Комментарии 166
Для разработки cli под растом я пользуюсь clap — очень помогает для обработки аргументов команды.
Так же в Го мне очень не нравится подход с дефолтными значениями и ошибка это просто такое значение. Тем самым Го позволяет вам забить/забыть на обработку ошибок и программа что то будет дальше выполнять.
Как пример вашей функции у которой мы первую ошибку забыли обработать и у нас в любом случае есть значение в contents и мы что то будем передавать в WriteFile.
func (config *Config) Save() error {
contents, err := json.MarshalIndent(config, "", " ")
err = ioutil.WriteFile(config.path, contents, 0o644)
...
return nil
}Но почему то в Го сообществе это считают нормальным. Я как то сказал, что жду генерики, чтобы можно было сделать нормальные Optional и Either и меня все заминусовали :)))
По-хорошему, такую ситуацию должен отлавливать линтер. go vet это должен отследить в рамках проверки на useless assignments.
Когда дженерики сделают (а их сделают, работа над proposal активно ведется), возможное наличие Optional не будет противоречить гошной концепции ошибок как значений, это скорее про избежание nil pointer dereference. Просто функция будет иметь сигнатуру вида:
func MyFunc[type T](s string) (Optional[T], error)
Either может не вписаться в текущую концепцию, потому что есть случаи, когда функция хоть и возвращает ошибку, но при этом возвращает какое-то значение
Потому что это привычка. Вон всё ядро на таком написано (в смысле на С, в котором нет исключений)
Да, ладно бы старики так писали, но Го это же хипстерское молодое и там все горой за такую обработку. И про генерики крутят носами что мол зачем оно нам. У нас есть кодогенерация и мы на ней все легко и просто делаем.
Может быть просто история циклична? Новые реализации появляются, новые концепции — редко.
Go это про простые (simple, not easy) подходы к разработке. В том числе и к разработке компилятора языка. Часто эта простота идет в приоритете над удобством использования, и можно очень по-разному к этому относиться :)
Я думаю писать в лоб как на Го можно на любом языке. Но если Джаву все козлят, что она многословна, то в Го кол-во строк для одного и того же решения получается больше. И всем это вдруг нравится.
Или почему генерики есть для map/list которые из коробки, но для остальных продвигается мантра — генерики это зло.
Еще вариант, у нас все имеет дефолтные значения, кроме ссылки, она может быть нуль, но ссылка когда interface{} там опять уже всегда не нул а надо копать в глубину чтобы понять какое значение.
И поэтому я не понимаю о какой простоте можно говорить в Го.
И поэтому я не понимаю о какой простоте можно говорить в Го.
А он и не простой по факту.
Отличная линка.
Отличная линка.
Там больше ворчание, которое мы издаем при изучении всего нового.
Скажем, первые 3 пункта подряд — чисто достоинства языка, выставляемые как недостаток.
Там пишется, что компилятор Go ограничивает мусор в коде и требует определенного форматирования.
Для чего для других языков создаются code styles и утилиты их проверящие (в Go же своя встроенная go fmt и ограничения компилятора на мусорный код)
Зачем брать какую то часть и описывая ее говорить, что все остальное тоже фигня. Там много чего по существу.
Однако полный разбор этой статьи — потратить кучу времени.
Я сразу отметил низкий уровень знакомства автора с языком.
Разбирать его брюзжание — стоит ли?
У автора выпирает то, что он ожидает увидеть другой язык.
Первые 3 пункта — достоинства языка, идущие в глазах автора как недостатки
4-й пункт — чисто вкусовщина, реально нейтральная вещь. Просто ему не нравится.
5-й пункт — автор говорит о неудобстве, но при этом не замечает реальной проблемы (о которой вы упомянули). Я бы не принимал всерьез слова человека с таким уровнем незнания языка как у него.
6-й пункт — вкусовщина, нейтральная вещь, но ему не нравится.
7-й пункт — вкусовщина. Кто то скажет что это плохо. Кто то скажет, что удобно, что можно одноименную переменную использовать.
8-й пункт — ээээ… А что вы вообще ожидали увидеть в языке со статической типизацией?
9-й пункт — притянуто за уши. Автор использует пример с append, которая при необходимости сама распределяет новую память. Если бы он использовал пример A[10] = «нельзя», то было бы всё логично
На этом я устал разбирать его ворчание.
В первых 9 пунктах — только пункт номер 7 по делу. Да и то это вкусовщина. Можно засчитать за 0,5 проблемы языка.
Косяк языка что можно было бы заметить в пункте 5 автор статьи не заметил.
0,5 найденных автором проблем в 9 первых пунктах?
И 3 достоинства языка, преподносимые как его недостатки в этих же 9 пунктах?
Как после этого можно серьезно воспринимать этого автора и эту статью?
Конечно, косяки в языке есть, как и в других языках. Се ля ви.
Но статья больше кликбейтная, чем по делу. Львиная доля претензий — высосана автором из пальца.
8-й пункт — ээээ… А что вы вообще ожидали увидеть в языке со статической типизацией?
В языке со статической типизацией я бы хотел видеть вывод типов.
9-й пункт — притянуто за уши. Автор использует пример с append, которая при необходимости сама распределяет новую память. Если бы он использовал пример A[10] = «нельзя», то было бы всё логично
Но вставка нового элемента в мапу и так выделяет память, так что нифига не логично.
9-й пункт — притянуто за уши. Автор использует пример с append, которая при необходимости сама распределяет новую память. Если бы он использовал пример A[10] = «нельзя», то было бы всё логично
Но вставка нового элемента в мапу и так выделяет память, так что нифига не логично.
Разумеется распределяет. Но неявно.
Согласно концепциям Go всё по возможности должно быть явным.
Минимум магии.
8-й пункт — ээээ… А что вы вообще ожидали увидеть в языке со статической типизацией?
В языке со статической типизацией я бы хотел видеть вывод типов.
Оно работает в Go, если написать вот так:
a:= 5
или так
a:= «Привет»
В концепциях Go приветствуется явность.
Конечно это все, что вы ожидаете, — можно сделать.
Но тогда это будет другой язык.
Где концепции «явности» уже не столь чисты.
В Go очень многие вещи сложно понять, если не знаешь внутреннее устройство. Но с другой стороны, почему разработчик вообще должен об этом знать?
(наброс по теме пункта 44)
Есть два куска кода:
В них я совершаю одну и ту же операцию — к слайсу дописываю новое значение и получаю новый слайс. При изменении значения в первом слайсе в первой программе второй слайс не изменится, во второй программе — изменится. По коду разница вроде бы лишь в способе инициализации изначального слайса. Я никогда не задумывался об этом нюансе, хотя знаю внутреннее устройство слайсов.
Почему программист, который пришел в Go из-за его простоты вообще должен заморачиваться о таких весьма неочевидных вещах?
И поэтому я не понимаю о какой простоте можно говорить в Го.
О простоте реализации. С логичностью мало общего имеет, что подтверждает комментарий AnthonyMikh с ссылкой на пост в соседней подветке.
Лично я не считаю дженерики злом. Более того, мне бы хотелось увидеть их в Go с привычным по другим языкам синтаксисом в виде угловых скобок. Но их мы не увидим, потому что "это сильно усложнит парсер". Скорее всего скобки будут квадратными
О простоте реализации.
Например? Потому я действительно не понимаю.
Но их мы не увидим, потому что "это сильно усложнит парсер". Скорее всего скобки будут квадратными
Да, это просто жесть. Не смочь сделать <> потому что как мы будем понимать что это выражение x < z, y > w а не генерик :)))) Это кстати тоже показатель, что развивать язык тяжело будет дальше.
Как я писал год назад, у меня на хаскелле программу проще было написать чем на го. Если на хаскелле посидел с гуглом и заработало, то в го я скопипастил то что гугл насоветовал, а потом в дебаггере пытался дедлок поймать чтобы починить.
Я как то сказал, что жду генерики, чтобы можно было сделать нормальные Optional и Either и меня все заминусовали
Для этого одних лишь дженериков недостаточно, нужны ещё сумм-типы. А их в Go, скорее всего, не добавят никогда, потому что сложна.
Можно будет сделать интерфейс Optional, две структуры Some и None которы реализуют Optional и можно уже работать.
Тем самым Го позволяет вам забить/забыть на обработку ошибок и программа что то будет дальше выполнять.
