Для будущих студентов курса "PostgreSQL" подготовили перевод полезной статьи.
Также приглашаем всех желающих на открытое демо-занятие «Проблемы миграции данных». На вебинаре мы:
— Поговорим о видах миграции и способах их реализации;
— Разберем основные проблемы, связанные с миграцией данных и пути их устранения;
— Рассмотрим несколько реальных практических кейсов и порассуждаем над эффективностью их решения;
— Вспомним программные средства, позволяющие автоматизировать процесс миграции данных.

В наших предыдущих статьях о гибридных облаках (Hybrid Cloud) мы часто говорили, что один из основных вариантов их использования — это аварийное восстановление. Любые неожиданные аварии могут сильно повлиять на бизнес, поэтому не забывайте о DRP-планах (disaster recovery plan, план аварийного восстановления). Уделите этому моменту достаточно внимания. DRP-план проектируется под вашу конкретную систему в соответствии с требованиями приложений, инфраструктуры и бизнеса. Эффективность решения оценивается по времени восстановления системы после аварии.
Планирование непрерывности бизнеса (Business Continuity), в свою очередь, должно включать в себя тестирование DRP-плана и проверку его функционирования. Решения по восстановлению баз данных должны обеспечивать непрерывную работу и соответствовать ожиданиям и требованиям RTO и RPO. Продуктивные базы данных должны быть доступны даже в случае аварии: простои могут стоить вам очень дорого. Администраторы и архитекторы должны обеспечить доступность и соответствие SLA по восстановлению. Аварийные ситуации не должны влиять на доступность баз данных и непрерывность бизнеса.
Обеспечение аварийного восстановления
К настройке кластера необходимо подходить системно, с учетом лучших практик и отраслевых стандартов. А также убедиться, что в вашем решении присутствуют следующие элементы:
Failover и Switchover
Автоматическое резервное копирование
Высокая доступность (High Availability)
Балансировка нагрузки (Load Balancing)
Распределенное окружение (Highly Distributed Environment)
Failover и Switchover
Failover — это автоматическое переключение с основного сервера на резервный в случае аварии. Горячий (hot standby) или теплый (warm standby) резервный сервер повышается (promote) до роли первичного (primary) / основного (master). Для обеспечения высокой доступности должен присутствовать хотя бы один вторичный сервер, который может заменить упавший. Если основной сервер выходит из строя, то резервный начинает отработку failover и берет на себя роль главного. Обычно используется как минимум два сервера, один из которых главный, а другой резервный. Для проверки работоспособности кластера используется механизм heartbeat (сердцебиение): состояние узлов и связь между ними непрерывно тестируется. Однако в некоторых ситуациях может сработать ложная тревога. Поэтому иногда для мониторинга используют третий узел, который находится в отдельной сети или в отдельном датацентре. Такое решение более надежно и предотвращает ошибочный failover. На третий узел также могут быть возложены дополнительные функции и проверки. Подобная конфигурация требует полноценного и тщательного тестирования работоспособности failover.
В идеале у основного и резервного узла/кластера должны быть одинаковые характеристики производительности. Если резервные узлы находятся в публичном облаке, а основной — локально, то убедитесь, что вы учли этот момент при планировании мощностей и ресурсов, чтобы избежать нежелательных последствий.
При настройке failover в гибридном облаке убедитесь, что используете подходящие инструменты. Для реализации failover используются сторонние инструменты, не входящие в состав PostgreSQL, такие как ClusterControl, pg_auto_failover от CitusData (куплен Microsoft), Pgpool-II, Bucardo и другие. Все они обеспечивают изоляцию узлов (node fencing), также известную как STONITH (Shoot The Other Node In The Head). Это гарантирует, что вышедший из строя узел не будет принимать запросы на изменения и не вернется в рабочее состояние в роли основного сервера. Эта проблема широко известна как split-brain.
Автоматическое резервное копирование
Резервное копирование помогает минимизировать потерю данных в случае аварии. При выборе решения следует продумать и подготовить: инфраструктуру для резервного копирования, избыточность и безопасность резервных копий, производительность и скорость хранилища данных.
