Когда мы выбирали инструмент для обработки больших данных, то рассматривали разные варианты — как проприетарные, так и с открытым кодом. Оценивали возможности быстрой адаптации, доступности и гибкости технологий. В том числе, миграцию между версиями. В итоге выбрали решение с открытым исходным кодом Greenplum, которое лучше всех соответствовало нашим требованиям, но требовало решения одного важного вопроса.

Дело в том, что файлы баз данных Greenplum версий 4 и 5 не совместимы между собой, и поэтому простой апгрейд от одной версии к другой невозможен. Миграцию данных можно провести только через выгрузку и загрузку данных. В этом посте я расскажу о возможных вариантах этой миграции.
Это слишком медленный вариант, когда речь идет о десятках терабайт, так как все данные выгружаются и загружаются через мастер-ноды. Но достаточно быстрый для переноса DDL и маленьких таблиц. Можно выгружать как в файл, так и запускать одновременно pg_dump и psql через конвейер (pipe) как на кластере-источнике, так и на кластере-приемнике. pg_dump просто выгружает в один файл, содержащий и DDL-команды, и команды COPY с данными. Полученные данные можно удобно обработать, что будет показано ниже.

Требует версию Greenplum 4.2 или новее. Необходимо чтобы одновременно работали и кластер-источник и кластер-приемник. Самый быстрый способ для переноса таблиц с большим объемом данных для версии с открытым кодом. Но этот способ очень медленный для переноса пустых и маленьких таблиц из-за больших накладных затрат.
gptransfer использует pg_dump для переноса DDL и gpfdist для переноса данных. Количество primary сегментов на кластере-приемнике должно быть не меньше, чем сегмент-хостов на кластере-источнике. Это важно учитывать при создании кластеров-«песочниц», если в них будут передаваться данные с основных кластеров, и планируется использование утилиты gptransfer. Даже если сегмент-хостов мало, на каждом из них можно развернуть необходимое количество сегментов. Количество сегментов на кластере-приемнике может быть меньше, чем на кластере-источнике, однако это негативно скажется на скорости переноса данных. Между кластерами должна быть настроена авторизация ssh по сертификатам.

Это схема для режима fast, когда количество сегментов на кластере-приемнике больше или равно количеству на кластере-источнике. Запуск самой утилиты показан на схеме на мастер-ноде кластера-приемника. В данном режиме на кластере-источнике создается внешняя таблица на запись, которая пишет данные на каждом сегменте в named pipe. Выполняется команда INSERT INTO writable_external_table SELECT * FROM source_table. Данные из named pipe читаются gpfdist. На кластере-приемнике создается также внешняя таблица, только уже на чтение. Таблица указывает на данные, которые предоставляют gpfdist по одноименному протоколу. Выполняется команда INSERT INTO target_table SELECT * FROM external_gpfdist_table. Данные автоматически перераспределяются между сегментами кластера-приемника.
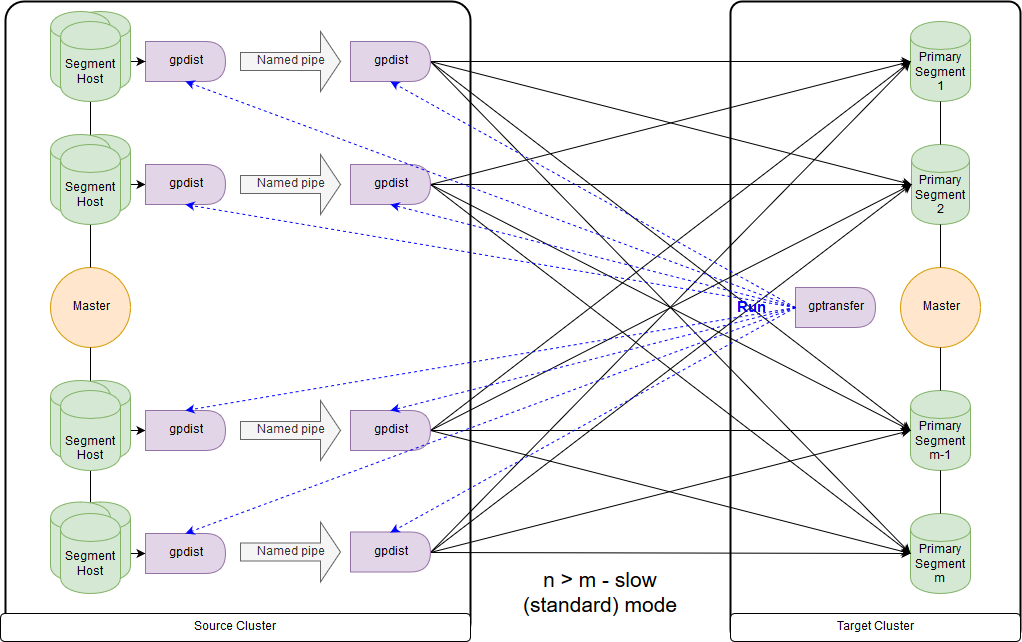
А это схема для режима slow, или, как выдает сам gptransfer, standard mode. Основным отличием является то, что на каждом сегмент-хосте кластера-источника запускается пара gpfdist для всех сегментов этого сегмент-хоста. Внешняя таблица на запись ссылается на gpfdist, выступающие в качестве приемника данных. При этом если в параметре LOCATION внешней таблице на запись указано несколько значений, то сегменты распределятся равномерно по gpfdist при записи данных. Данные между gpfdist на сегмент-хосте передаются через named pipe. Из-за этого скорость передачи данных меньше, но все равно получается быстрее чем при передаче данных только через мастер-ноду.
