Всем привет!
Мы с командой представляем направление развития бизнеса с партнерами Росбанка. Сегодня хотим рассказать об успешном опыте автоматизации банковского бизнес-процесса с использованием прямых интеграций между системами, искусственного интеллекта в части распознавания образов и текста на базе GreenOCR, РФ-законодательстве и подготовке сэмплов для обучения.

Итак, начнем. В Росбанке существует бизнес-процесс открытия счета для заемщика в лице банка партнера. Существующий процесс, следуя всем регуляторным требованиям и требованиям группы Societe Generale, до автоматизации занимал до 20 минут операционного времени на каждого клиента. Процесс включает в себя получение сканов документов back-офисом, проверку корректности заполнения каждого документа и разнесения полей документа по информационным системам банка, ряд других проверок и только в самом конце — открытие счета. Это именно тот процесс, который стоит за кнопкой «Открыть счет».
Основные поля документа — фамилия, имя, отчество, дата рождения клиента и др. — содержатся практически во всех типах получаемых документов и дублируются при вводе в разные системы Банка. Наиболее сложный документ – вопросник KYC (от Know Your Customer — знай своего клиента) – представляет собой печатную форму формата А4, заполняемую шрифтом 8 кегля и содержащую порядка 170 текстовых полей и чек-боксов, а также табличные представления.
Основная цель, стоявшая перед нами, — сократить до минимума время открытия счета.
Анализ процесса показал, что необходимо:
Для решения задач (1) и (2) было решено воспользоваться уже внедренным в банке решением по распознаванию образов и текста на базе GreenOCR (рабочее название – «распознавалка»). Форматы используемых в бизнес-процессе документов не являются стандартными, поэтому перед командой стояла задача разработать требования к «распознавалке» и подготовить примеры для обучения нейронной сети (сэмплы).
Для решения задач (2) и (3) была необходима доработка систем и межсистемных интеграция.
Комплект клиентских документов, используемых в бизнес-процессе, включал в себя:
Для начала были досконально изучены документы и разработаны требования, включавшие в себя не только работу распознавалки с динамичными полями, но также и работу со статичным текстом, полями с рукописными данными, в целом распознавание документа по периметру и прочие доработки.
Распознавание паспорта входило в коробочный функционал системы GreenOCR и доработок не потребовало.
Для остальных типов документов в результате проведенного анализа были определены необходимые атрибуты и признаки, которые должна возвращать «распознавалка». При этом пришлось учитывать следующие моменты, затруднявшие процесс распознавания и потребовавшие заметного усложнения используемых алгоритмов:
Изначально задача показалась нам не слишком сложной и выглядела довольно стандартно:
Требования –> Вендор –> Модель –> Тестирование модели -> Запуск процесса
В случае не успешных тестов модель возвращается вендору на повторное обучение.
Ежедневно мы получаем огромное количество сканов документов, и подготовить выборку для обучения модели не должно было стать проблемой. Вся обработка персональных данных должна соответствовать требованиям Федерального закона «О персональных данных» N152-ФЗ. Согласия клиентов на обработку персональных данных клиентов есть только внутри Росбанка. Передать вендору, для обучения модели, документы клиентов мы не можем.
Рассматривалось три пути решения проблемы:
Проанализировав с командой предложенные варианты, на предмет скорости их реализации и возможных рисков, мы выбрали третий вариант — путь имитационного моделирования документов для обучения модели. Основное преимущество этого процесса – возможность охватить максимально широкий спектр устройств сканирования для сокращения количества итераций по калибровке и доработке модели.
Шаблоны документов были реализованы в html-формате. Быстро и оперативно был подготовлен массив тестовых данных и макрос, заполняющий шаблоны синтезированными данными и автоматизирующий печать. Далее мы сгенерировали печатные формы в pdf-формате и каждому файлу присвоили уникальный идентификатор для сверки ответов, получаемых с «разпознавалки».
Обучение нейронной сети, разметка областей и настройка форм проходили на стороне вендора.

По причине ограниченных сроков, обучение модели разбили на 2 этапа.
