Привет, хабровчане. Сегодня стартуют занятия в первой группе курса «PostgreSQL». В связи с этим, хотим рассказать вам о том, как проходил открытый вебинар по данному курсу.

В очередном открытом уроке поговорили о том, с какими вызовами столкнулись SQL-базы в эру облаков и Kubernetes. А заодно рассмотрели, как базы данных SQL приспосабливаются и мутируют под воздействием этих вызовов.
Вебинар провёл Валерий Безруков, Google Cloud Practice Delivery Manager в EPAM Systems.
Для начала давайте вспомним, как начинался выбор СУБД в конце прошлого века. Впрочем, это не составит труда, ведь выбор СУБД в те времена начинался и заканчивался Oracle.

В конце 90-х — начале нулевых, особого выбора, по сути, не было, если говорить про промышленные масштабируемые БД. Да, существовали IBM DB2, Sybase и ещё какие-то базы данных, которые появлялись и исчезали, но в общем и целом они были не так заметны на фоне Oracle. Соответственно, навыки инженеров тех времён были так или иначе завязаны на то единственный выбор, который существовал.
Oracle DBA должен был уметь:
— создавать:
— выполнять резервное копирование и восстановление;
— осуществлять мониторинг;
— бороться с неоптимальными запросами.
При этом от Oracle DBA особо не требовалось:
В общем, если говорить о выборе в те времена, то он напоминает выбор в советском магазине в конце 80-х:

С тех пор, разумеется, деревья подросли, мир изменился, и стало как-то так:

Изменился и рынок СУБД, что хорошо видно по свежему докладу компании Gartner:

И здесь нельзя не отметить, что свою нишу заняли облака, популярность которых растёт. Если почитать тот же отчёт компании Gartner, мы увидим следующие выводы:
Сегодня все мы в облаке. А те вопросы, которые у нас появляются, — это вопросы выбора. А он огромный, даже если говорить только про выбор технологий СУБД в формате On-premises. А ещё у нас есть managed services и SaaS. Таким образом, выбор с каждым годом только усложняется.
Наряду с вопросами выбора, действуют и ограничительные факторы:
Что ждут сейчас от DA/DE:
Нижеследующий пример на базе GCP демонстрирует, как устроен выбор той или иной технологии работы с данными в зависимости от их структуры:

Обратите внимание, что в схеме отсутствует PostgreSQL, а всё потому, что он прячется под терминологией Cloud SQL. И когда мы попадаем в Cloud SQL, нам нужно опять сделать выбор:

Следует заметить, что этот выбор не всегда понятен, поэтому разработчики приложения зачастую руководствуются интуицией.
Итого:

Не претендуя на истину в последней инстанции, скажем следующее:
Нужно менять подход к обучению:
Нужно знать не только и не сколько продукт, а:
А ещё нужно уметь мигрировать данные и понимать базовые принципы интеграции с ETL.
В недавнем прошлом приходилось делать бэкенд для мобильного приложения. К моменту начала работы над ним бэкенд уже был разработан и готов к внедрению, а команда разработчиков потратила на этот проект около двух лет. При этом были поставлены следующие задачи:
Само приложение было микросервисным, а код на Python/Django был разработан с нуля и сразу в GCP. Что касается целевой аудитории, то предполагалось, что будет два региона — US и EU, а трафик распределялся через Global Load balancer. Все Workloads и вычислительная нагрузка работали в Google Kubernetes Engine.
Что касается данных, то были 3 структуры:

Может возникнуть вопрос, почему был выбран Cloud SQL? Говоря по правде, такой вопрос в последние годы вызывает какую-то неловкую паузу — возникает ощущение, что люди стали стесняться реляционных баз, но тем не менее они продолжают их активно использовать ;-).
Что касается нашего случая, то Cloud SQL был выбран по следующим причинам:
Соответственно, PostgreSQL выбрали из этого перечня скорее интуитивно (ну не Oracle же выбирать, в самом деле ).
Чего не хватало:
При том, что сам Django может работать с несколькими БД параллельно и делить их по чтению и записи, записи в приложении было не так уж и много (более 90 % — чтение). И в общем, и в целом, если можно было сделать read-реплику основной базы в Европе и Азии, это было бы компромиссным вариантом решения. Ну а что тут такого сложного?
А сложность заключалась в том, что заказчик не хотел отказываться от использования managed services и Cloud SQL. А возможности Cloud SQL на данный момент времени ограничены. Cloud SQL поддерживает High availability (HA) и Read Replica (RR), но та же RR поддерживается лишь в одном регионе. Создав БД в американском регионе, сделать read-реплику в европейском регионе средствами Cloud SQL нельзя, хотя сам постгрес этого делать не мешает. Переписка с сотрудниками Google ни к чему не привела и закончилась обещаниями в стиле «мы знаем проблему и работаем над ней, когда-нибудь вопрос будет решён».
Если перечислить возможности Cloud SQL тезисно, то это будет выглядеть приблизительно так:
1. High availability (HA):
2. Read Replica (RR):
К тому же, как это принято, при выборе технологии всегда сталкиваешься с какими-нибудь ограничениями:
Учитывая ситуацию, от заказчика поступил вопрос на засыпку: «А можете что-нибудь похожее сделать, чтобы было, как Google Spanner, но работало ещё и с Django ORM?»
Первое, что пришло в голову:
Увы, оказалось, что так сделать нельзя, т. к. нет доступа к хосту (он вообще в другом проекте) — pg_hba и так далее, а ещё нет доступа под superuser.
После очередных размышлений и с учётом предыдущих обстоятельств ход мысли несколько изменился:
— является proxy для внешнего MySQL;
— выглядит как инстанс MySQL;
— придуман для миграции данных из других облаков или On-premises.
Так как настройка репликации MySQL не требует доступа к хосту, в принципе всё работало, но очень нестабильно и неудобно. А когда пошли дальше, стало и вовсе страшно, т. к. мы всю структуру разворачивали terraform’ом, а вдруг оказалось, что external master не поддерживается terraform’ом. Да, у Google есть CLI, но почему-то и тут всё работало через раз — то создаётся, то не создаётся. Возможно, потому, что CLI придумывали для миграции данных снаружи, а не для реплик.
Собственно, на этом стало понятно, что Cloud SQL не подходит от слова совсем. Как говорится, мы сделали всё, что смогли.
Так как остаться в рамках Cloud SQL не получилось, попытались сформулировать требования к компромиссному решению. Требования оказались следующие:
В результате этих требований на горизонте наконец-то появились подходящие варианты СУБД и обвязки:
— pgpool-II;
— Patroni.
Технология MySQL Galera разработана компанией Codership и представляет собой plugin for InnoDB. Особенности:
По описанию вещь совершенно бомбическая и представляет собой open source-проект, написанный на Go. Основной участник — Cockroach Labs (основана выходцами из Google). Эта реляционная СУБД изначально создана быть распределённой (с горизонтальным масштабированием «из коробки») и отказоустойчивой. Её авторы из компании обозначили цель «совместить богатство функциональности SQL с горизонтальной доступностью, привычной для NoSQL-решений».
Из приятного бонуса — поддержка постгресного протокола подключения.
Это надстройка над PostgreSQL, на самом деле, новая сущность, принимающая на себя все соединения и обрабатывающая их. Имеет свой лоад балансер и парсер, лицензируется по лицензии BSD. Предоставляет широкие возможности, но выглядит несколько пугающе, т. к. наличие новой сущности могло стать источником неких дополнительных приключений.
Это последнее, на что упал взгляд, и, как оказалось, не зря. Patroni — опенсорсная утилита, которая, по сути, представляет собой демон на Python, позволяющий автоматически обслуживать кластеры PostgreSQL с различными типами репликации и автоматическим переключением ролей. Штука оказалась очень интересной, так как она хорошо интегрируется с кубером и не несёт никаких новых сущностей.
Выбор давался непросто:
Таким образом, выбор пал на Patroni.
Пришла пора подвести краткие итоги. Да, мир ИТ-инфраструктуры существенно поменялся, и это только начало. И если раньше облака были лишь другим типом инфраструктуры, то теперь всё иначе. Мало того, инновации в облаках появляются постоянно, появляться будут и, возможно, они будут появляться только в облаках и лишь потом, силами стартапов, будут переноситься в On-premises.
Что касается SQL, то SQL будет жить. Это значит, что PostgreSQL и MySQL надо знать и работать с ними надо уметь, но еще важнее уметь их правильно применять.

