
Сегодня любая компания старается копить и использовать данные в своих бизнес-процессах, и Почта не исключение.
У Почты нет проблем с количеством данных – у нас работает более 300 IT-систем, есть база в 40 млн пользователей и каждый день происходит 11 миллионов клиентских взаимодействий. В результате мы накопили 25 петабайт различных данных, которые помогают нам проектировать сервисы, улучшать процессы внутри компании, снижать риски и находить новые способы монетизации и экономии.
В этой статье мы расскажем про то, как в Почте России устроена работа с данными, как устроены специфические почтово-логистические процессы и какую роль в них играет Big Data.
Какие данные у нас есть и для чего
Почта — это крупнейшая в России логистическая и ритейл сеть, главная особенность которой с точки зрения данных заключается в том, что каждая единица «товара» (т. е. письмо, посылка) принадлежит конкретному получателю. В обычном магазине, если покупателю нужен товар, ему выдают любую единицу из партии, в Почте же каждое отправление поименовано, поэтому требования к сбору и отслеживанию данных намного строже.
Мы делим информацию на несколько типов:
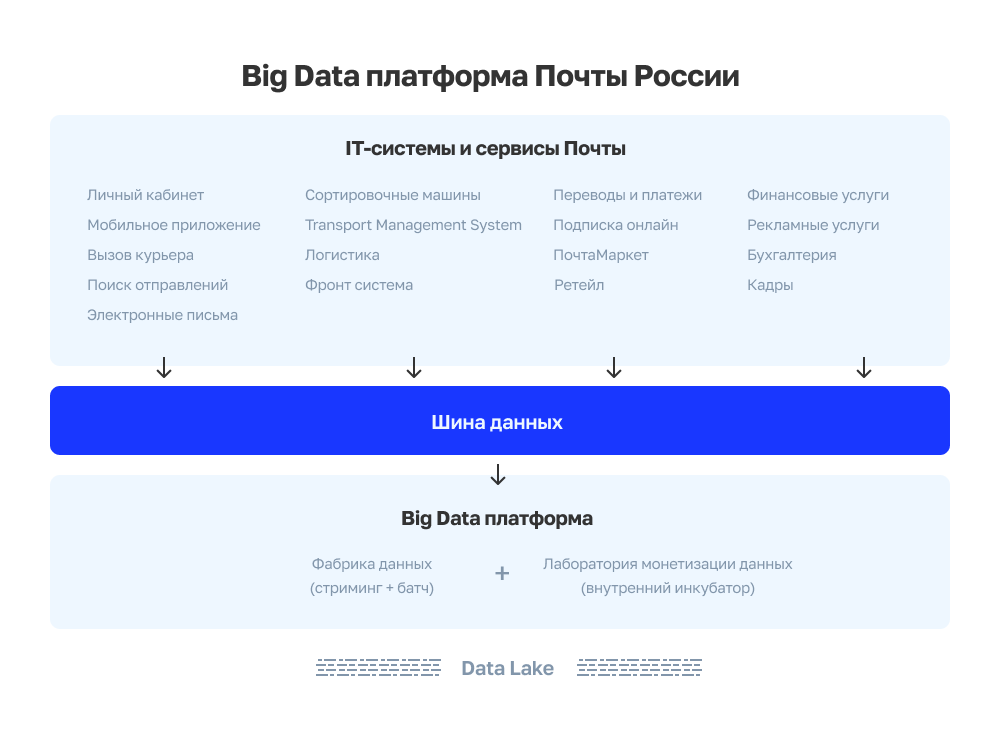
Вся эта информация собирается из разных сервисов в DataCloud — едином корпоративном хранилище данных, с которым большинство систем интегрированы через корпоративную шину данных. Однако DataCloud для Почты – не просто хранилище информации, а core-система, которая является важным звеном всех ключевых бизнес-процессов компании. Она отдает данные онлайн в ЕАС (единую автоматизированную систему отделений почтовой связи), в информационную систему Сортмастер, которая автоматизирует сортировку почтовых отправлений, в систему биллинга для формирования счетов, в трекинг и в другие системы.
В Data Cloud используются открытые продукты:
А также коммерческие решения:
DataСloud состоит из двух технологических компонент:
Какие задачи Почты решаются с помощью данных?
Контроль доставки и других KPI
При отправке письма или посылки отправитель выбирает тариф, который зависит от расстояния и срока доставки. Чтобы определить сроки для разных направлений, мы разбиваем маршруты на «плечи» – минимальные отрезки логистического пути. Для каждой пары из «плеча» и тарифа устанавливаем свой контрольный срок.
Далее в дело вступают аналитики, которые с помощью инструментов и данных, собранных в Big Data, оптимизируют полученные маршруты отправлений. В Почте внедрено несколько больших систем управления магистралью (пересылкой отправлений по основным маршрутам передвижения). Из этих систем в режиме онлайн собирается информация о том, где находится конкретная посылка или письмо. Анализируя эти данные, а также уровень загрузки дорог, объема перевозимого трафика и ряд других факторов, маршруты отправлений корректируются так, чтобы получить оптимальное соотношение скорости и стоимости доставки.
