
Если вы считаете, что умеете готовить, то может, вы знаете о том, как сделать суфле или пахлаву, а может — и не знаете. Но есть кое-что такое, чему вы, вероятно, научились, просто готовя разные блюда. Например, вы, скорее всего, можете вскипятить воду, можете правильно разбить яйцо, можете поджарить мясо. Если говорить о работе в Linux или Unix, то тут тоже можно сделать похожие наблюдения. Возможно, вы не знаете о том, как установить сервер Wayland, или о том, как написать модуль ядра. Но есть определённые базовые навыки, вроде работы с файлами или редактирования текстов, которые люди осваивают независимо от того, чем они занимаются, навыки, которые помогают им в самых разных ситуациях. Один из навыков, полезных в самых разных ситуациях, овладение которым часто вызывает определённые сложности, это — умение пользоваться регулярными выражениями. Многие программы используют их в качестве средства описания шаблонов поиска чего-либо. Обычно — для поиска данных в строках, например — в файлах с каким-то текстом.

Если вы не очень хорошо умеете пользоваться регулярными выражениями, знайте, что это легко исправить. Их не так уж и сложно изучить, кроме того — существуют замечательные инструменты, которые способны помочь при работе с регулярными выражениями. Сами регулярные выражения используются во многих утилитах. При этом везде используются одни и те же базовые синтаксические конструкции регулярных выражений. Источником путаницы, правда, являются особенности устройства регулярных выражений в разных средах. То, что выходит за рамки базовых синтаксических конструкций, в разных местах может различаться.
Разберём основы регулярных выражений, то, что нужно для того, чтобы хорошо их понимать и эффективно использовать.
Возможно, первая программа, о которой вспоминают, когда говорят о регулярных выражениях, это — grep. Это — простая утилита, которая принимает регулярное выражение и имя файла (или несколько имён). Источником данных для неё может служить и стандартный поток ввода. В обычном режиме работы эта утилита выводит строки, в которых найдено совпадение с регулярным выражением. Это — простая, но мощная программа, она является одним из популярнейших инструментов командной строки. Именно поэтому я и решил построить примеры к этой статье на её основе.
Но grep — это далеко не единственная программа, использующая регулярные выражения. Среди других программ, в которых применяются регулярные выражения, можно отметить awk, sed, perl, разные редакторы, вроде Vim и emacs. Этот список можно продолжать ещё очень долго. Столь широкая распространённость регулярных выражений ведёт к тому, что их можно увидеть, например, в неких настройках программ, они встречаются даже в веб-приложениях, где используются для расширения возможностей этих приложений.
В различных системах может присутствовать не только grep, но и другие, похожие утилиты, вроде egrep. Например, в моей системе имеется команда egrep, которая представляет собой «обёртку» вокруг grep. Она вызывает
Взгляните на следующий пример:
Эта команда просмотрит файл
Строки со словом
Если точка — это «универсальный символ», то как тогда найти строки, в которых есть точка? Для этого можно воспользоваться экранированием символов с использованием обратной косой черты. Этот приём можно использовать в применении к любым специальным символам. В результате регулярное выражение

Использование обратной косой черты
Тут есть одна особенность. Оболочка интерпретирует последовательность символов
Иногда того, кто использует регулярные выражения, не интересует один заранее заданный символ. Но его при этом не устроит и поиск любого символа. В таких ситуациях в дело вступают классы символов. Например:
Эта команда найдёт строки вроде
Кроме того, можно описывать классы символов, которые не должны содержаться в искомых строках. Делается это с использованием символа
Мы уже знаем о том, как найти слова
