
Я решил написать статью для тех, кто пытается найти актуальные вопросы и ответы для собеседований в Amazon. Я взял несколько вопросов с собеседований, которые задавали в последние месяцы, и попытался дать краткие и понятные ответы на них. Есть вопросы сложные, есть — простые, но в любом случае могут пригодиться и те, и другие.
В: У пары есть двое детей, и пара знает, что один из детей — мальчик. Какова вероятность того, что другой ребенок будет мальчиком?
Здесь нет подвоха. Вероятность того, что один ребенок будет мальчиком, не зависит от другого, поэтому она равна 50%. Вы можете запутаться из-за вопроса Леонарда Млодинова, где ответ — одна треть, но это совершенно другой вопрос, не относящийся к нашему.
В: Объясните, что такое p-значение.
Если вы погуглите, что такое p-значение, то получите такой ответ: «Это вероятность получить для данной вероятностной модели распределения значений случайной величины такое же или более экстремальное значение статистики (среднего арифметического, медианы и др.), по сравнению с ранее наблюдаемым, при условии, что нулевая гипотеза верна».
Многословный ответ, по той причине, что значение p очень специфично по значению и часто понимается неправильно.
Более простое определение p-значения: «Это вероятность того, что наблюдаемая статистика возникнет случайно, с учетом распределения выборки».
Альфа устанавливает стандарт того, насколько экстремальными должны быть значения, прежде чем нулевая гипотеза может быть отклонена. Значение p указывает на крайность данных.
В: Есть 4 красных и 2 синих шара, какова вероятность того, что они будут одинаковыми в двух выборах?
Ответ равен вероятности того, что оба красные, плюс вероятность того, что оба синие. Предположим, что этот вопрос без замены.
- Вероятность 2 красных = (4/6) * (3/6) = 1/3 или 33%
- Вероятность 2 синих = (2/6) * (1/6) = 1/18 или 5,6%
Следовательно, вероятность того, что шары будут одинаковыми, составляет примерно 38,6%.
Q: Опишите дерево, SVM и случайный лес. Расскажите об их преимуществах и недостатках.
Деревья решений: древовидная модель, используемая для моделирования решений на основе одного или нескольких условий.
Плюсы: легко реализовать, интуитивно понятно, обрабатывает пропущенные значения.
Минусы: высокая дисперсия, неточность
Плюсы: точность при большой размерности
Минусы: склонность к чрезмерной подгонке, не дает напрямую оценок вероятности
Плюсы: может достигать более высокой точности, обрабатывать отсутствующие значения, масштабирование функции не требуется, может определять важность функции.
Минусы: черный ящик, интенсивные вычисления.
Снижение размерности — это процесс уменьшения количества функций в наборе данных. Это важно в основном в том случае, когда вы хотите уменьшить дисперсию своей модели (переобучение).
В Википедии говорится о четырех преимуществах уменьшения размерности:
- Сокращает необходимое время и место для хранения.
- Удаление мультиколлинеарности улучшает интерпретацию параметров модели машинного обучения.
- Становится легче визуализировать данные при уменьшении до очень малых размеров, таких как 2D или 3D.
- Избегает “проклятия размерности”.
Нам нужно сделать некоторые предположения по этому вопросу, прежде чем мы сможем на него ответить. Предположим, что есть два возможных места для покупки определенного товара на Amazon, и вероятность найти его в месте A составляет 0,6, а B — 0,8. Вероятность найти товар на Amazon можно объяснить так:
Мы можем переформулировать вышеизложенное как P (A) = 0,6 и P (B) = 0,8. Кроме того, давайте предположим, что это независимые события, а это означает, что вероятность одного события не зависит от другого. Затем мы можем использовать формулу…
P (A или B) = P (A) + P (B) — P (A и B)
P (A или B) = 0,6 + 0,8 — (0,6 * 0,8)
P (A или B) = 0,92
В: Если есть 8 шариков равного веса и 1 шарик, который весит немного больше (всего 9 шариков), сколько взвешиваний необходимо, чтобы определить, какой шарик самый тяжелый?