На первом этапе было проведено обучение модели распознаванию типов документов и «грубому» распознаванию содержимого самих документов:
Требования –> Вендор –> Подготовка тестовых данных-> Сбор данных-> Обучение модели по распознаванию форм– > Тестирование форм -> Настройка модели
На втором этапе происходило детальное обучение модели распознаванию содержимого каждого типа документов. Обучение и внедрение модели на втором этапе можно описать следующей схемой, одинаковой для всех типов документов:
Подготовка тестовых данных в разных разрешениях -> Сбор и передача данных вендору -> Обучение модели -> Тестирование модели -> Калибровка модели -> Внедрение модели –> Проверка результатов в бою -> Выявление проблемных кейсов -> Имитация проблемных кейсов и передача вендору -> Повторение шагов с тестирования
Следует отметить, что, несмотря на весьма широкий охват спектра использованных устройств сканирования, ряд устройств все же не был представлен в примерах для обучения модели. Поэтому ввод модели в бой проходил в пилотном режиме, и результаты не использовались для автоматизации. Данные, полученные при работе в пилотном режиме, только записывались в базу данных для последующего анализа и разбора.
Так как контур обучения модели находился на стороне вендора и не был связан с системами банка, после каждого цикла обучения модель передавалась вендором в банк, где проводилась её проверка на тестовой среде. В случае успешной проверки модель переносилась на сертификационную среду, где проводилось ее регрессионное тестирование, и далее — на промышленную среду, для выявления особых кейсов, не учтенных при обучении модели.
В периметре банка на модель подавались данные, результаты записывались в базу данных. Анализ качества данных проводился с помощью всемогущего Excel — с использованием сводных таблиц, логики с формулами и их комбинаций vlookup, hlookup, index, len, match и посимвольного сравнения строк через функцию if.
Тестирование с использованием имитированных документов позволило выполнить максимальное количество тестовых сценариев и максимально автоматизировать процесс.
Вначале в ручном режиме была выполнена проверка возврата всех полей на соответствие исходным требованиям по каждому типу документа. Далее проверялись ответы модели при динамическом заполнении текстовых блоков разной длины. Целью было проверить качество ответов при переходе текста со строки на строку и со страницы на страницу. В конце проверяли качество ответов по полям в зависимости от качества скана документа. Для максимально качественной калибровки модели использовались сканы документов с низким разрешением.
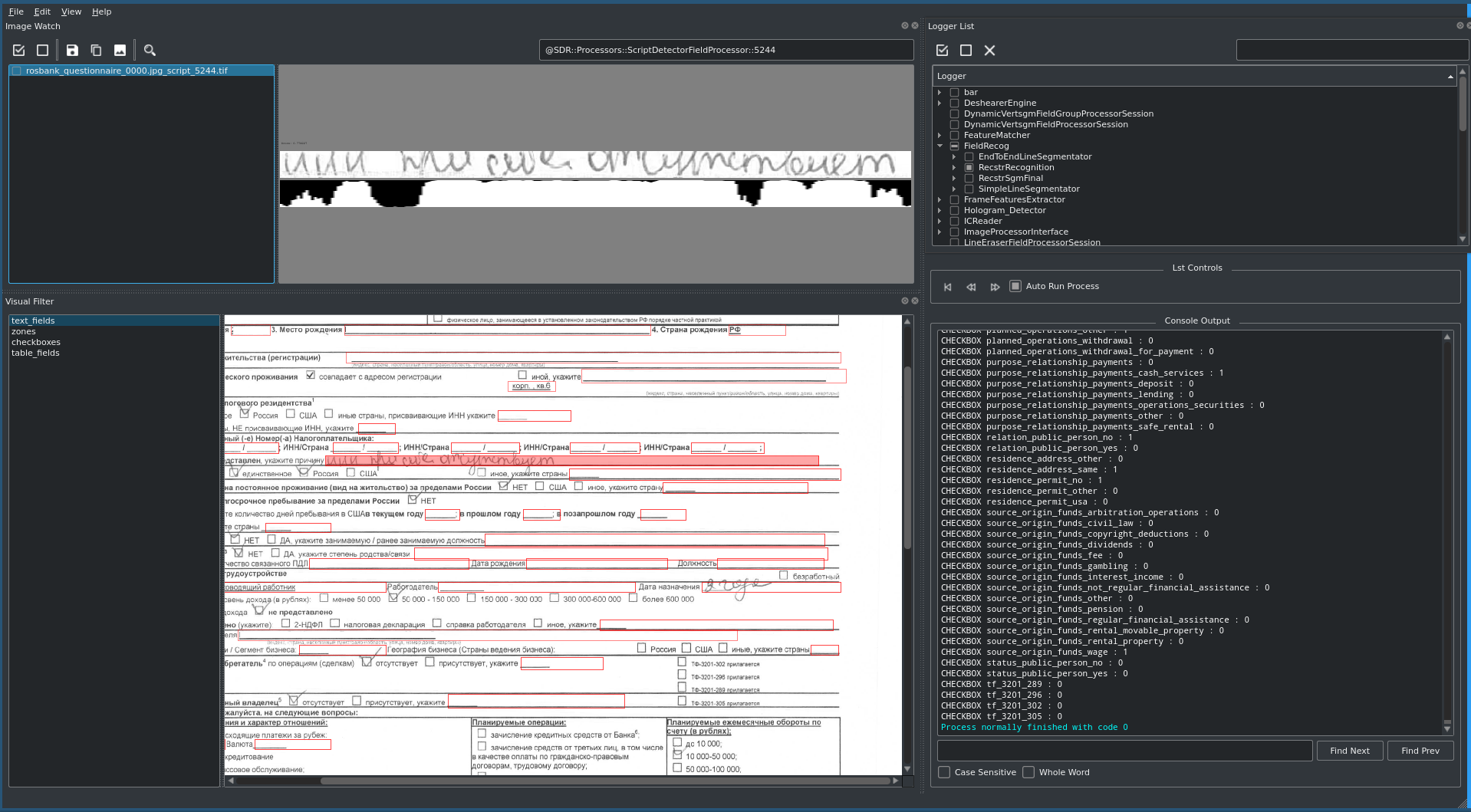
Особое внимание следовало уделить самому сложному документу, содержащему наибольшее количество полей и чек-боксов, — вопроснику KYC. Для него заранее были подготовлены специальные сценарии заполнения документа и написаны автоматизированные макросы, которые позволили ускорить процесс тестирования, проверить все возможные комбинации данных и оперативно дать обратную связь вендору для калибровки модели.
