Перевод статьи подготовлен в преддверии старта курса «MS SQL Server Developer».

Может ли запрос, выполняющийся параллельно, использовать меньше CPU и выполняться быстрее, чем такой же запрос, выполняющийся последовательно?
Да! Для демонстрации я буду использовать две таблицы с одной колонкой типа

Примечание — TSQL скрипт в виде текста находится в конце статьи.
В таблицу
В таблицу

Теперь напишем запрос для подсчета количества совпадений значений в этих таблицах. Используем хинт MAXDOP 1, чтобы быть уверенным, что запрос не будет выполняться параллельно.
Вот его план выполнения и статистика:

Этот запрос выполняется за 891 мс и использует 890 мс CPU.
Теперь запустим тот же запрос с MAXDOP 2.
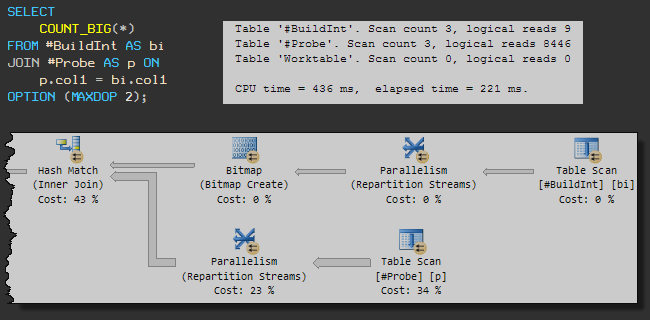
Запрос выполняется 221 мс и использует 436 мс CPU. Время выполнения уменьшилось в четыре раза, а использование CPU в два!
Причина, по которой параллельное выполнение запроса намного эффективнее, заключается в операторе Bitmap (битовая карта).
Давайте внимательно посмотрим на фактический план выполнения параллельного запроса:

И сравним его с последовательным планом:

Принцип работы оператора Bitmap достаточно хорошо документирован, поэтому здесь я приведу только краткое описание со ссылками на документацию в конце статьи.
Соединение хешированием (hash join) выполняется в два этапа:
Естественно, из-за возможных коллизий хеша, необходимо по-прежнему сравнивать реальные значения ключей.
Многие не знают, что Hash Match, даже в последовательных запросах, всегда использует битовую карту. Но в таком плане вы не увидите ее явно, потому что она является частью внутренней реализации оператора Hash Match.
HASH JOIN на этапе построения (build) и создания хеш-таблицы устанавливает один (или несколько) битов в битовой карте. После этого с помощью битовой карты можно эффективно проверять совпадения значений хеша без затрат на обращение к хеш-таблице.
При последовательном плане для каждой строки второй таблицы вычисляется хэш и проверяется по битовой карте. Если соответствующие биты в битовой карте установлены, то в хэш-таблице может быть совпадение, поэтому далее проверяется хеш-таблица. И наоборот, если ни один из битов, соответствующих значению хеша, не установлен, то мы можем быть уверены, что в хэш-таблице совпадений нет, и можно сразу отбросить проверяемую строку.
Относительно небольшие затраты на построение битовой карты компенсируются экономией времени на отсутствие проверок строк, для которых точно нет совпадений в хеш-таблице. Такая оптимизация часто оказывается эффективной, так как проверка битовой карты значительно быстрее проверки хеш-таблицы.
В параллельном плане битовая карта отображается как отдельный оператор Bitmap.
При переходе от этапа построения к этапу проверки битовая карта передается оператору HASH MATCH со стороны второй (проверяемой, probe) таблицы. Как минимум, битовая карта передается на сторону probe перед JOIN и оператором обмена (Parallelism).
Здесь битовая карта может исключить строки, которые не удовлетворяют условию соединения, до того, как они будут переданы в оператор обмена.
Конечно, в последовательных планах операторы обмена отсутствуют, поэтому такое перемещение битовой карты за пределы HASH JOIN не даст никаких дополнительных преимуществ по сравнению со «встроенной» битовой картой внутри оператора HASH MATCH.
В некоторых ситуациях (хотя и только в параллельном плане) оптимизатор может переместить Bitmap еще дальше вниз по плану на probe-стороне соединения.
Идея здесь заключается в том, что чем раньше строки будут отфильтрованы, тем меньше затрат потребуется на перемещение данных между операторами и, возможно, даже получится исключить некоторые операции.
Также оптимизатор, как правило, старается разместить простые фильтры как можно ближе к «листьям»: наиболее эффективно фильтровать строки как можно раньше. Однако я должен упомянуть, что битовая карта, о которой мы говорим, добавляется после завершения оптимизации.
Решение о добавлении этого (статического) типа битовой карты в план после оптимизации принимается на основе ожидаемой селективности фильтра (поэтому важна точная статистика).
Вернемся к концепции перемещения bitmap-фильтра на probe-сторону соединения.
Во многих случаях bitmap-фильтр может быть перемещен в оператор Scan или Seek. Когда это происходит, то предикат в плане выглядит следующим образом:

Он применяется ко всем строкам, которые соответствуют seek-предикату (для Index Seek) или ко всем строкам для Index Scan или Table Scan. Например, на скриншоте выше показан bitmap-фильтр, примененный к Table Scan для heap-таблицы.
Если bitmap-фильтр построен на одном столбце или выражении типа integer или bigint, и применяется к одному столбцу типа integer или bigint, то оператор Bitmap может быть перемещен еще ниже по плану, даже дальше, чем операторы Seek или Scan.
Предикат по-прежнему будет отображаться в операторах Scan или Seek, как в примере выше, но теперь он будет помечен атрибутом INROW, что означает перемещение фильтра в Storage Engine и его применение к строкам при их чтении.
При такой оптимизации строки фильтруются еще до того, как Query Processor увидит эту строку. Из Storage Engine передаются только те строки, которые соответствуют HASH MATCH JOIN.
Условия при которых применяется такая оптимизация зависит от версии SQL Server. Например, в SQL Server 2005, в дополнение к условиям, указанным ранее, проверяемый столбец (probe) должен быть определен как NOT NULL. Это ограничение было ослаблено в SQL Server 2008.
Вам может быть интересно, насколько INROW-оптимизация влияет на производительность. Будет ли перенос оператора как можно ближе к Seek или Scan таким же эффективным, как фильтрация в Storage Engine? Я отвечу на этот интересный вопрос в других статьях. А здесь мы еще посмотрим на MERGE JOIN и NESTED LOOP JOIN.
Использование вложенных циклов без индексов — это плохая идея. Мы должны полностью сканировать одну из таблиц для каждой строки из другой таблицы — в общей сложности 5 миллиардов сравнений. Этот запрос, вероятно, будет выполняться очень долго.
Этот тип физического соединения требует отсортированных входных данных, поэтому принудительный MERGE JOIN приводит к тому, что перед ним присутствует сортировка. Последовательный план выглядит следующим образом:

Теперь запрос использует 3105 мс CPU, а общее время выполнения составляет 5632 мс.
Увеличение общего времени выполнения связано с тем, что одна из операций сортировки использует tempdb (несмотря на то, что SQL Server имеет достаточно памяти для сортировки).
Слив в tempdb происходит из-за того, что алгоритм выделения грантов памяти, применяемый по умолчанию, не резервирует заранее достаточное количество памяти. Пока не будем на это обращать внимание, ясно, что запрос не будет завершен менее чем за 3105 мс.
Продолжим форсировать MERGE JOIN, но разрешим параллелизм (MAXDOP 2):
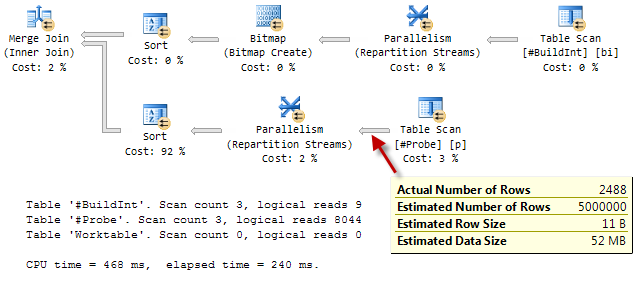
Как и в параллельном HASH JOIN, который мы видели ранее, bitmap-фильтр располагается на другой стороне MERGE JOIN ближе к Table Scan и применяется с использованием INROW-оптимизации.
При 468 мс CPU и 240 мс затраченного времени MERGE JOIN с дополнительными сортировками работает почти так же быстро, как и параллельный HASH JOIN (436 мс / 221 мс).
Но у параллельного MERGE JOIN есть один недостаток: он резервирует 330 КБ памяти, исходя из ожидаемого количества сортируемых строк. Так как битовые карты такого типа используются после стоимостной оптимизации, то корректировка оценки не производится, несмотря на то, что через нижнюю сортировку проходит только 2488 строк.
Оператор Bitmap может появиться в плане с MERGE JOIN только вместе с последующим блокирующим оператором (например, Sort). Блокирующий оператор должен получить все необходимые значения на вход, прежде чем он сгенерирует первую строку на выход. Это гарантирует, что битовая карта будет полностью заполнена до того, как строки из JOIN-таблицы будут считываться и проверяться по ней.
Нет необходимости, чтобы блокирующий оператор был на другой стороне MERGE JOIN, но важно с какой стороны будет использоваться битовая карта.
Если доступны подходящие индексы, то ситуация будет иной. Распределение наших «случайных» данных такое, что в таблице

