Комментарии 89
Давайте проясним один момент. Внутри процессора x86 нет RISC-составляющей. Это просто маркетинговый ход.
Папа-компьютерщик из Осло(подпись автора), видимо не в курсе, что RISC-ядро появилось в x86 уже в Pentium Pro.
Все так просто?
RISC-подобные микроинструкции в P6, конечно, имеются. Но сама философия RISC (https://www.gartner.com/en/information-technology/glossary/risc-reduced-instruction-set-computer) стремится исключить микрокод (в RISC-V как раз для упрощения аппаратной реализации (экономии мультиплексоров) для некоторых операндов весьма замороченный порядок битов (кто возился с RISC-V эмуляторами, поймет :-). Недаром для RISC-V такое внимание уделяется тестированию чуть ли не всех возможных битовых комбинаций в командах.
Но дальнейшее развитие CISC-процессоров пошло как раз в направлении реализации все большего количества CISC-инструкций аппаратными блоками (расхожий пример — цена AESENC — 1 uops (https://www.agner.org/optimize/instruction_tables.pdf)).
Но есть и контрпример — в VIA C3 можно было добраться до инструкций RISC-ядра (https://en.wikipedia.org/wiki/Alternate_Instruction_Set).
Хотя и в самом RISC-V есть некоторое отклонение от "линии партии", а именно, многообразие расширений RISC-V. Причем многие из них можно эмулировать стандартным RV32(64)I, что на первый взгляд нарушает "no instruction or addressing mode whose function can be implemented by a sequence of other instructions should be included in the ISA", но есть удобная оговорка "unless its inclusion can be quantitatively shown to improve performance" (https://www.realworldtech.com/risc-vs-cisc/).
Все так просто?
Не все просто, но то, что современные x86 risc это да.
Поэтому
Вероятно, вы слышали, что M1 — процессор с архитектурой ARM, а ARM — это RISC, в отличие от Intel и AMD.
вводит как минимум в заблуждение.
Второй момент, что реализация Risc у всех разная, отсюда у нас всякого рода атаки на память.
В комментариях к статье "ZX Spectrum из коронавируса и палок (на самом деле, не совсем)" этот вопрос, что и откуда растет, достаточно полно обсуждался. Я же повторю еще раз цитату "RISC это не технология, RISC это стратегия дизайна. Когда то RISC был бунтом против норм, сейчас он — норма"
Надеюсь что расставленные точки над i, не вызовут очередного витка противостояния.
Кстати, интересно а этот Alternate Instruction Set где нибудь подробно описан, или задокументирован? Ну что его можно было использовать? К примеру насколько сложно было бы перенести к примеру Linux? И насколько был бы VIA C3 быстрее в родном режиме? Точнее сколько ресурсов съедает интерпретация x86 в нативные RISC инструкции?
Там цепочка ссылок с цитатами, собственные слова этого Боба Колуэлла можно прочесть тут: www.quora.com/Why-are-RISC-processors-considered-faster-than-CISC-processors/answer/Bob-Colwell-1
потому что в прошлом веке ещё была такая альтернатива — или сложные многотактовые команды, или сокращенные однотактовые.
Сейчас такой альтернативы нет — все команды на современных процессорах выполняются за 1 такт. что CISC, что RISC
А вся борьба за производительность идет на уровне производительности чтения из памяти.
Ключевая проблема архитектуры х86 — это переменная длина команды
Все команды не могут выполнятся за один такт это явно неправда. Простейшие примеры это как раз команды доступа к памяти которые выполняются очень долго. Или например всякие команды связанные с atomic операциями, которые требуют синхронизации ядер между собой
обсуждение скорости выполнения команд CISC/RISC относится исключительно к процессорному ядру.
Сама команда загрузки выполняется за 1 такт. + время ожидания готовности памяти
дальнейшее выполнение программы не может быть продолжено пока не команда не завершилась успешно. Соответственно фактическое время выполнения команды load будет 1 такт если значение есть в кеше либо же 1 такт + время ожидания значения из основной памяти. Вот это время ожидание это момент когда процессор фактически простаивает и может заняться чем то другим. Out-Of-Order execution может применяться для выполенения других команд которые не зависят от ожидания значения из памяти.
