Комментарии 20
> таким образом вы обеспечите своему приложению минимум побочных эффектов, присущих императивному программированию
С этого момента, пожалуйста, поподробнее.
С этого момента, пожалуйста, поподробнее.
Предположим, в приложении используется база данных, к которой обращается сервисный уровень с запросами на предмет закешированной информации.
Из этой базы данных вычитывается некая сущность DBEntity. Соответствующий EntityService генерирует на её основании сущность Entity, которая не несёт с собой обвес из логики, доставшийся от NSManagedObject'a.
Затем Entity отправляется наверх, на уровни UI.
При недобросовестном подходе в эту сущность могут быть внесены изменения.
Таким образом, передавая её по цепочке между экранами, мы получаем ситуацию, когда данные «на руках» будут отличаться от тех, что записаны в БД. Более того, информация может не обладать необходимой консистентностью, которую изначально обеспечил EntityService, но которая впоследствии была нарушена недобросовестным разработчиком.
Есть несколько подходов к решению подобных проблем.
Во-первых, делать неизменяемые модельные объекты.
Во-вторых, не передавать их куда попало — об этом и сказано в статье.
Посудите сами, какое искушение: Entity изначально попадает на первый экран, там дорабатывается до необходимого состояния, затем отдаётся на второй экран.
Бывают такие ситуации? По неопытности — конечно, бывают.
Только вот тут же возникает зависимость экрана-2 от экрана-1 — отныне второй экран не может существовать отдельно от первого, ведь он ожидает «доработанные» данные.
Я привожу аналогию с побочными эффектами императивного программирования, потому что обрабатываемая сущность, казалось бы, одна и та же — а результат работы экрана может отличаться в зависимости от того, где эта сущность до этого побывала.
Из этой базы данных вычитывается некая сущность DBEntity. Соответствующий EntityService генерирует на её основании сущность Entity, которая не несёт с собой обвес из логики, доставшийся от NSManagedObject'a.
Затем Entity отправляется наверх, на уровни UI.
При недобросовестном подходе в эту сущность могут быть внесены изменения.
Таким образом, передавая её по цепочке между экранами, мы получаем ситуацию, когда данные «на руках» будут отличаться от тех, что записаны в БД. Более того, информация может не обладать необходимой консистентностью, которую изначально обеспечил EntityService, но которая впоследствии была нарушена недобросовестным разработчиком.
Есть несколько подходов к решению подобных проблем.
Во-первых, делать неизменяемые модельные объекты.
Во-вторых, не передавать их куда попало — об этом и сказано в статье.
Посудите сами, какое искушение: Entity изначально попадает на первый экран, там дорабатывается до необходимого состояния, затем отдаётся на второй экран.
Бывают такие ситуации? По неопытности — конечно, бывают.
Только вот тут же возникает зависимость экрана-2 от экрана-1 — отныне второй экран не может существовать отдельно от первого, ведь он ожидает «доработанные» данные.
Я привожу аналогию с побочными эффектами императивного программирования, потому что обрабатываемая сущность, казалось бы, одна и та же — а результат работы экрана может отличаться в зависимости от того, где эта сущность до этого побывала.
О побочных эффектах
Идея функционального программирования декларирует использование методов, результат работы которых детерминированно задаётся входными параметрами.
В ходе же работы императивной программы результат выполнения того или иного метода может зависеть ещё и от сторонних переменных, на состояние которых влияют внешние условия. Такие, как порядок выполнения предшествующих инструкций исходного кода, к примеру.
В ходе же работы императивной программы результат выполнения того или иного метода может зависеть ещё и от сторонних переменных, на состояние которых влияют внешние условия. Такие, как порядок выполнения предшествующих инструкций исходного кода, к примеру.
Второй экран ожидает определённый объект, что значит «доработанные» данные? Можете привести пример этих «недобросовестных» изменений?
Пример (слегка надуманный, но суть дела иллюстрирует):
Приложение — магазин для яхтсменов.
Экран-1 представляет собой список судоходных канатов.
Каждый канат — определённого типа и длины.
Длина в модельной сущности указана в миллиметрах.
Rope
+type: Enum;
+length: Real;
Когда пользователь выбирает один из заказов — открывается Экран-2 с детальной информацией.
От заказчика поступило указание сделать такое же приложение, но для США.
А в США длина измеряется в дюймах.
