Мы уже познакомились с устройством буферного кеша — одного из основных объектов в разделяемой памяти, — и поняли, что для восстановления после сбоя, когда содержимое оперативной памяти пропадает, нужно вести журнал предзаписи.
Нерешенная проблема, на которой мы остановились в прошлый раз, состоит в том, что неизвестно, с какого момента можно начинать проигрывание журнальных записей при восстановлении. Начать с начала, как советовал Король из Алисы, не получится: невозможно хранить все журнальные записи от старта сервера — это потенциально и огромный объем, и такое же огромное время восстановления. Нам нужна такая постепенно продвигающаяся вперед точка, с которой мы можем начинать восстановление (и, соответственно, можем безопасно удалять все предшествующие журнальные записи). Это и есть контрольная точка, о которой сегодня пойдет речь.
Каким свойством должна обладать контрольная точка? Мы должны быть уверены, что все журнальные записи, начиная с контрольной точки, будут применяться к страницам, записанным на диск. Если бы это было не так, при восстановлении мы могли бы прочитать с диска слишком старую версию страницы и применить к ней журнальную запись, и тем самым безвозвратно повредили бы данные.
Как получить контрольную точку? Самый простой вариант — периодически приостанавливать работу системы и сбрасывать все грязные страницы буферного и других кешей на диск. (Заметим, что страницы только записываются, но не вытесняются из кеша.) Такие точки будет удовлетворять условию, но, конечно, никто не захочет работать с системой, постоянно замирающей на неопределенное, но весьма существенное время.
Поэтому на практике все несколько сложнее: контрольная точка из точки превращается в отрезок. Сперва мы начинаем контрольную точку. После этого, не прерывая работу и по возможности не создавая пиковых нагрузок, потихоньку сбрасываем грязные буферы на диск.

Когда все буферы, которые были грязными на момент начала контрольной точки, окажутся записанными, контрольная точка считается завершенной. Теперь (но не раньше) мы можем использовать момент начала в качестве той точки, с которой можно начинать восстановление. И журнальные записи вплоть до этого момента нам больше не нужны.

Выполнением контрольной точки занимается специальный фоновый процесс checkpointer.
Продолжительность записи грязных буферов определяется значением параметра checkpoint_completion_target. Он показывает, какую часть времени между двумя соседними контрольными точками будет происходить запись. Значение по умолчанию равно 0.5 (как на рисунках выше), то есть запись занимает половину времени между контрольными точками. Обычно значение увеличивают вплоть до 1.0 для большей равномерности.
Рассмотрим подробнее, что происходит при выполнении контрольной точки.
Сначала процесс контрольной точки сбрасывает на диск буферы статуса транзакций (XACT). Поскольку их немного (всего 128), они записываются сразу же.
Затем начинается основная работа — запись грязных страниц из буферного кеша. Как мы уже говорили, сбросить все страницы одномоментно невозможно, поскольку размер буферного кеша может быть значительным. Поэтому сперва все грязные на текущий момент страницы помечаются в буферном кеше в заголовках специальным флагом.
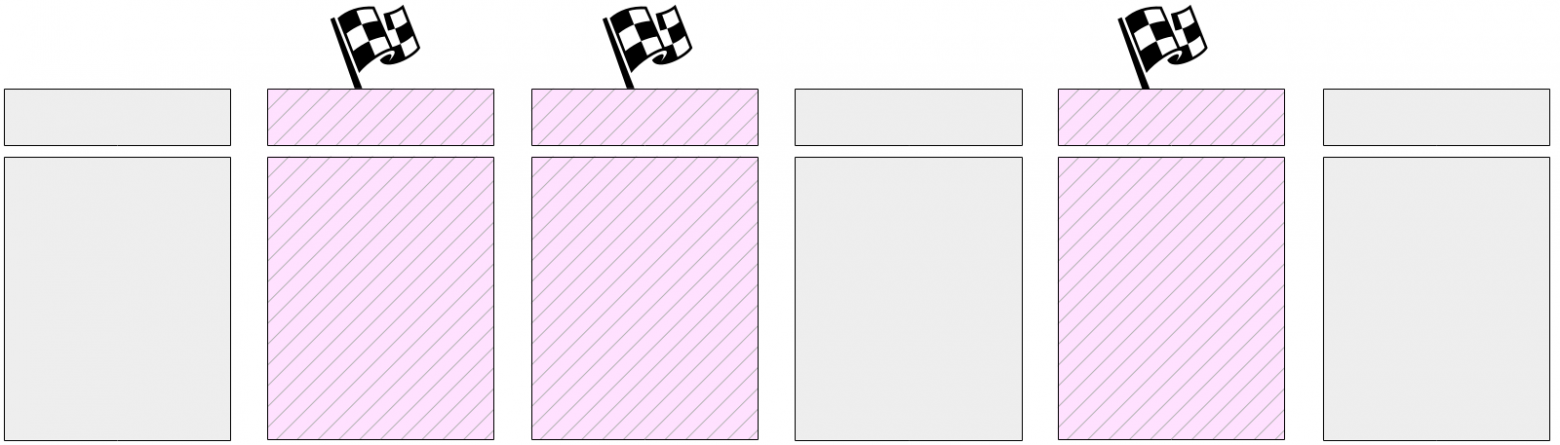
А затем процесс контрольной точки постепенно проходит по всем буферам и сбрасывает помеченные на диск. Напомним, что страницы не вытесняются из кеша, а только записываются на диск, поэтому не нужно обращать внимания ни на число обращений к буферу, ни на его закрепление.