Либо же можно выполнять команды из другого потока (Hyper Threading)
Сейчас такой альтернативы нет — все команды на современных процессорах выполняются за 1 такт.
Это вряд ли. Как минимум ряд инструкций из AES-NI (например, aesdec), насколько я знаю, выполняются отнюдь не за 1 такт — latency там может быть от 4 до 8 тактов в зависимости от конкретной архитектуры, даже если оба операнда — регистры.
очень-очень рядом :)))))
там где-то в середине статьи приводится пример команд, где покороче у х86 и подлиннее у арм :)
из-за чего в интеле 4 декодера, и то с трудом, а у м1 восемь, без особого труда :)))
То что длинна команд может в СISC большая быть, не делает его VLIW.
из-за чего в интеле 4 декодера, и то с трудом,
А ничего что в Skylake 5 декодеров, причем 1 из них сложный декодер, который способен 1-4 микрооперации давать?
VLIW — qualcomm hexagon dsp. Вот одна инструкция:
{ R17:16 = MEMD(R0++M1)
MEMD(R6++M1) = R25:24
R20 = CMPY(R20, R8):<<1:rnd:sat
R11:10 = VADDH(R11:10, R13:12)
}:endloop0
Я очень хочу процессор, который все команды выполняет за один такт (и тактов с секунду много). А то как только деление f64, так всё, пошло муржить.
Так в х86 уже давно придумали, конвейер!) Просто шли инструкции потоком и будут тебе твои f64/такт
Вы сильно переоцениваете производительность float-point деления. Вот результаты бенчмарка. Это мой рабочий ноутбук примерно 4х-летней давности.
Вот код бенчмарка:
use criterion::{black_box, criterion_group, criterion_main, Criterion};
pub fn fdiv(c: &mut Criterion) {
c.bench_function("fdiv", |b| b.iter(
||{
let mut base: f64 = 1e308;
for x in 0..1000{
base = black_box(base/11.11);
}
}
));
}
criterion_group!(bench, fdiv);
criterion_main!(bench);Что тут видно? 1000 тел цикла выполняется за 8.74us, т.е. 8.7 ns на каждую операцию. Каждая операция внутри — это inc, cmp, jmp и, собственно, fdivl. Мой процессор работает на частоте 2.40GHz, т.е. один тик — это 416ps. 8.74ns/0.416 — это 20 тиков. Как вы думаете, сколько из этих тиков приходится на inc/cmp/jmp, и сколько на fdivl? Я даже не уверен, что там есть jmp, или там внутри честный loop unrolling.
Я полез искать — со времён K7 не сильно всё поменялось. Там тоже обещали 11-25 тиков latency для fdiv.
Ну вот у меня есть 2D геометрическая область, заданная парой точек (итого 4 точки). Мне нужно её разделить на NxN областей (можем на случае 2х2 сфокусироваться).
Как?
Сейчас код дуболомный:
pub fn split(&self) -> [Self;4]{
let len_x = (self.end.x - self.start.x) / 2.0;
let len_y = (self.end.y - self.start.y) / 2.0;
[
Self::from_coords(self.start.x, self.start.y, self.start.x + len_x, self.start.y + len_y),
Self::from_coords(self.start.x + len_x, self.start.y, self.end.x, self.start.y + len_y),
Self::from_coords(self.start.x, self.start.y + len_y, self.start.x + len_x, self.end.y),
Self::from_coords(self.start.x + len_x, self.start.y + len_y, self.end.x, self.end.y),
]
}(from_coords — конструктор для Boundry, которую я и режу в split).
Как мне вот этот /2.0 убрать?
А вот вопрос — будет ли оно быстрее.
1000 делений на 2.0 — это 443.17 ns
А вот умножения на 0.5:
fdiv time: [442.59 ns 442.84 ns 443.11 ns]
change: [-0.0256% +0.0292% +0.0863%] (p = 0.30 > 0.05)
No change in performance detected.Не видно разницы.
Код:
pub fn fdiv(c: &mut Criterion) {
let mut base = [1e308f64;1000];
c.bench_function("fdiv", |b| b.iter(
||{
for i in 0..1000{
base[i] = black_box(base[i]*0.5);
}
}
));
}… а вот без конвейеризации
2.5865 us -> 2.5861 us
Всё равно нет разницы. Умножение и деление — либо хорошо оптимизированы для простых случаев, либо считаются за одинаковое время.