Потребуются два взвешивания (см. Части A и B выше):
Вы должны разделить девять шариков на три группы по три и взвесить две группы. Если весы уравновешиваются (вариант 1), вы знаете, что тяжелый шарик относится к третьей группе шариков. В противном случае вы возьмете группу с большим весом (вариант 2).
Затем вы выполните тот же шаг, но у вас будет три группы по одному шарику вместо трех групп по три.
Q: Что такое «переобучение»?
Переобучение — это ошибка, когда модель слишком хорошо «подходит» к данным, что приводит к модели с высокой дисперсией и низким смещением. Как следствие, модель с переобучением будет неточно предсказывать новые точки данных, даже если она имеет высокую точность данных обучения.
Q: У нас есть две модели: одна с точностью 85%, другая — 82%. Какой ты выберешь?
Если нам важна лишь точность модели, то ответ — 85%. Но если бы об этом спросил интервьюер, вероятно, стоит узнать, в каком контексте задан вопрос, т.е. что модель пробует предсказать. Это даст нам лучшее представление о том, действительно ли метрикой оценки должна быть точность или другая метрика, такая как recall или оценка f1.
Q: Что такое наивный байесовский алгоритм?
Наивный байесовский классификатор — популярный классификатор, используемый в Data Science. Идея, лежащая в основе этого, основана на теореме Байеса:

Говоря простым языком, это уравнение используется для ответа на следующий вопрос. «Какова вероятность y (моей выходной переменной) при X (моих входных переменных)? И из-за наивного предположения, что переменные независимы для данного класса, вы можете сказать, что:

Кроме того, убрав знаменатель, мы можем сказать, что P (y | X) пропорционально правой части.
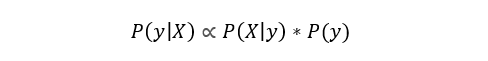
Поэтому цель — найти класс с максимальной пропорциональной вероятностью.
Q: Как изменение основного членского взноса повлияет на рынок?
Я не уверен на 100% в ответе на этот вопрос, но постараюсь сделать все возможное!
Давайте возьмем пример увеличения основного членского взноса — в нем участвуют две стороны: покупатели и продавцы.
Для покупателей влияние увеличения основного членского взноса в конечном итоге зависит от эластичности спроса по цене для покупателей. Если эластичность цены высока, то данное повышение цены приведет к значительному падению спроса и наоборот. Покупатели, которые продолжают покупать членские взносы, вероятно, являются самыми лояльными и активными клиентами Amazon — они также, вероятно, будут уделять больше внимания продуктам с премией.
Продавцы пострадают, так как теперь стоимость покупки корзины продуктов Amazon выше. При этом некоторые продукты пострадают сильнее, в то время как другие могут не пострадать. Вполне вероятно, что продукты премиум-класса, которые покупают самые лояльные клиенты Amazon, пострадают не так сильно, как электроника.
Спасибо за внимание!
Что мне нравится в этих собеседованиях и рассматриваемых на них проблемах, так это две вещи:
- Они помогают вам изучить новые концепции, с которыми вы до этого не были знакомы.
- Они открывают концепции, которые вы знаете, с новой стороны.
Надеюсь, все это поможет вам в подготовке к вашему путешествию в мир Data Science!
Комментарий к статье Вячеслава Архипова, специалиста в области Data Science AR-стартапа Banuba и консультанта по учебной программе онлайн-университета Skillbox.
Подборка вопросов охватывает широкий спектр тем, в которых должен ориентироваться дата-сайентист: теория вероятностей, статистика, машинное обучение и даже экономика. Правильные ответы на вопросы и умение рассуждать покажут «ширину» знаний соискателя.
Но среди этих вопросов нет ни одного «со звездочкой». На этот стандартный набор вопрос ответит практически любой выпускник ВУЗа. Если бы я проводил собеседование, то добавил бы парочку вопросов, вскрывающих знание не только стандартных определений, но и тонких нюансов.
Ну например:
1) Как можно получить случайную величину с заданным распределением, имея в наличие реализацию нормальной СВ?
2) Что такое корреляция случайных величин и какова ее геометрическая интерпретация?
3) Как можно бороться с переобучением?
4) В чем преимущество метода главных компонент по сравнению, например, с процессом Грама-Шмидта?
5) Как можно улучшить классификацию, имея набор слабых классификаторов?
А так же у меня возник бы вопрос к соискателю, почему он приводит в качестве источника информации именно Википедию и по каким материалам еще он учился.
