Всем привет! Перевод сегодняшнего материала мы хотим приурочить к запуску нового потока по курсу «Разработчик Java», который стартует уже завтра. Что ж начнём.
JVM может быть сложным зверем. К счастью, большая часть этой сложности скрыта под капотом, и мы, как разработчики приложений и ответственные за деплой, часто не должны об этом сильно беспокоиться. Хотя из-за роста популярности технологий развертывания приложений в контейнерах, стоит обратить внимание на распределение памяти в JVM.

Два вида памяти
JVM разделяет память на две основные категории: «кучу» (heap) и «не кучу» (non-heap). Куча — это часть памяти JVM, с которой разработчики наиболее знакомы. Здесь хранятся объекты, созданные приложением. Они остаются там до тех пор, пока не будут убраны сборщиком мусора. Как правило, размер кучи, которую использует приложение, изменяется в зависимости от текущей нагрузки.
Память вне кучи делится на несколько областей. В HotSpot для изучения областей этой памяти можно использовать механизм Native memory tracking (NMT). Обратите внимание, что, хотя NMT не отслеживает использование всей нативной памяти (например, не отслеживается выделение нативной памяти сторонним кодом), его возможностей достаточно для большинства типичных приложений на Spring. Для использования NMT запустите приложение с параметром
Давайте посмотрим использование NMT на примере нашего старого друга Petclinic. Диаграмма ниже показывает использование памяти JVM по данным NMT (за вычетом собственного оверхеда NMT) при запуске Petclinic с максимальным размером кучи 48 МБ (
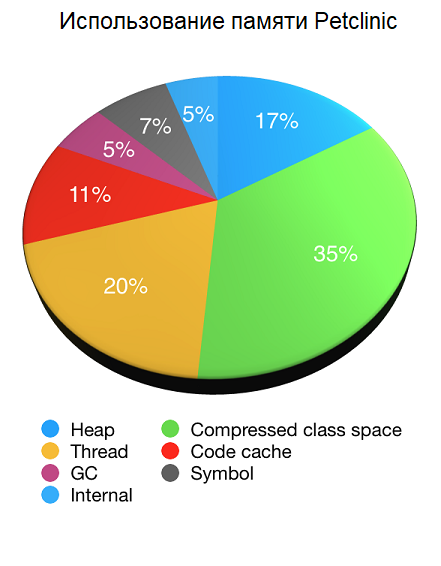
Как вы видите, на память вне кучи приходится большая часть используемой памяти JVM, причем память кучи составляет только одну шестую часть от общего объёма. В этом случае это примерно 44 МБ (из которых 33 МБ использовалось сразу после сборки мусора). Использование памяти вне кучи составило в сумме 223 МБ.
Области нативной памяти
Compressed class space (область сжатых указателей): используется для хранения информации о загруженных классах. Ограничивается параметром
Примечание переводчика
Отличия
По сравнению с кучей, память вне кучи меньше изменяется под нагрузкой. Как только приложение загрузит все классы, которые будут использоваться и JIT полностью прогреется, всё перейдет в устойчивое состояние. Чтобы увидеть уменьшение использования области Compressed class space, загрузчик классов, который загрузил классы, должен быть удален сборщиком мусора. Это было распространено в прошлом, когда приложения развертывались в контейнерах сервлетов или серверах приложений (загрузчик классов приложения удалялся сборщиком мусора, когда приложение удалялось с сервера приложений), но с современными подходами к развертыванию приложений это случается редко.
Настройка JVM
Настроить JVM для эффективного использования доступной оперативной памяти непросто. Если вы запустите JVM с параметром
Интересной областью памяти JVM является кэш кода JIT. По умолчанию HotSpot JVM будет использовать до 240 МБ. Если кэш кода слишком мал, в JIT может не хватить места для хранения своих данных, и в результате будет снижена производительность. Если кэш слишком велик, то память может быть потрачена впустую. При определении размера кэша важно учитывать его влияние как на использование памяти, так и на производительность.