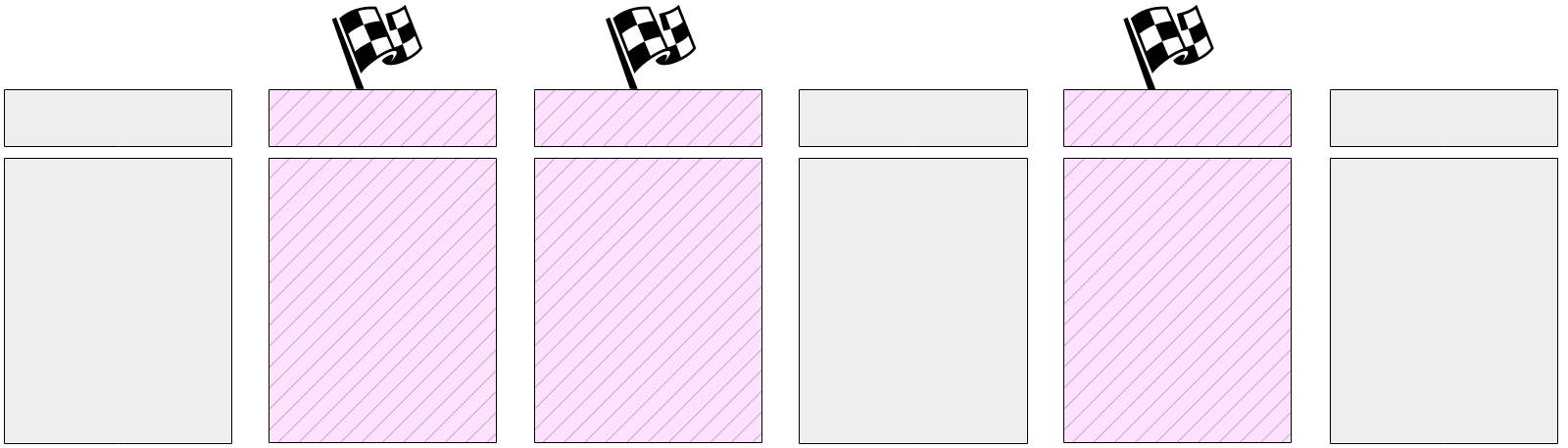
Помеченные буферы могут также быть записаны и серверными процессами — смотря кто доберется до буфера первым. В любом случае при записи снимается установленный ранее флаг, так что (для целей контрольной точки) буфер будет записан только один раз.
Естественно, в ходе выполнения контрольной точки страницы продолжают изменяться в буферном кеше. Но новые грязные буферы не помечены флагом и процесс контрольной точки не должен их записывать.

В конце своей работы процесс создает журнальную запись об окончании контрольной точки. В этой записи содержится LSN момента начала работы контрольной точки. Поскольку контрольная точка ничего не записывает в журнал в начале своей работы, по этому LSN может находиться любая журнальная запись.
Кроме того, в файле $PGDATA/global/pg_control обновляется указание на последнюю пройденную контрольную точку. До того, как контрольная точка завершится, pg_control указывает на предыдущую контрольную точку.

Чтобы посмотреть на работу контрольной точки, создадим какую-нибудь таблицу — ее страницы попадут в буферный кеш и будут грязными:
Запомним текущую позицию в журнале:
Теперь выполним контрольную точку вручную и убедимся, что в кеше не осталось грязных страниц (как мы говорили, новые грязные страницы могут появляться, но в нашем случае никаких изменений в процессе выполнения контрольной точки не происходило):
Посмотрим, как контрольная точка отразилась в журнале:
Здесь мы видим две записи. Последняя из них — запись о прохождении контрольной точки (CHECKPOINT_ONLINE). LSN начала контрольной точки указан после слова redo, и эта позиция соответствует журнальной записи, которая в момент начала контрольной точки была последней.
Ту же информацию мы найдем и в управляющем файле:
Теперь мы готовы уточнить алгоритм восстановления, намеченный в прошлой статье.
Если в работе сервера произошел сбой, то при последующем запуске процесс startup обнаруживает это, посмотрев в файл pg_control и увидев статус, отличный от «shut down». В этом случае выполняется автоматическое восстановление.
Сначала процесс восстановления прочитает из того же pg_control позицию начала контрольной точки. (Для полноты картины заметим, что, если присутствует файл backup_label, то запись о контрольной точке читается из него — это нужно для восстановления из резервных копий, но это тема для отдельного цикла.)