С помощью Big Data мы управляем разными KPI. Это контрольные сроки, сохранность отправлений, среднее время очереди в отделении, жалобы и претензии, средний чек и так далее. Все эти показатели влияют на мотивацию и зарплату сотрудников. С помощью данных мы прогнозируем нагрузку на всю систему и на отделения, и, используя эти прогнозы, составляем графики работы сотрудников. В случае со сроками DataCloud отслеживает фактические сроки, сравнивает их с контрольными, находит отклонения и высчитывает процент выполнения KPI.
Process mining
С помощью алгоритмов машинного обучения мы умеем отслеживать отклонения во всех стандартных процессах. Работает это так: у нас есть массив данных по всем бизнес-процессам, мы знаем, как должны проходить типовые процессы и какие отклонения считать плохими. На основе этой информации мы учим алгоритмы определять проблемы по различным паттернам.
Один из примеров использования такого сценария — серая почта. Это когда в массовую отправку мимо кассы вбрасывают письма. Мы умеем отслеживать похожие на серую почту отправления по массе контейнеров и по поведению посылок на маршруте.
Но недополучать прибыль мы можем по разным причинам – это не только серая почта, анализ данных показал что причиной может быть и человеческий фактор, а именно ошибки при вводе данных, и несовершенство взаимодействия многочисленных IT систем. Проанализировав данные о приеме отправлений в отделениях почтовой связи мы смогли обнаружить источник дополнительной выручки в размере 250 млн руб. в год.
Оказалось, что при приеме отправлений они иногда оформлялись некорректно и Почта взимала не полную стоимость доставки (она зависит от маршрута и веса отправления), а существенно меньшую сумму. Собранные в Data Cloud данные позволяют отследить весь путь любого отправления, который проходит из одной информационной системы Почты в другую, сопоставить атрибуты на старте отправления и финише и отладить процесс там, где показатель качества был невелик. Благодаря этим данным, Почта не только исправила ряд ошибок, но и работает над перестройкой текущей архитектуры IT систем. Фактически благодаря данным наработкам, Почта взяла курс на создание цифрового двойника, одновременно решая текущие проблемы.
Через DataCloud мы также получаем ежедневные отчеты о разных проблемах. К примеру, из отчета мы можем увидеть, что в регионе возникли массовые замедления – например, в Сибири выпало много снега, встали все поезда и сотни посылок никуда не едут. Мы видим проблему на любом расстоянии и ищем возможные решения — поменять вид транспорта, перестроить маршруты. Так что если ваша посылка задерживается на каком-то участке маршрута, то мы знаем где, почему, и что нужно исправлять.
Ситуационное реагирование
Есть такие проблемы, на которые нужно реагировать в реальном времени — застрявшая на ленте посылка, попавшая в аварию машина и тому подобные.
Для быстрого реагирования на в Почте существует автоматизированный ситуационный центр.
Здесь на мониторах у сотрудников по результатам анализа данных всплывают тикеты. Одна из типичных задач центра — зацикливание посылки, когда у отправления повреждается штрихкод. Такую проблему до появления автоматизации решали вручную – отправление начинало путешествовать между двумя сортировочными узлами и какой – нибудь сотрудник рано или поздно замечал коробку и вынимал ее из общего потока.
Теперь же мы видим такую ошибку сразу и удаленно отправляем на автоматизированную сортировочную линию команду сбросить посылку в отбраковку, где на нее приклеят новый, исправный штрихкод.
Трекинг
Мы доставляем 2 млрд посылок в год, и все их нужно отслеживать в трекинге, при этом на каждое отправление приходится по 20–30 событий. Поэтому основной массив данных приходится на информацию об отправлениях и их жизненном цикле, проще говоря – трекинг.
У каждого отправления есть жизненный цикл – начиная от операции «прием» в отделении связи и заканчивая операцией «вручение». Наблюдать за жизненным циклом отправлений нужно не только клиентам, но и самой Почте и её партнерам. В этом нам помогает распределённая СУБД Apache Cassandra.
Один из свежих примеров использования подобных данных — интеграция с китайской логистической компанией Cainiao для отслеживания посылок с AliExpress. Интеграция позволила отслеживать заказы в реальном времени, что помогло снизить долю недоставленных товаров с 10% до 3–5%, а срок доставки в крупнейшие города снизился почти в полтора раза. (Важное примечание – говоря о недоставленных товарах, мы имеем в виду не потерянные, а те, которые прибыли позже контрольного срока, который составляет 60 дней. А физически теряем мы крайне мало).
Работает все так: когда клиент оформляет покупку с доставкой через Cainiao, те присылают Почте информацию о заказе: трек-номер, логистический номер и состав вложений. Почта получает эти данные и записывает себе для отслеживания, и когда посылка едет по территории РФ и получает новые статусы, мы оповещаем китайскую службу об этих статусах, обращаясь к их API. Таким образом, Cainiao получает данные о статусах практически сразу.
При создании системы для управления трекингом в 2014 году мы ориентировались на 3 главных критерия. Она должна была:
Мы выбрали NoSQL Data base Cassandra, так как понимали, что при высоких нагрузках обычные реляционные БД вроде Postgress или Oracle будут работать медленно, так как имеют строгие требования к записи данных. По этой причине вновь добавленные данные не сразу возвращаются на чтение. В итоге Cassandra оказалась идеальным решением.
