Оценка контента одна из главных составляющих формулы релевантности. Знание текстовых признаков и вклад каждого из них в оценку сайта позволит приблизиться к более профессиональной работе с ресурсом. В данной статье будет рассмотрена модель, позволяющая восстановить формулу ранжирования по каждому конкретному запросу, указана значимость определение тематики сайта при продвижении по определенному запросу, а также проработан вопрос, связанного с определением неестественного текста.
Восстановление формулы ранжирования
Если переводить данную задачу в область математики, то входные данные можно представить набором векторов, где каждый вектор – множество характеристик каждого сайта, а координаты в векторе – параметр, по которым оценивается сайт. В описанном векторном пространстве обязательно должна быть задана функция, определяющая отношение порядка двух объектов между собой. Эта функция позволяет ранжировать объекты между собой по принципу «больше — меньше», однако при этом сказать, насколько именно одно больше или меньше другого – нельзя. Такого вида задачи относятся к задачам оценки порядковой регрессии.
Наши сотрудники разработали алгоритм на основе модели линейной регрессии с регулируемой селективностью, который позволил с определенной долей погрешности восстановить ранги сайтов и спрогнозировать изменение выдачи при соответствующих корректировках параметров сайта. Первым шагом алгоритма является обучение модели. В данном случае обучающая выборка представляет собой результаты ранжирования сайтов в рамках одного поискового запроса. Упорядоченность сайтов в рамках поискового запроса фактически означает, что в признаковом пространстве существует некоторое направление, на которое объекты обучающей выборки должны проектироваться в нужном порядке. Это направление и является искомым в задаче восстановления формулы ранжирования. Однако судя по рис.1, таких направлений может быть много.

Рис. 1. Выбор направляющего вектора
Для решения данного вопроса был рассмотрен подход, лежащий в основе метода опорных точек, а именно – выбор такого направления, которое будет обеспечивать максимальное удаление объектов друг от друга.
Следующая задача, которая была решена — выбор стратегии обучения. Рассматривалось два варианта – сокращенная стратегия обучения, при которой учитывается порядок двух соответствующих элементов, и полная стратегия, которая учитывает весь порядок объектов. В результате экспериментов была выбрана сокращенная стратегия, которая заключается в решении следующего уравнения:(1)
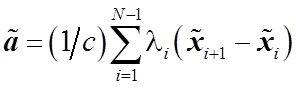 , где
, где 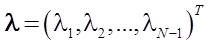 — решение стандартной задачи квадратичного программирования при линейных ограничениях:
— решение стандартной задачи квадратичного программирования при линейных ограничениях: 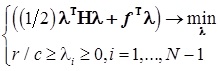 , где
, где
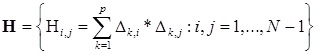 — симметричная матрица
— симметричная матрица
 — вектор коэффициента
— вектор коэффициента
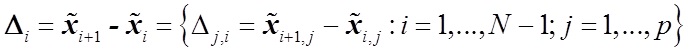 — разница векторов характеристик
— разница векторов характеристик
Данный подход на различных выборках (100 признаков и 500 признаков на 20 различных множествах поисковых запросов) показал хорошие результаты (см. табл. 1).
Таблица 1. Результаты сокращенной модели


Рис. 2. Восстановленные коэффициенты регрессии при n=100

Рис. 3. Восстановленные коэффициенты регрессии при n=500
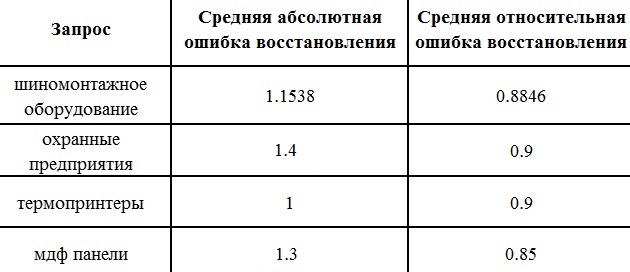
Если говорить о результатах на конкретных запросах, то проведенные эксперименты дают следующий показатель ошибка
Таблица 2. Ошибки вычислений
При работе над проектом данный подход использовался для прогнозирования позиций при конкретном изменении на сайте. Подобные эксперименты проводились на базе текстовых признаков. Первоначально были собраны данные по сайтам из ТОП20 по рассматриваемому запросу, затем данные подвергались стандартизации с помощью соответствующего алгоритма. После чего выполнялся алгоритм непосредственно по вычислению «релевантности» с помощью метода квадратичного программирования.
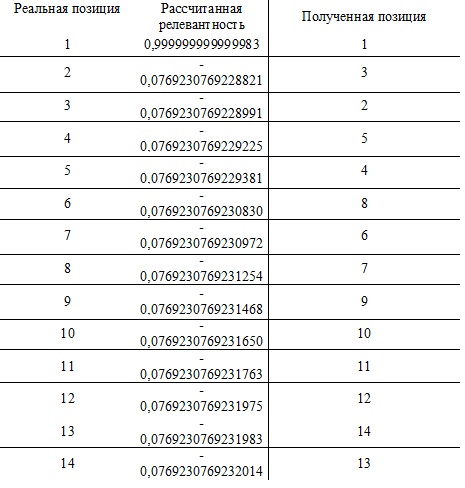
Полученные значения релевантности сайта сортируются и делается вывод о восстановленных позициях.
Таблица 3. Восстановление позиций
Было выявлено, что наибольшее влияние на позиции при ранжировании запроса «шиномонтажное оборудование» вносят признаки: наличие в Яндекс каталоге, вхождение первого слова из запроса «шиномонтажное», вхождение в h1 первого слова запроса «шиномонтажное», вхождение в title страницы второго слова запроса «оборудование».
Были произведены соответствующие корректировки в параметрах сайта и запущена программа. В результате был дан прогноз на соответствующую позицию.
Рис. 4. Программа, восстанавливающая формулу ранжирования
На сайте были произведены все эти изменения, после очередного апдейта сайт занял позиции, близкие к прогнозируемым. Первоначальная позиция была 50, после указанных изменений она составила ТОП20.