Далее он будет читать журнал, начиная с найденной позиции, последовательно применяя журнальные записи к страницам (если в этом есть необходимость, как мы уже обсуждали в прошлый раз).
В заключение все нежурналируемые таблицы перезаписываются с помощью образов в init-файлах.
На этом процесс startup завершает работу, а процесс checkpointer тут же выполняет контрольную точку, чтобы зафиксировать на диске восстановленное состояние.
Можно сымитировать сбой, принудительно остановив сервер в режиме immediate.
(Ключ
Проверим состояние кластера:
При запуске PostgreSQL понимает, что произошел сбой и требуется восстановление.
Необходимость восстановления отмечается в журнале сообщений: database system was not properly shut down; automatic recovery in progress. Затем начинается проигрывание журнальных записей с позиции, отмеченной в «redo starts at» и продолжается до тех пор, пока удается получать следующие журнальные записи. На этом восстановление завершается в позиции «redo done at» и СУБД начинает работать с клиентами (database system is ready to accept connections).
А что происходит при нормальной остановке сервера? Чтобы сбросить грязные страницы на диск, PostgreSQL отключает всех клиентов и затем выполняет финальную контрольную точку.
Запомним текущую позицию в журнале:
Теперь аккуратно останавливаем сервер:
Проверим состояние кластера:
А в журнале обнаружим единственную запись о финальной контрольной точке (CHECKPOINT_SHUTDOWN):
(Страшным фатальным сообщением pg_waldump всего-навсего хочет сказать о том, что дочитал до конца журнала.)
Снова запустим экземпляр.
Как мы выяснили, контрольная точка — один из процессов, который записывает грязные страницы из буферного кеша на диск. Но не единственный.
Если обслуживающему процессу (backend) потребуется вытеснить страницу из буфера, а страница окажется грязной, ему придется самостоятельно записать ее на диск. Это нехорошая ситуация, приводящая к ожиданиям — гораздо лучше, когда запись происходит асинхронно, в фоновом режиме.
Поэтому в дополнение к процессу контрольной точки (checkpointer) существует также процесс фоновой записи (background writer, bgwriter или просто writer). Этот процесс использует тот же самый алгоритм поиска буферов, что и механизм вытеснения. Отличий по большому счету два.
Записываются буферы, которые одновременно:
Таким образом фоновый процесс записи как бы бежит впереди вытеснения и находит те буферы, которые с большой вероятностью вскоре будут вытеснены. В идеале за счет этого обслуживающие процессы должны обнаружить, что выбранные ими буферы можно использовать, не останавливаясь для записи.
Процесс контрольной точки обычно настраивается из следующих соображений.
Сначала надо определиться, какой объем журнальных файлов мы можем себе позволить сохранять между двумя последовательными контрольными точками (и какое время восстановления нас устраивает). Чем больше, тем лучше, но по понятным причинам это значение будет ограничено.
Далее мы можем посчитать, за какое время при обычной нагрузке будет генерироваться этот объем. Как это делать, мы уже рассматривали (надо запомнить позиции в журнале и вычесть одну из другой).
Это время и будет нашим обычным интервалом между контрольными точками. Записываем его в параметр checkpoint_timeout. Значение по умолчанию — 5 минут — явно слишком мало, обычно время увеличивают, скажем, до получаса. Повторюсь: чем реже можно позволить себе контрольные точки, тем лучше — это сокращает накладные расходы.
Однако возможно (и даже вероятно), что иногда нагрузка будет выше, чем обычная, и за указанное в параметре время будет сгенерирован слишком большой объем журнальных записей. В этом случае хотелось бы выполнять контрольную точку чаще. Для этого в параметре max_wal_size мы указываем общий допустимый объем журнальных файлов. Если фактический объем будет получаться больше, сервер инициирует внеплановую контрольную точку.
Сервер хранит журнальные файлы не только за прошедшую завершенную контрольную точку, но и за текущую еще не завершенную. Поэтому для получения общего объема надо умножать
объем между контрольными точками на (1 + checkpoint_completion_target). А до версии 11 — на (2 + checkpoint_completion_target), поскольку PostgreSQL хранил файлы и за позапрошлую контрольную точку тоже.
Таким образом, большая часть контрольных точек происходит по расписанию: раз в checkpoint_timeout единиц времени. Но при повышенной нагрузке контрольная точка вызывается чаще, при достижении объема max_wal_size.
Важно понимать, что значение max_wal_size может быть превышено:
Для полноты картины — можно установить не только максимальный объем, но и минимальный: параметр min_wal_size. Смысл этой настройки в том, что сервер не удаляет файлы, пока они укладываются по объему в min_wal_size, а просто переименовывает их и использует заново. Это позволяет немного сэкономить на постоянном создании и удалении файлов.
