«Данные — новая нефть», — твердят со всех сторон аналитики, эксперты, учёные. Действительно, бизнес, органы власти, межнациональные институты всех сфер деятельности собирают данные, новый виток развития получил IoT, терабайты данных генерирует носимая электроника. Вся наша жизнь — данные. А заметили ли вы особенность фразы «данные — новая нефть»? Они такие же нужные, такие же дорогие, — правильно. Но что такое нефть? Это сырьё. На ней, как таковой, не поедешь, ею не смажешь, её не используешь на стройке и в косметике. Нефть для придания ей потребительской ценности нуждается в хранении и переработке. Та же история с данными: их нужно добыть, сохранить, очистить, обработать и интерпретировать. Только тогда они принесут бизнесу и потребителям реальную, ощутимую пользу.
Мы не могли обойти эту тему и финансировали исследование, проведённое независимой исследовательской компанией IDC. Результаты получились любопытные и впервые в Рунете мы их публикуем именно на Хабре.

Эта милая олдскульная картинка не имеет ничего общего с миром данных, в котором мы живём. Сейчас данные — это не длинная комната с ящиками, это просто вся планета Земля
Довольно давно на одной из отраслевых IT-конференций сразу несколько компаний пожаловались, что им не хватает некой технологии (касается сферы переводов с иностранного языка на родной и обратно). Разработчики, присутствующие в зале, удивлённо развели руками: от рынка запроса не поступало. Выяснилось, что были и исследования, и митапы, и две (!) конференции бизнеса, но мысль так и не была донесена до мира разработки. А кто-то мог обогнать большую компанию и сделать свой первый долларовый миллион. К чему мы это? Сбор, хранение и обработка данных — непаханное поле для крутых технологических решений. Если вы увидите проблемы, поймёте сформированный запрос на ближайшие 2-5 лет, у вас есть все шансы создать особенное и востребованное решение в DataOps. Поэтому внимательно отнеситесь к отчёту и идеям внутри него — наверняка кто-то найдёт свой инсайт.
А представителям бизнеса этот отчёт — знаковый повод задуматься, насколько много данных упущено в компании и какие перспективы они открывают.
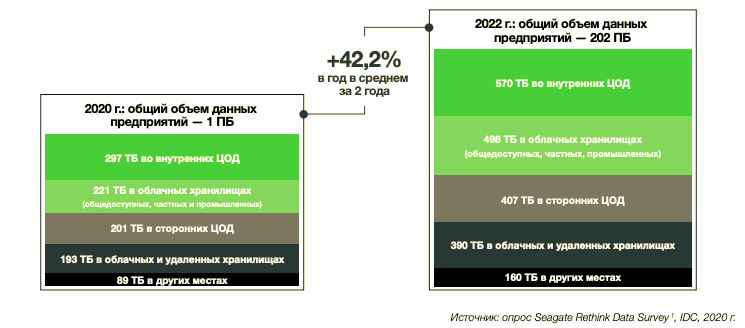
Рост объемов данных остается беспрецедентным. Проведенное исследование показывает, что в течение ближайших двух лет — с начала 2020 по начало 2022 года — объем генерируемых предприятиями данных будет увеличиваться на 42,2% в год. Прогнозы IDC основаны на косвенном показателе — емкости корпоративных систем хранения.
Ожидаемый годовой рост объемов данных
Удалось выделить три фактора, которыми обусловлен рост объема хранимых данных:
Разрастание данных отражает степень разнесенности корпоративных данных. Поскольку данные предприятий хранятся распределенно, ими сложнее управлять. Респонденты сообщили, что около 30% хранимых данных размещаются во внутренних центрах обработки, 20% — в сторонних, 19% — в периферийных или удаленных, 22% — в облачных хранилищах и ещё 9% — в других местах. Ожидается, что в ближайшие два года это распределение существенно не изменится, а значит, корпоративные среды хранения в обозримом будущем останутся такими же разрозненными и непрозрачными.
Дейв Мосли, генеральный директор Seagate Technology
Количество создаваемых данных ежегодно увеличивается, причем ожидается, что совокупные темпы годового прироста в 2015– 2025 годах составят около 26%.
Где создаются и хранятся данные
Для понимания структуры хранения данных важно определить значение слова «периферия». Периферия — это расположение компонентов сети в различных отраслях, то есть то, где хранятся или собираются данные. Периферия — это внешняя граница сети, которая может находиться за сотни и даже тысячи километров от ближайшего предприятия или облачного центра обработки данных, как можно ближе к источнику данных. Это место, где происходит принятие решений в режиме реального времени. Например, беспилотный автомобиль, ящик вышки сотовой связи и сама вышка, производственная площадка — это периферия. А публичное облако, ЦОД, датацентр в противоположность — это центр хранения и обработки данных. Периферия имеет свои особенности и может находиться далеко от центра, иметь нестабильное соединение, требовать оперативного использования данных и т.д. То есть нужно понимать, что разнесения данных по периферии и центру не избежать никаким образом, никакая унификация и централизация большинству компаний не подойдёт.
Всё большие объемы данных требуют анализа и принятия решений на периферии. По технологическим и экономическим соображениям собирать, хранить и обрабатывать данные таким образом становится выгоднее. Смещение центра тяжести в направлении периферии обусловлено развитием четырех технологий.
Помимо этих технологий, спрос на периферийные вычисления в значительной степени стимулируют такие факторы, как задержки, большие объемы данных при недостаточной пропускной способности, высокая стоимость, а также суверенитет данных и требования нормативно-правового соответствия. Поскольку огромное количество информации создается вне традиционных центров обработки данных, облако разрастается по направлению к периферии. Но речь идет не о противостоянии, как могло показаться в начале, а о синергии облака и периферии. Это сложный процесс.