Рис.5. Результаты продвижения запроса «шиномонтажное оборудование»
Измерение тематики текста
В работе с восстановлением формулы ранжирования была подтверждена значимость измерения тематической близости тематики текста по отношению к тематике всего сайта. Подобную метрику можно построить на базе расчета косинуса между векторами соответствующих тематики страницы, релевантной запросу, и всего сайта: (2)
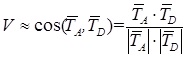
где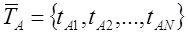 и
и 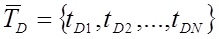 соответственно обозначение вектора тематичности сайта и рассматриваемого документа.
соответственно обозначение вектора тематичности сайта и рассматриваемого документа.
N – число слов в словаре коллекции. Вес каждого слова j в документе Di рассчитывается по формуле:(3)
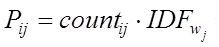
где countij – число вхождений слова в документ, IDFwj — обратная частота слова в коллекции. После расчета веса каждого слова в документе, вектор нормируется:(4)
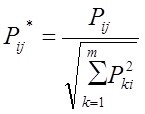
Аналогичным образом строится вектор и для всего сайта, при этом текст сайта получается объединением текстов всех входящих в него документов.
Таким образом, алгоритм определения тематической ценности документа можно представить в следующем виде:
1) Определяется словарь, в котором отсутствуют редкие и стоп-слова, т.е. IDF слов, формирующих словарь, лежит в диапазоне значимых слов.
2) Строится N-мерный вектор тематичности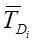 для рассматриваемого документа
для рассматриваемого документа  , используя формулы 3 и 4.
, используя формулы 3 и 4.
3) Строится N-мерный вектор тематичности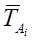 для всего сайта
для всего сайта  , используя формулы 3 и 4.
, используя формулы 3 и 4.
4) С помощью (2) устанавливается близость векторови . Чем ближе вектора, тем тематическая ценность документа выше.
На основе данной модели была написана программа, позволяющая определить тематическую схожесть рассматриваемого документа и текстовой составляющей самого сайта. Эксперименты проводились на базе 3 групп сайтов: с одинаковой тематикой, с близкой тематикой, с разной тематикой. Всего было обработано 200 статей. В результате обработки были получены следующие данные по 20 группам «1 тестовый документ / 9 обучающих документов», представленные в таблице.
Таблица 4. Результаты проверки тематической полноты

Из таблицы видно, что предложенный метод определения тематической полноты информационного ресурса работает на практике: проверяемые документы, расположенные на сайтах с более полно раскрывающейся тематикой, имеют более высокие показатели. Однако были выявлены и недочеты разработанной системы. Во-первых, на сайтах часто находятся неинформативные или малоинформативные страницы (формы заказов, обратной связи, контакты и т.п.). Во-вторых, при выборе случайно заданного количества обучающих текстов можно отобрать нетематические страницы. В-третьих, в качестве тестовых текстов могут попасться неспецифический контент, но близкие по тематике, например – правописание того или иного слова. В-четвертых, существуют сайты, которые охватывают разные тематические направления, при этом пересекающихся по смыслу (интернет-магазины, новостные сайты, банки рефератов).
При перечисленных недочетах общая картина позволяет оценить тематическую полноту ресурса. В качестве примера рассмотрим сайт тематики «логистика» с запросами, касающимися оборудования (на сайте присутствует каталог, помимо информации о логистике). Сайт зарегистрирован в Яндекс.Каталоге и имеет рубрику «экспедирование и перевозка грузов»:

Рис. 6. Рубрика, присвоенная в Каталоге.Яндекса
При использовании рассмотренного выше метода был сделан вывод, что тематическая полнота продвигаемых страниц не полная по отношению к запросам тематики «перевозка и доставка из Китая», но достаточная большая по отношению к тематике «оборудование». Соотношение страниц «логистика: оборудование» составляло соответственно «30:200». Соответственно, и позиции, и трафик был лишь у запросов, связанных с оборудованием. При этом приоритетна была «логистика». Для решения проблемы было написано письмо в Яндекс с целью получения развернутой информации. Однако был получен стандартный ответ «Платона» об улучшении и развитии сайта, но в целом все в порядке.
В качестве решения стоял выбор между развитием требуемой тематике на сайте и разнесением двух тематик на разные поддомены. Выиграла необходимость получить быстрый результат. Были составлены ТЗ на перенос направления «оборудование» на поддомен, а на основном сайте сохранена информация по «логистике», а так же на развитие ресурса путем добавления новых релевантных тематике страниц. Результат изменений представлен на рис. Запросы по оборудованию успешно перешли на поддомен и заняли положительные позиции. А после добавления тематических страниц по логистике и запросы по перевозкам, стали показывать положительную динамику.