Процесс фоновой записи имеет смысл настраивать после того, как настроена контрольная точка. Совместно эти процессы должны успевать записывать грязные буферы до того, как они потребуются обслуживающим процессам.
Процесс фоновой записи работает циклами максимум по bgwriter_lru_maxpages страниц, засыпая между циклами на bgwriter_delay.
Количество страниц, которые будут записаны за один цикл работы, определяется по среднему количеству буферов, которые запрашивались обслуживающими процессами с прошлого запуска (при этом используется скользящее среднее, чтобы сгладить неравномерность между запусками, но при этом не зависеть от давней истории). Вычисленное количество буферов умножается на коэффициент bgwriter_lru_multiplier (но при любом раскладе не будет превышать bgwriter_lru_maxpages).
Значения по умолчанию: bgwriter_delay = 200ms (скорее всего слишком много, за 1/5 секунды много воды утечет), bgwriter_lru_maxpages = 100, bgwriter_lru_multiplier = 2.0 (пытаемся реагировать на спрос с опережением).
Если процесс совсем не обнаружил грязных буферов (то есть в системе ничего не происходит), он «впадает в спячку», из которой его выводит обращение серверного процесса за буфером. После этого процесс просыпается и опять работает обычным образом.
Настройку контрольной точки и фоновой записи можно и нужно корректировать, получая обратную связь от мониторинга.
Параметр checkpoint_warning выводит предупреждение, если контрольные точки, вызванные переполнением размера журнальных файлов, выполняются слишком часто. Его значение по умолчанию — 30 секунд, и его надо привести в соответствие со значением checkpoint_timeout.
Параметр log_checkpoints (выключеный по умолчанию) позволяет получать в журнале сообщений сервера информацию о выполняемых контрольных точках. Включим его.
Теперь поменяем что-нибудь в данных и выполним контрольную точку.
В журнале сообщений мы увидим примерно такую информацию:
Тут видно, сколько буферов было записано, как изменился состав журнальных файлов после контрольной точки, сколько времени заняла контрольная точка и расстояние (в байтах) между соседними контрольными точками.
Но, наверное, самая полезная информация — это статистика работы процессов контрольной точки и фоновой записи в представлении pg_stat_bgwriter. Представление одно на двоих, потому что когда-то обе задачи выполнялись одним процессом; затем их функции разделили, а представление так и осталось.
Здесь, в числе прочего, мы видим количество выполненных контрольных точек:
Большое значение checkpoint_req (по сравнению с checkpoints_timed) говорит о том, что контрольные точки происходят чаще, чем предполагалось.
Важная информация о количестве записанных страниц:
В хорошо настроенной системе значение buffers_backend должно быть существенно меньше, чем сумма buffers_checkpoint и buffers_clean.
Еще для настройки фоновой записи пригодится maxwritten_clean — это число показывает, сколько раз процесс фоновой записи прекращал работу из-за превышения bgwriter_lru_maxpages.
Сбросить накопленную статистику можно с помощью следующего вызова:
Продолжение.
Нерешенная проблема, на которой мы остановились в прошлый раз, состоит в том, что неизвестно, с какого момента можно начинать проигрывание журнальных записей при восстановлении. Начать с начала, как советовал Король из Алисы, не получится: невозможно хранить все журнальные записи от старта сервера — это потенциально и огромный объем, и такое же огромное время восстановления. Нам нужна такая постепенно продвигающаяся вперед точка, с которой мы можем начинать восстановление (и, соответственно, можем безопасно удалять все предшествующие журнальные записи). Это и есть контрольная точка, о которой сегодня пойдет речь.
Контрольная точка
Каким свойством должна обладать контрольная точка? Мы должны быть уверены, что все журнальные записи, начиная с контрольной точки, будут применяться к страницам, записанным на диск. Если бы это было не так, при восстановлении мы могли бы прочитать с диска слишком старую версию страницы и применить к ней журнальную запись, и тем самым безвозвратно повредили бы данные.
Как получить контрольную точку? Самый простой вариант — периодически приостанавливать работу системы и сбрасывать все грязные страницы буферного и других кешей на диск. (Заметим, что страницы только записываются, но не вытесняются из кеша.) Такие точки будет удовлетворять условию, но, конечно, никто не захочет работать с системой, постоянно замирающей на неопределенное, но весьма существенное время.
Поэтому на практике все несколько сложнее: контрольная точка из точки превращается в отрезок. Сперва мы начинаем контрольную точку. После этого, не прерывая работу и по возможности не создавая пиковых нагрузок, потихоньку сбрасываем грязные буферы на диск.

Когда все буферы, которые были грязными на момент начала контрольной точки, окажутся записанными, контрольная точка считается завершенной. Теперь (но не раньше) мы можем использовать момент начала в качестве той точки, с которой можно начинать восстановление. И журнальные записи вплоть до этого момента нам больше не нужны.

Выполнением контрольной точки занимается специальный фоновый процесс checkpointer.