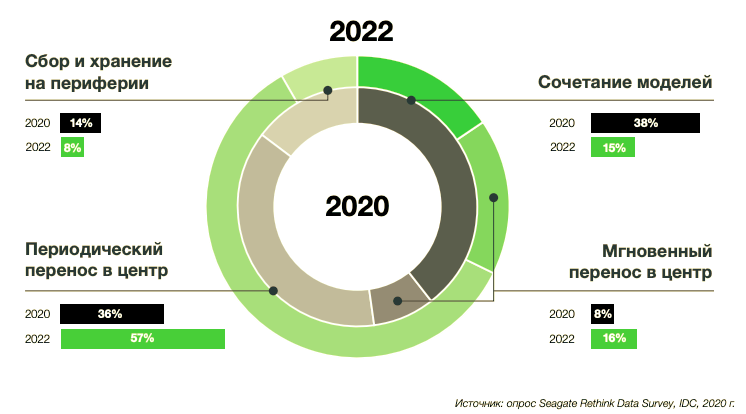
Исследование показало, что в среднем организации периодически перемещают около 36% своих данных с периферии в центр. Всего через два года этот показатель вырастет до 57%. Объем данных, передаваемых с периферии в центр в режиме реального времени, увеличится с 8% до 16%. Планы управления данными должны считаться с таким развитием событий: необходимо готовиться к масштабному перемещению данных по направлению от конечных точек через периферию к публичным, частным и промышленным облакам.
Прежде всего, их ожидает большее разрастание данных. Это ведет к обособлению и разрозненности, в результате чего не все и не всегда могут получить доступ к нужной информации. Без автоматизации управление разрастанием данных требует значительных усилий со стороны сотрудников и приобретения излишних программных инструментов.
Ожидается, что все больше устройств хранения будет поддерживать некоторые вычислительные функции, а в дальнейшем, возможно, полностью обеспечивать необходимые вычисления.
Предполагается, что на периферии будут храниться критически важные данные, необходимые для обработки запросов, чувствительных к задержкам, поступающих с конечных точек.
В то же время распределенные вычисления позволят анализировать потоковые данные. Потоковые данные, скорее всего, будут кешироваться на носителях до тех пор, пока серверы не начнут поддерживать полноценные функции аналитики. Таким образом, граница между хранением и кешированием на периферии может оказаться размытой, особенно с учетом того, что данные, вероятно, будут храниться там недолго: сразу после анализа или обработки вся релевантная информация будет передаваться в центр
Подход к сбору данных на периферии: сегодня и через два года
Периферийные устройства представляют определенные сложности с точки зрения сбора данных. Нередко только периферийное приложение имеет инструкции о том, какие данные необходимо собирать и обрабатывать, а какие можно игнорировать. Из-за этого многие решения принимаются там же, где создаются данные. Однако в более новых приложениях для централизованного управления данными эти решения могут приниматься с помощью искусственного интеллекта (ИИ) и машинного обучения (МО). Такие программы могут идентифицировать конфиденциальные данные (например, личную или медицинскую информацию, номера кредитных карт и т. д.) и автоматически скрывать их от всех, кто не уполномочен их просматривать. Это снижает вероятность несанкционированного доступа или непреднамеренного раскрытия.
Чем активнее данные будут использоваться, тем большую ценность они принесут, — кажется, эта простая формула выглядит как аксиома. Однако, если вы хоть раз в своей компании касались работы с накопленными данными, скорее всего вы видели, что часть из них никогда не используются для принятия оперативных и стратегических решений. Как думаете, сколько данных «оседают» на дно аналитики невостребованным илом? Процентов 10? 30%? Ого, может, 35-40%? Всё гораздо сложнее и печальнее: 44% данных не собираются вообще, из собранных 56% не используются 43%. Упущенная ценность колоссальна.
Какая часть данных на самом деле используется?
Согласно результатам опроса Rethink Data, значительная часть бизнес-данных организаций не используется. Данные таят в себе огромные возможности извлечения ценности, но эти возможности часто упускают.
Факт: только 11% организаций считают себя лидерами в своей отрасли в смысле способности извлекать ценность из бизнес-данных. Этот показатель оказался даже ниже для сферы здравоохранения и транспортной отрасли, где положительный ответ на этот вопрос дали менее 10% организаций. Ясно одно: компаниям нужны «живые» озера данных, в которые будет своевременно поступать свежая информация, а старая и неиспользуемая будет передаваться в хранилища с низкой стоимостью. Ни одна компания не хочет, чтобы ее озеро данных превратилось в болото, полное необработанной, но потенциально полезной информации. При измерении ценности данных каждая организация оперирует множеством переменных, таких как отрасль, в которой создаются данные, цель, которой они служат, и, наконец, способы их монетизации. Рассмотрим в качестве примера типы данных, которые создаются больницей. Это информация о пациентах, расписания смен, сведения о страховке и выставленных счетах, снимки томографии, информация о методах лечения рака, оперативные и финансовые показатели, а также данные, используемые в рекламных целях. Согласно закону, больницы обязаны хранить данные в течение многих лет после смерти пациента. Скорее всего, это неактивные данные, которые, однако, можно использовать. Разные данные имеют разную ценность — это вдвойне верно для конфиденциальных данных, требования к хранению которых особо строги. В будущем видеосеансы дистанционного оказания медицинских услуг, действия хирургов во время операции или даже материалы роботизированной операции будут записываться и сохраняться по разным причинам, даже если это будет необходимо лишь для обучения или в юридических целях. Можно ли измерить ценность таких данных? IDC еще только предстоит дать количественную оценку ценности глобальной инфосферы. Тем не менее, если исходить из определенных предположений о ценности байта, созданного в больнице с численностью персонала от 1000 до 2500 человек и доходом свыше 1 млрд долларов США, то, по расчетам IDC, ценность всей совокупности данных, созданных в такой больнице, может достигать нескольких сотен миллионов долларов США.
Рави Наик, старший вице-президент и главный директор по информационным технологиям Seagate Technology
От того, где и как хранятся данные, зависит, какую пользу организация может из них извлечь. Ниже перечислены области, где инновации в сфере хранения данных непосредственно отражаются на ценности последних.