Cassandra работает быстро благодаря тому, что в ней не требуется полное подтверждение записи. То есть в нее можно постоянно писать данные и сразу же читать их нужными системами. Технология предполагает многократное копирование данных на сервера – это обеспечивает надёжность хранения. Сейчас система работает на 31 сервере c фактором репликации 5. Это значит, что при попытке записи одной строки в основное хранилище, запись должна попасть на несколько разных серверов. Так мы защищаем данные от потерь.
С нагрузкой тоже все хорошо. Самая большая зафиксированная нагрузка на чтение — до 20 000 запросов в секунду без просадки производительности, и это даже не пик. На запись – 10 000 операций в секунду на пике. Cassandra расположена во внутреннем контуре и приспособлена для онлайн-обработки и передачи данных о логистических событиях – как во внешние системы (мобильное приложение, сайт pochta.ru), так и в наши внутренние системы.
Аналитика и управленческие решения
Данные нужны нам не только для решения оперативных задач. Мы используем их еще для того, чтобы анализировать и улучшать работу сервисов, проверять востребованность новых услуг. Решения, принятые не на основе данных, часто субъективны. Поэтому Почта перестраивает подход к исследованиям пользовательского опыта и стремимся принимать решения на основе конкретных чисел. Для этого у нас есть инфраструктура для Data Science – технологическая платформа, включенная в контур Datacloud, которая позволяет разрабатывать и применять модели искусственного интеллекта на основе информации, собранной с множества IT-систем.
Чтобы сделать работу с данными доступной для людей с самыми разными навыками, мы сделали простой и удобный инструмент — песочницу данных. С ее помощью сотрудники строят отчеты, выводят нужные показатели, создают витрины выверки счетов для работы с международными платформами, создают модели.
Раньше для работы с данными требовался IT-бэкграунд, достаточно глубокое знание SQL и подобных программ. Сейчас же достаточно либо самого базового уровня SQL, либо он вообще не нужен – в песочнице можно строить собственные отчеты в кубах (которые выглядят как сводная таблица в Excel), использовать простые фильтры или готовые формы. Сейчас платформу используют более более 200 аналитиков различных бизнес-подразделений. Только за первое полугодие 2020 года число сотрудников, работающих с платформой, увеличилось на 65%.
Песочница данных
«Песочница» представляет собой набор ресурсов, с помощью которых специалисты могут экспериментировать и изменять данные любым способом, проводить глубокий анализ, чтобы ответить на важные бизнес-вопросы.
У Почты России множество бизнес-подразделений – это блок электронной коммерции, международный блок, блок почтового бизнеса, управление сетью отделений и так далее. У каждого из них есть собственные аналитики, и именно для них и предназначена песочница. Фактически мы предоставляем self–service BI, где аналитики могут построить красивую визуализацию, проверить гипотезу, пропилотировать отчетность. Еще песочницу можно использовать как полигон для разработки моделей и их регулярного применения. С ее помощью мы проверяем гипотезы о направлениях развития существующих продуктов, о внедрении новых, о ценообразовании, прогнозируем нагрузки.
Когда в Почте появляется новая услуга, важно быстро понять, насколько она хорошо внедрена и какие показатели демонстрирует. В песочнице можно собрать нужную информацию и дать бизнес-аналитикам оценить качественные или количественные показатели внедрения. Для этого в песочницу добавляют новый источник данных и бизнес-аналитики анализируют новые данные, например, доходы/расходы в разрезе отделений или нагрузку на сотрудников и т.д.
До появления песочницы сотрудники добывали данные разными способами – самостоятельно скачивали их из систем-источников, работали со сводными таблицами, разворачивали свои сервера. Все это приводило к удорожанию владения данными для компании, так как одна и та же информация запрашивалась разными пользователями. Теперь трудозатраты на подготовку, хранение и запросы на систему объединены в один поток, а значит обходятся дешевле и работают быстрее.
Песочница состоит из:

Песочница представляет собой отдельную физическую инфраструктуру, отдельную от промышленной среды. Она состоит из нескольких типов инструментов: хранения данных, анализа и построения моделей искусственного интеллекта. В песочнице накапливаются данные, отделенные от производственной базы. Пользователи могут загружать собственные данные как часть проекта на короткие периоды, даже если те не включены в официальную модель компании.
С точки зрения самих данных, песочница разделена на несколько областей:

Полная копия всех накопленных в промышленной среде данных — это «зеркало» промышленной среды со всеми ее данными, доступными для анализа без влияния на промышленный контур системы.
Область временного получения данных от источников — это отдельная область, в которой мы можем быстро получать любые данные от любых систем по специальному регламенту. Это нужно, чтобы давать аналитикам возможность как можно быстрее смотреть и пилотировать данные, понимать насколько те пригодны для работы, проверять гипотезы и строить тестовую отчетность и на ее основе принимать решение, нужны ли эти данные в промышленном контуре. Если оказывается что нужны, то запускать промышленное подключение.