Сругается компилятор, если вы использовали возвращаемые значения, но проигнорировали возвращаемую ошибку. Вы должны явно указать, что игнорируете ошибку, использовав "_", пример:
retValue, _:= funcName(param)вместо:
retValue, err:= funcName(param)То есть если программист явно отказался рассматривать ошибку, то ему виднее. Может там несущественная ошибка.
func (config *Config) Save() error { contents, err := json.MarshalIndent(config, "", " ") err = ioutil.WriteFile(config.path, contents, 0o644) ... return nil }
Но почему то в Го сообществе это считают нормальным.
Потому что ваш пример не скомпилируется, а компилятор сругается на эту строчку
contents, err := json.MarshalIndent(config, "", " ")такими словами: «err declared but not used»
такими словами: «err declared but not used»
не будет он ругаться тк err используется ниже по коду в WriteFile
не будет он ругаться тк err используется ниже по коду в WriteFile
Хоть и до этого мне было известно, что компилятор Go умный, но на всякий случай
прежде чем написать свой ответ — я попытался скомпилировать этот кусок кода.
Ошибка компилятора, которая процитирована — именно с этой проверки.
Вот смотрите мой пример в go playground
Мы успешно забыли про первую ошибку и работаем с res как ни в чем не бывало дальше.
У меня линтеры включены и ваш код выдает такое:
main.go:9:7: ineffectual assignment to `err` (ineffassign)
res, err := getInt()
^
main.go:10:2: ineffectual assignment to `res` (ineffassign)
res++
^
main.go:15:2: ineffectual assignment to `res2` (ineffassign)
res2++
^У меня и локально go build проходит без всяких предупреждений.
Так же вы говорили про ошибки компилятора, а теперь мы вдруг речь уже ведем о внешних линтерах. Которые не являются частью языка, не у всех установлены, по разному настроены, кидают простыню сообщений и на них забивают через некоторое время. Как пример разных настроек — в Goland никаких сообщений о том, что с кодом что-то не так, не показывается.
У меня и локально go build проходит без всяких предупреждений.
Так же вы говорили про ошибки компилятора, а теперь мы вдруг речь уже ведем о внешних линтерах.
Есть еще разная квалификация программистов.
Например, я и без линтеров сразу видел косяк в вашем коде.
Линтер включил только чтобы было формальное сообщение об ошибке, которое можно процитировать.
Что из того? Программисты разной квалификации существуют. Это объективно.
Как пример разных настроек — в Goland никаких сообщений о том, что с кодом что-то не так, не показывается.
У каждого языка свои проблемы.
У Раста — другие.
И что из того?
Линтеры существуют. Они осуществляют кучу полезных проверок.
Глупо их не использовать, если вашей квалификации недостаточно, чтобы наметанным опытным взглядом сразу выявить косяки в коде.
На современном железе это бесплатно, синтаксический разбор кода Go делается быстро.
Линтеры существуют.
Ну вот смотрите запускаю я go build и golint и никаких варнингов. Голанд зеленая тоже. Но вы продолжайте дальше утверждать, что проблем нет.
Есть еще разная квалификация программистов.
Мы говорим об языках и насколько они позволяют избегать ошибок.
Например, я и без линтеров сразу видел косяк в вашем коде.
Я тоже видел и это лишь показывает, что вы умнее Го компилятора :)))
У каждого языка свои проблемы.
Согласен, но назовите по каким причинам мне надо взять и писать мой микросервис не на Джаве или Расте или Ноде/Тайпскрипт а на Го?
Я вижу Го как язык который нахватался каких то обрывочных идей но целостности нет.
Или вот мои вопросы
так же отличный комментарий
Ну вот смотрите запускаю я go build и golint и никаких варнингов. Голанд зеленая тоже. Но вы продолжайте дальше утверждать, что проблем нет.
Для Go существует множество линтеров (golint, vet, errcheck, deadcode, пр.)
Но проще использовать стандарт де-факто для линтеров Go, их все объединяющий в одну утилиту, запускающую множество линтеров параллельно:
golangci-lint.run
Согласен, но назовите по каким причинам мне надо взять и писать мой микросервис не на Джаве или Расте или Ноде/Тайпскрипт а на Го?
Коммерческую разработку писать нужно на том, что лично вы лучше знаете.
Я вижу Го как язык который нахватался каких то обрывочных идей но целостности нет.
Я вижу Го как язык из которого создатели осознанно выкинули кучу заведомо известных им концепций, применяемых в других языках. Решив, что усложнения ни к чему.
Пример: усложненная Ява, монстр С++ vs упрощенный Go.
Строго говоря, зачем бы создавать Go, если оставить его таким же переусложненным как Java/C++? В чем бы тогда был смысл очередного языка?
Может показаться, что отказ от каких то концепций — это шаг назад. Что нужно только добавлять и добавлять… Но человечество проходило переусложнение еще и до С++ и до Java.
Так кучу концепций впихнули в PL/I, разработанный в середине 1960-х. И для него так и не было создано ни одного компилятора, реализующего все концепции языка.
Или вот мои вопросы
Это к разработчикам языка.
На Хабре был перевод интервью с разработчиками. Может, кто вспомнит и ссылку приведет.
Там и про генерики подробно с доводами написано почему именно они их не стали вставлять в версию Go1 (но уже будет в Go2).
В частности, в том интервью рассматриваются особенности генериков Java/C++/C#. У каждого — свои особенности, свои недостатки и свои достоинства. У всех этих языков сильно разные концепции генериков и ни одна авторов Go на тот момент полностью не устраивала. Там и объясняется почему именно авторам языка не хотелось бы видеть их в таком виде в Go.
так же отличный комментарий
В самом начале статьи по приведенной вами ссылке очень хорошо написано:
Go — простой и забавный язык. Но в нём, как и в любых других языках, есть свои подводные камни. И во многих из них сам Go не виноват. Одни — это естественное следствие прихода программистов из других языков, другие возникают из-за ложных представлений и нехватки подробностей
Да, действительно, это типичная ошибка, когда программисты, привыкшие к одному языку концепции из того языка пытаются притянуть за уши в другой язык.
Иногда это получается нормально. А иногда нет.
Ведь зачастую языки создаются вовсе не потому чтоб просто вместо «BEGIN END» использовать "{}". А именно для реализации несколько иных концепций.
Поэтому не все паттерны/рецепты из вашего прежнего языка хороши для использования их в вашем новом языке.
так же отличный комментарий
Если пробежаться по «проблемам» Go, озвучанными в статье по приведенной вами ссылке, то первые 3 пункта критикуют как раз именно достоинства Go, что компилятор препятствует замусориванию кода, что компилятор и go fmt заставляют следовать тому, для чего в других языках создаются внешние утилиты и пишутся портянки code styles.
У каждого языка есть свои особенности (иначе какой смысл в другом языке). Приведенная статья большей частью просто ворчание человека, который еще не привык к языку.
Я за свою 25-летнюю карьеру программиста освоил порядка 15 языков программирования. И концепции Go не вызвали у меня отторжения.
Коммерческую разработку писать нужно на том, что лично вы лучше знаете.
Меня интересовало ваше мнение, а не банальная отмазка.
Решив, что усложнения ни к чему.
Вы считаете, что на Джаве нельзя писать так же коряво и в лоб как и на Го?
Или можно пример когда решение на Джаве потребует больше времени на реализацию и будет сложнее в понимании чем решение на Го?
Но человечество проходило переусложнение еще и до С++ и до Java.
Те по вашему для прикладного программиста сделать в Джаве
@Mock MyInterface someVar гораздо сложнее чем на каждый чих перегенерировать моки в Го?
Там и объясняется почему именно авторам языка не хотелось бы видеть их в таком виде в Go.
Авторы лицемеры, потому что для list и map они почему то генерики сделали. Если они не нужны по их мнению, то покажите как надо без них писать.
Приведенная статья большей частью просто ворчание человека, который еще не привык к языку.
Те для вас вот такое поведение или такое это брюзжание?
Можете подобный зашквар показать в Джаве?
И концепции Go не вызвали у меня отторжения.
А какая концепция в Го? И можете показать пример кода который бы на Джаве был невыносимо сложнее/дольше писать/понимать.
Коммерческую разработку писать нужно на том, что лично вы лучше знаете.
Меня интересовало ваше мнение, а не банальная отмазка.
То что мой ответ вам не нравится, вовсе не означает, что я вам не ответил.
Как человек с опытом в 25 лет я отлично знаю как много факторов влияют на выбор инструмента.