При миграции данных с Greenplum 4 на Greenplum 5 запускать gptransfer нужно именно на мастер-ноде кластера-приемника. Если запустить gptransfer на кластере-источнике, то получим ошибку отсутствия поля
Также нужно проверить переменные GPHOME, чтобы они совпадали у кластера-источника и кластера-приемника. Иначе получим достаточно странную ошибку (gptransfer utility fails when source and target have different GPHOME path).
Можно просто создать соответствующий симлинк и переопределить переменную GPHOME в сеансе, в котором запускается gptransfer.
При запуске gptransfer на кластере-приемнике опция «--source-map-file» должна указывать на файл, содержащий список хостов и их ip-адресов с primary-сегментами кластера-источника. Например:
С опцией «--full» можно перенести не только таблицы, а базы данных целиком, однако на кластере-приемнике не должны быть созданы пользовательские базы данных. Также следует помнить, что есть проблемы из-за изменения синтаксиса при переносе внешних таблиц.
Давайте оценим дополнительные накладные расходы, например, путем копирования 10 пустых таблиц (таблицы с big_db.public.test_table_2 по big_db.public.test_table_11) с помощью gptarnsfer:
В итоге перенос 10 пустых таблиц занял порядка 16 секунд (14:40-15:02), то есть одна таблица — 1,6 сек. За это время, в нашем случае, можно загрузить с помощью pg_dump & psql порядка 100 Мбайт данных.
Как вариант: использовать надстройки над ними, gpcrondump & gpdbrestore, так как gp_dump & gp_restore объявлены deprecated. Хотя сами gpcrondump & gpdbrestore в процессе своей работы используют gp_dump & gp_restore. Это наиболее универсальный способ, но не самый быстрый. Файлы резервных копий, созданные с помощью gp_dump, представляют собой на мастер-ноде набор DDL-команд, а на primary сегментах, в основном, наборы команд COPY и данных. Подходит для случаев, когда невозможно обеспечить одновременную работу кластера-приемника и кластера-источника. Есть и в старых версиях Greenplum, и в новых: gp_dump, gp_restore.

Созданы как замена gp_dump & gp_restore. Для их работы необходима версия Greenplum минимум 4.3.17 (const MINIMUM_GPDB4_VERSION = «4.3.17»). Схема работы аналогична gpbackup & gprestore, при этом скорость работы намного быстрее. Самый быстрый способ получения DDL-команд для больших баз. По умолчанию переносит глобальные объекты, для восстановления нужно указывать «gprestore --with-globals». Опциональный параметр «--jobs» может задавать количество заданий (и сеансов в базу данных) при создании резервной копии. Из-за того, что создаются несколько сеансов, важно обеспечить консистентность данных до момента получения всех блокировок. Еще есть полезная опция «--with-stats», позволяющая переносить статистику по объектам, используемую для построения планов исполнения. Более подробная информация здесь.
