Перевод статьи подготовлен специально для студентов курса «Архитектор высоких нагрузок».

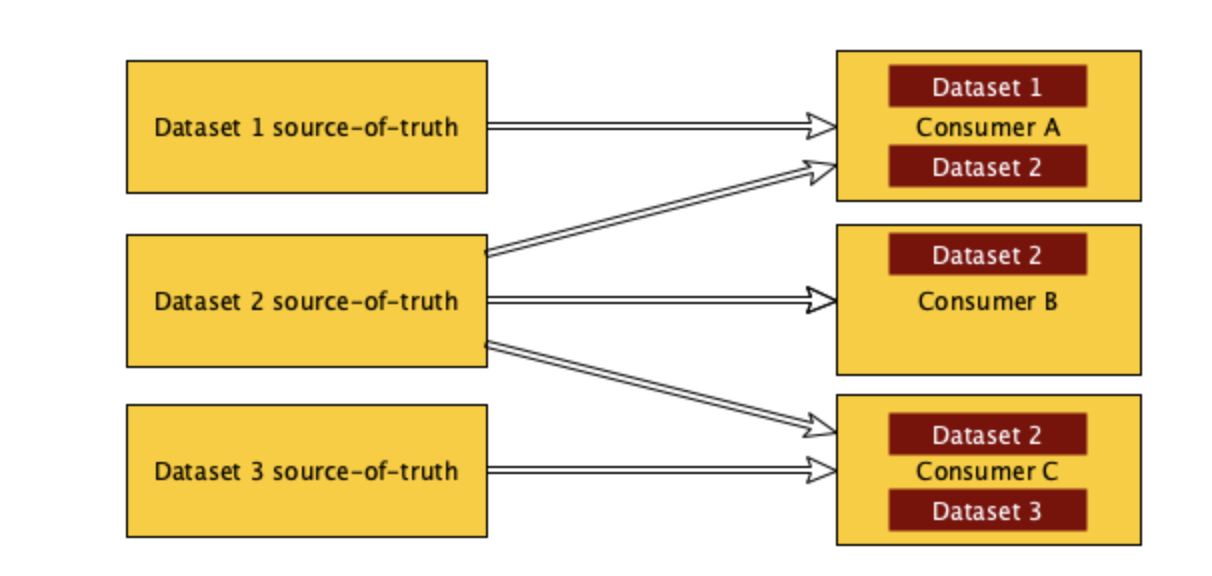
В микросервисной архитектуре Netflix передача наборов данных от одного к нескольким конечным точкам может быть крайне сложной. Эти наборы данных могут содержать все, что угодно, начиная от конфигурации сервиса до результатов пакетной обработки. Для оптимизации доступа часто необходимой оказывается резидентная база данных, а изменения должны отправляться сразу же после обновления данных.
Один из примеров, отражающий необходимость распределенной рассылки набора данных выглядит так: в любой момент времени Netflix выполняет огромное количество A/B тестов. Эти тесты охватывают несколько сервисов и команд, а операторы тестов должны иметь возможность изменять конфигурацию на лету. Также необходима возможность обнаружения узлов, которые не смогли получить последнюю тестовую конфигурацию, и возможность отката к старым версиям в случае, если что-то пойдет не так.
Другим примером набора данных, который необходимо распространить, является выходная последовательность модели машинного обучения: результаты ее работы могут использоваться несколькими командами, однако ML — команды не обязательно заинтересованы в поддержке сервисов бесперебойного доступа в критической ситуации. Вместо той ситуации, когда каждой команде требуется создавать резервные копии, чтобы иметь возможность лаконично сделать откат, особое внимание уделяется тому, чтобы несколько команд могли пользоваться результатами работы какой-либо одной команды.
Без поддержки на уровне инфраструктуры каждая команда в конечном итоге пытается реализовать свое собственное решение, но получается это у разных команд с переменным успехом. Сами по себе наборы данных имеют разный размер, от нескольких байт до нескольких гигабайт. Важно создать возможность наблюдать за выполнением процессов и обнаруживать неисправности с помощью специальных инструментов, чтобы операторы могли быстро производить изменения без необходимости создавать собственное решение.
Распространение данных
В Netflix мы используем внутреннюю систему pub/sub-данных, которая называется Gutenberg. Gutenberg позволяет распространять наборы данных с версионированием — получатели подписываются на данные и получают их последние версии при публикации. Каждая версия набора данных остается неизменяемой и содержит полное представление данных, то есть зависимость от предыдущих версий отсутствует. Gutenberg позволяет просматривать старые версии данных в случае, если нужно, например, сделать отладку, быстро решить проблему, связанную с данными, или переобучить модель машинного обучения. В этой статье мы расскажем про высокоуровневую архитектуру Gutenberg.

1 тема -> много версий
Конструкция верхнего уровня Gutenberg – это «тема». Издатель публикует данные внутри темы, а получатели извлекают их из нее. Публикация в теме добавляется как отдельная версия. Для тем характерна определенная политика хранения, которая определяет количество версий, в зависимости от варианта использования. Например, можно настроить тему так, чтобы он хранила 10 версий или версии за последние 10 дней.