На HASH JOIN (как в последовательный, так параллельный) это изменение не повлияет. HASH JOIN не может воспользоваться индексами, поэтому планы и производительность остаются прежними.
MERGE JOIN больше не должен выполнять операцию соединения многие ко многим и больше не требует оператора Sort на входных данных.
Отсутствие блокирующего оператора сортировки означает, что Bitmap не может быть использован.
В результате мы видим последовательный план, вне зависимости от параметра MAXDOP, а производительность хуже, чем у параллельного плана до добавления индексов: 702 мс CPU и 704 мс затраченного времени:
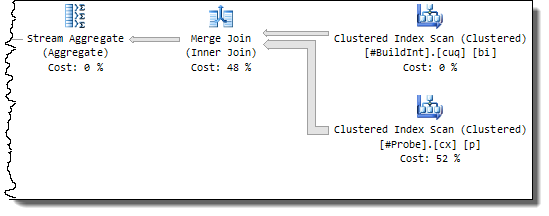
Однако здесь есть заметное улучшение по сравнению с исходным планом последовательного MERGE JOIN (3105 мс / 5632 мс). Это связано с устранением сортировки и лучшей производительностью соединения «один-ко-многим».
Nested Loops Join (соединение вложенными циклами)
Как и следовало ожидать, NESTED LOOP работает значительно лучше. Аналогично MERGE JOIN, оптимизатор решает не использовать параллелизм:

На данный момент это самый эффективный план — всего 16 мс CPU и 16 мс затраченного времени.
Конечно, это предполагает, что данные, необходимые для выполнения запроса, уже находятся в памяти. В противном случае каждый поиск в probe-таблице будет генерировать случайный ввод-вывод.
На моем ноутбуке выполнение NESTED LOOP с холодным кэшем заняло 78 мс CPU и 2152 мс затраченного времени. При тех же обстоятельствах MERGE JOIN использовал 686 мс CPU и 1471 мс. HASH JOIN — 391 мс CPU и 905 мс.
MERGE JOIN и HASH JOIN выигрывают при большом, возможно, последовательном вводе-выводе с использованием упреждающего чтения (read-ahead).
Parallel Hash Join (Craig Freedman)
Query Execution Bitmap Filters (SQL Server Query Processing Team)
Bitmaps in Microsoft SQL Server 2000 (статья из MSDN)
Interpreting Execution Plans Containing Bitmap Filters (документация SQL Server)
Understanding Hash Joins (документация SQL Server)


Может ли запрос, выполняющийся параллельно, использовать меньше CPU и выполняться быстрее, чем такой же запрос, выполняющийся последовательно?
Да! Для демонстрации я буду использовать две таблицы с одной колонкой типа
integer.
Примечание — TSQL скрипт в виде текста находится в конце статьи.
Генерируем демо-данные
В таблицу
#BuildInt вставляем 5 000 случайных целых чисел (для того, чтобы у вас были такие же значения, как и у меня я использую RAND с seed и цикл WHILE).
В таблицу
#Probe вставляем 5 000 000 записей.
Последовательный план
Теперь напишем запрос для подсчета количества совпадений значений в этих таблицах. Используем хинт MAXDOP 1, чтобы быть уверенным, что запрос не будет выполняться параллельно.
Вот его план выполнения и статистика:

Этот запрос выполняется за 891 мс и использует 890 мс CPU.
Параллельный план
Теперь запустим тот же запрос с MAXDOP 2.