Часто надо сделать так, чтобы некий шаблон мог бы присутствовать в находимых строках в одном экземпляре, но мог бы и полностью в них отсутствовать. Может понадобиться и поиск повторяющихся символов, а заодно и выявление их полного отсутствия. Иногда надо, чтобы регулярное выражение реагировало бы на нечто, имеющееся в строке в единственном экземпляре или повторяющееся несколько раз. Предположим, что нужно найти в файле некоего лога числа с десятичной точкой, перед которыми может присутствовать дефис, символизирующий знак «минус», а может и не присутствовать. В этой ситуации можно использовать конструкцию

Графическое представление регулярного выражения (создано с помощью Regexper)
Этому шаблону будут соответствовать числа
В более продвинутых регулярных выражениях для описания повторов можно пользоваться фигурными скобками, указывая в них то, сколько раз может повторяться шаблон. Некоторые инструменты требуют экранирования символов фигурных скобок. При работе с grep экранировать их не нужно. То есть, например, если нужно найти четыре буквы, записанные в нижнем регистре, можно воспользоваться конструкцией
Безусловно, то же самое можно описать и так:
Для grep достаточно факта нахождения совпадения с регулярным выражением. При работе с некоторыми другими инструментами в расчёт принимается совпадение с наибольшим или наименьшим количеством символов. Например, регулярное выражение
Возможно, вы обратили внимание на то, что в вышеприведённых примерах совпадение с шаблоном может быть найдено в любой части строки. Но, если нужно, можно привязать шаблон к началу строки, воспользовавшись символом
Последовательность
Существует несколько способов группировки регулярных выражений. Можно использовать скобки (правда, некоторые инструменты требуют их экранирования при использовании их для группировки шаблонов). Вот пример:
Такое регулярное выражение будет искать строки, начинающиеся с буквы
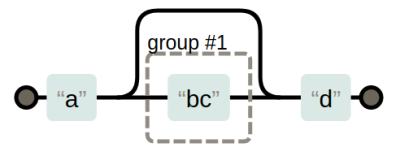
Графическое представление регулярного выражения (создано с помощью Regexper)
Это — не то же самое, что
Но если объединить эту возможность с группировкой — может получиться нечто весьма полезное. Например, конструкция вида
О самих регулярных выражениях можно говорить ещё очень долго. Но сейчас давайте немного от них отвлечёмся и поговорим о том, какую пользу они могут принести тому, кто умеет с ними работать. Предположим, у нас имеется лог-файл, в котором содержится масса температурных данных в градусах Цельсия. В этом файле есть и другие данные. Но все температурные данные представлены в виде чисел, за которыми идёт пробел и буква
Преобразовать эти числа к необходимому виду можно с помощью чего-то вроде awk. Не хочу тут вдаваться в подробности об awk, отмечу лишь то, что тут имеется функция
В первой строке кода осуществляется поиск текстов, содержащих пробел и букву
К сожалению, между способами использования регулярных выражений существуют небольшие различия. Вот что однажды сказал по этому поводу Дональд Кнут: «Я определяю UNIX, как 30 определений регулярных выражений, живущих под одной крышей».
Я уже говорил о некоторых из этих различий. Например, некоторые реализации регулярных выражений воспринимают скобки как группировочные символы в том случае, если они не экранированы. А другие, при таком их использовании, требуют их экранировать. Иначе скобки будут восприниматься как обычные символы.
Часто в регулярных выражениях используются сокращённые конструкции для описания чего-то вроде цифр и пробельных символов. Это полезная возможность, так как она повышает переносимость регулярных выражений. Например, конструкция
Собственно говоря, это — всё, что нужно знать о регулярных выражениях для начала работы с ними. Если вы хотите отлаживать регулярные выражения в интерактивном режиме, то знайте, что существует множество хороших инструментов, направленных на решение этой задачи. Ещё можно строить схемы регулярных выражений. Это помогает лучше понимать их смысл.
Возможно, вам пригодится библиотека регулярных выражений, из которой можно, так сказать, что-нибудь позаимствовать. А если вы хотите изучать регулярные выражения в игровой форме — можете заглянуть сюда и сюда.
Пользуетесь ли вы регулярными выражениями, работая в Linux?



