Перевод статьи подготовлен специально для студентов курса «DevOps практики и инструменты».

Фабиан Рейнарц (Fabian Reinartz) — разработчик программного обеспечения, фанат Go и любитель решать сложные задачи. Также он мэйнтейнер Prometheus и соучредитель Kubernetes SIG instrumentation. В прошлом он был production-инженером в SoundCloud и возглавлял группу мониторинга в CoreOS. В настоящее время работает в Google.
Бартек Плотка (Bartek Plotka) — инфраструктурный инженер в Improbable. Увлекается новыми технологиями и проблемами распределенных систем. Имеет опыт низкоуровневого программирования в Intel, опыт контрибьютора в Mesos и production-опыт SRE мирового масштаба в Improbable. Занимается улучшением мира микросервисов. Три его любви: Golang, open source и волейбол.
Глядя на наш флагманский продукт SpatialOS, вы можете догадаться, что для Improbable нужна высокодинамичная облачная инфраструктура глобального масштаба с десятками кластеров Kubernetes. Мы были одними из первых, кто начал использовать систему мониторинга Prometheus. Prometheus способен отслеживать миллионы метрик в реальном времени и поставляется с мощным языком запросов, позволяющим извлекать необходимую информацию.
Простота и надежность Prometheus является одним из основных его преимуществ. Однако, пройдя определенный масштаб, мы столкнулись с несколькими недостатками. Для решения этих проблем мы разработали Thanos — проект с открытым исходным кодом, созданный компанией Improbable, для бесшовной трансформации существующих кластеров Prometheus в единую систему мониторинга с неограниченным хранилищем исторических данных. Thanos доступен на Github здесь.
Будьте в курсе последних новостей от Improbable.
При определенном масштабе возникают проблемы, выходящие за рамки возможностей ванильного Prometheus. Как надежно и экономно хранить петабайты исторических данных? Можно ли это сделать без ущерба времени ответа на запрос? Можно ли получить доступ ко всем метрикам, расположенных на разных серверах Prometheus, с помощью одного API-запроса? Можно ли каким-то образом объединить реплицированные данные, собранные с помощью Prometheus HA?
Для решения этих вопросов мы создали Thanos. В следующих разделах описывается как мы подошли к решению этих вопросов и объясняются цели, которые мы преследовали.
Prometheus предлагает функциональный подход к шардингу. Даже один Prometheus-сервер обеспечивает достаточную масштабируемость, чтобы освободить пользователей от сложностей горизонтального шардинга практически во всех вариантах использования.
Хотя это отличная модель развертывания, но часто требуется получить доступ к данным на разных серверах Prometheus через единый API или UI — global view. Конечно, есть возможность отобразить несколько запросов в одной панели Grafana, но каждый запрос может быть выполнен только на один сервер Prometheus. С другой стороны, с помощью Thanos вы можете запрашивать и агрегировать данные с нескольких серверов Prometheus, поскольку все они доступны с одной конечной точки.
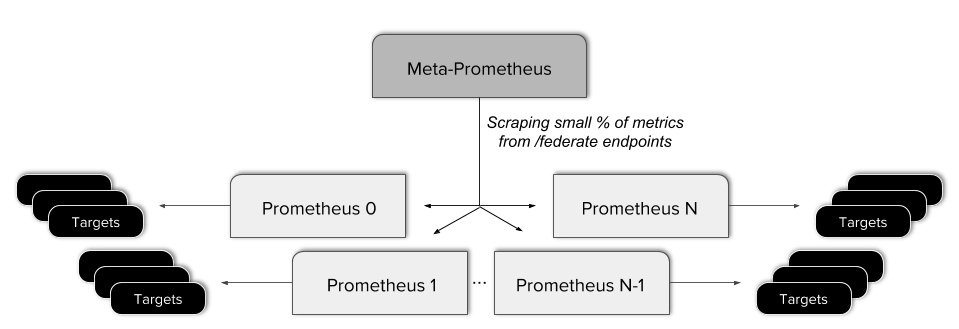
Ранее, для получения global view в Improbable, мы организовали наши экземпляры Prometheus в многоуровневую Hierarchical Federation. Это означало создание одного мета-сервера Prometheus, который собирает часть метрик с каждого “листового" сервера.
Этот подход оказался проблематичным. Он привел к усложнению конфигурации, добавлению дополнительной потенциальной точки отказа и применению сложных правил для предоставления federated-конечной точке только нужных данных. Кроме того, federation такого рода не позволяет получить настоящее global view, так как не все данные доступны из одного API-запроса.
