Перевод статьи подготовлен специально для студентов курса «Базы данных».

То, что вы, возможно, не знали о генерации случайных чисел в sysbench
Sysbench — это популярный инструмент для тестирования производительности. Первоначально он был написан Петром Зайцевым в начале 2000-ых и стал стандартом де-факто для тестирования и бенчмарка. В настоящее время он поддерживается Алексеем Копытовым и размещен в Github по адресу.
Однако, я заметил, что, несмотря на его широкое распространение, в sysbench есть малознакомые многим моменты. Например, возможность простой модификации тестов MySQL с помощью Lua или настройка параметров встроенного генератора случайных чисел.
Я написал эту статью с целью показать, как легко можно настроить sysbench под ваши требования. Есть много способов расширения функциональности sysbench и один из них — настройка генерации случайных идентификаторов (ID).
По умолчанию sysbench поставляется с пятью различными вариантами генерации случайных чисел. Но очень часто (на самом деле, почти никогда) ни один из них не указывается явно, и еще реже можно увидеть параметры генерации (для вариантов, где они доступны).
Если у вас возник вопрос: «И почему меня это должно интересовать? Ведь значения по умолчанию вполне подходят», — тогда этот пост призван помочь вам понять, почему это не всегда так.
Какие есть способы генерации случайных чисел в sysbench? На данный момент реализованы следующие (их вы легко можете посмотреть через опцию --help):
По умолчанию используется Special со следующими параметрами:
Поскольку мне нравятся простые и легко воспроизводимые тесты и сценарии, все последующие данные будут собраны с помощью следующих команд sysbench:
Не стесняйтесь экспериментировать самостоятельно. Описание скрипта и данные можно найти здесь.
Для чего в sysbench используется генератор случайных чисел? Одно из назначений — генерация ID, которые будут использоваться в запросах. Так, в нашем примере будут генерироваться числа между 1 и 100, с учетом создания 10 таблиц по 100 строк в каждой.
Что, если запустить sysbench, как указано выше, и изменять только -rand-type?
Я запустил этот скрипт и использовал general log для сбора и анализа частоты сгенерированных значений ID. Вот результат:
Special

