
В последнее время можно наблюдать рост популярности языка программирования Python. Он используется в DevOps, в анализе данных, в веб-разработке, в сфере безопасности и в других областях. Но вот скорость… Здесь этому языку похвастаться нечем. Автор материала, перевод которого мы сегодня публикуем, решил выяснить причины медлительности Python и найти средства его ускорения.

Как Java, в плане производительности, соотносится с C или C++? Как сравнить C# и Python? Ответы на эти вопросы серьёзно зависят от типа анализируемых исследователем приложений. Не существует идеального бенчмарка, но, изучая производительность программ, написанных на разных языках, неплохой отправной точкой может стать проект The Computer Language Benchmarks Game.
Я ссылаюсь на The Computer Language Benchmarks Game уже больше десяти лет. Python, в сравнении с другими языками, такими, как Java, C#, Go, JavaScript, C++, является одним из самых медленных. Сюда входят языки, в которых используется JIT-компиляция (C#, Java), и AOT-компиляция (C, C++), а также интерпретируемые языки, такие, как JavaScript.
Тут мне хотелось бы отметить, что говоря «Python», я имею в виду эталонную реализацию интерпретатора Python — CPython. В этом материале мы коснёмся и других его реализаций. Собственно говоря, здесь мне хочется найти ответ на вопрос о том, почему Python требуется в 2-10 раз больше времени, чем другим языкам, на решение сопоставимых задач, и о том, можно ли сделать его быстрее.
Вот основные теории, пытающиеся объяснить причины медленной работы Python:
Проанализируем эти идеи и попытаемся найти ответ на вопрос о том, что сильнее всего оказывает влияние на производительность Python-приложений.
Современные компьютеры обладают многоядерными процессорами, иногда встречаются и многопроцессорные системы. Для того чтобы использовать всю эту вычислительную мощь, операционная система применяет низкоуровневые структуры, называемые потоками, в то время как процессы (например — процесс браузера Chrome) могут запускать множество потоков и соответствующим образом их использовать. В результате, например, если какой-то процесс особенно сильно нуждается в ресурсах процессора, его выполнение может быть разделено между несколькими ядрами, что позволяет большинству приложений быстрее решать встающие перед ними задачи.
Например, у моего браузера Chrome, в тот момент, когда я это пишу, имеется 44 открытых потока. Тут стоит учитывать то, что структура и API системы работы с потоками различается в операционных системах, основанных на Posix (Mac OS, Linux), и в ОС семейства Windows. Операционная система, кроме того, занимается планированием работы потоков.
Если раньше вы не встречались с многопоточным программированием, то сейчас вам нужно познакомиться с так называемыми блокировками (locks). Смысл блокировок заключается в том, что они позволяют обеспечить такое поведение системы, когда, в многопоточной среде, например, при изменении некоей переменной в памяти, доступ к одной и той же области памяти (для чтения или изменения) не могут одновременно получить несколько потоков.
Когда интерпретатор CPython создаёт переменные, он выделяет память, а затем подсчитывает количество существующих ссылок на эти переменные. Эта концепция известна как подсчёт ссылок (reference counting). Если число ссылок равняется нулю, тогда соответствующий участок памяти освобождается. Именно поэтому, например, создание «временных» переменных, скажем, в пределах областей видимости циклов, не приводит к чрезмерному увеличению объёма памяти, потребляемого приложением.
Самое интересное начинается тогда, когда одними и теми же переменными совместно пользуются несколько потоков, а главная проблема тут заключается в том, как именно CPython выполняет подсчёт ссылок. Тут и проявляется действие «глобальной блокировки интерпретатора», которая тщательно контролирует выполнение потоков.
Интерпретатор может выполнять лишь одну операцию за раз, независимо от того, как много потоков имеется в программе.
Если у нас имеется однопоточное приложение, работающее в одном процессе интерпретатора Python, то GIL никак на производительность не влияет. Если, например, избавиться от GIL, никакой разницы в производительности мы не заметим.
Если же, в пределах одного процесса интерпретатора Python, надо реализовать параллельную обработку данных с применением механизмов многопоточности, и используемые потоки будут интенсивно использовать подсистему ввода-вывода (например, если они будут работать с сетью или с диском), тогда можно будет наблюдать последствия того, как GIL управляет потоками. Вот как это выглядит в случае использования двух потоков, интенсивно нагружающих процессов.

Визуализация работы GIL (взято отсюда)
Если у вас имеется веб-приложение (например, основанное на фреймворке Django), и вы используете WSGI, то каждый запрос к веб-приложению будет обслуживаться отдельным процессом интерпретатора Python, то есть, у нас имеется лишь 1 блокировка на запрос. Так как интерпретатор Python запускается медленно, в некоторых реализациях WSGI имеется так называемый «режим демона», при использовании которого процессы интерпретатора поддерживаются в рабочем состоянии, что позволяет системе быстрее обслуживать запросы.
В PyPy есть GIL, он обычно более чем в 3 раза быстрее, чем CPython.
В Jython нет GIL, так как потоки Python в Jython представлены в виде потоков Java. Такие потоки используют возможности по управлению памятью JVM.
Если говорить о JavaScript, то, в первую очередь, надо отметить, что все JS-движки используют алгоритм сборки мусора mark-and-sweep. Как уже было сказано, основная причина необходимости использования GIL — это алгоритм управления памятью, применяемый в CPython.