С этим тесно связано единое представление данных, собранных на высокодоступных (high-availability, HA) серверах Prometheus. HA-модель Prometheus независимо собирает данные дважды, что настолько просто, что проще быть не может. Однако использовать объединенное и дедуплицированное представление обоих потоков было бы намного удобнее.
Конечно, в высокодоступных серверах Prometheus существует необходимость. В Improbable мы действительно серьезно относимся к ежеминутному мониторингу данных, но наличие одного экземпляра Prometheus на кластер является единой точкой отказа. Любая ошибка конфигурации или сбой оборудования могут потенциально привести к потере важных данных. Даже простое развертывание может привести к небольшим сбоям в сборе метрик, поскольку перезапуск может быть значительно дольше интервала скрапинга.
Дешевое, быстрое и долгосрочное хранилище метрик — это наша мечта (разделяемая большинством пользователей Prometheus). В Improbable мы были вынуждены настроить срок хранения метрик на девять дней (для Prometheus 1.8). Это добавляет очевидные ограничения на то, как далеко мы можем посмотреть назад.
Prometheus 2.0 в этом отношении стал лучше, так как количество time series больше не влияет на общую производительность сервера (см. KubeCon keynote about Prometheus 2). Тем не менее Prometheus хранит данные на локальном диске. Хотя высокоэффективное сжатие данных может значительно сократить использование локального SSD, но в конечном счете все равно существует ограничение на объем сохраняемых исторических данных.
Кроме того, в Improbable мы заботимся о надежности, простоте и стоимости. Большие локальные диски сложнее в эксплуатации и резервном копировании. Они стоят дороже и требуют больше инструментов для резервного копирования, что приводит к излишней сложности.
Как только мы начали работать с историческими данными, мы поняли, что существуют фундаментальные сложности c O-большим, которые делают запросы все медленнее и медленнее, если мы работаем с данными за недели, месяцы и годы.
Стандартным решением этой проблемы будет даунсэмплинг (downsampling) — уменьшение частоты дискретизации сигнала. С помощью понижения дискретизации мы можем “уменьшить масштаб” до большего временного диапазона и поддерживать прежнее количество выборок, что позволит сохранить отзывчивость запросов.
Даунсэмплинг старых данных является неизбежным требованием любого решения для долгосрочного хранения и выходит за рамки ванильного Prometheus.
Одной из первоначальных целей проекта Thanos была бесшовная интеграция с любыми существующими установками Prometheus. Вторая цель состояла в простой эксплуатации с минимальным входным барьером. Любые зависимости должны быть легко удовлетворены как для небольших, так и для крупных пользователей, что также подразумевает незначительную базовую стоимость.
После того как в предыдущем разделе были перечислены наши цели, давайте поработаем над ними и посмотрим, как Thanos решает эти проблемы.
Чтобы получить global view поверх существующих экземпляров Prometheus, нам нужно связать единую точку входа запросов со всеми серверами. Именно этим и занимается компонент Thanos Sidecar. Он развертывается рядом с каждым сервером Prometheus и работает как прокси, обслуживая локальные данные Prometheus через gRPC-интерфейс Store API, позволяющий выбирать time series данные по меткам и временному диапазону.
С другой стороны находится горизонтально масштабируемый компонент Querier без сохранения состояния, который делает чуть больше, чем просто отвечает на запросы PromQL через стандартный Prometheus HTTP API. Компоненты Querier, Sidecar и другие Thanos взаимодействуют по протоколу gossip.

Это решает основную часть нашей головоломки — объединение данных с изолированных серверов Prometheus в единое представление. Фактически Thanos можно использовать только ради этой возможности. В существующие сервера Prometheus не требуется вносить какие-либо изменения!
Однако рано или поздно мы захотим сохранить данные, выходящие за пределы обычного времени хранения Prometheus. Для хранения исторических данных мы выбрали объектное хранилище. Оно широко доступно в любом облаке, а также в локальных ЦОДах и очень экономично. Кроме того, практически любое объектное хранилище доступно через хорошо известный S3 API.
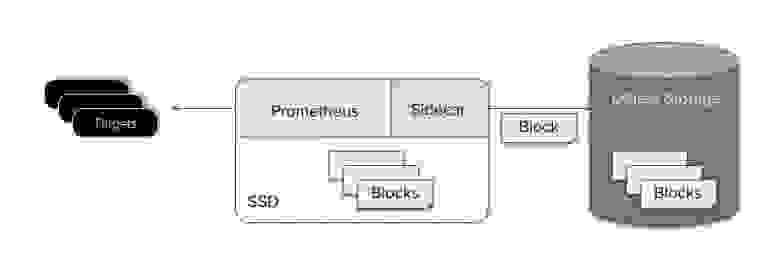
Prometheus записывает данные из оперативной памяти на диск примерно каждые два часа. Блок сохраняемых данных содержит все данные для фиксированного промежутка времени и является неизменяемым. Это очень удобно, так как Thanos Sidecar может просто смотреть каталог данных Prometheus и, по мере появления новых блоков, загружать их в бакеты объектного хранилища.