Чтобы сделать работу пользователей в песочнице удобнее, здесь же существует две пользовательские области. Это личные (user area) схемы, в которые каждый человек может подгрузить свои данные с помощью доступных интерфейсов, делать выборки из общедоступных данных. И пилотная область — предназначенная для работы групп пользователей над какой-то общей задачей. Суть ее та же самая — подгрузить данные или создать собственные выборки на основе существующих, пилотировать их на каком-то объеме, но обязательно с ограниченным сроком жизни, после которого принимается решение: успешен пилот или нет. И также в случае успеха инициируется промышленный запуск решения.
И еще одна область — для построения моделей искусственного интеллекта. Это датасеты, витрины, выборки для разработки, обучения и регулярного применения моделей.
Качество и доступность данных
C помощью анализа данных мы собираемся сокращать время, которое тратим на решения о судьбе новых продуктов и услуг. Поэтому для нас важны качество, доступность и стабильность данных – ведь машина не человек, она не распознает ошибку в расчетах, если информация была собрана не по правилам.
В эпоху Agile и продуктовых подходов, когда команды часто что-то меняют в продуктах и системах, становится важно сохранять порядок в данных. Чтобы держать изменения под контролем, мы особенно внимательно следим за качеством и стандартами данных как на уровне хранилища, так и на уровне IT-систем.
Еще, чтобы данные были корректными, их нужно подробно описывать и делать прозрачными для всех. Сейчас этот процесс автоматизирован и интегрирован в процесс разработки. Каждая доработка рождает метаданные – данные о данных, в которых описано что это за информация, откуда она поступила и так далее. C помощью метаданных становится легче находить информацию и управлять ею в большом потоке.
А также мы описываем все атрибуты, включая бизнес-алгоритмы и их расчеты. По названию не всегда возможно определить, как использовать атрибут. Конечно, иногда можно догадаться по названию о смысле, но все-таки содержание не всегда очевидно. Поэтому мы закладываем в описание еще и бизнес-смысл, бизнес-алгоритмы, информацию о том, откуда данные поступили. Все это нужно, чтобы пользователь не догадывался, а получал точные и понятные результаты.
Для управления качеством мы собираем рабочие группы, на которых обсуждаем статусы качества объектов, фиксируем методики и критерии, рассматриваем влияние разных событий на качество данных. И если видим проблемы, то можем рекомендовать что-то поменять в бизнес-процессах – обновить инструкцию для работников в отделении, автоматизировать процесс, доработать систему. Так, если мы видим задержку в поступлении отчетов из IT систем регионов – то собираем группу на которой совместно находим проблему (чаще всего техническую) и предлагаем способы ее решения.
Когда данные подробно описаны и есть интерактивный пользовательский интерфейс, с помощью которого пользователи ищут нужные атрибуты и получают информацию о том, что те означают, работа с песочницей становится гораздо эффективнее.
Это лишь часть задач, которая стоит перед нашей командой по управлению данными. Количество данных в Почте растет с каждый днем, и для новых кейсов нам нужны аналитики, умеющие строить хранилища и озера данных, специалисты по качеству данных — для внедрения процессов и методологии, а также сотрудники, которые будут заниматься архитектурой и описанием данных.
Открытые вакансии Почтовых Технологий смотрите на pochta.tech
У Почты нет проблем с количеством данных – у нас работает более 300 IT-систем, есть база в 40 млн пользователей и каждый день происходит 11 миллионов клиентских взаимодействий. В результате мы накопили 25 петабайт различных данных, которые помогают нам проектировать сервисы, улучшать процессы внутри компании, снижать риски и находить новые способы монетизации и экономии.
В этой статье мы расскажем про то, как в Почте России устроена работа с данными, как устроены специфические почтово-логистические процессы и какую роль в них играет Big Data.
Какие данные у нас есть и для чего
Почта — это крупнейшая в России логистическая и ритейл сеть, главная особенность которой с точки зрения данных заключается в том, что каждая единица «товара» (т. е. письмо, посылка) принадлежит конкретному получателю. В обычном магазине, если покупателю нужен товар, ему выдают любую единицу из партии, в Почте же каждое отправление поименовано, поэтому требования к сбору и отслеживанию данных намного строже.
Мы делим информацию на несколько типов:
- Digital — о том, что пользователь делает в приложении/на сайте. Анализируя её, мы можем улучшать сервисы и оценивать востребованность новых услуг;
- Логистическая — о перемещениях посылок. Эта информация показывается клиентам в мобильном приложении и на портале pochta.ru;
- Служебная (внутренняя логистика) — о внутренних процессах. Такие данные необходимы для создания полной истории перемещения посылок;
- Финансовая — о транзакциях.