Вы помните, что это floating point? Я не уверен, что умножение на 0.5 сильно быстрее деления. Кстати, а какой алгоритм умножения для f64?
Насчёт миллиардов — это criterion. Он сделал больше 5 миллионов итераций функции (1000 чисел) для статистически значимых результатов. Если он говорит, что "разницы нет", значит нет.
Это потрясающая задача. Ассемблер бенчмарка — больше 10 мегабайт текста (сам бенчмарк имеет много интересных опций, таков уж criterion). Я попытаюсь завтра ответить на ваш вопрос, но мне придётся сначала научиться раст генерировать код в отдельные объектные файлы и т.д. Задача интересная и полезная...
Я попытаюсь завтра ответить на ваш вопрос
Получилось?
Кстати, если это 64-битный режим, то по умолчанию SSE — то есть если вообще деление осталось, то будет divsd, а не fdiv (и, возможно, векторизованное).
Ой, я и забыл про исходный тредик. Я научился смотреть ассемблер, избавился от criterion (т.к. от него ассемблера слишком много из-за макросов), научился заставлять компилятор выносить нужную мне функцию в отдельную функцию no matter what, разобрался с феноменами деления и умножения (да, деление на степени двойки — это у множение на соотв. числа, умножение на 2 — сложение), написал статью на медиум по этим вопросам https://medium.com/journey-to-rust/viewing-assembly-for-rust-function-d4870baad941
А в тредик описать забыл, извините.
Интересно, если я black_box вокруг 2 использую, оно замаскирует?
… Замаскирует. Потрясающе.
change: [+87.133% +87.144% +87.156%] (p = 0.00 < 0.05)
Performance has regressed.
сравнивал не-пайплайновое:
base[0] = black_box(base[0]*black_box(0.5));
и
base[0] = black_box(base[0]/black_box(2.0));
А вот пайплайновое (умножение vs деление).
change: [-41.503% -41.452% -41.407%] (p = 0.00 < 0.05)
Performance has improved.
Офигеть. Самый полезный тред за этот месяц — сколько узнал...
Нет, criterion очень точный и делает очень много итераций, а вся история свелась к тому, является ли цифра 2.0 black box'ом или нет (т.е. может ли компилятор оптимизировать его).
https://habr.com/en/company/selectel/blog/542074/?reply_to=22687892#comment_22689838
сложение\вычитание — ~10-15 тактов
умножение\деление — ~5-8 тактов
Но это именно для fp32(или fp24, не помню уже) и он был не конвейерный. Есть всякие оптимизации которые больше «транзисторов» съедают, но я делал просто в лоб.
сложение\вычитание — ~10-15 тактов
умножение\деление — ~5-8 тактов
Не в обиду, но это ни о чём не говорит. Тут много нюансов. Вы ведь не перебирали пространство решений на поиск самой эффективной реализации? Если интересно, у Xilinx есть корочка Floating Point, где можно поиграться с кол-вом тактов, максимальной частотой и оптимизациями по ресурсам для операций с плавающей точкой.
Это я к чему, далеко не факт, что ваша реализация сойдется по таймингам или ресурсам для случая того же процессора, а если не сойдется, тогда что толку в 5 тактах деления?
"но я делал просто в лоб" — я написал, да, можно у фпу разными выкрутасами уменьшить такты на команду, но мне было интересно посмотреть банальные реализации по стандарту.
Тут какб кто как сделает. Но суть что не всё так очевидно, и деление может оказаться не таким уж и медленным.)
Зы Сижу на Altera там тоже есть параметрезируемые… Модули, но они как-то не интуитивно работают, настроил циферки, чота получил, а как оно работает ток боги знают (иди читай документацию на IP)
Как вы думаете, сколько из этих тиков приходится на inc/cmp/jmp, и сколько на fdivl?
Обратите внимание, что в вашем коде есть зависимости по данным, из-за чего следующую итерацию деления нельзя начинать до результата предыдущей.
Однако, если бы этой зависимости не было (вы бы делили независимые операнды), то получали бы результат каждый такт (при условии, что fdivl конвейеризировано и нет заморочек с обращением к кэшу и т.д.) и с latency во всё те же 20 тактов. Т.е. время выполнения было бы 430 нс или около того.
Спасибо за замечание. Я как раз и пытался сделать конвейер (ради этого 1000 была добавлена), но ступил. Сейчас проверю без зависимости.
let mut base = [1e308f64;1000];
for i in 0..1000{
base[i] = black_box(base[i]/11.11);
}
}fdiv time: [1.8966 us 1.8984 us 1.9004 us]
change: [-78.313% -78.259% -78.204%] (p = 0.00 < 0.05)
Performance has improved.(почесав в затылке я вынес let за пределы цикла, стало 1.6867 us)
Итого: 1.69ns на операцию, 4 тика. Если считать, что цикл — это 1 или 2 тика, мне делают fdiv за 1-2 тика. Сильно быстрее.
Я был не прав, оно хорошо конвейеризируется.
И уж добивая вопрос, на моём AMD 5600X тот же бенчмарк выдал 969.74ns. Что транслируется в 970ps на операцию, при частоте 3.7GHz это 270ps на тик, т.е. 3.5 тика на операцию. (Вот он прогресс процессоров за последние 10+ лет — с 4.1 тика до 3.5 тика).
В соседнем треде меня убеждают, что может (с учётом конвейеризации). Получается 3.5 тика на операцию (вместе с циклом).
Транзисторы умеют только складывать и сдвигать биты в регистрах.
Разные математические операции раскладываются в разное количество последовательного выполнения этих примитивов.
Я первый раз слышу про транзисторы, которые умеют складывать. Обычно нужна нереальная куча транзисторов даже для невинного XOR'а. Но это совершенно не отменяет возможности иметь аппаратную акселерацию сложных инструкций (в т.ч. за счёт ALU, которое бегает быстрее остального процессора).
Так а как оно будет бегать «быстрее остального процессора»? Одни транзисторы будут бегать быстрее других или как-то волшебно распараллелить? Так вот деление устроено так, что там особо не параллелизуется (как и синусы, корни etc).
Блок ALU, отвечающий за деление, работает на большей частоте, чем остальной процессор. Например, на 10-кратной. Процессор — на частоте в 3Гц, конкретная небольшая (пара десятков тысяч) транзисторов — на 30Ггц. Ещё можно иметь несколько блоков деления, когда каждое деление долго, но за счёт конвейеризации, аммортизированное время выполнения быстрее.
В целом, если видеокарты могут быстро делить, то и процессоры могут, было бы желание.
(И да, я подумываю о CUDA, ибо на проце медленно).
пруф?
>> Ещё можно иметь несколько блоков деления, когда каждое деление долго, но за счёт конвейеризации, аммортизированное время выполнения быстрее.
так разговор изначально был про «любая мат. операция за такт» =)
>> В целом, если видеокарты могут быстро делить, то и процессоры могут, было бы желание.
не могут)
Я говорю, что мне нужно иметь fpu, который (аммортизированно) считает 1 операция за такт. Исходный комментарий был о том, что мол, шли свои инструкции в конвейер и будет тебе 1 инструкция за такт (а я показал бенчмарком, что это очень не так).
Меня устраивает вариант "20 fpu операций за 20 тактов", если мне про это не надо будет думать (а компилятор справится).
деление f64 это обычное целочисленное деление 53-разрядных чисел.
Нет, далеко не всегда и не везде. Почитайте про Goldschmidt method — как минимум у AMD именно он. Про современный Intel я точных данных не слышал — во времена FDIV bug был SRT, который, да, целочисленный. Но с тех пор дети выросли и сами работают....
но тут (как уже написал кто-то) важно не превысить критическое время цикла
Совершенно не важно. Если известно, что блок деления выдаёт, например, 7 бит за время 3 тактов, поставят делитель тактовой на 3 — это совершенно банально. Если не скупиться, на каждую такую задачу есть несколько вариантов готовых блоков, как её сделать (для деления, например, можно пакован разных вариантов SRT заранее разработать) и выбирать, какой будет эффективнее на пару процентов, чем альтернативы.
Но это совершенно не отменяет возможности иметь аппаратную акселерацию сложных инструкций (в т.ч. за счёт ALU, которое бегает быстрее остального процессора).