И самый главный из них на сегодня — наличие свободных рук квалифицированных разработчиков, доступных для привлечения к работе над проектом.
Если рассматривать какой-то реальный проект, то, возможно, какое значение для каких то отдельных кусков вашего гипотетического проекта будет иметь производительность и тогда скриптовые языки нежелательны. Но рассуждать об этом не зная никакой конкретики проекта не могу.
В подавляющем большинстве случаев проблема производительности связана не столько с языком программирования, сколько с квалификацией программистов. Ибо такие вещи как работа с сетью или с БД от языка уже не зависит. А эти вещи будут серьезно влиять на производительность всей системы. Тем более микросервисной, где внутренняя сеть сжирает прилично производительности.
Мой ответ не изменился: если мы не знаем о проекте ничего конкретного, то лучше всего писать на том, что разработчики лучше всего знают.
Да, возможно, в каком-то конкретном случае был бы целесообразнее TypeScript (один и те же разработчики бэкенда и фронтенда) или Erlang (хитрая многопоточность, работа системы без необходимости перезагрузки при обновлениях) или Java (обновления версий без перезагрузки системы) и пр. и пр.
Но без знания что там именно у вас за проект — ничего более точного сказать нельзя.
Решив, что усложнения ни к чему.
Вы считаете, что на Джаве нельзя писать так же коряво и в лоб как и на Го?
Или можно пример когда решение на Джаве потребует больше времени на реализацию и будет сложнее в понимании чем решение на Го?
Вам известна история создания Java?
Там была идея — что нужно разработчика обложить со всех сторон жесткими ограничениями языка. И тогда он, мол, косячить станет меньше.
Затем мир шарахнулся в противоположенную сторону. «Программиста не нужно ограничивать. Тогда у него выше производительность». И мы наблюдали всплеск использования динамических языков.
Но по мере усложнения проектов понадобилось всё же добавить больше контроля в язык программирования.
И когда позже создавали Go, использовалась противоположенная концепция нежели у Java и динамических языков — язык должен быть со статическими типами, но при этом язык не должен быть таким многословным как Java, что нашему мозгу проще работать с облегченными концепция, это позволяет больше ресурсов мозга выделить не на борьбу с языком, а на решение собственно прикладной задачи, ради чего программиста и нанимают. И в эту концепцию прекрасно вписывается и выведение типов и сборщик мусора.
Rust в свою очередь создан для решения вполне конкретной задачи Mozilla и подобных задач. Для крупных ответственных проектов нуждающихся в надежности и производительности.
И как следствие имеем, что в Rust программисту нужно детально прописывать коде свою хотелку. Что существенно увеличивает стоимость (и сроки) реализации проектов.
Если вы одинаково хорошо знаете все эти языки и хорошо представляете что за проект вы будете делать следующим — то, в зависимости от проекта, вы можете выбрать индивидуально под проект идеально подходящий под него язык — Java, Python, Go или Rust.
На практике, разумеется, это невозможно. У нас есть предпочтения, любопытство в изучении нового или напротив желание расслаблено работать по накатанной технологии. Кроме нас над проектом (если он сколько-нибудь крупный) работают куча других людей, которые обладают другими знаниями языков.
Поэтому объективный выбор языка программирования лучше подходящий под тот или иной проект — невозможен. Но это не означает, что к этому не нужно стремиться.
Я за свою 25-летнюю карьеру программиста освоил порядка 15 языков программирования. И концепции Go не вызвали у меня отторжения.
15 вариаций Алгола?
Я за свою 25-летнюю карьеру программиста освоил порядка 15 языков программирования. И концепции Go не вызвали у меня отторжения.
15 вариаций Алгола?
Верное замечание — подавляющее большинство современных языков программирования являются вариациями Алгола.
Кроме SQL (HTML — не язык программирования). Ну и кроме Хаскеля.
А все эти C, C#, Go, Rust, Java, Python и пр. — по сути вариации Алгола, да.
Согласен, но назовите по каким причинам мне надо взять и писать мой микросервис не на Джаве или Расте или Ноде/Тайпскрипт а на Го?Не надо воспарять, какие еще микросервисы??? Тема, напомню «Разработка инструмента командной строки».
У Го один из лучших набор либ.
Просто функция будет иметь сигнатуру вида:
func MyFunc[type T](s string) (Optional[T], error)
Это не решит проблему тк Optional это уже результат какой-то. Как пример фун-ия getUserById которая вполне может вернуть юзера или пустой опшинал если юзера нет. А так можно будет получить ошибку Connection Error забить на нее и думать что юзера нет и давайте мы его создадим.
Either может не вписаться в текущую концепцию, потому что есть случаи, когда функция хоть и возвращает ошибку, но при этом возвращает какое-то значение
Это как по мне так вообще криво. Я даже не могу представить ситуацию когда такое может понадобиться.
А так можно будет получить ошибку Connection Error забить на нее и думать что юзера нет и давайте мы его создадим.
Так в том и смысл, что мы должны по-разному обработать ошибку, когда пользователь по id не найден (выдать условный 404), и когда у нас ошибка соединения (выдать условный 500, или возможно даже инициировать повторный запрос с переподключением). Ошибки это значения, и обработка ошибок — это не только прокидывание их вверх по стеку.
Я даже не могу представить ситуацию когда такое может понадобиться.
Имплементации io.Reader и io.Writer как правило возвращают количество считанных или записанных байт даже если вернулась какая-то ошибка.
Я говорю про ситуацию когда у вас фун-ия вернула (Optional.empty, SomeError) и вы забыли обработать ошибку и у вас по прежнему есть доступ к результату который пустой и дальше по коду вы будете что то с этим результатом делать.
Ошибки это значения, и обработка ошибок — это не только прокидывание их вверх по стеку.
Да точно, но обычно с этой информации при ошибке особо нет толку. Ну и по крайней мере можно будет сделать Either в своем коде и работать правильно.
Имплементации io.Reader и io.Writer как правило возвращают количество считанных или записанных байт даже если вернулась какая-то ошибка.
Ну в расте похожая история, например бинарный поиск возвращает Result<usize, usize>, в случае Ок(i) значит что значение найдено по индексу i, а Err(j) означает что значение не найдено, но если его вставить по j то оно не нарушит порядок. Для update_or_insert эта функция просто замечательно подходит.
Так и для чтения если вам так нужно всегда возвращать количество прочитанных байт можно возвращать Result<usize, (usize, WriteError)>, или прямо в сам WriteError поле добавить, сколько байт записали прежде чем ошиблись. Но все же, такое использование намного реже бывает чем "или результат или ошибка".
«Вот в этом куске (значение) случилась (ошибка) разбора». Плюс, «лобовой» способ избежать «побочных эффектов» любителям функционального стиля.
в чем проблема сделать это частью ошибки? иначе если вы пробросите просто одну ошибку вверх то для какой части она была потеряется
«Там строка и тут строка. До свидания, пока.» Как-то так на Go выходит функция. (Чаще всего. Некоторым знакомым удаётся писать даже подобие дженериков на гошных интерфейсах, но читать такое тяжко.)
- И да, пробрасывать ошибки наверх через весь код в Go затруднительно, т.к. «ошибка» — это обычное значение какого-то типа (использовать для этого «error» просто договорились). Меня не напрягает т.к. в основном делаю что-то низкоуровневое и концепции из ООП туда плохо заходят. А профессиональные «прикладники» с бэкграундом в java/C++/etc. заслуженно кидают в Go помидоры. Но нужен ли он им?
Но нужен ли он им?
Ну Го продвигается как язык для написание микросервисов те он вполне должен годиться для написания бизнес логики а не только лоу-левел для кубернетиса.
