Комментарии 44
Добрый день, спасибо за статью. Не могли бы вы пояснить вот что. Корни бренда "Райффайзенбанк" исходят, если я не ошибаюсь, из Австрии. В связи с этим не вполне ясно, в какой мере российское отделение связано с австрийским?
И, как следствие, описанное в статье относится исключительно к российскому отделению банка, или ко всей полноте, независимо от страны?
АО «Райффайзенбанк» является российским акционерным обществом, зарегистрированным в России и действующим на территории России. При этом наш единственный акционер — австрийский Raiiffeisen Bank International. Описанное в статье относится исключельно к российскому Райффайзенбанку.
Ага, таким образом у австрийцев какие-то свои технологии? Взаимодействовали ли с ними, консультировались ли?
То есть понимаете, у австрийцев нет ритейла, они — не универсальный банк. При этом в масштабе всей банковской группы RBI в России самый большой банк по всем показателям. Поэтому задачи, которые перед нами стоят — уникальные в масштабе группы RBI.
Хотя в целом обмен опытом есть, и я не исключаю, что наши решения и опыт, если они хорошо себя зарекомендуют тут, будут тиражироваться на остальные банки группы.
И насколько мне известно, каких-то особых своих технологий у австрийцев нет, с Open Source'ом нет желания тягаться ни у кого;)
Плюс нам предоставлена достаточно большая свобода в принятии решений, мы вполне можем сами решить, куда развиваться.
А можно встречный вопрос — вы себе наше взаимодействие с Австрией представляли по-другому? Чего ожидали?
Честно говоря я не очень знаком с принципами работы международных организаций такого масштаба. Судя по вашему ответу я себе также иначе представлял деятельность вашего банка в целом, я почему-то думал, что его деятельность в целом одинакова во всех странах. Просто мне показалось странным, что столь масштабный проект делается филиалом, и стало интересно, как в этом участвует головная организация.
Я как-то думал, что вот есть головная организация в Австрии, а по другим странам распределены филиалы. Головная организация помимо основных задач, также разрабатывает ПО, а потом филиалы его у себя внедряют. Как-то не приходило в голову, что филиал будет такими амбициозными проектами заниматься отдельно от остальных. Но благодаря вашим пояснениям о роде деятельности RBI, и что услуги конечным пользователям они не предоставляют, стало яснее.
Причем в европейских банках законодательство плюс/минус похожее, правила бухучета не меняются уже много лет, поэтому коробочных решений из Австрии больше.
А у нас все-таки национальная специфика, не каждое коробочное решение оттуда нам подойдет.
Плюс согласен, логотип у нас у всех общий, это вводит в заблуждение.
Когда кто-то в Австрии видит желто-черный логотип, думают, что это одно и то же:

На самом деле, если дело происходит в Австрии, то скорее всего вы видите один из земельных банков Райффайзен, тех, с которых все начиналось. Они владеют 59% акций Raiffeisen Bank International (остальной 41% акций находится в свободном обороте и торгуется на венской бирже), который сам по себе ведет корпоративный и инвестиционный бизнес, и является в свою очередь акционером всех банков за пределами Австрии, включая российский Райффайзенбанк.
Ой, как у вас всё сложно-то оказывается. Все друг-другу принадлежат.
P.S. Признайтесь, вы специально выбирали фото, соответствующее стереотипным австрийским улочкам, чего только повозка с тыквами стоит? :)
Думаю, не ошибусь, если скажу, что задачи решаемые ВТБ24 несколько объёмнее, чем у головы…
что задачи решаемые ВТБ24 несколько объёмнее, чем у головы
Так ВТБ24 вроде как не голова, голова как раз просто ВТБ, а которая с 24, это для конечных клиентов сервис. Про БМ не знал, что они теперь у ВТБ, никогда их на улицах не видел. Впрочем, я не из Москвы.
Но оно и понятно, похоже практически любая сложная организация имеет хитрую структуру.
А я не москвич, так что с достопримечательностями вашего метро не знаком. У нас есть свой "городской банк", но насколько я знаю, он сам по себе.
Ой, как у вас всё сложно-то оказывается.
Хочется ответить такой картинкой:)

2. входные данные AVRO, это json/avro, не paquet/avro? источники сами занимаются ETL в avro?
3. для доступа используете Hive и Spark, а Hive с которым движком? Nez, MR, может тоже Spark?