При работе в контейнере Docker последние версии Java теперь знают об ограничениях памяти контейнера и пытаются соответствующим образом изменить размер памяти JVM. К сожалению, часто происходит выделение большого количества памяти вне кучи и недостаточного в куче. Допустим, у вас есть приложение, работающее в контейнере с 2-мя процессорами и 512 МБ доступной памяти. Вы хотите, чтобы обрабатывалось больше нагрузки и увеличиваете количество процессоров до 4-х и память до 1 ГБ. Как мы обсуждали выше, размер кучи обычно изменяется в зависимости от нагрузки, а память вне кучи изменяется значительно меньше. Поэтому мы ожидаем, что большая часть дополнительных 512 МБ будет предоставлена куче, чтобы справиться с увеличенной нагрузкой. К сожалению, по умолчанию JVM этого не сделает и распределит дополнительную память более менее равномерно между памятью в куче и вне кучи.
К счастью, команда CloudFoundry обладает обширными знаниями о распределении памяти в JVM. Если вы загружаете приложения в CloudFoundry, то сборщик (build pack) автоматически применит эти знания для вас. Если вы не используете CloudFoudry или хотели бы больше понять о том, как настроить JVM, то рекомендуется прочитать описание третьей версии Java buildpack’s memory calculator.
Что это значит для Spring
Команда Spring проводит много времени, думая о производительности и использовании памяти, рассматривая возможность использования памяти как в куче, так и вне кучи. Один из способов ограничить использование памяти вне кучи — это делать части фреймворка максимально универсальными. Примером этого является использование Reflection для создания и внедрения зависимостей в бины вашего приложения. Благодаря использованию Reflection количество кода фреймворка, который вы используете, остается постоянным, независимо от количества бинов в вашем приложении. Для оптимизации времени запуска мы используем кэш в куче, очищая этот кэш после завершения запуска. Память кучи может быть легко очищена сборщиком мусора, чтобы предоставить больше доступной памяти вашему приложению.
Традиционно ждём ваши комментарии по материалу.
JVM может быть сложным зверем. К счастью, большая часть этой сложности скрыта под капотом, и мы, как разработчики приложений и ответственные за деплой, часто не должны об этом сильно беспокоиться. Хотя из-за роста популярности технологий развертывания приложений в контейнерах, стоит обратить внимание на распределение памяти в JVM.

Два вида памяти
JVM разделяет память на две основные категории: «кучу» (heap) и «не кучу» (non-heap). Куча — это часть памяти JVM, с которой разработчики наиболее знакомы. Здесь хранятся объекты, созданные приложением. Они остаются там до тех пор, пока не будут убраны сборщиком мусора. Как правило, размер кучи, которую использует приложение, изменяется в зависимости от текущей нагрузки.
Память вне кучи делится на несколько областей. В HotSpot для изучения областей этой памяти можно использовать механизм Native memory tracking (NMT). Обратите внимание, что, хотя NMT не отслеживает использование всей нативной памяти (например, не отслеживается выделение нативной памяти сторонним кодом), его возможностей достаточно для большинства типичных приложений на Spring. Для использования NMT запустите приложение с параметром
-XX:NativeMemoryTracking=summary и с помощью jcmd VM.native_memory summary посмотрите информацию об используемой памяти.Давайте посмотрим использование NMT на примере нашего старого друга Petclinic. Диаграмма ниже показывает использование памяти JVM по данным NMT (за вычетом собственного оверхеда NMT) при запуске Petclinic с максимальным размером кучи 48 МБ (
-Xmx48M):
Как вы видите, на память вне кучи приходится большая часть используемой памяти JVM, причем память кучи составляет только одну шестую часть от общего объёма. В этом случае это примерно 44 МБ (из которых 33 МБ использовалось сразу после сборки мусора). Использование памяти вне кучи составило в сумме 223 МБ.
Области нативной памяти
Compressed class space (область сжатых указателей): используется для хранения информации о загруженных классах. Ограничивается параметром
MaxMetaspaceSize. Функция количества классов, которые были загружены.Примечание переводчика
Почему-то автор пишет про «Compressed class space», а не про всю область «Class». Область «Compressed class space» входит в состав области «Сlass», а параметрMaxMetaspaceSizeограничивает размер всей области «Class», а не только «Compressed class space». Для ограничения «Compressed class space» используется параметрCompressedClassSpaceSize.
Отсюда:
IfUseCompressedOopsis turned on andUseCompressedClassesPointersis used, then two logically different areas of native memory are used for class metadata…
A region is allocated for these compressed class pointers (the 32-bit offsets). The size of the region can be set withCompressedClassSpaceSizeand is 1 gigabyte (GB) by default…
TheMaxMetaspaceSizeapplies to the sum of the committed compressed class space and the space for the other class metadata
Если включен параметрUseCompressedOopsи используетсяUseCompressedClassesPointers, тогда для метаданных классов используется две логически разные области нативной памяти…
Для сжатых указателей выделяется область памяти (32-битные смещения). Размер этой области может быть установленCompressedClassSpaceSizeи по умолчанию он 1 ГБ…
ПараметрMaxMetaspaceSizeотносится к сумме области сжатых указателей и области для других метаданных класса.
