Перевод статьи подготовлен в преддверии старта курса «Data Engineer».

Structured Streaming был впервые представлен в Apache Spark 2.0. Эта платформа зарекомендовала себя как лучший выбор для создания распределенных приложений потоковой обработки. Унификация API SQL/Dataset/DataFrame и встроенных функций Spark значительно упрощают разработчикам реализацию их сложных насущных необходимостей, таких как агрегирование потоковой передачи (streaming aggregation), объединение потоков (stream-stream join) и поддержка работы с окнами (windowing support). С момента релиза Structured Streaming популярным запросом от разработчиков стала просьба улучшить управление потоковой передачей, точно так же, как мы сделали это в Spark Streaming (например, DStream). В Apache Spark 3.0 мы выпустили новый UI для Structured Streaming.
Новый UI Structured Streaming обеспечивает простой способ мониторинга всех потоковых заданий с предоставлением полезной информации и статистики, упрощая устранение неполадок во время отладки, а также улучшая наблюдаемость производства с помощью метрик в реальном времени. UI представляет два набора статистики: 1) агрегированную информацию о задании потокового запроса (streaming query job) и 2) подробную статистическую информацию о потоковых запросах, включая Input Rate, Process Rate, Input Rows, Batch Duration, Operation Duration и т.д.
Когда разработчик отправляет потоковый SQL запрос, он отображается на вкладке Structured Streaming, которая включает как активные потоковые запросы, так и завершенные. В таблице результатов будет приведена некоторая базовая информация относительно потоковых запросов, включая имя запроса, статус, ID, runID, время отправки, продолжительность запроса, ID последнего пакета, а также агрегированную информацию, такую как средняя скорость приема и средняя скорость обработки. Существует три типа состояния потокового запроса: RUNNING, FINISHED и FAILED. Все FINISHED и FAILED запросы перечислены в таблице завершенных потоковых запросов. В столбце Error отображаются подробные сведения об исключении неудавшегося запроса.
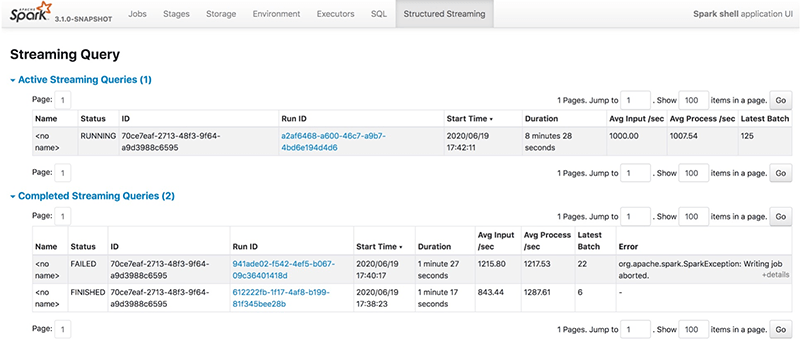
Мы можем просмотреть подробную статистику потокового запроса, перейдя по ссылке Run ID.
На странице Statistics отображаются метрики, включая скорость приема/обработки, задержку и детализированную продолжительность операции, которые полезны для понимания состояния ваших потоковых запросов, что позволяет легко отлаживать аномалии при обработке запросов.
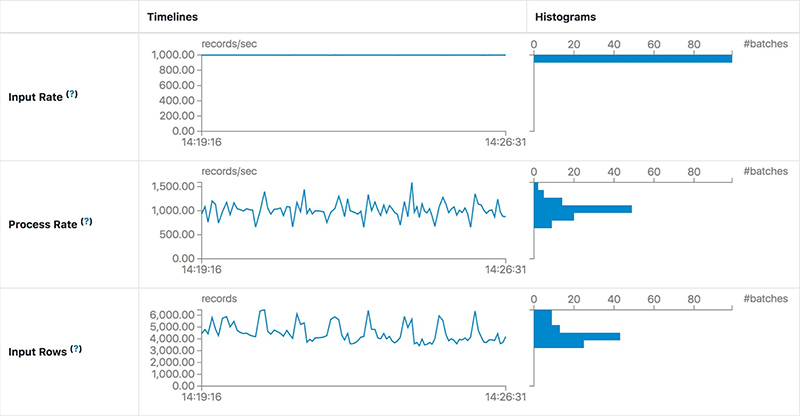
Она содержит следующие метрики:
Отслеживаемые операции перечислены ниже:
Следует отметить, что не все перечисленные операции будут отображаться в UI. Существуют разные операции с разными типами источников данных, поэтому часть перечисленных операций может выполняться в одном потоковом запросе.