Запрос выполняется 221 мс и использует 436 мс CPU. Время выполнения уменьшилось в четыре раза, а использование CPU в два!
Магия Bitmap
Причина, по которой параллельное выполнение запроса намного эффективнее, заключается в операторе Bitmap (битовая карта).
Давайте внимательно посмотрим на фактический план выполнения параллельного запроса:

И сравним его с последовательным планом:

Принцип работы оператора Bitmap достаточно хорошо документирован, поэтому здесь я приведу только краткое описание со ссылками на документацию в конце статьи.
Hash Join (соединение хешированием)
Соединение хешированием (hash join) выполняется в два этапа:
- Этап «построения» (англ. — build). Читаются все строки одной из таблиц и создается хеш-таблица для ключей соединения.
- Этап «проверки» (англ. — probe). Читаются все строки второй таблицы, вычисляется хеш той же хэш-функцией по тем же ключам соединения и ищется совпадающий бакет в хэш-таблице.
Естественно, из-за возможных коллизий хеша, необходимо по-прежнему сравнивать реальные значения ключей.
Примечание переводчика: подробнее о принципе работы hash join можно посмотреть в статье Визуализируем и разбираемся с Hash Match Join
Bitmap в последовательных планах
Многие не знают, что Hash Match, даже в последовательных запросах, всегда использует битовую карту. Но в таком плане вы не увидите ее явно, потому что она является частью внутренней реализации оператора Hash Match.
HASH JOIN на этапе построения (build) и создания хеш-таблицы устанавливает один (или несколько) битов в битовой карте. После этого с помощью битовой карты можно эффективно проверять совпадения значений хеша без затрат на обращение к хеш-таблице.
При последовательном плане для каждой строки второй таблицы вычисляется хэш и проверяется по битовой карте. Если соответствующие биты в битовой карте установлены, то в хэш-таблице может быть совпадение, поэтому далее проверяется хеш-таблица. И наоборот, если ни один из битов, соответствующих значению хеша, не установлен, то мы можем быть уверены, что в хэш-таблице совпадений нет, и можно сразу отбросить проверяемую строку.
Относительно небольшие затраты на построение битовой карты компенсируются экономией времени на отсутствие проверок строк, для которых точно нет совпадений в хеш-таблице. Такая оптимизация часто оказывается эффективной, так как проверка битовой карты значительно быстрее проверки хеш-таблицы.
Bitmap в параллельных планах
В параллельном плане битовая карта отображается как отдельный оператор Bitmap.
При переходе от этапа построения к этапу проверки битовая карта передается оператору HASH MATCH со стороны второй (проверяемой, probe) таблицы. Как минимум, битовая карта передается на сторону probe перед JOIN и оператором обмена (Parallelism).
Здесь битовая карта может исключить строки, которые не удовлетворяют условию соединения, до того, как они будут переданы в оператор обмена.
Конечно, в последовательных планах операторы обмена отсутствуют, поэтому такое перемещение битовой карты за пределы HASH JOIN не даст никаких дополнительных преимуществ по сравнению со «встроенной» битовой картой внутри оператора HASH MATCH.
В некоторых ситуациях (хотя и только в параллельном плане) оптимизатор может переместить Bitmap еще дальше вниз по плану на probe-стороне соединения.
Идея здесь заключается в том, что чем раньше строки будут отфильтрованы, тем меньше затрат потребуется на перемещение данных между операторами и, возможно, даже получится исключить некоторые операции.
Также оптимизатор, как правило, старается разместить простые фильтры как можно ближе к «листьям»: наиболее эффективно фильтровать строки как можно раньше. Однако я должен упомянуть, что битовая карта, о которой мы говорим, добавляется после завершения оптимизации.
Решение о добавлении этого (статического) типа битовой карты в план после оптимизации принимается на основе ожидаемой селективности фильтра (поэтому важна точная статистика).
Перемещение bitmap-фильтра
Вернемся к концепции перемещения bitmap-фильтра на probe-сторону соединения.
Во многих случаях bitmap-фильтр может быть перемещен в оператор Scan или Seek. Когда это происходит, то предикат в плане выглядит следующим образом:

Он применяется ко всем строкам, которые соответствуют seek-предикату (для Index Seek) или ко всем строкам для Index Scan или Table Scan. Например, на скриншоте выше показан bitmap-фильтр, примененный к Table Scan для heap-таблицы.
Углубляемся ...
Если bitmap-фильтр построен на одном столбце или выражении типа integer или bigint, и применяется к одному столбцу типа integer или bigint, то оператор Bitmap может быть перемещен еще ниже по плану, даже дальше, чем операторы Seek или Scan.
Предикат по-прежнему будет отображаться в операторах Scan или Seek, как в примере выше, но теперь он будет помечен атрибутом INROW, что означает перемещение фильтра в Storage Engine и его применение к строкам при их чтении.
При такой оптимизации строки фильтруются еще до того, как Query Processor увидит эту строку. Из Storage Engine передаются только те строки, которые соответствуют HASH MATCH JOIN.
Условия при которых применяется такая оптимизация зависит от версии SQL Server. Например, в SQL Server 2005, в дополнение к условиям, указанным ранее, проверяемый столбец (probe) должен быть определен как NOT NULL. Это ограничение было ослаблено в SQL Server 2008.
Вам может быть интересно, насколько INROW-оптимизация влияет на производительность. Будет ли перенос оператора как можно ближе к Seek или Scan таким же эффективным, как фильтрация в Storage Engine? Я отвечу на этот интересный вопрос в других статьях. А здесь мы еще посмотрим на MERGE JOIN и NESTED LOOP JOIN.
Другие варианты JOIN
Использование вложенных циклов без индексов — это плохая идея. Мы должны полностью сканировать одну из таблиц для каждой строки из другой таблицы — в общей сложности 5 миллиардов сравнений. Этот запрос, вероятно, будет выполняться очень долго.
Merge Join (соединение слиянием)
Этот тип физического соединения требует отсортированных входных данных, поэтому принудительный MERGE JOIN приводит к тому, что перед ним присутствует сортировка. Последовательный план выглядит следующим образом:
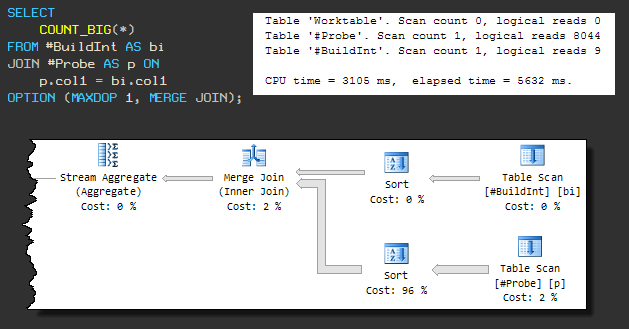
Теперь запрос использует 3105 мс CPU, а общее время выполнения составляет 5632 мс.
Увеличение общего времени выполнения связано с тем, что одна из операций сортировки использует tempdb (несмотря на то, что SQL Server имеет достаточно памяти для сортировки).
Слив в tempdb происходит из-за того, что алгоритм выделения грантов памяти, применяемый по умолчанию, не резервирует заранее достаточное количество памяти. Пока не будем на это обращать внимание, ясно, что запрос не будет завершен менее чем за 3105 мс.
Продолжим форсировать MERGE JOIN, но разрешим параллелизм (MAXDOP 2):