Отменяет. Есть такое понятие «критический путь», грубо говоря, количество логических вентилей, которые обязательно должен пройти сигнал от регистра до регистра. Критический путь определяет максимальную тактовую частоту логики. Конвейера конструируются так, чтобы бегать на максимальной частоте, т.е. разбиваются на стадии в том числе с учетом минимизации критического пути. Все эти аппаратные акселерации действуют по тем же законам физики и должны будут укладываться в требуемый период конвейера. Если они не укладываются, их приходится разбивать на несколько тактов и тоже конвейеризировать. Вы хотите уместить много логики в 1 такт (аппаратный акселератор чего-то там), следовательно у вас вырастет критический путь и уменьшится частота. Вы упрётесь в физику, как и упоминали выше.
Далее, если же вы всё же какую-то мелкую операцию сможете заакселерировать быстрее такта основного процессора, то тут вам результат придется перевести в более медленную частотную область основного конвейера и этот перевод потребует нескольких тактов, так что в итоге всё равно проиграете.
не потому что он RISC, а потому что VLIW
У VLIW не бывает OoO, так что мимо.
Ключевая проблема архитектуры х86 — это переменная длина команды
На х86 есть кэши микроопов, CISC декодеры там большую часть времени вовсе стоят.
Сейчас такой альтернативы нет — все команды на современных процессорах выполняются за 1 такт. что CISC, что RISC
Это, мягко говоря, не правда: https://www.agner.org/optimize/instruction_tables.pdf
Можете убедиться, что даже целочисленное умножение занимает 3 такта.
Ключевая проблема архитектуры x86 (ИМХО) в том, что ради повышения производительности не за счёт повышения тактовой частоты пришлось наворотить огород с внеочередным выполнением команд. Например, в kaby lake 97 микро-операций может находиться в reservation station, а какие именно операции туда положить решает branch predictor, в котором чуть ли не нейросети принимают решение. А каждая микро-операция там — это теневая копия регистров. После спекулятивного исполнения на стадии retirement её пытаться встроить так, чтобы все думали, что там in-order исполнение было. Если вдруг какие-то зависимости между командами были — то результат внеочередного исполнения придётся выкинуть и попробовать сделать ещё раз. И вся эта массивно-параллельная конструкция спрятана за абсолютно линейным ISA, который ещё и даёт строгие гарантии на memory order.
Зато можно запустить говно мамонта, где-нибудь их 80-х. Почему Интел за это держится? Ну, как минимум они уже один раз попробовали с Itanium.
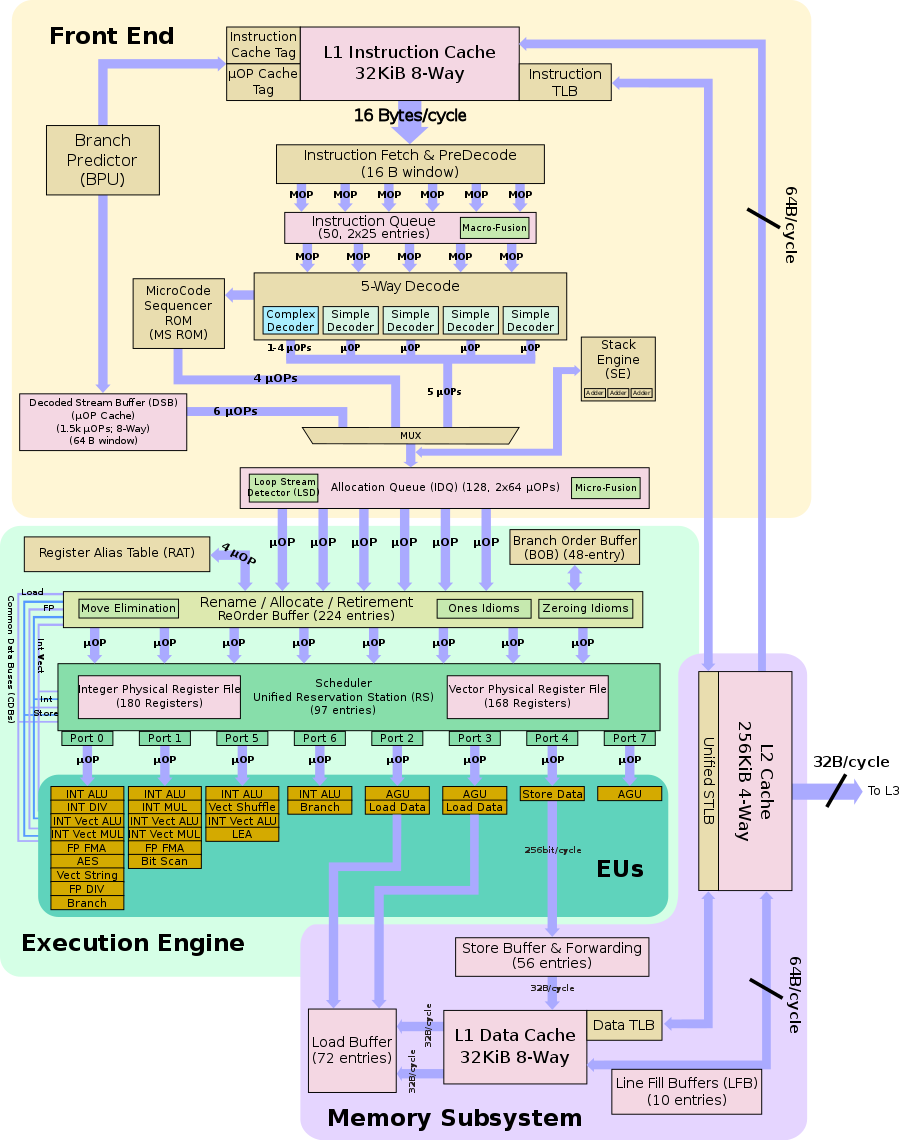