Uniform

Zipfian
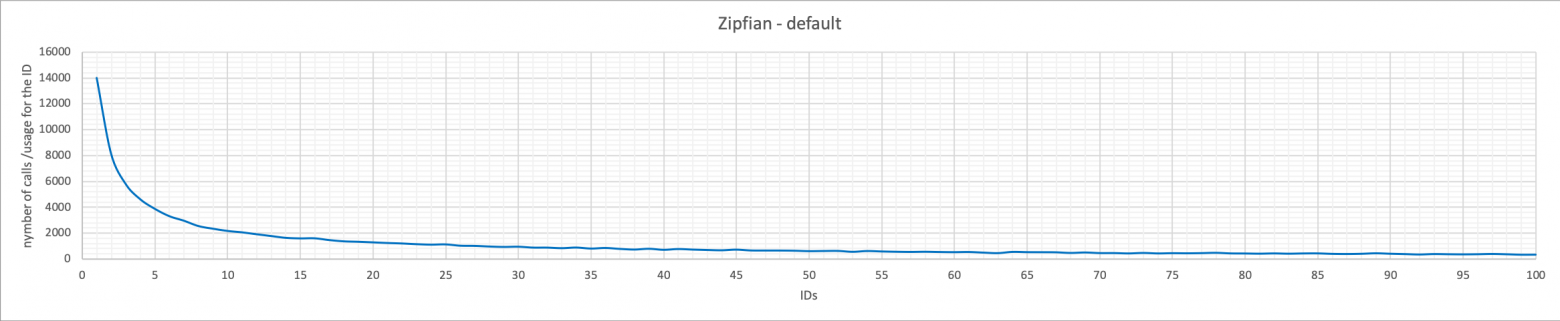
Pareto
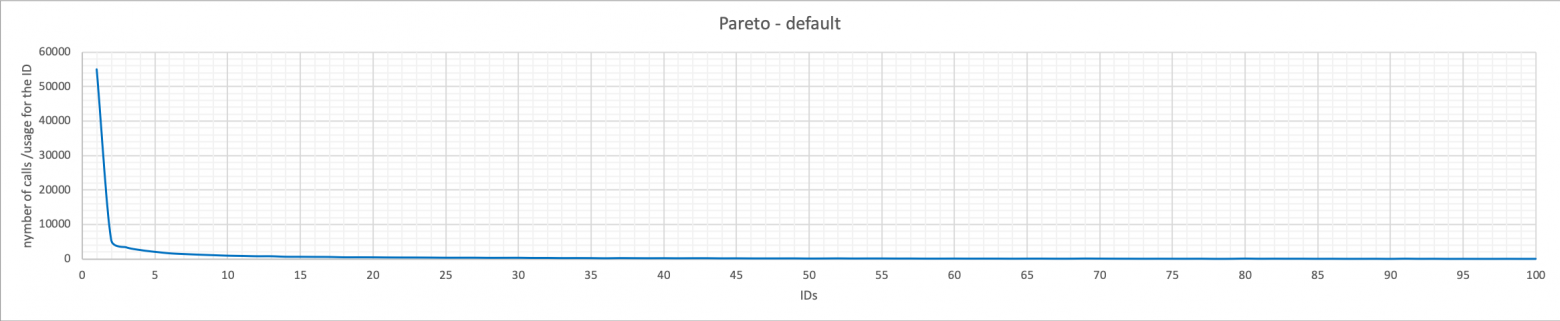
Gaussian
Видно, что этот параметр имеет значение, верно? В конце концов, sysbench делает именно то, что мы от него ожидали.
Давайте посмотрим внимательнее на каждое из распределений.
По умолчанию используется special, поэтому если вы НЕ указываете rand-type, то sysbench будет использовать special. Special использует очень ограниченное количество значений ID. В нашем примере мы можем увидеть, что используются в основном значения 50-51, остальные значения между 44-56 — крайне редко, а другие практически не используются. Обратите внимание, что выбранные значения находятся в середине доступного диапазона 1-100.
В этом случае пик находится около двух ID, представляющих 2% выборки. Если я увеличу количество записей до одного миллиона, то пик останется, но будет на значении 7493, что составляет 0,74% от выборки. Так как это будет более ограничивать, то количество страниц, вероятно, будет больше одной.
Как сказано в названии, если мы используем Uniform, то для ID будут использоваться все значения, а распределение будет… равномерным.
Распределение Ципфа, иногда называемое дзета-распределением — это дискретное распределение, обычно используемое в лингвистике, страховании и моделировании редких событий. В этом случае sysbench будет использовать числа начиная с наименьшего (1) и очень быстро уменьшать частоту использования, двигаясь к большим числам.
Pareto применяет правило “80-20”. В данном случае сгенерированные ID будут еще меньше размазаны и будут более сосредоточены в небольшом сегменте. В нашем примере у 52% всех ID было значение 1, а 73% значений были в первых 10 числах.
Распределение Гаусса (нормальное распределение) хорошо известно и знакомо. Используется в основном в статистике и прогнозировании вокруг центрального фактора. В этом случае используемые ID распределяются по колоколообразной кривой, начиная со среднего значения, и медленно убывая к краям.
У каждого из вышеперечисленных вариантов есть свое использование и их можно сгруппировать по назначению. Pareto и Special сосредоточены на “горячих точках”. В этом случае приложение использует одну и ту же страницу / данные снова и снова. Это может быть то, что нам нужно, но мы должны понимать, что мы делаем и не допустить здесь ошибки.
Например, если мы тестируем эффективность сжатия страниц InnoDB при чтении, нам следует избегать использования значения по умолчанию Special или Pareto. Если у нас есть набор данных 1 ТБ и буферный пул 30 ГБ, и мы запрашиваем одну и ту же страницу много раз, то эта страница уже будет прочитана с диска и будет доступна несжатой в памяти.
Короче говоря, такой тест — это пустая трата времени и усилий.
То же самое, если нам нужно проверить эффективность записи. Писать одну и ту же страницу снова и снова — это не лучший вариант.
Как насчет тестирования производительности?
Опять же, мы хотим протестировать производительность, но для какого случая? Важно понимать, что способ генерации случайных чисел сильно влияет на результаты теста. И ваши “достаточно хорошие значения по умолчанию” могут привести к ошибочным выводам.
На следующих графиках показаны разные задержки (latency) в зависимости от rand-type (тип теста, время, дополнительные параметры и количество потоков везде одинаковые).
От типа к типу задержки существенно отличаются:

Здесь я делал чтение и запись, а данные брал из Performance Schema (
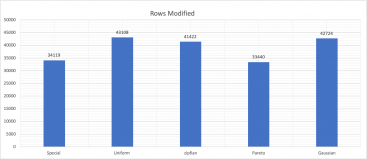
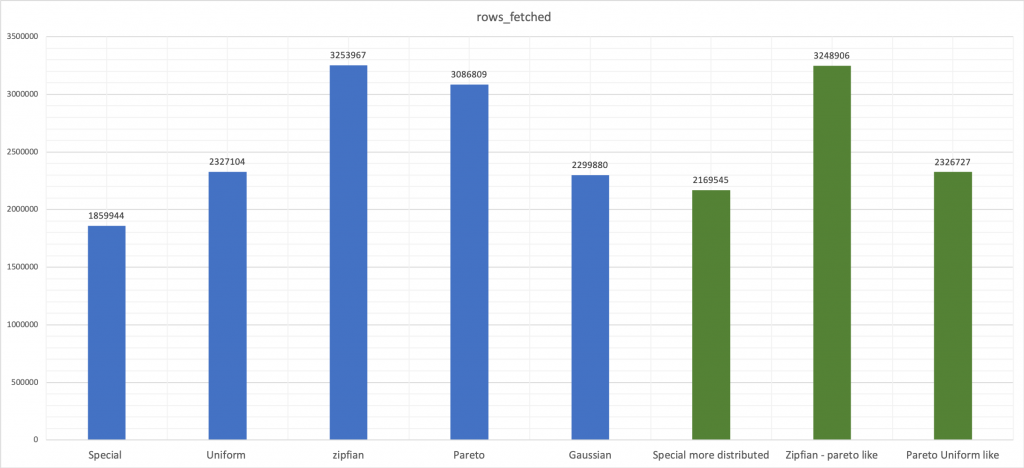
Изменение rand-type влияет не только на задержку, но и на количество обработанных строк, о чем говорит performance schema.
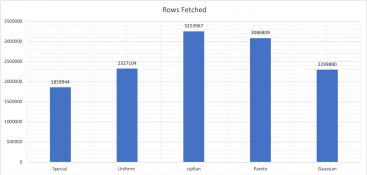
Учитывая все вышесказанное, важно понимать, что мы пытаемся оценить и протестировать.
Если моей целью является тестирование производительности системы на всех уровнях, я, возможно, предпочту использовать Uniform, который в равной степени нагрузит набор данных / сервер БД / систему и, более вероятно, распределит чтение / загрузку / запись равномерно.
Если моя задача состоит в том, чтобы поработать с “горячими точками”, то, вероятно, Pareto и Special — правильный выбор.
Но при этом не используйте значения по умолчанию вслепую. Они могут вам подойти, но часто они предназначены для крайних случаев. По моему опыту часто можно настроить параметры, чтобы получить нужный вам результат.
Например, вы хотите использовать значения в середине, расширив интервал так, чтобы не было острого пика (Special по умолчанию) или колокола (Gaussian).
Можно настроить Special для получения что-то вроде этого:
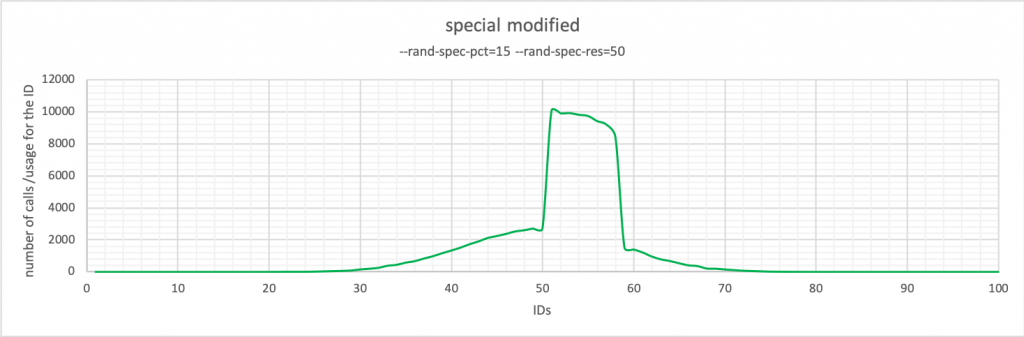
В этом случае ID все еще находятся рядом, и есть конкуренция. Но влияние одной “горячей точки” меньше, поэтому возможные конфликты теперь будут с несколькими ID, которые, в зависимости от количества записей на странице, могут быть на нескольких страницах.
Еще один пример — партиционирование (partitioning). Например, как проверить работу вашей системы с партициями, сосредоточившись на свежих данных, архивируя старые?
Легко! Помните график распределения Pareto? Вы можете изменить его в соответствии с вашими потребностями.