Нерадивый программист модернизирует Экран-1 так, что в модельной сущности поле длины перевычисляется так, чтобы на Экран-2 попадало значение в дюймах.
rope.length = rope.length / 25.4f; // TODO: Вынести «магию» в константы.
Но вот незадача: Экран-2 позволяет делать заказы, а для этого приложение отсылает соответствующий HTTP-запрос, и в запрос сериализуется эта самая модельная сущность.
В итоге сервер получает заказ на канат с неправильно рассчитанной длиной.
Приложение — магазин для яхтсменов.
Экран-1 представляет собой список судоходных канатов.
Каждый канат — определённого типа и длины.
Длина в модельной сущности указана в миллиметрах.
Rope
+type: Enum;
+length: Real;
Когда пользователь выбирает один из заказов — открывается Экран-2 с детальной информацией.
От заказчика поступило указание сделать такое же приложение, но для США.
А в США длина измеряется в дюймах.
Нерадивый программист модернизирует Экран-1 так, что в модельной сущности поле длины перевычисляется так, чтобы на Экран-2 попадало значение в дюймах.
rope.length = rope.length / 25.4f; // TODO: Вынести «магию» в константы.
Но вот незадача: Экран-2 позволяет делать заказы, а для этого приложение отсылает соответствующий HTTP-запрос, и в запрос сериализуется эта самая модельная сущность.
В итоге сервер получает заказ на канат с неправильно рассчитанной длиной.
BepTep, в прошлой статье в комментах вы отписали:
Все еще ждем.
Я думаю, следующая статья от меня так или иначе будет подробнее раскрывать эту архитектуру.
Этот подход используется практически на всех наших новых проектах («новый» — возраст от полугода), поэтому попросту описать один из них будет довольно легко.
Все еще ждем.
Не хотелось бы смешивать теорию с практикой — может получиться каша.
Так, в этой статье добавились недостающие элементы подхода проектирования — уровни представления.
В любом случае, благодарю за напоминание. С меня статья.
Благо, не так давно наши юристы дали добро на раскрытие некоторых деталей реализации… но это уже совсем другая история.
Так, в этой статье добавились недостающие элементы подхода проектирования — уровни представления.
В любом случае, благодарю за напоминание. С меня статья.
Благо, не так давно наши юристы дали добро на раскрытие некоторых деталей реализации… но это уже совсем другая история.
десяток классов-наследников RMRTableViewCell
Не лучше/проще ли уйти от наследования в сторону протоколов?
Во многом зависит от ситуации.
Если я правильно понял вопрос, Вы предлагаете использовать нечто, вроде шаблона «Стратегия»: ячейка будет предоставлять слот для алгоритма собственного заполнения.
Это удобно, когда в приложении для нескольких типов данных используется одно и то же представление.
Например, ячейка с заголовком, подзаголовком и пиктограммой — нечто универсальное.
Один и тот же класс представляет эту ячейку на Interface Builder'e, а необходимый алгоритм присваивается в зависимости от сущности, которую в ячейку нужно вписать.
В этом случае Вам всё равно понадобится десяток классов, каждый из которых будет следовать протоколу этого алгоритма заполнения. Т.е. Вы выигрываете за счёт вёрстки, но сущностей от этого меньше не станет.
И да, я бы не рекомендовал подобный подход. Универсальность — это благо, но только до определённого предела.
Часто бывает так, что вёрстка может разниться в зависимости от типа данных. Где-то мелкую иконку добавить, где-то заголовок сделать жирным, где-то ещё одно поле на экран вывести — море вариантов.
В этом случае создаются классы ячеек вместе с выделенной под них вёрсткой. Один класс — один layout. Таким образом, чисто с точки зрения информатики, мы не нагружаем один и тот же макет ответственностью за отрисовку различных типов данных, т.е. соблюдаем принцип единственной ответственности.
Да, существует правило о том, что композицию зачастую лучше использовать, чем наследование. Но в данном контексте подключается ещё и вопрос вёрстки, который смещает равновесие.
Надеюсь, я правильно понял Ваш вопрос.
Если я правильно понял вопрос, Вы предлагаете использовать нечто, вроде шаблона «Стратегия»: ячейка будет предоставлять слот для алгоритма собственного заполнения.
Это удобно, когда в приложении для нескольких типов данных используется одно и то же представление.
Например, ячейка с заголовком, подзаголовком и пиктограммой — нечто универсальное.
Один и тот же класс представляет эту ячейку на Interface Builder'e, а необходимый алгоритм присваивается в зависимости от сущности, которую в ячейку нужно вписать.
В этом случае Вам всё равно понадобится десяток классов, каждый из которых будет следовать протоколу этого алгоритма заполнения. Т.е. Вы выигрываете за счёт вёрстки, но сущностей от этого меньше не станет.
И да, я бы не рекомендовал подобный подход. Универсальность — это благо, но только до определённого предела.
Часто бывает так, что вёрстка может разниться в зависимости от типа данных. Где-то мелкую иконку добавить, где-то заголовок сделать жирным, где-то ещё одно поле на экран вывести — море вариантов.
В этом случае создаются классы ячеек вместе с выделенной под них вёрсткой. Один класс — один layout. Таким образом, чисто с точки зрения информатики, мы не нагружаем один и тот же макет ответственностью за отрисовку различных типов данных, т.е. соблюдаем принцип единственной ответственности.
Да, существует правило о том, что композицию зачастую лучше использовать, чем наследование. Но в данном контексте подключается ещё и вопрос вёрстки, который смещает равновесие.
Надеюсь, я правильно понял Ваш вопрос.
Надеюсь, я правильно понял Ваш вопрос.
Не совсем :)
Я имел ввиду некий протокол
@protocol DataObjectRenderer
- (void)reloadCellWithDataObject:(DataObject *)object;
@end
В таком случае нет прямой необходимости создавать базовый класс и ячейки (как и любые контролы) могут максимально абстрагироваться, декларируя только то, что они могут рендерить некий DataObject.
Кроме того, с таким подходом нас не интересует тип контрола: ячейка таблицы, ячейка коллекции, UIView, etc.
Наследование же привносит ненужную сложность и увеличивает связанность, имхо.
Ага, я понял.
Это действительно удобно, когда необходимо один и тот же объект отрисовывать несколькими способами.
По поводу ненужной сложности наследования позволю себе с Вами не согласиться: Ваш подход, фактически, предполагает то же самое, только «абстрактный» класс RMRTableViewCell заменяется на протокол DataObjectRenderer.
В то же время, мы получаем ситуацию, когда в исходном коде присутствует излишне абстрактная сущность (ячейка), следующая некоему протоколу.
На мой взгляд, это — возможный источник ошибок, ведь велико искушение на эту же ячейку навесить ещё несколько протоколов, чтобы она же отрисовывала и другие объекты.
Т.е. потенциально возрастает вероятность нарушения принципа единственной ответственности и разрастания класса.
Я — не сторонник писать слишком абстрактные вещи там, где можно ввести более строгую типизацию.
iOS SDK — абстрактен, и этого достаточно. А про «кричащий» архитектурный дизайн я написал ещё в статье.
Сужение абстракции в приложении — да, это ограничение, но оно ограждает нас от ошибок.
В то же время, рекомендую вспомнить принцип You Ain't Gonna Need It: действительно ли Вам необходимо объединять принципиально разные представления под эгидой одного протокола? Не будет ли это over-engineering'ом? Не придаёте ли Вы одному протоколу слишком много информационной значимости?
Решать Вам.
Это действительно удобно, когда необходимо один и тот же объект отрисовывать несколькими способами.
По поводу ненужной сложности наследования позволю себе с Вами не согласиться: Ваш подход, фактически, предполагает то же самое, только «абстрактный» класс RMRTableViewCell заменяется на протокол DataObjectRenderer.
В то же время, мы получаем ситуацию, когда в исходном коде присутствует излишне абстрактная сущность (ячейка), следующая некоему протоколу.
На мой взгляд, это — возможный источник ошибок, ведь велико искушение на эту же ячейку навесить ещё несколько протоколов, чтобы она же отрисовывала и другие объекты.
Т.е. потенциально возрастает вероятность нарушения принципа единственной ответственности и разрастания класса.
Я — не сторонник писать слишком абстрактные вещи там, где можно ввести более строгую типизацию.
iOS SDK — абстрактен, и этого достаточно. А про «кричащий» архитектурный дизайн я написал ещё в статье.
Сужение абстракции в приложении — да, это ограничение, но оно ограждает нас от ошибок.
В то же время, рекомендую вспомнить принцип You Ain't Gonna Need It: действительно ли Вам необходимо объединять принципиально разные представления под эгидой одного протокола? Не будет ли это over-engineering'ом? Не придаёте ли Вы одному протоколу слишком много информационной значимости?
