Всем привет!
Меня зовут Лидия, я тимлид небольшой DataScience-команды в QIWI.
Мы с ребятами довольно часто сталкиваемся с задачей исследования потребностей клиентов, и в этом посте мне бы хотелось поделиться мыслями о том, как начать тему с сегментацией и какие подходы могут помочь разобраться в море неразмеченных данных.
Кого сейчас удивишь персонализацией? Отсутствие персональных предложений в продукте или сервисе уже кажется моветоном, и мы ждем те самые, отобранные только для нас, сливки везде – от ленты в Instagram до личного тарифного плана.
Однако, откуда берется тот самый контент или предложение? Если вы впервые погружаетесь в темные воды машинного обучения, то наверняка столкнетесь с вопросом – с чего начать и как выявить те самые интересы клиента. Чаще всего при наличии большой базы пользователей и отсутствии знаний об оных возникает желание пойти по двум популярным путям:
1. Разметить вручную выборку пользователей и обучить на ней модель, которая позволит определять принадлежность к этому классу или классам – в случае мультиклассового таргета.
Вариант неплохой, но на начальном этапе может заманить в ловушку – ведь мы еще не знаем, какие в принципе сегменты у нас есть и насколько они будут полезны для продвижения новых продуктовых фич, коммуникаций и прочего. Не говоря уже о том, что ручная разметка клиентов – дело достаточно затратное и иногда непростое, ведь чем больше у вас сервисов, тем большее количество данных нужно просмотреть для понимания, чем живет и дышит этот клиент. Большая вероятность, что получится нечто такое:

2. Обжегшись на варианте #1, часто выбирают вариант unsupervised-анализа без обучающей выборки.
Если оставить за бортом шутки про эффективность kmeans, то можно отметить один важный момент, объединяющий все методы кластеризации без обучения – они просто позволяют вам объединить клиентов на основании близости по выбранным метрикам. Например, количеству покупок, числу дней жизни, балансу и другому.
Это тоже может быть полезно в случае, если вы хотите разделить вашу аудиторию на крупные группы и затем изучать каждую, либо выделить ядро и отстающие по продуктовым метрикам сегменты.
Например, в двумерном пространстве полезный результат может выглядеть следующим образом — сразу видно, какие кластеры стоит исследовать более детально.

Но чем больше метрик вы использовали для кластеризации, тем сложнее будет интерпретировать результат. И те самые предпочтения клиента все еще покрыты тайной.
Что же делать, вот вопрос? В QIWI мы не раз ломали голову над этой дилеммой, пока не пришли к любопытной модели, навеянной этой статьей. Среди прочих кейсов в статье рассказывалось о решении от Константина Воронцова для выделения латентных паттернов поведения пользователей банковских карт на базе библиотеки BigARTM.
Суть такова – транзакции клиента представлялись как набор слов и затем из полученной текстовой коллекции, где документ = клиенту, а слова = MCC-кодам (merchant category код, международная классификация торговых точек), выделялись текстовые тематики при помощи одного из инструментов Natural Language Processing (NLP) — тематического моделирования .
В нашем исполнении pipeline выглядит так:

Звучит абсолютно естественно – если мы хотим понять, чем и как живет наша аудитория, почему бы и не представить действия, которые клиенты совершают внутри нашей экосистемы, как историю, ими рассказанную. И составить путеводитель по тематикам этих историй.
Несмотря на то, что концепция выглядит изящно и просто, на практике при реализации модели пришлось столкнуться с несколькими проблемами:
Для первой проблемы решение нашлось довольно легко – все крупные клиенты были разделены простейшим классификатором на «ядро» и «звезд» (см. картинку выше) и уже каждый из кластеров обрабатывался как отдельная текстовая коллекция.
А вот второй и третий пункт заставили задуматься – действительно, как валидировать результаты обучения без обучающей выборки? Конечно, есть метрики качества модели, но, кажется, что их недостаточно – и именно поэтому мы решили сделать очень простую вещь – проверить результаты на тех же исходных данных.
Выглядит эта проверка следующим образом: результатом классификации является набор тематик, например, вот такой:

Здесь питоновский список – это набор самых вероятных ключевых MCC-категорий покупок для данной темы (из матрицы «слово – тематика»). Если посмотреть отдельно на покупки в категории airlines and air carriers, вполне логично, что клиенты с темой «путешественники» будут составлять основную долю ее пользователей.