Инфраструктура резервного копирования
Для инфраструктуры резервного копирования вы должны выбрать лучший из доступных вам вариантов. Обращайте внимание на скорость, объем хранилища и высокую доступность. Популярным вариантом является SAN или NAS, а также использование сторонних провайдеров для хранения данных. Очень важно, чтобы решение обеспечивало высокую скорость записи и чтения, особенно при использовании сжатия и шифрования, так как для декомпрессии и дешифрования требуются ресурсы, что следует учитывать при восстановлении. На этом этапе вы должны определить максимальное значение RPO, которое можете достичь, а также согласовать с вашими клиентами достижимый SLA. В идеале следует хранить резервную копию удаленно за пределами вашей локальной сети или привлечь сторонних провайдеров. Например, хранить резервные копии в облаках. Для этого есть множество решений и вариантов.
Избыточность резервных копий
Разместить данные в нескольких местах — очень хорошее решение. Это увеличит ваши шансы на восстановление данных при случайном удалении нужных резервных копий из-за человеческой или программной ошибки. Некоторые облачные сервисы, такие как Amazon S3, Google Cloud Storage и Azure Blob Storage, предлагают репликацию хранилищ. Это обеспечивает дополнительную избыточность и гибко настраивается в соответствии с вашими требованиями.
Высокая доступность
Высокодоступный кластер PostgreSQL в гибридном облаке обеспечивает бесперебойную работу вашей базы данных. Степень высокой доступности можно посчитать и измерить. Кластер PostgreSQL в публичном облаке может использоваться как резервный. И иногда он может быть менее производительным, чем основной. Приложение может учитывать это и ограничивать клиентов или трафик, который идет к базе данных. Такое решение позволяет снизить расходы. Но все, конечно, зависит от ваших конкретных условий. Если у вас много пользователей и большой постоянный трафик, то для обеспечения доступности 99,9999999% необходимо убедиться, что ресурсы вторичного кластера соответствуют первичному. Для клиентов очень важно, чтобы не было потери функциональности или она была минимальной.
Балансировка нагрузки
Балансировка нагрузки позволяет получить более управляемую конфигурацию и уменьшить риски, особенно при появлении высокой нагрузки, с которой сервер не справляется, что приводит к переходу сервера в нерабочее состояние. Эту ситуацию можно исправить, оптимизировав плохие запросы и архитектуру базы данных. Также необходимо распределить нагрузку по чтению и записи, и хорошо понимать требования вашего приложения, такие как необходимость "мастер-мастер" репликации или "только мастер", но с вертикальным масштабированием для повышения производительности. Есть также большой выбор сторонних инструментов, таких как pgbouncer и Pgpool II, которые помогут вам развернуть PostgreSQL в гибридном облаке.
Распределенное окружение
Распределение резервных копий по разным хранилищам и облачным провайдерам обеспечивает большую гибкость и надежность. Гибкость заключается в том, что можно переключаться на сервера в нужном регионе, не затронутым аварией. Это важный момент, который вы должны понимать и быть готовым. Приложение и клиенты должны обслуживаться непрерывно, без простоев. Такой подход добавляет сложности и требует углубленных знаний в области баз данных, информационной безопасности и сетей. Здесь решающее значение имеют оптимизация и настройка, поскольку очень важно, чтобы при обеспечении безопасности данных, отправляемых через Интернет, не ухудшилась производительность.
Для развертывания и управления базами данных в таких сложных конфигурациях помогают инструменты, охватывающие все аспекты вашего кластера на всех уровнях, начиная с локального, частного облака, заканчивая публичным.
Использование ClusterControl для гибридного облака
ClusterControl позволяет гибко управлять базами данных и упростить настройку. Он управляет failover'ом, автоматическим резервным копированием, параметрами высокой доступности, балансировкой нагрузки и распределенным развертыванием, что упрощает добавление узлов в публичное, частное облако, а также в локальное развертывание.