VLIW же в Итаниумах показал себя с настолько плохой стороны, что пришлось делать нормальный OoO бэкенд.
Работал в конторе, которая делает софт для всяких телекомов — это как раз те самые ребята, которые покупали Itanium. И там даже не с производительностью проблемы были (переносили не с x86, а со всяких проприетарных платформ типа HP-UX), а с тем, что надо было не просто пересобирать всё, а код переписывать, под модель памяти Itanium, в которой есть типы.
Ключевая проблема архитектуры x86 (ИМХО) в том, что ради повышения производительности не за счёт повышения тактовой частоты пришлось наворотить огород с внеочередным выполнением команд.
А что вы имеете против внеочередного выполнения? Эта тема отлично маскирует latency долгих операций (в том числе доступа в кэш и условных переходов) и позволяет более эффективно использовать ресурсы процессора. В целом, перечисленные вами методики — это набор классных инженерных решений, которые выжимают все соки из конструкции и при этом обеспечивают корректность результата.
Лично я — ничего :) Но по-факту — это же одна из самых сложных частей процессора, очень крутая в инженерном смысле, но очень сложная. И всё это спрятано от компилятора, хотя он мог бы очень даже хорошо тут помочь.
И всё это спрятано от компилятора, хотя он мог бы очень даже хорошо тут помочь.
Соглашусь, комбинация статического (компилятор) и динамического планирования должна оказаться ещё более выигрышной.
Отмечу, что совсем от этой сложности избавиться нельзя, эти навороты позволяют процессору эффективно планировать выполнение инструкций в реальном времени на основе текущей занятости своих ресурсов. Компилятор со своей колокольни предсказать может далеко не всё (т.е. компилятор сам по себе будет действовать более консервативно, а значит иметь меньше выигрыша). Itanium упоролся в том числе в это.
Более того, я не уверен, что хоть какой-то процессор ARM использует аппаратные потоки.
Сейчас уже нет. ThunderX2 (в девичестве Vulkan) имел SMT4 (как и Netlogic XLP, из которого он переделан). ThunderX3 должен был продолжить эту традицию, но что-то пошло не так.
это одна из причин, почему ряд производителей высокопроизводительных чипов ARM, таких как Ampere, выпускают 80-ядерный процессор без гипертрединга
Причина там, в первую очередь — экономия транзисторного бюджета, а также тот факт, что Ampere собирается наставить ядер N1
Очень точно сказано. Во время появления, технологические нормы — ??? мкм, средства проектирования — кульман+карандаш с резинкой :) Аппаратный умножитель был экзотикой. Куча алгоритмов реализовывались так, что только бы не использовать умножения :)
Вот тогда слово «Reduced» действительно что-то значило.