В очередном открытом уроке поговорили о том, с какими вызовами столкнулись SQL-базы в эру облаков и Kubernetes. А заодно рассмотрели, как базы данных SQL приспосабливаются и мутируют под воздействием этих вызовов.
Вебинар провёл Валерий Безруков, Google Cloud Practice Delivery Manager в EPAM Systems.
Когда деревья были маленькими…
Для начала давайте вспомним, как начинался выбор СУБД в конце прошлого века. Впрочем, это не составит труда, ведь выбор СУБД в те времена начинался и заканчивался Oracle.

В конце 90-х — начале нулевых, особого выбора, по сути, не было, если говорить про промышленные масштабируемые БД. Да, существовали IBM DB2, Sybase и ещё какие-то базы данных, которые появлялись и исчезали, но в общем и целом они были не так заметны на фоне Oracle. Соответственно, навыки инженеров тех времён были так или иначе завязаны на то единственный выбор, который существовал.
Oracle DBA должен был уметь:
- устанавливать Oracle Server из дистрибутива;
- настраивать Oracle Server:
- init.ora;
- listener.ora;
— создавать:
- табличные пространства;
- схемы;
- пользователей;
— выполнять резервное копирование и восстановление;
— осуществлять мониторинг;
— бороться с неоптимальными запросами.
При этом от Oracle DBA особо не требовалось:
- уметь выбирать оптимальную СУБД или другую технологию хранения и обработки данных;
- обеспечивать высокую доступность и горизонтальную масштабируемость (это не всегда был вопрос DBA);
- хорошо знать предметную область, инфраструктуру, прикладную архитектуру, ОС;
- выполнять загрузку и выгрузку данных, миграцию данных между разными СУБД.
В общем, если говорить о выборе в те времена, то он напоминает выбор в советском магазине в конце 80-х:

Наше время
С тех пор, разумеется, деревья подросли, мир изменился, и стало как-то так:

Изменился и рынок СУБД, что хорошо видно по свежему докладу компании Gartner:

И здесь нельзя не отметить, что свою нишу заняли облака, популярность которых растёт. Если почитать тот же отчёт компании Gartner, мы увидим следующие выводы:
- Многие заказчики находятся на пути перевода приложений в облако.
- Новые технологии сначала появляются в облаке и не факт, что они вообще когда-нибудь переедут в необлачную инфраструктуру.
- Стала привычной модель ценообразования по принципу pay-as-you-go. Все желают платить только за то, чем пользуются, и это даже уже не тренд, а просто констатация факта.
Что сейчас?
Сегодня все мы в облаке. А те вопросы, которые у нас появляются, — это вопросы выбора. А он огромный, даже если говорить только про выбор технологий СУБД в формате On-premises. А ещё у нас есть managed services и SaaS. Таким образом, выбор с каждым годом только усложняется.
Наряду с вопросами выбора, действуют и ограничительные факторы:
- цена. Многие технологии по-прежнему стоят денег;
- навыки. Если мы говорим о свободном ПО, то возникает вопрос навыков, т. к. бесплатный софт требует от людей, его разворачивающих и эксплуатирующих, достаточной компетентности;
- функционал. Не все сервисы, которые доступны в облаке и построены, скажем, даже на базе того же Postgres, обладают теми же фичами, что и Postgres On-premises. Это существенный фактор, который нужно знать и понимать. Мало того, этот фактор приобретает более важное значение, чем знание каких-то скрытых возможностей отдельно взятой СУБД.
Что ждут сейчас от DA/DE:
- хорошего понимания предметной области и прикладной архитектуры;
- умения правильно выбирать подходящую технологию СУБД с учётом поставленной задачи;
- умения подбирать оптимальный метод реализации выбранной технологии в контексте имеющихся ограничений;
- умения выполнять перенос и миграцию данных;
- умения реализовывать и эксплуатировать выбранные решения.
Нижеследующий пример на базе GCP демонстрирует, как устроен выбор той или иной технологии работы с данными в зависимости от их структуры:

Обратите внимание, что в схеме отсутствует PostgreSQL, а всё потому, что он прячется под терминологией Cloud SQL. И когда мы попадаем в Cloud SQL, нам нужно опять сделать выбор:

Следует заметить, что этот выбор не всегда понятен, поэтому разработчики приложения зачастую руководствуются интуицией.
Итого:
- Чем дальше, тем актуальнее становится вопрос выбора. И даже если смотреть только на GCP, managed services и SaaS, то какое-то упоминание РСУБД появляется лишь на 4-м шаге (а там Spanner рядом). Плюс, выбор PostgreSQL появляется вообще на 5-м шаге, а рядом ещё MySQL и SQL Server, то есть всего много, а выбирать надо.
- Нельзя забывать и про ограничения на фоне соблазнов. В основном, все хотят Spanner, но он дорогой. В итоге типовой запрос выглядит примерно так: «Сделайте нам, пожалуйста, Spanner но за цену Cloud SQL, ну вы же профессионалы!»

А что делать-то?
Не претендуя на истину в последней инстанции, скажем следующее:
Нужно менять подход к обучению:
- учить, как учили раньше DBA, нет смысла;
- знания одного продукта сейчас уже недостаточно;
- а знать десятки на уровне одного — невозможно.
Нужно знать не только и не сколько продукт, а:
- use case его применения;
- разные методы развёртывания;
- преимущества и недостатки каждого из методов;
- аналогичные и альтернативные продукты, чтобы делать осознанный и оптимальный выбор и не всегда в пользу знакомого продукта.
А ещё нужно уметь мигрировать данные и понимать базовые принципы интеграции с ETL.
Реальный случай
В недавнем прошлом приходилось делать бэкенд для мобильного приложения. К моменту начала работы над ним бэкенд уже был разработан и готов к внедрению, а команда разработчиков потратила на этот проект около двух лет. При этом были поставлены следующие задачи:
- построить CI/CD;
- сделать review архитектуры;
- запустить всё это в эксплуатацию.
Само приложение было микросервисным, а код на Python/Django был разработан с нуля и сразу в GCP. Что касается целевой аудитории, то предполагалось, что будет два региона — US и EU, а трафик распределялся через Global Load balancer. Все Workloads и вычислительная нагрузка работали в Google Kubernetes Engine.
Что касается данных, то были 3 структуры:
- Cloud Storage;
- Datastore;
- Cloud SQL (PostgreSQL).
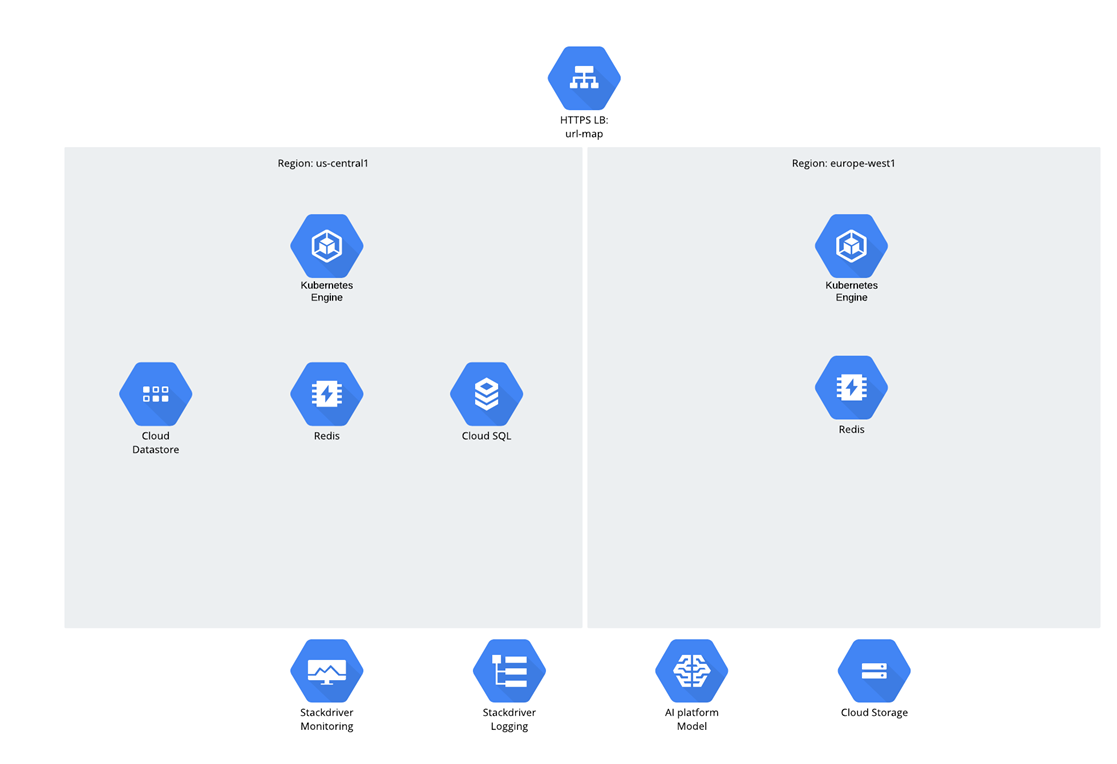
Может возникнуть вопрос, почему был выбран Cloud SQL? Говоря по правде, такой вопрос в последние годы вызывает какую-то неловкую паузу — возникает ощущение, что люди стали стесняться реляционных баз, но тем не менее они продолжают их активно использовать ;-).
Что касается нашего случая, то Cloud SQL был выбран по следующим причинам:
- Как было упомянуто, приложение разрабатывалось с помощью Django, а в нём есть модель отображения постоянных данных из SQL-базы в объекты Python (Django ORM).
- Сам фреймворк поддерживал достаточно конечный список СУБД:
- PostgreSQL;
- MariaDB;
- MySQL;
- Oracle;
- SQLite.
Соответственно, PostgreSQL выбрали из этого перечня скорее интуитивно (ну не Oracle же выбирать, в самом деле ).
Чего не хватало:
- приложение было развернуто только в 2-х регионах, а в планах появился 3-й (Азия);
- БД находилась в североамериканском регионе (Iowa);
- со стороны заказчика присутствовали опасения насчёт возможных задержек с доступом из Европы и Азии и перебоев в обслуживании в случае простоя СУБД.
