
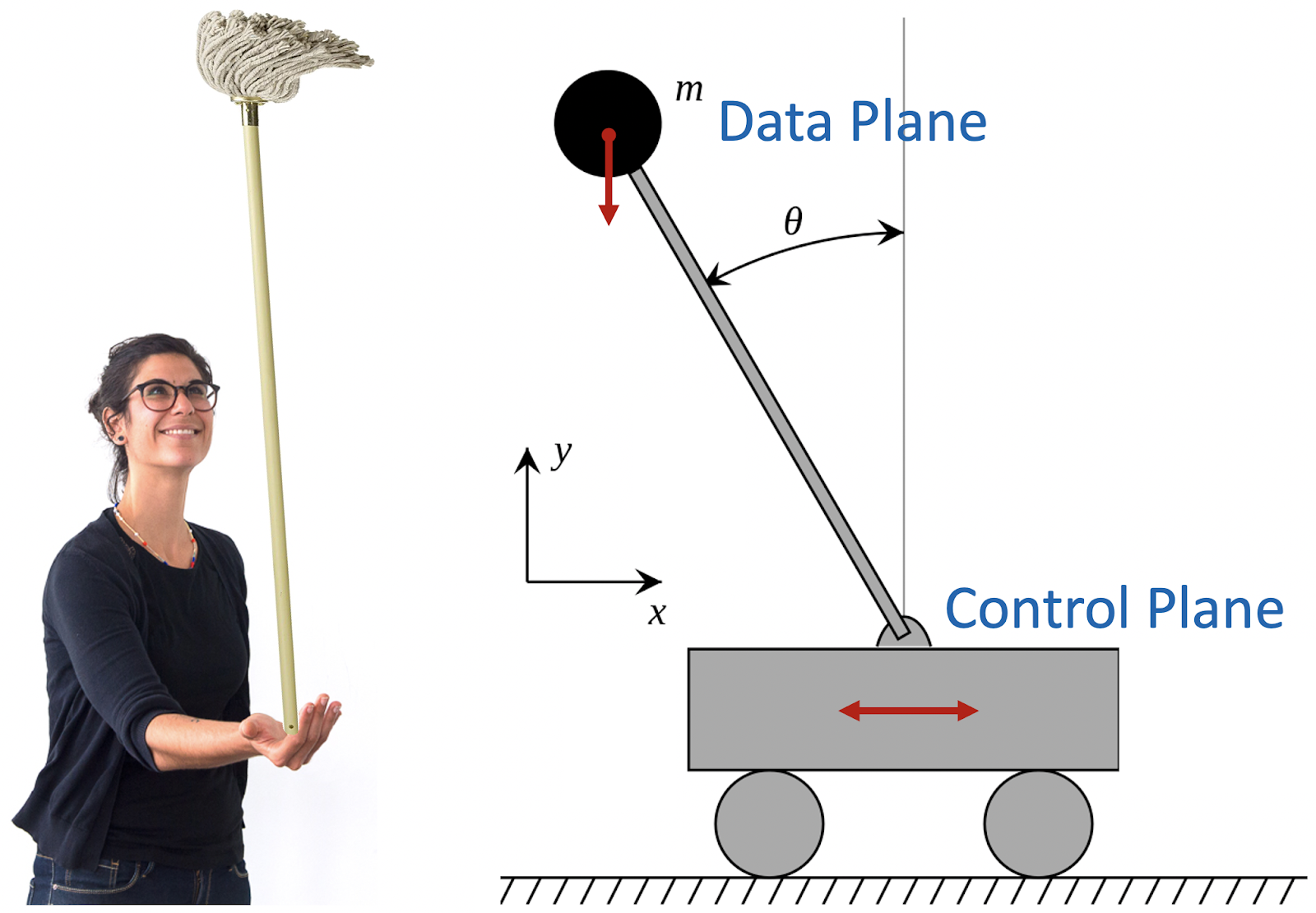
Помните детскую забаву? Поставить швабру на ладонь и удержать ее в вертикальном положении как можно дольше? В теории управления она известна под именем обратного маятника. Есть палка с грузом на конце и тележка, которая должна удерживать этот маятник в вертикальном положении.