Загрузка в объектное хранилище сразу после записи на диск позволяет также сохранить простоту “скрапера” (Prometheus и Thanos Sidecar). Что упрощает поддержку, стоимость и дизайн системы.
Как видите, резервное копирование данных реализуется очень просто. Но что насчет запроса к данным в объектном хранилище?
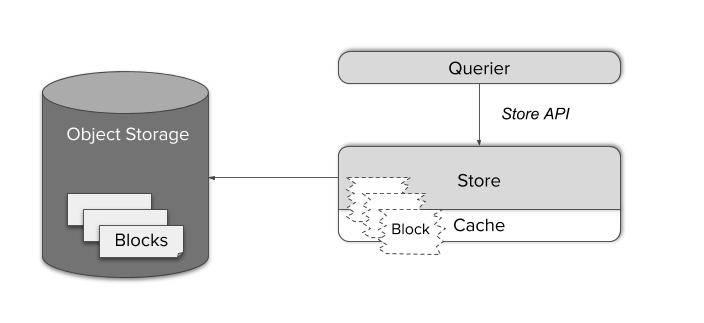
Компонент Thanos Store действует как прокси для получения данных из объектного хранилища. Как и Thanos Sidecar, он участвует в gossip-кластере и реализует Store API. Таким образом, существующие Querier могут рассматривать его как Sidecar, в качестве еще одного источника time series данных — никакой специальной настройки не требуется.
Блоки time series данных состоят из нескольких больших файлов. Загрузка их по требованию была бы довольно неэффективной, а локальное кэширование потребовало огромной памяти и дискового пространства.
Вместо этого Store Gateway знает, как обращаться с форматом хранения Prometheus. Благодаря умному планировщику запросов и кэшированию только необходимых индексных частей блоков, стало возможным сократить сложные запросы до минимального количества HTTP-запросов к файлам объектного хранилища. Таким образом, можно сократить число запросов на четыре-шесть порядков и достичь времени отклика, которое в целом трудно отличить от запросов к данным на локальном SSD.
Как показано на диаграмме выше, Thanos Querier значительно снижает затраты на один запрос к данным в объектном хранилище, используя формат хранения Prometheus и размещая связанные данные рядом. Используя этот подход, мы можем объединить множество одиночных запросов в минимальное количество bulk-операций.
После того как новый блок time series данных успешно загружен в объектное хранилище, мы рассматриваем его как “исторические” данные, которые сразу же становятся доступны через Store Gateway.
Однако через некоторое время блоки из одного источника (Prometheus с Sidecar) накапливаются и уже не используют весь потенциал индексации. Для решения этой проблемы мы ввели еще один компонент под названием Compactor. Он просто применяет локальный механизм уплотнения Prometheus к историческим данным в объектном хранилище и может быть запущен как простое периодическое пакетное задание.
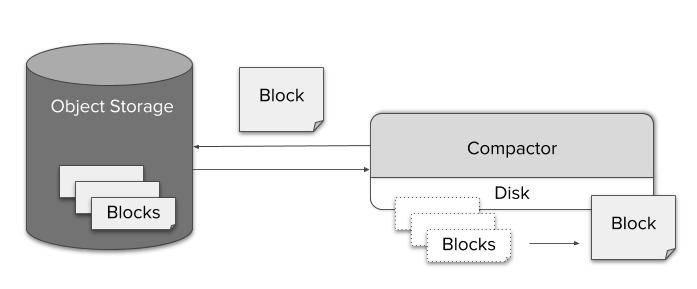
Благодаря эффективному сжатию, запрос в хранилище за длительный промежуток времени не представляет проблем с точки зрения размера данных. Однако потенциальная стоимость распаковки миллиарда значений и прогон их через обработчик запросов неизбежно приведет к резкому увеличению времени выполнения запроса. С другой стороны, поскольку на каждый пиксель экрана приходятся сотни точек данных, становится невозможным даже визуализировать данные в полном разрешении. Таким образом, даунсэмплинг не только возможен, но и не приведет к заметной потере точности.