Управлять огромными данными, которые генерируются даже в малом бизнесе, не говоря уж о гигантах, старыми методами и приёмами уже не получится. У вас не сложится табличка Excel, вас не спасёт даже Access — да даже и упоминать о них странно, ведь в 2020-2025 году значение данных настолько нарастает, что нужно думать о совершенно другой парадигме управления данными.
Тем более что что она уже существует — DataOps.
IDC определяет DataOps как методологию, сводящую вместе создателей данных и их потребителей. Но DataOps — лишь один из компонентов управления данными, наряду с оркестрацией конечных точек и центра, архитектурой данных и обеспечением их безопасности. Задача управления данными — обеспечить комплексный взгляд на хранящуюся и передаваемую информацию, а также дать пользователям возможность работать с ней и извлекать из нее максимальную пользу.
Согласно результатам опроса, в среднем лишь 10% организаций из разных отраслей и регионов полноценно внедрили у себя DataOps. Они уже пользуются этой возможностью. DataOps — это не технология и не процесс, а скорее новая методология, которая сводит вместе создателей данных и их потребителей, обеспечивая тем самым эффективное сотрудничество между ними и ускоряя внедрение инноваций.
Давайте познакомимся с DataOps поближе.
Есть потребители данных: бизнес-подразделения, отвечающие за принятие организационных решений в отношении разработки, дистрибуции и (или) маркетинга продукции, контроля затрат, производственной деятельности и т. д. Чаще всего это высшее руководство (генеральные директора, вице-президенты и т. п.) и сотрудники, помогающие ему в работе. Потребителям нужны не собственно данные, а результаты их анализа, на основании которых можно принимать взвешенные решения. Простой набор данных здесь подойдёт только недоверчивому фанату аналитики.
Есть создатели данных: машины (конечные точки, IoT-устройства) и люди, готовящие отчеты и информацию для тех, кто принимает решения.
Есть сами данные, которые весьма разнородны: какие-то требуются для анализа немедленно, какие-то нужны в историческом срезе, а какие-то вообще должны просто храниться и использоваться лишь в случае возникновения инцидента (например, для пост-анализа причин нестандартной аварии на производстве).
Стоит задача: как собрать и сохранить данные, чтобы их можно было обработать, а на основе аналитики и прогнозов уже принять решение? Аналитикам это уже практически не под силу — потенциал человеческого труда для анализа такого массива данных исчерпывается, нужны особые инструменты.
Методология DataOps позволяет использовать такие технологии, как искусственный интеллект и машинное обучение, для поиска взаимосвязей между данными из центра, облака и с источников данных на периферии. Кроме того, в DataOps для получения данных используется процесс, построенный по принципу ELT (Extract, Load, Transform — «извлечение, загрузка, преобразование»). Он извлекает данные из нескольких разных источников и загружает в единую структуру, часто в виде озера данных. А ИИ может превращать эту массу необработанных данных в четкую полезную информацию, на основании которой можно принимать взвешенные решения.
Правда, люди и здесь умудряются немного подпортить себе жизнь, внедряя целый зоопарк разнородного ПО: в большинстве организаций для сходных задач часто используется по несколько разных инструментов. Это заметно усложняет управление данными в масштабах предприятия. Лишь около трети организаций используют единое решение. Это происходит по разным причинам. Иногда за закупку инструментов в пределах одной организации отвечают несколько разных человек, иногда решения несовместимы с определенными платформами, иногда старые решения используются наряду с новыми.
Подходы к развертыванию инструментов и приложений для управления данными
И действительно, DataOps хорош в работе с данными, классифицирует данными, управляет метаданными, позволяет аккуратно работать с политиками и успешно и безопасно управлять персональными данными. И это та часть искусственного интеллекта, которая прекрасно работает.
И которой, конечно, мешает нормально работать человек. Увы, эффективному использованию DataOps не всегда мешают только технические проблемы. Культурные особенности и человеческий фактор тоже играют свою роль, и каждый владелец компании должен их учитывать. Очень часто организации страдают от разобщенности: отдельные команды соперничают и добиваются собственных целей, вместо того чтобы сотрудничать и обмениваться полезной информацией. При этом конкурирующие группы борются за контроль над данными, рассматривая их как источник власти.
В результате корпоративные данные (порой одни и те же) хранятся, контролируются и анализируются не централизованно, а несколькими разными группами в пределах компании. Часто результаты такого анализа не совпадают, потому что для получения максимально точной и полной картины нужно использовать глобальный репозиторий данных, а при организационной разобщенности это невозможно. Чтобы решить эту проблему, нужно начинать со стратегии владельца предприятия. В ней должны закрепляться глобальные принципы работы: стандарты, архитектура данных, управление данными, общий доступ к общим аналитическим инструментам для всех групп.
Если передать функции формирования отчетов ИТ-отделу, можно создать централизованную инфраструктуру с инструментами, решениями и возможностями, с которыми смогут работать все группы в организации. Так можно победить разобщенность в работе с корпоративными данными. В итоге все команды смогут принимать взвешенные решения на основании результатов анализа надежных и доступных всем в компании данных из глобальных пулов.
Правда, реакция ИТ-отдела наверняка будет непередаваемой.
«Да кому нужны наши данные!», — восклицают в компаниях и хранят свой ценный актив как попало. Между тем, утечка данных ведет ко множеству проблем: прямым убыткам, крупным штрафам, потере лица, репутации и клиентов. Хакерские атаки могут привести к краже корпоративных секретов, снижению производительности труда сотрудников, невосстановимой утере данных, а в случае атаки с целью вымогательства — к прямым убыткам и потере лица. При этом во множестве организаций респондентов на корпоративном уровне не внедрены даже обычные практики защиты данных.