Рис. 6. Результаты продвижения, после разведения тематик
Таким образом, за счет схемы «поддомен + домен» получилось без потерь разнести тематики и за счет этого повысить релевантность каждой из тематик по-отдельности и добиться положительную динамику по запросам.
Измерение естественности текста
Требования попадания в Яндекс.Каталог ужесточаются. В последнее время приходится сталкиваться с тем, что при проверки сайта, сотрудники яндекса сообщают о некачественном контенте. Выявить данный факт вручную на большом сайте представляется проблемой. Поэтому в настоящий момент ведутся работы по анализу признаков данных текстов. Расскажу о некоторых из них. Можно выделить два основных подхода в получении спам-текста: замена русских букв латинскими и генерация контента, лишенного смысла.
Первый подход вскрывается путем выявления измененных слов с помощью инвертированной частоты и сравнением с установленной эмпирическим путем критической величиной. Слова, образованные заменой русских букв аналогичными латинскими, являются редкими словами с точки зрения статистики употребления. С помощью инвертированной частоты по общей коллекции можно выявить такие слова. Каждому элементу текстового узла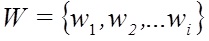 , ставится в соответствие значение
, ставится в соответствие значение 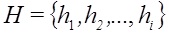 с помощью функции инвертированной частоты fh:(5)
с помощью функции инвертированной частоты fh:(5)
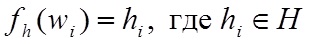
В качестве функции инвертированной частоты были рассмотрены:(6), (7), (8).
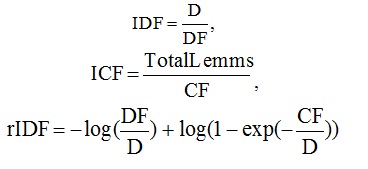
Здесь D – число документов в коллекции, DF – количество документов, в которых встречается лемма, CF – число вхождений леммы в коллекцию, TotalLemms – общее число вхождений всех лемм в коллекции. Из этих вариантов лучший результат в эксперименте, также как и в исследовании Гулина А. показал ICF (7), поэтому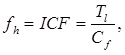 где – число вхождений леммы в рассматриваемом тексте, – общее число вхождений всех лемм во множестве.
где – число вхождений леммы в рассматриваемом тексте, – общее число вхождений всех лемм во множестве.
Чем больше значение функции fh, тем реже слово встречается. Для получения интервала ICF значимых слов была написана программа, на вход которой подавались тексты различного содержания (устранение тематического влияния). Программа обработала порядка 500 МБ текстовой информации. В результате обработки был получен словарь обратных частот слов ICF в нормальной форме. Лемматизация слов была осуществлена с помощью парсера mystem, компании Яндекс. Все элементы словаря были отсортированы в порядке увеличения обратной частоты. В результате анализа данного словаря был получен интервал значимых слов: [500; 191703].
Для установления критерия выявления спам-текстов, также вводится критическая величина Hкрит и производится подсчет Hp процента слов, чья характеристика превышает установленную эмпирическим путем критическую величину Hкрит :(9)
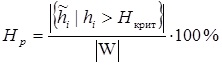
В качестве критической отметки используется процент незначащих слов – 50% (наибольший показатель частоты служебных слов — 37.60%, а придуманных слов автором в среднем — 5.63%). Большой процент употребления в одном тексте таких словообразований Hp будет свидетельствовать о том, что документ является сгенерированным.
Однако сайтов с такими спам-текстами достаточно мало. Второй подход более распространен. Существует класс неестественных текстов, порожденных с помощью генераторов на основе цепей Маркова. На основе исследований Павлова А.С. была предложена модель, позволяющая выявлять такие тексты.
Вся текстовая составляющая B документа D имеет ряд признаков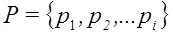 , трудно контролируемых автором. Для построения автоматического классификатора неестественных текстов используются выделенные признаки в машинном обучении. В качестве разрабатываемого подхода лежит алгоритм на основе деревьев решений C4.5. Сам алгоритм определения неестественного текста выглядит следующим образом:
, трудно контролируемых автором. Для построения автоматического классификатора неестественных текстов используются выделенные признаки в машинном обучении. В качестве разрабатываемого подхода лежит алгоритм на основе деревьев решений C4.5. Сам алгоритм определения неестественного текста выглядит следующим образом:
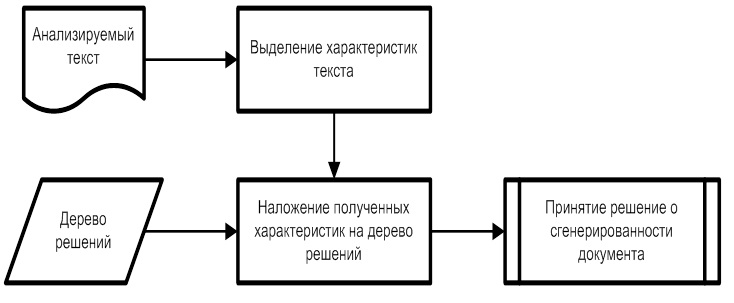
Рис. 7. Алгоритм определения сгенерированного контента
Для получения дерева решений была подготовлена база естественных текстов в размере 2000 и база неестественных текстов объемом также 2000, часть найдена в интернете, часть сгенерирована, остальные получены путем синонимизации документов-образцов или путем перевода с иностранных языков. Исходной коллекцией стала коллекция ROMIP By.Web. Инструменты генерации и синонимизации были найдены в интернете (TextoGEN, Generating The Web 2.2, SeoGenerator и другие).
Полученный набор текстов делился на две равные части. Первая группа использовалась в качестве обучающей выборки, а вторая часть – тестовый набор. Обе выборки имели равное количество документов-образцов и порожденных текстов.
Для процесса обучения была написана программа, которая по каждому тексту строила вектор, оценивающий параметры, влияющие на определение естественности текста. Согласно исследованию Павлова А.С. наибольший вклад в обучение вносит список параметров, определяющих текстовое разнообразие и частоту использования частей речи. В таблице представлен список наиболее ценных признаков для классификации русскоязычных текстов, для каждого признака указана F-мера и тип признака.
Таблица 5. Наиболее ценные признаки для классификации текстов

По полученным векторам P каждого из документа D строилось дерево решений. Данная процедура проводилась с помощью аналитической платформы Deductor Studio Academic версии 5.2. В Deductor в основе обработчика «Дерево решений» лежит модифицированный алгоритм C4.5, решающий задачи классификации. В результате было построено дерево со 157 узлами и 79 правилами. На рис. представлена часть полученного дерева. Полученные правила использовались в основной программе при определении спам-текстов сайта.

