, необходимо сообщить о средних потерях на разные GPU, чтобы параметры модели могли оставаться синхронизированными. Как только одни и те же параметры на разных графических процессорах получают свои градиенты, выполняется синхронизация последних, чтобы они были одинаковы.
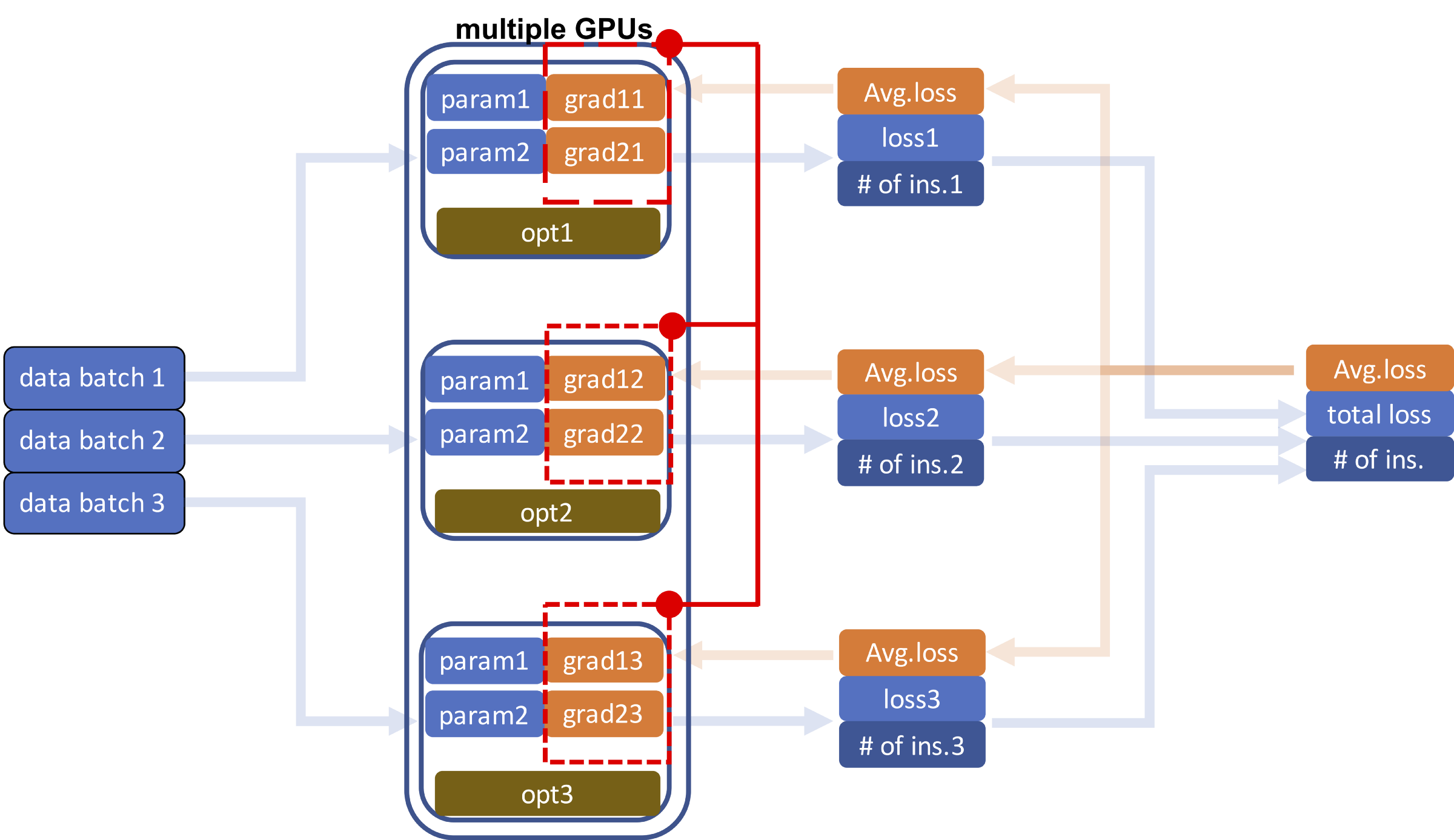
Синхронизация градиента
4. Обновление с DDP
После синхронизации градиентов мы можем обновлять параметры модели параллельно, используя отдельные оптимизаторы на каждом процессоре.