При том, что сам Django может работать с несколькими БД параллельно и делить их по чтению и записи, записи в приложении было не так уж и много (более 90 % — чтение). И в общем, и в целом, если можно было сделать read-реплику основной базы в Европе и Азии, это было бы компромиссным вариантом решения. Ну а что тут такого сложного?
А сложность заключалась в том, что заказчик не хотел отказываться от использования managed services и Cloud SQL. А возможности Cloud SQL на данный момент времени ограничены. Cloud SQL поддерживает High availability (HA) и Read Replica (RR), но та же RR поддерживается лишь в одном регионе. Создав БД в американском регионе, сделать read-реплику в европейском регионе средствами Cloud SQL нельзя, хотя сам постгрес этого делать не мешает. Переписка с сотрудниками Google ни к чему не привела и закончилась обещаниями в стиле «мы знаем проблему и работаем над ней, когда-нибудь вопрос будет решён».
Если перечислить возможности Cloud SQL тезисно, то это будет выглядеть приблизительно так:
1. High availability (HA):
- в рамках одного региона;
- посредством дисковой репликации;
- не используются механизмы PostgreSQL;
- возможно автоматическое и ручное управление — failover/failback;
- при переключении СУБД недоступна в течение нескольких минут.
2. Read Replica (RR):
- в рамках одного региона;
- hot standby;
- PostgreSQL streaming replication.
К тому же, как это принято, при выборе технологии всегда сталкиваешься с какими-нибудь ограничениями:
- заказчик не хотел плодить сущности и использовать IaaS, кроме как через GKE;
- заказчик не хотел бы разворачивать self service PostgreSQL/MySQL;
- ну и вообще, Google Spanner вполне бы подошел, если бы не его цена, правда, с ним Django ORM работать не может, а так штука-то хорошая.
Учитывая ситуацию, от заказчика поступил вопрос на засыпку: «А можете что-нибудь похожее сделать, чтобы было, как Google Spanner, но работало ещё и с Django ORM?»
Вариант решения № 0
Первое, что пришло в голову:
- остаться в рамках CloudSQL;
- встроенной репликации между регионами не будет ни в каком виде;
- попытаться прикрутить реплику к существующему Cloud SQL by PostgreSQL;
- где-то и как-то запустить инстанс PostgreSQL, но хотя бы master не трогать.
Увы, оказалось, что так сделать нельзя, т. к. нет доступа к хосту (он вообще в другом проекте) — pg_hba и так далее, а ещё нет доступа под superuser.
Вариант решения № 1
После очередных размышлений и с учётом предыдущих обстоятельств ход мысли несколько изменился:
- всё также пытаемся остаться в рамках CloudSQL, но переходим на MySQL, т. к. у Cloud SQL by MySQL есть external master, который:
— является proxy для внешнего MySQL;
— выглядит как инстанс MySQL;
— придуман для миграции данных из других облаков или On-premises.
Так как настройка репликации MySQL не требует доступа к хосту, в принципе всё работало, но очень нестабильно и неудобно. А когда пошли дальше, стало и вовсе страшно, т. к. мы всю структуру разворачивали terraform’ом, а вдруг оказалось, что external master не поддерживается terraform’ом. Да, у Google есть CLI, но почему-то и тут всё работало через раз — то создаётся, то не создаётся. Возможно, потому, что CLI придумывали для миграции данных снаружи, а не для реплик.
Собственно, на этом стало понятно, что Cloud SQL не подходит от слова совсем. Как говорится, мы сделали всё, что смогли.