ClusterControl Auto Recovery
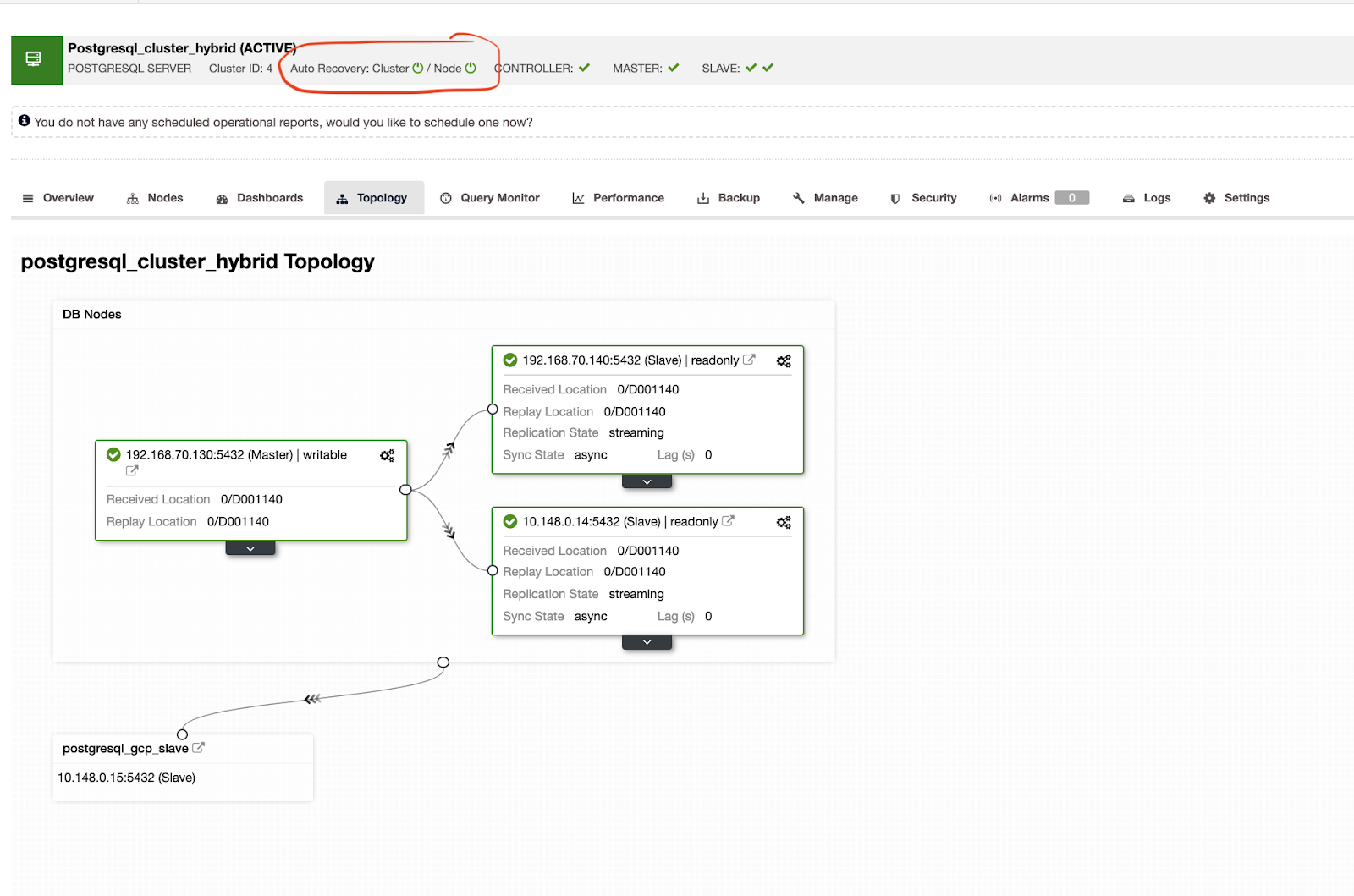
Auto Recovery (автоматическое восстановление) в ClusterControl представляет собой множество механизмов failover и параметров восстановления, особенно при падении узла или деградации кластера. Настраивается все очень легко — смотрите скриншот ниже.
Резервное копирование и восстановление
В ClusterControl также есть функции управления резервным копированием и восстановлением, которые позволяют вам создавать резервные копии, задавать расписание резервного копирования и восстанавливать базы данных. Также есть варианты резервного копирования в облако, что позволяет иметь избыточные резервные копии, повышая надежность решения.

Как вы видите, в ClusterControl простой пользовательский интерфейс, позволяющий выбрать резервную копию для восстановления или удаления. Также есть возможность управления периодом хранения (retention period).

Поддержка высокой доступности и балансировки нагрузки
Вам не нужно вручную настраивать или даже изучать настройку высокой доступности кластера PostgreSQL. В ClusterControl есть простой и удобный интерфейс. На скриншоте ниже вы можете увидеть настройки для HAProxy и Keepalived.