Каждая версия содержит метаданные (ключи и значения) и указатель данных. Указатель данных можно рассматривать в качестве специальных метаданных, указывающих на то, где на самом деле хранятся опубликованные данные. На сегодняшний день Gutenberg поддерживает прямые указатели данных (если полезная нагрузка записывается в самом значении указателя данных) и указатели данных S3 (если полезная нагрузка хранится в S3). Прямые указатели данных обычно используются, когда данные маленького объема (менее 1 Мб), а S3 используется в качестве резервного хранилища в случае, если объем данных большой.

1 тема -> много публикуемых наборов
Gutenberg предоставляет возможность отправить публикацию определенному набору пользователей-получателей – например, набор может быть сгруппирован по определенному региону, приложению или кластеру. Это можно использовать для контроля качества изменений данных или ограничения набора данных таким образом, чтобы на него могло подписаться подмножество приложений. Издатели определяют область публикации конкретной версии данных и могут добавить области к ранее опубликованным данным. Обратите внимание, что это значит, что понятие последней версии данных зависит от конкретной области – два приложения могут получить последними разные версии данных в зависимости от области публикации, определенной издателем. Сервис Gutenberg сопоставляет приложения-получатели с областями публикации прежде, чем решает, что отправить в качестве последней версии.
Наиболее распространенным вариантом использования Gutenberg является распространение данных разного размера от одного издателя нескольким получателям. Часто данные хранятся в памяти получателей и используются в качестве «общего кэша», где они всегда остаются доступными во время выполнения кода получателя и под капотом атомарно заменяются при надобности. Многие из этих вариантов использования могут быть сгруппированы в «конфигурации», например конфигурация кэша Open Connect Appliance, поддерживаемые ID типов устройств, поддерживаемые метаданные способов оплаты и конфигурации А/В тестирования. Gutenberg обеспечивает абстракцию между публикацией и получением этих данных, что позволяет издателям свободно итерироваться по своему приложению не затрагивая данные нижестоящих получателей. В некоторых случаях публикация выполняется с помощью пользовательского интерфейса, управляемого Gutenberg, а командам вообще не нужно трогать собственное приложение для публикации.
Другой вариант использования системы Gutenberg – это хранилище версионированных данных. Это полезно для приложений с машинным обучением, где команды строят и обучают модели на основе исторических данных, видят, как они меняются с течением времени, затем меняют определенные параметры и снова запускают приложение. Чаще всего в batch-вычислениях Gutenberg используется для хранения и распространения результатов этих вычислений в качестве различных версий наборов данных. Online варианты использования подписываются на темы, чтобы выдавать на запросы в реальном времени данные из наборов последней версии, тогда как автономные системы могут использовать исторические данные из тех же тем, например, для обучения модели машинного обучения.
Важно отметить, что Gutenberg не спроектирован как система событий, он предназначен исключительно для управления версиями и рассылки данных. В частности, частые публикации не означают, что подписчик обязан получать каждую версию. Когда он запросит обновление, то получит последнюю версию, даже если в данный момент его текущая версия сильно отстает от актуальной. Традиционные pub-sub или системы событий больше подходят для сообщений маленького размера, которые отправляются последовательно. То есть получатели могут создать представление о всем наборе данных, потребляя весь (сжатый) поток событий. Однако Gutenberg предназначен для публикации и использования полного неизменяемого представления набора данных.