В JavaScript нет GIL, однако, JS — это однопоточный язык, поэтому в нём подобный механизм и не нужен. Вместо параллельного выполнения кода в JavaScript применяются методики асинхронного программирования, основанные на цикле событий, промисах и коллбэках. В Python есть нечто подобное, представленное модулем
Мне часто приходилось слышать о том, что низкая производительность Python является следствием того, что это — интерпретируемый язык. Подобные утверждения основаны на грубом упрощении того, как, на самом деле, работает CPython. Если, в терминале, ввести команду вроде
Для нас, при рассмотрении этого процесса, особенно важным является тот факт, что здесь, на стадии компиляции, создаётся
Подобное применяется не только к написанным нами скриптам, но и к импортированному коду, включая сторонние модули.
В результате, большую часть времени (если только вы не пишете код, который запускается лишь один раз) Python занимается выполнением готового байт-кода. Если сравнить это с тем, что происходит в Java и в C#, окажется, что код на Java компилируется в «Intermediate Language», и виртуальная машина Java читает байт-код и выполняет его JIT-компиляцию в машинный код. «Промежуточный язык» .NET CIL (это то же самое, что .NET Common-Language-Runtime, CLR), использует JIT-компиляцию для перехода к машинному коду.
В результате, и в Java и в C# используется некий «промежуточный язык» и присутствуют похожие механизмы. Почему же тогда Python показывает в бенчмарках гораздо худшие результаты, чем Java и C#, если все эти языки используют виртуальные машины и какие-то разновидности байт-кода? В первую очередь — из-за того, что в .NET и в Java используется JIT-компиляция.
JIT-компиляция (Just In Time compilation, компиляция «на лету» или «точно в срок») требует наличия промежуточного языка для того, чтобы позволить осуществлять разбиение кода на фрагменты (кадры). Системы AOT-компиляции (Ahead Of Time compilation, компиляция перед исполнением) спроектированы так, чтобы обеспечить полную работоспособность кода до того, как начнётся взаимодействие этого кода с системой.
Само по себе использование JIT не ускоряет выполнение кода, так как на выполнение поступают, как и в Python, некие фрагменты байт-кода. Однако JIT позволяет выполнять оптимизации кода в процессе его выполнения. Хороший JIT-оптимизатор способен выявить наиболее нагруженные части приложения (такую часть приложения называют «hot spot») и оптимизировать соответствующие фрагменты кода, заменив их оптимизированными и более производительными вариантами, чем те, что использовались ранее.
Это означает, что когда некое приложение снова и снова выполняет некие действия, подобная оптимизация способна значительно ускорить выполнение таких действий. Кроме того, не забывайте о том, что Java и C# — это языки со строгой типизацией, поэтому оптимизатор может делать о коде больше предположений, способствующих улучшению производительности программ.
JIT-компилятор есть в PyPy, и, как уже было сказано, эта реализация интерпретатора Python гораздо быстрее, чем CPython. Сведения, касающиеся сравнения разных интерпретаторов Python, можно найти в этом материале.
У JIT-компиляторов есть и недостатки. Один из них — время запуска. CPython и так запускается сравнительно медленно, а PyPy в 2-3 раза медленнее, чем CPython. Длительное время запуска JVM — это тоже известный факт. CLR .NET обходит эту проблему, запускаясь в ходе загрузки системы, но тут надо отметить, что и CLR, и та операционная система, в которой запускается CLR, разрабатываются одной и той же компанией.
Если у вас имеется один процесс Python, который работает длительное время, при этом в таком процессе имеется код, который может быть оптимизирован, так как он содержит интенсивно используемые участки, тогда вам стоит серьёзно взглянуть на интерпретатор, имеющий JIT-компилятор.
Однако, CPython — это реализация интерпретатора Python общего назначения. Поэтому, если вы разрабатываете, с использованием Python, приложения командной строки, то необходимость длительного ожидания запуска JIT-компилятора при каждом запуске этого приложения сильно замедлит работу.
CPython пытается обеспечить поддержку как можно большего количества вариантов использования Python. Например, существует возможности подключения JIT-компилятора к Python, правда, проект, в рамках которого реализуется эта идея, развивается не особенно активно.
В результате можно сказать, что если вы, с помощью Python, пишете программу, производительность которой может улучшиться при использовании JIT-компилятора — используйте интерпретатор PyPy.
В статически типизированных языках, при объявлении переменных, необходимо указывать их типы. Среди таких языков можно отметить C, C++, Java, C#, Go.
В динамически типизированных языках понятие типа данных имеет тот же смысл, но тип переменной является динамическим.
В этом простейшем примере Python сначала создаёт первую переменную
Может показаться, что писать на языках с динамической типизацией удобнее и проще, чем на языках со статической типизацией, однако, такие языки созданы не по чьей-то прихоти. При их разработке учтены особенности работы компьютерных систем. Всё, что написано в тексте программы, в итоге, сводится к инструкциям процессора. Это означает, что данные, используемые программой, например, в виде объектов или других типов данных, тоже преобразуются к низкоуровневым структурам.
Python выполняет подобные преобразования автоматически, программист этих процессов не видит, и заботиться о подобных преобразованиях ему не нужно.