Продолжительность записи грязных буферов определяется значением параметра checkpoint_completion_target. Он показывает, какую часть времени между двумя соседними контрольными точками будет происходить запись. Значение по умолчанию равно 0.5 (как на рисунках выше), то есть запись занимает половину времени между контрольными точками. Обычно значение увеличивают вплоть до 1.0 для большей равномерности.
Рассмотрим подробнее, что происходит при выполнении контрольной точки.
Сначала процесс контрольной точки сбрасывает на диск буферы статуса транзакций (XACT). Поскольку их немного (всего 128), они записываются сразу же.
Затем начинается основная работа — запись грязных страниц из буферного кеша. Как мы уже говорили, сбросить все страницы одномоментно невозможно, поскольку размер буферного кеша может быть значительным. Поэтому сперва все грязные на текущий момент страницы помечаются в буферном кеше в заголовках специальным флагом.
А затем процесс контрольной точки постепенно проходит по всем буферам и сбрасывает помеченные на диск. Напомним, что страницы не вытесняются из кеша, а только записываются на диск, поэтому не нужно обращать внимания ни на число обращений к буферу, ни на его закрепление.
Помеченные буферы могут также быть записаны и серверными процессами — смотря кто доберется до буфера первым. В любом случае при записи снимается установленный ранее флаг, так что (для целей контрольной точки) буфер будет записан только один раз.
Естественно, в ходе выполнения контрольной точки страницы продолжают изменяться в буферном кеше. Но новые грязные буферы не помечены флагом и процесс контрольной точки не должен их записывать.
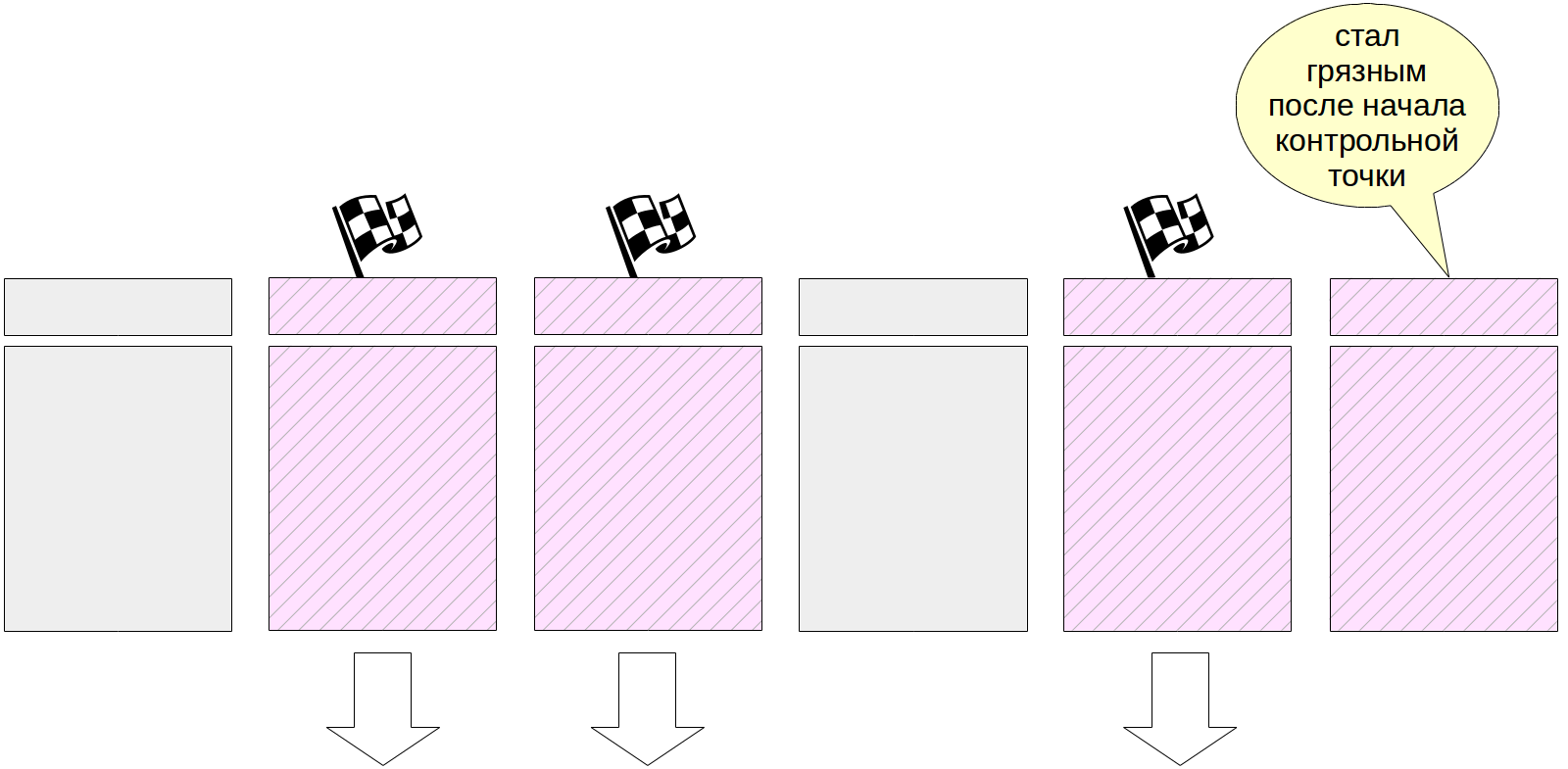
В конце своей работы процесс создает журнальную запись об окончании контрольной точки. В этой записи содержится LSN момента начала работы контрольной точки. Поскольку контрольная точка ничего не записывает в журнал в начале своей работы, по этому LSN может находиться любая журнальная запись.