1. Про Spark Streaming — да, мы пока в процессе вывода в прод, на тестах зарекомендовал себя хорошо. И цели, для которых мы используем Spark Streaming — realtime аналитика, это не настолько критичный сервис, чтобы было страшно;)
2. Не совсем понял вопрос. Данные берем из реляционных баз данных, в AVRO преобразует Scoop.
3. Для Hive используем Tez, т.к. он идет в поставке Hortonworks.
Что касается реальных кейсов и того, кто что про них говорит.
Как показывают мои личные наблюдения, если кто-то о чем-то молчит, это не всегда значит, что он ничего не делает. И наоборот, если кто-то говорит о чем-то вслух, это не всегда значит, что так оно и есть.
Я в начале статьи сообщил, что текст будет про технологии. Мне такой уровень изложения показался более оптимальным, чем выкладывать конфиги и скриншоты.
Реальный кейс я тоже упомянул один — ежедневный прогноз на базе машинного обучения спроса на снятие наличных в банкоматах и оптимизация работы службы инкассации.
Есть и другие.
Но тут я хочу привести одну аналогию. В начале 20 века во многих международных журналах по физике энтузиасты охотно делились исследованиями по ядерной физике, проникая вглубь атома. А потом эти публикации резко пропали. Потому что все осознали, что кто первый научится управлять ядерной реакцией, тот получит весомый аргумент в разговорах на мировой арене. Как показывает история, так в итоге и получилось.
То же самое и с реальными кейсами по биг дате. Многие из них очень легко можно воссоздать по малейшей подсказке и они приносят слишком много пользы, чтобы о них можно было открыто говорить.
выбрали Hortonworks, потому что его дистрибутив не содерджит проприетарных компонентов.CDH тоже не содержит. За пределами HDP и CDH у обеих компаний есть не-opensource продукты.
К тому же, у Hortonworks из коробки доступна 2-я версия Spark, а у Cloudera – только 1.6.Spark2 в CDH тоже есть. Он устанавливается отдельным пакетом.
1. Что есть на рынке? Почитали интернет, почитали Гартнера, определились: Horton или Cloudera, MapR не рассматривали.
2. Как у них все устроено? Cloudera — есть EDH, есть Analytic DB, есть Operational DB… Ну хорошо, как насчет EDH.
3. Сразу же натыкаешься на 60-дневный триал для Cloudera Enterprise, полностьб бесплатный только Cloudera Express. Ну хорошо, допустим. А что там есть в нем?
4. Идем на страницу версий, видим там только Spark 1.6. И тут возникает вопрос — если мы покупаем у них лицензию, нам нужна от них поддержка. Будет ли она оказываться, если мы те компоненты, которые у них идут в поставке, будет апгрейдить на другие компоненты, которые у них не описаны?
С Horton все проще. Качаешь HDP и все. Хочешь поддержку — покупаешь. Не хочешь — не покупаешь. Никаких триалов. Там уже в 2016 году был HDP 2.5, в котором был Spark 2.0. Скачали, начали использовать, не жалеем.
Сейчас конечно разобраться с Cloudera не составило бы труда, но тогда ход мыслей был таким и цепочка случайностей именно такая.
Плюс сейчас появился HDF, мы его тоже используем.
Ибо текущеее мягко говоря не катит по сравнению с конкурентами.
А то ради пополнения с2с постоянно проиходится лезть в мобильный браузер потому что шаблоны из ИБ в МБ не подгягиваются :)
Мой ответ будет состоять из двух частей.
Часть первая, философская. Раньше человек, который работал на компьютере, назывался «Оператор ЭВМ» и умел справляться с любой задачей, от набивки перфокарт до замены высохшего конденсатора. По мере того, как технологии усложнялись, а требования к скорости разработки ужесточались, возникло разделение на специализации. В этой связи мы бы и рады помочь коллегам с мобильным приложением, но боюсь, если мы, привыкшие работать с Hadoop и Spark, начнем всесто них допиливать мобильное приложение, мы еще сильнее отстанем от конкурентов=)
Что касается второй части, практической. Наши коллеги, которые знают толк в мобильной разработке, уже работают над новым приложением. Обещаю, если им понадобится, мы всей биг датой придем им на помощь, чтобы приблизить долгожданный релиз.
