Комментарии 29
Правда мне всегда было интересно зачем все это извращение с бинарными деревьями(кроме фана для души), когда существует более эффективное семейство B-деревьев.
Каждой задаче свой инструмент: для структур в памяти подходят почти сбалансированные двоичные деревья, а B-деревьев для внешней памяти. Как часто используемый пример красно-черных деревьев в стандартной библиотеке Java -TreeMap
https://docs.oracle.com/javase/8/docs/api/java/util/TreeMap.html
Что внешняя память что оперативка имеет один и тот же параметр — размер блока и понятие локальности когда работать с размерами меньше этого блока не имеет смысла потому что любое обращение к памяти будет грузить или записывать весь этот блок. Соотвественно B-деревья походят не только для внешней памяти а и для структур в памяти поскольку нет смысла делать узел меньше чем размер блока (для оперативной памяти вместо блока используется название "кеш-линия") — то есть для современных процессоров нет смысла делать узел дерева размером меньше 64 байта (размер кеш-линии в x64 и arm). И узнать какой будет ранг у б-дерева можно просто поделив 64 байта на размер указателя на другие узлы (указатели тоже можно закодировать более компактно если ограничить их общее количество)
Красно-чёрное дерево — это как сортировка пузырьком в мире деревьев. Более расточительную по памяти структуру придумать сложно.
Какова альтернатива для std::map, например?
NIL вообще не хранится и является нулевым указателем, что даёт нам +8 байт на каждый узел в дереве, а число узлов равно числу ключей. Даже если мы введём 4 типа узлов разного размера (разветвление, левая полуветка, правая полуветка, лист), то это даст +2 бита на каждый узел (вместе с цветом =3). И при этом балансировка оставляет желать лучшего.
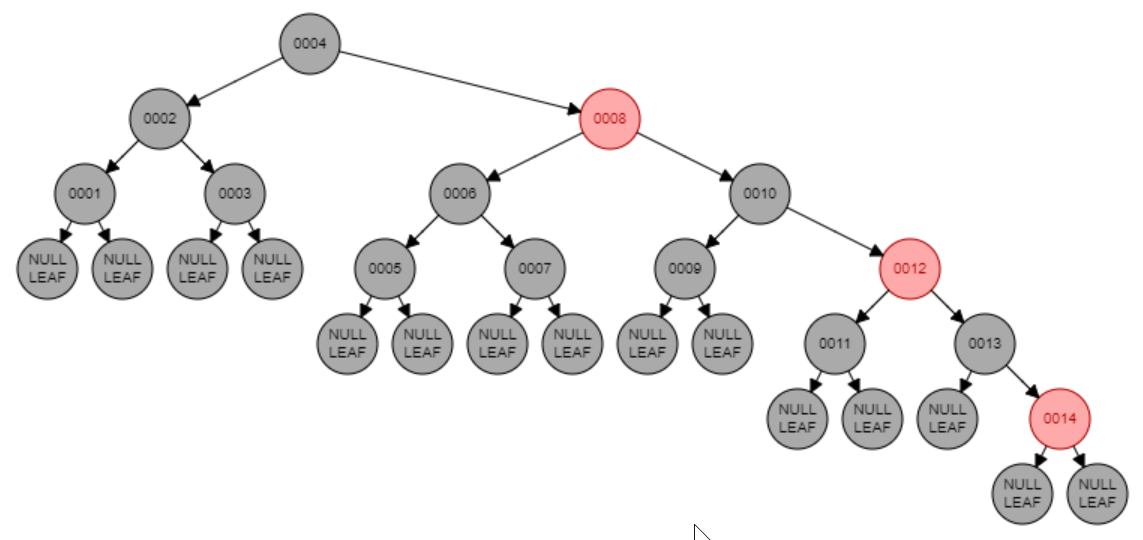
Для сравнения: 2-3 B-дерево потребует всего 1 бит на каждый узел для указания его размера, число узлов будет в среднем в полтора раза меньше числа ключей, а с балансировкой там всё в порядке.

Половина узлов — одинарные, имеют два указателя.
Половина узлов — листовые, не имеют указателей. Указатели имеют лишь ветви. Так как глубина листьев всегда одинаковая, достаточно отдельно хранить глубину дерева, чтобы понимать какие ссылки указывают на ветки, а какие на листья.
И это всё при условии, что у нас узлы 2-3 дерева динамически меняются по размеру, что требует постоянных обращений к аллокатору памяти.
Уменьшать нет смысла (всё-равно придётся снова увеличивать или удалять целиком), а если только увеличивать, то число аллокаций в худшем случае будет равным rb-tree. Но даже если выделять памяти с запасом, экономия на листьях с лихвой перекроет эти затраты.
И не забывайте, для чего вообще эти деревья нужны — для ускорения поиска и вставки всё же.
Так с поиском у rb-tree тоже всё плохо. Вот на скринах, например, для поиска 14 узла нужно сделать 5 хопов против 2.
Ок, тогда можно сделать как, собственно вы же и написали — хранить два бита для определения типа узла.
И тогда мы получим те же проблемы с аллокациями памяти.
Если мы не будем уменьшать, то тогда у нас лишняя память как раз и будет стоить те самые выигранные биты.
В худшем случае.
А как в 2-3 дереве получили 2 сравнения?
Сравнения ничего не стоят. Стоят хопы — переходы по указателям.
Важно как характеристика ведёт себя логарифмически на больших числах.
Интуитивная оценка: до двух крат разницы по глубине между узлами, что даёт в среднем процентов на 30 больше хопов по сравнению с оптимально сбалансированным деревом.
Какое-то странное у вас дерево. Обычно, в 2-3 В-дереве узел размера 1 может быть только в вырожденном случае: дерево из одного элемента.
Еще есть декартовы деревья, они же treap. Там память нужна аж для двух ключей и оно еще и рандомизированное. Но зато его писать в несколько раз легче любых других деревьев.
Балансировка красно-чёрных деревьев — Три случая