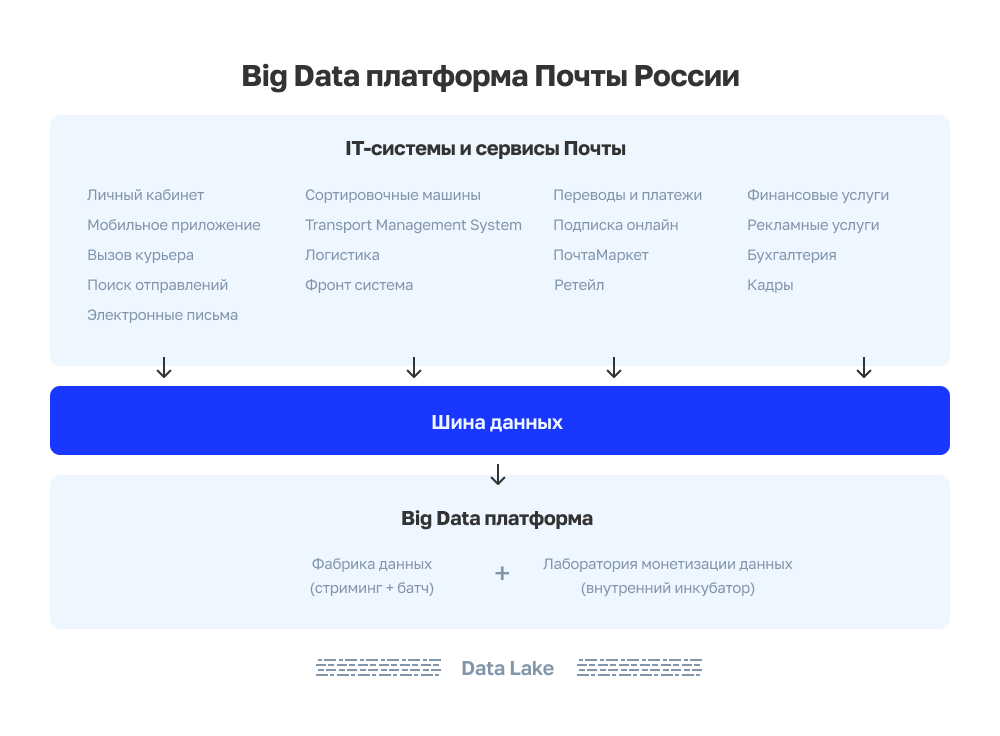
Вся эта информация собирается из разных сервисов в DataCloud — едином корпоративном хранилище данных, с которым большинство систем интегрированы через корпоративную шину данных. Однако DataCloud для Почты – не просто хранилище информации, а core-система, которая является важным звеном всех ключевых бизнес-процессов компании. Она отдает данные онлайн в ЕАС (единую автоматизированную систему отделений почтовой связи), в информационную систему Сортмастер, которая автоматизирует сортировку почтовых отправлений, в систему биллинга для формирования счетов, в трекинг и в другие системы.
В Data Cloud используются открытые продукты:
- Hadoop — система для распределенных вычислений, хранения и обработки больших объемов данных;
- Cassandra — высоконагруженная нереляционная база данных для потоковой обработки данных;
- Spark — движок для распределенных вычислений, работающий на базе Hadoop;
- Hive — для формирования SQL-запросов и обработки больших наборов данных, расположенных в распределенном хранилище (Hadoop);
- Presto — высокопроизводительный инструмент для выполнения SQL-запросов в Hadoop;
- Kafka — высокопроизводительная горизонтально масштабируемая очередь (информационная шина);
- Airflow, Pentaho DI — инструменты для построения и управления ETL-процессами преобразования данных.
А также коммерческие решения:
- Vertica — реляционная СУБД для расчета и хранения витрин данных;
- Qlik Sense — BI-средство для построения аналитических панелей и дашбордов, а также инструмент Self Service BI для аналитиков;
- Форсайт — BI-средство для формирования регулярной и детализированной отчетности.
DataСloud состоит из двух технологических компонент:
- Фабрика данных — собирает данные со всех систем, обрабатывает и обогащает их. Практически все IT-системы и сервисы Почты являются либо поставщиками, либо потребителями системы. Вообще, к потребителям данных можно отнести еще и всех сотрудников и клиентов Почты;
- Лаборатория монетизации данных — внутренний инкубатор, где прогоняются идеи новых продуктов. О том, как проверяем идеи, мы расскажем чуть дальше — в разделе про «песочницу».
Какие задачи Почты решаются с помощью данных?
Контроль доставки и других KPI
При отправке письма или посылки отправитель выбирает тариф, который зависит от расстояния и срока доставки. Чтобы определить сроки для разных направлений, мы разбиваем маршруты на «плечи» – минимальные отрезки логистического пути. Для каждой пары из «плеча» и тарифа устанавливаем свой контрольный срок. Далее в дело вступают аналитики, которые с помощью инструментов и данных, собранных в Big Data, оптимизируют полученные маршруты отправлений. В Почте внедрено несколько больших систем управления магистралью (пересылкой отправлений по основным маршрутам передвижения). Из этих систем в режиме онлайн собирается информация о том, где находится конкретная посылка или письмо. Анализируя эти данные, а также уровень загрузки дорог, объема перевозимого трафика и ряд других факторов, маршруты отправлений корректируются так, чтобы получить оптимальное соотношение скорости и стоимости доставки.