Подписывайтесь на наш блог, чтобы быть в курсе и узнать одними из первых ;)
— У меня 258 часов разработки… Считаю что это не правильно. В итоге сроки срывались, а по шапке довали разработчикам.
А в целом Райфу просто не везет с мобильными разработчиками, но надо отдать должное условия они создают отличные для работы. Нужен мак, купят мак. Нужно два, купят два.
А так сколько читаю статей про Big Data (в наших росс реалиях) понимаю что это все в угоду целям IT директорам ну и нам для сатисфакции инженерных амбиций (интересов) в новых технологиях.
А какие претенденты на роль Self-Service BI рассматриваете?
Нужно сделать важную оговорку, какой класс задач мы планируем отдавать на Self-Service BI.
У нас есть достаточно большое количество однотипных задач, суть которых сводится к тому, чтобы получить исторические данные (возможно, сджойнив несколько таблиц), группировать, покрутить в Pivot, аггрегировать, вывести результат, оформить или в виде таблицы, или в виде графика.
Сейчас такие отчеты разрабатывает отдельная ИТ команда.
Вот от таких задач мы могли бы эту команду разгрузить, дав польльзователям возможность управляться самим.
Прикол в том, что пользователи и сами умеют делать такие вещи в Excel, пересадить их на другое средство, которое не похоже на то, с чем они привыкли работать, достаточно сложно и не гуманно. И поэтому требование к такому инструменту — чтобы он был похож на Excel.
Поэтому в первую очередь смотрим на… MS Power BI. А там поглядим.
Ну и более сложные задачи, например, посчитать финансовые потоки, применить сглаживание, экстраполяцию, мы не будем пытаться решать с помощью Self-Service BI, потому что есть негативный опыт, связанный со сложностью отладки и трудоемкостью выявления ошибок.
В том-то и дело, что нельзя сказать, что где-то болело. Банк жил до определенного момента в своей реляционной парадигме, нагрузка была в пределах нормы, business as usual. Пожалуй, первыми, от кого пришел тревожный сигнал, что это стратегическое направление не развивалось, была Enterprise Архитектура, т.е. ИТ.
Зашевелились, начали обсуждать, породили хайп. Хайп подхватило Правление, почти одновременно Big Data попала в документ «Стратегия развития ИТ-2020», без конкретики, какую задачу решаем.
Дальше сыграли два фактора — высокая самоорганизация и свобода принятия решений на локальном уровне. Сами себе придумали Data Lake. По мере того, как он вызревал, архитектура начала позиционировать на него отдельные задачки. Так у нас появились первые заказчики. Параллельно ходили продавали решение бизнесу сами.
Сейчас имеем в клиентах Retail, в потенциальных клиентах — Risk Management, Compliance. Основное, что привлекает:
1. Низкое TCO по сравнению с коммерческими продуктами по хранению и обработке данных
2. Python — возможности по сравнению с коммерческими продуктами по анализу данных
3. Возможность анализировать данные с минимальной задержкой, вплоть до онлайн
4. Возможность хранить и анализировать неструктурированные данные
Знаю, что в разных умных статьях говорится, что если у Big Data-проекта, помимо всего прочего, изначально нет бизнес-заказчика и решаемой проблемы, то такой проект обречен на провал, но нам удалось пока избежать этой участи;)
P.S. Спасибо за вашу оценку мобильному приложению.
У них шаблоны из ИБ не подтягиваются в МБ.
Иногда есть отвалы кодов из PUSH уведомлений
Дизайн середина двухтысячных )
Даже вход по отпечатку странный
Чуть сместишь палец на экран и вход слетает, приходится снова на иконку отпечатка тапать
Учёт расходов не работает в МБ без подключенных СМС — О_о
Шаблоны МБ отдельно, ИБ отдельно
В ИБ глюк при заходе через браузер Opera начальную страницу корежит, но потом вроде всё норм
Пополение с карт другого банка не поддерживает ни NFC сканирование ни фотографирование карты :)

Но чтобы повысить привлекательность, пиарологи-маркетеры придумали название «экосистема» =)
А ещё подумалось, что с учётом нынешнего разнообразия типов данных, требуемых скоростей и сложности решаемых задач, если бы существовала одна, «стандартная» система для Big Data, она была бы слишком дорогой, слишком сложной и слишком не гибкой.
Так что то, что изображено на рисунке, это вполне натуральная эволюционная ситуация.