«Сложные» ошибки есть в стандартных пакетах, а в своих проектах обычно хватает оборачивания ошибки в свою ошибку с описанием, благо в Go1.13 завезли это в стандартную библиотеку Работа с ошибками в Go 1.13
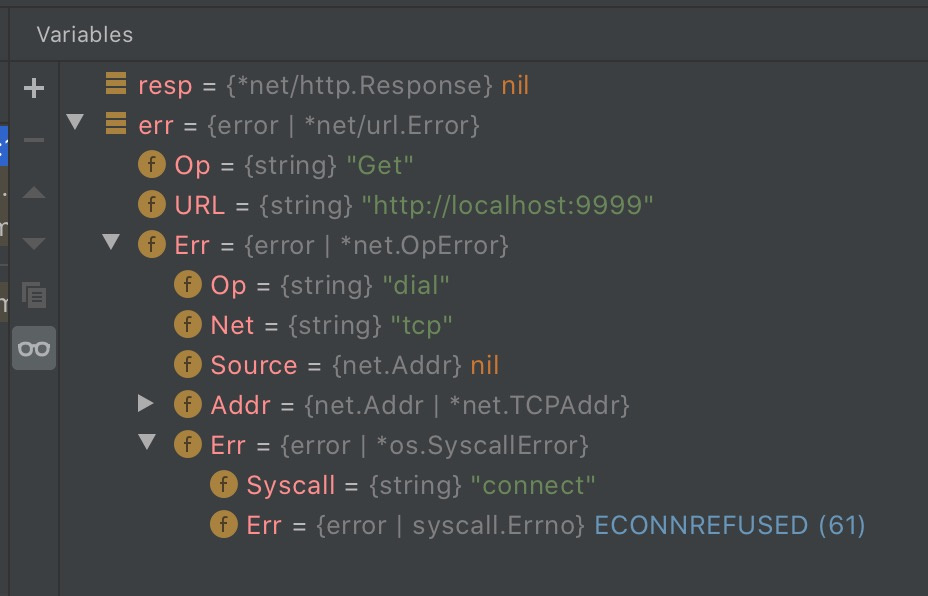
Но обрабатывать эти ошибки, вставляя буквально после каждого вызова внешней функции все эти if err != nil { return } реально утомляет. И зачастую эта проверка на ошибки визуально занимает больше места, чем сам вызов "полезной" функции. В rust'е всё же с ? это всё элегантнее смотрится. И всякие там .map_err() помогают.
Вообще, по задумке, обработка вида if err != nil { return } не должна быть единственным способом обработки ошибки — ошибка иногда должна обрабатываться иначе (и не только на самом высоком уровне), реагировать на отдельный вид ошибок, или врапить ошибку в другую.
Например, слой бизнес-логики не должен ловить ошибки sql.ErrNoRows или mongo.ErrNoDocuments для того, чтобы произвести особую обработку, он должен отлавливать что-то наподобие repo.ErrNotFound.
Всё верно, иногда ошибка обрабатывается так как вы написали, подобная обработка является частью бизнес-логики и само значение ошибки является значимым и ожидаемым ("ошибки" типа io.EOF или sql.ErrNoRows — это просто один из вариантов корректного завершения вызова, который должен быть обработан).
Выше же я писал про наиболее распространённый случай, когда ошибка просто пробрасывается наверх, иногда заворачиваясь в дополнительное описание/контекст, когда конечная судьба такой цепочки ошибок — просто быть залоггированной или выведенной пользователю в текстовом виде. Этот кейс встречается как ни крути чаще других, и именно он вызывает в Go наибольшую боль. Речь была об этом. Эргономика должна затачиваться под наиболее частый случай, а не под наиболее редкий. В расте это решено лучше благодаря ? и другим удобствам.
Выше же я писал про наиболее распространённый случай, когда ошибка просто пробрасывается наверх, иногда заворачиваясь в дополнительное описание/контекст, когда конечная судьба такой цепочки ошибок — просто быть залоггированной или выведенной пользователю в текстовом виде. Этот кейс встречается как ни крути чаще других, и именно он вызывает в Go наибольшую боль. Речь была об этом. Эргономика должна затачиваться под наиболее частый случай, а не под наиболее редкий. В расте это решено лучше благодаря? и другим удобствам.
Ну не знаю почему вы считаете что ваш вариант чаще. Наверное пишете утилиты для тех. спецов?
Обычному пользователю в законченной системе вообще ошибка низкоуровневая никак не нужна.
Я логгирую по месту возникновения — там можно подробней квалифицировать ошибку.
А ваш кейс прекрасно решается через panic.
Логгировать по месту возникновения — значит размазать логику логгирования по всему приложению. С архитектурной точки зрения не всегда хорошо (хотя, конечно, вопрос дискуссионный).
А panic — вообще последнее средство. Решать на паниках какие-то кейсы — кмк моветон. Но, опять же, вкусовщина.
Логгировать по месту возникновения — значит размазать логику логгирования по всему приложению. С архитектурной точки зрения не всегда хорошо (хотя, конечно, вопрос дискуссионный).
На каждом уровне код лучше всего знает свою ситуацию.
И логгирование по месту как раз позволяет сопроводить запись в лог подробностями, не доступными выше и ниже.
И полноценное логгирование или сразу по месту идет или вы перебрасываете кучу информации вверх по стеку. По сути это одно и тоже. Иного и не дано, если вам нужна подробная диагностика.
Правда при переброске информации для логгирования вверх по стеку вам нужна будет какая то удобная структура для этого, если вы вообще собираетесь структуировать логи, а не мешать все в кучу в одну длинную строку. То есть вам в любом случае нужно что то сложное передавать и это предусматривать.
И тут простота маскирования ошибки в Rust перестает быть полезной. Если вам нужно сопровождать ошибку полезной информацией на каждом этапе и/или детально логгировать её — вам нужно это запрограммировать.
Если же речь идет об простом изменении потока выполнения программы «с ошибкой» или «без ошибки» без уточнения подробностей об ошибке, то да, вариант Rust получается компактным.
А panic — вообще последнее средство. Решать на паниках какие-то кейсы — кмк моветон. Но, опять же, вкусовщина.
Если вам совершенно не нужны все эти промежуточные слои, как было описано выше — то нормальное средство.
Паника ловится в Go без проблем и вся программа никуда не вылетает.
Сколько программистов, столько и мнений, да.
Проброс информации об ошибке наверх делается элементарно с помощью какого-нибудь pkg/errors через wrap. Этой информации вполне хватает для отладки.
В расте как правило 2 способа обработать ошибку:
- прокинуть её выше не меняя
- завернуть её в свою ошибку, ну как эксепшны обычно зваорачиваются в длинную портянку Inner -> Inner ->… Стектрейс при желании конечно же есть.
Так что не понимаю, в чем проблема такую ошибку залоггировать и зачем тут нужны паники.
Но обрабатывать эти ошибки, вставляя буквально после каждого вызова внешней функции все эти if err != nil { return } реально утомляет
Ошибку следует обрабатывать близко к моменту её появления, иначе вы теряете контекст.
habr.com/ru/company/ruvds/blog/515674/#comment_22004264
Если уж такая обработка по вашему алгоритму не нужна и писать проверку ошибки после каждого вызова лениво, то можно использовать panic/recover
И да, пробрасывать ошибки наверх через весь код в Go затруднительно, т.к. «ошибка» — это обычное значение какого-то типа (использовать для этого «error» просто договорились).
В общем случае информация об ошибке должна обрабатываться близко к моменту когда её поймали.
Пример:
Что вам даст ошибка «Файл не найден» на самом верху? Какой файл? Что за файл?
Ах, это файл конфигурации? Вот и надо его обрабатывать в процедуре загрузки конфигурации и наверху отдавать ошибку «Конфигурация не загружена»
Когда ошибка добирается до самого верха — то подробности уже ничего полезного не дают.
Впрочем, иногда нужно обработать ошибку выше, но это поблизости чуть повыше, когда контекст еще ясен — на это есть вот такой механизм работы с вложенными ошибками habr.com/ru/company/mailru/blog/473658
А вот профессионал (синьор) на java как-то вполне серьёзно объяснял мне почему исключения таки надо прокидывать. И с ним я тоже не спорил, потому что KPI. Разбор исключений в разы тормозит разработку. То что в определённых ситуациях стектрейсы наматываются вплоть до коллапса его софтины — это проблемы «негров». В основном же работает (и даже через тесты проходит, так тестируют).
Вот это, а ещё достаточно низкая энтропия языка приводит к отторжению golang профессионалами с бэкграундом на java/scala/c++/etc.
Мне-то ок, но я-то начинал с asm на всяких микроконтроллерах и basic на самосборном zx-spectrum (с жёсткой адресацией инструкций и циклами через goto, зато прямым доступом к памяти и возможностью легко вклеить кусок на том же asm).
А вот профессионал (синьор) на java как-то вполне серьёзно объяснял мне почему исключения таки надо прокидывать. И с ним я тоже не спорил, потому что KPI. Разбор исключений в разы тормозит разработку. То что в определённых ситуациях стектрейсы наматываются вплоть до коллапса его софтины — это проблемы «негров».
Если хочется работать в таком стиле (ну наверное это когда то надо, например, в каких то простых утилитах) — то не нужно обрабатывать error, тут можно использовать panic в Go.