Отсутствие необходимости указывать тип переменной при её объявлении — это не та особенность языка, которая делает Python медленным. Архитектура языка позволяет сделать динамическим практически всё, что угодно. Например, во время выполнения программы можно заменять методы объектов. Опять же, во время выполнения программы можно использовать технику «обезьяньих патчей» в применении к низкоуровневым системным вызовам. В Python возможно практически всё.
Именно архитектура Python чрезвычайно усложняет оптимизацию.
Для того чтобы проиллюстрировать эту идею, я собираюсь воспользоваться инструментом для трассировки системных вызовов в MacOS, который называется DTrace.
В готовом дистрибутиве CPython нет механизмов поддержки DTrace, поэтому CPython нужно будет перекомпилировать с соответствующими настройками. Тут используется версия 3.6.6. Итак, воспользуемся следующей последовательностью действий:
Теперь, пользуясь
А вот как средство трассировки
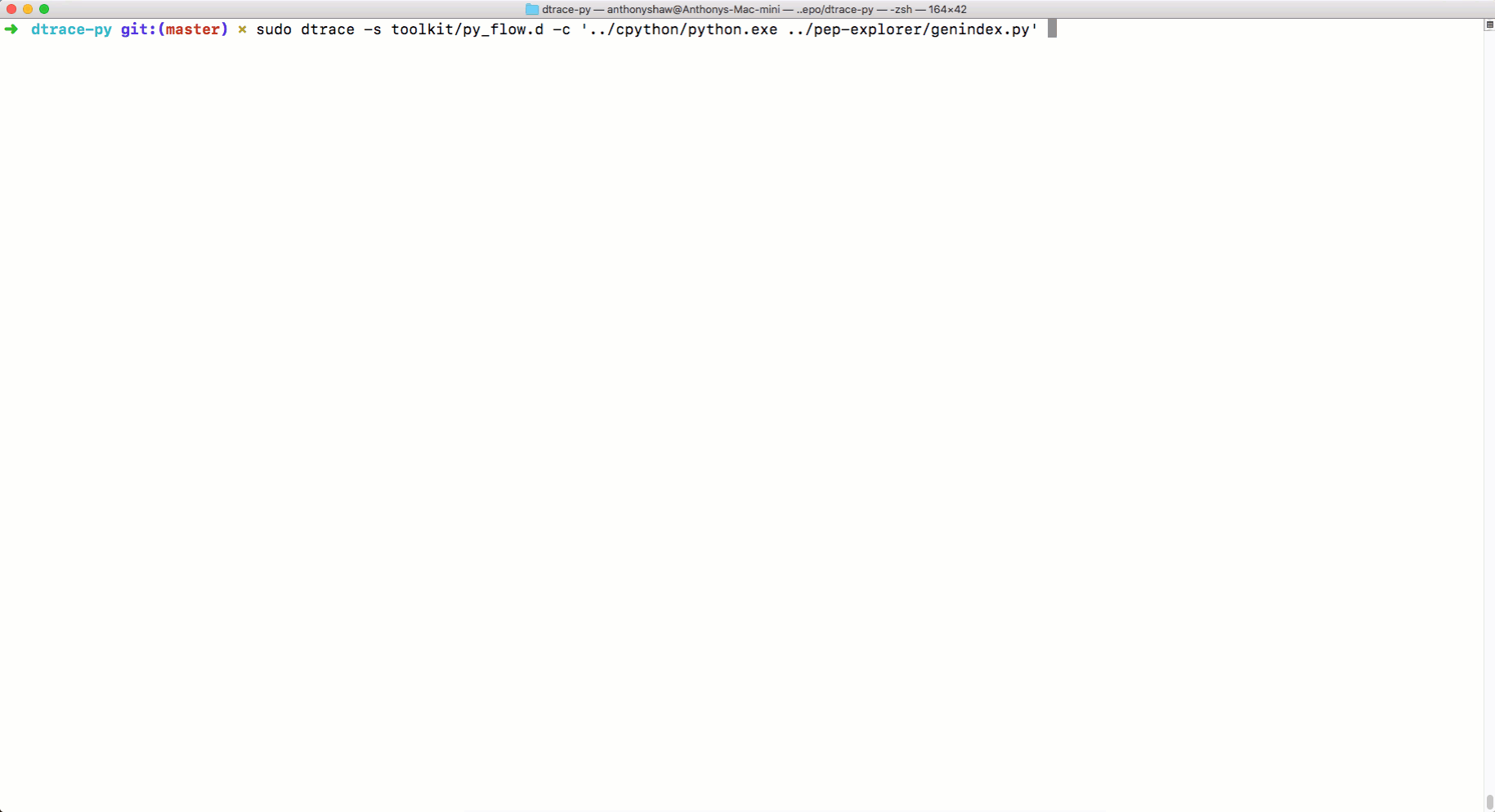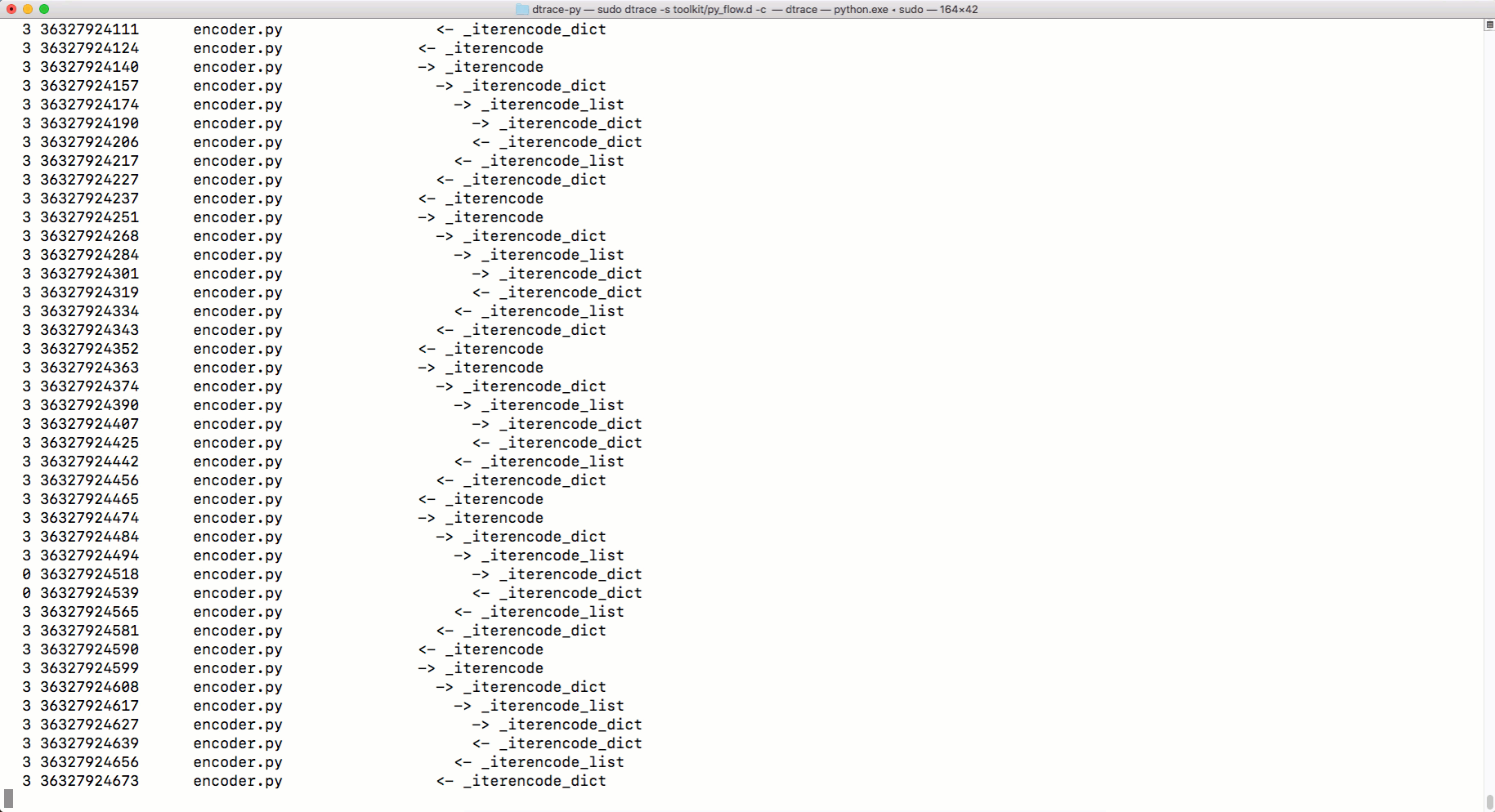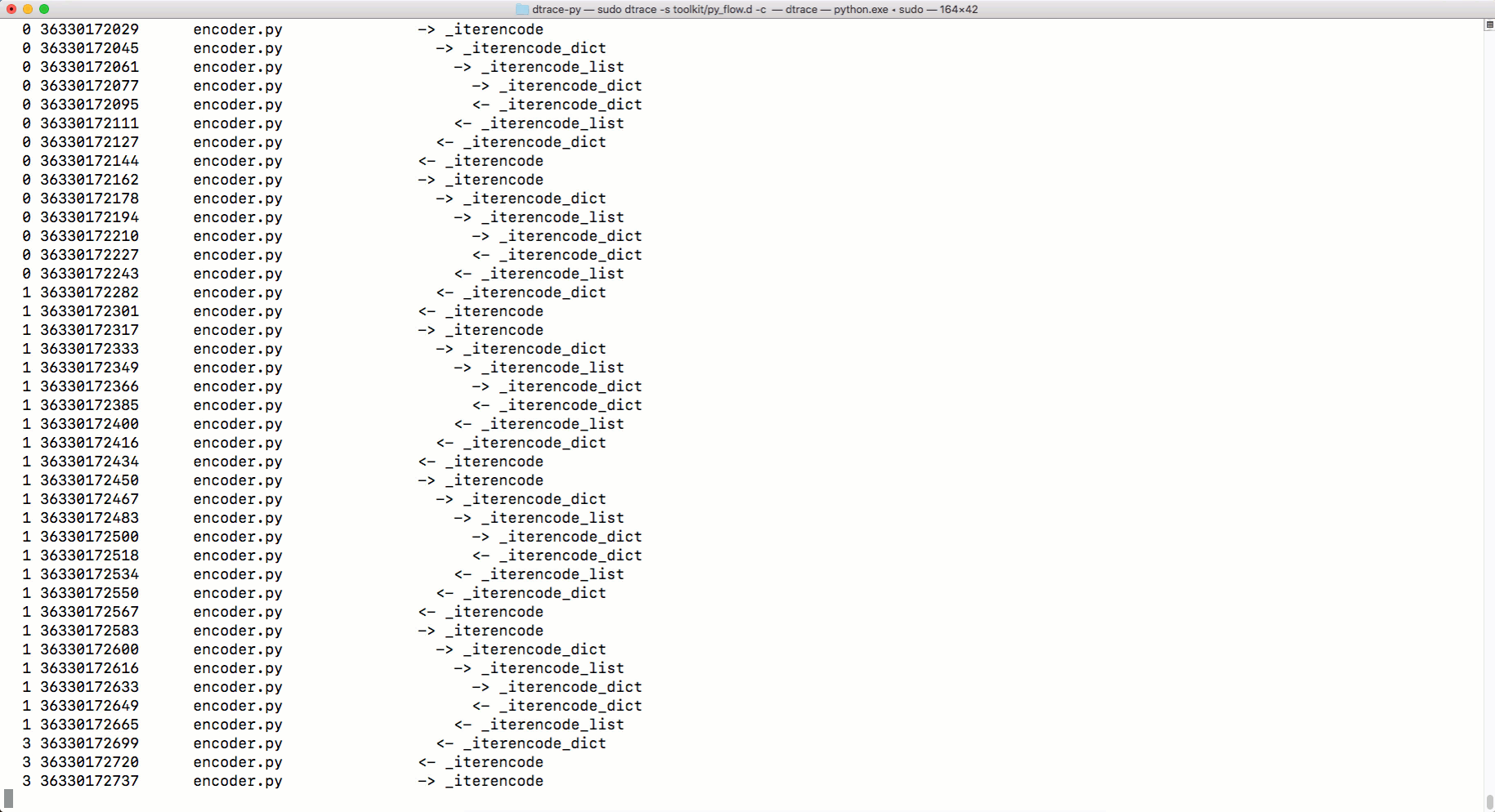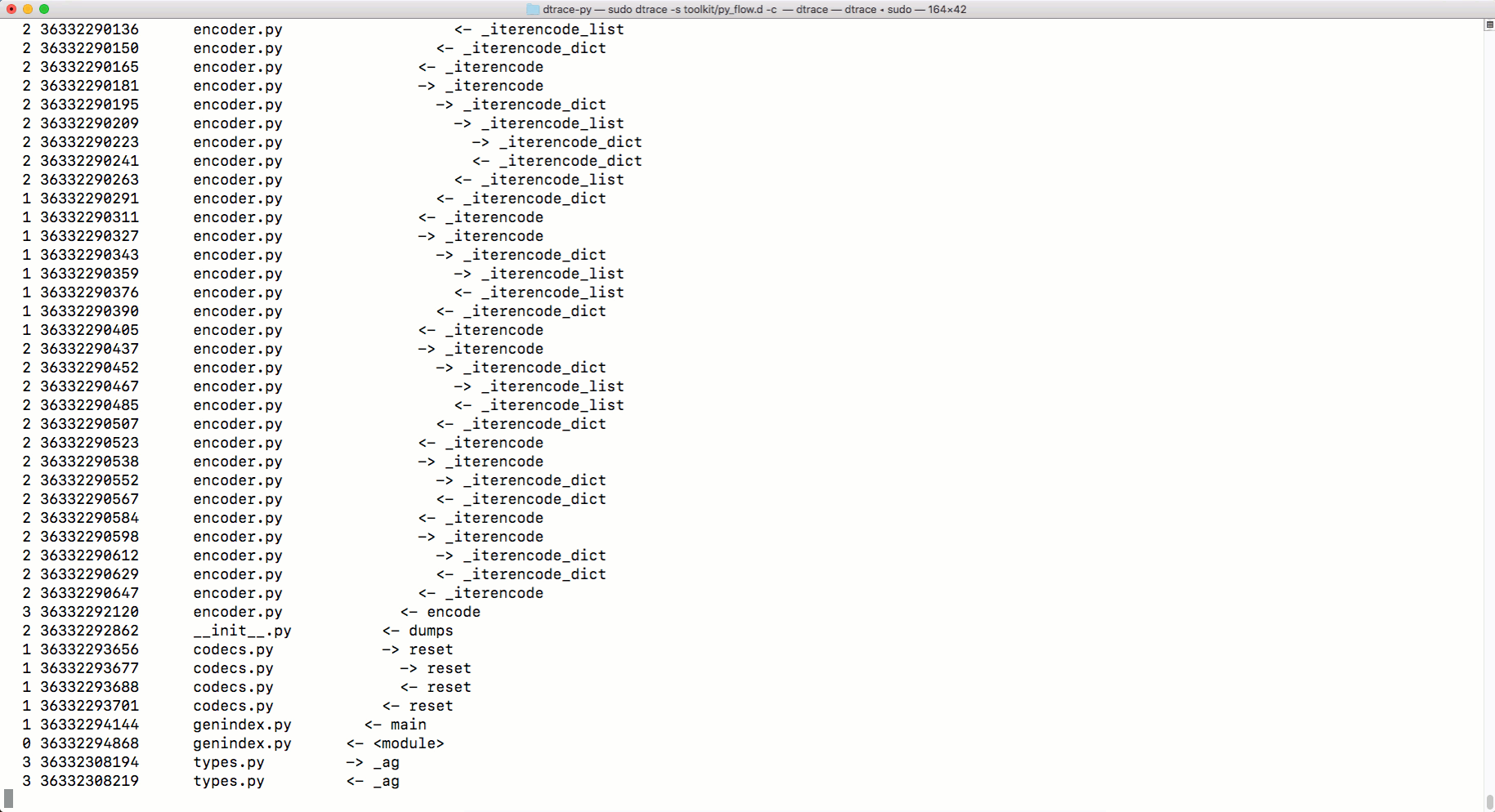
Трассировка с использованием DTrace
Теперь ответим на вопрос о том, влияет ли динамическая типизация на производительность Python. Вот некоторые соображения по этому поводу:
Причиной невысокой производительности Python является его динамическая природа и универсальность. Его можно использовать как инструмент для решения разнообразнейших задач. Для достижения тех же целей можно попытаться поискать более производительные, лучше оптимизированные инструменты. Возможно, найти их удастся, возможно — нет.