В ответах на вопросы, связанные с безопасностью предприятия, не применялся принцип «все или ничего». То есть, например, респондент мог ответить «да» на вопрос о шифровании данных на отключенных устройствах и «нет» на все остальные. Таким образом, весьма вероятно, что большая часть организаций имеет ряд существенных уязвимостей в системе безопасности.
Реализация продуманной программы защиты данных может выглядеть пугающе. Кроме того, важно не забывать, что лучшее — враг хорошего. Предположим, вы — владелец бизнеса. У вас полно дел, времени не хватает, но нужно принять хотя бы самые необходимые меры, а о менее срочных проблемах можно будет подумать позднее. Вот список действий, которые защитят данные от наиболее серьезных угроз.
Собирайте данные, обрабатывайте их, используйте в работе. Тогда вы увидите свою компанию и свой бизнес совсем другими.
Мы рекомендуем вам обязательно ознакомиться с отчётом. И у нас на это пять причин.
→ Смотреть отчёт без регистрации и SMS
А как ваши компании работают с данными?
Мы не могли обойти эту тему и финансировали исследование, проведённое независимой исследовательской компанией IDC. Результаты получились любопытные и впервые в Рунете мы их публикуем именно на Хабре.

Эта милая олдскульная картинка не имеет ничего общего с миром данных, в котором мы живём. Сейчас данные — это не длинная комната с ящиками, это просто вся планета Земля
Почему вы должны познакомиться с отчётом прямо сейчас?
Довольно давно на одной из отраслевых IT-конференций сразу несколько компаний пожаловались, что им не хватает некой технологии (касается сферы переводов с иностранного языка на родной и обратно). Разработчики, присутствующие в зале, удивлённо развели руками: от рынка запроса не поступало. Выяснилось, что были и исследования, и митапы, и две (!) конференции бизнеса, но мысль так и не была донесена до мира разработки. А кто-то мог обогнать большую компанию и сделать свой первый долларовый миллион. К чему мы это? Сбор, хранение и обработка данных — непаханное поле для крутых технологических решений. Если вы увидите проблемы, поймёте сформированный запрос на ближайшие 2-5 лет, у вас есть все шансы создать особенное и востребованное решение в DataOps. Поэтому внимательно отнеситесь к отчёту и идеям внутри него — наверняка кто-то найдёт свой инсайт.
А представителям бизнеса этот отчёт — знаковый повод задуматься, насколько много данных упущено в компании и какие перспективы они открывают.
Данные росли, растут и будут расти
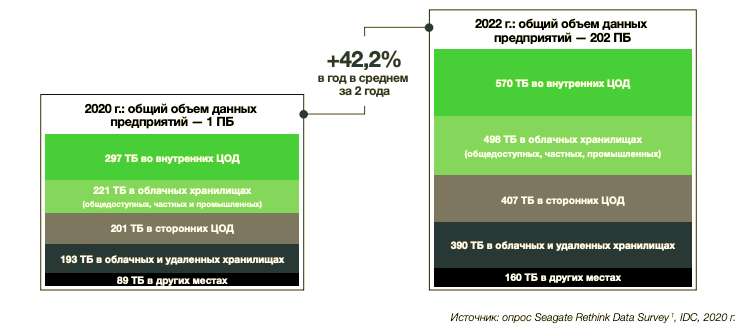
Рост объемов данных остается беспрецедентным. Проведенное исследование показывает, что в течение ближайших двух лет — с начала 2020 по начало 2022 года — объем генерируемых предприятиями данных будет увеличиваться на 42,2% в год. Прогнозы IDC основаны на косвенном показателе — емкости корпоративных систем хранения.
Ожидаемый годовой рост объемов данных
Удалось выделить три фактора, которыми обусловлен рост объема хранимых данных:
- Более активное использование аналитики.
- Увеличение количества IoT-устройств.
- Перенос данных в облако.
Разрастание данных отражает степень разнесенности корпоративных данных. Поскольку данные предприятий хранятся распределенно, ими сложнее управлять. Респонденты сообщили, что около 30% хранимых данных размещаются во внутренних центрах обработки, 20% — в сторонних, 19% — в периферийных или удаленных, 22% — в облачных хранилищах и ещё 9% — в других местах. Ожидается, что в ближайшие два года это распределение существенно не изменится, а значит, корпоративные среды хранения в обозримом будущем останутся такими же разрозненными и непрозрачными.
Рост суммарного количества создаваемых данных будет экспоненциально ускоряться и к 2025 году их объем достигнет 175 зеттабайт. Сегодня мы создаем больше данных за час, чем двадцать лет назад создавали за целый год. Данные — это человеческий потенциал. <…> Когда объемы измеряются зеттабайтами, нам требуется простой, безопасный и недорогой способ сбора, хранения и применения данных.
Дейв Мосли, генеральный директор Seagate Technology
Количество создаваемых данных ежегодно увеличивается, причем ожидается, что совокупные темпы годового прироста в 2015– 2025 годах составят около 26%.
- Объем новых данных в 2025 году возрастет до 175,8 ЗБ, в то время как в 2015 году он составлял всего 18,2 ЗБ.
- В 2025 году предприятия будут хранить 9 ЗБ информации, тогда как в 2015 году этот показатель был равен 0,8 ЗБ.
- Результаты опроса Rethink Data подтверждают эту тенденцию. Практически все респонденты сообщали, что количество собираемых данных и емкость хранилищ в их организациях увеличиваются. Это говорит о том, что более активное использование аналитики и IoT-устройств, а также перенос данных в облако входят в тройку главных факторов, влияющих на рост объема хранимых данных.