И эту проверку удобно реализовать в виде дашборда – заодно у вас появится наглядный материал для генерации продуктовых гипотез – кому кэшбэк на авиабилеты, а кому скидку на кофе.
А еще в коллекции для тематического моделирования можно добавить не только транзакционные события, но и мета информацию из других моделей, тематики обращений в клиентскую поддержку и многое другое. Или использовать в качестве категориальных фич для supervised-алгоритмов – например, моделей предсказания оттока и прочее.
Конечно, в таком подходе есть свои нюансы – например, коллекция обрабатывается как bag of words и порядок покупок не учитывается, но его вполне можно компенсировать использованием N грамм или расчетом тематических меток на каждый значимый период жизни клиента (каждый месяц, например). Однако, сама идея читабельной и интерпретируемой истории о клиентах, комбинации NLP и других моделей кажется нам очень привлекательной.
А как вам эта тема? С какими сложностями или радостями сегментации сталкивается ваша data science команда? Будет интересно узнать ваше мнение.
Меня зовут Лидия, я тимлид небольшой DataScience-команды в QIWI.
Мы с ребятами довольно часто сталкиваемся с задачей исследования потребностей клиентов, и в этом посте мне бы хотелось поделиться мыслями о том, как начать тему с сегментацией и какие подходы могут помочь разобраться в море неразмеченных данных.
Кого сейчас удивишь персонализацией? Отсутствие персональных предложений в продукте или сервисе уже кажется моветоном, и мы ждем те самые, отобранные только для нас, сливки везде – от ленты в Instagram до личного тарифного плана.
Однако, откуда берется тот самый контент или предложение? Если вы впервые погружаетесь в темные воды машинного обучения, то наверняка столкнетесь с вопросом – с чего начать и как выявить те самые интересы клиента. Чаще всего при наличии большой базы пользователей и отсутствии знаний об оных возникает желание пойти по двум популярным путям:
1. Разметить вручную выборку пользователей и обучить на ней модель, которая позволит определять принадлежность к этому классу или классам – в случае мультиклассового таргета.
Вариант неплохой, но на начальном этапе может заманить в ловушку – ведь мы еще не знаем, какие в принципе сегменты у нас есть и насколько они будут полезны для продвижения новых продуктовых фич, коммуникаций и прочего. Не говоря уже о том, что ручная разметка клиентов – дело достаточно затратное и иногда непростое, ведь чем больше у вас сервисов, тем большее количество данных нужно просмотреть для понимания, чем живет и дышит этот клиент. Большая вероятность, что получится нечто такое:
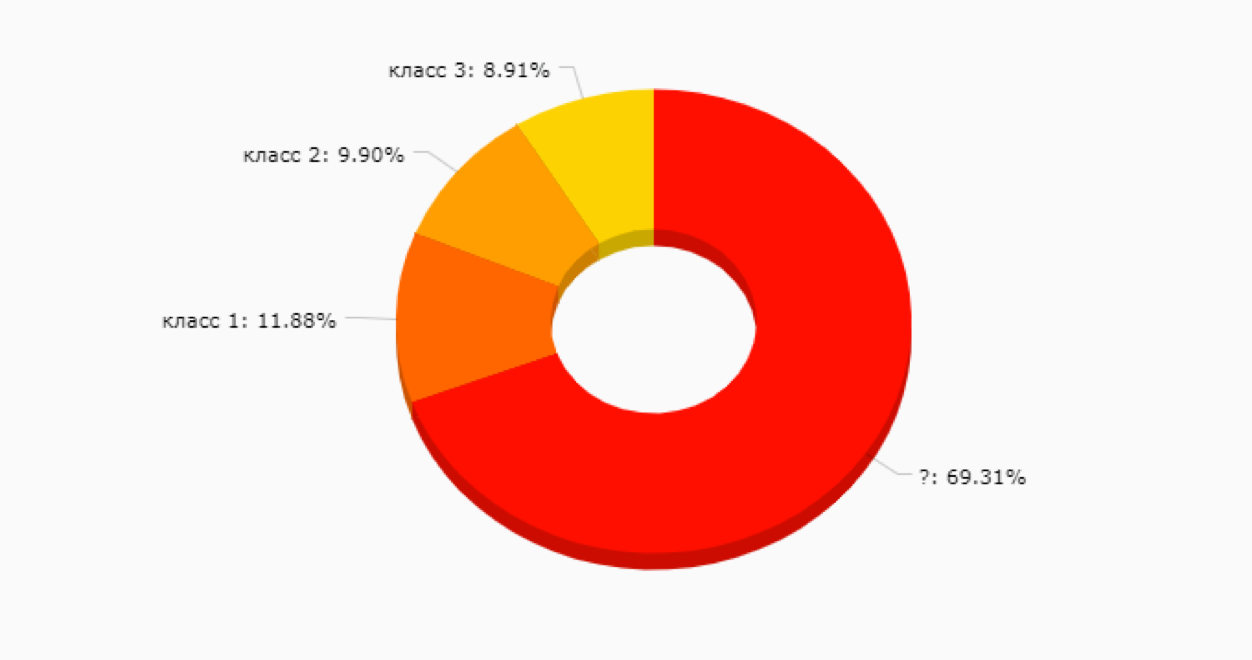
2. Обжегшись на варианте #1, часто выбирают вариант unsupervised-анализа без обучающей выборки.
Если оставить за бортом шутки про эффективность kmeans, то можно отметить один важный момент, объединяющий все методы кластеризации без обучения – они просто позволяют вам объединить клиентов на основании близости по выбранным метрикам. Например, количеству покупок, числу дней жизни, балансу и другому.
Это тоже может быть полезно в случае, если вы хотите разделить вашу аудиторию на крупные группы и затем изучать каждую, либо выделить ядро и отстающие по продуктовым метрикам сегменты.
Например, в двумерном пространстве полезный результат может выглядеть следующим образом — сразу видно, какие кластеры стоит исследовать более детально.