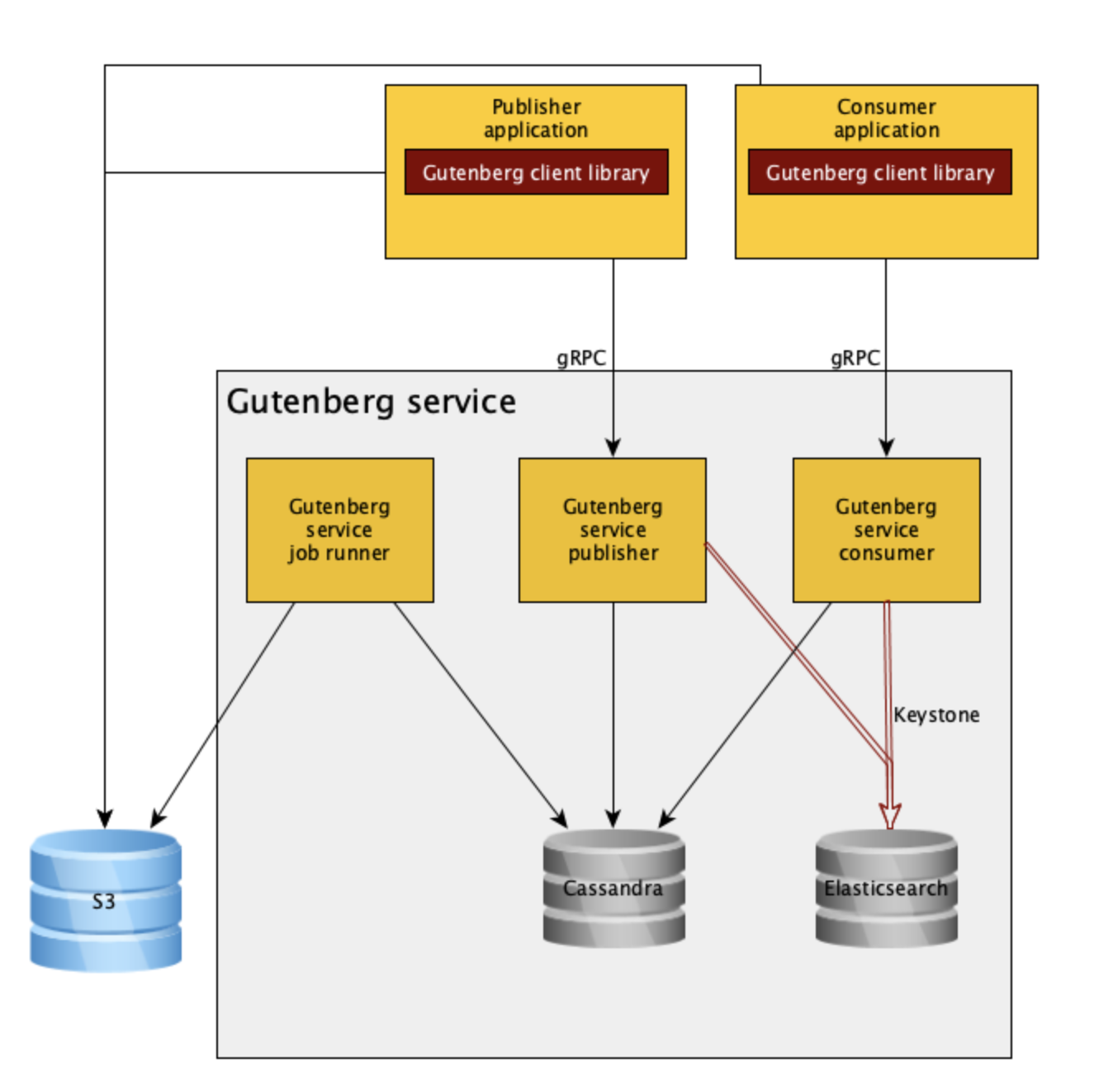
Gutenberg состоит из сервиса gRPC и REST API, а также из клиентской библиотеки Java, которая использует API gRPC.
Архитектура высокого уровня
Клиентская библиотека Gutenberg обрабатывает такие задачи, как управление подпиской, загрузка/выгрузка S3, метрики Atlas и параметры, которые можно настроить с помощью свойств Archaius. Она взаимодействует с сервисом Gutenberg через gRPC, используя Eureka для обнаружения служб.
Издатели обычно используют высокоуровневые API для публикации строк, файлов и массивов байт. В зависимости от размера данных, они могут быть опубликованы в качестве прямого указателя на данные или выгружены в S3, а затем опубликованы как указатель данных S3. Клиент может загрузить полезную нагрузку в S3 от имени издателя или опубликовать только метаданные полезной нагрузки, которая уже есть в S3.
Прямые указатели данных автоматически глобально реплицируются. Данные, опубликованные в S3, по умолчанию загружаются издателем в несколько областей, хотя это также может быть настроено.
Клиентская библиотека обеспечивает управление подпиской получателей. Это позволяет пользователям создавать подписки на определенные темы, из которых библиотека извлекает данные (например, из S3), чтобы передать их установленному пользователем получателю. Подписки работают по модели опроса – они запрашивают у службы новое обновление каждые 30 секунд, отправляя версию, которую они получили последней. Подписанные клиенты не будут использовать более старую версию данных, чем та, что у них имеется на настоящий момент, если она не закреплена (см. «отказоустойчивость» ниже). Логика повторных запросов вшита и конфигурируема. Например, пользователи могут настроить Gutenberg так, чтобы он использовал более старые версии данных, если процесс скачивания обрывается или чтобы он обрабатывал последнюю версию данных при запуске, чаще всего для того, чтобы работать с изменениями данным, несовместимыми с обратной связью. Gutenberg также предоставляет предварительно сконфигурированную подписку, которая хранит последние данные и под капотом атомарно обновляет их, когда приходят изменения. Это отвечает большинству вариантов использования подписки, когда абоненты заботятся только о текущем значении в любой момент времени, что позволяет пользователям указывать значение по умолчанию, например, для темы, в которой никогда раньше не было публикаций (например, если тема используется для конфигурации), или же если существует ошибка, зависящая от темы (чтобы избежать блокировки запуска сервиса, когда есть валидное значение по умолчанию).
Gutenberg также предоставляет высокоуровневые клиентские API, которые под капотом имеют низкоуровневые API gRPC и обеспечивают дополнительный функционал и прозрачность выполнения запросов. Одним из примеров может являться загрузка данных для конкретной темы и версии, что широко используется компонентами, подключенными к Netflix Hollow. Другим примером может послужить получение последней версии темы в определенный момент времени – распространенный вариант использования при дебаге или обучении моделей машинного обучения.
Gutenberg был спроектирован с уклоном на то, чтобы позволить сервисам-получателям успешно запускаться, а не гарантировать, что они запускаются с самыми актуальными данными. По этой причине клиентская библиотека была построена с резервной логикой для обработки состояний, когда она не может взаимодействовать с сервисом Gutenberg. Если HTTP-запросы не дают результатов, клиент загружает резервный кэш метаданных опубликованной темы из S3 и работает с ним. Этот кэш содержит всю информацию для принятия решения о необходимости применения обновления и о том, откуда следует извлекать данные (либо из самих метаданных публикации, либо из S3). Это позволяет клиентам извлекать данные (которые потенциально устарели, в зависимости от текущего состояния резервного кэша) без использования сервиса.