Следующий шаг обучения обычно можно начинать сразу. Однако, поскольку почти все параметры «плавают» и в некоторых GPU может возникать ошибка вычислений, особенно когда выполняется много шагов обучения, мы иногда синхронизируем параметры в начале или в конце шага.
Эти изменения отражены в следующем псевдокоде. Примечательно, что функцию принимает идентификатор устройства (т. е. идентификатор GPU), модель должна выполнять синхронизацию параметров перед каждым прямым проходом, функция потерь должна усредняться перед обратным проходом, и, наконец, градиенты должны быть усреднены перед обновлением параметров модели.
def train_multiple_GPUs(args, device_id):
# main components
dataset = Dataset()
dataloader = DataLoader(dataset)
model = DDP(Model())
loss_ = Loss()
optimizer = Optimizer(model.parameters())
device = Device(device_id)
model.to(device)
model.train()
# actual training loops
for epoch in range(1, Max_Epoch):
for (data, target) in dataloader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
model.synchronization() # parameter synchronization
output = model(data)
loss = loss_(output, target)
loss_average = average(loss)
loss.backward()
model.parameter.grad.average()
optimizer.step()
Обучение на нескольких GPU
Масштабирование — несколько узлов с несколькими GPU
До сих пор мы говорили о том, как использовать несколько GPU на одном узле. Это здорово, но не приведёт далеко. Если мы хотим по-настоящему масштабироваться, нам нужно распределить рабочую нагрузку между несколькими узлами, каждый из которых имеет несколько процессоров.
def torch.distributed.init_process_group(
backend=args.distributed_backend, # 'nccl' is the best available backend for GPU