Если вы не очень хорошо умеете пользоваться регулярными выражениями, знайте, что это легко исправить. Их не так уж и сложно изучить, кроме того — существуют замечательные инструменты, которые способны помочь при работе с регулярными выражениями. Сами регулярные выражения используются во многих утилитах. При этом везде используются одни и те же базовые синтаксические конструкции регулярных выражений. Источником путаницы, правда, являются особенности устройства регулярных выражений в разных средах. То, что выходит за рамки базовых синтаксических конструкций, в разных местах может различаться.
Разберём основы регулярных выражений, то, что нужно для того, чтобы хорошо их понимать и эффективно использовать.
Все переводы серии
Кунг-фу стиля Linux: удобная работа с файлами по SSH
Кунг-фу стиля Linux: мониторинг дисковой подсистемы
Кунг-фу стиля Linux: глобальный поиск и замена строк с помощью ripgrep
Кунг-фу стиля Linux: упрощение работы с awk
Кунг-фу стиля Linux: наблюдение за файловой системой
Кунг-фу стиля Linux: наблюдение за файлами
Кунг-фу стиля Linux: удобный доступ к справке при работе с bash
Кунг-фу стиля Linux: великая сила make
Кунг-фу стиля Linux: устранение неполадок в работе incron
Кунг-фу стиля Linux: расшаривание терминала в браузере
Кунг-фу стиля Linux: синхронизация настроек
Кунг-фу стиля Linux: бесплатный VPN по SSH
Кунг-фу стиля Linux: превращение веб-приложений в полноценные программы
Кунг-фу стиля Linux: утилита marker и меню для командной строки
Кунг-фу стиля Linux: sudo и поворот двух ключей
Кунг-фу стиля Linux: программное управление окнами
Кунг-фу стиля Linux: организация работы программ после выхода из системы
Кунг-фу стиля Linux: регулярные выражения
Кунг-фу стиля Linux: запуск команд
Кунг-фу стиля Linux: разбираемся с последовательными портами
Кунг-фу стиля Linux: базы данных — это файловые системы нового уровня
Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории
Кунг-фу стиля Linux: PDF для пингвинов
Кунг-фу стиля Linux: мониторинг дисковой подсистемы
Кунг-фу стиля Linux: глобальный поиск и замена строк с помощью ripgrep
Кунг-фу стиля Linux: упрощение работы с awk
Кунг-фу стиля Linux: наблюдение за файловой системой
Кунг-фу стиля Linux: наблюдение за файлами
Кунг-фу стиля Linux: удобный доступ к справке при работе с bash
Кунг-фу стиля Linux: великая сила make
Кунг-фу стиля Linux: устранение неполадок в работе incron
Кунг-фу стиля Linux: расшаривание терминала в браузере
Кунг-фу стиля Linux: синхронизация настроек
Кунг-фу стиля Linux: бесплатный VPN по SSH
Кунг-фу стиля Linux: превращение веб-приложений в полноценные программы
Кунг-фу стиля Linux: утилита marker и меню для командной строки
Кунг-фу стиля Linux: sudo и поворот двух ключей
Кунг-фу стиля Linux: программное управление окнами
Кунг-фу стиля Linux: организация работы программ после выхода из системы
Кунг-фу стиля Linux: регулярные выражения
Кунг-фу стиля Linux: запуск команд
Кунг-фу стиля Linux: разбираемся с последовательными портами
Кунг-фу стиля Linux: базы данных — это файловые системы нового уровня
Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории
Кунг-фу стиля Linux: PDF для пингвинов
Программы, в которых используются регулярные выражения
Возможно, первая программа, о которой вспоминают, когда говорят о регулярных выражениях, это — grep. Это — простая утилита, которая принимает регулярное выражение и имя файла (или несколько имён). Источником данных для неё может служить и стандартный поток ввода. В обычном режиме работы эта утилита выводит строки, в которых найдено совпадение с регулярным выражением. Это — простая, но мощная программа, она является одним из популярнейших инструментов командной строки. Именно поэтому я и решил построить примеры к этой статье на её основе.