Кроме того, в файле $PGDATA/global/pg_control обновляется указание на последнюю пройденную контрольную точку. До того, как контрольная точка завершится, pg_control указывает на предыдущую контрольную точку.

Чтобы посмотреть на работу контрольной точки, создадим какую-нибудь таблицу — ее страницы попадут в буферный кеш и будут грязными:
=> CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n);
=> CREATE EXTENSION pg_buffercache;
=> SELECT count(*) FROM pg_buffercache WHERE isdirty;
count
-------
78
(1 row)
Запомним текущую позицию в журнале:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/3514A048
(1 row)
Теперь выполним контрольную точку вручную и убедимся, что в кеше не осталось грязных страниц (как мы говорили, новые грязные страницы могут появляться, но в нашем случае никаких изменений в процессе выполнения контрольной точки не происходило):
=> CHECKPOINT;
=> SELECT count(*) FROM pg_buffercache WHERE isdirty;
count
-------
0
(1 row)
Посмотрим, как контрольная точка отразилась в журнале:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/3514A0E4
(1 row)
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A048 -e 0/3514A0E4
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/3514A048, prev 0/35149CEC, desc: RUNNING_XACTS nextXid 101105 latestCompletedXid 101104 oldestRunningXid 101105
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A07C, prev 0/3514A048, desc: CHECKPOINT_ONLINE redo 0/3514A048; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 101105; online
Здесь мы видим две записи. Последняя из них — запись о прохождении контрольной точки (CHECKPOINT_ONLINE). LSN начала контрольной точки указан после слова redo, и эта позиция соответствует журнальной записи, которая в момент начала контрольной точки была последней.
Ту же информацию мы найдем и в управляющем файле:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | egrep 'Latest.*location'
Latest checkpoint location: 0/3514A07C
Latest checkpoint's REDO location: 0/3514A048
Восстановление
Теперь мы готовы уточнить алгоритм восстановления, намеченный в прошлой статье.
Если в работе сервера произошел сбой, то при последующем запуске процесс startup обнаруживает это, посмотрев в файл pg_control и увидев статус, отличный от «shut down». В этом случае выполняется автоматическое восстановление.
Сначала процесс восстановления прочитает из того же pg_control позицию начала контрольной точки. (Для полноты картины заметим, что, если присутствует файл backup_label, то запись о контрольной точке читается из него — это нужно для восстановления из резервных копий, но это тема для отдельного цикла.)
Далее он будет читать журнал, начиная с найденной позиции, последовательно применяя журнальные записи к страницам (если в этом есть необходимость, как мы уже обсуждали в прошлый раз).
В заключение все нежурналируемые таблицы перезаписываются с помощью образов в init-файлах.
На этом процесс startup завершает работу, а процесс checkpointer тут же выполняет контрольную точку, чтобы зафиксировать на диске восстановленное состояние.
Можно сымитировать сбой, принудительно остановив сервер в режиме immediate.
student$ sudo pg_ctlcluster 11 main stop -m immediate --skip-systemctl-redirect
(Ключ
--skip-systemctl-redirect нужен здесь из-за того, что используется PostgreSQL, установленный в Ubuntu из пакета. Он управляется командой pg_ctlcluster, которая на самом деле вызывает systemctl, а она уже вызывает pg_ctl. Со всеми этими обертками название режима по пути теряется. А ключ --skip-systemctl-redirect позволяет обойтись без systemctl и сохранить важную информацию.)Проверим состояние кластера:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
При запуске PostgreSQL понимает, что произошел сбой и требуется восстановление.
student$ sudo pg_ctlcluster 11 main start
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:49.441 MSK [8865] LOG: database system was interrupted; last known up at 2019-07-17 15:27:48 MSK
2019-07-17 15:27:49.801 MSK [8865] LOG: database system was not properly shut down; automatic recovery in progress
2019-07-17 15:27:49.804 MSK [8865] LOG: redo starts at 0/3514A048
2019-07-17 15:27:49.804 MSK [8865] LOG: invalid record length at 0/3514A0E4: wanted 24, got 0
2019-07-17 15:27:49.804 MSK [8865] LOG: redo done at 0/3514A07C
2019-07-17 15:27:49.824 MSK [8864] LOG: database system is ready to accept connections
2019-07-17 15:27:50.409 MSK [8872] [unknown]@[unknown] LOG: incomplete startup packet
Необходимость восстановления отмечается в журнале сообщений: database system was not properly shut down; automatic recovery in progress. Затем начинается проигрывание журнальных записей с позиции, отмеченной в «redo starts at» и продолжается до тех пор, пока удается получать следующие журнальные записи. На этом восстановление завершается в позиции «redo done at» и СУБД начинает работать с клиентами (database system is ready to accept connections).