Необходимая доработка систем банка и межсистемная интеграция были выполнены заранее и выставлены на тестовых средах банка.
Реализованный сценарий состоит из следующих этапов:
На данный момент завершено обучение модели, проведено успешное тестирование и внедрение бизнес-процесса на производственной среде банка. Выполненная автоматизация позволила сократить среднее время открытия счета с 20 минут до 5 минут. Автоматизирован трудоемкий этап бизнес-процесса по распознаванию и вводу данных документа, выполнявшийся ранее вручную. При этом резко снижена вероятность возникновения ошибок под воздействием человеческого фактора. Кроме того, гарантирована идентичность данных, взятых из одного и того же документа, в разных системах банка.
Мы с командой представляем направление развития бизнеса с партнерами Росбанка. Сегодня хотим рассказать об успешном опыте автоматизации банковского бизнес-процесса с использованием прямых интеграций между системами, искусственного интеллекта в части распознавания образов и текста на базе GreenOCR, РФ-законодательстве и подготовке сэмплов для обучения.

Итак, начнем. В Росбанке существует бизнес-процесс открытия счета для заемщика в лице банка партнера. Существующий процесс, следуя всем регуляторным требованиям и требованиям группы Societe Generale, до автоматизации занимал до 20 минут операционного времени на каждого клиента. Процесс включает в себя получение сканов документов back-офисом, проверку корректности заполнения каждого документа и разнесения полей документа по информационным системам банка, ряд других проверок и только в самом конце — открытие счета. Это именно тот процесс, который стоит за кнопкой «Открыть счет».
Основные поля документа — фамилия, имя, отчество, дата рождения клиента и др. — содержатся практически во всех типах получаемых документов и дублируются при вводе в разные системы Банка. Наиболее сложный документ – вопросник KYC (от Know Your Customer — знай своего клиента) – представляет собой печатную форму формата А4, заполняемую шрифтом 8 кегля и содержащую порядка 170 текстовых полей и чек-боксов, а также табличные представления.
Что нам предстояло сделать?
Основная цель, стоявшая перед нами, — сократить до минимума время открытия счета.
Анализ процесса показал, что необходимо:
- Сократить количество ручных верификаций каждого документа;
- Провести автоматизацию заполнения одних и тех же полей в разных системах банка;
- Сократить перемещение сканов документов между системами;
Для решения задач (1) и (2) было решено воспользоваться уже внедренным в банке решением по распознаванию образов и текста на базе GreenOCR (рабочее название – «распознавалка»). Форматы используемых в бизнес-процессе документов не являются стандартными, поэтому перед командой стояла задача разработать требования к «распознавалке» и подготовить примеры для обучения нейронной сети (сэмплы).