Что вам даст ошибка «Файл не найден» на самом верху? Какой файл? Что за файл?
Ах, это файл конфигурации? Вот и надо его обрабатывать в процедуре загрузки конфигурации и наверху отдавать ошибку «Конфигурация не загружена»
Ну так это сложно, нужен дополнительный код, которого лишь немного меньше стало с errors.Wrap. А в каком-нибудь Rust это может выглядеть так:
let mut config_file = File::open(config_path)
.context(CantReadConfigurationFile { config_path })?;
// работаем с config_fileНу так это сложно, нужен дополнительный код, которого лишь немного меньше стало с errors.Wrap. А в каком-нибудь Rust это может выглядеть так
А как это будет выглядеть, если нужно залоггировать первичную ошибку и все её последствия (вторичные ошибки), возникающие по мере разматывания стека на верхний уровень? И сопроводить эти логи дополнительной информацией?
В серьезном софте подробнейшее логгирование — это норма, для серверных решений например.
Вот я буквально ниже скинул пример как я пофиксил решение автора в расте. Ошибка выглядит так:
ApiError(Graphql(Some([Error { message: "Access denied! You need to be authorized to perform this action!", locations: Some([Location { line: 2, column: 5 }]), path: Some([Key("tweets")]), extensions: Some({"code": String("INTERNAL_SERVER_ERROR"), "exception": Object({"stacktrace": Array([String("Error: Access denied! You need to be authorized to perform this action!"), String(" at Object. (/home/node/app/node_modules/type-graphql/dist/helpers/auth-middleware.js:13:44)"), String(" at Generator.next ()"), String(" at fulfilled (/home/node/app/node_modules/tslib/tslib.js:107:62)"), String(" at runMicrotasks ()"), String(" at processTicksAndRejections (internal/process/task_queues.js:97:5)")])})}) }])))Как по мне вполне детально, весь путь (MainError->ApiError->GraphqlError->InternalError) сохранен полностью.
Как это реализовать в коде.
Ну вот так например https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=5f6db8b3cb17c896f2f3b4721057303b
Дальше эта матрешка может расти неограниченно. Это подход библиотек, где надо знать ошибки.
Подходы приложений а-ля "пофиг что упало, залогировали и погнали дальше" решаются либами вроде anyhow.
Какой язык вы использовали бы для разработки инструмента командной строки?
Нежно люблю Rust и немного изучаю, но для того, чтобы разработать простой инструмент коммандной строки я бы выбрал Python:
- может быть простым, как валенок, но не сильно ограничивает в извращениях, если потребуются
- миллион библиотек, кажется, на все случаи жизни
Это хороший вариант если пользоваться вашим инструментом будете только вы. Если вам придется устанавливать его кому то еще то внезапно выяснится что есть куча версий питона, плюс несовместимые версии библиотек в системе и прочие проблемы. Без virtualenv/docker пользоваться питон приложениями очень тяжело из-за совместимости и поэтому это не очень хороший вариант для легковесного консольного приложения которое должно работать у всех одинаково.
Так pipx же. pipx install — и вот у тебя уже есть независимая полная инсталляция питонного приложения :)
Это кстати в теории можно даже рассматривать как отдельный критерий для выбора языка — средство доставки вашего приложения до конечного пользователя. По сути для Go/Rust/Python существуют свои собственные менеджеры пакетов и у всех их есть свои недостатки. А если собирать например deb пакет то тут у Go/Rust будет преимущество.
что делать любям на винде у которых не предустановлен pip?
Ну там… установить? Ну то есть установить питон. Пип — просто его модуль. Дальше python -m pip install --user pipx. А дальше уже pipx install… Но это всё сложные пути — можн оже распространять через choco/scoop.
Фишка в том, что я не могу/не хочу устанавливать питон. А нативный язык он ничего не требует, просто скачал и запустил.
Да, это правда, такая проблема существует. С другой стороны вот дотнет себе все устанавливают и ничего.
Никто кроме разработчиков его не устанавливает, просто на виндовсах он предустановлен. Но если речь про кроссплатформу, то лучше все же брать что-то что не тянет мегабайты рантайма. Тем более, что написать на расте CLI тулзу чуть более чем элементарно: structopts, envconfig, anyhow и погнали.
Я давно был на винде последний раз, но раньше половина софта, который тебе был нужен (и игр), требовал установит какую-нить специальную версию vc redistributable или чего-то такого. Ну точнее они сами её качали и ставили и у тебя их было на машине 5 в итоге.
Ну как сказать предустановлен. Если приложение собрано под .NET Core, то без его установки оно работать не будет, а он точно не предустановлен.
ну так можно собирать не под кор а под фулл фреймворк, все крупные библиотеки до сих пор так делают. Кор это для докера и линукса, ну и тех кто действительно не стесняется ставить с приложением рантайм.
.NET Core умеет в компилироваться в однофайловый бинарь, прямо как golang.
Минус вижу только один — вес такого бинаря стартует с ~26 мегабайт, но едва ли это можно назвать проблемой при текущих объёмах носителей
Там в Core 3.1 отвратная реализация этого "одного exe-шника" была, он типа как файл-дроппер работал, изрыгая из себя кучу dll. Может сейчас что-то поменялось.
Обещают в .net 5 поменять (или уже поменяли?) — как только mono runtime завезут. Mono будет генерировать "тонкие" бинари через LLVM, как сейчас с xamarin для iphone.
Ну в любом случае конечного юзера (особенно нетехнаря) крайне редко беспокоят подробности реализации — скачалось? запустилось? ну и збс. Тем более, что "рыгает" оно во временную директорию, делая процесс "отрыжки" абсолютно незаметным для пользователя. Гемора с доставкой приложения точно меньше, чем у приложения с интерпретатором.
Но! Можно писать под предустановленные в системе (4ех NET 3.5) и тогда ваши утилиты будут занимать 20-40Кб.
Это камень в сторону Го.
Вот только self-contained binary на питоне сделать немного проблемно, к сожалению
UPD буду обновлять страницу, перед тем, как отправить комментарий
https://habr.com/ru/company/ruvds/blog/515674/?reply_to=21976326#comment_21974884
Есть альтернативные варианты
Докер — великолепное решение для запуска серверного софта. Иногда подходит для запуска сложного десктопного софта. И уж совсем глупо натягивать в него 500 строк элементарной консольной утилиты.
Этот код является эквивалентом следующего кода:
Всё-таки на самом деле там зовётся именно From::from, а не Into::into. Это существенно ограничивает преобразование ошибок.
Если бы я разрабатывал программы только для Linux, или если бы Linux была бы операционной системой, представляющей для меня наибольший интерес.
Вот это очень странный поинт, учитывая кросс-компиляцию Го.
В целом почти все пункты итогового сравнения относятся к обоим ЯП, разве что го действительно проще для понимания, а раст действительно лучше по памяти.
Если смотреть объективно: для Go есть Cobra и Viper (советую глянуть всем кто разрабатывает CLI программы), которые выводят Go на совсем другой уровень.
Да вроде не такое плохое сравнение. Два языка вообще невозможно сравнивать изнутри, потому что в них всегда разные подходы, и найдется тот, кто скажет: "вы просто не умеете пользоваться X", и будет прав. А вот сравнивая извне (память, быстродействие и пр.) — вполне можно.
Автор пишет, что у Go хуже с кросплатформой, но это не так (и коллеги уже выше это заметили, ведь они компетентны). У Rust только Tier1 платформы поддерживаются полноценно, а их гораздо меньше, чем то, что поддерживает Go (+ у Go есть другие реализации (TinyGo например), у Rust реализация (полнофункциональныя) одна).
Автор называет обработку ошибок Go негибкой, но это спекуляция. Ошибка в Go — это интерфейс, который может быть реализован чем угодно, куда гибче? Автор просто не умеет этим пользоваться.
Автор называет Rust мультипарадигмальным, но это спекуляция. В моём учебнике по Rust написано, что он системный. И я на 100% с этим согласен. Для прикладной разработки всегда возьму что-то другое.
Автор называет Rust более безопасным. Это конечно не так. Отличный пример релиза в котором исправлена ошибка в Borrow Checker: blog.rust-lang.org/2020/02/27/Rust-1.41.1.html — он просто не работал в оперделенных случаях. Но он — истина в послдней инстанции, и если он работает неверно, с этим ничего не поделать практически.
Автор много пишет (в т.ч. в выводах про GOROOT и GOPATH). Тут без комментариев.