Приложения, написанные на Python, можно оптимизировать, используя возможности по асинхронному выполнению кода, инструменты профилирования, и — правильно подбирая интерпретатор. Так, для оптимизации скорости работы приложений, время запуска которых неважно, а производительность которых может выиграть от использования JIT-компилятора, рассмотрите возможность использования PyPy. Если вам нужна максимальная производительность и вы готовы к ограничениям статической типизации — взгляните на Cython.
Уважаемые читатели! Как вы решаете проблемы невысокой производительности Python?


Общие положения
Как Java, в плане производительности, соотносится с C или C++? Как сравнить C# и Python? Ответы на эти вопросы серьёзно зависят от типа анализируемых исследователем приложений. Не существует идеального бенчмарка, но, изучая производительность программ, написанных на разных языках, неплохой отправной точкой может стать проект The Computer Language Benchmarks Game.
Я ссылаюсь на The Computer Language Benchmarks Game уже больше десяти лет. Python, в сравнении с другими языками, такими, как Java, C#, Go, JavaScript, C++, является одним из самых медленных. Сюда входят языки, в которых используется JIT-компиляция (C#, Java), и AOT-компиляция (C, C++), а также интерпретируемые языки, такие, как JavaScript.
Тут мне хотелось бы отметить, что говоря «Python», я имею в виду эталонную реализацию интерпретатора Python — CPython. В этом материале мы коснёмся и других его реализаций. Собственно говоря, здесь мне хочется найти ответ на вопрос о том, почему Python требуется в 2-10 раз больше времени, чем другим языкам, на решение сопоставимых задач, и о том, можно ли сделать его быстрее.
Вот основные теории, пытающиеся объяснить причины медленной работы Python:
- Причина этого — в GIL (Global Interpreter Lock, глобальная блокировка интерпретатора).
- Причина в том, что Python — это интерпретируемый, а не компилируемый язык.
- Причина — в динамической типизации.
Проанализируем эти идеи и попытаемся найти ответ на вопрос о том, что сильнее всего оказывает влияние на производительность Python-приложений.
GIL
Современные компьютеры обладают многоядерными процессорами, иногда встречаются и многопроцессорные системы. Для того чтобы использовать всю эту вычислительную мощь, операционная система применяет низкоуровневые структуры, называемые потоками, в то время как процессы (например — процесс браузера Chrome) могут запускать множество потоков и соответствующим образом их использовать. В результате, например, если какой-то процесс особенно сильно нуждается в ресурсах процессора, его выполнение может быть разделено между несколькими ядрами, что позволяет большинству приложений быстрее решать встающие перед ними задачи.
Например, у моего браузера Chrome, в тот момент, когда я это пишу, имеется 44 открытых потока. Тут стоит учитывать то, что структура и API системы работы с потоками различается в операционных системах, основанных на Posix (Mac OS, Linux), и в ОС семейства Windows. Операционная система, кроме того, занимается планированием работы потоков.
Если раньше вы не встречались с многопоточным программированием, то сейчас вам нужно познакомиться с так называемыми блокировками (locks). Смысл блокировок заключается в том, что они позволяют обеспечить такое поведение системы, когда, в многопоточной среде, например, при изменении некоей переменной в памяти, доступ к одной и той же области памяти (для чтения или изменения) не могут одновременно получить несколько потоков.
Когда интерпретатор CPython создаёт переменные, он выделяет память, а затем подсчитывает количество существующих ссылок на эти переменные. Эта концепция известна как подсчёт ссылок (reference counting). Если число ссылок равняется нулю, тогда соответствующий участок памяти освобождается. Именно поэтому, например, создание «временных» переменных, скажем, в пределах областей видимости циклов, не приводит к чрезмерному увеличению объёма памяти, потребляемого приложением.
Самое интересное начинается тогда, когда одними и теми же переменными совместно пользуются несколько потоков, а главная проблема тут заключается в том, как именно CPython выполняет подсчёт ссылок. Тут и проявляется действие «глобальной блокировки интерпретатора», которая тщательно контролирует выполнение потоков.
Интерпретатор может выполнять лишь одну операцию за раз, независимо от того, как много потоков имеется в программе.
▍Как GIL влияет на производительность Python-приложений?