Одним из преимуществ предоставления клиентской библиотеки является возможность получения метрик, которые можно использовать для оповещения о проблемах инфраструктуры в целом и ошибках в конкретных приложениях. Сегодня эти метрики используются командой Gutenberg для мониторинга нашего SLI распространения публикации и оповещения в случае возникновения типичных проблем. Некоторые клиенты также используют эти метрики для оповещения об ошибках, характерных для конкретного приложения, например об отдельных сбоях публикации или отказе получения определенной темы.
Сервис Gutenberg – это приложение Governator/Tomcat, которое предоставляет конечные точки gRPC и REST. Оно использует глобально реплицированный кластер Cassandra для хранения и распространения метаданных публикации в каждом регионе. Инстансы, обрабатывающие запросы получателей, масштабируются отдельно от инстансов, обрабатывающих запросы на публикацию. Запросов на получение примерно в 1000 раз больше, чем запросов на публикацию. Кроме того, это позволяет убрать зависимость факта публикации от получения, поэтому внезапный всплеск публикаций не повлияет на получение, и наоборот.
Каждый инстанс в кластере запросов получателей обрабатывает свой собственный in-memory кэш последних публикаций, подтягивая его из Cassandra каждые несколько секунд. Это необходимо для обработки большого количества запросов на получение, поступающих от подписанных клиентов без передачи трафика в кластер Cassandra. Помимо этого, кэши с малым ttl-пулом запросов защищают от всплесков запросов, которые потенциально могут настолько замедлить Cassandra, что это повлияет на весь регион. У нас случались ситуации, когда внезапные ошибки, совпадающие с перераспределением больших кластеров, вызывали перебои в работе сервиса Gutenberg. Кроме того, мы используем адаптивный ограничитель параллелизма, находящийся в исходном приложении, чтобы подавлять работу приложений с некорректным поведением, не затрагивая другие.
В случаях, когда данные опубликованы в S3 в нескольких регионах, сервер принимает решение о том, какой сегмент отправить для загрузки клиенту обратно, в зависимости от того, где находится этот клиент. Это также позволяет сервису предоставлять клиенту сегмент в «ближайшем» регионе или заставить клиент перейти в другой регион, если текущий регион по тем или иным причинам отключен.
Перед возвратом данных подписки получателям сервис Gutenberg сначала проверяет данные на согласованность. Если проверка завершается неудачно, а подписчик уже получил какие-то данные, сервис ничего не возвращает, что фактически означает недоступность обновления. Если клиент-подписчик еще не получил какие-либо данные (обычно это значит, что он только что запустился), сервис запрашивает историю темы и возвращает последнее значение, которое проходит проверку согласованности. Это связано с тем, что мы наблюдаем эпизодические задержки репликации на уровне Cassandra, где к моменту запроса подписчиками новых данных, метаданные, связанные с последней опубликованной версией, были реплицированы только частично. Это может привести к тому, что клиент получит неполные данные, которые затем приведут к ошибкам запроса данных или ошибках в бизнес-логике. Выполнение таких проверок на согласованность на сервере ограждает получателей от оповещений о возможной согласованности, которые приходят с выбором сервиса хранилища данных.
Возможность вести мониторинг публикаций тем и узлов, которые используют данные темы, важная функция для аудита и сбора информации об использовании. Для сбора этих данных служба перехватывает запросы от издателей и получателей (как запросы на обновление данных от подписчиков, так и другие) и индексирует их в Elasticsearch с помощью пайплайна данных Keystone. Так у нас появляется возможность получить данные для мониторинга тем, которые используются и уже нет. Мы публикуем глубинные ссылки на дашборд Kibana из внутреннего UI, чтобы владельцы тем могли самостоятельно управлять своими подписчиками.
В дополнение к кластерам, обрабатывающим запросы издателя и получателя, сервис Gutenberg запускает еще один кластер, который обрабатывает периодические запросы. В частности, он решает две задачи:
В мире разработки приложений случаются неудачные развертывания, и распространенной стратегией исправления таких проблем являются откаты до ранних версий. Data-driven архитектура усложняет ситуацию, поскольку поведение определяется данными, которые меняются с течением времени.
Данные, распространяемые Gutenberg влияют и во многих случаях управляют поведением системы. Это значит, что если что-то идет не так, то нужен способ отката к проверенной хорошей версии данных. Чтобы облегчить ситуацию, Gutenberg дает возможность «привязать» тему к определенной версии. Пины переопределяют последнюю версию данных и заставляют клиент обновиться до этой версии, что позволяет быстро исправить критическую ситуацию, а не пытаться понять, как опубликовать последнюю рабочую версию. Вы можете даже применить привязку к области публикации, чтобы только получатели из этой области могли пользоваться данными. Пины также переопределяют данные, опубликованные при активной привязке, но при удалении пина клиенты получат последнюю версию, которая может быть последней закрепленной версией или же новой версией, которая была опубликована в то время, пока была закреплена старая.
