
Два этих модных слова, связанных с Data Science, сбивают с толку многих людей. Data Mining часто неправильно понимают как извлечение и получение данных, но на самом деле все намного сложнее. В этом посте давайте расставим точки над Mining и выясним разницу между Data Mining и Data Extraction.
Что такое Data Mining?
Data mining, также называемый Обнаружение знаний в базе данных (KDD), представляет собой метод, часто используемый для анализа больших массивов данных с помощью статистических и математических методов для поиска скрытых закономерностей или тенденций и извлечения из них ценности.
Что можно сделать с помощью Data Mining?
Автоматизируя процесс, инструменты data mining могут просматривать базы данных и эффективно выявлять скрытые закономерности. Для предприятий data mining часто используется для выявления закономерностей и взаимосвязей в данных, помогающих принимать оптимальные решения в бизнесе.
Примеры применения
После того, как в 1990-х годах data mining получил широкое распространение, компании в широком спектре отраслей, включая розничную торговлю, финансы, здравоохранение, транспорт, телекоммуникации, электронную коммерцию и т.д., начали использовать методы data mining для получения информации на основе данных. Data mining может помочь сегментировать клиентов, выявить мошенничество, прогнозировать продажи и многое другое.
- Сегментация клиентов
Благодаря анализу данных о клиентах и выявлению черт целевых клиентов, компании могут выстраивать их в отдельную группу и предоставлять отвечающие их потребностям специальные предложения. - Анализ рыночной корзины
Эта методика основана на теории, что если вы покупаете определенную группу товаров, вы, скорее всего, купите другую группу товаров. Один известный пример: когда отцы покупают подгузники для своих младенцев, они, как правило, покупают пиво вместе с подгузниками. - Прогнозирование продаж
Это может показаться похожим на анализ рыночной корзины, но на этот раз анализ данных используется для прогнозирования того, когда покупатель снова купит продукт в будущем. Например, тренер покупает банку протеина, которой должно хватит на 9 месяцев. Магазин, продающий этот протеин, планирует выпустить новый через 9 месяцев, чтобы тренер снова его купил. - Обнаружение мошенничества
Data mining помогает в построении моделей для обнаружения мошенничества. Собирая образцы мошеннических и правдивых отчетов, предприятия получают право определять, какие операции являются подозрительными. - Обнаружение паттернов в производстве
В обрабатывающей промышленности data mining используется, чтобы помочь в проектировании систем, путем выявления взаимосвязи между архитектурой продукта, профилем и потребностями клиентов. Добыча данных также может предсказать сроки разработки продукции и затраты.
И это лишь несколько сценариев использования data mining.
Этапы Data Mining
Data mining — это целостный процесс сбора, отбора, очистки, преобразования и извлечения данных для оценки закономерностей и, в конечном итоге, для извлечения ценности.
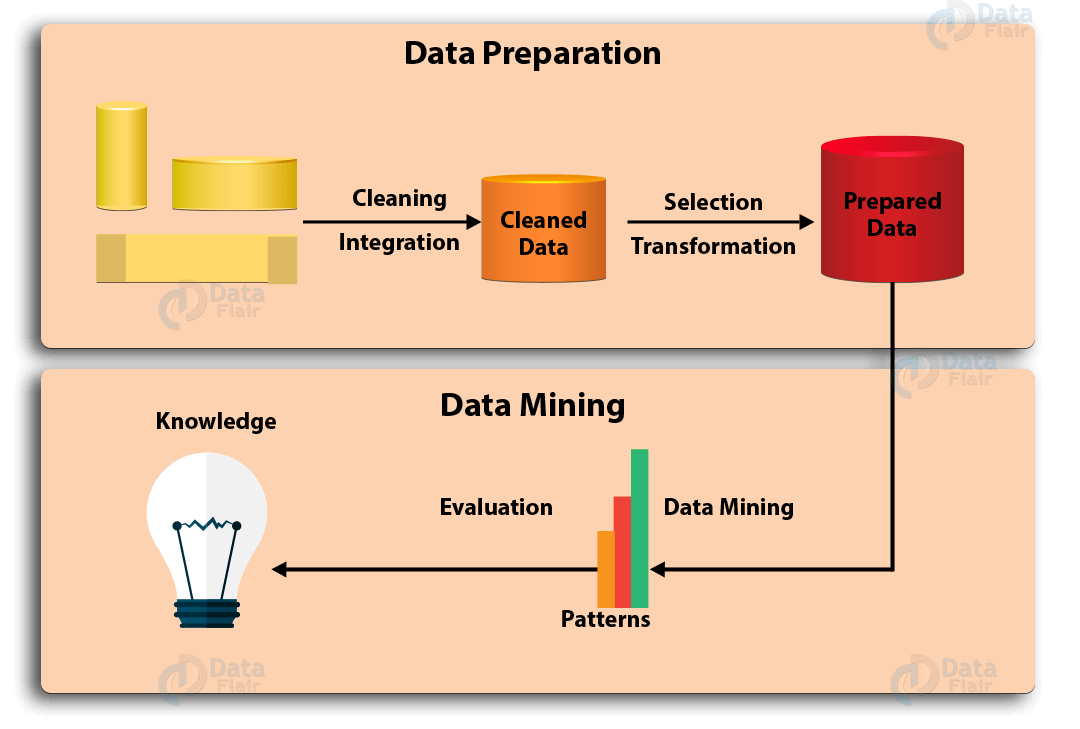
Как правило, весь процесс добычи данных можно обобщить до 7 этапов:
- Очистка данных