Для даунсемплинга данных Compactor непрерывно агрегирует данные с разрешением в пять минут и один час. Для каждого необработанного фрагмента, закодированного с помощью TSDB XOR-сжатия, хранятся различные типы агрегированных данных, такие, как min, max или sum для одного блока. Это позволяет Querier автоматически выбирать агрегат, который подходит для данного PromQL-запроса.
Для использования данных с пониженной точностью пользователю не требуется никакой специальной конфигурации. Querier автоматически переключается между различными разрешениями и необработанными данными по мере увеличения и уменьшения масштаба пользователем. При желании пользователь может управлять этим напрямую через параметр “step” в запросе.
Так как стоимость хранения одного ГБ является небольшой, то по умолчанию Thanos сохраняет исходные данные, данные с разрешением в пять минут и в один час. Нет необходимости удалять исходные данные.
Даже с Thanos recording rules являются существенной частью стека мониторинга. Они уменьшают сложность, задержку и стоимость запросов. Они также удобны пользователям для получения агрегированных данных по метрикам. Thanos базируется на ванильных экземплярах Prometheus, поэтому вполне допустимо хранить recording rules и alerting rules на существующем сервере Prometheus. Однако в некоторых случаях этого может быть недостаточно:

Для всех этих случаев Thanos включает в себя отдельный компонент, называемый Ruler, который вычисляет rule и alert через Thanos Queries. Предоставляя хорошо известный StoreAPI, узел Query может получить доступ к свежим вычисленным метрикам. Позже они также сохраняются в объектном хранилище и становятся доступны через Store Gateway.
Thanos достаточно гибок, чтобы его можно было настроить под ваши требования. Это особенно полезно при миграции с простого Prometheus. Давайте на небольшом примере быстро вспомним, что мы узнали о компонентах Thanos. Вот как перенести ваш ванильный Prometheus в мир “безлимитного хранения метрик”:

Только этих двух шагов достаточно, чтобы обеспечить global view и бесшовную дедупликацию данных от потенциальных HA-реплик Prometheus! Просто подключите свои дашборды к конечной точке HTTP Querier или используйте интерфейс Thanos UI напрямую.
Однако если вам требуется резервное копирование метрик и долгосрочное хранение, то потребуется выполнить еще три шага:
Если вы хотите узнать больше, не стесняйтесь, посмотрите на наши примеры манифеста kubernetes и getting started!
Всего за пять шагов мы превратили Prometheus в надежную систему мониторинга с global view, неограниченным временем хранения и потенциальной высокой доступности метрик.
Thanos с самого начала был проектом с открытым исходным кодом. Бесшовная интеграция с Prometheus и возможность использовать только часть Thanos делает его прекрасным выбором для масштабирования системы мониторинга без лишних усилий.
Мы всегда рады GitHub Pull Request и Issues. В то же время не стесняйтесь обращаться к нам через Github Issues или slack Improbable-eng #thanos, если у вас есть вопросы или отзывы, или вы хотите поделиться своим опытом использования! Если вам нравится то, что мы делаем в Improbable, не стесняйтесь обращаться к нам — у нас всегда есть вакансии!
Узнать подробнее о курсе.

Фабиан Рейнарц (Fabian Reinartz) — разработчик программного обеспечения, фанат Go и любитель решать сложные задачи. Также он мэйнтейнер Prometheus и соучредитель Kubernetes SIG instrumentation. В прошлом он был production-инженером в SoundCloud и возглавлял группу мониторинга в CoreOS. В настоящее время работает в Google.
Бартек Плотка (Bartek Plotka) — инфраструктурный инженер в Improbable. Увлекается новыми технологиями и проблемами распределенных систем. Имеет опыт низкоуровневого программирования в Intel, опыт контрибьютора в Mesos и production-опыт SRE мирового масштаба в Improbable. Занимается улучшением мира микросервисов. Три его любви: Golang, open source и волейбол.
Глядя на наш флагманский продукт SpatialOS, вы можете догадаться, что для Improbable нужна высокодинамичная облачная инфраструктура глобального масштаба с десятками кластеров Kubernetes. Мы были одними из первых, кто начал использовать систему мониторинга Prometheus. Prometheus способен отслеживать миллионы метрик в реальном времени и поставляется с мощным языком запросов, позволяющим извлекать необходимую информацию.
Простота и надежность Prometheus является одним из основных его преимуществ. Однако, пройдя определенный масштаб, мы столкнулись с несколькими недостатками. Для решения этих проблем мы разработали Thanos — проект с открытым исходным кодом, созданный компанией Improbable, для бесшовной трансформации существующих кластеров Prometheus в единую систему мониторинга с неограниченным хранилищем исторических данных. Thanos доступен на Github здесь.