С помощью Big Data мы управляем разными KPI. Это контрольные сроки, сохранность отправлений, среднее время очереди в отделении, жалобы и претензии, средний чек и так далее. Все эти показатели влияют на мотивацию и зарплату сотрудников. С помощью данных мы прогнозируем нагрузку на всю систему и на отделения, и, используя эти прогнозы, составляем графики работы сотрудников. В случае со сроками DataCloud отслеживает фактические сроки, сравнивает их с контрольными, находит отклонения и высчитывает процент выполнения KPI.
Process mining
С помощью алгоритмов машинного обучения мы умеем отслеживать отклонения во всех стандартных процессах. Работает это так: у нас есть массив данных по всем бизнес-процессам, мы знаем, как должны проходить типовые процессы и какие отклонения считать плохими. На основе этой информации мы учим алгоритмы определять проблемы по различным паттернам. Один из примеров использования такого сценария — серая почта. Это когда в массовую отправку мимо кассы вбрасывают письма. Мы умеем отслеживать похожие на серую почту отправления по массе контейнеров и по поведению посылок на маршруте.
Но недополучать прибыль мы можем по разным причинам – это не только серая почта, анализ данных показал что причиной может быть и человеческий фактор, а именно ошибки при вводе данных, и несовершенство взаимодействия многочисленных IT систем. Проанализировав данные о приеме отправлений в отделениях почтовой связи мы смогли обнаружить источник дополнительной выручки в размере 250 млн руб. в год.
Оказалось, что при приеме отправлений они иногда оформлялись некорректно и Почта взимала не полную стоимость доставки (она зависит от маршрута и веса отправления), а существенно меньшую сумму. Собранные в Data Cloud данные позволяют отследить весь путь любого отправления, который проходит из одной информационной системы Почты в другую, сопоставить атрибуты на старте отправления и финише и отладить процесс там, где показатель качества был невелик. Благодаря этим данным, Почта не только исправила ряд ошибок, но и работает над перестройкой текущей архитектуры IT систем. Фактически благодаря данным наработкам, Почта взяла курс на создание цифрового двойника, одновременно решая текущие проблемы.
Через DataCloud мы также получаем ежедневные отчеты о разных проблемах. К примеру, из отчета мы можем увидеть, что в регионе возникли массовые замедления – например, в Сибири выпало много снега, встали все поезда и сотни посылок никуда не едут. Мы видим проблему на любом расстоянии и ищем возможные решения — поменять вид транспорта, перестроить маршруты. Так что если ваша посылка задерживается на каком-то участке маршрута, то мы знаем где, почему, и что нужно исправлять.
Ситуационное реагирование
Есть такие проблемы, на которые нужно реагировать в реальном времени — застрявшая на ленте посылка, попавшая в аварию машина и тому подобные.Для быстрого реагирования на в Почте существует автоматизированный ситуационный центр.
Здесь на мониторах у сотрудников по результатам анализа данных всплывают тикеты. Одна из типичных задач центра — зацикливание посылки, когда у отправления повреждается штрихкод. Такую проблему до появления автоматизации решали вручную – отправление начинало путешествовать между двумя сортировочными узлами и какой – нибудь сотрудник рано или поздно замечал коробку и вынимал ее из общего потока.
Теперь же мы видим такую ошибку сразу и удаленно отправляем на автоматизированную сортировочную линию команду сбросить посылку в отбраковку, где на нее приклеят новый, исправный штрихкод.
Трекинг
Мы доставляем 2 млрд посылок в год, и все их нужно отслеживать в трекинге, при этом на каждое отправление приходится по 20–30 событий. Поэтому основной массив данных приходится на информацию об отправлениях и их жизненном цикле, проще говоря – трекинг. У каждого отправления есть жизненный цикл – начиная от операции «прием» в отделении связи и заканчивая операцией «вручение». Наблюдать за жизненным циклом отправлений нужно не только клиентам, но и самой Почте и её партнерам. В этом нам помогает распределённая СУБД Apache Cassandra.
Один из свежих примеров использования подобных данных — интеграция с китайской логистической компанией Cainiao для отслеживания посылок с AliExpress. Интеграция позволила отслеживать заказы в реальном времени, что помогло снизить долю недоставленных товаров с 10% до 3–5%, а срок доставки в крупнейшие города снизился почти в полтора раза. (Важное примечание – говоря о недоставленных товарах, мы имеем в виду не потерянные, а те, которые прибыли позже контрольного срока, который составляет 60 дней. А физически теряем мы крайне мало).
Работает все так: когда клиент оформляет покупку с доставкой через Cainiao, те присылают Почте информацию о заказе: трек-номер, логистический номер и состав вложений. Почта получает эти данные и записывает себе для отслеживания, и когда посылка едет по территории РФ и получает новые статусы, мы оповещаем китайскую службу об этих статусах, обращаясь к их API. Таким образом, Cainiao получает данные о статусах практически сразу.
При создании системы для управления трекингом в 2014 году мы ориентировались на 3 главных критерия. Она должна была:
- Быть способной обрабатывать большое количество данных.
- Быть надежной (все системы трекаются через нее).
- Выдерживать высокие нагрузки.