Рис. 8. Дерево решений. Аналитическая платформа Deductor 5.2.
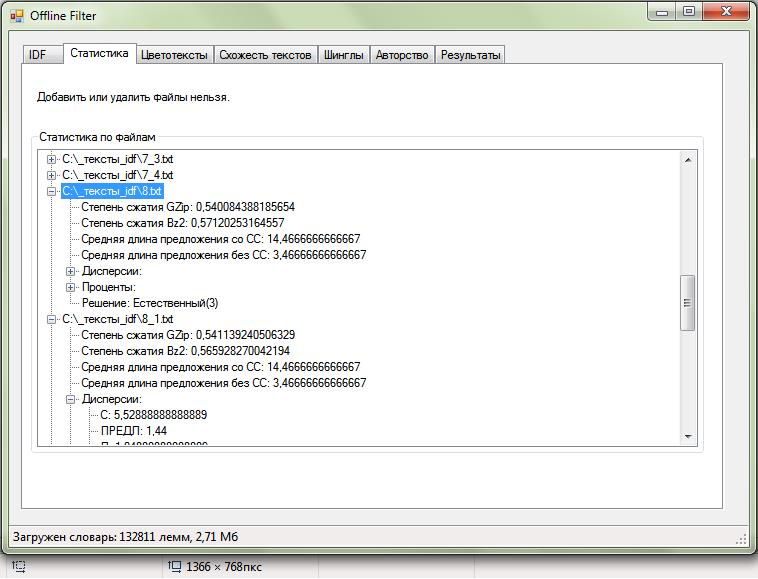
Рис. 9. Результат работы программы по анализу текстов
На практике данный подход помог обнаружить причину отсутствия динамики по запросам. Программа обнаружила сгенерированные тексты на всех страницах категорий сайта. При расследовании было выяснено, что они представляют контент машинного перевода этого же сайта, но английской версии.
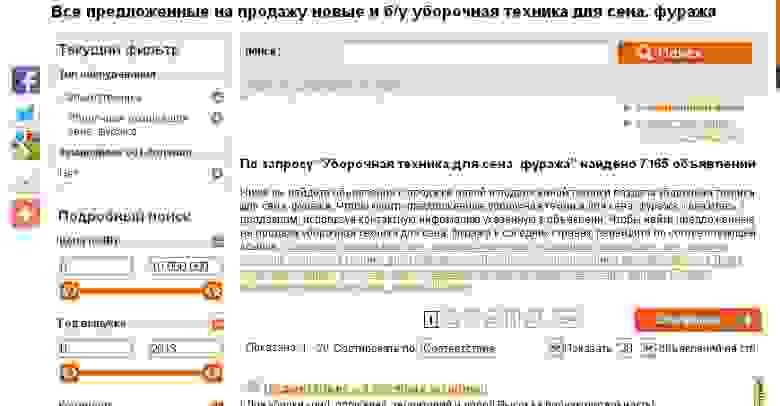
Рис. 10. Тексты на страницах категорий
После редактирования данных текстов даже только на продвигаемых страницах, была получена хорошая динамику: запросы из ТОП500 сразу попали в ТОП10 за 9 недель.

Рис. 11. Пример измененного текста.
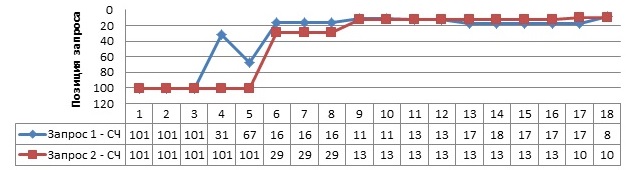
Рис. 12. Изменение позиций по неделям после выкладки.
В заключение необходимо отметить, что разработка рассмотренных функционалов — не обязательна! Она полезна при глобальных исследованиях поисковых машин. При продвижении сайта достаточно выработать подход, позволяющий точечно работать с запросами на основе анализа ТОПа. Для этого существует много естественных инструментов:
1) Проверьте, сколько по запросу релевантных страниц на сайте и сравните с конкурентами – сможете оценить текстовую полноту сайта
2) Обратите внимание на подсвеченные слова в многословных запросам в сохраненной копии – помощь при составлении текстов, на сколько далеко могут стоять друг от друга слова
3) Используйте язык запросов. Например, анализируя выдачу по точному запросу и без кавычек, можно выявить проблемы с текстовой составляющей
4) Через расширенный поиск ищите запрос по конкретным сайтам и анализируйте, какие страницы и почему выше продвигаемой
5) Результаты Вебмастера.Яндекса и Вебмастера.Гугл, данные метрики и GA также помогут выявить проблемы и провести работу с ними.
Целенаправленная деятельность по запросам всегда дает положительный результат.
Авторы статьи: Неелова Н.В. (к.т.н., руководитель отдела ПП Ingate), Поленова Е.А. (руководитель группы ПП Ingate).
Восстановление формулы ранжирования
Если переводить данную задачу в область математики, то входные данные можно представить набором векторов, где каждый вектор – множество характеристик каждого сайта, а координаты в векторе – параметр, по которым оценивается сайт. В описанном векторном пространстве обязательно должна быть задана функция, определяющая отношение порядка двух объектов между собой. Эта функция позволяет ранжировать объекты между собой по принципу «больше — меньше», однако при этом сказать, насколько именно одно больше или меньше другого – нельзя. Такого вида задачи относятся к задачам оценки порядковой регрессии.
Наши сотрудники разработали алгоритм на основе модели линейной регрессии с регулируемой селективностью, который позволил с определенной долей погрешности восстановить ранги сайтов и спрогнозировать изменение выдачи при соответствующих корректировках параметров сайта. Первым шагом алгоритма является обучение модели. В данном случае обучающая выборка представляет собой результаты ранжирования сайтов в рамках одного поискового запроса. Упорядоченность сайтов в рамках поискового запроса фактически означает, что в признаковом пространстве существует некоторое направление, на которое объекты обучающей выборки должны проектироваться в нужном порядке. Это направление и является искомым в задаче восстановления формулы ранжирования. Однако судя по рис.1, таких направлений может быть много.
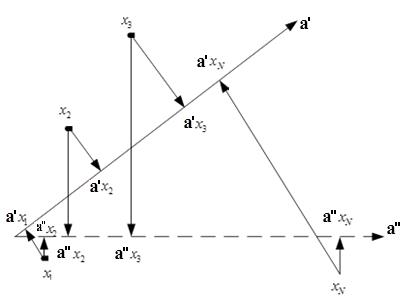
Рис. 1. Выбор направляющего вектора
Для решения данного вопроса был рассмотрен подход, лежащий в основе метода опорных точек, а именно – выбор такого направления, которое будет обеспечивать максимальное удаление объектов друг от друга.
Следующая задача, которая была решена — выбор стратегии обучения. Рассматривалось два варианта – сокращенная стратегия обучения, при которой учитывается порядок двух соответствующих элементов, и полная стратегия, которая учитывает весь порядок объектов. В результате экспериментов была выбрана сокращенная стратегия, которая заключается в решении следующего уравнения:(1)
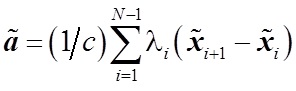 , где
, где 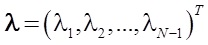 — решение стандартной задачи квадратичного программирования при линейных ограничениях:
— решение стандартной задачи квадратичного программирования при линейных ограничениях: 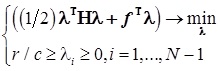 , где
, где 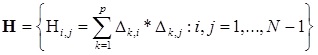 — симметричная матрица
— симметричная матрица  — вектор коэффициента
— вектор коэффициента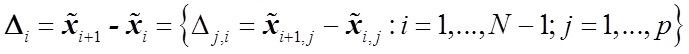 — разница векторов характеристик
— разница векторов характеристикДанный подход на различных выборках (100 признаков и 500 признаков на 20 различных множествах поисковых запросов) показал хорошие результаты (см. табл. 1).
Таблица 1. Результаты сокращенной модели