Но grep — это далеко не единственная программа, использующая регулярные выражения. Среди других программ, в которых применяются регулярные выражения, можно отметить awk, sed, perl, разные редакторы, вроде Vim и emacs. Этот список можно продолжать ещё очень долго. Столь широкая распространённость регулярных выражений ведёт к тому, что их можно увидеть, например, в неких настройках программ, они встречаются даже в веб-приложениях, где используются для расширения возможностей этих приложений.
В различных системах может присутствовать не только grep, но и другие, похожие утилиты, вроде egrep. Например, в моей системе имеется команда egrep, которая представляет собой «обёртку» вокруг grep. Она вызывает
grep с передачей этой утилите опции командной строки -E, что воздействует на вид регулярных выражений, с которыми работает grep. В результате тут я, если не отмечено иное, буду говорить именно о egrep.Поиск строк по шаблонам и классы
Взгляните на следующий пример:
egrep dog somefile.txt
Эта команда просмотрит файл
somefile.txt и найдёт следующие строки:I am a dog.
There is a special dogma involved.
---dog---
▍Точка — это универсальный символ
Строки со словом
Dog при этом найдены не будут. Дело в том, что регулярные выражения, по умолчанию, чувствительны к регистру символов. Если бы этим все возможности регулярных выражений и ограничивались, тогда ничего особенно интересного в них бы не было. Но их возможности гораздо шире. Например, точка играет роль чего-то, напоминающего шаблон, соответствующий любому символу. Поэтому регулярное выражение d.g соответствует и строке dog, и строке dig (и, раз уж мы об этом говорим, строке d$g).▍Экранирование символов
Если точка — это «универсальный символ», то как тогда найти строки, в которых есть точка? Для этого можно воспользоваться экранированием символов с использованием обратной косой черты. Этот приём можно использовать в применении к любым специальным символам. В результате регулярное выражение
d\.g найдёт строку d.g и ничего другого. Правда, тут стоит помнить о том, что символ обратной косой черты может иметь особый смысл в различных программах. Например, посмотрите на этот сеанс работы с egrep.Использование обратной косой черты
Тут есть одна особенность. Оболочка интерпретирует последовательность символов
\. как обычную точку. Она не считает обратную косую черту частью регулярного выражения, воспринимая её как экранирующий символ, используемый в самой оболочке. Для того чтобы, всё же, передать egrep конструкцию \., нужно экранировать символ обратной косой черты ещё одним таким же символом (\\). Именно это и сделано во втором примере. Экранирование специальных символов может оказаться непростой задачей, конкретные действия зависят от используемой оболочки. Если вы применяете bash, то вам, возможно, достаточно будет заключить регулярное выражение в одинарные или двойные кавычки. Но даже при таком подходе остаются актуальными правила, касающиеся обратной косой черты.▍Классы символов
Иногда того, кто использует регулярные выражения, не интересует один заранее заданный символ. Но его при этом не устроит и поиск любого символа. В таких ситуациях в дело вступают классы символов. Например:
egrep [XYZ][0-9][0-9][0-9]V afile.txt
Эта команда найдёт строки вроде
X000V и Z123V. Этот приём часто используют для того чтобы сделать поиск нечувствительным к регистру символов (например, используя конструкции вроде [aA] или [a-zA-Z]).Кроме того, можно описывать классы символов, которые не должны содержаться в искомых строках. Делается это с использованием символа
^. Например, класс [^XYZ] соответствует любому символу кроме X, Y и Z. Если нужно найти тире (-), то этот знак должен идти в начале группы. А вот если нужно найти символ ^ — его не надо ставить в начало группы. Так как порядок символов в группе не играет роли при её обработке, проблем это не вызовет. В результате, например, если нас интересуют все цифры, а так же символы - и ^, то соответствующее регулярное выражение будет выглядеть так:egrep [-0-9^]
Повторы
Мы уже знаем о том, как найти слова