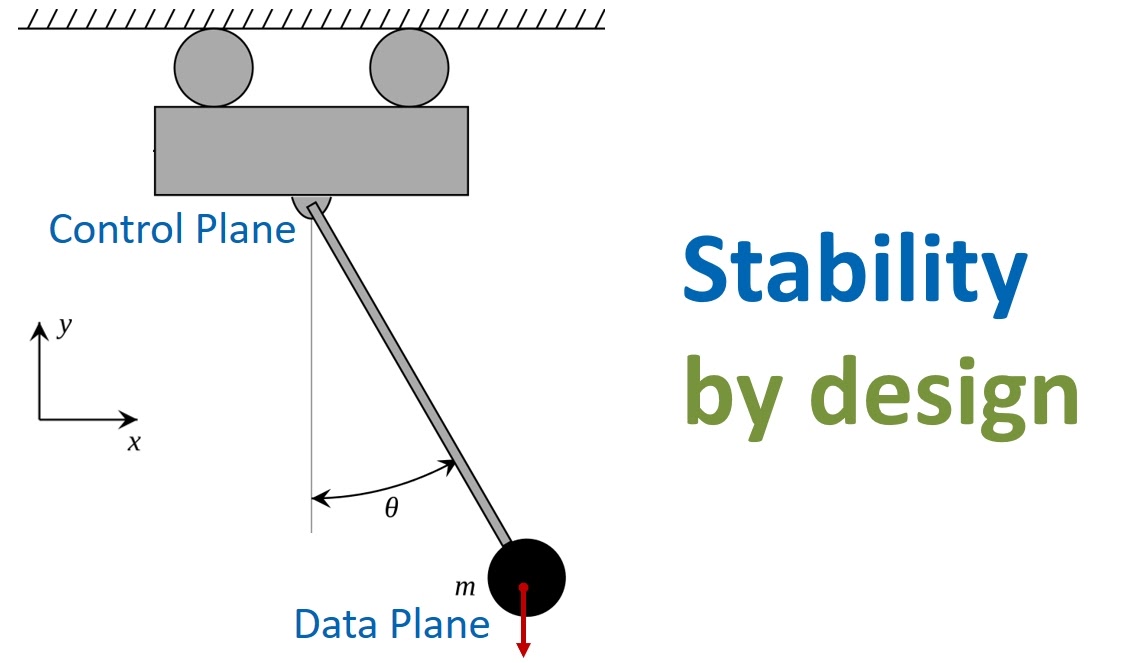
Это отличная аналогия для современных облачных сервисов. Палка с грузом — это Data Plane сервиса. На русский язык этот термин можно перевести как «уровень передачи и обработки данных». Тележка — Control Plane или «уровень управления». Основная задача Control Plane заключается в обеспечении стабильной работы Data Plane. То есть нужно балансировать так, чтобы Data Plane всегда был в вертикальном, работоспособном состоянии. Это не просто — любые задержки и сбои в Control Plane неминуемо приведут к тому, что Data Plane «упадет». Василий Пантюхин, архитектор AWS, поделится примером того, как нетривиальную задачу по стабилизации сервисов решают в облаке Amazon.
Нестабильную систему сделать просто, часто само как-то получается. Но последствия могут быть катастрофическими. Например, в Стокгольме есть замечательный музей королевского корабля Васа. Строительство курировал сам король, но несмотря на это, корабль был спроектирован исключительно глупо. Он был слишком узкий и имел очень высоко расположенный центр тяжести, что и привело к его неустойчивости. После выхода из гавани, из-за ветра корабль дал такой сильный крен, что затонул не пройдя и двух километров.

Конечно, нам не хотелось бы, чтобы сервисы AWS были такими. В архитектуру изначально нужно закладывать стабильность при которой любые проблемы с Control Plane серьезно не повлияют на работоспособность Data Plane. Продолжая морскую аналогию, можно сказать, что сервисы должны быть как катамараны — непереворачиваемые и непотопляемые.
Too big to fail
Облако AWS сейчас предоставляет ресурсы в 25 географических регионах. В каждом регионе находится несколько Зон Доступности (Availability Zones или AZ) — это группы дата-центров внутри региона. В крупнейших регионах AWS число дата-центров в одной AZ доходит до восьми.
Несмотря на огромные размеры, инфраструктура очень надежная. Но даже в ней иногда случаются неприятности. В 2011 году в регионе Северная Вирджиния внезапно стали недоступными 13% томов сервиса Elastic Block Store (EBS). И это достаточно много.

Давайте разберемся, в чем была проблема. EBS — это базовый сервис блочного хранения данных. Для пользователей это не более чем набор дисков, которые можно подключать к виртуальным машинам (Elastic Compute Cloud или EC2).

Но под капотом EBS построен как распределенная и очень сложная система. Если заглянуть за первый уровень сложности, то мы увидим что каждый том состоит из множества секций (Partitions). Они, в свою очередь, имеет две копии данных — основная (Primary) и реплика (Replica). Запись данных всегда производится в синхронном режиме на обе копии, а чтение — только с Primary. В сессии на Highload++ я использовал термины Master и Slave, но сейчас прогрессивное ИТ-сообщество от них отказывается. Во избежание вопросов, я последовал их примеру.