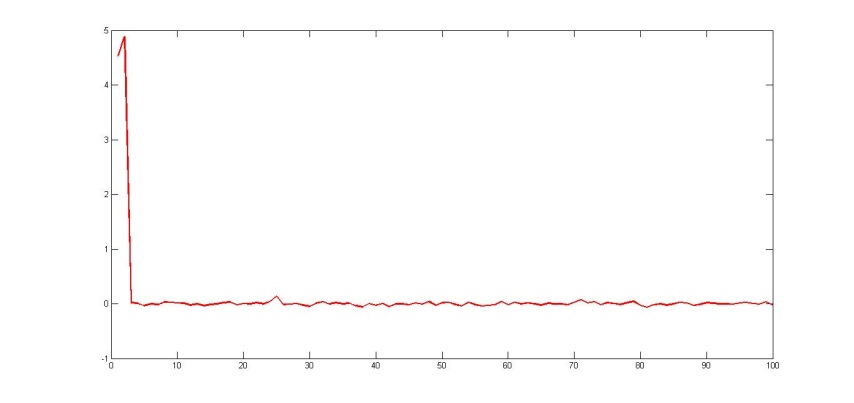
Рис. 2. Восстановленные коэффициенты регрессии при n=100
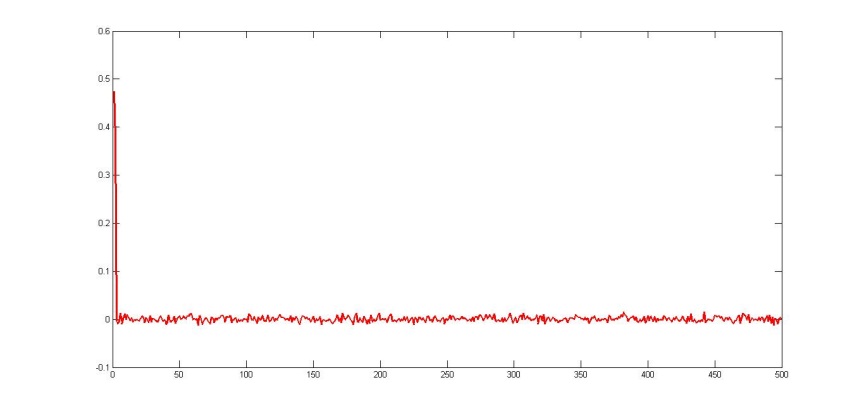
Рис. 3. Восстановленные коэффициенты регрессии при n=500
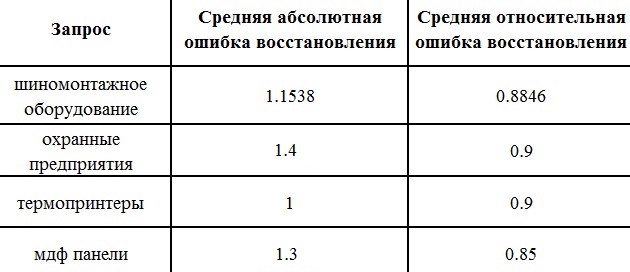
Если говорить о результатах на конкретных запросах, то проведенные эксперименты дают следующий показатель ошибка
Таблица 2. Ошибки вычислений
При работе над проектом данный подход использовался для прогнозирования позиций при конкретном изменении на сайте. Подобные эксперименты проводились на базе текстовых признаков. Первоначально были собраны данные по сайтам из ТОП20 по рассматриваемому запросу, затем данные подвергались стандартизации с помощью соответствующего алгоритма. После чего выполнялся алгоритм непосредственно по вычислению «релевантности» с помощью метода квадратичного программирования.
Полученные значения релевантности сайта сортируются и делается вывод о восстановленных позициях.
Таблица 3. Восстановление позиций

Было выявлено, что наибольшее влияние на позиции при ранжировании запроса «шиномонтажное оборудование» вносят признаки: наличие в Яндекс каталоге, вхождение первого слова из запроса «шиномонтажное», вхождение в h1 первого слова запроса «шиномонтажное», вхождение в title страницы второго слова запроса «оборудование».
Были произведены соответствующие корректировки в параметрах сайта и запущена программа. В результате был дан прогноз на соответствующую позицию.
Рис. 4. Программа, восстанавливающая формулу ранжирования
На сайте были произведены все эти изменения, после очередного апдейта сайт занял позиции, близкие к прогнозируемым. Первоначальная позиция была 50, после указанных изменений она составила ТОП20.
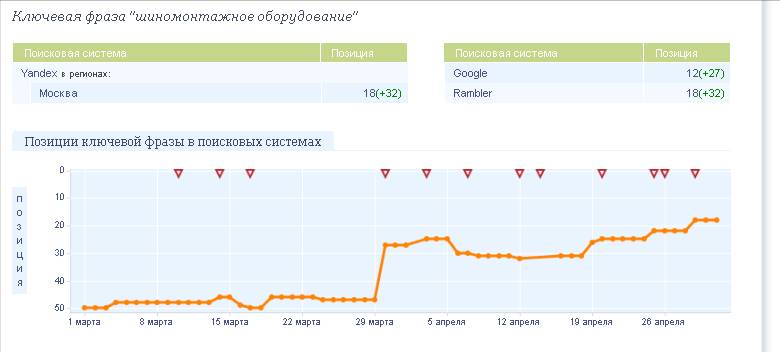
Рис.5. Результаты продвижения запроса «шиномонтажное оборудование»
Измерение тематики текста
В работе с восстановлением формулы ранжирования была подтверждена значимость измерения тематической близости тематики текста по отношению к тематике всего сайта. Подобную метрику можно построить на базе расчета косинуса между векторами соответствующих тематики страницы, релевантной запросу, и всего сайта: (2)
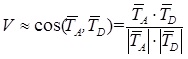
где
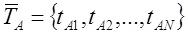 и
и  соответственно обозначение вектора тематичности сайта и рассматриваемого документа.
соответственно обозначение вектора тематичности сайта и рассматриваемого документа. N – число слов в словаре коллекции. Вес каждого слова j в документе Di рассчитывается по формуле:(3)

