И снова здравствуйте. В июне OTUS вновь запускает курс «MS SQL Server разработчик», традиционно в преддверии старта курса мы начинаем делиться с вами материалом по теме.

Если в вашем запросе отсутствует ORDER BY, то вы не можете быть уверены в том, что сортировка результатов не изменится со временем.
Конечно, поначалу все будет довольно предсказуемо, но по мере того, как происходят изменения (в индексах, таблицах, конфигурации сервера, объеме ваших данных), вы можете столкнуться с некоторыми неприятными сюрпризами.
Давайте начнем с чего-нибудь простого: выполним SELECT для таблицы Users базы данных Stack Overflow. В этой таблице есть кластерный индекс по колонке Id, который начинается с единицы и увеличивается до триллиона. Для этого запроса данные возвращаются в порядке кластерного индекса:

Но если создать индекс на DisplayName и Location, то SQL Server внезапно решит использовать новый индекс, а не кластерный:

Вот план выполнения:

Почему SQL Server решил использовать этот индекс, хотя ему не нужно было сортировать по DisplayName и Location? Потому что этот индекс — наименьшая копия данных, которые необходимо получить. Давайте посмотрим на размеры индексов с помощью

В кластерном индексе (CX/PK) около 8,9 млн строк и его размер 1,1 ГБ.
В некластерном индексе для DisplayName, Location также около 8,9 млн строк, но его размер всего 368 МБ. Если вам нужно сделать scan для получения результатов запроса, то почему бы не выбрать наименьший источник данных, так как это будет быстрее. Именно по этой причине SQL Server поступил таким образом.
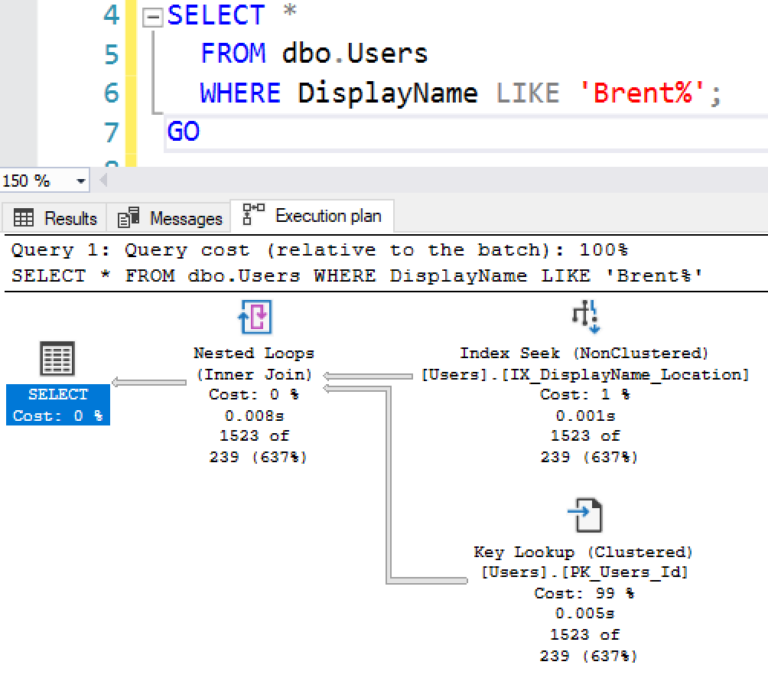
Хорошо, теперь, когда у нас есть индекс для DisplayName и Location, давайте попробуем выполнить запрос, который ищет конкретное имя (DisplayName). Результаты получаются отсортированными по DisplayName:

В плане выполнения видно, что используется индекс по DisplayName и Location:
Но если искать по другому значению, то результаты уже не будут отсортированы по DisplayName:
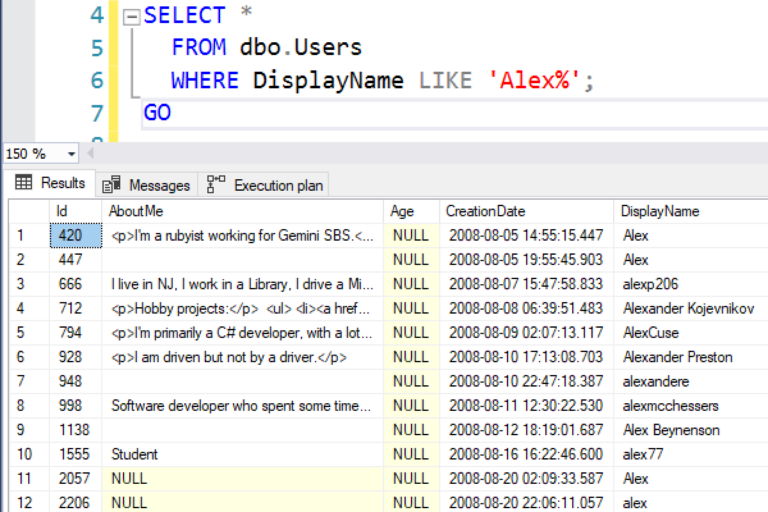
SQL Server обнаружил, что Alex’ов много и более разумно выполнить Clustered Index Scan вместо Index Seek + Key Lookup:
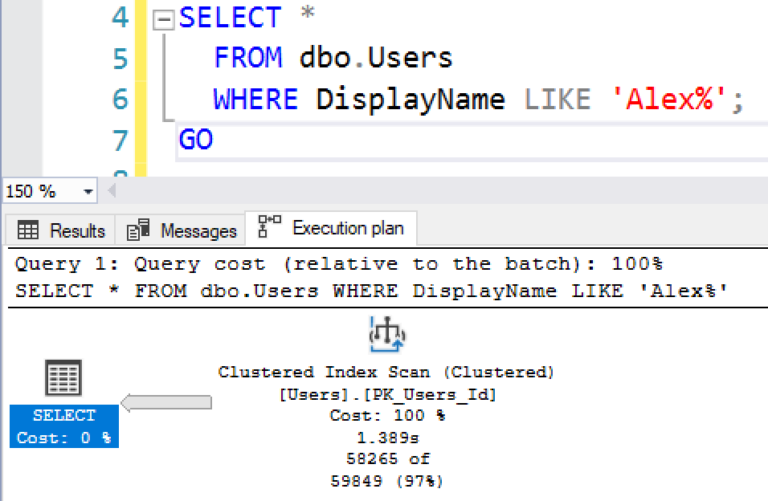
Даже в этих, действительно простых случаях, вы не можете гарантировать, что SQL Server всегда будет использовать ту копию данных, которую вы ожидаете.
В последнее время я столкнулся с гораздо более сложными случаями:
Узнать подробнее о курсе.

Если в вашем запросе отсутствует ORDER BY, то вы не можете быть уверены в том, что сортировка результатов не изменится со временем.
Конечно, поначалу все будет довольно предсказуемо, но по мере того, как происходят изменения (в индексах, таблицах, конфигурации сервера, объеме ваших данных), вы можете столкнуться с некоторыми неприятными сюрпризами.
Давайте начнем с чего-нибудь простого: выполним SELECT для таблицы Users базы данных Stack Overflow. В этой таблице есть кластерный индекс по колонке Id, который начинается с единицы и увеличивается до триллиона. Для этого запроса данные возвращаются в порядке кластерного индекса:

Но если создать индекс на DisplayName и Location, то SQL Server внезапно решит использовать новый индекс, а не кластерный:

Вот план выполнения:

Почему SQL Server решил использовать этот индекс, хотя ему не нужно было сортировать по DisplayName и Location? Потому что этот индекс — наименьшая копия данных, которые необходимо получить. Давайте посмотрим на размеры индексов с помощью
sp_BlitzIndex: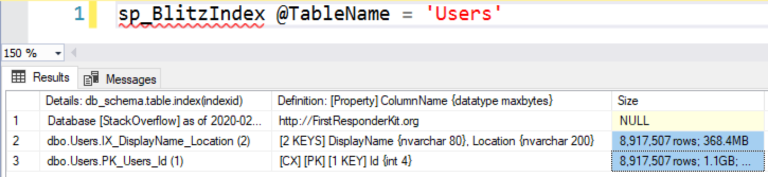
В кластерном индексе (CX/PK) около 8,9 млн строк и его размер 1,1 ГБ.
В некластерном индексе для DisplayName, Location также около 8,9 млн строк, но его размер всего 368 МБ. Если вам нужно сделать scan для получения результатов запроса, то почему бы не выбрать наименьший источник данных, так как это будет быстрее. Именно по этой причине SQL Server поступил таким образом.
“Да, но мой запрос содержит WHERE”.
Хорошо, теперь, когда у нас есть индекс для DisplayName и Location, давайте попробуем выполнить запрос, который ищет конкретное имя (DisplayName). Результаты получаются отсортированными по DisplayName:

В плане выполнения видно, что используется индекс по DisplayName и Location:

Но если искать по другому значению, то результаты уже не будут отсортированы по DisplayName:

SQL Server обнаружил, что Alex’ов много и более разумно выполнить Clustered Index Scan вместо Index Seek + Key Lookup:

Даже в этих, действительно простых случаях, вы не можете гарантировать, что SQL Server всегда будет использовать ту копию данных, которую вы ожидаете.
В последнее время я столкнулся с гораздо более сложными случаями:
- Удаление индекса, который использовался в запросе
- Включение принудительной параметризации (Forced Parameterization), которая изменяет оценку предполагаемого количества строк, заставляя SQL Server выбирать другой индекс
- Изменение уровня совместимости базы данных (Compatibility Level) с включением нового механизма оценки кардинальности (Cardinality Estimator), который выдает другой вариант плана.
Узнать подробнее о курсе.