При развертывании нового кода часто рекомендуют создавать новые сборки с подмножеством трафика, развертывать их постепенно или каким-либо другим образом снижать риски при развертывании, замедляя его. Для случаев, когда данные управляют поведением, следует применять аналогичный принцип.
Одна из функций, которую предоставляет Gutenberg, — это возможность постепенного развертывания данных с помощью пайплайнов Spinnaker. В конкретной теме пользователи настраивают область публикации, к которой они хотят перейти и время задержки перехода. Публикация в этой теме запускает пайплайн, который последовательно публикует одну и ту же версию данных в каждой области. Пользователи могут взаимодействовать с пайплайном, например, они могут приостановить или отменить выполнение пайплайна, если их приложение начинает работать некорректно, или же они могут ускорить публикацию, чтобы получить ее раньше. Например, для некоторых тем мы разворачиваем новую версию данных по одному AWS-региону за раз.
Gutenberg используется в Netflix в течение последних трех лет. На настоящий момент Gutenberg хранит минимум десятки тысяч тем на продакшене, из которых около четверти были опубликованы по крайней мере один раз за последние 6 месяцев. Темы публикуются с разной частотой – от десятков раз в минуту до одного раза в несколько месяцев, то есть в среднем мы видим около 1-2 публикаций в секунду, с пиками и провалами с разницей в 12 часов.
В течение заданного 24-х часового периода число узлов, подписанных хотя бы на одну тему, колеблется в пределах шестизначных чисел. Наибольшее количество тем, на которое подписан один из узлов доходит до 200, когда в среднем количество подписок для среднестатистического узла равняется 7. В дополнение к приложениям-подписчикам существует большое количество приложений, которые запрашивают определенные версии определенных тем, например для машинного обучения и Hollow. В настоящее время количество узлов, которые делают запрос без подписки на тему, находятся в диапазоне нескольких сотен тысяч, наибольшее количество запрашиваемых тем – 60, тогда как среднее значение – 4.
Вот план работ, который мы набросали для усовершенствования Gutenberg:
На этом все. Ждем всех желающих на курсе.

Введение
В микросервисной архитектуре Netflix передача наборов данных от одного к нескольким конечным точкам может быть крайне сложной. Эти наборы данных могут содержать все, что угодно, начиная от конфигурации сервиса до результатов пакетной обработки. Для оптимизации доступа часто необходимой оказывается резидентная база данных, а изменения должны отправляться сразу же после обновления данных.
Один из примеров, отражающий необходимость распределенной рассылки набора данных выглядит так: в любой момент времени Netflix выполняет огромное количество A/B тестов. Эти тесты охватывают несколько сервисов и команд, а операторы тестов должны иметь возможность изменять конфигурацию на лету. Также необходима возможность обнаружения узлов, которые не смогли получить последнюю тестовую конфигурацию, и возможность отката к старым версиям в случае, если что-то пойдет не так.
Другим примером набора данных, который необходимо распространить, является выходная последовательность модели машинного обучения: результаты ее работы могут использоваться несколькими командами, однако ML — команды не обязательно заинтересованы в поддержке сервисов бесперебойного доступа в критической ситуации. Вместо той ситуации, когда каждой команде требуется создавать резервные копии, чтобы иметь возможность лаконично сделать откат, особое внимание уделяется тому, чтобы несколько команд могли пользоваться результатами работы какой-либо одной команды.
Без поддержки на уровне инфраструктуры каждая команда в конечном итоге пытается реализовать свое собственное решение, но получается это у разных команд с переменным успехом. Сами по себе наборы данных имеют разный размер, от нескольких байт до нескольких гигабайт. Важно создать возможность наблюдать за выполнением процессов и обнаруживать неисправности с помощью специальных инструментов, чтобы операторы могли быстро производить изменения без необходимости создавать собственное решение.

Распространение данных
В Netflix мы используем внутреннюю систему pub/sub-данных, которая называется Gutenberg. Gutenberg позволяет распространять наборы данных с версионированием — получатели подписываются на данные и получают их последние версии при публикации. Каждая версия набора данных остается неизменяемой и содержит полное представление данных, то есть зависимость от предыдущих версий отсутствует. Gutenberg позволяет просматривать старые версии данных в случае, если нужно, например, сделать отладку, быстро решить проблему, связанную с данными, или переобучить модель машинного обучения. В этой статье мы расскажем про высокоуровневую архитектуру Gutenberg.
Модель данных

1 тема -> много версий
Конструкция верхнего уровня Gutenberg – это «тема». Издатель публикует данные внутри темы, а получатели извлекают их из нее. Публикация в теме добавляется как отдельная версия. Для тем характерна определенная политика хранения, которая определяет количество версий, в зависимости от варианта использования. Например, можно настроить тему так, чтобы он хранила 10 версий или версии за последние 10 дней.
Каждая версия содержит метаданные (ключи и значения) и указатель данных. Указатель данных можно рассматривать в качестве специальных метаданных, указывающих на то, где на самом деле хранятся опубликованные данные. На сегодняшний день Gutenberg поддерживает прямые указатели данных (если полезная нагрузка записывается в самом значении указателя данных) и указатели данных S3 (если полезная нагрузка хранится в S3). Прямые указатели данных обычно используются, когда данные маленького объема (менее 1 Мб), а S3 используется в качестве резервного хранилища в случае, если объем данных большой.