где countij – число вхождений слова в документ, IDFwj — обратная частота слова в коллекции. После расчета веса каждого слова в документе, вектор нормируется:(4)
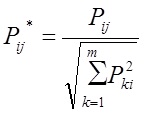
Аналогичным образом строится вектор и для всего сайта, при этом текст сайта получается объединением текстов всех входящих в него документов.
Таким образом, алгоритм определения тематической ценности документа можно представить в следующем виде:
1) Определяется словарь, в котором отсутствуют редкие и стоп-слова, т.е. IDF слов, формирующих словарь, лежит в диапазоне значимых слов.
2) Строится N-мерный вектор тематичности
 для рассматриваемого документа
для рассматриваемого документа 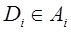 , используя формулы 3 и 4.
, используя формулы 3 и 4.3) Строится N-мерный вектор тематичности
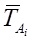 для всего сайта
для всего сайта 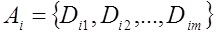 , используя формулы 3 и 4.
, используя формулы 3 и 4.4) С помощью (2) устанавливается близость векторов
и . Чем ближе вектора, тем тематическая ценность документа выше.На основе данной модели была написана программа, позволяющая определить тематическую схожесть рассматриваемого документа и текстовой составляющей самого сайта. Эксперименты проводились на базе 3 групп сайтов: с одинаковой тематикой, с близкой тематикой, с разной тематикой. Всего было обработано 200 статей. В результате обработки были получены следующие данные по 20 группам «1 тестовый документ / 9 обучающих документов», представленные в таблице.
Таблица 4. Результаты проверки тематической полноты
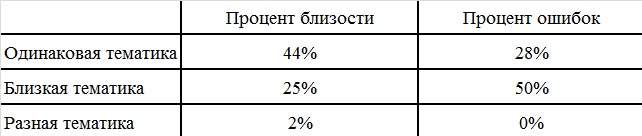
Из таблицы видно, что предложенный метод определения тематической полноты информационного ресурса работает на практике: проверяемые документы, расположенные на сайтах с более полно раскрывающейся тематикой, имеют более высокие показатели. Однако были выявлены и недочеты разработанной системы. Во-первых, на сайтах часто находятся неинформативные или малоинформативные страницы (формы заказов, обратной связи, контакты и т.п.). Во-вторых, при выборе случайно заданного количества обучающих текстов можно отобрать нетематические страницы. В-третьих, в качестве тестовых текстов могут попасться неспецифический контент, но близкие по тематике, например – правописание того или иного слова. В-четвертых, существуют сайты, которые охватывают разные тематические направления, при этом пересекающихся по смыслу (интернет-магазины, новостные сайты, банки рефератов).
При перечисленных недочетах общая картина позволяет оценить тематическую полноту ресурса. В качестве примера рассмотрим сайт тематики «логистика» с запросами, касающимися оборудования (на сайте присутствует каталог, помимо информации о логистике). Сайт зарегистрирован в Яндекс.Каталоге и имеет рубрику «экспедирование и перевозка грузов»:
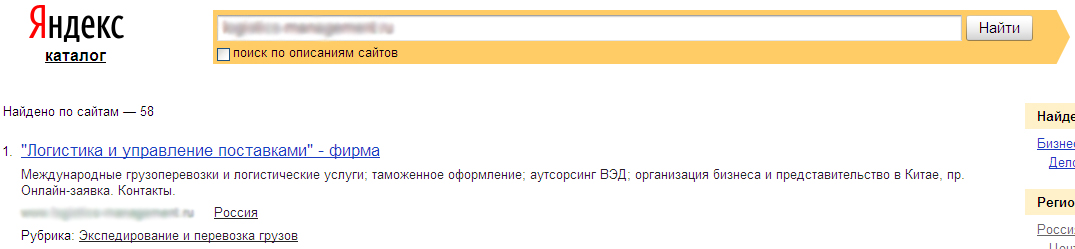
Рис. 6. Рубрика, присвоенная в Каталоге.Яндекса
При использовании рассмотренного выше метода был сделан вывод, что тематическая полнота продвигаемых страниц не полная по отношению к запросам тематики «перевозка и доставка из Китая», но достаточная большая по отношению к тематике «оборудование». Соотношение страниц «логистика: оборудование» составляло соответственно «30:200». Соответственно, и позиции, и трафик был лишь у запросов, связанных с оборудованием. При этом приоритетна была «логистика». Для решения проблемы было написано письмо в Яндекс с целью получения развернутой информации. Однако был получен стандартный ответ «Платона» об улучшении и развитии сайта, но в целом все в порядке.
В качестве решения стоял выбор между развитием требуемой тематике на сайте и разнесением двух тематик на разные поддомены. Выиграла необходимость получить быстрый результат. Были составлены ТЗ на перенос направления «оборудование» на поддомен, а на основном сайте сохранена информация по «логистике», а так же на развитие ресурса путем добавления новых релевантных тематике страниц. Результат изменений представлен на рис. Запросы по оборудованию успешно перешли на поддомен и заняли положительные позиции. А после добавления тематических страниц по логистике и запросы по перевозкам, стали показывать положительную динамику.
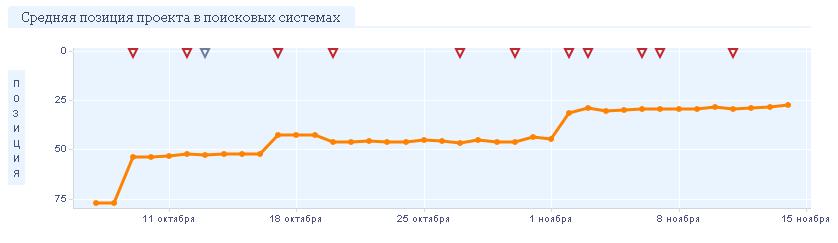
Рис. 6. Результаты продвижения, после разведения тематик
Таким образом, за счет схемы «поддомен + домен» получилось без потерь разнести тематики и за счет этого повысить релевантность каждой из тематик по-отдельности и добиться положительную динамику по запросам.
Измерение естественности текста
Требования попадания в Яндекс.Каталог ужесточаются. В последнее время приходится сталкиваться с тем, что при проверки сайта, сотрудники яндекса сообщают о некачественном контенте. Выявить данный факт вручную на большом сайте представляется проблемой. Поэтому в настоящий момент ведутся работы по анализу признаков данных текстов. Расскажу о некоторых из них. Можно выделить два основных подхода в получении спам-текста: замена русских букв латинскими и генерация контента, лишенного смысла.
Первый подход вскрывается путем выявления измененных слов с помощью инвертированной частоты и сравнением с установленной эмпирическим путем критической величиной. Слова, образованные заменой русских букв аналогичными латинскими, являются редкими словами с точки зрения статистики употребления. С помощью инвертированной частоты по общей коллекции можно выявить такие слова. Каждому элементу текстового узла
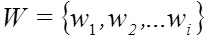 , ставится в соответствие значение
, ставится в соответствие значение  с помощью функции инвертированной частоты fh:(5)
с помощью функции инвертированной частоты fh:(5)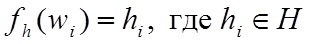
В качестве функции инвертированной частоты были рассмотрены:(6), (7), (8).
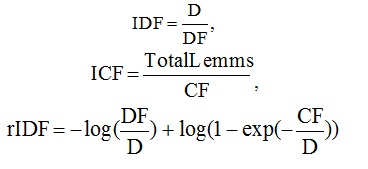
Здесь D – число документов в коллекции, DF – количество документов, в которых встречается лемма, CF – число вхождений леммы в коллекцию, TotalLemms – общее число вхождений всех лемм в коллекции. Из этих вариантов лучший результат в эксперименте, также как и в исследовании Гулина А. показал ICF (7), поэтому
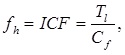 где – число вхождений леммы в рассматриваемом тексте, – общее число вхождений всех лемм во множестве.
где – число вхождений леммы в рассматриваемом тексте, – общее число вхождений всех лемм во множестве. Чем больше значение функции fh, тем реже слово встречается. Для получения интервала ICF значимых слов была написана программа, на вход которой подавались тексты различного содержания (устранение тематического влияния). Программа обработала порядка 500 МБ текстовой информации. В результате обработки был получен словарь обратных частот слов ICF в нормальной форме. Лемматизация слов была осуществлена с помощью парсера mystem, компании Яндекс. Все элементы словаря были отсортированы в порядке увеличения обратной частоты. В результате анализа данного словаря был получен интервал значимых слов: [500; 191703].
Для установления критерия выявления спам-текстов, также вводится критическая величина Hкрит и производится подсчет Hp процента слов, чья характеристика превышает установленную эмпирическим путем критическую величину Hкрит :(9)
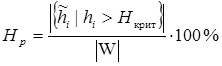
В качестве критической отметки используется процент незначащих слов – 50% (наибольший показатель частоты служебных слов — 37.60%, а придуманных слов автором в среднем — 5.63%). Большой процент употребления в одном тексте таких словообразований Hp будет свидетельствовать о том, что документ является сгенерированным.
Однако сайтов с такими спам-текстами достаточно мало. Второй подход более распространен. Существует класс неестественных текстов, порожденных с помощью генераторов на основе цепей Маркова. На основе исследований Павлова А.С. была предложена модель, позволяющая выявлять такие тексты.
Вся текстовая составляющая B документа D имеет ряд признаков
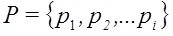 , трудно контролируемых автором. Для построения автоматического классификатора неестественных текстов используются выделенные признаки в машинном обучении. В качестве разрабатываемого подхода лежит алгоритм на основе деревьев решений C4.5. Сам алгоритм определения неестественного текста выглядит следующим образом:
, трудно контролируемых автором. Для построения автоматического классификатора неестественных текстов используются выделенные признаки в машинном обучении. В качестве разрабатываемого подхода лежит алгоритм на основе деревьев решений C4.5. Сам алгоритм определения неестественного текста выглядит следующим образом: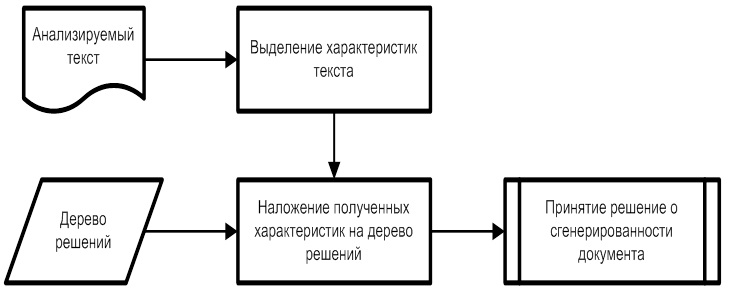
Рис. 7. Алгоритм определения сгенерированного контента
Для получения дерева решений была подготовлена база естественных текстов в размере 2000 и база неестественных текстов объемом также 2000, часть найдена в интернете, часть сгенерирована, остальные получены путем синонимизации документов-образцов или путем перевода с иностранных языков. Исходной коллекцией стала коллекция ROMIP By.Web. Инструменты генерации и синонимизации были найдены в интернете (TextoGEN, Generating The Web 2.2, SeoGenerator и другие).
Полученный набор текстов делился на две равные части. Первая группа использовалась в качестве обучающей выборки, а вторая часть – тестовый набор. Обе выборки имели равное количество документов-образцов и порожденных текстов.
Для процесса обучения была написана программа, которая по каждому тексту строила вектор, оценивающий параметры, влияющие на определение естественности текста. Согласно исследованию Павлова А.С. наибольший вклад в обучение вносит список параметров, определяющих текстовое разнообразие и частоту использования частей речи. В таблице представлен список наиболее ценных признаков для классификации русскоязычных текстов, для каждого признака указана F-мера и тип признака.
Таблица 5. Наиболее ценные признаки для классификации текстов