Если у нас имеется однопоточное приложение, работающее в одном процессе интерпретатора Python, то GIL никак на производительность не влияет. Если, например, избавиться от GIL, никакой разницы в производительности мы не заметим.
Если же, в пределах одного процесса интерпретатора Python, надо реализовать параллельную обработку данных с применением механизмов многопоточности, и используемые потоки будут интенсивно использовать подсистему ввода-вывода (например, если они будут работать с сетью или с диском), тогда можно будет наблюдать последствия того, как GIL управляет потоками. Вот как это выглядит в случае использования двух потоков, интенсивно нагружающих процессов.

Визуализация работы GIL (взято отсюда)
Если у вас имеется веб-приложение (например, основанное на фреймворке Django), и вы используете WSGI, то каждый запрос к веб-приложению будет обслуживаться отдельным процессом интерпретатора Python, то есть, у нас имеется лишь 1 блокировка на запрос. Так как интерпретатор Python запускается медленно, в некоторых реализациях WSGI имеется так называемый «режим демона», при использовании которого процессы интерпретатора поддерживаются в рабочем состоянии, что позволяет системе быстрее обслуживать запросы.
▍Как ведут себя другие интерпретаторы Python?
В PyPy есть GIL, он обычно более чем в 3 раза быстрее, чем CPython.
В Jython нет GIL, так как потоки Python в Jython представлены в виде потоков Java. Такие потоки используют возможности по управлению памятью JVM.
▍Как управление потоками организовано в JavaScript?
Если говорить о JavaScript, то, в первую очередь, надо отметить, что все JS-движки используют алгоритм сборки мусора mark-and-sweep. Как уже было сказано, основная причина необходимости использования GIL — это алгоритм управления памятью, применяемый в CPython.
В JavaScript нет GIL, однако, JS — это однопоточный язык, поэтому в нём подобный механизм и не нужен. Вместо параллельного выполнения кода в JavaScript применяются методики асинхронного программирования, основанные на цикле событий, промисах и коллбэках. В Python есть нечто подобное, представленное модулем
asyncio.Python — интерпретируемый язык
Мне часто приходилось слышать о том, что низкая производительность Python является следствием того, что это — интерпретируемый язык. Подобные утверждения основаны на грубом упрощении того, как, на самом деле, работает CPython. Если, в терминале, ввести команду вроде
python myscript.py, тогда CPython начнёт длительную последовательность действий, которая заключается в чтении, лексическом анализе, парсинге, компиляции, интерпретации и выполнении кода скрипта. Если вас интересуют подробности — взгляните на этот материал.Для нас, при рассмотрении этого процесса, особенно важным является тот факт, что здесь, на стадии компиляции, создаётся
.pyc-файл, и последовательность байт-кодов пишется в файл в директории __pycache__/, которая используется и в Python 3, и в Python 2.Подобное применяется не только к написанным нами скриптам, но и к импортированному коду, включая сторонние модули.
В результате, большую часть времени (если только вы не пишете код, который запускается лишь один раз) Python занимается выполнением готового байт-кода. Если сравнить это с тем, что происходит в Java и в C#, окажется, что код на Java компилируется в «Intermediate Language», и виртуальная машина Java читает байт-код и выполняет его JIT-компиляцию в машинный код. «Промежуточный язык» .NET CIL (это то же самое, что .NET Common-Language-Runtime, CLR), использует JIT-компиляцию для перехода к машинному коду.
В результате, и в Java и в C# используется некий «промежуточный язык» и присутствуют похожие механизмы. Почему же тогда Python показывает в бенчмарках гораздо худшие результаты, чем Java и C#, если все эти языки используют виртуальные машины и какие-то разновидности байт-кода? В первую очередь — из-за того, что в .NET и в Java используется JIT-компиляция.
JIT-компиляция (Just In Time compilation, компиляция «на лету» или «точно в срок») требует наличия промежуточного языка для того, чтобы позволить осуществлять разбиение кода на фрагменты (кадры). Системы AOT-компиляции (Ahead Of Time compilation, компиляция перед исполнением) спроектированы так, чтобы обеспечить полную работоспособность кода до того, как начнётся взаимодействие этого кода с системой.
Само по себе использование JIT не ускоряет выполнение кода, так как на выполнение поступают, как и в Python, некие фрагменты байт-кода. Однако JIT позволяет выполнять оптимизации кода в процессе его выполнения. Хороший JIT-оптимизатор способен выявить наиболее нагруженные части приложения (такую часть приложения называют «hot spot») и оптимизировать соответствующие фрагменты кода, заменив их оптимизированными и более производительными вариантами, чем те, что использовались ранее.
Это означает, что когда некое приложение снова и снова выполняет некие действия, подобная оптимизация способна значительно ускорить выполнение таких действий. Кроме того, не забывайте о том, что Java и C# — это языки со строгой типизацией, поэтому оптимизатор может делать о коде больше предположений, способствующих улучшению производительности программ.
JIT-компилятор есть в PyPy, и, как уже было сказано, эта реализация интерпретатора Python гораздо быстрее, чем CPython. Сведения, касающиеся сравнения разных интерпретаторов Python, можно найти в этом материале.
▍Почему в CPython не используется JIT-компилятор?