Для копирования баз есть утилита gpcopy — замена gptansfer. Но она входит лишь в проприетарную версию Greenplum от Pivotal, начиная с 4.3.26 — в версии с открытым кодом данной утилиты нет. В процессе работы на кластере-источнике выполняется команда COPY source_table TO PROGRAM ‘gpcopy_helper …’ ON SEGMENT CSV IGNORE EXTERNAL PARTITIONS. На стороне кластера-приемника создается временная внешняя таблица CREATE EXTERNAL WEB TEMP TABLE external_temp_table (LIKE target_table) EXECUTE '… gpcopy_helper –listen …' и выполняется команда INSERT INTO target_table SELECT * FROM external_temp_table. В результате на каждом сегменте кластера-приемника запускаются gpcopy_helper с параметром –listen, которые получают данные от gpcopy_helper’ов с сегментов кластера-источника. За счет такой схемы передачи данных, а также компрессии скорость передачи получается значительно выше. Между кластерами также должна быть настроена авторизация ssh по сертификатам. Также хочу отметить, что у gpcopy есть удобная опция «--truncate-source-after» (и «--validate») для случаев, когда кластер-источник и кластер-приемник расположены на одних и тех же серверах.
Для определения стратегии переноса нужно определить, что нам важнее: перенести данные быстро, но с большими трудозатратами и, возможно, менее надежно (gpbackup, gptransfer или их комбинация) или с меньшими трудозатратами, но медленнее (gpbackup или gptransfer без комбинирования).
Самый быстрый способ переноса данных — когда есть кластер-источник и кластер-приемник — следующий:
Данный способ оказался в наших замерах быстрее минимум в 2 раза, чем gp_dump & gp_restore. Альтернативные способы: перенос всех баз с помощью gptransfer –full, gpbackup & gprestore, или gp_dump & gp_restore.
Размеры таблиц можно получить следующим запросом:
Файлы резервных копий, в Greenplum версий 4 и 5 также совместимы не полностью. Так, в Greenplum 5 из-за изменения синтаксиса в командах CREATE EXTERNAL TABLE и COPY отсутствует параметр INTO ERROR TABLE, и нужно выставить параметр SET gp_ignore_error_table в true, чтобы восстановление резервной копии не завершалось по ошибке. При установленном параметре мы просто получим предупреждение.
Кроме того, в пятой версии появился другой протокол взаимодействия с внешними таблицами pxf, и для его использования нужно изменить параметр LOCATION, а также настроить службу pxf.
Также стоит обратить внимание, что в файлах резервной копии gp_dump & gp_restore и на мастер-ноде, и на каждом primary сегменте параметр SET gp_strict_xml_parse установлен в false. В Greenplum 5 такого параметра нет, и, как результат, мы получаем сообщение об ошибке.
Если для внешних таблиц использовался протокол gphdfs, нужно проверить в файлах резервных копий список источников в параметре LOCATION для внешних таблиц по строке 'gphdfs://'. Например, должно быть только 'gphdfs://hadoop.local:8020'. Если есть другие строки, их нужно добавить в скрипт замены на мастер-ноде по аналогии.
Производим замены на мастер-ноде (на примере файла данных gp_dump):
В последних версиях имя профиля HdfsTextSimple объявлено deprecated, новое имя — hdfs:text.
За рамками статьи остались необходимость явного преобразования в текст (Implicit Text Casting), новый механизм управления ресурсами кластера Resource Groups, пришедший на смену Resource Queues, оптимизатор GPORCA, который включен по умолчанию в Greenplum 5, мелкие проблемы с клиентами.
Я с интересом жду выхода шестой версии Greenplum, который запланирован на весну 2019 года: уровень совместимости с PostgreSQL 9.4, Full Text Search, GIN Index Support, Range Types, JSONB, zStd Compression. Также стали известны предварительные планы на Greenplum 7: уровень совместимости с PostgreSQL минимум 9.6, Row Level Security, Automated Master Failover. Также разработчики обещают наличие утилит апгрейда баз данных для обновления между мажорными версиями, так что жить будет проще.
Статья подготовлена командой управления данными «Ростелекома»

Дело в том, что файлы баз данных Greenplum версий 4 и 5 не совместимы между собой, и поэтому простой апгрейд от одной версии к другой невозможен. Миграцию данных можно провести только через выгрузку и загрузку данных. В этом посте я расскажу о возможных вариантах этой миграции.
Оцениваем варианты миграции
pg_dump & psql (или pg_restore)
Это слишком медленный вариант, когда речь идет о десятках терабайт, так как все данные выгружаются и загружаются через мастер-ноды. Но достаточно быстрый для переноса DDL и маленьких таблиц. Можно выгружать как в файл, так и запускать одновременно pg_dump и psql через конвейер (pipe) как на кластере-источнике, так и на кластере-приемнике. pg_dump просто выгружает в один файл, содержащий и DDL-команды, и команды COPY с данными. Полученные данные можно удобно обработать, что будет показано ниже.