1 тема -> много публикуемых наборов
Gutenberg предоставляет возможность отправить публикацию определенному набору пользователей-получателей – например, набор может быть сгруппирован по определенному региону, приложению или кластеру. Это можно использовать для контроля качества изменений данных или ограничения набора данных таким образом, чтобы на него могло подписаться подмножество приложений. Издатели определяют область публикации конкретной версии данных и могут добавить области к ранее опубликованным данным. Обратите внимание, что это значит, что понятие последней версии данных зависит от конкретной области – два приложения могут получить последними разные версии данных в зависимости от области публикации, определенной издателем. Сервис Gutenberg сопоставляет приложения-получатели с областями публикации прежде, чем решает, что отправить в качестве последней версии.
Варианты использования
Наиболее распространенным вариантом использования Gutenberg является распространение данных разного размера от одного издателя нескольким получателям. Часто данные хранятся в памяти получателей и используются в качестве «общего кэша», где они всегда остаются доступными во время выполнения кода получателя и под капотом атомарно заменяются при надобности. Многие из этих вариантов использования могут быть сгруппированы в «конфигурации», например конфигурация кэша Open Connect Appliance, поддерживаемые ID типов устройств, поддерживаемые метаданные способов оплаты и конфигурации А/В тестирования. Gutenberg обеспечивает абстракцию между публикацией и получением этих данных, что позволяет издателям свободно итерироваться по своему приложению не затрагивая данные нижестоящих получателей. В некоторых случаях публикация выполняется с помощью пользовательского интерфейса, управляемого Gutenberg, а командам вообще не нужно трогать собственное приложение для публикации.
Другой вариант использования системы Gutenberg – это хранилище версионированных данных. Это полезно для приложений с машинным обучением, где команды строят и обучают модели на основе исторических данных, видят, как они меняются с течением времени, затем меняют определенные параметры и снова запускают приложение. Чаще всего в batch-вычислениях Gutenberg используется для хранения и распространения результатов этих вычислений в качестве различных версий наборов данных. Online варианты использования подписываются на темы, чтобы выдавать на запросы в реальном времени данные из наборов последней версии, тогда как автономные системы могут использовать исторические данные из тех же тем, например, для обучения модели машинного обучения.
Важно отметить, что Gutenberg не спроектирован как система событий, он предназначен исключительно для управления версиями и рассылки данных. В частности, частые публикации не означают, что подписчик обязан получать каждую версию. Когда он запросит обновление, то получит последнюю версию, даже если в данный момент его текущая версия сильно отстает от актуальной. Традиционные pub-sub или системы событий больше подходят для сообщений маленького размера, которые отправляются последовательно. То есть получатели могут создать представление о всем наборе данных, потребляя весь (сжатый) поток событий. Однако Gutenberg предназначен для публикации и использования полного неизменяемого представления набора данных.
Разработка и архитектура
Gutenberg состоит из сервиса gRPC и REST API, а также из клиентской библиотеки Java, которая использует API gRPC.

Архитектура высокого уровня
Клиент
Клиентская библиотека Gutenberg обрабатывает такие задачи, как управление подпиской, загрузка/выгрузка S3, метрики Atlas и параметры, которые можно настроить с помощью свойств Archaius. Она взаимодействует с сервисом Gutenberg через gRPC, используя Eureka для обнаружения служб.
Публикация
Издатели обычно используют высокоуровневые API для публикации строк, файлов и массивов байт. В зависимости от размера данных, они могут быть опубликованы в качестве прямого указателя на данные или выгружены в S3, а затем опубликованы как указатель данных S3. Клиент может загрузить полезную нагрузку в S3 от имени издателя или опубликовать только метаданные полезной нагрузки, которая уже есть в S3.
Прямые указатели данных автоматически глобально реплицируются. Данные, опубликованные в S3, по умолчанию загружаются издателем в несколько областей, хотя это также может быть настроено.
Управление подпиской
Клиентская библиотека обеспечивает управление подпиской получателей. Это позволяет пользователям создавать подписки на определенные темы, из которых библиотека извлекает данные (например, из S3), чтобы передать их установленному пользователем получателю. Подписки работают по модели опроса – они запрашивают у службы новое обновление каждые 30 секунд, отправляя версию, которую они получили последней. Подписанные клиенты не будут использовать более старую версию данных, чем та, что у них имеется на настоящий момент, если она не закреплена (см. «отказоустойчивость» ниже). Логика повторных запросов вшита и конфигурируема. Например, пользователи могут настроить Gutenberg так, чтобы он использовал более старые версии данных, если процесс скачивания обрывается или чтобы он обрабатывал последнюю версию данных при запуске, чаще всего для того, чтобы работать с изменениями данным, несовместимыми с обратной связью. Gutenberg также предоставляет предварительно сконфигурированную подписку, которая хранит последние данные и под капотом атомарно обновляет их, когда приходят изменения. Это отвечает большинству вариантов использования подписки, когда абоненты заботятся только о текущем значении в любой момент времени, что позволяет пользователям указывать значение по умолчанию, например, для темы, в которой никогда раньше не было публикаций (например, если тема используется для конфигурации), или же если существует ошибка, зависящая от темы (чтобы избежать блокировки запуска сервиса, когда есть валидное значение по умолчанию).
