В преддверии старта курса "Machine Learning. Professional" публикуем перевод полезной статьи.
Также приглашаем посмотреть запись открытого вебинара по теме "Кластеризация".
Отбор признаков – это важная задача для любого приложения с машинным обучением. Особенно важно, когда данные, о которых идет речь, имеют много признаков. Оптимальное количество признаков повышает точность модели. Выделить наиболее важные признаки и найти количество оптимальных можно с помощью определения важности признаков или их ранжирования. В этой статье мы познакомимся с ранжированием признаков.
Recursive Feature Elimination
Первым элементом, необходимым для рекурсивного исключения признаков (recursive feature elimination), является оценщик, например, линейная модель или дерево решений.
У таких моделей есть коэффициенты для линейных моделей и важности признаков в деревьях решений. Для выбора оптимального количества признаков нужно обучить оценщика и выбрать признаки с помощью коэффициентов или значений признаков. Наименее важные признаки будут удаляться. Этот процесс будет повторяться рекурсивно о тех пор, пока не будет получено оптимальное число признаков.
Применение в Sklearn
В Scikit-learn можно применить рекурсивное исключение признаков с помощью класса sklearn.featureselection.RFE. Класс принимает следующие параметры:
estimator– оценщик машинного обучения, который может выдать важность признаков за счет атрибутовcoefилиfeatureimportances attributes.nfeaturestoselect– количество признаков для выбора. Отбирает половину по умолчанию.step– целое число, указывает количество признаков, которые будут удалены на каждой итерации, или число в диапазоне от 0 до 1, указывающее процент признаков, подлежащих удалению на каждой итерации.
После обучения можно получить следующие атрибуты:
ranking— ранжирование признаков.nfeatures— количество выбранных признаков.support— массив, указывающий, был выбран признак или нет.
Применение
Как уже было сказано ранее, мы будем работать с оценщиком, который предлагает атрибуты featureimportances или coeff. Давайте рассмотрим небольшой пример. Изначально в наборе данных 13 признаков. Мы будем работать над выделением оптимального количества признаков.
import pandas as pddf = pd.read_csv(‘heart.csv’)df.head()
Давайте получим признаки x и y.
X = df.drop([‘target’],axis=1)
y = df[‘target’]Мы разделим изначальный набор данных на тестовый и обучающий наборы:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,random_state=0)Сделаем несколько импортов:
Pipeline– в помощь для кросс-валидации, поможет избежать утечки данных.RepeatedStratifiedKFold– для многократной k-блочной кросс-валидации.crossvalscore– для скоринга кросс-валидации.GradientBoostingClassifier– оценщик, который мы будем использовать.Numpy– для вычисления среднего всех оценок.
from sklearn.pipeline import Pipeline
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import RFE
import numpy as np
from sklearn.ensemble import GradientBoostingClassifierПервым шагом мы создаем экземпляр класса RFE с указанием оценщика и количества признаков, которые будут отобраны. В нашем случае выберем 6:
rfe = RFE(estimator=GradientBoostingClassifier(), n_features_to_select=6)Далее мы создаем экземпляр модели, которую хотим использовать:
model = GradientBoostingClassifier()Мы используем Pipeline для преобразования данных. В Pipeline мы указываем rfe для шага отбора признаков и модель, которая будет использоваться на следующем шаге.
Затем мы задаем RepeatedStratifiedKFold с 10 сплитами и 5 повторениями. Многократная k-блочная кросс-валидация гарантирует, что количество сэмплов каждого класса будет сбалансированным в каждом блоке. RepeatedStratifiedKFold использует многократную k-блочную кросс-валидацию заданное количество раз с различной рандомизацией на каждом повторении.
pipe = Pipeline([(‘Feature Selection’, rfe), (‘Model’, model)])
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=5, random_state=36851234)
n_scores = cross_val_score(pipe, X_train, y_train, scoring=’accuracy’, cv=cv, n_jobs=-1)
np.mean(n_scores)Следующий шаг — это использование пайплайна на наборе данных.
pipe.fit(X_train, y_train)Так мы сможем проверить support и ранжирование. Support указывает на то был выбран признак или нет.