Я могу на Rust написать так, что памяти в 10000 раз больше потребует, чем в случае с Go. И во столько же раз медленнее, но не буду, ведь у меня нет цели доказать превосходство Go. Правда в том, что прикладной Go удобнее и эффективнее в прикладной разработке чем системный Rust и приходится жульничать как автор чтобы доказать обратное.
Автор называет Rust мультипарадигмальным, но это спекуляция. В моём учебнике по Rust написано, что он системный.
Это ведь ортогональные понятия.
Так вот, на Rust можно писать прикладные штуки, я не спорю. Но придётся думать о памяти. Можно писать тоже самое на Python и не думать о памяти. Или думать. Но в случае с Rust мы не можем выбрать, нам придётся о ней думать, это дизайн такой. Очень полезный в системном прогаммировании. Но совершенно бесполезный в большинстве случаев современного прикладного ПО на современных ПК. Во это я имел в виду.
Ну я вот часто думаю о памяти в прикладных штуках. Недавно например переписывал сервис авторизации с сишарпа на раст. Казалось бы, куда прикладнее так сказать. А почему? А чтобы памяти меньше жрал и рпц больше выдавал, потому что на этот сервис основная нагрузка — все сервисы которым недостаточно жвт ходят туда за данными.
Но! В особо запущенных случаях (я такие знаю), память может выжираться при неумелом обращении.
Автор называет яблоки круглыми, но это спекуляция. В моём учебнике по яблокам написано, что они зелёные.
Отличный пример релиза в котором исправлена ошибка в Borrow Checker: blog.rust-lang.org/2020/02/27/Rust-1.41.1.html — он просто не работал в оперделенных случаях.
Да, не работал аж 27 дней. После чего в тесты добавили регрессию и эта ошибка больше никогда не повторится. К чему вы это все?
Почему огромная часть Go сообщества воспринимает любое не хвалебное высказывание в сторону Go как личное оскорбление?
Как по-вашему относиться к клевете? Почему новичок должен выбирать Rust начитавшись таких статей?
Ну по поводу ошибок я полностью согласен — она уровня аля детский сад. Посмотрите комментарии выше насчет ошибок или насчет простоты Го.
Почему Раст — на нем интересно писать и он делает вас лучшим программистом. В Го новичку для развития делать вообще нечего — бери здесь, кидай сюда. Новичок после Го будет думать что это абсолютно нормальный подход сделать кодогенерацию итератора вместо понимания абстракций.
Так же он эффективней Го. Я когда изучал его то баловался с задачами с leetcode.
Вот попробуйте реализовать на Го например эту задачу
У меня на Расте получилось 4 мс по ЦПУ и 778Кб по памяти.
Почему Раст — на нем интересно писать
Возможно. Тут кому как.
он делает вас лучшим программистом
Согласен.
В Го новичку для развития делать вообще нечего — бери здесь, кидай сюда
Тут кому как. Знаю нескольких людей, не самых глупых, которые Go не осилили.
Новичок после Го будет думать что это абсолютно нормальный подход сделать кодогенерацию итератора вместо понимания абстракций.
Возможно. Наверное, от человека зависит, от учебников что он читал.
Так же он эффективней Го.
Всё верно (ну если мы оба имеем в виду производительность конечного машинного кода, а не производительность нового в проекте программиста например).
Вот попробуйте реализовать на Го например эту задачу
У меня на Расте получилось 4 мс по ЦПУ и 778Кб по памяти.
Спасибо, гляну как-нибудь. В среднем Go будет вдвое медленнее и в несколько раз больше памяти съест. И это ожидаемо, таков дизайн.
Если бы вы писали эту статью, она точно была бы адекватной и возможно справедливой. Но автору до вас далеко.
Тут кому как. Знаю нескольких людей, не самых глупых, которые Go не осилили.
в каком смысле не осилили? Не смогли на нем писать ничего или не захотели писать на нем?
Возможно. Наверное, от человека зависит, от учебников что он читал.
Учебники хороши, когда их можно применять и есть куда применять. А если прочитать и не пользоваться, то все вылетит с головы.
И это ожидаемо, таков дизайн.
Да это так и есть и Джава будет медленней прожорливей. Но вот нишу для Раста и нишу для Джавы я понимаю. Ниша Го для меня загадка. Когда есть вокруг Джава, Раст, Питон или ЖС/Тайпскрипт я не понимаю когда надо выбирать Го.
Ниша Го для меня загадка. Когда есть вокруг Джава, Раст, Питон или ЖС/Тайпскрипт я не понимаю когда надо выбирать Го.
Примерно для того, для чего его применяет Google.
Для интернет-сервисов.
VM Java создает не нужный оверхед при исполнении и при разработке.
Rust создает не нужный оверхед при разработке.
Python не гарантирует стабильности, ибо динамические типы уже в среднем проекте дают сюрпризы, что же про большой говорить. И по скорости не так здорово.
Это все разные языки, идеально подходящие для разные применения.
Что, конечно же, не мешает их использовать и в пересекающихся областях.
VM Java создает не нужный оверхед при исполнении и при разработке.
Про исполнение это дискуссионный вопрос. Потому что надо брать и сравнивать что то сложное. Как пример асинхронный драйвер из vertx был самым быстрым. Или взять что из последнего и там в топе Го практически не встречается, а Джава да.
И про разработку, вы тут не правы. На Джаве программы пишутся быстрее чем на Го. Взять например простой рест ендпоинт который ассинхронный и что то читает с базы и отдает потом жсон наружу. в Джаве со спрингом это будет буквально две строчки кода, в Го я думаю вам придется написать их гораздо больше.
Rust создает не нужный оверхед при разработке.
Возможно, но думаю что дело в квалификации программиста.
И при одинаковой квалификации Го и Раст девелопера, последний будет продуктивней. Потому что ему не надо лепить какие то генераторы, а будут генерики. На каждый чих делать if err != nil а использовать цепочку вызовов.
А так же за Растом система типов а в Го будут interface{} и дальше только молится что туда попадет что ожидается.
На Джаве программы пишутся быстрее чем на Го. Взять например простой рест ендпоинт который ассинхронный и что то читает с базы и отдает потом жсон наружу
Натянутый пример.
Все упирается в том какие готовые инструменты (библиотеки и пр.) вы используете.
В предельном случае для этого вообще прослойка не нужна между пользователем и СУБД.
Это уже и многие СУБД умеют делать сами.
Почему натянутый? по большому счету большинство микро-сервисов получили запрос, куда то сходили за данными, как то их по преобразовывали и вернули результат.
Ну или вы скажите пример какой типичный микросервис будет писаться быстрее на Го а на Джаве или Расте это будет ужас ужас.
Почему натянутый?
Потому что вопрос только в том, а будете ли вы использовать какую-то готовую библиотеку, узкозаточенную под данную задачу, или нет.
Вы привели пример с такой библиотекой.
Это не имеет отношения к самому языку. Допускаю, что подобная вещь готовая есть и для Go.
Но в вырожденном случае, который вы привели в пример, нет необходимости и в промежуточном слое написанном на Java или Go или Rust или на чем угодно. Можно сразу из БД отдавать JSON.
Когда же нужно все же переварить перед выдачей пользователю, то это уже выглядит не так просто как тот вырожденный случай, что вы привели в примере своем.
Это имеет отношении к реальности. Если я решаю задачи бизнеса за Х денег на Джаве, а вы за Х*2 на Го, то бизнес не будет волновать, что я читер и взял спрингбут и погнали, а вы с нуля на чистом Го реализовываете весь стек.
П.С. И я все еще хочу увидеть типичный пример микро-сервиса который на Джаве будет тормознутым, а на Расте его реализовать потребуется куча времени, а реализация Го будет быстра и в разработке и рантайме.
Это имеет отношении к реальности. Если я решаю задачи бизнеса за Х денег на Джаве, а вы за Х*2 на Го, то бизнес не будет волновать, что я читер и взял спрингбут и погнали, а вы с нуля на чистом Го реализовываете весь стек.
Ну и как можно с вами поддерживать адекватную беседу, когда вы такие передергивания допускаете в беседе?
С чего вы решили, что на Go нужно писать всё с нуля?
Просто потому что вам там удобно думать?
Ему уже много лет и готовых библиотек полным-полно.
Понимаете, с умным человеком приятно пообщаться, может чего нового откроешь для себя.
Но при таких передергиваниях как у вас… позвольте откланяться и больше с вами не общаться.