Будьте в курсе последних новостей от Improbable.
Наши цели с Thanos
При определенном масштабе возникают проблемы, выходящие за рамки возможностей ванильного Prometheus. Как надежно и экономно хранить петабайты исторических данных? Можно ли это сделать без ущерба времени ответа на запрос? Можно ли получить доступ ко всем метрикам, расположенных на разных серверах Prometheus, с помощью одного API-запроса? Можно ли каким-то образом объединить реплицированные данные, собранные с помощью Prometheus HA?
Для решения этих вопросов мы создали Thanos. В следующих разделах описывается как мы подошли к решению этих вопросов и объясняются цели, которые мы преследовали.
Запрос данных с нескольких экземпляров Prometheus (global query)
Prometheus предлагает функциональный подход к шардингу. Даже один Prometheus-сервер обеспечивает достаточную масштабируемость, чтобы освободить пользователей от сложностей горизонтального шардинга практически во всех вариантах использования.
Хотя это отличная модель развертывания, но часто требуется получить доступ к данным на разных серверах Prometheus через единый API или UI — global view. Конечно, есть возможность отобразить несколько запросов в одной панели Grafana, но каждый запрос может быть выполнен только на один сервер Prometheus. С другой стороны, с помощью Thanos вы можете запрашивать и агрегировать данные с нескольких серверов Prometheus, поскольку все они доступны с одной конечной точки.
Ранее, для получения global view в Improbable, мы организовали наши экземпляры Prometheus в многоуровневую Hierarchical Federation. Это означало создание одного мета-сервера Prometheus, который собирает часть метрик с каждого “листового" сервера.
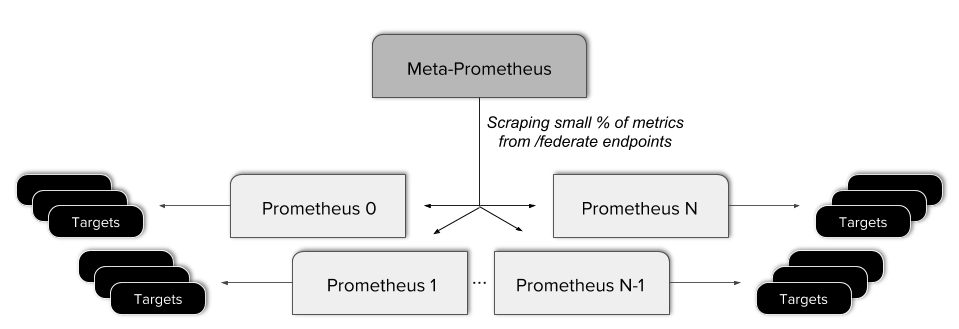
Этот подход оказался проблематичным. Он привел к усложнению конфигурации, добавлению дополнительной потенциальной точки отказа и применению сложных правил для предоставления federated-конечной точке только нужных данных. Кроме того, federation такого рода не позволяет получить настоящее global view, так как не все данные доступны из одного API-запроса.
С этим тесно связано единое представление данных, собранных на высокодоступных (high-availability, HA) серверах Prometheus. HA-модель Prometheus независимо собирает данные дважды, что настолько просто, что проще быть не может. Однако использовать объединенное и дедуплицированное представление обоих потоков было бы намного удобнее.
Конечно, в высокодоступных серверах Prometheus существует необходимость. В Improbable мы действительно серьезно относимся к ежеминутному мониторингу данных, но наличие одного экземпляра Prometheus на кластер является единой точкой отказа. Любая ошибка конфигурации или сбой оборудования могут потенциально привести к потере важных данных. Даже простое развертывание может привести к небольшим сбоям в сборе метрик, поскольку перезапуск может быть значительно дольше интервала скрапинга.
Надежное хранение исторических данных
Дешевое, быстрое и долгосрочное хранилище метрик — это наша мечта (разделяемая большинством пользователей Prometheus). В Improbable мы были вынуждены настроить срок хранения метрик на девять дней (для Prometheus 1.8). Это добавляет очевидные ограничения на то, как далеко мы можем посмотреть назад.
Prometheus 2.0 в этом отношении стал лучше, так как количество time series больше не влияет на общую производительность сервера (см. KubeCon keynote about Prometheus 2). Тем не менее Prometheus хранит данные на локальном диске. Хотя высокоэффективное сжатие данных может значительно сократить использование локального SSD, но в конечном счете все равно существует ограничение на объем сохраняемых исторических данных.