В реальном мире данные не всегда очищаются и структурируются. Часто они шумные, неполные и могут содержать ошибки. Чтобы удостовериться, что результат data mining точный, сначала необходимо очистить данные. Некоторые методы очистки включают заполнение недостающих значений, автоматический и ручной контроль и т.д. - Интеграция данных
Это этап, на котором данные из разных источников извлекаются, комбинируются и интегрируются. Источниками могут быть базы данных, текстовые файлы, электронные таблицы, документы, многомерные массивы данных, интернет и так далее. - Выборка данных
Обычно не все интегрированные данные необходимы в data mining. Выборка данных — это этап, в котором из большой базы данных выбираются и извлекаются только полезные данные. - Преобразование данных
После выбора данных они преобразуются в подходящие для добычи формы. Этот процесс включает в себя нормализацию, агрегирование, обобщение и т.д. - Интеллектуальный анализ данных
Здесь наступает самая важная часть data mining — использование интеллектуальных методов для поиска закономерностей в них. Процесс включает регрессию, классификацию, прогнозирование, кластеризацию, изучение ассоциаций и многое другое. - Оценка модели
Этот этап направлен на выявление потенциально полезных, простых в понимании шаблонов, а также шаблонов, подтверждающих гипотезы. - Представление знаний
На заключительном этапе полученная информация представлена в привлекательном виде с применением методов представления знаний и визуализации.
Недостатки Data Mining
- Большие вложения времени и труда
Поскольку добыч данных — это длительный и сложный процесс, он требует большой работы продуктивных и квалифицированных людей. Специалисты по интеллектуальному анализу данных могут воспользоваться мощными инструментами добычи данных, однако им требуются специалисты для подготовки данных и понимания результатов. В результате на обработку всей информации может потребоваться некоторое время. - Приватность и безопасность данных
Поскольку data mining собирает информацию о клиентах с помощью рыночных методов, она может нарушить конфиденциальность пользователей. Кроме того, хакеры могут получить данные, хранящиеся в системах добычи данных. Это представляет угрозу для безопасности данных клиентов. Если украденные данные используются не по назначению, это может легко навредить другим.
Выше приведено краткое введение в data mining. Как я уже упоминала, data mining содержит процесс сбора и интеграции данных, который включает в себя процесс извлечения данных (data extraction). В этом случае можно с уверенностью сказать, что data extraction может быть частью длительного процесса data mining.
Что такое Data Extraction?
Также известное как «извлечение веб-данных» и «веб-скрепинг», этот процесс представляет собой акт извлечения данных из (обычно неструктурированных или плохо структурированных) источников данных в централизованные места и централизацию в одном месте для хранения или дальнейшей обработки. В частности, к неструктурированным источникам данных относятся веб-страницы, электронная почта, документы, файлы PDF, отсканированный текст, отчеты мейнфреймов, катушечные файлы, объявления и т.д. Централизованные хранилища могут быть локальными, облачными или гибридными. Важно помнить, что извлечение данных не включает в себя обработку или другой анализ, который может произойти позже.
