В преддверии старта курса «Data Engineer» подготовили перевод небольшого, но интересного материала.

В этой статье я расскажу о том, как Parquet сжимает большие наборы данных в маленький файл footprint, и как мы можем достичь пропускной способности, значительно превышающей пропускную способность потока ввода-вывода, используя параллелизм (многопоточность).
Как вы можете понять из спецификации формата Apache Parquet, он содержит несколько уровней кодирования, которые позволяют достичь существенного уменьшения размера файла, среди которых можно выделить:
Чтобы показать вам, как это работает, давайте рассмотрим набор данных:
Почти все реализации Parquet используют для сжатия словарь по умолчанию. Таким образом, закодированные данные выглядят следующим образом:
Индексы в словаре дополнительно сжимаются алгоритмом кодирования повторов:
Идя по обратному пути, вы с легкостью можете восстановить исходный массив строк.
В своей предыдущей статье я создал набор данных, который очень хорошо сжимается таким способом. При работе с
Набор данных, который занимает 1 Гб (1024 Мб) в
В реализации Apache Parquet на языке C++ — parquet-cpp, которую мы сделали доступной для Python в PyArrow, была добавлена возможность читать столбцы параллельно.
Чтобы попробовать эту функцию, установите PyArrow из conda-forge:
Теперь при чтении файла Parquet вы можете использовать аргумент
Для данных с низкой энтропией декомпрессия и декодирование сильно завязываются на процессоре. Поскольку всю работу у нас делает C++, не возникает проблем с параллелизмом GIL и мы можем добиться значительного повышения скорости. Посмотрите, чего я смог добиться, читая набор данных из 1 Гб в pandas DataFrame на четырехъядерном ноутбуке (Xeon E3-1505M, NVMe SSD):

Полный сценарий бенчмаркинга вы можете посмотреть здесь.
Я включил сюда производительность как для случаев сжатия с помощью словаря, так и для случаев без использования словаря. Для данных с низкой энтропией несмотря на то, что все файлы небольшие (~1,5 МБ с использованием словарей и ~45 МБ — без), сжатие с помощью словаря существенно влияет на производительность. С 4 потоками производительность чтения на pandas возрастает до 4 GB/s. Это гораздо быстрее, чем формат Feather или же любой другой мне известный.
С релизом версии 1.0 parquet-cpp (Apache Parquet на C++) вы сможете сами убедиться в росте производительности ввода-вывода, которые теперь доступны для пользователей Python.
Поскольку все базовые механизмы реализованы на С++, на других языках (например, на R) можно создавать интерфейсы для Apache Arrow (столбчатые структуры данных) и parquet-cpp. Привязка Python представляет из себя облегченную оболочку базовых библиотек libarrow и libparquet на C++.
На этом все. Если хотите подробнее узнать о нашем курсе, записывайтесь на день открытых дверей, который пройдет уже сегодня!