В этом разделе мы рассмотрим несколько случаев, когда новый UI Structured Streaming указывает на то, что происходит что-то необычное. Демонстрационный запрос на высоком уровне выглядит так, и в каждом случае мы будем предполагать некоторые предварительные условия:
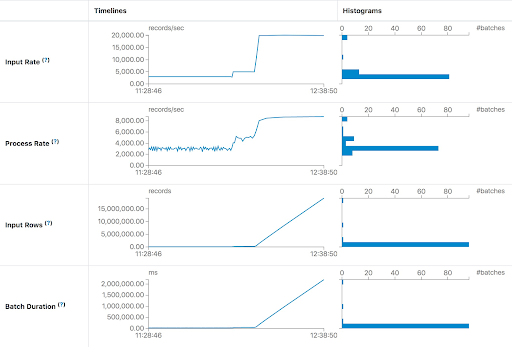
В первом случае мы запускаем запрос для обработки данных Apache Kafka как можно скорее. Для каждого батча потоковое задание обрабатывает все доступные данные в Kafka. Если вычислительной мощности недостаточно для обработки пакетных данных, задержка быстро возрастет. Наиболее интуитивно понятное суждение заключается в том, что Input Rows и Batch Duration будут линейно расти. Параметр Input Rows указывает на то, что задание потоковой передачи может обрабатывать не более 8000 записей в секунду. Но текущая Input Rate составляет около 20 000 записей в секунду. Мы можем предоставить потоковому заданию больше ресурсов для выполнения или добавить достаточное количество разделов для обработки всех потребителей, необходимых, чтобы не отставать от производителей.
Чем отличается этот случай от предыдущего? Задержка не увеличивается, а остается стабильной, как показано на следующем снимке экрана:
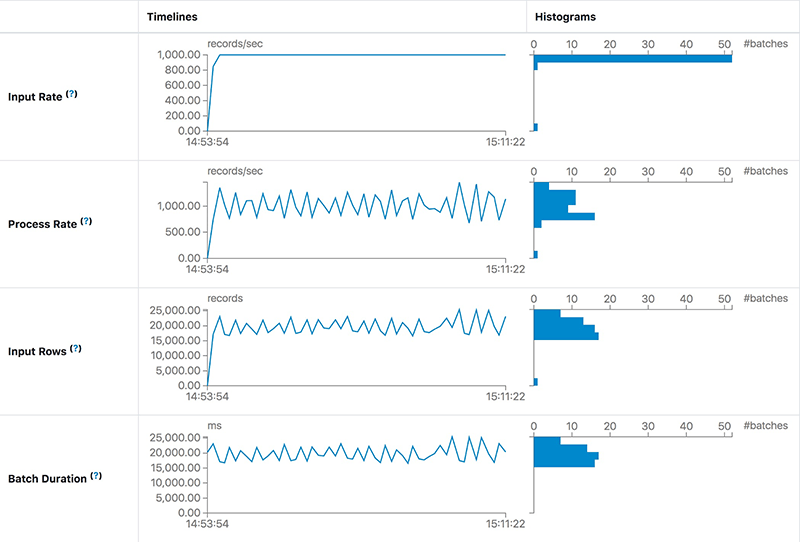
Мы обнаружили, что Process Rate может оставаться стабильной при той же Input Rate. Это означает, что мощности обработки задания достаточно для обработки входных данных. Однако длительность обработки каждого батча, т. е. задержка, все еще составляет 20 секунд. Основная причина большой задержки — слишком большое количество данных в каждом батче. Обычно мы можем уменьшить задержку, увеличив параллелизм этого задания. После добавления еще 10 разделов Kafka и 10 ядер для задач Spark мы обнаружили, что задержка составляет около 5 секунд — что намного лучше, чем 20 секунд.