Для решения задач (2) и (3) была необходима доработка систем и межсистемных интеграция.
Наша команда под руководством Юлии Алексашиной
- Александр Башков — внутренняя разработка систем (.Net)
- Валентина Сайфуллина — бизнес анализ, тестирование
- Григорий Проскурин — интеграции между системами (.Net)
- Екатерина Пантелеева — бизнес анализ, тестирование
- Сергей Фролов — Project Management, анализ качества моделей
- Участники от внешнего вендора (Smart Engines совместно с Философия.ит)
Обучение распознавалки
Комплект клиентских документов, используемых в бизнес-процессе, включал в себя:
- Паспорт;
- Согласие — печатная форма формата А4, 1 л;
- Доверенность — печатная форма формата А4, 2 л;
- Вопросник KYC – печатная форма формата А4, 1 л;
Для начала были досконально изучены документы и разработаны требования, включавшие в себя не только работу распознавалки с динамичными полями, но также и работу со статичным текстом, полями с рукописными данными, в целом распознавание документа по периметру и прочие доработки.
Распознавание паспорта входило в коробочный функционал системы GreenOCR и доработок не потребовало.
Для остальных типов документов в результате проведенного анализа были определены необходимые атрибуты и признаки, которые должна возвращать «распознавалка». При этом пришлось учитывать следующие моменты, затруднявшие процесс распознавания и потребовавшие заметного усложнения используемых алгоритмов:
- Каждый документ может содержать текстовые поля и статический текст, меняющие свое положение в пределах печатной формы при заполнении шаблона документа реальными данными. Наиболее заметно это сказывается при распознавании многостраничного документа, когда поле может «переползать» с одной страницы на другую;
- Шрифт 8-го кегля очень чувствителен к разрешению скана документа. При низких разрешениях такой шрифт не может быть распознан ни системой распознавания, ни визуально;
- В процессе сканирования используются документы самого разного качества (зачастую невысокого) и сканеры с самыми разными техническими характеристиками;
- Документ одного и того же типа может иметь разные шаблоны;
- Исходная ориентация документа, использовавшаяся при сканировании, заранее неизвестна;
- Имена файлов получаемых сканов документов могут быть произвольными и при этом могут повторяться;
Безопасность персональных данных
Изначально задача показалась нам не слишком сложной и выглядела довольно стандартно:
Требования –> Вендор –> Модель –> Тестирование модели -> Запуск процесса
В случае не успешных тестов модель возвращается вендору на повторное обучение.
Ежедневно мы получаем огромное количество сканов документов, и подготовить выборку для обучения модели не должно было стать проблемой. Вся обработка персональных данных должна соответствовать требованиям Федерального закона «О персональных данных» N152-ФЗ. Согласия клиентов на обработку персональных данных клиентов есть только внутри Росбанка. Передать вендору, для обучения модели, документы клиентов мы не можем.
Рассматривалось три пути решения проблемы:
- Распространить и обеспечить себя типовыми формами согласий всех клиентов на передачу персональных данных на случаи передачи данных вендору, что означало бы пройти долгий путь всех необходимых согласований в крупной компании, что, в свою очередь, ставило бы под угрозу соблюдение сроков проекта;
- Маскировать готовые данные. Этот путь означал бы высокий риск получения неточной модели и высокие трудозатраты на подготовку выборки документов, так как каждый документ пришлось бы обрабатывать вручную – удалять (маскировать) персональные данные, а также проводить заключительную проверку всего массива подготовленных документов на предмет правильности и полноты удаления персональных данных;
- Синтезировать (имитировать) документы из несуществующих данных. Было ясно, что этот путь потребует привлечения подразделений банка для синтеза, печати и сканирования документов и, следовательно, значительного объема ручной работы, но при этом обеспечит максимальную гибкость и оперативность внесения изменений;
Обучение модели
Проанализировав с командой предложенные варианты, на предмет скорости их реализации и возможных рисков, мы выбрали третий вариант — путь имитационного моделирования документов для обучения модели. Основное преимущество этого процесса – возможность охватить максимально широкий спектр устройств сканирования для сокращения количества итераций по калибровке и доработке модели.
Шаблоны документов были реализованы в html-формате. Быстро и оперативно был подготовлен массив тестовых данных и макрос, заполняющий шаблоны синтезированными данными и автоматизирующий печать. Далее мы сгенерировали печатные формы в pdf-формате и каждому файлу присвоили уникальный идентификатор для сверки ответов, получаемых с «разпознавалки».
Обучение нейронной сети, разметка областей и настройка форм проходили на стороне вендора.
По причине ограниченных сроков, обучение модели разбили на 2 этапа.
На первом этапе было проведено обучение модели распознаванию типов документов и «грубому» распознаванию содержимого самих документов:
Требования –> Вендор –> Подготовка тестовых данных-> Сбор данных-> Обучение модели по распознаванию форм– > Тестирование форм -> Настройка модели
На втором этапе происходило детальное обучение модели распознаванию содержимого каждого типа документов. Обучение и внедрение модели на втором этапе можно описать следующей схемой, одинаковой для всех типов документов:
Подготовка тестовых данных в разных разрешениях -> Сбор и передача данных вендору -> Обучение модели -> Тестирование модели -> Калибровка модели -> Внедрение модели –> Проверка результатов в бою -> Выявление проблемных кейсов -> Имитация проблемных кейсов и передача вендору -> Повторение шагов с тестирования
Следует отметить, что, несмотря на весьма широкий охват спектра использованных устройств сканирования, ряд устройств все же не был представлен в примерах для обучения модели. Поэтому ввод модели в бой проходил в пилотном режиме, и результаты не использовались для автоматизации. Данные, полученные при работе в пилотном режиме, только записывались в базу данных для последующего анализа и разбора.
Тестирование
Так как контур обучения модели находился на стороне вендора и не был связан с системами банка, после каждого цикла обучения модель передавалась вендором в банк, где проводилась её проверка на тестовой среде. В случае успешной проверки модель переносилась на сертификационную среду, где проводилось ее регрессионное тестирование, и далее — на промышленную среду, для выявления особых кейсов, не учтенных при обучении модели.
В периметре банка на модель подавались данные, результаты записывались в базу данных. Анализ качества данных проводился с помощью всемогущего Excel — с использованием сводных таблиц, логики с формулами и их комбинаций vlookup, hlookup, index, len, match и посимвольного сравнения строк через функцию if.
Тестирование с использованием имитированных документов позволило выполнить максимальное количество тестовых сценариев и максимально автоматизировать процесс.
Вначале в ручном режиме была выполнена проверка возврата всех полей на соответствие исходным требованиям по каждому типу документа. Далее проверялись ответы модели при динамическом заполнении текстовых блоков разной длины. Целью было проверить качество ответов при переходе текста со строки на строку и со страницы на страницу. В конце проверяли качество ответов по полям в зависимости от качества скана документа. Для максимально качественной калибровки модели использовались сканы документов с низким разрешением.
Особое внимание следовало уделить самому сложному документу, содержащему наибольшее количество полей и чек-боксов, — вопроснику KYC. Для него заранее были подготовлены специальные сценарии заполнения документа и написаны автоматизированные макросы, которые позволили ускорить процесс тестирования, проверить все возможные комбинации данных и оперативно дать обратную связь вендору для калибровки модели.
Интеграция и внутренняя разработка
Необходимая доработка систем банка и межсистемная интеграция были выполнены заранее и выставлены на тестовых средах банка.
Реализованный сценарий состоит из следующих этапов:
- Прием входящих сканов документов;
- Отправка принятых сканов в «распознавалку». Отправка возможна в синхронном и асинхронном режиме с числом потоков до 10;
- Получение ответа от «распознавалки», сверка и валидация принятых данных;
- Сохранение исходного скана документа в электронной библиотеке банка;
- Инициирование в системах банка процессов обработки принятых с «распознавалки» данных и последующая верификация сотрудником;
Итог
На данный момент завершено обучение модели, проведено успешное тестирование и внедрение бизнес-процесса на производственной среде банка. Выполненная автоматизация позволила сократить среднее время открытия счета с 20 минут до 5 минут. Автоматизирован трудоемкий этап бизнес-процесса по распознаванию и вводу данных документа, выполнявшийся ранее вручную. При этом резко снижена вероятность возникновения ошибок под воздействием человеческого фактора. Кроме того, гарантирована идентичность данных, взятых из одного и того же документа, в разных системах банка.