По полученным векторам P каждого из документа D строилось дерево решений. Данная процедура проводилась с помощью аналитической платформы Deductor Studio Academic версии 5.2. В Deductor в основе обработчика «Дерево решений» лежит модифицированный алгоритм C4.5, решающий задачи классификации. В результате было построено дерево со 157 узлами и 79 правилами. На рис. представлена часть полученного дерева. Полученные правила использовались в основной программе при определении спам-текстов сайта.
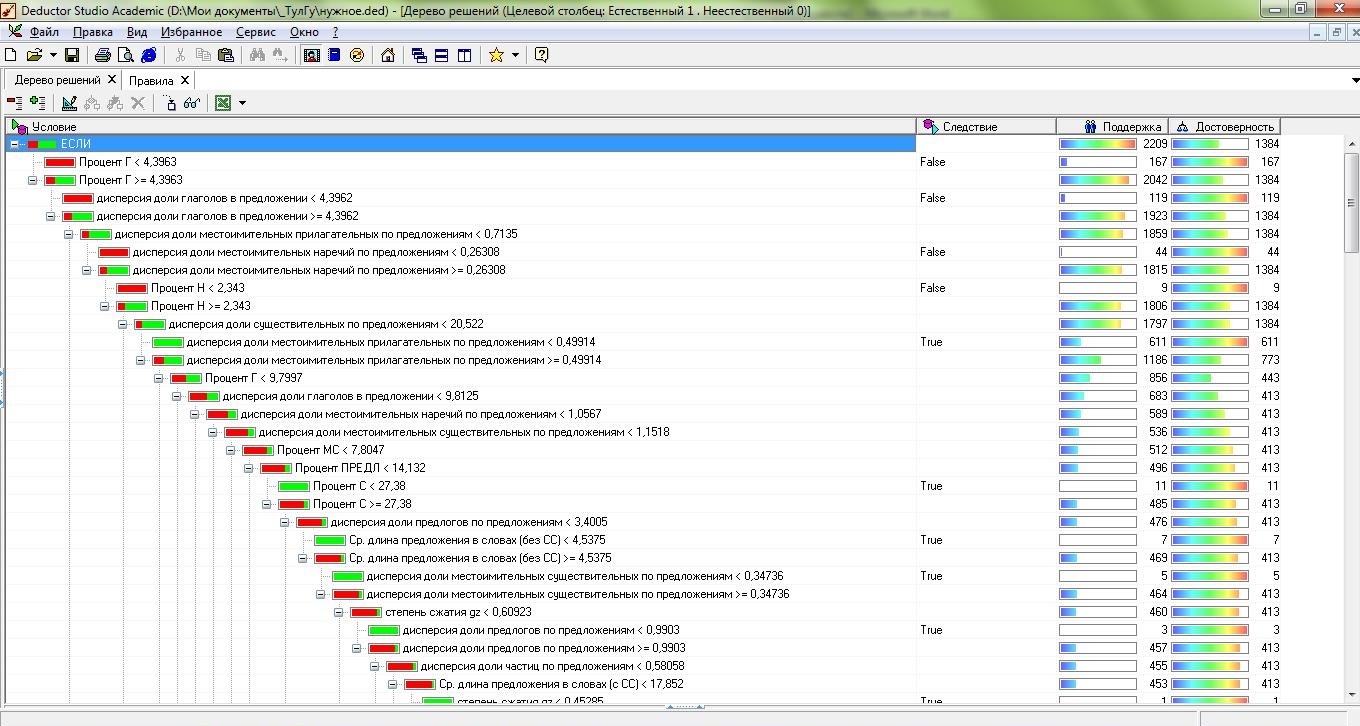
Рис. 8. Дерево решений. Аналитическая платформа Deductor 5.2.