Решать Вам.
Мне кажется обе наши точки зрения вполне валидны.
Дело в том, что я противник наследования в целом (ну кроме как от классов iOS SDK), потому как люди очень часто нарушают другой принцип — принцип подстановки Лисков.
Касательно нескольких протоколов для одной ячейки — да, может быть такая проблема, но наследование от нее тоже не защищает, имхо.
Главное дисциплина!
Дело в том, что я противник наследования в целом (ну кроме как от классов iOS SDK), потому как люди очень часто нарушают другой принцип — принцип подстановки Лисков.
Касательно нескольких протоколов для одной ячейки — да, может быть такая проблема, но наследование от нее тоже не защищает, имхо.
Главное дисциплина!
BepTep спасибо за статьи. Приятно видеть, что у вас есть процесс переноса знаний, практик и подходов между мобильными платформами. В большинстве проектов, где я участвовал команды были довольно обособленные, каждая со своим багажом и наработками. Поэтому в чужой монастырь со своим уставом мало кто рисковал ходить.
Приезжайте к нам в Университет Иннополис, будет интересно обсудить разработку архитектуры и другие практики программной инженерии. Мы вам расскажем как и чему мы учим студентов на курсе Architectures for Software Systems, а вы расскажете про то, что вы используете. Хочется быть ближе к индустрии, давать студентам востребованные знания, которые соответствуют методологиям из реального мира. Кстати, как вы отнесетесь к предложению прочитать гостевую лекцию?
Приезжайте к нам в Университет Иннополис, будет интересно обсудить разработку архитектуры и другие практики программной инженерии. Мы вам расскажем как и чему мы учим студентов на курсе Architectures for Software Systems, а вы расскажете про то, что вы используете. Хочется быть ближе к индустрии, давать студентам востребованные знания, которые соответствуют методологиям из реального мира. Кстати, как вы отнесетесь к предложению прочитать гостевую лекцию?
BepTep Спасибо за ваши посты! Очень интересно! Жду продолжения. Пожалуйста, ответьте на вопрос от начинающего. :) Вопрос относится к этой вашей иллюстрации:
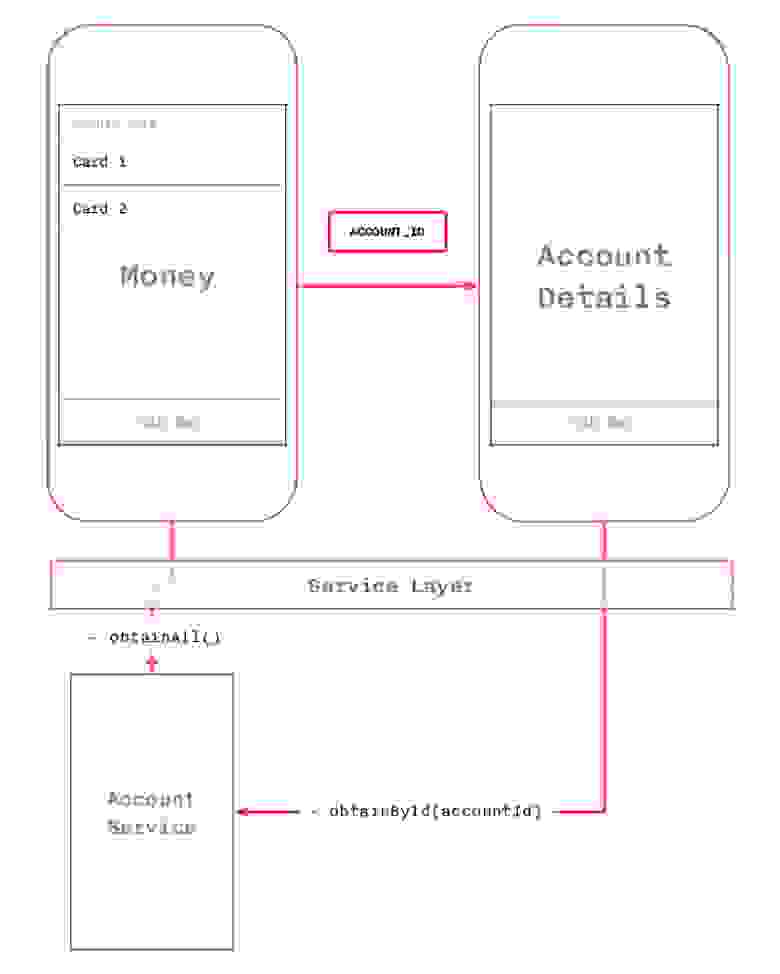
Правильно ли я понимаю, что подразумевается передача данных в методе prepareForSegue? Дело в том, что мне очень не нравится яблочный паттерн «сегвеев», но может быть, я чего-то не понимаю, а вы с вашим более обширным опытом как раз меня переубедите. :)