dog, dig, dug и d$g. Это очень хорошо, но лишь этим возможности регулярных выражений не ограничиваются. А именно, при использовании регулярных выражений можно описывать последовательности повторяющихся символов. Можно сделать и так, чтобы некий символ был бы необязательным. Например, вот регулярное выражение, которое найдёт и слово bar, и слово bear: be?ar.Часто надо сделать так, чтобы некий шаблон мог бы присутствовать в находимых строках в одном экземпляре, но мог бы и полностью в них отсутствовать. Может понадобиться и поиск повторяющихся символов, а заодно и выявление их полного отсутствия. Иногда надо, чтобы регулярное выражение реагировало бы на нечто, имеющееся в строке в единственном экземпляре или повторяющееся несколько раз. Предположим, что нужно найти в файле некоего лога числа с десятичной точкой, перед которыми может присутствовать дефис, символизирующий знак «минус», а может и не присутствовать. В этой ситуации можно использовать конструкцию
-?[0-9]+\.?[0-9]*. Для того чтобы лучше понимать подобные конструкции, полезным может оказаться представление их в виде диаграмм.Графическое представление регулярного выражения (создано с помощью Regexper)
Этому шаблону будут соответствовать числа
-25.2, 33., 17.125. Знак + указывает на то, что в строке должна быть, как минимум, одна цифра, но их может быть и больше. Символ * соответствует любому количеству цифр, в том числе — и нулевому. Обратите внимание на то, что символ десятичной точки нуждается в экранировании. У этого регулярного выражения есть одна интересная особенность. Оно будет работать и без экранирования символа десятичной точки. Ведь точка соответствует любому символу. Но при таком подходе найдено будет и нечто вроде 14X2, то есть, в нашем случае, неправильно оформленное число.▍Продвинутое описание повторов
В более продвинутых регулярных выражениях для описания повторов можно пользоваться фигурными скобками, указывая в них то, сколько раз может повторяться шаблон. Некоторые инструменты требуют экранирования символов фигурных скобок. При работе с grep экранировать их не нужно. То есть, например, если нужно найти четыре буквы, записанные в нижнем регистре, можно воспользоваться конструкцией
[a-z]{4}.Безусловно, то же самое можно описать и так:
[a-z][a-z][a-z][a-z]. Применение фигурных скобок лишь ускоряет ввод соответствующих конструкций. В фигурных скобках, кроме того, можно указывать диапазон количества повторов, задавая его нижнюю и верхнюю границы. Например — так: [a-z]{2,4}. Это соответствует последовательностям длиной от двух до четырёх символов. Это — то же самое, что и [a-z][a-z][a-z]?[a-z]?.▍В разных программах обработка повторов различается
Для grep достаточно факта нахождения совпадения с регулярным выражением. При работе с некоторыми другими инструментами в расчёт принимается совпадение с наибольшим или наименьшим количеством символов. Например, регулярное выражение
abc*, применённое к строке, содержащей abccccc, может обнаружить только символы ab, а может и найти совпадение со всей этой последовательностью символов. Это зависит от конкретного инструмента (и иногда — от настроек этого инструмента, например — от опций командной строки). Но об этом стоит помнить. Разные инструменты работают по-разному в деле обработки множественных совпадений. Например, при применении шаблона X к строке XyyX может быть найден только первый X, но могут быть найдены и оба символа. Но для grep, опять же, это значения не имеет. Этот инструмент интересует нахождение в строке хотя бы одного совпадения с регулярным выражением.Привязка шаблона к началу и к концу строки
Возможно, вы обратили внимание на то, что в вышеприведённых примерах совпадение с шаблоном может быть найдено в любой части строки. Но, если нужно, можно привязать шаблон к началу строки, воспользовавшись символом
^, или к концу строки — с помощью символа $. Например, такая конструкция поможет найти пустые строки: ^ *$. А если нужно, чтобы подобные строки начинались бы с символа табуляции, можно поступить так: ^[ \t]*$.Последовательность
\t, как и в языке C, означает знак табуляции. В зависимости от того, какой именно инструмент используется, в вашем распоряжении могут оказаться и другие особые символы. Вот, например, как искать строки, первым непробельным символом которых является %: ^[ \t]*%.Группировка
Существует несколько способов группировки регулярных выражений. Можно использовать скобки (правда, некоторые инструменты требуют их экранирования при использовании их для группировки шаблонов). Вот пример:
egrep a(bc)?d
Такое регулярное выражение будет искать строки, начинающиеся с буквы
a, за которой идёт символ d или последовательность символов bcd.