А что происходит при нормальной остановке сервера? Чтобы сбросить грязные страницы на диск, PostgreSQL отключает всех клиентов и затем выполняет финальную контрольную точку.
Запомним текущую позицию в журнале:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn
---------------------------
0/3514A14C
(1 row)
Теперь аккуратно останавливаем сервер:
student$ sudo pg_ctlcluster 11 main stop
Проверим состояние кластера:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: shut down
А в журнале обнаружим единственную запись о финальной контрольной точке (CHECKPOINT_SHUTDOWN):
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A14C
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A14C, prev 0/3514A0E4, desc: CHECKPOINT_SHUTDOWN redo 0/3514A14C; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown
pg_waldump: FATAL: error in WAL record at 0/3514A14C: invalid record length at 0/3514A1B4: wanted 24, got 0
(Страшным фатальным сообщением pg_waldump всего-навсего хочет сказать о том, что дочитал до конца журнала.)
Снова запустим экземпляр.
student$ sudo pg_ctlcluster 11 main start
Фоновая запись
Как мы выяснили, контрольная точка — один из процессов, который записывает грязные страницы из буферного кеша на диск. Но не единственный.
Если обслуживающему процессу (backend) потребуется вытеснить страницу из буфера, а страница окажется грязной, ему придется самостоятельно записать ее на диск. Это нехорошая ситуация, приводящая к ожиданиям — гораздо лучше, когда запись происходит асинхронно, в фоновом режиме.
Поэтому в дополнение к процессу контрольной точки (checkpointer) существует также процесс фоновой записи (background writer, bgwriter или просто writer). Этот процесс использует тот же самый алгоритм поиска буферов, что и механизм вытеснения. Отличий по большому счету два.
- Используется не указатель на «следующую жертву», а свой собственный. Он может опережать указатель на «жертву», но никогда не отстает от него.
- При обходе буферов счетчик обращений не уменьшается.
Записываются буферы, которые одновременно:
- содержат измененные данные (грязные),
- не закреплены (pin count = 0),
- имеют нулевое число обращений (usage count = 0).
Таким образом фоновый процесс записи как бы бежит впереди вытеснения и находит те буферы, которые с большой вероятностью вскоре будут вытеснены. В идеале за счет этого обслуживающие процессы должны обнаружить, что выбранные ими буферы можно использовать, не останавливаясь для записи.
Настройка
26.05.2020 — в раздел внесены уточнения. Спасибо stegmatic, указавшему на ошибку.
Процесс контрольной точки обычно настраивается из следующих соображений.
Сначала надо определиться, какой объем журнальных файлов мы можем себе позволить сохранять между двумя последовательными контрольными точками (и какое время восстановления нас устраивает). Чем больше, тем лучше, но по понятным причинам это значение будет ограничено.
Далее мы можем посчитать, за какое время при обычной нагрузке будет генерироваться этот объем. Как это делать, мы уже рассматривали (надо запомнить позиции в журнале и вычесть одну из другой).
Это время и будет нашим обычным интервалом между контрольными точками. Записываем его в параметр checkpoint_timeout. Значение по умолчанию — 5 минут — явно слишком мало, обычно время увеличивают, скажем, до получаса. Повторюсь: чем реже можно позволить себе контрольные точки, тем лучше — это сокращает накладные расходы.
Однако возможно (и даже вероятно), что иногда нагрузка будет выше, чем обычная, и за указанное в параметре время будет сгенерирован слишком большой объем журнальных записей. В этом случае хотелось бы выполнять контрольную точку чаще. Для этого в параметре max_wal_size мы указываем общий допустимый объем журнальных файлов. Если фактический объем будет получаться больше, сервер инициирует внеплановую контрольную точку.
Сервер хранит журнальные файлы не только за прошедшую завершенную контрольную точку, но и за текущую еще не завершенную. Поэтому для получения общего объема надо умножать
объем между контрольными точками на (1 + checkpoint_completion_target). А до версии 11 — на (2 + checkpoint_completion_target), поскольку PostgreSQL хранил файлы и за позапрошлую контрольную точку тоже.
Таким образом, большая часть контрольных точек происходит по расписанию: раз в checkpoint_timeout единиц времени. Но при повышенной нагрузке контрольная точка вызывается чаще, при достижении объема max_wal_size.
Важно понимать, что значение max_wal_size может быть превышено:
- Параметр max_wal_size — только пожелание, но не жесткое ограничение. Может получиться и больше.