Указав значение -rand-pareto, вы можете получить именно то, что хотели, заставив sysbench сфокусироваться на больших значениях ID.
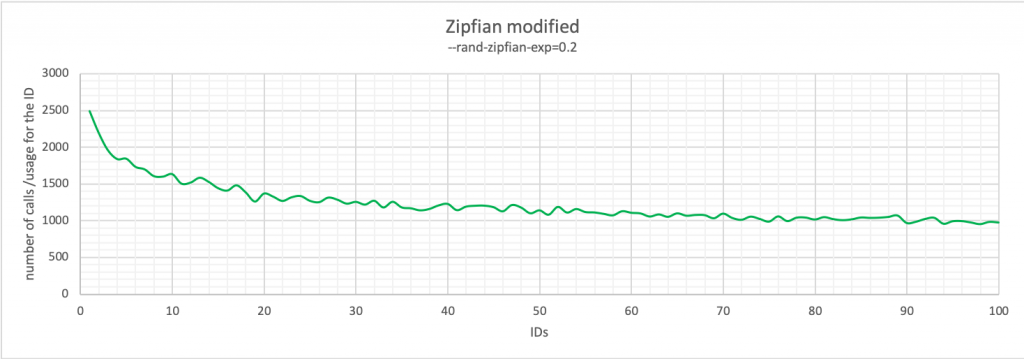
Zipfian также можно настроить и, хотя, вы не можете получить инверсию, как в случае с Pareto, но можете легко перейти от пика на одном значении к более равномерному распределению. Хорошим примером может служить следующее:
Последнее, что нужно иметь в виду, и мне кажется, что это очевидные вещи, но лучше сказать, чем не сказать — при изменении параметров генерации случайных чисел будет меняться производительность.
Сравните задержки (latency):
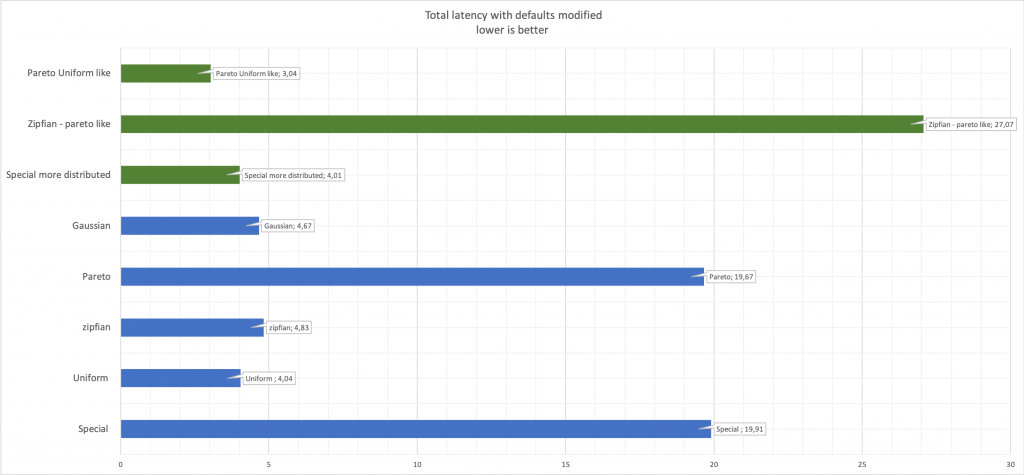
Здесь зеленым цветом показаны измененные значения по сравнению с исходными синими.
К этому моменту вы уже должны понять, как легко можно настроить в sysbench генерацию случайных чисел, и насколько полезным это может быть для вас. Имейте в виду, что описанное выше относится к любым вызовам, например, при использовании
Учитывая это, не копируйте бездумно код из чужих статей, а думайте и вникайте в то, что вам требуется и как этого добиться.
Перед запуском тестов проверьте параметры генерации случайных чисел, чтобы убедиться, что они подходят и соответствуют вашим потребностям. Чтобы упростить себе жизнь, я использую этот простой тест. Этот тест выводит довольно понятную информацию о распределении ID.
Мой совет в том, что вы должны понимать ваши потребности и правильно проводить тестирование/бенчмаркинг.
Прежде всего, это сам sysbench
Статьи по Zipfian:
Pareto:
Статья Percona о том, как писать свои скрипты в sysbench
Все материалы, использованные для этой статьи, находятся на GitHub.
→ Узнать подробнее о курсе