Смотрите сами (сорри только на свифте умею):
Недостаток 1: один метод на все случаи — с большим свичем внутри
Недостаток 2: первый VC должен знать не только конкретную имплементацию следующего (класс AccountDetailsViewController), но и уметь правильно его сетапить (accountId) — нарушена та самая обособленность контроллеров
Недостаток 3: на самом деле, элементарное поведение «перейти в AccountDetails» разбито на две части в совершенно разных местах контролера, так как помимо сниппета внутри prepareForSegue нам нужно было засетить selectedAccount внутри accessoryButtonTapped, и там же, собственно, вызвать performSegueWithIdentifier. Жуть!!! Код был бы гораздо читабельнее, если бы все это в одном месте, а именно accessoryButtonTapped
Недостаток 4: В обоих местах мы захардкодили одну и ту же стрингу с айдишником сегвея — плохо. Либо — что тоже плохо — мы загрязнили свой контроллер какой-то левой константой, которая де факто вообще не про этот контроллер, а про сториборд, в котором сидит его nib.
Все это мне кажется чрезмерной платой за
Достоинство 1: наглядная стрелочка в XCode с формочкой аттрибутов.
При этом, на самом деле в больших story это вовсе не наглядно, а превращается в стремное спагетти, особенно с суррогатными пустыми контроллерами из RBStoryboardLink. :)
Как быть?? Я предлагаю как раз между контроллерами и Service Layer вместить еще один слой делегатов, отвечающий за правильную настройку переходов:
Таким образом, снимаем груз ответственности с первого VC, делая его по-настоящему обособленным: все, что он должен уметь — это показать список аккаунтов и дернуть делегат в нужный момент, мол, юзер хочет видеть details. Как вы думаете, такой подход имеет право быть?
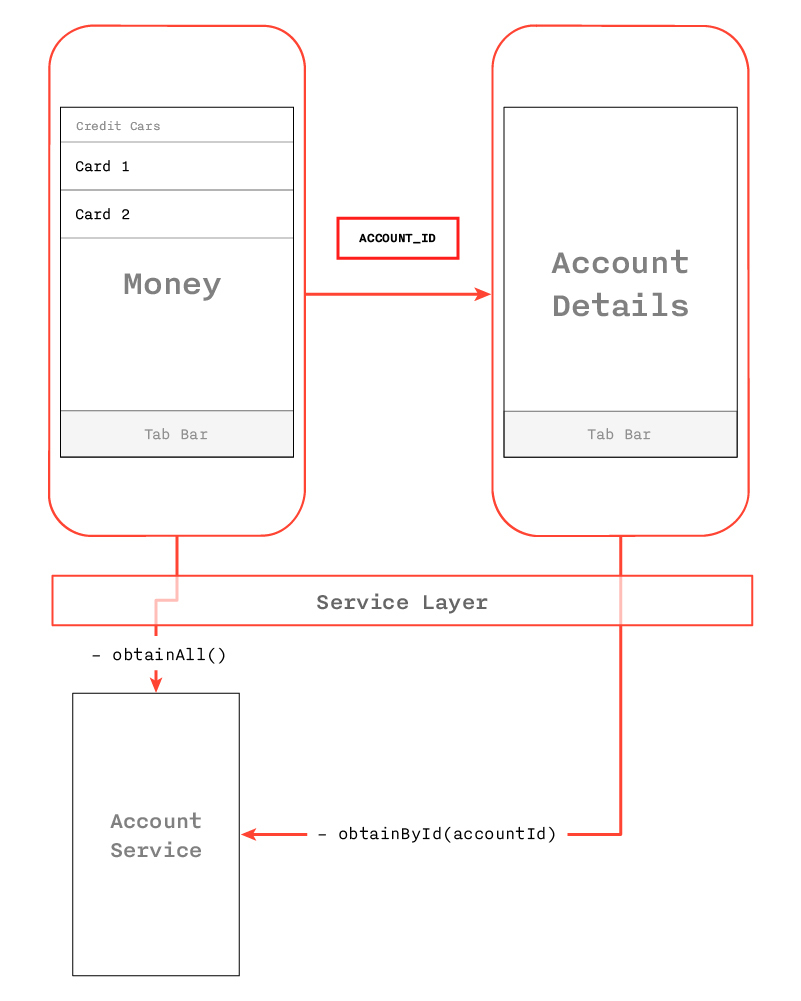
Правильно ли я понимаю, что подразумевается передача данных в методе prepareForSegue? Дело в том, что мне очень не нравится яблочный паттерн «сегвеев», но может быть, я чего-то не понимаю, а вы с вашим более обширным опытом как раз меня переубедите. :)
Смотрите сами (сорри только на свифте умею):
override func prepareForSegue(segue: UIStoryboardSegue, sender: AnyObject?) {
switch segue.identifier! {
case "showAccountDetails":
let vc = segue.destinationViewController as AccountDetailsViewController
vc.accountId = self.selectedAccount.accountId
...