У JIT-компиляторов есть и недостатки. Один из них — время запуска. CPython и так запускается сравнительно медленно, а PyPy в 2-3 раза медленнее, чем CPython. Длительное время запуска JVM — это тоже известный факт. CLR .NET обходит эту проблему, запускаясь в ходе загрузки системы, но тут надо отметить, что и CLR, и та операционная система, в которой запускается CLR, разрабатываются одной и той же компанией.
Если у вас имеется один процесс Python, который работает длительное время, при этом в таком процессе имеется код, который может быть оптимизирован, так как он содержит интенсивно используемые участки, тогда вам стоит серьёзно взглянуть на интерпретатор, имеющий JIT-компилятор.
Однако, CPython — это реализация интерпретатора Python общего назначения. Поэтому, если вы разрабатываете, с использованием Python, приложения командной строки, то необходимость длительного ожидания запуска JIT-компилятора при каждом запуске этого приложения сильно замедлит работу.
CPython пытается обеспечить поддержку как можно большего количества вариантов использования Python. Например, существует возможности подключения JIT-компилятора к Python, правда, проект, в рамках которого реализуется эта идея, развивается не особенно активно.
В результате можно сказать, что если вы, с помощью Python, пишете программу, производительность которой может улучшиться при использовании JIT-компилятора — используйте интерпретатор PyPy.
Python — динамически типизированный язык
В статически типизированных языках, при объявлении переменных, необходимо указывать их типы. Среди таких языков можно отметить C, C++, Java, C#, Go.
В динамически типизированных языках понятие типа данных имеет тот же смысл, но тип переменной является динамическим.
a = 1
a = "foo"В этом простейшем примере Python сначала создаёт первую переменную
a, потом — вторую с тем же именем, имеющую тип str, и освобождает память, которая была выделена первой переменной a.Может показаться, что писать на языках с динамической типизацией удобнее и проще, чем на языках со статической типизацией, однако, такие языки созданы не по чьей-то прихоти. При их разработке учтены особенности работы компьютерных систем. Всё, что написано в тексте программы, в итоге, сводится к инструкциям процессора. Это означает, что данные, используемые программой, например, в виде объектов или других типов данных, тоже преобразуются к низкоуровневым структурам.
Python выполняет подобные преобразования автоматически, программист этих процессов не видит, и заботиться о подобных преобразованиях ему не нужно.
Отсутствие необходимости указывать тип переменной при её объявлении — это не та особенность языка, которая делает Python медленным. Архитектура языка позволяет сделать динамическим практически всё, что угодно. Например, во время выполнения программы можно заменять методы объектов. Опять же, во время выполнения программы можно использовать технику «обезьяньих патчей» в применении к низкоуровневым системным вызовам. В Python возможно практически всё.
Именно архитектура Python чрезвычайно усложняет оптимизацию.
Для того чтобы проиллюстрировать эту идею, я собираюсь воспользоваться инструментом для трассировки системных вызовов в MacOS, который называется DTrace.
В готовом дистрибутиве CPython нет механизмов поддержки DTrace, поэтому CPython нужно будет перекомпилировать с соответствующими настройками. Тут используется версия 3.6.6. Итак, воспользуемся следующей последовательностью действий:
wget https://github.com/python/cpython/archive/v3.6.6.zip
unzip v3.6.6.zip
cd v3.6.6
./configure --with-dtrace
makeТеперь, пользуясь
python.exe, можно применять DTRace для трассировки кода. Об использовании DTrace с Python можно почитать здесь. А вот тут можно найти скрипты для измерения с помощью DTrace различных показателей работы Python-программ. Среди них — параметры вызова функций, время выполнения программ, время использования процессора, сведения о системных вызовах и так далее. Вот как пользоваться командой dtrace:sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe script.py’А вот как средство трассировки
py_callflow показывает вызовы функций в приложении.Трассировка с использованием DTrace
Теперь ответим на вопрос о том, влияет ли динамическая типизация на производительность Python. Вот некоторые соображения по этому поводу:
- Проверка и конверсия типов — операции тяжёлые. Каждый раз, когда выполняется обращение к переменной, её чтение или запись, производится проверка типа.
- Язык, обладающей подобной гибкостью, сложно оптимизировать. Причина, по которой другие языки настолько быстрее Python, заключается в том, что они идут на те или иные компромиссы, выбирая между гибкостью и производительностью.
- Проект Cython объединяет Python и статическую типизацию, что, например, как показано в этом материале, приводит к 84-кратному росту производительности в сравнении с применением обычного Python. Обратите внимание на этот проект, если вам нужна скорость.
Итоги
Причиной невысокой производительности Python является его динамическая природа и универсальность. Его можно использовать как инструмент для решения разнообразнейших задач. Для достижения тех же целей можно попытаться поискать более производительные, лучше оптимизированные инструменты. Возможно, найти их удастся, возможно — нет.
Приложения, написанные на Python, можно оптимизировать, используя возможности по асинхронному выполнению кода, инструменты профилирования, и — правильно подбирая интерпретатор. Так, для оптимизации скорости работы приложений, время запуска которых неважно, а производительность которых может выиграть от использования JIT-компилятора, рассмотрите возможность использования PyPy. Если вам нужна максимальная производительность и вы готовы к ограничениям статической типизации — взгляните на Cython.
Уважаемые читатели! Как вы решаете проблемы невысокой производительности Python?