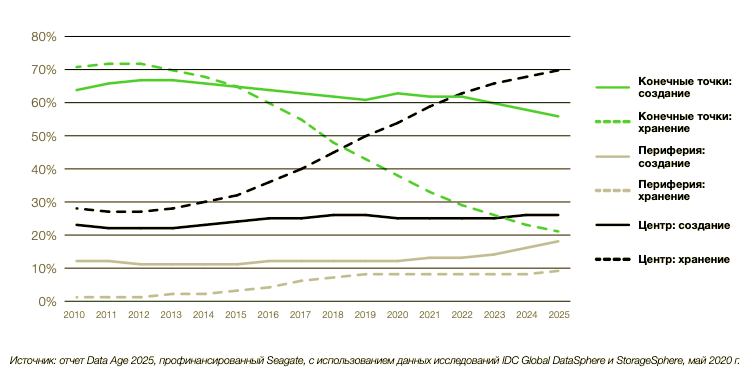
- По результатам Global DataSphere, в 2015 году 65% данных было создано на конечных точках и 35% в центре и на периферии.
- Ожидается, что к 2025 году 44% всех данных, созданных в центре и на периферии, будет использоваться для аналитики, искусственного интеллекта и глубокого обучения, а данные с растущего числа IoT-устройств будут передаваться на периферию корпоративной сети.
- Центр тяжести данных смещается и в направлении центра, и в направлении периферии. К 2025 году почти 80% всех данных в мире будут храниться в центре и на периферии, что составит значительный рост по сравнению с 35% в 2015 году.
- По прогнозам IDC, к 2025 году емкость запоминающих устройств (жестких и оптических дисков, твердотельных и ленточных накопителей), используемых предприятиями, составит 12,6 ЗБ. Поставщики облачных услуг будут управлять 51% от этой емкости.
Где создаются и хранятся данные

Для понимания структуры хранения данных важно определить значение слова «периферия». Периферия — это расположение компонентов сети в различных отраслях, то есть то, где хранятся или собираются данные. Периферия — это внешняя граница сети, которая может находиться за сотни и даже тысячи километров от ближайшего предприятия или облачного центра обработки данных, как можно ближе к источнику данных. Это место, где происходит принятие решений в режиме реального времени. Например, беспилотный автомобиль, ящик вышки сотовой связи и сама вышка, производственная площадка — это периферия. А публичное облако, ЦОД, датацентр в противоположность — это центр хранения и обработки данных. Периферия имеет свои особенности и может находиться далеко от центра, иметь нестабильное соединение, требовать оперативного использования данных и т.д. То есть нужно понимать, что разнесения данных по периферии и центру не избежать никаким образом, никакая унификация и централизация большинству компаний не подойдёт.
Всё большие объемы данных требуют анализа и принятия решений на периферии. По технологическим и экономическим соображениям собирать, хранить и обрабатывать данные таким образом становится выгоднее. Смещение центра тяжести в направлении периферии обусловлено развитием четырех технологий.
- ИИ стал более экономичным и практичным.
- Развернуты миллиарды IoT-устройств.
- Операторы беспроводной связи модернизируют свои сети для поддержки пятого поколения мобильной связи (5G).
- Инновации в периферийных центрах обработки данных решают проблемы распределенных площадок, а удельные издержки снижаются.
Помимо этих технологий, спрос на периферийные вычисления в значительной степени стимулируют такие факторы, как задержки, большие объемы данных при недостаточной пропускной способности, высокая стоимость, а также суверенитет данных и требования нормативно-правового соответствия. Поскольку огромное количество информации создается вне традиционных центров обработки данных, облако разрастается по направлению к периферии. Но речь идет не о противостоянии, как могло показаться в начале, а о синергии облака и периферии. Это сложный процесс.
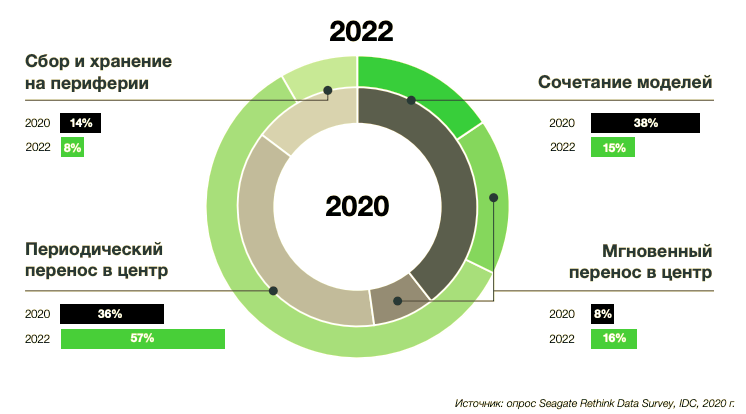
Исследование показало, что в среднем организации периодически перемещают около 36% своих данных с периферии в центр. Всего через два года этот показатель вырастет до 57%. Объем данных, передаваемых с периферии в центр в режиме реального времени, увеличится с 8% до 16%. Планы управления данными должны считаться с таким развитием событий: необходимо готовиться к масштабному перемещению данных по направлению от конечных точек через периферию к публичным, частным и промышленным облакам.
Что это означает для предприятий?
Прежде всего, их ожидает большее разрастание данных. Это ведет к обособлению и разрозненности, в результате чего не все и не всегда могут получить доступ к нужной информации. Без автоматизации управление разрастанием данных требует значительных усилий со стороны сотрудников и приобретения излишних программных инструментов.
Ожидается, что все больше устройств хранения будет поддерживать некоторые вычислительные функции, а в дальнейшем, возможно, полностью обеспечивать необходимые вычисления.
Предполагается, что на периферии будут храниться критически важные данные, необходимые для обработки запросов, чувствительных к задержкам, поступающих с конечных точек.
В то же время распределенные вычисления позволят анализировать потоковые данные. Потоковые данные, скорее всего, будут кешироваться на носителях до тех пор, пока серверы не начнут поддерживать полноценные функции аналитики. Таким образом, граница между хранением и кешированием на периферии может оказаться размытой, особенно с учетом того, что данные, вероятно, будут храниться там недолго: сразу после анализа или обработки вся релевантная информация будет передаваться в центр
Подход к сбору данных на периферии: сегодня и через два года
Периферийные устройства представляют определенные сложности с точки зрения сбора данных. Нередко только периферийное приложение имеет инструкции о том, какие данные необходимо собирать и обрабатывать, а какие можно игнорировать. Из-за этого многие решения принимаются там же, где создаются данные. Однако в более новых приложениях для централизованного управления данными эти решения могут приниматься с помощью искусственного интеллекта (ИИ) и машинного обучения (МО). Такие программы могут идентифицировать конфиденциальные данные (например, личную или медицинскую информацию, номера кредитных карт и т. д.) и автоматически скрывать их от всех, кто не уполномочен их просматривать. Это снижает вероятность несанкционированного доступа или непреднамеренного раскрытия.