init_method=args.distributed_init_method, # 'tcp' or shared file system
world_size=args.distributed_world_size, # number of nodes in total
rank=args.distributed_rank, # index of current node
)
К счастью, тот же механизм, который используется для адресации процессоров на одном узле, можно распространить на несколько узлов. Вы можете просто установить индекс узла, то есть параметр rank в функции init_process_group глобально, чтобы каждый GPU имел уникальный идентификатор относительно всех узлов.
Коммуникация — вот где возникают сложности
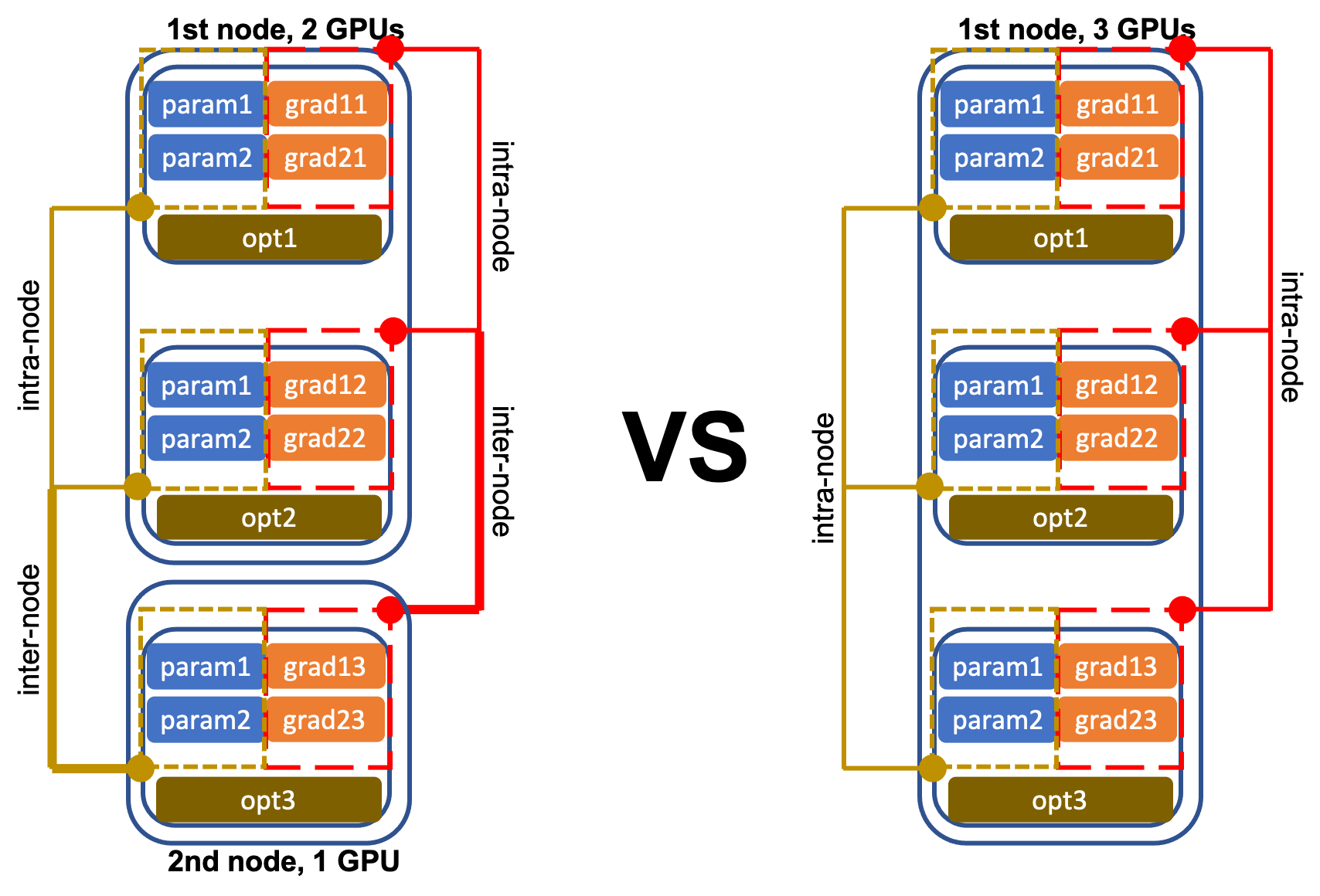
Внутриузловая и межузловая коммуникация
Когда у вас есть несколько узлов с несколькими процессорами, связь должна быть налажена между процессорами на одном узле и между разными узлами, чтобы во время процедуры обучения совместно использовать вычисленные градиенты и обновления параметров.
Конечно, межузловая связь намного медленнее, чем внутриузловая. А совместное использование градиентов и обновлений параметров превращается в полный беспорядок, когда узлы и GPU не идентичны — как в случае, когда у вас нет миллиарда долларов, которые можно потратить на центр обработки данных с настраиваемым вычислительным оборудованием.
Когда родители заставляют вас делиться игрушками
В большинстве университетских вычислительных центров различные исследовательские лаборатории совместно используют свои вычислительные ресурсы. Существуют разные модели того, как это делается, но обычно ИТ-администраторы берут на себя значительный контроль над системами и не позволяют учёным устанавливать (обновлять или удалять обновления) необходимого программного обеспечения.