Мы выбрали NoSQL Data base Cassandra, так как понимали, что при высоких нагрузках обычные реляционные БД вроде Postgress или Oracle будут работать медленно, так как имеют строгие требования к записи данных. По этой причине вновь добавленные данные не сразу возвращаются на чтение. В итоге Cassandra оказалась идеальным решением.
Cassandra работает быстро благодаря тому, что в ней не требуется полное подтверждение записи. То есть в нее можно постоянно писать данные и сразу же читать их нужными системами. Технология предполагает многократное копирование данных на сервера – это обеспечивает надёжность хранения. Сейчас система работает на 31 сервере c фактором репликации 5. Это значит, что при попытке записи одной строки в основное хранилище, запись должна попасть на несколько разных серверов. Так мы защищаем данные от потерь.
С нагрузкой тоже все хорошо. Самая большая зафиксированная нагрузка на чтение — до 20 000 запросов в секунду без просадки производительности, и это даже не пик. На запись – 10 000 операций в секунду на пике. Cassandra расположена во внутреннем контуре и приспособлена для онлайн-обработки и передачи данных о логистических событиях – как во внешние системы (мобильное приложение, сайт pochta.ru), так и в наши внутренние системы.
Аналитика и управленческие решения
Данные нужны нам не только для решения оперативных задач. Мы используем их еще для того, чтобы анализировать и улучшать работу сервисов, проверять востребованность новых услуг. Решения, принятые не на основе данных, часто субъективны. Поэтому Почта перестраивает подход к исследованиям пользовательского опыта и стремимся принимать решения на основе конкретных чисел. Для этого у нас есть инфраструктура для Data Science – технологическая платформа, включенная в контур Datacloud, которая позволяет разрабатывать и применять модели искусственного интеллекта на основе информации, собранной с множества IT-систем. Чтобы сделать работу с данными доступной для людей с самыми разными навыками, мы сделали простой и удобный инструмент — песочницу данных. С ее помощью сотрудники строят отчеты, выводят нужные показатели, создают витрины выверки счетов для работы с международными платформами, создают модели.
Раньше для работы с данными требовался IT-бэкграунд, достаточно глубокое знание SQL и подобных программ. Сейчас же достаточно либо самого базового уровня SQL, либо он вообще не нужен – в песочнице можно строить собственные отчеты в кубах (которые выглядят как сводная таблица в Excel), использовать простые фильтры или готовые формы. Сейчас платформу используют более более 200 аналитиков различных бизнес-подразделений. Только за первое полугодие 2020 года число сотрудников, работающих с платформой, увеличилось на 65%.
Песочница данных
«Песочница» представляет собой набор ресурсов, с помощью которых специалисты могут экспериментировать и изменять данные любым способом, проводить глубокий анализ, чтобы ответить на важные бизнес-вопросы.
У Почты России множество бизнес-подразделений – это блок электронной коммерции, международный блок, блок почтового бизнеса, управление сетью отделений и так далее. У каждого из них есть собственные аналитики, и именно для них и предназначена песочница. Фактически мы предоставляем self–service BI, где аналитики могут построить красивую визуализацию, проверить гипотезу, пропилотировать отчетность. Еще песочницу можно использовать как полигон для разработки моделей и их регулярного применения. С ее помощью мы проверяем гипотезы о направлениях развития существующих продуктов, о внедрении новых, о ценообразовании, прогнозируем нагрузки.
Когда в Почте появляется новая услуга, важно быстро понять, насколько она хорошо внедрена и какие показатели демонстрирует. В песочнице можно собрать нужную информацию и дать бизнес-аналитикам оценить качественные или количественные показатели внедрения. Для этого в песочницу добавляют новый источник данных и бизнес-аналитики анализируют новые данные, например, доходы/расходы в разрезе отделений или нагрузку на сотрудников и т.д.
До появления песочницы сотрудники добывали данные разными способами – самостоятельно скачивали их из систем-источников, работали со сводными таблицами, разворачивали свои сервера. Все это приводило к удорожанию владения данными для компании, так как одна и та же информация запрашивалась разными пользователями. Теперь трудозатраты на подготовку, хранение и запросы на систему объединены в один поток, а значит обходятся дешевле и работают быстрее.
Песочница состоит из:
- Инфраструктуры загрузки и хранения данных;
- Инструментов по работе с данными — интерфейсов, через которые люди могут пользоваться данными, средств анализа данных;
- Инструментов описания данных, необходимых для корректной интерпретации данных.

Песочница представляет собой отдельную физическую инфраструктуру, отдельную от промышленной среды. Она состоит из нескольких типов инструментов: хранения данных, анализа и построения моделей искусственного интеллекта. В песочнице накапливаются данные, отделенные от производственной базы. Пользователи могут загружать собственные данные как часть проекта на короткие периоды, даже если те не включены в официальную модель компании.