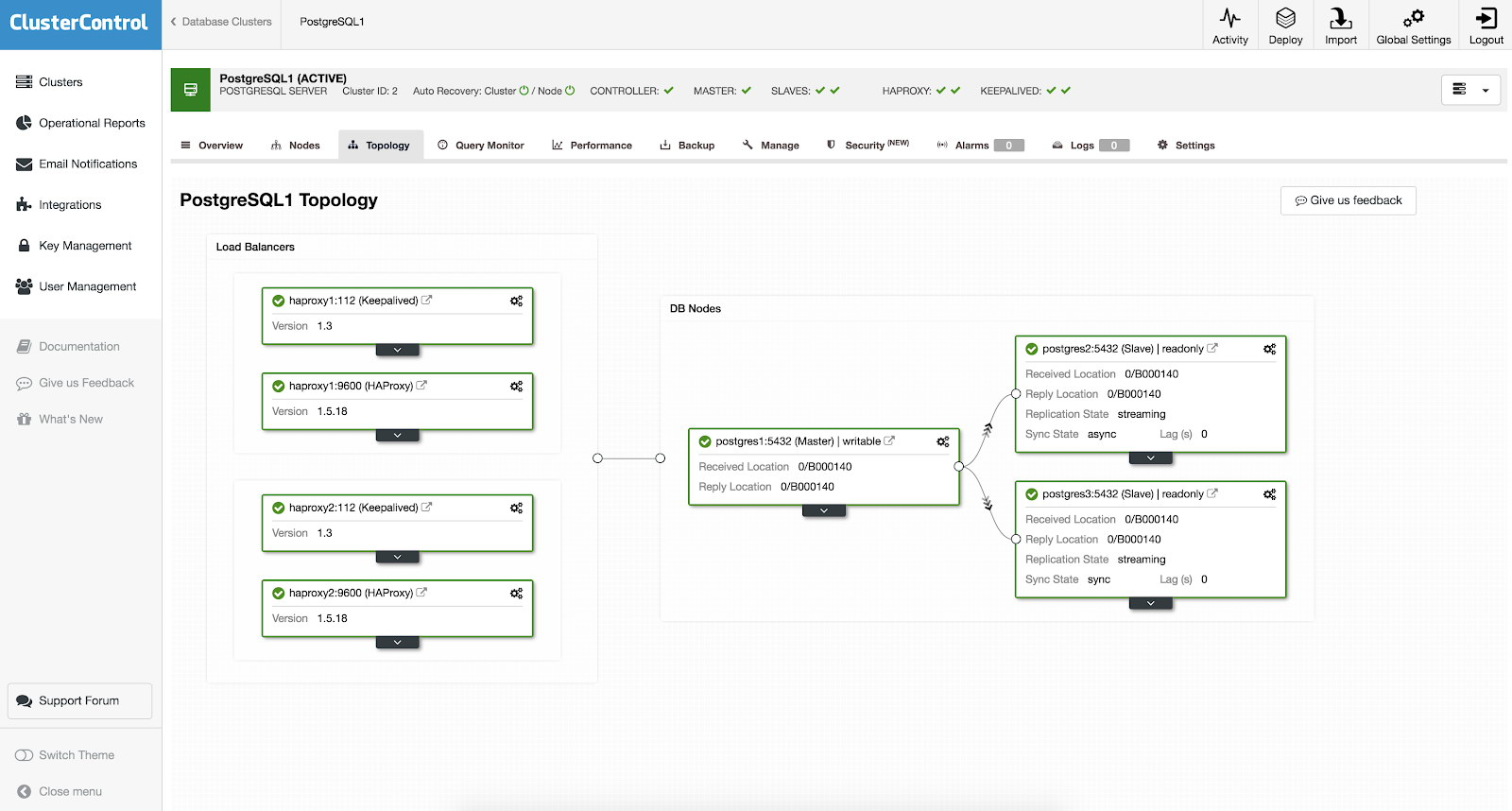
Настроить высокую доступность в ClusterControl можно, выбрав: <Ваш_кластер> → Manage → Load Balancer.