Но чем больше метрик вы использовали для кластеризации, тем сложнее будет интерпретировать результат. И те самые предпочтения клиента все еще покрыты тайной.
Что же делать, вот вопрос? В QIWI мы не раз ломали голову над этой дилеммой, пока не пришли к любопытной модели, навеянной этой статьей. Среди прочих кейсов в статье рассказывалось о решении от Константина Воронцова для выделения латентных паттернов поведения пользователей банковских карт на базе библиотеки BigARTM.
Суть такова – транзакции клиента представлялись как набор слов и затем из полученной текстовой коллекции, где документ = клиенту, а слова = MCC-кодам (merchant category код, международная классификация торговых точек), выделялись текстовые тематики при помощи одного из инструментов Natural Language Processing (NLP) — тематического моделирования .
В нашем исполнении pipeline выглядит так:

Звучит абсолютно естественно – если мы хотим понять, чем и как живет наша аудитория, почему бы и не представить действия, которые клиенты совершают внутри нашей экосистемы, как историю, ими рассказанную. И составить путеводитель по тематикам этих историй.
Несмотря на то, что концепция выглядит изящно и просто, на практике при реализации модели пришлось столкнуться с несколькими проблемами:
- наличием выбросов и аномалий в данных и, как следствие, смещением тематик в сторону категорий покупок клиентов с большим оборотом,
- правильным определением числа топиков N,
- вопросом валидации результатов (возможно ли это в принципе?)
Для первой проблемы решение нашлось довольно легко – все крупные клиенты были разделены простейшим классификатором на «ядро» и «звезд» (см. картинку выше) и уже каждый из кластеров обрабатывался как отдельная текстовая коллекция.
А вот второй и третий пункт заставили задуматься – действительно, как валидировать результаты обучения без обучающей выборки? Конечно, есть метрики качества модели, но, кажется, что их недостаточно – и именно поэтому мы решили сделать очень простую вещь – проверить результаты на тех же исходных данных.
Выглядит эта проверка следующим образом: результатом классификации является набор тематик, например, вот такой:

Здесь питоновский список – это набор самых вероятных ключевых MCC-категорий покупок для данной темы (из матрицы «слово – тематика»). Если посмотреть отдельно на покупки в категории airlines and air carriers, вполне логично, что клиенты с темой «путешественники» будут составлять основную долю ее пользователей.

И эту проверку удобно реализовать в виде дашборда – заодно у вас появится наглядный материал для генерации продуктовых гипотез – кому кэшбэк на авиабилеты, а кому скидку на кофе.
А еще в коллекции для тематического моделирования можно добавить не только транзакционные события, но и мета информацию из других моделей, тематики обращений в клиентскую поддержку и многое другое. Или использовать в качестве категориальных фич для supervised-алгоритмов – например, моделей предсказания оттока и прочее.
Конечно, в таком подходе есть свои нюансы – например, коллекция обрабатывается как bag of words и порядок покупок не учитывается, но его вполне можно компенсировать использованием N грамм или расчетом тематических меток на каждый значимый период жизни клиента (каждый месяц, например). Однако, сама идея читабельной и интерпретируемой истории о клиентах, комбинации NLP и других моделей кажется нам очень привлекательной.
А как вам эта тема? С какими сложностями или радостями сегментации сталкивается ваша data science команда? Будет интересно узнать ваше мнение.