Я не решил как раз, я вам банальный пример привел
На Джаве программы пишутся быстрее чем на Го. Взять например простой рест ендпоинт который ассинхронный и что то читает с базы и отдает потом жсон наружу
и вы сказали что это не показатель потому что я буду использовать что то готовое а это не честно. Теперь вы говорите что на Го надо брать библиотеки.
Ну тогда давайте вы покажите пример проекта на Го в котором будет простой ендпоинт который будет ходить в Редис за данными в какой нить лист и отдавать жсон этого листа наружу. Так же проект обернуть тестами с моками для сервис layer и какими нить интеграционными для хождения в Редис. И все должно тестироваться и собираться и потом создавать докер образ — причем под Линуксом/Виндовс/Мак чтобы разработчики могли это все локально собирать и смотреть.
и мы сравним с таким же проектом от меня. и посмотрим кто сколько времени потратил и какой код на выходе получился.
Я не решил как раз, я вам банальный пример привел
На Джаве программы пишутся быстрее чем на Го. Взять например простой рест ендпоинт который ассинхронный и что то читает с базы и отдает потом жсон наружуи вы сказали что это не показатель потому что я буду использовать что то готовое а это не честно. Теперь вы говорите что на Го надо брать библиотеки.
У меня где-то написано, что Go настолько радикально быстр при разработке, что на нём можно писать быстрее в тысячи раз (или сколько там времени ушло на создание Спринга)?
Покажите у меня это место, пожалуйста. Нет? Ну тогда еще раз: с человеком притягивающим аргументацию за уши общаться нет желания. Счастливо.
и посмотрим кто сколько времени потратил и какой код на выходе получился.
habr.com/ru/company/ruvds/blog/515674/#comment_22013274
Вы серьезно полагаете, что кто-то будет тратить на вас время после такой «аргументации»?
Соревнуйтесь без меня. Найдите себе такого же тролля как и вы — и дискутируйте друг с другом выдуманными доводами…
Вот ваше сообщение
в нем нет ни каких фактов, ни примеров, есть только надо быть как Гугл и делать все на Го, а Джава и Раст тормоз в разработке, а Джава так еще и тормоз в рантайме.
Мои предложения о том, что взять и сделать что то одинаковое и потом сравнить, вы просто игнорируете.
Но троль я :))))))
Хорошего вам вечера.
Мои предложения о том, что взять и сделать что то одинаковое и потом сравнить, вы просто игнорируете.
Но троль я :))))))
Вот оно:
Если я решаю задачи бизнеса за Х денег на Джаве, а вы за Х*2 на Го, то бизнес не будет волновать, что я читер и взял спрингбут и погнали, а вы с нуля на чистом Го реализовываете весь стек.
Тут: habr.com/ru/company/ruvds/blog/515674/#comment_22013268
Давайте и я попробую в последний раз написать как я вижу нашу беседу:
Вы:
VM Java создает не нужный оверхед при исполнении и при разработке.
нет ни каких либо примером или фактов, на что я вам отвечаю
На Джаве программы пишутся быстрее чем на Го. Взять например простой рест ендпоинт который ассинхронный и что то читает с базы и отдает потом жсон наружу. в Джаве со спрингом это будет буквально две строчки кода, в Го я думаю вам придется написать их гораздо больше.
те я готов подтвердить свое утверждение что на Джава я напишу быстрее вот такое чем вы на Го. Я не говорил что должны писать только на чистом Го из коробки без всяких библиотек и так же если я говорю что буду брать спрингбут то это подразумевает что вы вольны брать любую библиотеку тоже.
Ваш ответ
Натянутый пример.
Все упирается в том какие готовые инструменты (библиотеки и пр.) вы используете.
Те вы вместо того чтобы согласиться и показать мне как надо, рассказываете что задание ужасное и вообще все дело в спрингбуте. Так как это соотносится с вашим самым первым сообщением где Джава тормоз в разработке если на все мои попытки ее посрамить вы уходите в какие то разговоры ?
Потом я пытался вам сказать, что бизнесу пофиг на все наши терки, ему главное какая стоимость разработки его пожеланий. И если кто то может делать на готовых кубиках, так это только отлично. Это я к тому, что в реальном мире надо рассматривать эко-системы Джавы и Го целиком, А не считать, что в чистом Го есть горутины а Джаве только системные потоки и значит на Джаве нельзя сделать что либо кроме Thread per Request.
Дальше вы обиделись и начали меня называть тролем.
Поэтому, в который раз, чтобы не флудить словами, а доказать делом мы с вами сделаем вот такой проект и сравним сколько времени заняло, сколько строк кода получилось, какую нагрузку держит и сколько памяти жрет. Это будет лучше чем тысячи слов.
И я все еще хочу увидеть типичный пример микро-сервиса который на Джаве будет тормознутым
Зависит от масштабов.
На больших масштабах оверхед VM совсем незаметен.
Я могу взять SpringBoot, а могу Quarkus и сделать через GraalVM готовый бинарник. Могу взять Azul GC или вообще без ГЦ запускать. Те с Джава я могу покрыть огромное кол-во use case оставаясь в рамках одной системы и мне не надо менять ни утилиты для работы ни разработчиков. Или взять node.js и тайпсрипт и быть в гармонии на фронтенде и бекенде.
А про Го мне приходится допытываться хоть про какую конкретику.
Почему?
habr.com/ru/company/ruvds/blog/515674/#comment_22013274
Зависит от масштабов.Оверхед в в Яве во времени старта, «прогрева» и потреблении памяти.
На больших масштабах оверхед VM совсем незаметен.
Для серверов это может быть и не очень критично.
А по сложности языков лично я Го и Яву плюс минус считаю одинаковыми.
P.S. Таргетинг: Го создан как замена Явы, Гугл vs Оракл в энтерпрайзе.
Оверхед в в Яве во времени старта, «прогрева» и потреблении памяти.
Да есть такое, но мы можем взять GraalVM и у нас будет бинарник с быстрым стартом.
По поводу памяти, на каком нить синтетическом тесте где Го все алоцирует на стеке конечно будет большая разница. Насколько будет разница будет в реальном мире — я не знаю, не сравнивал. Если у вас есть сравнения и исходники то я буду благодарен.
Но если у нас все упирается в память то давайте возьмем Раст или разница в год на 1Гб памяти в AWS будет около 90$. Это для хорошего калифорнийского програмиста будет меньше часы работы.
А по сложности языков лично я Го и Яву плюс минус считаю одинаковыми.
Да я тоже так примерно считаю.
P.S. Таргетинг: Го создан как замена Явы, Гугл vs Оракл в энтерпрайзе.
А вот тут проблема, поскольку бизнес логику на Го писать неудобно. Поскольку там не нужны горутины, а нужны способы выразить разные абстракции. А в Го с этим проблематично :( Ни генериков, ни тип-сум, чуть в сторону и торчат уши interface{}
Или как вы будете реализовывать на Го
type User struct {
FirstName String
LastName String
}но так чтобы он был имутабельный, создавать его можно было с определенным набором данных чтобы быть уверенным что там всегда лежат правильные данные и мы могли читать его свойства FirstName/LastName
Вот пример на Джаве
@Getter
public final class User {
private final String firstName;
private final String lastName;
public User(String firstName, String lastName) {
..../validate
this.firstName = firstName;
this.lastName = lastName;
}
}и это мне гарантирует что никто его не изменит, никто не подсунет в метод другую имплементацию этого класса, объект будет всегда создан валидным и при этом все могут читать его свойства(это мы еще брали модули с ждк9, где вообще можно разделить доступ).
Вот недавняя статья про Го и чистую архитектуру. Как по мне то для 2020 года такой код выкладывать как эталон чистой архитектуры это печально :(
По поводу памяти, на каком нить синтетическом тесте где Го все алоцирует на стеке конечно будет большая разница. Насколько будет разница будет в реальном мире — я не знаю, не сравнивал. Если у вас есть сравнения и исходники то я буду благодарен.
интересная статья
Да, мне нравится. Продолжение, если интересно.
Возможно, но думаю что дело в квалификации программиста.
И при одинаковой квалификации Го и Раст девелопера, последний будет продуктивней.
Предлагаю оставить этот вопрос. Доказательства на уровне «мне кажется, я думаю» — бессмысленная трата времени.
Так а вы думаете что в расте у автора меньше ошибок или что он на нем лучше написал? Получилось достаточно эквивалентно, тем более что автор изначально написал, что ни тот ни другой особо не знает.