В этой статье я расскажу о том, как Parquet сжимает большие наборы данных в маленький файл footprint, и как мы можем достичь пропускной способности, значительно превышающей пропускную способность потока ввода-вывода, используя параллелизм (многопоточность).
Apache Parquet: Лучший в работе с низкоэнтропийными данными
Как вы можете понять из спецификации формата Apache Parquet, он содержит несколько уровней кодирования, которые позволяют достичь существенного уменьшения размера файла, среди которых можно выделить:
- Кодирование (сжатие) с использованием словаря (аналогично способу представления данных pandas.Categorical, но сами по себе концепции разные);
- Сжатие страниц данных (Snappy, Gzip, LZO или Brotli);
- Кодирование длины выполнения (для null — указателей и индексов словаря) и целочисленной битовой упаковки;
Чтобы показать вам, как это работает, давайте рассмотрим набор данных:
['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']Почти все реализации Parquet используют для сжатия словарь по умолчанию. Таким образом, закодированные данные выглядят следующим образом:
dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]Индексы в словаре дополнительно сжимаются алгоритмом кодирования повторов:
dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]Идя по обратному пути, вы с легкостью можете восстановить исходный массив строк.
В своей предыдущей статье я создал набор данных, который очень хорошо сжимается таким способом. При работе с
pyarrow, мы можем включать и отключать кодирование с помощью словаря (которое включено по умолчанию), чтобы увидеть, как это повлияет на размер файла:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)Набор данных, который занимает 1 Гб (1024 Мб) в
pandas.DataFrame, со сжатием Snappy и сжатием с помощью словаря занимает всего 1.436 MB, то есть его можно записать даже на дискету. Без сжатия с помощью словаря он будет занимать 44.4 MB.Параллельное чтение в parquet-cpp с помощью PyArrow
В реализации Apache Parquet на языке C++ — parquet-cpp, которую мы сделали доступной для Python в PyArrow, была добавлена возможность читать столбцы параллельно.
Чтобы попробовать эту функцию, установите PyArrow из conda-forge:
conda install pyarrow -c conda-forgeТеперь при чтении файла Parquet вы можете использовать аргумент
nthreads: import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)Для данных с низкой энтропией декомпрессия и декодирование сильно завязываются на процессоре. Поскольку всю работу у нас делает C++, не возникает проблем с параллелизмом GIL и мы можем добиться значительного повышения скорости. Посмотрите, чего я смог добиться, читая набор данных из 1 Гб в pandas DataFrame на четырехъядерном ноутбуке (Xeon E3-1505M, NVMe SSD):
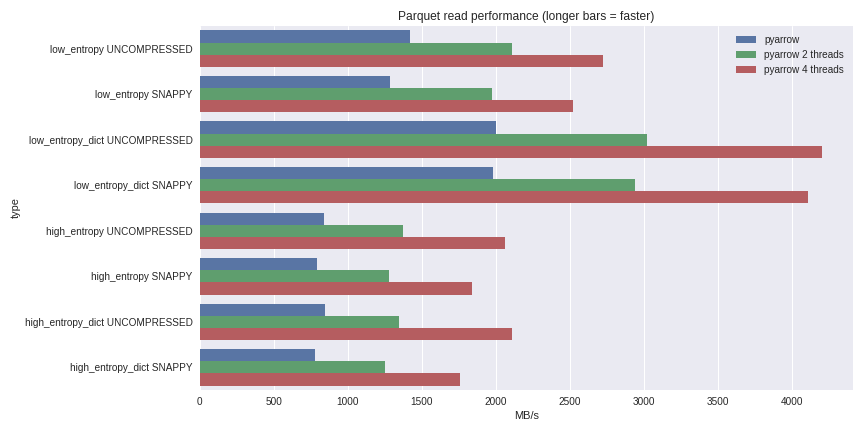
Полный сценарий бенчмаркинга вы можете посмотреть здесь.
Я включил сюда производительность как для случаев сжатия с помощью словаря, так и для случаев без использования словаря. Для данных с низкой энтропией несмотря на то, что все файлы небольшие (~1,5 МБ с использованием словарей и ~45 МБ — без), сжатие с помощью словаря существенно влияет на производительность. С 4 потоками производительность чтения на pandas возрастает до 4 GB/s. Это гораздо быстрее, чем формат Feather или же любой другой мне известный.
Заключение
С релизом версии 1.0 parquet-cpp (Apache Parquet на C++) вы сможете сами убедиться в росте производительности ввода-вывода, которые теперь доступны для пользователей Python.
Поскольку все базовые механизмы реализованы на С++, на других языках (например, на R) можно создавать интерфейсы для Apache Arrow (столбчатые структуры данных) и parquet-cpp. Привязка Python представляет из себя облегченную оболочку базовых библиотек libarrow и libparquet на C++.
На этом все. Если хотите подробнее узнать о нашем курсе, записывайтесь на день открытых дверей, который пройдет уже сегодня!