Что можно сделать с помощью Data Extraction?
В основном цели извлечения данных делятся на 3 категории.
- Архивация
Извлечение данных может преобразовать данные из физических форматов: книг, газет, счетов-фактур в цифровые форматы, например, базы данных для хранения или резервного копирования. - Изменение формата данных
Когда вы хотите перенести данные с вашего текущего сайта на новый, находящийся в стадии разработки, вы можете собрать данные с вашего собственного сайта, извлекая их. - Анализ данных
Распространен дополнительный анализ извлеченных данных для получения представления о них. Это может показаться похожим на анализ данных при data mining, но учтите, что анализ данных — это цель их извлечения, но не его часть. Более того, данные анализируются иначе. Один из примеров: владельцы интернет-магазинов извлекают информацию о продукте с сайтов электронной коммерции, таких как Amazon, для мониторинга стратегий конкурентов в режиме реального времени. Как и data mining, data extraction — это автоматизированный процесс, имеющий множество преимуществ. Раньше люди копировали и вставляли данные вручную из одного места в другое, что занимало очень много времени. Извлечение данных ускоряет сбор и значительно повышает точность извлекаемых данных.
Некоторые примеры применения Data Extraction
Подобно data mining, извлечение данных широко используется в различных отраслях промышленности. Помимо мониторинга цен в электронной коммерции, извлечение данных может помочь в собственном исследовании, агрегировании новостей, маркетинге, в работе с недвижимостью, путешествиях и туризме, в консалтинге, финансах и во многом другом.
- Лидогенерация
Компании могут извлекать данные из каталогов: Yelp, Crunchbase, Yellowpages и генерировать лидов для развития бизнеса. Вы можете посмотреть видео ниже, чтобы узнать, как извлечь данные из Yellowpages с помощью шаблона веб-скрепинга.
- Агрегация контента и новостей
Агрегирующие контент веб-сайты могут получать регулярные потоки данных из нескольких источников и поддерживать свои сайты в актуальном состоянии. - Анализ настроений
После извлечения обзоров, комментариев и отзывов из социальных сетей, таких как Instagram и Twitter, специалисты могут проанализировать лежащие в их основе взгляды и получить представление о том, как воспринимается бренд, продукт или некое явление.
Шаги Data Extraction
Извлечение данных — первый этап ETL (аббревиатура Extract, Transform, Load: извлечение, преобразование, загрузка) и ELT (извлечение, загрузка и преобразование). ETL и ELT сами по себе являются частью завершенной стратегии интеграции данных. Другими словами, извлечение данных может быть частью их добычи.
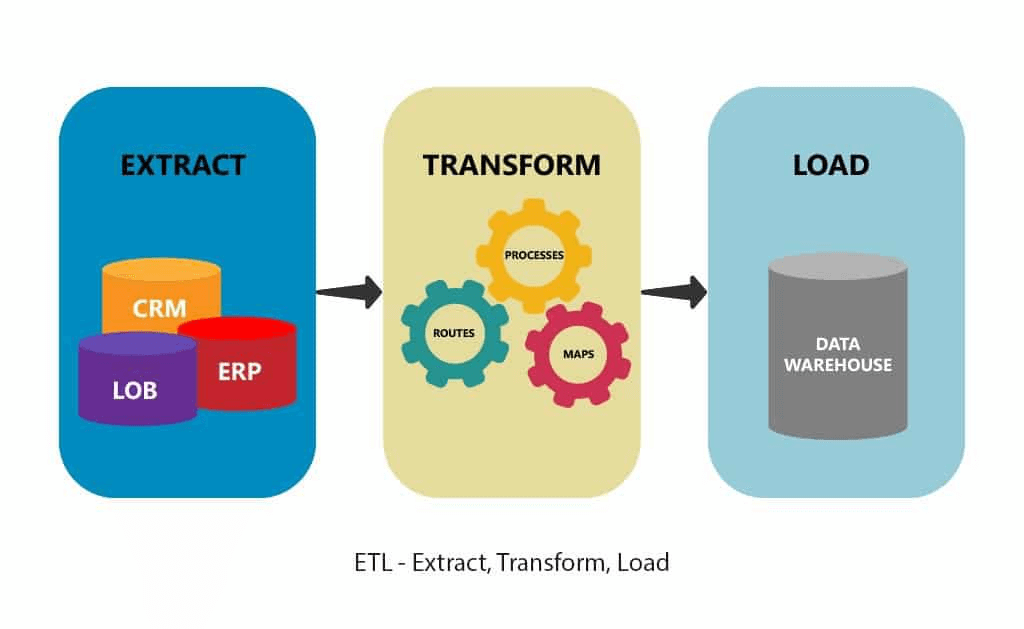
Извлечение, преобразование, загрузка
В то время как data mining — это получение информации из больших массивов данных, data extraction — это гораздо более короткий и простой процесс. Его можно свести к трем этапам:
- Выбор источника данных
Выберите источник, данные из которого вы хотите извлечь, например, веб-сайт. - Сбор данных
Отправьте «GET» запрос на сайт и проанализируйте полученный документ HTML с помощью языков программирования, таких как Python, PHP, R, Ruby и др. - Хранение данных
Сохраните данные в своей локальной базе данных или в облачном хранилище для будущего использования. Если вы опытный программист, который хочет извлечь данные, вышеуказанные шаги могут показаться вам простыми. Однако, если вы не программируете, есть короткий путь — использовать инструменты извлечения данных, например Octoparse. Инструменты data extraction, так же как и инструменты data mining, разработаны для того, чтобы сэкономить энергию и сделать обработку данных простой для всех. Эти инструменты не только экономичны, но и удобны для начинающих. Они позволяют пользователям собирать данные в течение нескольких минут, хранить их в облаке и экспортировать их во многие форматы: Excel, CSV, HTML, JSON или в базы данных на сайте через API.
Недостатки Data Extraction
- Сбой сервера
При извлечении данных в больших масштабах веб-сервер целевого сайта может быть перегружен, что может привести к поломке сервера. Это нанесет ущерб интересам владельца сайта. - Бан по IP
Когда человек слишком часто собирает данные, веб-сайты могут заблокировать его IP-адрес. Ресурс может полностью запретить IP-адрес или ограничить доступ, сделав данные неполными. Чтобы извлекать данные и избегать блокировки, нужно делать это с умеренной скоростью и применять некоторые методы антиблокировки. - Проблемы с законом
Извлечение данных из веба попадает в серую зону, когда дело касается законности. Крупные сайты, такие как Linkedin и Facebook, четко заявляют в своих условиях использования, что любое автоматическое извлечение данных запрещено. Между компаниями было много судебных исков из-за деятельности ботов.
Ключевые различия между Data Mining и Data Extraction
- Data mining также называется обнаружением знаний в базах данных, извлечением знаний, анализом данных/шаблонов, сбором информации. Data extraction используется взаимозаменяемо с извлечением веб-данных, сканированием веб-страниц, сбором данных и так далее.
- Исследования data mining в основном основаны на структурированных данных, тогда как при извлечении данных они обычно извлекаются из неструктурированных или плохо структурированных источников.
- Цель data mining — сделать данные более полезными для анализа. Data extraction — это сбор данных в одно место, где они могут быть сохранены или обработаны.
- Анализ при data mining основан на математических методах выявления закономерностей или тенденций. Data extraction базируется на языках программирования или инструментах извлечения данных для обхода источников.
- Цель data mining — найти факты, которые ранее не были известны или игнорировались, тогда как data extraction имеет дело с существующей информацией.
- Data mining сложнее и требует больших вложений в обучение людей. Data extraction при использовании подходящего инструмента может быть чрезвычайно простым и экономичным.
Мы помогаем начинающим не запутаться в Data. Специально для хабравчан мы сделали промокод HABR, дающий дополнительную скидку 10% к скидке указанной на баннере.

- Обучение профессии Data Science с нуля
- Онлайн-буткемп по Data Science
- Обучение профессии Data Analyst с нуля
- Онлайн-буткемп по Data Analytics
- Курс «Python для веб-разработки»
Eще курсы
- Курс по аналитике данных
- Курс по DevOps
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
- Профессия Java-разработчик с нуля
- Курс по JavaScript
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Продвинутый курс «Machine Learning Pro + Deep Learning»