gptransfer
Требует версию Greenplum 4.2 или новее. Необходимо чтобы одновременно работали и кластер-источник и кластер-приемник. Самый быстрый способ для переноса таблиц с большим объемом данных для версии с открытым кодом. Но этот способ очень медленный для переноса пустых и маленьких таблиц из-за больших накладных затрат.
gptransfer использует pg_dump для переноса DDL и gpfdist для переноса данных. Количество primary сегментов на кластере-приемнике должно быть не меньше, чем сегмент-хостов на кластере-источнике. Это важно учитывать при создании кластеров-«песочниц», если в них будут передаваться данные с основных кластеров, и планируется использование утилиты gptransfer. Даже если сегмент-хостов мало, на каждом из них можно развернуть необходимое количество сегментов. Количество сегментов на кластере-приемнике может быть меньше, чем на кластере-источнике, однако это негативно скажется на скорости переноса данных. Между кластерами должна быть настроена авторизация ssh по сертификатам.

Это схема для режима fast, когда количество сегментов на кластере-приемнике больше или равно количеству на кластере-источнике. Запуск самой утилиты показан на схеме на мастер-ноде кластера-приемника. В данном режиме на кластере-источнике создается внешняя таблица на запись, которая пишет данные на каждом сегменте в named pipe. Выполняется команда INSERT INTO writable_external_table SELECT * FROM source_table. Данные из named pipe читаются gpfdist. На кластере-приемнике создается также внешняя таблица, только уже на чтение. Таблица указывает на данные, которые предоставляют gpfdist по одноименному протоколу. Выполняется команда INSERT INTO target_table SELECT * FROM external_gpfdist_table. Данные автоматически перераспределяются между сегментами кластера-приемника.

А это схема для режима slow, или, как выдает сам gptransfer, standard mode. Основным отличием является то, что на каждом сегмент-хосте кластера-источника запускается пара gpfdist для всех сегментов этого сегмент-хоста. Внешняя таблица на запись ссылается на gpfdist, выступающие в качестве приемника данных. При этом если в параметре LOCATION внешней таблице на запись указано несколько значений, то сегменты распределятся равномерно по gpfdist при записи данных. Данные между gpfdist на сегмент-хосте передаются через named pipe. Из-за этого скорость передачи данных меньше, но все равно получается быстрее чем при передаче данных только через мастер-ноду.
При миграции данных с Greenplum 4 на Greenplum 5 запускать gptransfer нужно именно на мастер-ноде кластера-приемника. Если запустить gptransfer на кластере-источнике, то получим ошибку отсутствия поля
san_mounts в таблице pg_catalog.gp_segment_configuration:gptransfer -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate
20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate
20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Validating options...
20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database...
20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database...
20190109:12:46:14:010893 gptransfer:gpdb-source-master.local:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist
LINE 2: ... SELECT dbid, content, status, unnest(san_mounts...
^
' in '
SELECT dbid, content, status, unnest(san_mounts)
FROM pg_catalog.gp_segment_configuration
WHERE content >= 0
ORDER BY content, dbid
'') exiting...Также нужно проверить переменные GPHOME, чтобы они совпадали у кластера-источника и кластера-приемника. Иначе получим достаточно странную ошибку (gptransfer utility fails when source and target have different GPHOME path).
gptransfer -t big_db.public.test_table --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate
20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --source-host=gpdb-spurce-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate
20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Validating options...
20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[ERROR]:-gptransfer: error: GPHOME directory does not exist on gpdb-source-master.localМожно просто создать соответствующий симлинк и переопределить переменную GPHOME в сеансе, в котором запускается gptransfer.
При запуске gptransfer на кластере-приемнике опция «--source-map-file» должна указывать на файл, содержащий список хостов и их ip-адресов с primary-сегментами кластера-источника. Например:
sdw1,192.0.2.1
sdw2,192.0.2.2
sdw3,192.0.2.3
sdw4,192.0.2.4С опцией «--full» можно перенести не только таблицы, а базы данных целиком, однако на кластере-приемнике не должны быть созданы пользовательские базы данных. Также следует помнить, что есть проблемы из-за изменения синтаксиса при переносе внешних таблиц.