API получателя
Gutenberg также предоставляет высокоуровневые клиентские API, которые под капотом имеют низкоуровневые API gRPC и обеспечивают дополнительный функционал и прозрачность выполнения запросов. Одним из примеров может являться загрузка данных для конкретной темы и версии, что широко используется компонентами, подключенными к Netflix Hollow. Другим примером может послужить получение последней версии темы в определенный момент времени – распространенный вариант использования при дебаге или обучении моделей машинного обучения.
Устойчивость и «прозрачность» клиента
Gutenberg был спроектирован с уклоном на то, чтобы позволить сервисам-получателям успешно запускаться, а не гарантировать, что они запускаются с самыми актуальными данными. По этой причине клиентская библиотека была построена с резервной логикой для обработки состояний, когда она не может взаимодействовать с сервисом Gutenberg. Если HTTP-запросы не дают результатов, клиент загружает резервный кэш метаданных опубликованной темы из S3 и работает с ним. Этот кэш содержит всю информацию для принятия решения о необходимости применения обновления и о том, откуда следует извлекать данные (либо из самих метаданных публикации, либо из S3). Это позволяет клиентам извлекать данные (которые потенциально устарели, в зависимости от текущего состояния резервного кэша) без использования сервиса.
Одним из преимуществ предоставления клиентской библиотеки является возможность получения метрик, которые можно использовать для оповещения о проблемах инфраструктуры в целом и ошибках в конкретных приложениях. Сегодня эти метрики используются командой Gutenberg для мониторинга нашего SLI распространения публикации и оповещения в случае возникновения типичных проблем. Некоторые клиенты также используют эти метрики для оповещения об ошибках, характерных для конкретного приложения, например об отдельных сбоях публикации или отказе получения определенной темы.
Сервер
Сервис Gutenberg – это приложение Governator/Tomcat, которое предоставляет конечные точки gRPC и REST. Оно использует глобально реплицированный кластер Cassandra для хранения и распространения метаданных публикации в каждом регионе. Инстансы, обрабатывающие запросы получателей, масштабируются отдельно от инстансов, обрабатывающих запросы на публикацию. Запросов на получение примерно в 1000 раз больше, чем запросов на публикацию. Кроме того, это позволяет убрать зависимость факта публикации от получения, поэтому внезапный всплеск публикаций не повлияет на получение, и наоборот.
Каждый инстанс в кластере запросов получателей обрабатывает свой собственный in-memory кэш последних публикаций, подтягивая его из Cassandra каждые несколько секунд. Это необходимо для обработки большого количества запросов на получение, поступающих от подписанных клиентов без передачи трафика в кластер Cassandra. Помимо этого, кэши с малым ttl-пулом запросов защищают от всплесков запросов, которые потенциально могут настолько замедлить Cassandra, что это повлияет на весь регион. У нас случались ситуации, когда внезапные ошибки, совпадающие с перераспределением больших кластеров, вызывали перебои в работе сервиса Gutenberg. Кроме того, мы используем адаптивный ограничитель параллелизма, находящийся в исходном приложении, чтобы подавлять работу приложений с некорректным поведением, не затрагивая другие.
В случаях, когда данные опубликованы в S3 в нескольких регионах, сервер принимает решение о том, какой сегмент отправить для загрузки клиенту обратно, в зависимости от того, где находится этот клиент. Это также позволяет сервису предоставлять клиенту сегмент в «ближайшем» регионе или заставить клиент перейти в другой регион, если текущий регион по тем или иным причинам отключен.
Перед возвратом данных подписки получателям сервис Gutenberg сначала проверяет данные на согласованность. Если проверка завершается неудачно, а подписчик уже получил какие-то данные, сервис ничего не возвращает, что фактически означает недоступность обновления. Если клиент-подписчик еще не получил какие-либо данные (обычно это значит, что он только что запустился), сервис запрашивает историю темы и возвращает последнее значение, которое проходит проверку согласованности. Это связано с тем, что мы наблюдаем эпизодические задержки репликации на уровне Cassandra, где к моменту запроса подписчиками новых данных, метаданные, связанные с последней опубликованной версией, были реплицированы только частично. Это может привести к тому, что клиент получит неполные данные, которые затем приведут к ошибкам запроса данных или ошибках в бизнес-логике. Выполнение таких проверок на согласованность на сервере ограждает получателей от оповещений о возможной согласованности, которые приходят с выбором сервиса хранилища данных.
Возможность вести мониторинг публикаций тем и узлов, которые используют данные темы, важная функция для аудита и сбора информации об использовании. Для сбора этих данных служба перехватывает запросы от издателей и получателей (как запросы на обновление данных от подписчиков, так и другие) и индексирует их в Elasticsearch с помощью пайплайна данных Keystone. Так у нас появляется возможность получить данные для мониторинга тем, которые используются и уже нет. Мы публикуем глубинные ссылки на дашборд Kibana из внутреннего UI, чтобы владельцы тем могли самостоятельно управлять своими подписчиками.
В дополнение к кластерам, обрабатывающим запросы издателя и получателя, сервис Gutenberg запускает еще один кластер, который обрабатывает периодические запросы. В частности, он решает две задачи:
- Каждые несколько минут все последние публикации и метаданные собираются и отправляются в S3. Это инициирует начало работы резервного кэша, который используется клиентом, как было описано выше.