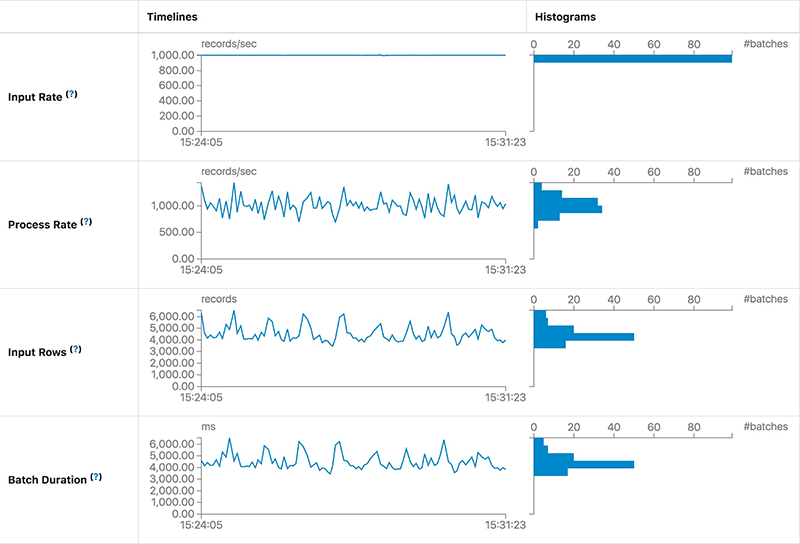
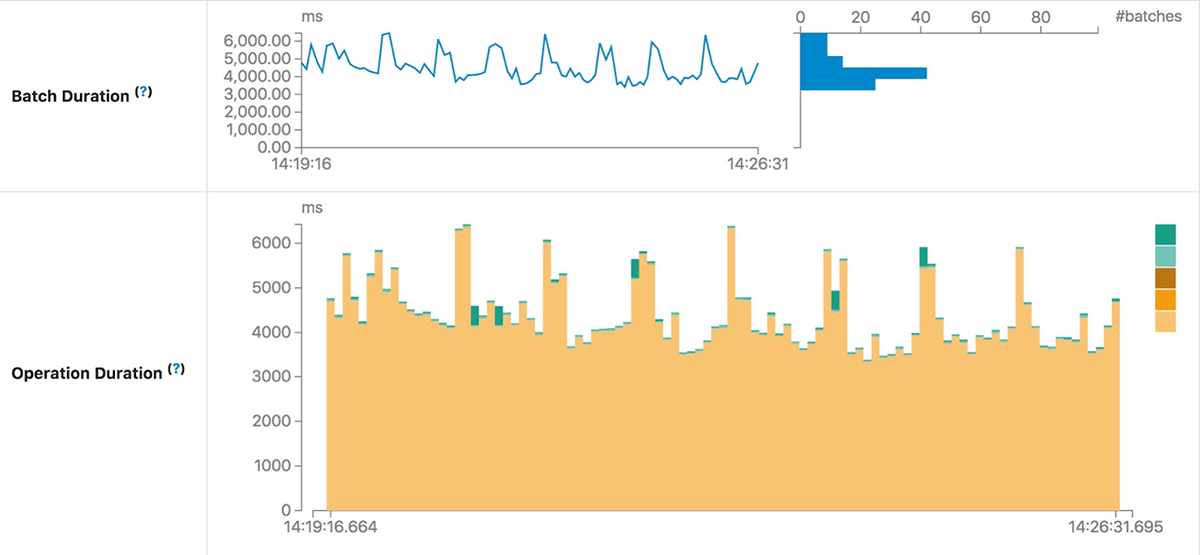
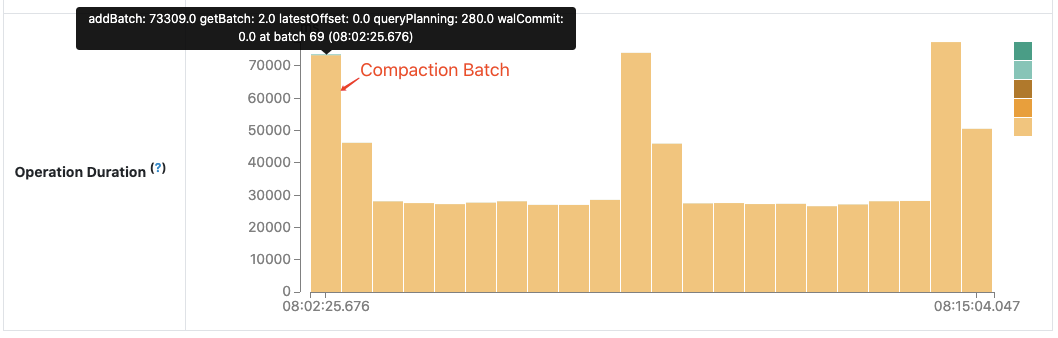
Диаграмма Operation Duration отображает количество времени, затрачиваемое на выполнение различных операций, в миллисекундах. Это полезно для понимания распределения времени в каждом батче и упрощения поиска и устранения неисправностей. Воспользуемся работой по улучшению производительности «SPARK-30915: Избегайте чтения файла лога метаданных при поиске ID последнего батча» в сообществе Apache Spark в качестве примера.
До этого улучшения, каждый следующий батч после сжатия требовал больше времени, чем другие батчи, когда сжатый лог метаданных становится огромным.
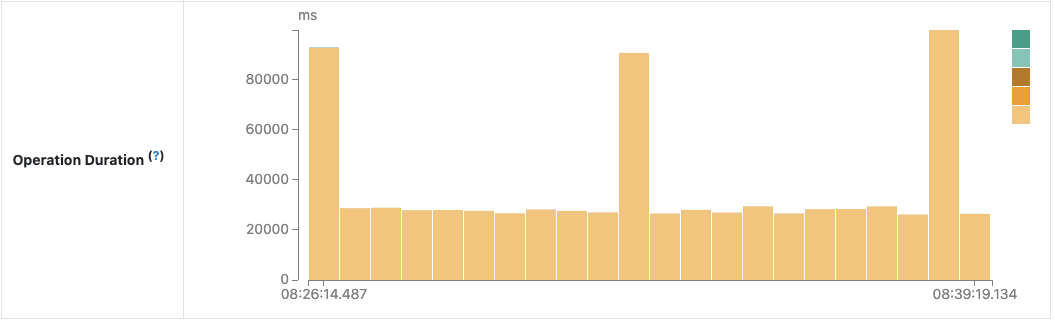
После исследования кода было обнаружено и исправлено ненужное чтение сжатого файла лога. Следующая диаграмма Operation Duration подтверждает ожидаемый эффект:
Как показано выше, новый UI Structured Streaming поможет разработчикам лучше контролировать свои потоковые задания, имея гораздо более полезную информацию о потоковых запросах. На правах ранней версии, новый UI все еще находится в разработке и будет улучшаться в будущих релизах. Есть несколько функций, которые могут быть реализованы в недалеком будущем, включая, помимо прочего, следующее:
Попробуйте этот новый Spark Streaming UI в Apache Spark 3.0 в новой версии Databricks Runtime 7.1. Если вы используете записные книжки Databricks notebooks, это также даст вам простой способ наблюдать статус любого потокового запроса в записной книжке и управлять своими запросами. Вы можете зарегистрировать бесплатную учетную запись на Databricks и начать работу за считанные минуты бесплатно, без какой-либо кредитной информации.