Рис. 9. Результат работы программы по анализу текстов
На практике данный подход помог обнаружить причину отсутствия динамики по запросам. Программа обнаружила сгенерированные тексты на всех страницах категорий сайта. При расследовании было выяснено, что они представляют контент машинного перевода этого же сайта, но английской версии.
Рис. 10. Тексты на страницах категорий
После редактирования данных текстов даже только на продвигаемых страницах, была получена хорошая динамику: запросы из ТОП500 сразу попали в ТОП10 за 9 недель.
Рис. 11. Пример измененного текста.
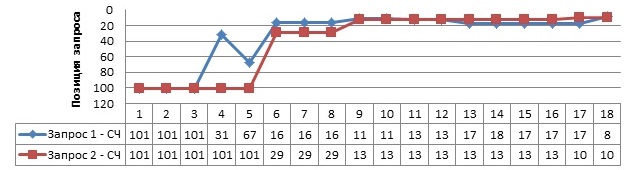
Рис. 12. Изменение позиций по неделям после выкладки.
В заключение необходимо отметить, что разработка рассмотренных функционалов — не обязательна! Она полезна при глобальных исследованиях поисковых машин. При продвижении сайта достаточно выработать подход, позволяющий точечно работать с запросами на основе анализа ТОПа. Для этого существует много естественных инструментов:
1) Проверьте, сколько по запросу релевантных страниц на сайте и сравните с конкурентами – сможете оценить текстовую полноту сайта
2) Обратите внимание на подсвеченные слова в многословных запросам в сохраненной копии – помощь при составлении текстов, на сколько далеко могут стоять друг от друга слова
3) Используйте язык запросов. Например, анализируя выдачу по точному запросу и без кавычек, можно выявить проблемы с текстовой составляющей
4) Через расширенный поиск ищите запрос по конкретным сайтам и анализируйте, какие страницы и почему выше продвигаемой
5) Результаты Вебмастера.Яндекса и Вебмастера.Гугл, данные метрики и GA также помогут выявить проблемы и провести работу с ними.
Целенаправленная деятельность по запросам всегда дает положительный результат.
Авторы статьи: Неелова Н.В. (к.т.н., руководитель отдела ПП Ingate), Поленова Е.А. (руководитель группы ПП Ingate).