}
}
Недостаток 1: один метод на все случаи — с большим свичем внутри
Недостаток 2: первый VC должен знать не только конкретную имплементацию следующего (класс AccountDetailsViewController), но и уметь правильно его сетапить (accountId) — нарушена та самая обособленность контроллеров
Недостаток 3: на самом деле, элементарное поведение «перейти в AccountDetails» разбито на две части в совершенно разных местах контролера, так как помимо сниппета внутри prepareForSegue нам нужно было засетить selectedAccount внутри accessoryButtonTapped, и там же, собственно, вызвать performSegueWithIdentifier. Жуть!!! Код был бы гораздо читабельнее, если бы все это в одном месте, а именно accessoryButtonTapped
Недостаток 4: В обоих местах мы захардкодили одну и ту же стрингу с айдишником сегвея — плохо. Либо — что тоже плохо — мы загрязнили свой контроллер какой-то левой константой, которая де факто вообще не про этот контроллер, а про сториборд, в котором сидит его nib.
Все это мне кажется чрезмерной платой за
Достоинство 1: наглядная стрелочка в XCode с формочкой аттрибутов.
При этом, на самом деле в больших story это вовсе не наглядно, а превращается в стремное спагетти, особенно с суррогатными пустыми контроллерами из RBStoryboardLink. :)
Как быть?? Я предлагаю как раз между контроллерами и Service Layer вместить еще один слой делегатов, отвечающий за правильную настройку переходов:
func tableView(tableView: UITableView, accessoryButtonTappedForRowWithIndexPath indexPath: NSIndexPath) {
delegate.didRequestDetailsForAccount(accounts[indexPath.row])
}
Таким образом, снимаем груз ответственности с первого VC, делая его по-настоящему обособленным: все, что он должен уметь — это показать список аккаунтов и дернуть делегат в нужный момент, мол, юзер хочет видеть details. Как вы думаете, такой подход имеет право быть?
Этот подход не просто имеет право быть — он обязан быть.
Другой вопрос: как это корректно организовать?
Обратите внимание, в конце предыдущей статьи я упоминал архитектурный шаблон VIPER, в рамках которого самый интересный элемент (на мой взгляд) — это непосредственно Router, т.е. сущность (или сущности), ответственная за навигацию по приложению.
Существует несколько наработок по этому поводу (включая предложенный способ конечного автомата). Если получится сделать из них что-то действительно стройное — обязательно напишу по этому поводу статью.
Главное опасение касательно данной задачи заключается в том, что сущность Router может быстро разрастись и покрыться методами, которые без рефакторинга будет невозможно реиспользовать.
В то же время, другая проблема — это over-engineering, вероятность попросту довести абстракцию до такого уровня, на котором её будет сложно понять.
Кстати, введение подобного элемента в дизайн исходного кода никак не конфликтует с Достоинством 1.
И да, небольшой, но интересный момент.
Обратите внимание, как именуются «делегаты» на платформе Android:
А что может Вам сказать название «delegate» — объект типа UITextFieldDelegate?
Если Вы не знакомы с iOS SDK — то ничего оно Вам не скажет.
В противовес, небольшой пример в рамках Вашего кода:
И последнее.
Спасибо за вопрос. Проблема довольно насущная.
Другой вопрос: как это корректно организовать?
Обратите внимание, в конце предыдущей статьи я упоминал архитектурный шаблон VIPER, в рамках которого самый интересный элемент (на мой взгляд) — это непосредственно Router, т.е. сущность (или сущности), ответственная за навигацию по приложению.