Вариант решения № 2
Так как остаться в рамках Cloud SQL не получилось, попытались сформулировать требования к компромиссному решению. Требования оказались следующие:
- работа в Kubernetes, максимальное использование ресурсов и возможностей Kubernetes (DCS, ...) и GCP (LB, ...);
- отсутствие балласта из кучи ненужных в облаке вещей типа HA proxy;
- возможность запускать в основном регионе HA PostgreSQL или MySQL; в остальных регионах — HA из RR основного региона плюс её копию (для надёжности);
- multi master (связываться с ним не хотелось, но это было не очень принципиально)
В результате этих требований на горизонте наконец-то появились подходящие варианты СУБД и обвязки:
- MySQL Galera;
- CockroachDB;
- PostgreSQL tools
— pgpool-II;
— Patroni.
MySQL Galera
Технология MySQL Galera разработана компанией Codership и представляет собой plugin for InnoDB. Особенности:
- multi master;
- синхронная репликация;
- чтение с любого узла;
- запись на любой узел;
- встроенный механизм HA;
- есть Helm chart от Bitnami.
CockroachDB
По описанию вещь совершенно бомбическая и представляет собой open source-проект, написанный на Go. Основной участник — Cockroach Labs (основана выходцами из Google). Эта реляционная СУБД изначально создана быть распределённой (с горизонтальным масштабированием «из коробки») и отказоустойчивой. Её авторы из компании обозначили цель «совместить богатство функциональности SQL с горизонтальной доступностью, привычной для NoSQL-решений».
Из приятного бонуса — поддержка постгресного протокола подключения.
Pgpool
Это надстройка над PostgreSQL, на самом деле, новая сущность, принимающая на себя все соединения и обрабатывающая их. Имеет свой лоад балансер и парсер, лицензируется по лицензии BSD. Предоставляет широкие возможности, но выглядит несколько пугающе, т. к. наличие новой сущности могло стать источником неких дополнительных приключений.
Patroni
Это последнее, на что упал взгляд, и, как оказалось, не зря. Patroni — опенсорсная утилита, которая, по сути, представляет собой демон на Python, позволяющий автоматически обслуживать кластеры PostgreSQL с различными типами репликации и автоматическим переключением ролей. Штука оказалась очень интересной, так как она хорошо интегрируется с кубером и не несёт никаких новых сущностей.
Что в итоге выбрали
Выбор давался непросто:
- CockroachDB — огонь, но стрёмно;
- MySQL Galera — тоже неплохо, много где используется, но MySQL;
- Pgpool — много лишних сущностей, так себе интеграция с облаком и K8s;
- Patroni — прекрасная интеграция с K8s, нет лишних сущностей, хорошо интегрируется с GCP LB.
Таким образом, выбор пал на Patroni.
Выводы
Пришла пора подвести краткие итоги. Да, мир ИТ-инфраструктуры существенно поменялся, и это только начало. И если раньше облака были лишь другим типом инфраструктуры, то теперь всё иначе. Мало того, инновации в облаках появляются постоянно, появляться будут и, возможно, они будут появляться только в облаках и лишь потом, силами стартапов, будут переноситься в On-premises.
Что касается SQL, то SQL будет жить. Это значит, что PostgreSQL и MySQL надо знать и работать с ними надо уметь, но еще важнее уметь их правильно применять.