- Сборщик мусора удаляет версии тем, которые не отвечают политике их хранения. Он также удаляет связанные с ними данные (например, объекты S3) и помогает обеспечить четко определенный жизненный цикл данных.
Отказоустойчивость
Привязка
В мире разработки приложений случаются неудачные развертывания, и распространенной стратегией исправления таких проблем являются откаты до ранних версий. Data-driven архитектура усложняет ситуацию, поскольку поведение определяется данными, которые меняются с течением времени.
Данные, распространяемые Gutenberg влияют и во многих случаях управляют поведением системы. Это значит, что если что-то идет не так, то нужен способ отката к проверенной хорошей версии данных. Чтобы облегчить ситуацию, Gutenberg дает возможность «привязать» тему к определенной версии. Пины переопределяют последнюю версию данных и заставляют клиент обновиться до этой версии, что позволяет быстро исправить критическую ситуацию, а не пытаться понять, как опубликовать последнюю рабочую версию. Вы можете даже применить привязку к области публикации, чтобы только получатели из этой области могли пользоваться данными. Пины также переопределяют данные, опубликованные при активной привязке, но при удалении пина клиенты получат последнюю версию, которая может быть последней закрепленной версией или же новой версией, которая была опубликована в то время, пока была закреплена старая.
Последовательное развертывание
При развертывании нового кода часто рекомендуют создавать новые сборки с подмножеством трафика, развертывать их постепенно или каким-либо другим образом снижать риски при развертывании, замедляя его. Для случаев, когда данные управляют поведением, следует применять аналогичный принцип.
Одна из функций, которую предоставляет Gutenberg, — это возможность постепенного развертывания данных с помощью пайплайнов Spinnaker. В конкретной теме пользователи настраивают область публикации, к которой они хотят перейти и время задержки перехода. Публикация в этой теме запускает пайплайн, который последовательно публикует одну и ту же версию данных в каждой области. Пользователи могут взаимодействовать с пайплайном, например, они могут приостановить или отменить выполнение пайплайна, если их приложение начинает работать некорректно, или же они могут ускорить публикацию, чтобы получить ее раньше. Например, для некоторых тем мы разворачиваем новую версию данных по одному AWS-региону за раз.
Масштабирование
Gutenberg используется в Netflix в течение последних трех лет. На настоящий момент Gutenberg хранит минимум десятки тысяч тем на продакшене, из которых около четверти были опубликованы по крайней мере один раз за последние 6 месяцев. Темы публикуются с разной частотой – от десятков раз в минуту до одного раза в несколько месяцев, то есть в среднем мы видим около 1-2 публикаций в секунду, с пиками и провалами с разницей в 12 часов.
В течение заданного 24-х часового периода число узлов, подписанных хотя бы на одну тему, колеблется в пределах шестизначных чисел. Наибольшее количество тем, на которое подписан один из узлов доходит до 200, когда в среднем количество подписок для среднестатистического узла равняется 7. В дополнение к приложениям-подписчикам существует большое количество приложений, которые запрашивают определенные версии определенных тем, например для машинного обучения и Hollow. В настоящее время количество узлов, которые делают запрос без подписки на тему, находятся в диапазоне нескольких сотен тысяч, наибольшее количество запрашиваемых тем – 60, тогда как среднее значение – 4.
Дальнейшая работа
Вот план работ, который мы набросали для усовершенствования Gutenberg:
- Поддержка множества языков: на сегодняшний день Gutenberg поддерживает только Java-клиенты, но все больше запросов мы видим с Node.JS и Python-клиентов. Некоторые из наших команд создали собственные решения, построенные на REST API Gutenberg или других системах. Вместо изобретения колеса разными командами, мы планируем создать клиентские библиотеки для Node.JS и Python.
- Шифрование и контроль доступа: для конфиденциальных данных издатели Gutenberg должны иметь возможность шифровать данные и отправлять данные для расшифровки получателям вне общей шины данных. Добавление этой функции откроет новые варианты использования Gutenberg.
- Улучшение последовательного развертывания: текущая реализация еще крайне сырая и требует больше усилий для поддержки кастомизации, чтобы обеспечить различные варианты использования. Например, пользователи должны иметь возможность настроить пайплайн развертывания для автоматического принятия или отклонения версий данных на основе собственных тестов.
- Шаблоны предупреждений: метрики, предоставляемые клиентом Gutenberg, используются самой командой Gutenberg и еще несколькими группами пользователей. Вместо этого мы планируем предоставить пользователям инструменты управления путем создания шаблонов параметризации, которые они смогут использовать для настройки собственных оповещений.
- Очистка темы: в настоящее время темы живут вечно, если они не удаляются явно, даже если никто уже не публикует и не получает ничего из них. Мы планируем создать автоматизированную систему очистки тем на основе тенденций получения, индексируемых в Elasticsearch.
- Интеграция каталога данных: постоянная проблема Netflix – это каталогизация характеристик данных и их источника. Предпринимаются усилия по централизации метаданных в источниках данных и их приемниках, и как только Gutenberg будет интегрирован, мы сможем использовать каталоги для автоматизации работы инструментов оповещения владельцев данных.
На этом все. Ждем всех желающих на курсе.