Поддержка распределенных окружений
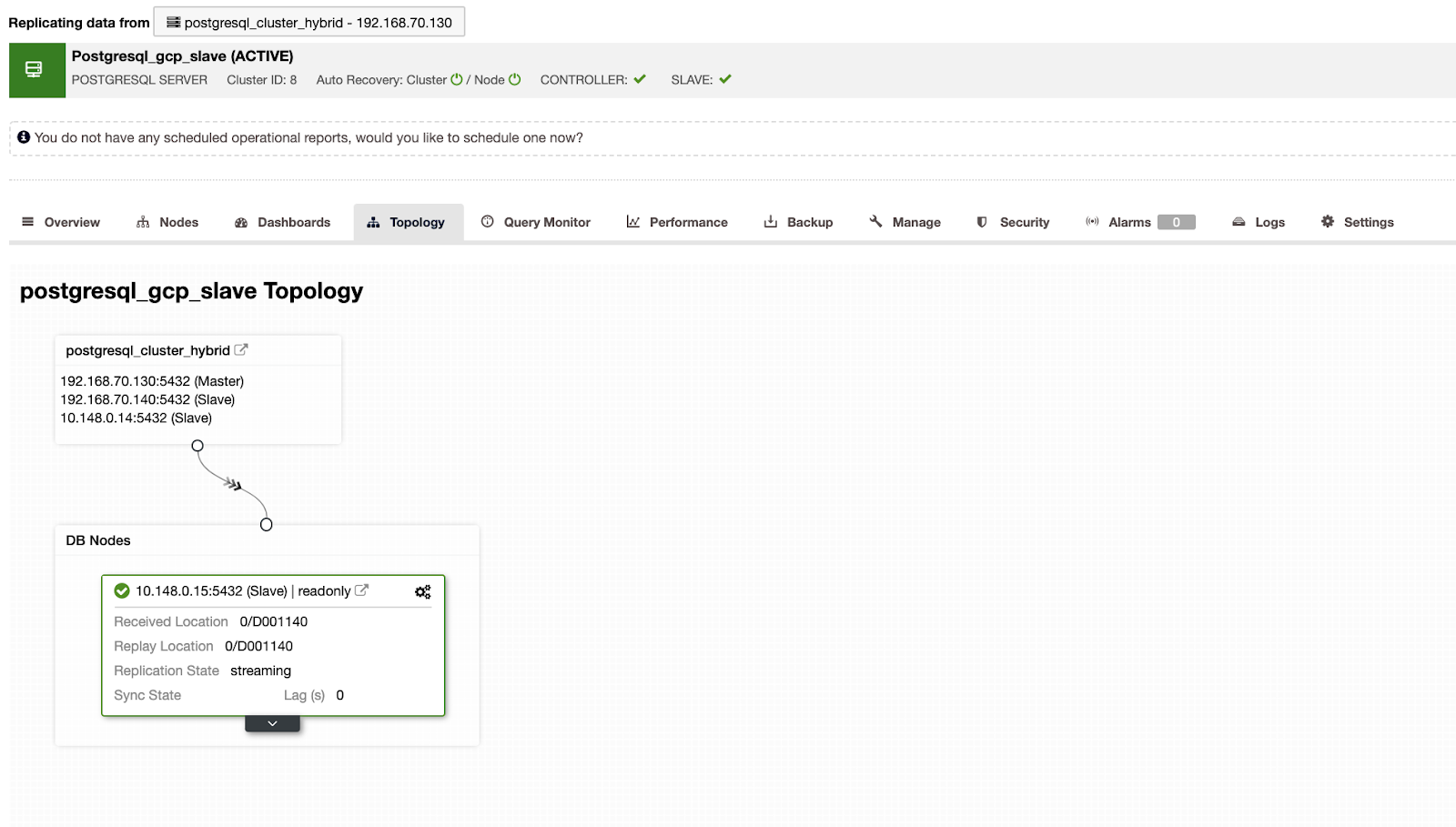
ClusterControl также поддерживает развертывание в облаках. Для кластера PostgreSQL вы можете развернуть вторичный кластер (Create Slave Cluster) в другом облаке, как показано ниже.

Получится следующий результат.

При настройке гибридного облака ClusterControl также покажет вам топологию вашего кластера:

Видно, что вторичный кластер расположен в отдельной сети в Google Cloud, тогда как master находится локально.
Заключение
Гибридное облако усложняет архитектуру решения, поэтому для управления резервными копиями и высокой доступностью необходимо использовать удобные инструменты.
Это очень важно, чтобы уберечь ваш бизнес от потенциальной катастрофы и избежать финансового ущерба с потерей доверия клиентов. Инвестируйте в правильные инструменты и навыки, и вы защитите бизнес от негативного воздействия.
Узнать подробнее о курсе "PostgreSQL"
Смотреть вебинар «Проблемы миграции данных»