Кроме того, в Improbable мы заботимся о надежности, простоте и стоимости. Большие локальные диски сложнее в эксплуатации и резервном копировании. Они стоят дороже и требуют больше инструментов для резервного копирования, что приводит к излишней сложности.
Даунсэмплинг
Как только мы начали работать с историческими данными, мы поняли, что существуют фундаментальные сложности c O-большим, которые делают запросы все медленнее и медленнее, если мы работаем с данными за недели, месяцы и годы.
Стандартным решением этой проблемы будет даунсэмплинг (downsampling) — уменьшение частоты дискретизации сигнала. С помощью понижения дискретизации мы можем “уменьшить масштаб” до большего временного диапазона и поддерживать прежнее количество выборок, что позволит сохранить отзывчивость запросов.
Даунсэмплинг старых данных является неизбежным требованием любого решения для долгосрочного хранения и выходит за рамки ванильного Prometheus.
Дополнительные цели
Одной из первоначальных целей проекта Thanos была бесшовная интеграция с любыми существующими установками Prometheus. Вторая цель состояла в простой эксплуатации с минимальным входным барьером. Любые зависимости должны быть легко удовлетворены как для небольших, так и для крупных пользователей, что также подразумевает незначительную базовую стоимость.
Архитектура Thanos
После того как в предыдущем разделе были перечислены наши цели, давайте поработаем над ними и посмотрим, как Thanos решает эти проблемы.
Global view
Чтобы получить global view поверх существующих экземпляров Prometheus, нам нужно связать единую точку входа запросов со всеми серверами. Именно этим и занимается компонент Thanos Sidecar. Он развертывается рядом с каждым сервером Prometheus и работает как прокси, обслуживая локальные данные Prometheus через gRPC-интерфейс Store API, позволяющий выбирать time series данные по меткам и временному диапазону.
С другой стороны находится горизонтально масштабируемый компонент Querier без сохранения состояния, который делает чуть больше, чем просто отвечает на запросы PromQL через стандартный Prometheus HTTP API. Компоненты Querier, Sidecar и другие Thanos взаимодействуют по протоколу gossip.
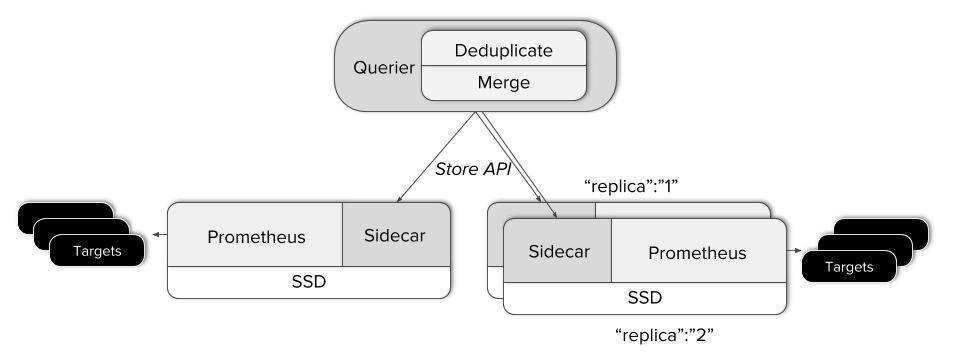
- Querier при получении запроса подключается к соответствующему серверу Store API, то есть к нашим Sidecar’ам и получает time series данные с соответствующих Prometheus-серверов.
- После этого он объединяет ответы и выполняет по ним PromQL-запрос. Querier может объединять как непересекающиеся данные, так и дублированные данные с HA-серверов Prometheus.
Это решает основную часть нашей головоломки — объединение данных с изолированных серверов Prometheus в единое представление. Фактически Thanos можно использовать только ради этой возможности. В существующие сервера Prometheus не требуется вносить какие-либо изменения!
Неограниченный срок хранения!
Однако рано или поздно мы захотим сохранить данные, выходящие за пределы обычного времени хранения Prometheus. Для хранения исторических данных мы выбрали объектное хранилище. Оно широко доступно в любом облаке, а также в локальных ЦОДах и очень экономично. Кроме того, практически любое объектное хранилище доступно через хорошо известный S3 API.
Prometheus записывает данные из оперативной памяти на диск примерно каждые два часа. Блок сохраняемых данных содержит все данные для фиксированного промежутка времени и является неизменяемым. Это очень удобно, так как Thanos Sidecar может просто смотреть каталог данных Prometheus и, по мере появления новых блоков, загружать их в бакеты объектного хранилища.

Загрузка в объектное хранилище сразу после записи на диск позволяет также сохранить простоту “скрапера” (Prometheus и Thanos Sidecar). Что упрощает поддержку, стоимость и дизайн системы.