- Thread (потоки): память, используемая потоками в JVM. Функция количества запущенных потоков.
- Code cache (кэш кода): память, используемая JIT для его работы. Функция количества классов, которые были загружены. Ограничивается параметром
ReservedCodeCacheSize. Можно уменьшить настройкой JIT, например, отключив многоуровневую компиляцию (tiered compilation). - GC (сборщик мусора): хранит данные, используемые сборщиком мусора. Зависит от используемого сборщика мусора.
- Symbol (символы): хранит такие символы, как имена полей, сигнатуры методов и интернированные строки. Чрезмерное использование памяти символов может указывать на то, что строки слишком интернированы.
- Internal (внутренние данные): хранит прочие внутренние данные, которые не входят ни в одну из других областей.
Отличия
По сравнению с кучей, память вне кучи меньше изменяется под нагрузкой. Как только приложение загрузит все классы, которые будут использоваться и JIT полностью прогреется, всё перейдет в устойчивое состояние. Чтобы увидеть уменьшение использования области Compressed class space, загрузчик классов, который загрузил классы, должен быть удален сборщиком мусора. Это было распространено в прошлом, когда приложения развертывались в контейнерах сервлетов или серверах приложений (загрузчик классов приложения удалялся сборщиком мусора, когда приложение удалялось с сервера приложений), но с современными подходами к развертыванию приложений это случается редко.
Настройка JVM
Настроить JVM для эффективного использования доступной оперативной памяти непросто. Если вы запустите JVM с параметром
-Xmx16M и ожидаете, что будет использоваться не более 16 МБ памяти, то вас ждёт неприятный сюрприз.Интересной областью памяти JVM является кэш кода JIT. По умолчанию HotSpot JVM будет использовать до 240 МБ. Если кэш кода слишком мал, в JIT может не хватить места для хранения своих данных, и в результате будет снижена производительность. Если кэш слишком велик, то память может быть потрачена впустую. При определении размера кэша важно учитывать его влияние как на использование памяти, так и на производительность.
При работе в контейнере Docker последние версии Java теперь знают об ограничениях памяти контейнера и пытаются соответствующим образом изменить размер памяти JVM. К сожалению, часто происходит выделение большого количества памяти вне кучи и недостаточного в куче. Допустим, у вас есть приложение, работающее в контейнере с 2-мя процессорами и 512 МБ доступной памяти. Вы хотите, чтобы обрабатывалось больше нагрузки и увеличиваете количество процессоров до 4-х и память до 1 ГБ. Как мы обсуждали выше, размер кучи обычно изменяется в зависимости от нагрузки, а память вне кучи изменяется значительно меньше. Поэтому мы ожидаем, что большая часть дополнительных 512 МБ будет предоставлена куче, чтобы справиться с увеличенной нагрузкой. К сожалению, по умолчанию JVM этого не сделает и распределит дополнительную память более менее равномерно между памятью в куче и вне кучи.
К счастью, команда CloudFoundry обладает обширными знаниями о распределении памяти в JVM. Если вы загружаете приложения в CloudFoundry, то сборщик (build pack) автоматически применит эти знания для вас. Если вы не используете CloudFoudry или хотели бы больше понять о том, как настроить JVM, то рекомендуется прочитать описание третьей версии Java buildpack’s memory calculator.
Что это значит для Spring
Команда Spring проводит много времени, думая о производительности и использовании памяти, рассматривая возможность использования памяти как в куче, так и вне кучи. Один из способов ограничить использование памяти вне кучи — это делать части фреймворка максимально универсальными. Примером этого является использование Reflection для создания и внедрения зависимостей в бины вашего приложения. Благодаря использованию Reflection количество кода фреймворка, который вы используете, остается постоянным, независимо от количества бинов в вашем приложении. Для оптимизации времени запуска мы используем кэш в куче, очищая этот кэш после завершения запуска. Память кучи может быть легко очищена сборщиком мусора, чтобы предоставить больше доступной памяти вашему приложению.
Традиционно ждём ваши комментарии по материалу.