Это означает, что если необходимо обучить большую модель, то некоторым бедным аспирантам необходимо привести алгоритм обучения в соответствие с инфраструктурой. А это сложно по нескольким причинам:
- Некоторые игрушки имеют сложные инструкции. Распределённая параллельная обработка данных пакета (DDP) — это боль, трудно понять её и заставить работать. Особенно верно это для большинства исследователей машинного обучения, которые не очень хорошо разбираются в особенностях распределённых вычислений. В дополнение к базовой настройке DDP мирный тренировочный запуск различных архитектур GPU на многих узлах требует тщательного разделения данных и изнурительного налаживания связи между GPU и узлами.
- С какими-то игрушками лучше играть лучше, чем с другими. В гетерогенной системе некоторые GPU работают быстрее других, а некоторые имеют больше памяти, чем у других. Это означает, что какие-то процессоры получают больше данных для обработки, чем другие, что прекрасно; но это также означает, что средние значения градиентов и обновления параметров должны тщательно взвешиваться.
- Родители не разрешают нам играть с какими-то игрушками. Большинство существующих распределённых обучающих платформ GPU требуют дополнительных пакетов, таких как Docker, OpenMPI и т. д. К сожалению, большинство компетентных администраторов кластеров не позволяют пользователям иметь административные привилегии, необходимые для настройки каждого узла, чтобы обучить модель.
- Какие-то игрушки плохо работают с другими. Пакеты глубокого обучения, такие как BERT и GPT2/3, разработанные крупными компаниями, как правило, имеют определённые форматы дизайна модели с несколькими логическими слоями, что затрудняет их использование и адаптацию к приложению.
Из-за этих проблем мы создали общую систему, которая охватывает все сложные части DDP: разделение данных, совместимость и настраиваемость, и развернули эту систему в Нотр-Даме.
Мы называем эту систему HetSeq. Она была адаптирована из популярного пакета PyTorch и обеспечивает возможность обучения больших моделей нейронных сетей в гетерогенной инфраструктуре. Её можно легко настроить через общую файловую систему без дополнительных пакетов и административных привилегий. Вот как обучать BERT с помощью HetSeq.
BERT в университете с HetSeq
Начнём с Anaconda. Создадим виртуальную среду и установим Python.
$ conda create --name hetseq
$ conda activate hetseq
$ conda install python=3.7.4Затем мы установим пакеты и привязки HetSeq: загрузим HetSeq с GitHub, установим пакеты из requirements.txt, а также HetSeq и биндинги из setup.py.
$ git clone https://github.com/yifding/hetseq.git
$ cd /path/to/hetseq
$ pip install -r requirements.txt
$ pip install --editable .Последний шаг перед обучением — это загрузка файлов данных BERT, включая корпус обучения, конфигурацию модели и словарь BPE отсюда. Загрузите DATA.zip, распакуйте его и поместите в каталог preprocessing/.
Обучение BERT с помощью HetSeq
Крутая вещь в HetSeq: она абстрагирует все детали о распределённой обработке. Таким образом, код обучения для 100 GPU почти такой же, как для одного! Давайте попробуем!
$DIST=/path/to/hetseq
$python3 ${DIST}/train.py \
$ --task bert --data ${DIST}/preprocessing/test_128/ \
$ --dict ${DIST}/preprocessing/uncased_L-12_H-768_A-12/vocab.txt \
$ --config_file ${DIST}/preprocessing/uncased_L-12_H-768_A-12/bert_config.json \
$ --max-sentences 32 --fast-stat-sync --max-update 900000 --update-freq 4 \
$ --valid-subset test --num-workers 4 \
$ --warmup-updates 10000 --total-num-update 1000000 --lr 0.0001 \
$ --weight-decay 0.01 --distributed-world-size 1 \
$ --device-id 0 --save-dir bert_single_gpuВ этом случае предположим, что у нас есть два вычислительных узла.