rfe.support_
array([ True, False, True, False, True, False, False, True, False,True, False, True, True])Мы можем поместить это в датафрейм и посмотреть результат.
pd.DataFrame(rfe.support_,index=X.columns,columns=[‘Rank’])
Также можем посмотреть относительное ранжирование.
rf_df = pd.DataFrame(rfe.ranking_,index=X.columns,columns=[‘Rank’]).sort_values(by=’Rank’,ascending=True)rf_df.head()
Автоматический отбор признаков
Вместо того, чтобы вручную настраивать количество признаков, было бы неплохо, если бы мы могли делать это автоматически. Вы можете достичь этого с помощью рекурсивного исключения признаков и кросс-валидации. Здесь вам поможет класс sklearn.featureselection.RFECV. Он принимает следующие параметры:
estimator– аналог класса RFE.minfeaturestoselect— минимальное количество признаков для отбора.cv— стратегия разделения для кросс-валидации.
Возвращаемые атрибуты:
nfeatures— оптимальное количество признаков, выбранных с помощью кросс-валидации.support— массив, содержащий информацию о выборе признака.ranking— ранжирование признаков.gridscores— оценка, полученная в результате кросс-валидации.
Первым шагом нужно импортировать класс и создать его экземпляр.
from sklearn.feature_selection import RFECVrfecv = RFECV(estimator=GradientBoostingClassifier())Далее мы определяем пайплайн и cv. В этом пайплайне мы используем только что созданный rfecv.
pipeline = Pipeline([(‘Feature Selection’, rfecv), (‘Model’, model)])
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=5, random_state=36851234)
n_scores = cross_val_score(pipeline, X_train, y_train, scoring=’accuracy’, cv=cv, n_jobs=-1)
np.mean(n_scores)Теперь применяем пайплайн и получаем оптимальное количество признаков.
pipeline.fit(X_train,y_train)Оптимальное количество признаков можно получить с помощью атрибута nfeatures.
print(“Optimal number of features : %d” % rfecv.n_features_)Optimal number of features : 7Ранжирование и support можно получить также, как и в прошлый раз.
rfecv.support_rfecv_df = pd.DataFrame(rfecv.ranking_,index=X.columns,columns=[‘Rank’]).sort_values(by=’Rank’,ascending=True)
rfecv_df.head()С помощью gridscores мы можем построить график с оценками, полученными при кросс-валидации.
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
plt.xlabel(“Number of features selected”)
plt.ylabel(“Cross validation score (nb of correct classifications)”)
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show()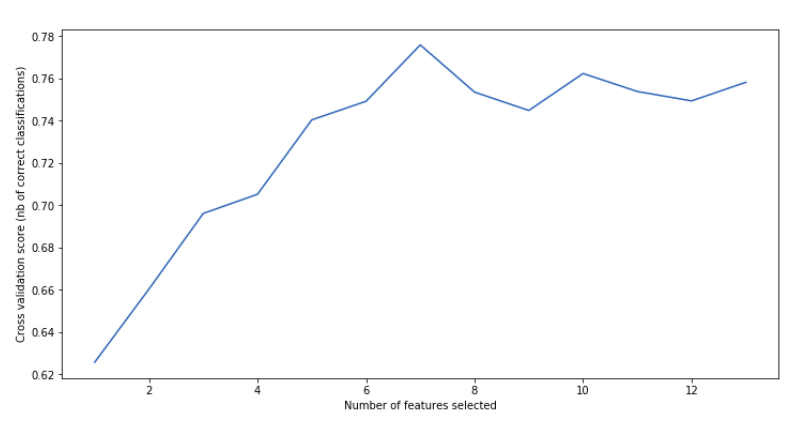
Заключение
В задачах регрессии этот метод применяется аналогично. Просто используйте регрессионные показатели вместо показателей точности. Надеюсь, эта статья дала вам некоторое представление о том, как можно выбрать оптимальное количество признаков для ваших задач машинного обучения.
Узнать подробнее о курсе "Machine Learning. Professional" и посмотреть урок по теме "Кластеризация" можно здесь.