Качество данных в DWH — консистентность Хранилища Данных. бесплатный вебинар.
Data Build Tool или что общего между Хранилищем Данных и Смузи
Погружение в Delta Lake: принудительное применение и эволюция схемы
Высокоскоростной Apache Parquet на Python с Apache Arrow

Structured Streaming был впервые представлен в Apache Spark 2.0. Эта платформа зарекомендовала себя как лучший выбор для создания распределенных приложений потоковой обработки. Унификация API SQL/Dataset/DataFrame и встроенных функций Spark значительно упрощают разработчикам реализацию их сложных насущных необходимостей, таких как агрегирование потоковой передачи (streaming aggregation), объединение потоков (stream-stream join) и поддержка работы с окнами (windowing support). С момента релиза Structured Streaming популярным запросом от разработчиков стала просьба улучшить управление потоковой передачей, точно так же, как мы сделали это в Spark Streaming (например, DStream). В Apache Spark 3.0 мы выпустили новый UI для Structured Streaming.
Новый UI Structured Streaming обеспечивает простой способ мониторинга всех потоковых заданий с предоставлением полезной информации и статистики, упрощая устранение неполадок во время отладки, а также улучшая наблюдаемость производства с помощью метрик в реальном времени. UI представляет два набора статистики: 1) агрегированную информацию о задании потокового запроса (streaming query job) и 2) подробную статистическую информацию о потоковых запросах, включая Input Rate, Process Rate, Input Rows, Batch Duration, Operation Duration и т.д.
Агрегированная информация о заданиях потоковых запросов
Когда разработчик отправляет потоковый SQL запрос, он отображается на вкладке Structured Streaming, которая включает как активные потоковые запросы, так и завершенные. В таблице результатов будет приведена некоторая базовая информация относительно потоковых запросов, включая имя запроса, статус, ID, runID, время отправки, продолжительность запроса, ID последнего пакета, а также агрегированную информацию, такую как средняя скорость приема и средняя скорость обработки. Существует три типа состояния потокового запроса: RUNNING, FINISHED и FAILED. Все FINISHED и FAILED запросы перечислены в таблице завершенных потоковых запросов. В столбце Error отображаются подробные сведения об исключении неудавшегося запроса.

Мы можем просмотреть подробную статистику потокового запроса, перейдя по ссылке Run ID.
Подробная статистическая информация
На странице Statistics отображаются метрики, включая скорость приема/обработки, задержку и детализированную продолжительность операции, которые полезны для понимания состояния ваших потоковых запросов, что позволяет легко отлаживать аномалии при обработке запросов.


Она содержит следующие метрики:
- Input Rate: агрегированная (по всем источникам) скорость поступления данных.
- Process Rate: агрегированная (по всем источникам) скорость, с которой Spark обрабатывает данные.
- Batch Duration: продолжительность каждого батча.
- Operation Duration: время, затраченное на выполнение различных операций в миллисекундах.
Отслеживаемые операции перечислены ниже:
addBatch: время, затраченное на чтение входных данных микро батча из источников, их обработку и запись выходных данных пакета в синк. Это обычно занимает большую часть времени микро батча.getBatch: время, затраченное на подготовку логического запроса чтения входных данных текущего микро пакета из источников.getOffset: время, затраченное на запрос источников, есть ли у них новые входные данные.walCommit: записывает смещения в логах метаданных.queryPlanning: создание плана выполнения.
Следует отметить, что не все перечисленные операции будут отображаться в UI. Существуют разные операции с разными типами источников данных, поэтому часть перечисленных операций может выполняться в одном потоковом запросе.