Давайте оценим дополнительные накладные расходы, например, путем копирования 10 пустых таблиц (таблицы с big_db.public.test_table_2 по big_db.public.test_table_11) с помощью gptarnsfer:
gptransfer -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-ba tch-size=50 --truncate
20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-batch-size=50 --truncate
20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating options...
20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database...
20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database...
20190118:06:14:09:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving source tables...
20190118:06:14:12:031521 gptransfer:mdw:gpadmin-[INFO]:-Checking for gptransfer schemas...
20190118:06:14:22:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving list of destination tables...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Reading source host map file...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Building list of source tables to transfer...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Number of tables to transfer: 10
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-gptransfer will use "standard" mode for transfer.
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating source host map...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating transfer table set...
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-The following tables on the destination system will be truncated:
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_2
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_3
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_4
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_5
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_6
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_7
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_8
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_9
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_10
20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_11
…
20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using batch size of 10
20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using sub-batch size of 16
20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_31521'
20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating schema public in database edw_prod...
20190118:06:14:40:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting transfer of big_db.public.test_table_5 to big_db.public.test_table_5...
…
20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Validation of big_db.public.test_table_4 successful
20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Removing work directories...
20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Finished.В итоге перенос 10 пустых таблиц занял порядка 16 секунд (14:40-15:02), то есть одна таблица — 1,6 сек. За это время, в нашем случае, можно загрузить с помощью pg_dump & psql порядка 100 Мбайт данных.
gp_dump & gp_restore
Как вариант: использовать надстройки над ними, gpcrondump & gpdbrestore, так как gp_dump & gp_restore объявлены deprecated. Хотя сами gpcrondump & gpdbrestore в процессе своей работы используют gp_dump & gp_restore. Это наиболее универсальный способ, но не самый быстрый. Файлы резервных копий, созданные с помощью gp_dump, представляют собой на мастер-ноде набор DDL-команд, а на primary сегментах, в основном, наборы команд COPY и данных. Подходит для случаев, когда невозможно обеспечить одновременную работу кластера-приемника и кластера-источника. Есть и в старых версиях Greenplum, и в новых: gp_dump, gp_restore.

Утилиты gpbackup & gprestore
Созданы как замена gp_dump & gp_restore. Для их работы необходима версия Greenplum минимум 4.3.17 (const MINIMUM_GPDB4_VERSION = «4.3.17»). Схема работы аналогична gpbackup & gprestore, при этом скорость работы намного быстрее. Самый быстрый способ получения DDL-команд для больших баз. По умолчанию переносит глобальные объекты, для восстановления нужно указывать «gprestore --with-globals». Опциональный параметр «--jobs» может задавать количество заданий (и сеансов в базу данных) при создании резервной копии. Из-за того, что создаются несколько сеансов, важно обеспечить консистентность данных до момента получения всех блокировок. Еще есть полезная опция «--with-stats», позволяющая переносить статистику по объектам, используемую для построения планов исполнения. Более подробная информация здесь.
Утилита gpcopy
Для копирования баз есть утилита gpcopy — замена gptansfer. Но она входит лишь в проприетарную версию Greenplum от Pivotal, начиная с 4.3.26 — в версии с открытым кодом данной утилиты нет. В процессе работы на кластере-источнике выполняется команда COPY source_table TO PROGRAM ‘gpcopy_helper …’ ON SEGMENT CSV IGNORE EXTERNAL PARTITIONS. На стороне кластера-приемника создается временная внешняя таблица CREATE EXTERNAL WEB TEMP TABLE external_temp_table (LIKE target_table) EXECUTE '… gpcopy_helper –listen …' и выполняется команда INSERT INTO target_table SELECT * FROM external_temp_table. В результате на каждом сегменте кластера-приемника запускаются gpcopy_helper с параметром –listen, которые получают данные от gpcopy_helper’ов с сегментов кластера-источника. За счет такой схемы передачи данных, а также компрессии скорость передачи получается значительно выше. Между кластерами также должна быть настроена авторизация ssh по сертификатам. Также хочу отметить, что у gpcopy есть удобная опция «--truncate-source-after» (и «--validate») для случаев, когда кластер-источник и кластер-приемник расположены на одних и тех же серверах.
Стратегия переноса данных
Для определения стратегии переноса нужно определить, что нам важнее: перенести данные быстро, но с большими трудозатратами и, возможно, менее надежно (gpbackup, gptransfer или их комбинация) или с меньшими трудозатратами, но медленнее (gpbackup или gptransfer без комбинирования).
Самый быстрый способ переноса данных — когда есть кластер-источник и кластер-приемник — следующий:
- Получаем DDL с помощью gpbackup --metadata-only, преобразованием и загружаем через конвейер с помощью psql
- Удаляем индексы
- Переносим таблицы, у которых размер 100 Мбайт и более, с помощью gptransfer
- Переносим таблицы, у которых размер менее 100 Мбайт, с помощью pg_dump | psql, как в первом пункте
- Создаем обратно ранее удаленные индексы
Данный способ оказался в наших замерах быстрее минимум в 2 раза, чем gp_dump & gp_restore. Альтернативные способы: перенос всех баз с помощью gptransfer –full, gpbackup & gprestore, или gp_dump & gp_restore.
Размеры таблиц можно получить следующим запросом:
SELECT
nspname AS "schema",
coalesce(tablename, relname) AS "name",
SUM(pg_total_relation_size(class.oid)) AS "size"
FROM pg_class class
JOIN pg_namespace namespace ON namespace.oid = class.relnamespace
LEFT JOIN pg_partitions parts ON class.relname = parts.partitiontablename
AND namespace.nspname = parts.schemaname
WHERE nspname NOT IN ('pg_catalog', 'information_schema', 'pg_toast', 'pg_bitmapindex', 'pg_aoseg', 'gp_toolkit')
GROUP BY nspname, relkind, coalesce(tablename, relname), pg_get_userbyid(class.relowner)
ORDER BY 1,2;
Необходимые преобразования
Файлы резервных копий, в Greenplum версий 4 и 5 также совместимы не полностью. Так, в Greenplum 5 из-за изменения синтаксиса в командах CREATE EXTERNAL TABLE и COPY отсутствует параметр INTO ERROR TABLE, и нужно выставить параметр SET gp_ignore_error_table в true, чтобы восстановление резервной копии не завершалось по ошибке. При установленном параметре мы просто получим предупреждение.
Кроме того, в пятой версии появился другой протокол взаимодействия с внешними таблицами pxf, и для его использования нужно изменить параметр LOCATION, а также настроить службу pxf.
Также стоит обратить внимание, что в файлах резервной копии gp_dump & gp_restore и на мастер-ноде, и на каждом primary сегменте параметр SET gp_strict_xml_parse установлен в false. В Greenplum 5 такого параметра нет, и, как результат, мы получаем сообщение об ошибке.
Если для внешних таблиц использовался протокол gphdfs, нужно проверить в файлах резервных копий список источников в параметре LOCATION для внешних таблиц по строке 'gphdfs://'. Например, должно быть только 'gphdfs://hadoop.local:8020'. Если есть другие строки, их нужно добавить в скрипт замены на мастер-ноде по аналогии.
grep -o gphdfs\:\/\/.*\/ /data1/master/gpseg-1/db_dumps/20181206/gp_dump_-1_1_20181206122002.gz | cut -d/ -f1-3 | sort | uniq
gphdfs://hadoop.local:8020Производим замены на мастер-ноде (на примере файла данных gp_dump):
mv /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz
gunzip -c /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz | sed "s#'gphdfs://hadoop.local:8020#'pxf:/#g" | sed "s/\(^.*pxf\:\/\/.*'\)/\1\\&\&\?PROFILE=HdfsTextSimple'/" |sed "s#'&#g" | sed 's/SET gp_strict_xml_parse = false;/SET gp_ignore_error_table = true;/g' | gzip -1 > /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz
netsВ последних версиях имя профиля HdfsTextSimple объявлено deprecated, новое имя — hdfs:text.
Итоги
За рамками статьи остались необходимость явного преобразования в текст (Implicit Text Casting), новый механизм управления ресурсами кластера Resource Groups, пришедший на смену Resource Queues, оптимизатор GPORCA, который включен по умолчанию в Greenplum 5, мелкие проблемы с клиентами.
Я с интересом жду выхода шестой версии Greenplum, который запланирован на весну 2019 года: уровень совместимости с PostgreSQL 9.4, Full Text Search, GIN Index Support, Range Types, JSONB, zStd Compression. Также стали известны предварительные планы на Greenplum 7: уровень совместимости с PostgreSQL минимум 9.6, Row Level Security, Automated Master Failover. Также разработчики обещают наличие утилит апгрейда баз данных для обновления между мажорными версиями, так что жить будет проще.
Статья подготовлена командой управления данными «Ростелекома»