То, что вы, возможно, не знали о генерации случайных чисел в sysbench
Sysbench — это популярный инструмент для тестирования производительности. Первоначально он был написан Петром Зайцевым в начале 2000-ых и стал стандартом де-факто для тестирования и бенчмарка. В настоящее время он поддерживается Алексеем Копытовым и размещен в Github по адресу.
Однако, я заметил, что, несмотря на его широкое распространение, в sysbench есть малознакомые многим моменты. Например, возможность простой модификации тестов MySQL с помощью Lua или настройка параметров встроенного генератора случайных чисел.
О чем эта статья?
Я написал эту статью с целью показать, как легко можно настроить sysbench под ваши требования. Есть много способов расширения функциональности sysbench и один из них — настройка генерации случайных идентификаторов (ID).
По умолчанию sysbench поставляется с пятью различными вариантами генерации случайных чисел. Но очень часто (на самом деле, почти никогда) ни один из них не указывается явно, и еще реже можно увидеть параметры генерации (для вариантов, где они доступны).
Если у вас возник вопрос: «И почему меня это должно интересовать? Ведь значения по умолчанию вполне подходят», — тогда этот пост призван помочь вам понять, почему это не всегда так.
Давайте начнем
Какие есть способы генерации случайных чисел в sysbench? На данный момент реализованы следующие (их вы легко можете посмотреть через опцию --help):
- Special (специальное распределение)
- Gaussian (распределение Гаусса)
- Pareto (распределение Парето)
- Zipfian (распределение Ципфа)
- Uniform (равномерное распределение)
По умолчанию используется Special со следующими параметрами:
rand-spec-iter = 12— количество итераций для специального распределенияrand-spec-pct = 1— процент от всего диапазона, в которое попадают “специальные” значения при специальном распределенииrand-spec-res = 75— процент “специальных” значений для использования в специальном распределении
Поскольку мне нравятся простые и легко воспроизводимые тесты и сценарии, все последующие данные будут собраны с помощью следующих команд sysbench:
- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine=innodb –db-driver=mysql –tables=10 –table_size=100 prepare
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
Не стесняйтесь экспериментировать самостоятельно. Описание скрипта и данные можно найти здесь.
Для чего в sysbench используется генератор случайных чисел? Одно из назначений — генерация ID, которые будут использоваться в запросах. Так, в нашем примере будут генерироваться числа между 1 и 100, с учетом создания 10 таблиц по 100 строк в каждой.
Что, если запустить sysbench, как указано выше, и изменять только -rand-type?
Я запустил этот скрипт и использовал general log для сбора и анализа частоты сгенерированных значений ID. Вот результат:
Special