Устранение проблем с производительностью потоковой передачи с помощью UI
В этом разделе мы рассмотрим несколько случаев, когда новый UI Structured Streaming указывает на то, что происходит что-то необычное. Демонстрационный запрос на высоком уровне выглядит так, и в каждом случае мы будем предполагать некоторые предварительные условия:
import java.util.UUID
val bootstrapServers = ...
val topics = ...
val checkpointLocation = "/tmp/temporary-" + UUID.randomUUID.toString
val lines = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option("subscribe", topics)
.load()
.selectExpr("CAST(value AS STRING)")
.as[String]
val wordCounts = lines.flatMap(_.split(" ")).groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.option("checkpointLocation", checkpointLocation)
.start()Увеличение задержки из-за недостаточной мощности обработки
В первом случае мы запускаем запрос для обработки данных Apache Kafka как можно скорее. Для каждого батча потоковое задание обрабатывает все доступные данные в Kafka. Если вычислительной мощности недостаточно для обработки пакетных данных, задержка быстро возрастет. Наиболее интуитивно понятное суждение заключается в том, что Input Rows и Batch Duration будут линейно расти. Параметр Input Rows указывает на то, что задание потоковой передачи может обрабатывать не более 8000 записей в секунду. Но текущая Input Rate составляет около 20 000 записей в секунду. Мы можем предоставить потоковому заданию больше ресурсов для выполнения или добавить достаточное количество разделов для обработки всех потребителей, необходимых, чтобы не отставать от производителей.

Стабильная, но высокая задержка
Чем отличается этот случай от предыдущего? Задержка не увеличивается, а остается стабильной, как показано на следующем снимке экрана:

Мы обнаружили, что Process Rate может оставаться стабильной при той же Input Rate. Это означает, что мощности обработки задания достаточно для обработки входных данных. Однако длительность обработки каждого батча, т. е. задержка, все еще составляет 20 секунд. Основная причина большой задержки — слишком большое количество данных в каждом батче. Обычно мы можем уменьшить задержку, увеличив параллелизм этого задания. После добавления еще 10 разделов Kafka и 10 ядер для задач Spark мы обнаружили, что задержка составляет около 5 секунд — что намного лучше, чем 20 секунд.

Используйте диаграмму Operation Duration для поиска и устранения неисправностей
Диаграмма Operation Duration отображает количество времени, затрачиваемое на выполнение различных операций, в миллисекундах. Это полезно для понимания распределения времени в каждом батче и упрощения поиска и устранения неисправностей. Воспользуемся работой по улучшению производительности «SPARK-30915: Избегайте чтения файла лога метаданных при поиске ID последнего батча» в сообществе Apache Spark в качестве примера.
До этого улучшения, каждый следующий батч после сжатия требовал больше времени, чем другие батчи, когда сжатый лог метаданных становится огромным.

После исследования кода было обнаружено и исправлено ненужное чтение сжатого файла лога. Следующая диаграмма Operation Duration подтверждает ожидаемый эффект:

Планы на будущее
Как показано выше, новый UI Structured Streaming поможет разработчикам лучше контролировать свои потоковые задания, имея гораздо более полезную информацию о потоковых запросах. На правах ранней версии, новый UI все еще находится в разработке и будет улучшаться в будущих релизах. Есть несколько функций, которые могут быть реализованы в недалеком будущем, включая, помимо прочего, следующее:
- Дополнительные сведения о выполнении потокового запроса: late data, вотермарки, метрики состояния данных и т. д.
- Поддержка Structured Streaming UI на Spark History Server.
- Более заметные подсказки необычного поведения: возникновение задержки и т. д.
Попробуйте новый UI
Попробуйте этот новый Spark Streaming UI в Apache Spark 3.0 в новой версии Databricks Runtime 7.1. Если вы используете записные книжки Databricks notebooks, это также даст вам простой способ наблюдать статус любого потокового запроса в записной книжке и управлять своими запросами. Вы можете зарегистрировать бесплатную учетную запись на Databricks и начать работу за считанные минуты бесплатно, без какой-либо кредитной информации.
Качество данных в DWH — консистентность Хранилища Данных. бесплатный вебинар.
Рекомендуем к прочтению:
Data Build Tool или что общего между Хранилищем Данных и Смузи
Погружение в Delta Lake: принудительное применение и эволюция схемы
Высокоскоростной Apache Parquet на Python с Apache Arrow