Как видите, резервное копирование данных реализуется очень просто. Но что насчет запроса к данным в объектном хранилище?
Компонент Thanos Store действует как прокси для получения данных из объектного хранилища. Как и Thanos Sidecar, он участвует в gossip-кластере и реализует Store API. Таким образом, существующие Querier могут рассматривать его как Sidecar, в качестве еще одного источника time series данных — никакой специальной настройки не требуется.
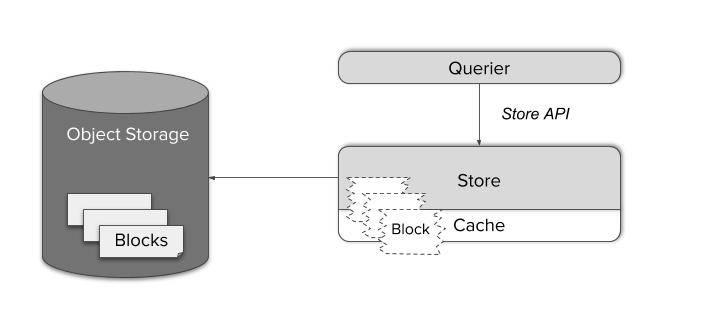
Блоки time series данных состоят из нескольких больших файлов. Загрузка их по требованию была бы довольно неэффективной, а локальное кэширование потребовало огромной памяти и дискового пространства.
Вместо этого Store Gateway знает, как обращаться с форматом хранения Prometheus. Благодаря умному планировщику запросов и кэшированию только необходимых индексных частей блоков, стало возможным сократить сложные запросы до минимального количества HTTP-запросов к файлам объектного хранилища. Таким образом, можно сократить число запросов на четыре-шесть порядков и достичь времени отклика, которое в целом трудно отличить от запросов к данным на локальном SSD.

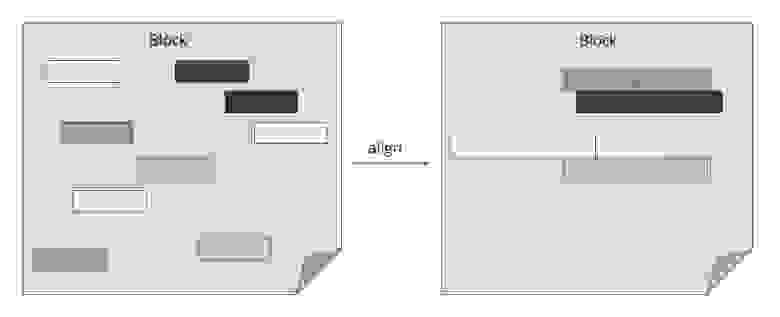
Как показано на диаграмме выше, Thanos Querier значительно снижает затраты на один запрос к данным в объектном хранилище, используя формат хранения Prometheus и размещая связанные данные рядом. Используя этот подход, мы можем объединить множество одиночных запросов в минимальное количество bulk-операций.
Уплотнение и даунсэмплинг
После того как новый блок time series данных успешно загружен в объектное хранилище, мы рассматриваем его как “исторические” данные, которые сразу же становятся доступны через Store Gateway.
Однако через некоторое время блоки из одного источника (Prometheus с Sidecar) накапливаются и уже не используют весь потенциал индексации. Для решения этой проблемы мы ввели еще один компонент под названием Compactor. Он просто применяет локальный механизм уплотнения Prometheus к историческим данным в объектном хранилище и может быть запущен как простое периодическое пакетное задание.

Благодаря эффективному сжатию, запрос в хранилище за длительный промежуток времени не представляет проблем с точки зрения размера данных. Однако потенциальная стоимость распаковки миллиарда значений и прогон их через обработчик запросов неизбежно приведет к резкому увеличению времени выполнения запроса. С другой стороны, поскольку на каждый пиксель экрана приходятся сотни точек данных, становится невозможным даже визуализировать данные в полном разрешении. Таким образом, даунсэмплинг не только возможен, но и не приведет к заметной потере точности.