Uniform

Zipfian

Pareto

Gaussian

Видно, что этот параметр имеет значение, верно? В конце концов, sysbench делает именно то, что мы от него ожидали.
Давайте посмотрим внимательнее на каждое из распределений.
Special
По умолчанию используется special, поэтому если вы НЕ указываете rand-type, то sysbench будет использовать special. Special использует очень ограниченное количество значений ID. В нашем примере мы можем увидеть, что используются в основном значения 50-51, остальные значения между 44-56 — крайне редко, а другие практически не используются. Обратите внимание, что выбранные значения находятся в середине доступного диапазона 1-100.
В этом случае пик находится около двух ID, представляющих 2% выборки. Если я увеличу количество записей до одного миллиона, то пик останется, но будет на значении 7493, что составляет 0,74% от выборки. Так как это будет более ограничивать, то количество страниц, вероятно, будет больше одной.
Uniform (равномерное распределение)
Как сказано в названии, если мы используем Uniform, то для ID будут использоваться все значения, а распределение будет… равномерным.
Zipfian (распределение Ципфа)
Распределение Ципфа, иногда называемое дзета-распределением — это дискретное распределение, обычно используемое в лингвистике, страховании и моделировании редких событий. В этом случае sysbench будет использовать числа начиная с наименьшего (1) и очень быстро уменьшать частоту использования, двигаясь к большим числам.
Pareto (Парето)
Pareto применяет правило “80-20”. В данном случае сгенерированные ID будут еще меньше размазаны и будут более сосредоточены в небольшом сегменте. В нашем примере у 52% всех ID было значение 1, а 73% значений были в первых 10 числах.
Gaussian (распределение Гаусса)
Распределение Гаусса (нормальное распределение) хорошо известно и знакомо. Используется в основном в статистике и прогнозировании вокруг центрального фактора. В этом случае используемые ID распределяются по колоколообразной кривой, начиная со среднего значения, и медленно убывая к краям.
Какой в этом смысл?
У каждого из вышеперечисленных вариантов есть свое использование и их можно сгруппировать по назначению. Pareto и Special сосредоточены на “горячих точках”. В этом случае приложение использует одну и ту же страницу / данные снова и снова. Это может быть то, что нам нужно, но мы должны понимать, что мы делаем и не допустить здесь ошибки.
Например, если мы тестируем эффективность сжатия страниц InnoDB при чтении, нам следует избегать использования значения по умолчанию Special или Pareto. Если у нас есть набор данных 1 ТБ и буферный пул 30 ГБ, и мы запрашиваем одну и ту же страницу много раз, то эта страница уже будет прочитана с диска и будет доступна несжатой в памяти.
Короче говоря, такой тест — это пустая трата времени и усилий.
То же самое, если нам нужно проверить эффективность записи. Писать одну и ту же страницу снова и снова — это не лучший вариант.
Как насчет тестирования производительности?
Опять же, мы хотим протестировать производительность, но для какого случая? Важно понимать, что способ генерации случайных чисел сильно влияет на результаты теста. И ваши “достаточно хорошие значения по умолчанию” могут привести к ошибочным выводам.
На следующих графиках показаны разные задержки (latency) в зависимости от rand-type (тип теста, время, дополнительные параметры и количество потоков везде одинаковые).
От типа к типу задержки существенно отличаются:

Здесь я делал чтение и запись, а данные брал из Performance Schema (
sys.schema_table_statistics). Как и ожидалось, Pareto и Special занимают гораздо больше времени, чем другие, заставляя систему (MySQL-InnoDB) искусственно страдать от конкуренции в одной “горячей точке”.Изменение rand-type влияет не только на задержку, но и на количество обработанных строк, о чем говорит performance schema.