Так а вы думаете что в расте у автора меньше ошибок или что он на нем лучше написал?
Я думаю, что автор не в позиции оценивать Go, который он не знает (за это ручаюсь). Он некомпетентен, непрофессионален, но при этом предвзят. Об этом большинство моих комментариев.
Получилось достаточно эквивалентно, тем более что автор изначально написал, что ни тот ни другой особо не знает.
Значит автор не может адекватно судить об обоих языках сразу, а не только об одном, как я писал.
Если он криво написал на обоих языках, как вы определили что он предвзят? Был бы предвзят написал бы правильно на том, к которому предвзят, нет? А то получается что он и тот и тот обругал.
Вроде того, только не нужно генерировать скелет, макросов достаточно. Работает так же как кодогенерация, только результат кодогенерации не замусоривает код.
Это когда утилита генерит вам весь скелет, а вы просто пишите бизнес-логику.
А если надо чутка перегенерировать после того, как часть логики написана, всё написанное руками — потеряется? Или Го кладёт сгенерированный код отдельно от кастомного (типа как partial class в дотнете)? Ни разу не трогал Го, просто любопытно, ибо кодогенерация часто упирается в такую проблему разделения.
Ну я бы сказал что код на go гораздо понятнее. Асинхронщина в коде rust, а также странная модель обработки ошибок, затрудняет понимание.
Это не странная модель, а очень даже общеприпятая и хорошо и изученная в функциональных языках.
А асинхронщина в расте вполне обычная, просто еще слегка недопиленая, да и немного более низкоуровневая, но зато и менее накладная.
А можно пример как странная модель ошибок затрудняет понимание? А то у меня обычно затрудненное понимание как раз в мейнстрим языках, начиная от "какие ошибки может вернуть функция" до "как мне параллельно запустить много запросов, и остановиться при первой ошибке, а если всё успешно то собрать результаты в массив"? Звучит длинно, но по сути это просто
let list = objects.map(|x| x.make_async_call()).join().await?;
Python — больше подойдёт для Linux, у него довольно простой синтаксис, и его удобно компилировать.
C# — для Windows без сопливых. C# c его .NET и Windows это продукты от одной корпорации, а значит работать вместе они должны отменно! Я знаю что недавно С# портировали под Linux но я не могу у себя в голове связать эти две вещи C# и Linux, поэтому я не хочу пробовать программировать на C# под линухом. У меня, как и многих есть понятие «программная экосистема». В случае с Microsoft — «Windows, Microsoft Office, Visual Studio, C#».
А с продукцией компании Iople их непонятном для меня Objective-C и Swift, а также программированием под gayOS я связываться не хочу и не буду!
Статью пролистал вскольз, потому что памятуя о "Talk is cheap. Show me the code" пошел смотреть на версию раста. Что сказать, если так писать то действительно раст неудобен. Например, обработка ошибок:
#[derive(Debug)]
pub struct Error(pub String);
trait ResponseData {}
impl From<reqwest::Error> for Error {
fn from(error: reqwest::Error) -> Self {
let url = match error.url() {
Some(url) => url.as_str(),
_ => "<none>",
};
Error(format!("Error requesting {}", url))
}
}Действительно, много лишнего кода. Обратите внимание на весёлый "<none>" как бонус.
Как это написать идеоматично? А вот например вот так:
#[derive(Debug, From)]
pub struct Error(pub reqwest::Error);Дальше, работа а асихронностью:
fn run_subcommand(context: &mut Context) -> Result<(), CliError> {
let mut runtime = Runtime::new().unwrap();
match context.next_arg().as_ref().map(String::as_str) {
Some("status") => runtime.block_on(status(context)),
Some("login") => runtime.block_on(login(context)),
Some("logout") => logout(context),
...
}
}Ну это же жесть. Зачем нам асинхронный рантайм на котором мы блочимся на единственной операции? Сделали бы тогда всё синхронно.
Как написать лучше?
async fn run_subcommand(args: &mut Context) -> Result<(), CliError> {
match context.next_arg().as_ref().map(String::as_str) {
Some("status") => status(context).await,
Some("login") => login(context).await,
Some("logout") => logout(context),
...
}
}
...
#[actix_rt::main]
async fn main() -> Result<(), Error> {
...
}дальше, вот этот стремный context.next_arg().as_ref().map(String::as_str). Зачем это? Можно взять просто StructOpts или тот же clap:
arg_enum! {
#[derive(Debug)]
enum AppMode {
Status,
Login,
Logout,
...
}
}
#[derive(StructOpt, Debug)]
struct Opt {
#[structopt(possible_values = &AppMode::variants(), case_insensitive = true)]
i: AppMode,
}
async fn run_subcommand(app_mode: AppMode) -> Result<(), CliError> {
match app_mode {
Status => status(context).await,
Login => login(context).await,
Logout => logout(context),
...
}
}(К слову, я про этот arg_enum не знал, просто первая ссылка в гугле "rust structopt enum")
Вся сущность Context это по сути итератор, только очень дорогой, который реаллоцирует на каждый вызов next()
pub fn next_arg(&mut self) -> Option<String> {
let arg = self.args.get(0).map(String::clone);
if self.args.len() > 0 {
self.args.remove(0);
}
return arg;
}Можно продолжать, но уже стена образовалась, так что пожалуй не буду.
В общем, если у автора есть претензии к тому что что-то неудобно, то ИМХО это скорее от непонимания, как и что надо писать. Многие вещи можно написать куда проще. Пример с Context который в цикле всегда удаляет первый элемент достаточно наглядно это показывает.
P.S. Спасибо за перевод
match context.next_arg().as_ref().map(String::as_str)Спс, не надо.
Я думал про это :) Если найду на это время то почему бы и нет.
Мм, решил поковырять в выходной, начало — отличное
Running `target\debug\hashtrack.exe`
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: ContextError { message: "environment variable not found" }', src\main.rs:166:23
error: process didn't exit successfully: `target\debug\hashtrack.exe` (exit code: 101)Хех. Ладно, разобрался в итоге. В общем, вот ПР который я сделал, в целом должно быть достаточно понятно, что поменялось: https://github.com/cuchi/hashtrack/pull/19
Дифф +331 −296, но если учесть что он сюда считает изменение лок файла на 150 строк то получается почти в 2 раза меньше кода который делает то же самое, но надежнее и гибче (например, помощь по субкомандам намного полезнее чем то что было в старой версии).
Не думаю, что спустя 1.5 недели сюда в комменты кто-то спуститс, но раз обещал — сделал)
Кстати, забавный момент, когда я реализовывал энум с вариантами работы приложения я смотрел на фрагмент кода с примерами использования, а по факту там есть ещё режим status которой этой документацией не покрывается. Такой вот маленький баг на ровном месте, которого конечно же быть не должно и в новой версии он невозможен, т.к. описание генерируется исходя из использований в коде, а не является независимой сущностью висящей в воздухе в строковой константе.
Не думаю, что спустя 1.5 недели сюда в комменты кто-то спуститс, но раз обещал — сделал)
Интернет-воины не забывают)
Спасибо большое, сейчас буду изучать! Прелесть таких языков как раст, что если пишет не новичок и код компилируется, значит он, скорее всего не просто работает, а работает правильно!
Вообще-то нет. За алгоритмы отвечает программист все равно.
То что вы написали разве что про Хаскель можно сказать.
Но на фоне языков динамических, где действительно сюрпризы могут подстерегать и спустя месяцы после ввода в эксплуатацию — у статических языков ситуация получше. Но не радикально лучше.
Языки не формируют бинарное "работает правильно если компилируется или нет". Это спектр, где языки покрывают определенные классы проблем. У хаскелля конечно этот класс шире чем у раста, но у раста шире чем у большинства мейнстрим языков. Список проблем которые покрывает компилятор можно посмотреть на первой странице документации. В частности, если код скопилировался, значит что например нигде нет состояния гонки данных. Джавы/сишарпы подобного не гарантируют, например.
Go так сильно нацелен на простоту, что иногда это стремление даёт противоположный эффект (например, как в случаях с GOROOT и GOPATH).
Такой прострой что туда не стали вкручивать обобщения, без них все стало так просто как это было в java 1.4. Вот почему, я(лично мой выбор), никогда не перейду и даже не стану пробовать этот "недоязык" в деле.
Будет повод попробовать — работа над дженериками уже ведется, через год может увидеть свет.
Разработка инструмента командной строки: сравнение Go и Rust