Существует несколько наработок по этому поводу (включая предложенный способ конечного автомата). Если получится сделать из них что-то действительно стройное — обязательно напишу по этому поводу статью.
Главное опасение касательно данной задачи заключается в том, что сущность Router может быстро разрастись и покрыться методами, которые без рефакторинга будет невозможно реиспользовать.
В то же время, другая проблема — это over-engineering, вероятность попросту довести абстракцию до такого уровня, на котором её будет сложно понять.
Кстати, введение подобного элемента в дизайн исходного кода никак не конфликтует с Достоинством 1.
И да, небольшой, но интересный момент.
Обратите внимание, как именуются «делегаты» на платформе Android:
OnItemClickListener
OnScrollListener
OnTouchListenerА что может Вам сказать название «delegate» — объект типа UITextFieldDelegate?
Если Вы не знакомы с iOS SDK — то ничего оно Вам не скажет.
В противовес, небольшой пример в рамках Вашего кода:
func tableView(tableView: UITableView, accessoryButtonTappedForRowWithIndexPath indexPath: NSIndexPath) {
router.navigateToAccountDetails(accounts[indexPath.row])
}И последнее.
Недостаток 4: В обоих местах мы захардкодили одну и ту же стрингу с айдишником сегвея — плохо. Либо — что тоже плохо — мы загрязнили свой контроллер какой-то левой константой, которая де факто вообще не про этот контроллер, а про сториборд, в котором сидит его nib.Небольшой спойлер-наводка: попробуйте использовать утилиты, которые будут генерировать и собирать константы на основании файлов вёрстки — таким образом Вы избавитесь от дублирования средствами автоматизации.
Спасибо за вопрос. Проблема довольно насущная.
Спасибо за развернутый ответ!
Вы навели меня на VIPER, теперь изучаю этот подход. К сожалению, он довольно молодой, все статьи в гугле не старше года-двух, и материалов действительно очень мало, в особенности — конкретных примеров.
Вы навели меня на VIPER, теперь изучаю этот подход. К сожалению, он довольно молодой, все статьи в гугле не старше года-двух, и материалов действительно очень мало, в особенности — конкретных примеров.
Мы недавно проводили изучение архитектуры VIPER и пришли к выводу, что она несколько недоработана. Основная проблема заключается как раз-таки в слое Router. Единственное(?) решение, которое действительно позволит соблюсти все принципы, это отказ от Storyboard (ну или как минимум отказ от Segues). На мой взгляд, это будет шаг назад, т.к. Storyboards и Segues во многих случаях очень удобны и наглядны. У меня есть наработки по вытаскиванию всей логики переходов в отдельный слой (контроллеры все так же ловят сегвеи, но сразу же передают их в Router через Presenter). К сожалению, какого-то адекватного законченного решения пока нет. Так как это наша первая попытка реализации слоистой архитектуры, вся система показалась нам довольно громоздкой и мы не увидели каких-то радикальных преимуществ. Ну и смущает отсутствие каких-то внятных примеров реализации (пара-тройка демо-приложений с одним-двумя экранами не в счет), а также многозначительное молчание со стороны авторов подхода.
Гораздо более удачной оказалась комбинация различных подходов: MVCP, MVVM, SOA. Как только мы отвязались от жесткого следования структуре VIPER, большинство возникших проблем исчезли сами собой.
Гораздо более удачной оказалась комбинация различных подходов: MVCP, MVVM, SOA. Как только мы отвязались от жесткого следования структуре VIPER, большинство возникших проблем исчезли сами собой.
Первое ограничение, которое у себя ввели Android-коллеги — это неспособность передавать сложные объекты между контроллерами (activity) — для этого дополнительно необходимо обеспечить сериализацию этих объектов.
каждый контроллер должен быть максимально обособленным
Вы здесь связали два несвязанных принципа. То, что нельзя передавать сложные объекты предварительно не реализовав сериализацию, не является посылом к максимальной обособленности контроллеров.
Данные простых типов (String, Integer и т.д) тоже сериализуются при передаче между Activity. Просто о серилизации простых типов подумали разработчики Android, а о кастомных (сложных) типах должен позаботиться разработчик.
Правильным посылом к максимальной обособленности контроллеров, как мне кажется, является принцип вызова Activity через Intent.
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Архитектурный дизайн мобильных приложений: часть 2