На первом узле:
$DIST=/path/to/hetseq
$python3 ${DIST}/train.py \
$ --task bert --data ${DIST}/preprocessing/test_128/ \
$ --dict ${DIST}/preprocessing/uncased_L-12_H-768_A-12/vocab.txt \
$ --config_file ${DIST}/preprocessing/uncased_L-12_H-768_A-12/bert_config.json \
$ --max-sentences 32 --fast-stat-sync --max-update 900000 --update-freq 4 \
$ --valid-subset test --num-workers 4 \
$ --warmup-updates 10000 --total-num-update 1000000 --lr 0.0001 \
$ --weight-decay 0.01 --save-dir bert_node2gpu4 \
$ --distributed-init-method tcp://10.00.123.456:11111 \
$ --distributed-world-size 8 --distributed-gpus 4 --distributed-rank 0На втором узле:
$DIST=/path/to/hetseq
$python3 ${DIST}/train.py \
$ --task bert --data ${DIST}/preprocessing/test_128/ \
$ --dict ${DIST}/preprocessing/uncased_L-12_H-768_A-12/vocab.txt \
$ --config_file ${DIST}/preprocessing/uncased_L-12_H-768_A-12/bert_config.json \
$ --max-sentences 32 --fast-stat-sync --max-update 900000 --update-freq 4 \
$ --valid-subset test --num-workers 4 \
$ --warmup-updates 10000 --total-num-update 1000000 --lr 0.0001 \
$ --weight-decay 0.01 --save-dir bert_node2gpu4 \
$ --distributed-init-method tcp://10.00.123.456:11111 \
$ --distributed-world-size 8 --distributed-gpus 4 --distributed-rank 4Два блока кода работают на двух разных узлах. Адрес TCP/IP должен быть установлен как один из IP-адресов узла. Как только они будут запущены, вы сможете наблюдать за выполнением кода на 8 процессорах и 2 разных узлах!
Так насколько хорошо это работает? Мы провели несколько экспериментов (подробности тут) над различными однородными (гомогенными, hom) и неоднородными (гетерогенными, het) установками.
| nodes | GPUs | training_time | speed_up |
|---|---|---|---|
| 1 | 4 | 7.19day | 1.00 |
| 2(het) | 8 | 4.19day | 1.72 |
| 2(hom) | 8 | 4.26day | 1.69 |