Данные: ценный актив, который не используется
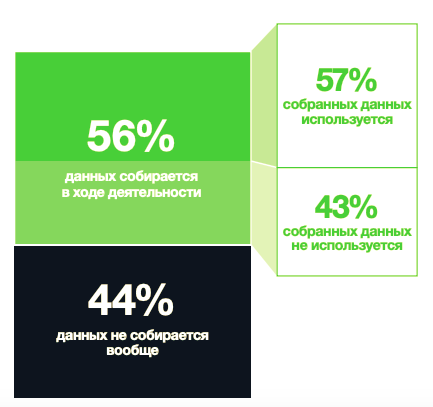
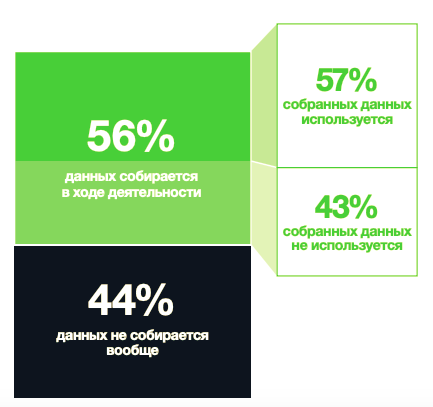
Чем активнее данные будут использоваться, тем большую ценность они принесут, — кажется, эта простая формула выглядит как аксиома. Однако, если вы хоть раз в своей компании касались работы с накопленными данными, скорее всего вы видели, что часть из них никогда не используются для принятия оперативных и стратегических решений. Как думаете, сколько данных «оседают» на дно аналитики невостребованным илом? Процентов 10? 30%? Ого, может, 35-40%? Всё гораздо сложнее и печальнее: 44% данных не собираются вообще, из собранных 56% не используются 43%. Упущенная ценность колоссальна.
Какая часть данных на самом деле используется?
Согласно результатам опроса Rethink Data, значительная часть бизнес-данных организаций не используется. Данные таят в себе огромные возможности извлечения ценности, но эти возможности часто упускают.
- Респонденты сообщили, что в их организациях собирается лишь 56% данных, которые потенциально могут быть получены в результате их деятельности. Таким образом, практически половина данных игнорируется.
- Из этих 56% только 57% данных были применены на практике.
- 43% собранных данных не использовались вообще.
- Это означает, что лишь 32% доступных бизнес-данных используются организациями, а целых 68% простаивают без дела.
Факт: только 11% организаций считают себя лидерами в своей отрасли в смысле способности извлекать ценность из бизнес-данных. Этот показатель оказался даже ниже для сферы здравоохранения и транспортной отрасли, где положительный ответ на этот вопрос дали менее 10% организаций. Ясно одно: компаниям нужны «живые» озера данных, в которые будет своевременно поступать свежая информация, а старая и неиспользуемая будет передаваться в хранилища с низкой стоимостью. Ни одна компания не хочет, чтобы ее озеро данных превратилось в болото, полное необработанной, но потенциально полезной информации. При измерении ценности данных каждая организация оперирует множеством переменных, таких как отрасль, в которой создаются данные, цель, которой они служат, и, наконец, способы их монетизации. Рассмотрим в качестве примера типы данных, которые создаются больницей. Это информация о пациентах, расписания смен, сведения о страховке и выставленных счетах, снимки томографии, информация о методах лечения рака, оперативные и финансовые показатели, а также данные, используемые в рекламных целях. Согласно закону, больницы обязаны хранить данные в течение многих лет после смерти пациента. Скорее всего, это неактивные данные, которые, однако, можно использовать. Разные данные имеют разную ценность — это вдвойне верно для конфиденциальных данных, требования к хранению которых особо строги. В будущем видеосеансы дистанционного оказания медицинских услуг, действия хирургов во время операции или даже материалы роботизированной операции будут записываться и сохраняться по разным причинам, даже если это будет необходимо лишь для обучения или в юридических целях. Можно ли измерить ценность таких данных? IDC еще только предстоит дать количественную оценку ценности глобальной инфосферы. Тем не менее, если исходить из определенных предположений о ценности байта, созданного в больнице с численностью персонала от 1000 до 2500 человек и доходом свыше 1 млрд долларов США, то, по расчетам IDC, ценность всей совокупности данных, созданных в такой больнице, может достигать нескольких сотен миллионов долларов США.
Чем больше фрагментов вы составите вместе, тем более полное и точное представление о реальности получите. <…> Данные должны находиться в движении, чтобы было возможно выявлять связи между ними — и, как следствие, составлять точную и подробную картину происходящего.
Рави Наик, старший вице-президент и главный директор по информационным технологиям Seagate Technology
От того, где и как хранятся данные, зависит, какую пользу организация может из них извлечь. Ниже перечислены области, где инновации в сфере хранения данных непосредственно отражаются на ценности последних.
- Экономия на масштабе за счет растущих объемов. С ростом количества доступных данных повышается качество аналитики. Грамотное управление данными подразумевает, что к ним применяются все инновации в области ИИ или МО — насколько это физически возможно. Именно поэтому такие компании, как Seagate, усиленно работают над повышением плотности записи, чтобы на устройство можно было вместить больше информации. Внимание к плотности записи обусловлено ситуацией в крупнейших в мире облачных хранилищах. Данные предприятий распределяются в соотношении 90 к 10: 90% хранится на жестких дисках, а 10% — на твердотельных накопителях.