«Но чтобы действительно понять разницу между RISC и CISC, вам нужно избавиться от этого мифа… Мысль о том, что внутри CISC-процессора может быть RISC, только запутает вас… Давайте поговорим о том, что из себя представляют RISC и CISC. И то, и другое — философия того, как нужно проектировать процессоры….Было принято решение сделать внутренности CISC-процессора более RISC-похожими….Фактически некоторые RISC-процессоры используют микрокод для некоторых инструкций, как CISC-процессоры.»
В статье точных определений RISC и CISC не приводится. Но мысль крутится вокруг того, что обе архитектуры частично позаимствовали философию обработки команд друг у друга. И в текущем моменте у каждой есть достоинства и недостатки, как и нет безоговорочного лидера.
Второй важный момент заключается в лицензировании. Apple не может свободно создавать свои процессоры с набором команд x86. Это часть интеллектуальной собственности Intel, а Intel не хочет конкурентов.
x86-compatible processors have been designed, manufactured and sold by a number of companies, including:
x86-processors for regular PCs
- Intel
- AMD
- VIA
- Zhaoxin
In the past:
- Transmeta (discontinued its x86 line)
- Rise Technology (acquired by SiS, that sold its x86 (embedded) line to DM&P)
- IDT (Centaur Technology x86 division acquired by VIA)
- Cyrix (acquired by National Semiconductor)
- National Semiconductor (sold the x86 PC designs to VIA and later the x86 embedded designs to AMD)
- NexGen (acquired by AMD)
- Chips and Technologies (acquired by Intel)
- Texas Instruments (discontinued its own x86 line)
- IBM (discontinued its own x86 line)
- UMC (discontinued its x86 line)
- NEC (discontinued its x86 line)
Процессор Apple так хорош в некоторых задачах потому что у него есть аппаратные ускорители, которые фактически… представляют собой специализированные CISC — ядра.
Статья написана с полным игнорированием этого факта.
Типовой подход проектирования (на примере ARM, RISC-V):
1. вначале простенький RISC
2. затем + расширения
3. далее всё что влезет, т.к. все помнят только п.1 :)
ISA может быть как в Форте у Технофорт ТФ-16, например.
У Мультиклета и Мальта, что-то своё изобретено…
У Мультиклета интересная идея, но подход к ISA скорее всего как у RISC,
т.е. набор команд попроще, все в один такт.
Про Мальта ничего не слышал. Может дадите какую-нибудь ссылку.
Научный парк МГУ, судя по адресу.
Что даёт некоторое ускорение по сравнению с х86, в последних х86 появилась такая фича как слияния инструкций, это когда две или три простых инструкций можно слить в одну и выполнить в одном из конвейере, вероятно за один такт. Что позволяет конкурировать с ARM процессорами. Старые х86 типа Athlon II x4 640, уже не могут конкурировать с современными(не очень) ARM процессорами, даже при тех же 3 инструкции за такт.
И ещё, в х86 разных фичь конечно больше.
arm победит amd64?
Я при своей жизни увижу, как все датацентры выбросили все серваки и все люди поменяли ноуты на arm?
У эпл получится пропушить эту идею, или всё сдохнет, как с клавиатурой бабочкой?
Просто я из статьи понял, что у cisc нет будущего и всё это было временно как хрущёвки)
В итоге то, за кем будущее?
Есть мнение, что за специализированными вычислителями. Процессоры общего назначения уже не дают достаточного выхлопа на популярных задачах, поэтому будут добавляться сопроцессоры, акселераторы и всё такое прочее для конкретных типов задач (в принципе, это можно наблюдать уже и сейчас, когда в пределах одной SoC совмещаются процессорные ядра, ядра GPU, FPGA и аппаратных кодеков обработки видео).
Я при своей жизни увижу, как все датацентры выбросили все серваки и все люди поменяли ноуты на arm?
Нет предпосылок для этого. В свое время х86 стабильно предлагал лучшее отношение цена/производительность, обратную совместимость, и широкий набор софта — RISC'ам нечего предложить здесь.
Чем ARM отличается от PowerPC? Оба же RISC.
Что означает RISC и CISC?