С точки зрения самих данных, песочница разделена на несколько областей:
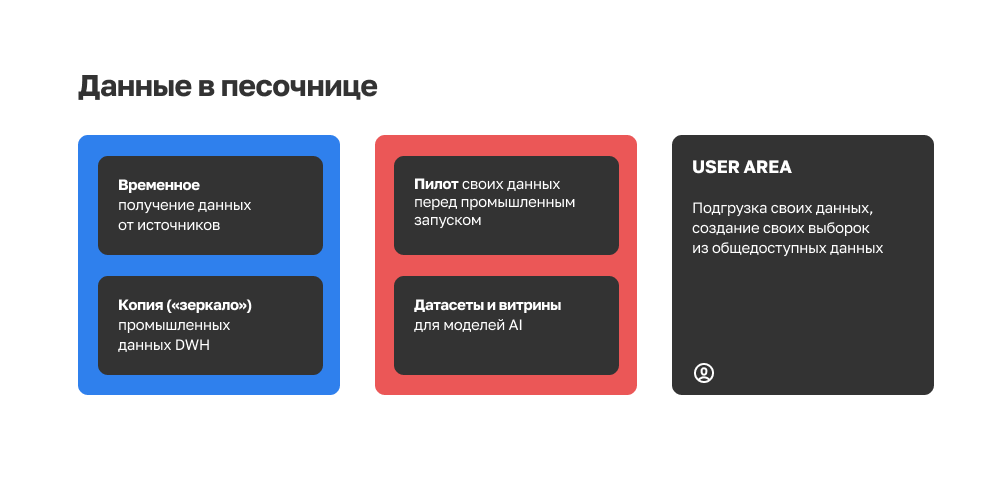
Полная копия всех накопленных в промышленной среде данных — это «зеркало» промышленной среды со всеми ее данными, доступными для анализа без влияния на промышленный контур системы.
Область временного получения данных от источников — это отдельная область, в которой мы можем быстро получать любые данные от любых систем по специальному регламенту. Это нужно, чтобы давать аналитикам возможность как можно быстрее смотреть и пилотировать данные, понимать насколько те пригодны для работы, проверять гипотезы и строить тестовую отчетность и на ее основе принимать решение, нужны ли эти данные в промышленном контуре. Если оказывается что нужны, то запускать промышленное подключение.
Чтобы сделать работу пользователей в песочнице удобнее, здесь же существует две пользовательские области. Это личные (user area) схемы, в которые каждый человек может подгрузить свои данные с помощью доступных интерфейсов, делать выборки из общедоступных данных. И пилотная область — предназначенная для работы групп пользователей над какой-то общей задачей. Суть ее та же самая — подгрузить данные или создать собственные выборки на основе существующих, пилотировать их на каком-то объеме, но обязательно с ограниченным сроком жизни, после которого принимается решение: успешен пилот или нет. И также в случае успеха инициируется промышленный запуск решения.
И еще одна область — для построения моделей искусственного интеллекта. Это датасеты, витрины, выборки для разработки, обучения и регулярного применения моделей.
Качество и доступность данных
C помощью анализа данных мы собираемся сокращать время, которое тратим на решения о судьбе новых продуктов и услуг. Поэтому для нас важны качество, доступность и стабильность данных – ведь машина не человек, она не распознает ошибку в расчетах, если информация была собрана не по правилам.
В эпоху Agile и продуктовых подходов, когда команды часто что-то меняют в продуктах и системах, становится важно сохранять порядок в данных. Чтобы держать изменения под контролем, мы особенно внимательно следим за качеством и стандартами данных как на уровне хранилища, так и на уровне IT-систем.
Еще, чтобы данные были корректными, их нужно подробно описывать и делать прозрачными для всех. Сейчас этот процесс автоматизирован и интегрирован в процесс разработки. Каждая доработка рождает метаданные – данные о данных, в которых описано что это за информация, откуда она поступила и так далее. C помощью метаданных становится легче находить информацию и управлять ею в большом потоке.
А также мы описываем все атрибуты, включая бизнес-алгоритмы и их расчеты. По названию не всегда возможно определить, как использовать атрибут. Конечно, иногда можно догадаться по названию о смысле, но все-таки содержание не всегда очевидно. Поэтому мы закладываем в описание еще и бизнес-смысл, бизнес-алгоритмы, информацию о том, откуда данные поступили. Все это нужно, чтобы пользователь не догадывался, а получал точные и понятные результаты.
Для управления качеством мы собираем рабочие группы, на которых обсуждаем статусы качества объектов, фиксируем методики и критерии, рассматриваем влияние разных событий на качество данных. И если видим проблемы, то можем рекомендовать что-то поменять в бизнес-процессах – обновить инструкцию для работников в отделении, автоматизировать процесс, доработать систему. Так, если мы видим задержку в поступлении отчетов из IT систем регионов – то собираем группу на которой совместно находим проблему (чаще всего техническую) и предлагаем способы ее решения.
Когда данные подробно описаны и есть интерактивный пользовательский интерфейс, с помощью которого пользователи ищут нужные атрибуты и получают информацию о том, что те означают, работа с песочницей становится гораздо эффективнее.
Это лишь часть задач, которая стоит перед нашей командой по управлению данными. Количество данных в Почте растет с каждый днем, и для новых кейсов нам нужны аналитики, умеющие строить хранилища и озера данных, специалисты по качеству данных — для внедрения процессов и методологии, а также сотрудники, которые будут заниматься архитектурой и описанием данных.
Открытые вакансии Почтовых Технологий смотрите на pochta.tech