- Еще одно направление развития в области хранения данных — повышение пропускной способности, обеспечивающее более быстрое и стабильное перемещение данных между хранилищем и сетью, а также увеличение скорости вычислений. Это важно для аналитики. Современные инструменты анализа используют графические процессоры, которым требуется высокая пропускная способность. Для ее увеличения в крупных корпоративных системах с ИИ, в частности, используется дезагрегированная компонуемая архитектура.
- Безопасность также не остается без внимания. Компании продолжают инвестировать в защиту устройств: создаются специальные микропрограммы, а в вычислительных системах реализуются протоколы цифровой проверки подлинности устройств. Системные решения выигрывают от повышенной безопасности на уровне компонентов и устройств, а сеть — от более защищенных систем. И, наконец, в более безопасных сетях лучше защищены вычислительные ресурсы.
- В долгосрочной перспективе архитектура перемещения данных должна будет обеспечивать аппаратное ускорение или аппаратную разгрузку через системы хранения данных. В частности, сжатие, шифрование и дедупликация наборов данных сегодня осуществляются в вычислительных системах. Из-за этого возникает потребность в масштабировании крупных архитектур, поскольку эти задачи выполняются на более высоком уровне. Но если аппаратное ускорение и аппаратная разгрузка будут выполняться на уровне хранилища или сети, это не потребуется.
DataOps: управление данными без o-o-oops
Управлять огромными данными, которые генерируются даже в малом бизнесе, не говоря уж о гигантах, старыми методами и приёмами уже не получится. У вас не сложится табличка Excel, вас не спасёт даже Access — да даже и упоминать о них странно, ведь в 2020-2025 году значение данных настолько нарастает, что нужно думать о совершенно другой парадигме управления данными.
Тем более что что она уже существует — DataOps.
IDC определяет DataOps как методологию, сводящую вместе создателей данных и их потребителей. Но DataOps — лишь один из компонентов управления данными, наряду с оркестрацией конечных точек и центра, архитектурой данных и обеспечением их безопасности. Задача управления данными — обеспечить комплексный взгляд на хранящуюся и передаваемую информацию, а также дать пользователям возможность работать с ней и извлекать из нее максимальную пользу.
Согласно результатам опроса, в среднем лишь 10% организаций из разных отраслей и регионов полноценно внедрили у себя DataOps. Они уже пользуются этой возможностью. DataOps — это не технология и не процесс, а скорее новая методология, которая сводит вместе создателей данных и их потребителей, обеспечивая тем самым эффективное сотрудничество между ними и ускоряя внедрение инноваций.
Давайте познакомимся с DataOps поближе.
Есть потребители данных: бизнес-подразделения, отвечающие за принятие организационных решений в отношении разработки, дистрибуции и (или) маркетинга продукции, контроля затрат, производственной деятельности и т. д. Чаще всего это высшее руководство (генеральные директора, вице-президенты и т. п.) и сотрудники, помогающие ему в работе. Потребителям нужны не собственно данные, а результаты их анализа, на основании которых можно принимать взвешенные решения. Простой набор данных здесь подойдёт только недоверчивому фанату аналитики.
Есть создатели данных: машины (конечные точки, IoT-устройства) и люди, готовящие отчеты и информацию для тех, кто принимает решения.
Есть сами данные, которые весьма разнородны: какие-то требуются для анализа немедленно, какие-то нужны в историческом срезе, а какие-то вообще должны просто храниться и использоваться лишь в случае возникновения инцидента (например, для пост-анализа причин нестандартной аварии на производстве).
Стоит задача: как собрать и сохранить данные, чтобы их можно было обработать, а на основе аналитики и прогнозов уже принять решение? Аналитикам это уже практически не под силу — потенциал человеческого труда для анализа такого массива данных исчерпывается, нужны особые инструменты.
Методология DataOps позволяет использовать такие технологии, как искусственный интеллект и машинное обучение, для поиска взаимосвязей между данными из центра, облака и с источников данных на периферии. Кроме того, в DataOps для получения данных используется процесс, построенный по принципу ELT (Extract, Load, Transform — «извлечение, загрузка, преобразование»). Он извлекает данные из нескольких разных источников и загружает в единую структуру, часто в виде озера данных. А ИИ может превращать эту массу необработанных данных в четкую полезную информацию, на основании которой можно принимать взвешенные решения.
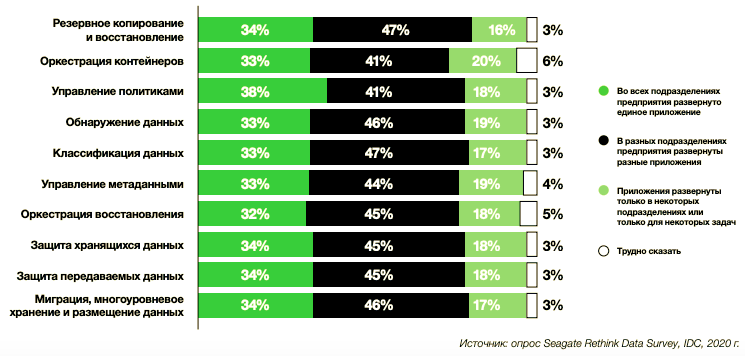
Правда, люди и здесь умудряются немного подпортить себе жизнь, внедряя целый зоопарк разнородного ПО: в большинстве организаций для сходных задач часто используется по несколько разных инструментов. Это заметно усложняет управление данными в масштабах предприятия. Лишь около трети организаций используют единое решение. Это происходит по разным причинам. Иногда за закупку инструментов в пределах одной организации отвечают несколько разных человек, иногда решения несовместимы с определенными платформами, иногда старые решения используются наряду с новыми.
Подходы к развертыванию инструментов и приложений для управления данными

И действительно, DataOps хорош в работе с данными, классифицирует данными, управляет метаданными, позволяет аккуратно работать с политиками и успешно и безопасно управлять персональными данными. И это та часть искусственного интеллекта, которая прекрасно работает.