Графическое представление регулярного выражения (создано с помощью Regexper)
Это — не то же самое, что
ab?c?d, так как такое регулярное выражение отреагирует на последовательность символов acd. Кроме того, в регулярных выражениях можно использовать символ |, играющий роль оператора ИЛИ. Например, конструкция a|b найдёт символ a или символ b, что не особенно отличается от возможностей конструкции [ab].Но если объединить эту возможность с группировкой — может получиться нечто весьма полезное. Например, конструкция вида
(dog)|(cat) способна найти и dog, и cat. В некоторых программах группировка способна помочь в выделении интересующих разработчика фрагментов кода, или может позволить выполнять продвинутую замену текстов. Например, в некоторых программах можно выполнить поиск с использованием регулярного выражения id=([0-9])+, а в строке замены можно использовать конструкцию \1 для того чтобы сослаться на любое число, совпавшее с выражением, указанным в скобках. То, как именно это будет выглядеть, зависит от конкретной программы. Например, в некоторых программах может применяться нечто вроде &1.В чём польза регулярных выражений? Зачем их изучать?
О самих регулярных выражениях можно говорить ещё очень долго. Но сейчас давайте немного от них отвлечёмся и поговорим о том, какую пользу они могут принести тому, кто умеет с ними работать. Предположим, у нас имеется лог-файл, в котором содержится масса температурных данных в градусах Цельсия. В этом файле есть и другие данные. Но все температурные данные представлены в виде чисел, за которыми идёт пробел и буква
C. В результате температурные показатели могут выглядеть, например, как -22 C и 13.5 C.Преобразовать эти числа к необходимому виду можно с помощью чего-то вроде awk. Не хочу тут вдаваться в подробности об awk, отмечу лишь то, что тут имеется функция
match и функция gensub, которая позволяет осуществлять поиск и замену строковых данных с использованием регулярных выражений. Кроме того, программа позволяет фильтровать строки с использованием правил, которые представляют собой регулярные выражения, ограниченные символами косой черты. Взгляните на этот код:/ C$/ {
if (match($0,/([-0-9.]+) C/,matchres)) # . в [] не нуждается в экранировании
print gensub(/[-0-9.]+ C/,matchres[1]*9.0/5.0+32 " F","g")
else
print
next; # продолжить работу, занявшись следующей строкой
}
{ print } # print other lines
В первой строке кода осуществляется поиск текстов, содержащих пробел и букву
C в конце строки. Подпрограмма match получает число в matchres[1]. При таком подходе она сочтёт подходящей и бессмыслицу вроде -…C, но мы можем предположить, что в наших данных ничего такого нет. Возможно, ситуацию улучшит использование такого регулярного выражения: -?[0-9]\.?[0-9]* (правда, обратите внимание на то, что для использования такого регулярного выражения с grep, из-за использования в его начале символа -, нужно будет воспользоваться опцией -e). Преобразование выполняет функция gensub. Как видите, для решения задачи понадобилось немало знаний о регулярных выражениях.Варианты регулярных выражений
К сожалению, между способами использования регулярных выражений существуют небольшие различия. Вот что однажды сказал по этому поводу Дональд Кнут: «Я определяю UNIX, как 30 определений регулярных выражений, живущих под одной крышей».
Я уже говорил о некоторых из этих различий. Например, некоторые реализации регулярных выражений воспринимают скобки как группировочные символы в том случае, если они не экранированы. А другие, при таком их использовании, требуют их экранировать. Иначе скобки будут восприниматься как обычные символы.
Часто в регулярных выражениях используются сокращённые конструкции для описания чего-то вроде цифр и пробельных символов. Это полезная возможность, так как она повышает переносимость регулярных выражений. Например, конструкция
[:digit:] является заменой для [0-9]. В некоторых программах для той же цели используются особые управляющие символы, вроде \d. Здесь можно найти таблицу, в которой имеются описания распространённых систем регулярных выражений.Инструменты для отладки регулярных выражений
Собственно говоря, это — всё, что нужно знать о регулярных выражениях для начала работы с ними. Если вы хотите отлаживать регулярные выражения в интерактивном режиме, то знайте, что существует множество хороших инструментов, направленных на решение этой задачи. Ещё можно строить схемы регулярных выражений. Это помогает лучше понимать их смысл.
Возможно, вам пригодится библиотека регулярных выражений, из которой можно, так сказать, что-нибудь позаимствовать. А если вы хотите изучать регулярные выражения в игровой форме — можете заглянуть сюда и сюда.
Пользуетесь ли вы регулярными выражениями, работая в Linux?
Все переводы серии
Кунг-фу стиля Linux: удобная работа с файлами по SSH
Кунг-фу стиля Linux: мониторинг дисковой подсистемы
Кунг-фу стиля Linux: глобальный поиск и замена строк с помощью ripgrep
Кунг-фу стиля Linux: упрощение работы с awk
Кунг-фу стиля Linux: наблюдение за файловой системой
Кунг-фу стиля Linux: наблюдение за файлами
Кунг-фу стиля Linux: удобный доступ к справке при работе с bash
Кунг-фу стиля Linux: великая сила make
Кунг-фу стиля Linux: устранение неполадок в работе incron
Кунг-фу стиля Linux: расшаривание терминала в браузере
Кунг-фу стиля Linux: синхронизация настроек
Кунг-фу стиля Linux: бесплатный VPN по SSH
Кунг-фу стиля Linux: превращение веб-приложений в полноценные программы
Кунг-фу стиля Linux: утилита marker и меню для командной строки
Кунг-фу стиля Linux: sudo и поворот двух ключей
Кунг-фу стиля Linux: программное управление окнами
Кунг-фу стиля Linux: организация работы программ после выхода из системы
Кунг-фу стиля Linux: регулярные выражения
Кунг-фу стиля Linux: запуск команд
Кунг-фу стиля Linux: разбираемся с последовательными портами
Кунг-фу стиля Linux: базы данных — это файловые системы нового уровня
Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории
Кунг-фу стиля Linux: PDF для пингвинов
Кунг-фу стиля Linux: мониторинг дисковой подсистемы
Кунг-фу стиля Linux: глобальный поиск и замена строк с помощью ripgrep
Кунг-фу стиля Linux: упрощение работы с awk
Кунг-фу стиля Linux: наблюдение за файловой системой
Кунг-фу стиля Linux: наблюдение за файлами
Кунг-фу стиля Linux: удобный доступ к справке при работе с bash
Кунг-фу стиля Linux: великая сила make
Кунг-фу стиля Linux: устранение неполадок в работе incron
Кунг-фу стиля Linux: расшаривание терминала в браузере
Кунг-фу стиля Linux: синхронизация настроек
Кунг-фу стиля Linux: бесплатный VPN по SSH
Кунг-фу стиля Linux: превращение веб-приложений в полноценные программы
Кунг-фу стиля Linux: утилита marker и меню для командной строки
Кунг-фу стиля Linux: sudo и поворот двух ключей
Кунг-фу стиля Linux: программное управление окнами
Кунг-фу стиля Linux: организация работы программ после выхода из системы
Кунг-фу стиля Linux: регулярные выражения
Кунг-фу стиля Linux: запуск команд
Кунг-фу стиля Linux: разбираемся с последовательными портами
Кунг-фу стиля Linux: базы данных — это файловые системы нового уровня
Кунг-фу стиля Linux: о повторении кое-каких событий сетевой истории
Кунг-фу стиля Linux: PDF для пингвинов