- Сервер не имеет права стереть журнальные файлы, еще не переданные через слоты репликации, и еще не записанные в архив при непрерывном архивировании. Если этот функционал используется, необходим постоянный мониторинг, потому что можно легко переполнить память сервера.
Для полноты картины — можно установить не только максимальный объем, но и минимальный: параметр min_wal_size. Смысл этой настройки в том, что сервер не удаляет файлы, пока они укладываются по объему в min_wal_size, а просто переименовывает их и использует заново. Это позволяет немного сэкономить на постоянном создании и удалении файлов.
Процесс фоновой записи имеет смысл настраивать после того, как настроена контрольная точка. Совместно эти процессы должны успевать записывать грязные буферы до того, как они потребуются обслуживающим процессам.
Процесс фоновой записи работает циклами максимум по bgwriter_lru_maxpages страниц, засыпая между циклами на bgwriter_delay.
Количество страниц, которые будут записаны за один цикл работы, определяется по среднему количеству буферов, которые запрашивались обслуживающими процессами с прошлого запуска (при этом используется скользящее среднее, чтобы сгладить неравномерность между запусками, но при этом не зависеть от давней истории). Вычисленное количество буферов умножается на коэффициент bgwriter_lru_multiplier (но при любом раскладе не будет превышать bgwriter_lru_maxpages).
Значения по умолчанию: bgwriter_delay = 200ms (скорее всего слишком много, за 1/5 секунды много воды утечет), bgwriter_lru_maxpages = 100, bgwriter_lru_multiplier = 2.0 (пытаемся реагировать на спрос с опережением).
Если процесс совсем не обнаружил грязных буферов (то есть в системе ничего не происходит), он «впадает в спячку», из которой его выводит обращение серверного процесса за буфером. После этого процесс просыпается и опять работает обычным образом.
Мониторинг
Настройку контрольной точки и фоновой записи можно и нужно корректировать, получая обратную связь от мониторинга.
Параметр checkpoint_warning выводит предупреждение, если контрольные точки, вызванные переполнением размера журнальных файлов, выполняются слишком часто. Его значение по умолчанию — 30 секунд, и его надо привести в соответствие со значением checkpoint_timeout.
Параметр log_checkpoints (выключеный по умолчанию) позволяет получать в журнале сообщений сервера информацию о выполняемых контрольных точках. Включим его.
=> ALTER SYSTEM SET log_checkpoints = on;
=> SELECT pg_reload_conf();
Теперь поменяем что-нибудь в данных и выполним контрольную точку.
=> UPDATE chkpt SET n = n + 1;
=> CHECKPOINT;
В журнале сообщений мы увидим примерно такую информацию:
postgres$ tail -n 2 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:55.248 MSK [8962] LOG: checkpoint starting: immediate force wait
2019-07-17 15:27:55.274 MSK [8962] LOG: checkpoint complete: wrote 79 buffers (0.5%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.001 s, sync=0.013 s, total=0.025 s; sync files=2, longest=0.011 s, average=0.006 s; distance=1645 kB, estimate=1645 kB
Тут видно, сколько буферов было записано, как изменился состав журнальных файлов после контрольной точки, сколько времени заняла контрольная точка и расстояние (в байтах) между соседними контрольными точками.
Но, наверное, самая полезная информация — это статистика работы процессов контрольной точки и фоновой записи в представлении pg_stat_bgwriter. Представление одно на двоих, потому что когда-то обе задачи выполнялись одним процессом; затем их функции разделили, а представление так и осталось.
=> SELECT * FROM pg_stat_bgwriter \gx
-[ RECORD 1 ]---------+------------------------------
checkpoints_timed | 0
checkpoints_req | 1
checkpoint_write_time | 1
checkpoint_sync_time | 13
buffers_checkpoint | 79
buffers_clean | 0
maxwritten_clean | 0
buffers_backend | 42
buffers_backend_fsync | 0
buffers_alloc | 363
stats_reset | 2019-07-17 15:27:49.826414+03
Здесь, в числе прочего, мы видим количество выполненных контрольных точек:
- checkpoints_timed — по расписанию (по достижению checkpoint_timeout),
- checkpoints_req — по требованию (в том числе по достижению max_wal_size).
Большое значение checkpoint_req (по сравнению с checkpoints_timed) говорит о том, что контрольные точки происходят чаще, чем предполагалось.
Важная информация о количестве записанных страниц:
- buffers_checkpoint — процессом контрольной точки,
- buffers_backend — обслуживающими процессами,
- buffers_clean — процессом фоновой записи.
В хорошо настроенной системе значение buffers_backend должно быть существенно меньше, чем сумма buffers_checkpoint и buffers_clean.
Еще для настройки фоновой записи пригодится maxwritten_clean — это число показывает, сколько раз процесс фоновой записи прекращал работу из-за превышения bgwriter_lru_maxpages.
Сбросить накопленную статистику можно с помощью следующего вызова:
=> SELECT pg_stat_reset_shared('bgwriter');
Продолжение.