И которой, конечно, мешает нормально работать человек. Увы, эффективному использованию DataOps не всегда мешают только технические проблемы. Культурные особенности и человеческий фактор тоже играют свою роль, и каждый владелец компании должен их учитывать. Очень часто организации страдают от разобщенности: отдельные команды соперничают и добиваются собственных целей, вместо того чтобы сотрудничать и обмениваться полезной информацией. При этом конкурирующие группы борются за контроль над данными, рассматривая их как источник власти.
В результате корпоративные данные (порой одни и те же) хранятся, контролируются и анализируются не централизованно, а несколькими разными группами в пределах компании. Часто результаты такого анализа не совпадают, потому что для получения максимально точной и полной картины нужно использовать глобальный репозиторий данных, а при организационной разобщенности это невозможно. Чтобы решить эту проблему, нужно начинать со стратегии владельца предприятия. В ней должны закрепляться глобальные принципы работы: стандарты, архитектура данных, управление данными, общий доступ к общим аналитическим инструментам для всех групп.
Если передать функции формирования отчетов ИТ-отделу, можно создать централизованную инфраструктуру с инструментами, решениями и возможностями, с которыми смогут работать все группы в организации. Так можно победить разобщенность в работе с корпоративными данными. В итоге все команды смогут принимать взвешенные решения на основании результатов анализа надежных и доступных всем в компании данных из глобальных пулов.
Правда, реакция ИТ-отдела наверняка будет непередаваемой.
Безопасность данных
«Да кому нужны наши данные!», — восклицают в компаниях и хранят свой ценный актив как попало. Между тем, утечка данных ведет ко множеству проблем: прямым убыткам, крупным штрафам, потере лица, репутации и клиентов. Хакерские атаки могут привести к краже корпоративных секретов, снижению производительности труда сотрудников, невосстановимой утере данных, а в случае атаки с целью вымогательства — к прямым убыткам и потере лица. При этом во множестве организаций респондентов на корпоративном уровне не внедрены даже обычные практики защиты данных.
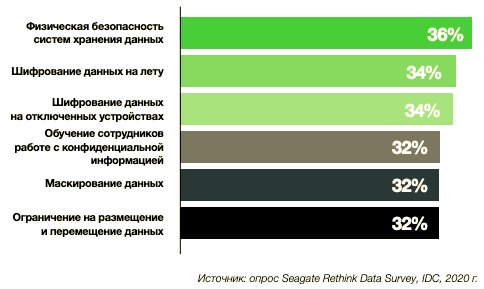
В ответах на вопросы, связанные с безопасностью предприятия, не применялся принцип «все или ничего». То есть, например, респондент мог ответить «да» на вопрос о шифровании данных на отключенных устройствах и «нет» на все остальные. Таким образом, весьма вероятно, что большая часть организаций имеет ряд существенных уязвимостей в системе безопасности.
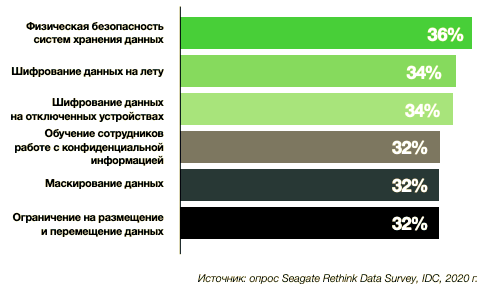
Ключевые этапы обеспечения безопасности данных
Реализация продуманной программы защиты данных может выглядеть пугающе. Кроме того, важно не забывать, что лучшее — враг хорошего. Предположим, вы — владелец бизнеса. У вас полно дел, времени не хватает, но нужно принять хотя бы самые необходимые меры, а о менее срочных проблемах можно будет подумать позднее. Вот список действий, которые защитят данные от наиболее серьезных угроз.
- Шифруйте данные на лету. Как минимум пользуйтесь только безопасными протоколами и сервисами: HTTPS вместо HTTP, SFTP вместо FTP, IPSec или SSL VPN для удаленного доступа. Это не так уж сложно: пользуйтесь только инструментами, которые используют защищенные соединения, правильно настройте их, выработайте стандарты и обяжите всех соблюдать их.
- Шифрование данных на отключенных устройствах. Ноутбуки и мобильные устройства представляют наибольший риск с точки зрения безопасности данных. Массивы и серверы хранения данных, как правило, располагаются в центре обработки с ограниченным доступом. Их вряд ли можно украсть из машины или выронить из кармана в такси. Сначала займитесь самыми серьезными угрозами. Введите полное шифрование дисков для ноутбуков на всем предприятии. Включите шифрование данных на мобильных устройствах на уровне файловой системы в политику управления такими устройствами.
- Обучайте пользователей. Как неоднократно подчеркивается в этом отчете, пользователи могут оказаться как самым сильным, так и самым слабым звеном. Владельцам бизнеса необходимо быть уверенными в том, что все их сотрудники прошли соответствующее обучение, осознают связанные с данными риски и следуют всем советам и рекомендациям. Остановитесь. Подумайте. Защитите.
Собирайте данные, обрабатывайте их, используйте в работе. Тогда вы увидите свою компанию и свой бизнес совсем другими.
Мы рекомендуем вам обязательно ознакомиться с отчётом. И у нас на это пять причин.
- Отчёт написан на редкость понятным и приятным языком — никаких канцеляризмов, никакой бюрократии и субъективности. Это просто качественное и полезное исследование.
- Вы узнаете ещё об одном аспекте бизнес-жизни загадочного восточного соседа — Китая.
- Предприниматели и руководители найдут полезный раздел об использовании данных.
- Вы узнаете всё о многооблачных средах и, возможно, придумаете свой инфраструктурный проект.
- Статья — это едва ли 20% всего отчёта, вы многое потеряете.
→ Смотреть отчёт без регистрации и SMS
А как ваши компании работают с данными?