1. Big Data. Вы уже перешли к продуктивному использованию? Или это все еще тестовый вариант. Я когда год назад в рамках подряда с Вами работал. Все было еще только в планах. Можно сказать даже не на бумаге. А в силу достаточно сложной архитектуры. Все это перевести в прод… Пожалуй на грани фантастики
2. На сколько успешно и трудозатратно проходила у Вас миграция SAS продуктов. Так как сейчас это пожалуй один из наиболее интересных продуктов в банковских секторах. FPS GRS MA.
1. Мы перешли к продуктивному использованию с начала июня, точнее, первые пилотные проекты (два) сейчас в продуктивной среде проходят так называемый стабилизационный период. Да, действительно, год назад все было не так. Почти никак. Действительно, архитектура в крупных банках как правило не отличается простотой, но на нас это фактически никак не влияло, мы же новый продукт внедряем с нуля (без костылей и технического долга=), и совокупная сложность ИТ-ландшафта на нас особо не влияла. Много времени ушло на изучение. По мере того, как стали набивать руку, определились с количеством серверов и где какие компоненты размещать, взяв за основу предлагаемую вендором архитектуру:
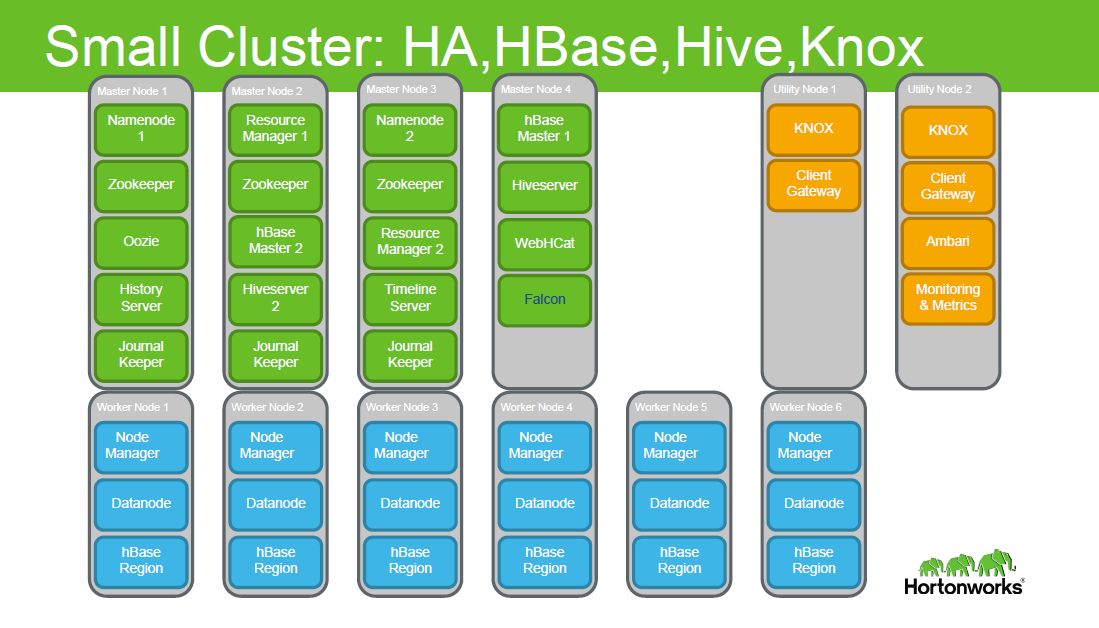
Создали сервера, убедились в работоспособности.
Пришлось помучиться со Scoop, он долго не хотел сохранять файлы в Avro.
Пришлось допилить Oozie, т.к. он умеет запускаться либо по таймеру, либо работая с файловой системой HDFS, а нам нужно было запускать джобы по событиям во внешних системах.
Для вывода такой конфигурации в Прод даже полгода более чем достаточно при наличии опыта. Впрочем, мы отдаем себе отчет в том, что нашему Data Lake'у еще очень далеко от законченного вида и нужно как наполнять его данными, так и добавлять новые продуктовые фичи.
2. По поводу миграции не очень понятно. Да, мы используем продукты SAS, но мы с них никуда не мигировали. имелась в виду миграция на них, т.е. их внедрение?
Что касается Oracle, есть аналогичные мысли посмотреть «Oracle Big Data Connector» и попробовать поискать, где это может быть применимо.
Big Data в Райффайзенбанке