Как и в параллельном HASH JOIN, который мы видели ранее, bitmap-фильтр располагается на другой стороне MERGE JOIN ближе к Table Scan и применяется с использованием INROW-оптимизации.
При 468 мс CPU и 240 мс затраченного времени MERGE JOIN с дополнительными сортировками работает почти так же быстро, как и параллельный HASH JOIN (436 мс / 221 мс).
Но у параллельного MERGE JOIN есть один недостаток: он резервирует 330 КБ памяти, исходя из ожидаемого количества сортируемых строк. Так как битовые карты такого типа используются после стоимостной оптимизации, то корректировка оценки не производится, несмотря на то, что через нижнюю сортировку проходит только 2488 строк.
Оператор Bitmap может появиться в плане с MERGE JOIN только вместе с последующим блокирующим оператором (например, Sort). Блокирующий оператор должен получить все необходимые значения на вход, прежде чем он сгенерирует первую строку на выход. Это гарантирует, что битовая карта будет полностью заполнена до того, как строки из JOIN-таблицы будут считываться и проверяться по ней.
Нет необходимости, чтобы блокирующий оператор был на другой стороне MERGE JOIN, но важно с какой стороны будет использоваться битовая карта.
С индексами
Если доступны подходящие индексы, то ситуация будет иной. Распределение наших «случайных» данных такое, что в таблице
#BuildInt можно создать уникальный индекс. А таблица #Probe содержит дубликаты, поэтому в ней придется обойтись неуникальным индексом:
На HASH JOIN (как в последовательный, так параллельный) это изменение не повлияет. HASH JOIN не может воспользоваться индексами, поэтому планы и производительность остаются прежними.
Merge Join (соединение слиянием)
MERGE JOIN больше не должен выполнять операцию соединения многие ко многим и больше не требует оператора Sort на входных данных.
Отсутствие блокирующего оператора сортировки означает, что Bitmap не может быть использован.
В результате мы видим последовательный план, вне зависимости от параметра MAXDOP, а производительность хуже, чем у параллельного плана до добавления индексов: 702 мс CPU и 704 мс затраченного времени:

Однако здесь есть заметное улучшение по сравнению с исходным планом последовательного MERGE JOIN (3105 мс / 5632 мс). Это связано с устранением сортировки и лучшей производительностью соединения «один-ко-многим».
Nested Loops Join (соединение вложенными циклами)
Как и следовало ожидать, NESTED LOOP работает значительно лучше. Аналогично MERGE JOIN, оптимизатор решает не использовать параллелизм:

На данный момент это самый эффективный план — всего 16 мс CPU и 16 мс затраченного времени.
Конечно, это предполагает, что данные, необходимые для выполнения запроса, уже находятся в памяти. В противном случае каждый поиск в probe-таблице будет генерировать случайный ввод-вывод.
На моем ноутбуке выполнение NESTED LOOP с холодным кэшем заняло 78 мс CPU и 2152 мс затраченного времени. При тех же обстоятельствах MERGE JOIN использовал 686 мс CPU и 1471 мс. HASH JOIN — 391 мс CPU и 905 мс.
MERGE JOIN и HASH JOIN выигрывают при большом, возможно, последовательном вводе-выводе с использованием упреждающего чтения (read-ahead).
Дополнительные ресурсы
Parallel Hash Join (Craig Freedman)
Query Execution Bitmap Filters (SQL Server Query Processing Team)
Bitmaps in Microsoft SQL Server 2000 (статья из MSDN)
Interpreting Execution Plans Containing Bitmap Filters (документация SQL Server)
Understanding Hash Joins (документация SQL Server)
Тестовый скрипт
USE tempdb;
GO
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #Probe
(
col1 INTEGER NOT NULL
);
GO
-- Load 5,000 rows into the build table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 2147483647));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 2147483647);
SET @I += 1;
END;
-- Load 5,000,000 rows into the probe table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 2147483647));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 2147483647));
SET @I += 1;
IF @I % 25 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
GO
-- Demos
SET STATISTICS XML OFF;
SET STATISTICS IO, TIME ON;
-- Serial
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1);
-- Parallel
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 2);
SET STATISTICS IO, TIME OFF;
-- Indexes
CREATE UNIQUE CLUSTERED INDEX cuq ON #BuildInt (col1);
CREATE CLUSTERED INDEX cx ON #Probe (col1);
-- Vary the query hints to explore plan shapes
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1, MERGE JOIN);
GO
DROP TABLE #BuildInt, #Probe;
Читать ещё:
