Комментарии 36
from numba import int32, deferred_type, optional
from numba.experimental import jitclass
node_type = deferred_type()
spec = OrderedDict()
spec['data'] = int32
spec['next'] = optional(node_type)
@jitclass(spec)
class LinkedNode(object):
def __init__(self, data, next):
self.data = data
self.next = next
def prepend(self, data):
return LinkedNode(data, self)
node_type.define(LinkedNode.class_type.instance_type)
С учетом активно развивающейся концепции аннотации типов и усовершенствованием парсера синтаксиса, мы скором получим динамический язык, который путем расстановки типов в ключевых местах (и их автоматического вывода) можно ускорить практически до скорости языка C.
А можно подробнее, как частичная типизация помогает убрать лок в интерпретаторе?
- Типы и структуру входных и выходных параметров.
- Типы переменных в самой функции строго зависят от входных параметров или являются элементарными типами.
Тогда для такой функции мы можем выйти из python интепретатора, освободить GIL, скомпилировать код в нэйтив для данной платформы, выполнить его и вернуться обратно в интепретатор. Самый удобный пакет сейчас для такого это numba, которая основана на LLVM.
Самое главное, что вся эта внутренняя работа абослютно незаметна для программиста. Все что нужно, это просто расставить типы. Уже как несколько лет такой подход идеально работает для математических вычислений в python, основанных на numpy array. Сам numpy array представляет собой python обертку над линейными областями памяти, поэтому для таких данных код генерируется очень хороший.
Для примера, рассмотрим следующую задачу.
Постановка задачи
Даны два набора из N точек в трехмерном пространстве. Необходимо посчитать матрицу попарных регуляризированных обратных расстояний. В нашем пример N = 5000.
def main():
""" For the given points set calculate RBF matrix
base on regularized inverse distances.
Input data:
-----------
p = [[p0_x, p0_y, p0_y],
[p0_x, p0_y, p0_y],
...
[pN_x, pN_y, pN_y]]
q = [[q0_x, q1_x, ..., qN_x],
[q0_y, q1_x, ..., qN_x],
[q0_z, q1_z, ..., qN_z]]
Output data:
-----------
R = [[f(p0, q0), f(p0, q1), ..., f(p0, qN)],
[f(p1, q0), f(p1, q1), ..., f(p1, qN)],
...
[f(pN, q0), f(pN, q1), ..., f(pN, qN)]],
where f(p, q) = 1 / (1 + |q - p|)
"""
N = 5000
p = np.random.rand(N, 3)
q = np.random.rand(3, N)
Чистый код на Python
def get_R_py(p, q):
R = np.empty((p.shape[0], q.shape[1]))
for i in range(p.shape[0]):
for j in range(q.shape[1]):
rx = p[i, 0] - q[0, j]
ry = p[i, 1] - q[1, j]
rz = p[i, 2] - q[2, j]
R[i, j] = 1 / (1 + math.sqrt(rx * rx + ry * ry + rz * rz))
return R
Время работы: 100.479 c.
Это очень долго. Теперь начинается магия!
Последовательная реализация с аннотацией типов
from numba import float64, jit
@jit(float64[:, :](float64[:, :], float64[:, :]), nopython=True, nogil=True)
def get_R_numba_sp(p, q):
R = np.empty((p.shape[0], q.shape[1]))
for i in range(p.shape[0]):
for j in range(q.shape[1]):
rx = p[i, 0] - q[0, j]
ry = p[i, 1] - q[1, j]
rz = p[i, 2] - q[2, j]
R[i, j] = 1 / (1 + math.sqrt(rx * rx + ry * ry + rz * rz))
return R
Время работы: 0.154 с, ускорее примерно в 700 раз. И все, что мы для этого сделали, по большому счету, только проставили типы.
Параллельная реализация с аннотацией типов
Ну ладно, а как на счет параллельности и GIL? Почти без изменений:
@jit(float64[:, :](float64[:, :], float64[:, :]), nopython=True, nogil=True, parallel=True)
def get_R_numba_mp(p, q):
R = np.empty((p.shape[0], q.shape[1]))
for i in prange(p.shape[0]):
for j in range(q.shape[1]):
rx = p[i, 0] - q[0, j]
ry = p[i, 1] - q[1, j]
rz = p[i, 2] - q[2, j]
R[i, j] = 1 / (1 + math.sqrt(rx * rx + ry * ry + rz * rz))
return R
Мы добавили а) parallel=True в аннотацию и б) во внешнем цикле range заменили на prange.
Время работы: 0.47 с, ускорение по сравнения с последовательной версией примерно в 3.3 раза, что неплохо для моего четырехядерного лаптопа.
И что дальше?
Уже как несколько лет это работает идеально для математики и numpy array. Но разработчики numba пошли гораздо дальше. Очень важный момент, что такой же аннотацией типов код можно скомплировать и для GPU. Кроме того, стали поддерживаться почти все python типы, включая типизированные List, Dict, а также спецификации для классов, что я показывал выше. А в планах тесная интеграция с python type annotations.
Сейчас репозиторий на GitHub очень активный, около 170 контрибьюторов. И мне нравится, как развивается этот проект.
Так, вроде, трюки с компилированием в нэйтив для числодрлбилок еще во 2м питоне были. Да, интересно, что всё больше сахара появляется, но сам интерпретатор как лочился, так и лочится. Конечно, приятно, что меньше возни руками для перехода в скомпилированый код.
Ну и в примере вы не просто и не столько типы проставили, а получили возможность в native скомпилировать, подключив numba, что, в принципе, типов могло и не требовать.
Естественно, что jit выиграет у интерпретатора на вычислительной задаче — это уже лет 15 не новость. С гораздо меньшим удобством замену range на prange и руками можно было бы сделать, тут, бесспорно, авторы молодцы.
Но, опять же, из самого питона GIL никуда не делся, вы просто «незаметно» вышли из него, но если вам понадобится что-то в интерпретируемом коде — вы снова залочитесь в одном потоке.
И я вижу, как это дальше развивается. Numba тесно интегрируется с аннотацией типов python и поддерживает все больше и больше чистых python структур, а не только numpy array. Все те функции python, для которых возможно полное выведение типов, будут скомпилированы в native и свободны от GIL, при этом будут бесшовно сшиваться с python интерпретаторами.
Это похоже на концепцию языка julia, где авторы создали динамический язык, способный к автоматическому выведению типов. Правда в julia они начали с того, что обрезали все те возможности языка, для которых такое выведение типов невозможно.
Python идет примерно по той же дороге, выделяя то подмножество языка, для которого это возможно, и шаг за шагом расширяет это подмножество.
Время работы: 0.154 с, ускорее примерно в 700 раз. И все, что мы для этого сделали, по большому счету, только проставили типы.
Время работы: 0.47 с, ускорение по сравнения с последовательной версией примерно в 3.3 раза, что неплохо для моего четырехядерного лаптопа.
Получается вроде бы наооборот замедление в 3 раза. или там 0,047?
А почему эти аннотации не могут тайпхинты юзать? Выглядят они жутко, если честно.
Но в ближайших планах как раз и перейти на тайпхинты с поддержкой все большего количество чистых пайтоновских структур данных.
class Point:
... x, y ...
def dist_to(self, p): ...
class Rect:
... p1, p2 # of type Point ...
def process(rects): # n-dim array of Rects
for r in rects:
...
r.p1.dist_to(r.p2)
...
Бонусом: чтобы при этом можно было (почти) не меняя кода принимать не array-of-structs, а struct-of-arrays для производительности.
Если оставаться чисто в парадигме вложенных классов, я бы это сделал через @jitclass, как в jitclass.py и в binarytree.py.
Другой вариант вместо python классов использовать Numpy Strutured Array и их поддержку в Numba, structures.py.
Дело в том, что это перевод статьи с Towards Data Science. У них есть неплохие статьи про Data Science, но статьи по питону у них обычно откровенно слабые.
Оно и понятно. Датасаентисты обычно питон не очень хорошо знают. Им это на самом деле не нужно.
Тайп хинтинг
По Вашему описанию непонятно. Тайп хинтинг был начиная с 3.5 (как указано в статье), но его синтаксис был был таким же (в 3.6 добавились хинты переменных). Как я понял отсюда (What's new in Python 3.9) добавлены built-in generic types: PEP 585.
Т.е. если раньше для описания типа словаря нам нужно было использовать Dict из модуля typing (напр. Dict[str, int]), то теперь можно использовать обычный dict (напр. dict[str, int]).
А если сравнивать два скриншота, приведенные вами:
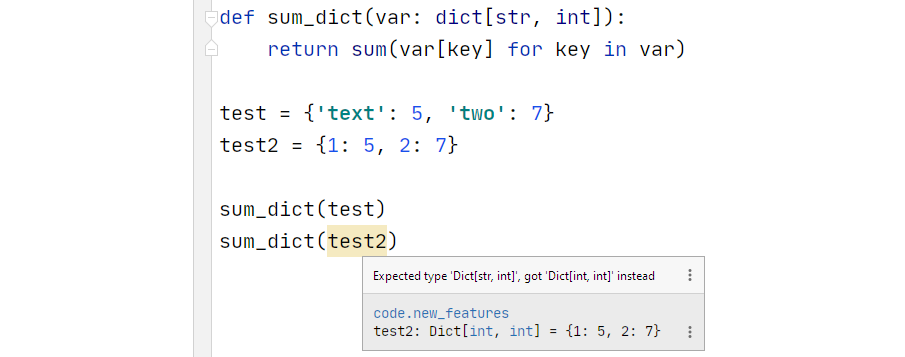
и благодаря новому синтаксису он теперь выглядит намного чище:

Во втором примере у Вас менее строгие ограничения на тип, вы не указали аргументы Generic'а. И можно будет любой dict в функцию передать. Что, в прочем, можно было сделать и раньше питона 3.9.
P.S. Я всегда буду обновлять комментарии перед отправкой, я буду всегда буду...
Эта проблема подчеркивает, что следующий код просто не может быть реализован с использованием текущего синтаксического анализатора (вызывает ошибку SyntaxError)
Вот как раз это никогда не было большой проблемой, просто токенайзер для "with" кривой, и простейщий lookahead для скобки как в тех же выражениях (и кортежах) был бы достаточен.
К чему они привязали issue12782 к PEG-based parser мне неведомо, ибо тот lookahead без необходимости backslash-ить существует с версий 2.5 или 2.6 если мне не изменяет память.
Сравните:
-with (open("a_really_long_foo") as foo,
- open("a_really_long_bar") as bar):
+if (open("a_really_long_foo") == foo,
+ open("a_really_long_bar") == bar):
passТ.е. алгоритм простой и в случае with и простейшим lookahead (открытая скобка) должен включаться "режим" auto-escape для NL, пока не найдена парная закрывающая скобка, точно также как это уже делается в доброй сотне других случаев.
Почему надо было ждать 3.9 чтобы это пофиксить я кроме как ленью долгоиграющей стратегией или идеей фикс "пересадить всех на новые версии" объяснить не могу.
Здесь оно и не сильно надо как бы (многострочный with можно тупо пробэкслэшить), но проблема в том, что они вообщем часто забывают, что многие системы либо еще очень долго, либо совсем не обновятся до 3.9… Т.е. абсолютно всё (даже подобные простейшие вещи) можно использовать только в проектах под >= 3.9.
Нафига removeprefix если есть re.sub?
регулярки сложные по своей сути
Написать, скомпилировать, запустить регулярное выражение или сделать все в нативном коде?
Второе явно быстрее и читаемее.
Такое ощущение, что язык усложняется и становится похожим на другие языки, из которых люди идут в питон за простотой. Жажда скорости не знает границ. Не таким уж и бессмысленным кажется то, что некоторые люди остаются на втором питоне, даже при том, что у них нет каких-то проектов, которые придётся переписывать.
Развитие — это процесс, при котором идёт в большей степени улучшение. Пока что у нас развитие, но не потеряется ли первоначальный смысл языка в погоне за скоростью и возможностью удовлетворить всех и вся?
Но что плохого в ускорении? Понадобилось мне в django проекте много математики, я за пару часов перевел проект на python 3, нагуглил про numba и время выполнения ресурсоемкой функции у меня упало с 10 секунд до 0.1 секунд.
Ничего нет плохого в ускорении, пока оно не идёт во вред другим плюсам языка, например понятности. Это извечный спор о том, оправдывает ли цель средства. Или то, что лучшее враг хорошего. У нас огромное количество примеров в любой сфере нашей жизни, что как только прекращается позитивное развитие, начинается деградация. C++ долгое время активно развивался, добавляя конструкции, позволяющие писать всё и вся. Тем не менее всё чаще возникают темы касательно того, а не пора ли его чистить от переизбытка хлама и делать более дружелюбным. Бешеная скорость и обширные возможности совсем не делают людей счастливыми. Вот я и боюсь, не превратят ли python в подобие C++. Мои опасения совсем не означают, что я олдфаг и противник всего нового. Python 3 во многих вещах мне нравится больше 2-го. Просто не надо делать из питона язык на все случаи жизни. У нас таких полно, на любой вкус.
А вот "=| " мне вообще не понятно зачем вводить. Есть же a.update(b) — как по мне более явный синтаксис
Слава Си и Перла не даёт покоя, наверное.
Видимо, по аналогии с множествами. Для них как раз оператор |= переопределён для вливания второго множества в первое.
оператор "+" тоже обсуждался и даже был в первом варианте, но многие были против него из за отсутствия коммутативности у объеденения словарей (т.е d1 + d2 ≠ d2 + d1). Якобы это будет смущать программистов.
В общем линтер похоже пополнится новыми правилами.
Для списков и строк мы не потеряем значения, используя "+". А вот в словарях при совпадении ключей можем потерять, причём это зависит от того, какой словарь будет первым.
Но вообще я думаю что никакой оператор вводить не надо было. Есть и так куча способов объеденения словарей. Самый явный из них, на мой взгляд, это {**d1, **d2}.
По поводу объединения словарей: я давно использую собственную функцию для этих целей, а именно
def merge_dicts(d1, d2, merge_value_func=None):
d_result = d1.copy()
for key, value in d2.items():
if key in d1:
if merge_value_func is None:
d_result[key] = value
else:
d_result[key] = merge_value_func(d_result[key], value)
else:
d_result[key] = value
return d_resultЗдесь имеется дополнительный параметр merge_value_func. Он позволяет скомбинировать в новом словаре значения для одних и тех же ключей в исходных словарях, например:
d1 = { 1 : 'a' }
d2 = { 1 : 'b' }
d = merge_dicts(d1, d2, lambda s1, s2: s1 + s2)Результат:
{1: 'ab'}в чём новость тайп хинтинга?
Спасибо за обзор!
"Обзор на лучших функций" — на лучшие функции.
Изменения на 90% — сахар. Тайп хинтинг точно так же юзаем в 3.7, если честно, не совсем понял, что изменилось
Новые фичи в Python 3.9