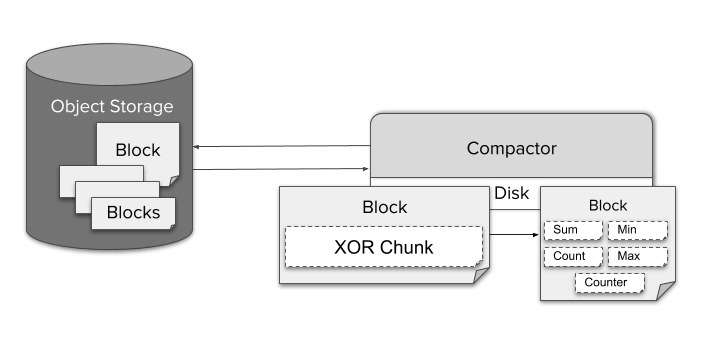
Для даунсемплинга данных Compactor непрерывно агрегирует данные с разрешением в пять минут и один час. Для каждого необработанного фрагмента, закодированного с помощью TSDB XOR-сжатия, хранятся различные типы агрегированных данных, такие, как min, max или sum для одного блока. Это позволяет Querier автоматически выбирать агрегат, который подходит для данного PromQL-запроса.
Для использования данных с пониженной точностью пользователю не требуется никакой специальной конфигурации. Querier автоматически переключается между различными разрешениями и необработанными данными по мере увеличения и уменьшения масштаба пользователем. При желании пользователь может управлять этим напрямую через параметр “step” в запросе.
Так как стоимость хранения одного ГБ является небольшой, то по умолчанию Thanos сохраняет исходные данные, данные с разрешением в пять минут и в один час. Нет необходимости удалять исходные данные.
Recording rules
Даже с Thanos recording rules являются существенной частью стека мониторинга. Они уменьшают сложность, задержку и стоимость запросов. Они также удобны пользователям для получения агрегированных данных по метрикам. Thanos базируется на ванильных экземплярах Prometheus, поэтому вполне допустимо хранить recording rules и alerting rules на существующем сервере Prometheus. Однако в некоторых случаях этого может быть недостаточно:
- Глобальные alert и rule (например, оповещение, когда сервис не работает на более чем двух из трех кластеров).
- Rule для данных вне локального хранилища.
- Стремление хранить все rule и alert в одном месте.

Для всех этих случаев Thanos включает в себя отдельный компонент, называемый Ruler, который вычисляет rule и alert через Thanos Queries. Предоставляя хорошо известный StoreAPI, узел Query может получить доступ к свежим вычисленным метрикам. Позже они также сохраняются в объектном хранилище и становятся доступны через Store Gateway.
Мощь Thanos
Thanos достаточно гибок, чтобы его можно было настроить под ваши требования. Это особенно полезно при миграции с простого Prometheus. Давайте на небольшом примере быстро вспомним, что мы узнали о компонентах Thanos. Вот как перенести ваш ванильный Prometheus в мир “безлимитного хранения метрик”:

- Добавьте Thanos Sidecar к вашим серверам Prometheus — например, соседний контейнер в Kubernetes pod.
- Разверните несколько реплик Thanos Querier для возможности просмотра данных. На данном этапе легко настроить gossip между Scraper и Querier. Для проверки взаимодействия компонент используйте метрику 'thanos_cluster_members'.
Только этих двух шагов достаточно, чтобы обеспечить global view и бесшовную дедупликацию данных от потенциальных HA-реплик Prometheus! Просто подключите свои дашборды к конечной точке HTTP Querier или используйте интерфейс Thanos UI напрямую.
Однако если вам требуется резервное копирование метрик и долгосрочное хранение, то потребуется выполнить еще три шага:
- Создайте бакет AWS S3 или GCS. Настройте Sidecar для копирования данных в эти бакеты. Теперь можно свести к минимуму локальное хранение данных.
- Разверните Store Gateway и подключите его к существующему gossip-кластеру. Теперь можно отправлять запросы к данным в резервных копиях!
- Разверните Compactor, чтобы повысить эффективность запросов для длительных промежутков времени, используя уплотнение и даунсэмплинг.
Если вы хотите узнать больше, не стесняйтесь, посмотрите на наши примеры манифеста kubernetes и getting started!
Всего за пять шагов мы превратили Prometheus в надежную систему мониторинга с global view, неограниченным временем хранения и потенциальной высокой доступности метрик.
Pull request: вы нужны нам!
Thanos с самого начала был проектом с открытым исходным кодом. Бесшовная интеграция с Prometheus и возможность использовать только часть Thanos делает его прекрасным выбором для масштабирования системы мониторинга без лишних усилий.
Мы всегда рады GitHub Pull Request и Issues. В то же время не стесняйтесь обращаться к нам через Github Issues или slack Improbable-eng #thanos, если у вас есть вопросы или отзывы, или вы хотите поделиться своим опытом использования! Если вам нравится то, что мы делаем в Improbable, не стесняйтесь обращаться к нам — у нас всегда есть вакансии!
Узнать подробнее о курсе.