Учитывая все вышесказанное, важно понимать, что мы пытаемся оценить и протестировать.
Если моей целью является тестирование производительности системы на всех уровнях, я, возможно, предпочту использовать Uniform, который в равной степени нагрузит набор данных / сервер БД / систему и, более вероятно, распределит чтение / загрузку / запись равномерно.
Если моя задача состоит в том, чтобы поработать с “горячими точками”, то, вероятно, Pareto и Special — правильный выбор.
Но при этом не используйте значения по умолчанию вслепую. Они могут вам подойти, но часто они предназначены для крайних случаев. По моему опыту часто можно настроить параметры, чтобы получить нужный вам результат.
Например, вы хотите использовать значения в середине, расширив интервал так, чтобы не было острого пика (Special по умолчанию) или колокола (Gaussian).
Можно настроить Special для получения что-то вроде этого:

В этом случае ID все еще находятся рядом, и есть конкуренция. Но влияние одной “горячей точки” меньше, поэтому возможные конфликты теперь будут с несколькими ID, которые, в зависимости от количества записей на странице, могут быть на нескольких страницах.
Еще один пример — партиционирование (partitioning). Например, как проверить работу вашей системы с партициями, сосредоточившись на свежих данных, архивируя старые?
Легко! Помните график распределения Pareto? Вы можете изменить его в соответствии с вашими потребностями.

Указав значение -rand-pareto, вы можете получить именно то, что хотели, заставив sysbench сфокусироваться на больших значениях ID.
Zipfian также можно настроить и, хотя, вы не можете получить инверсию, как в случае с Pareto, но можете легко перейти от пика на одном значении к более равномерному распределению. Хорошим примером может служить следующее:

Последнее, что нужно иметь в виду, и мне кажется, что это очевидные вещи, но лучше сказать, чем не сказать — при изменении параметров генерации случайных чисел будет меняться производительность.
Сравните задержки (latency):
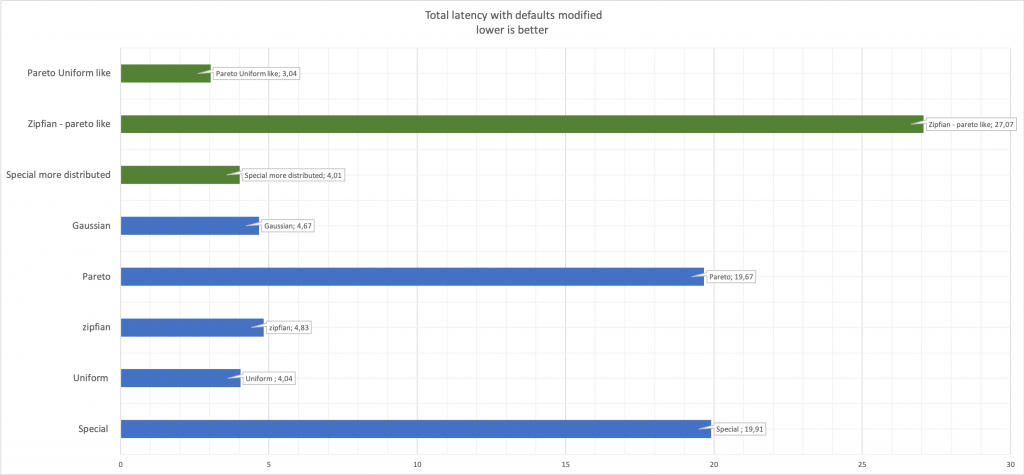
Здесь зеленым цветом показаны измененные значения по сравнению с исходными синими.

Выводы
К этому моменту вы уже должны понять, как легко можно настроить в sysbench генерацию случайных чисел, и насколько полезным это может быть для вас. Имейте в виду, что описанное выше относится к любым вызовам, например, при использовании
sysbench.rand.default:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
EndУчитывая это, не копируйте бездумно код из чужих статей, а думайте и вникайте в то, что вам требуется и как этого добиться.
Перед запуском тестов проверьте параметры генерации случайных чисел, чтобы убедиться, что они подходят и соответствуют вашим потребностям. Чтобы упростить себе жизнь, я использую этот простой тест. Этот тест выводит довольно понятную информацию о распределении ID.
Мой совет в том, что вы должны понимать ваши потребности и правильно проводить тестирование/бенчмаркинг.
Ссылки
Прежде всего, это сам sysbench
Статьи по Zipfian:
Pareto:
Статья Percona о том, как писать свои скрипты в sysbench
Все материалы, использованные для этой статьи, находятся на GitHub.
→ Узнать подробнее о курсе