| 4(het) | 16 | 2.23day | 3.22 |
| 4(hom) | 16 | 2.19day | 3.28 |
| 8(het) | 32 | 1.21day | 5.94 |
В общей сложности мы смогли управлять 32 GPU в 8 неоднородных узлах, сокращая время обучения языковой модели BERT с семи дней до примерно одного дня.
Под капотом HetSeq
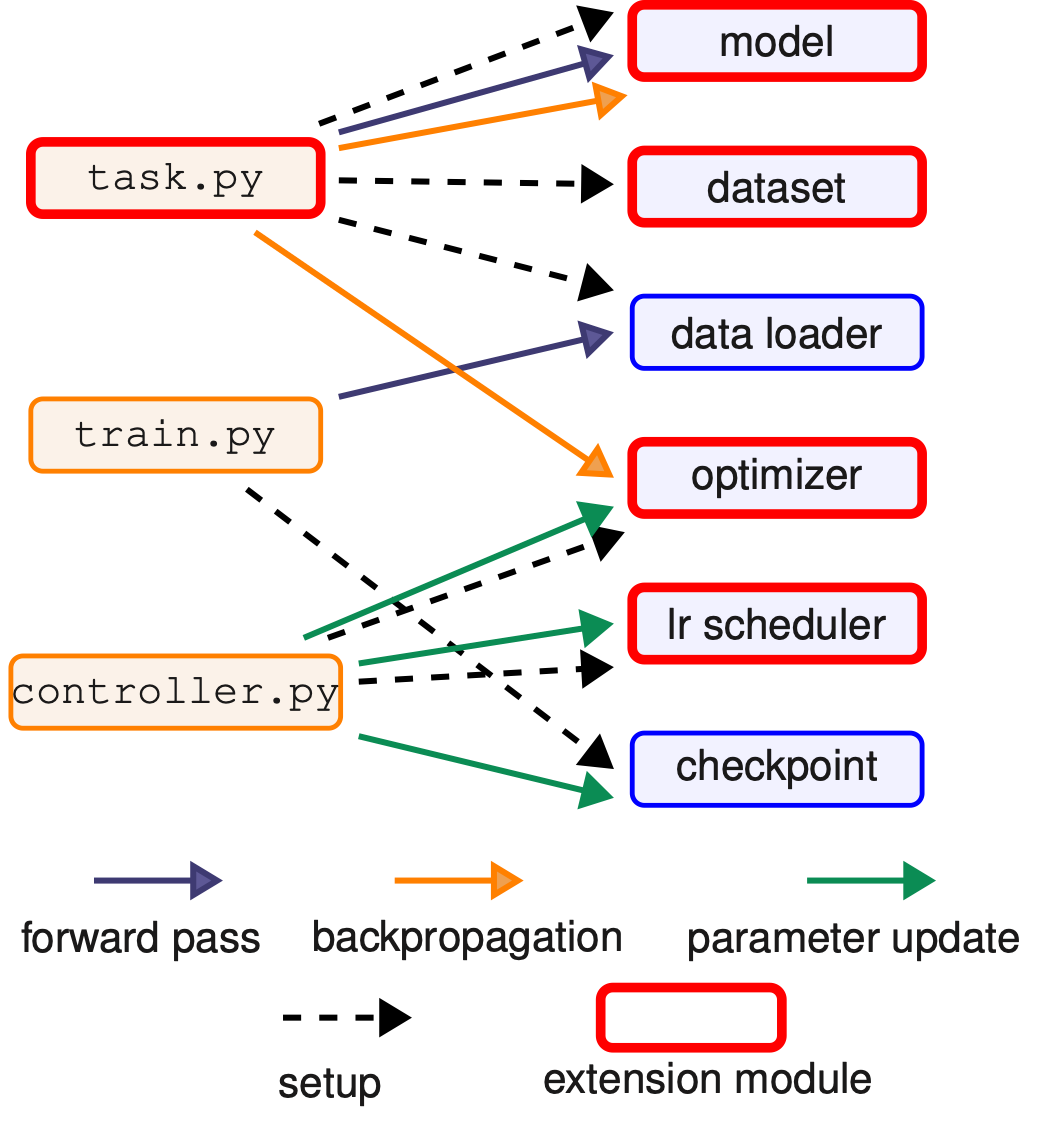
Структура пакета HetSeq
Пакет HetSeq содержит три основных модуля, показанных на рисунке слева: train.py, task.py и controller.py для координации основных компонентов, показанных справа. Модуль train.py инициализирует распределённую систему и её различные компоненты.
Модуль task.py определяет функции модели, набора данных, загрузчика данных и оптимизатора; он также выполняет функции прямого и обратного распространения. Модуль controller.py действует как главный контроллер обучения. Он работает как модель, оптимизатор и планировщик скорости обучения; загружает и сохраняет чекпоинты, сообщает о потере и обновляет параметры.
Но я хочу обучить не BERT!
Но я хочу обучить не BERT!
Нет проблем. Вы можете использовать HetSeq с любой другой моделью. Но вам нужно определить новую задачу с соответствующей моделью, набором данных, оптимизатором. и планировщиком скорости обучения. Есть пример MNIST со всеми расширенными классами. Предварительно определённые оптимизаторы, планировщики скорости обучения, наборы данных и модели могут быть повторно использованы в других приложениях. Для получения дополнительной информации ознакомьтесь с пакетом HetSeq и документацией.

Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
- Профессия Java-разработчик
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Продвинутый курс «Machine Learning Pro + Deep Learning»
- Курс «Python для веб-разработки»
- Курс по JavaScript
- Курс «Математика и Machine Learning для Data Science»
- Курс по аналитике данных
- Курс по DevOps