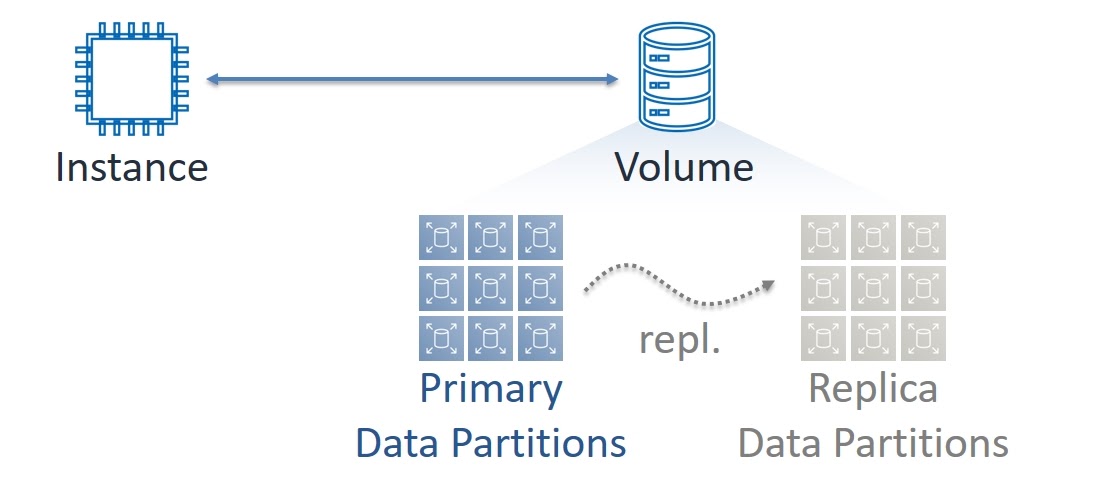
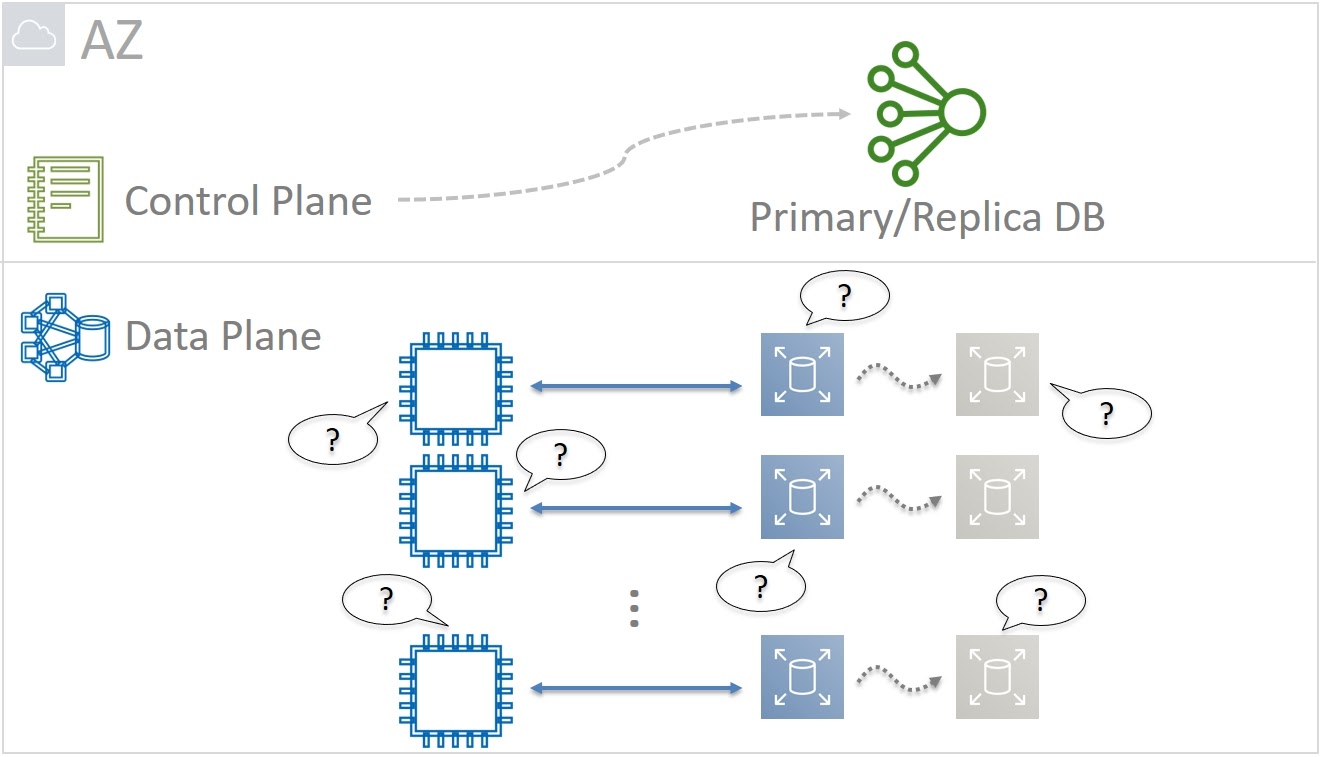
При этом и виртуальные машины, и тома EBS всегда работают в конкретных Зонах Доступности. Можно сказать, что Data Plane сервисов EC2 и EBS является зональными — в каждой AZ есть свой независимый набор компонентов для передачи и обработки данных.
А вот Control Plane сервиса EBS на момент происшествия в 2011 году был региональным — и его компоненты были распределены по всем Зонам Доступности в Регионе. Именно эта архитектурная особенность оказалась тонким местом, когда из-за человеческой ошибки произошел сбой сети в одной из Availability Zones.
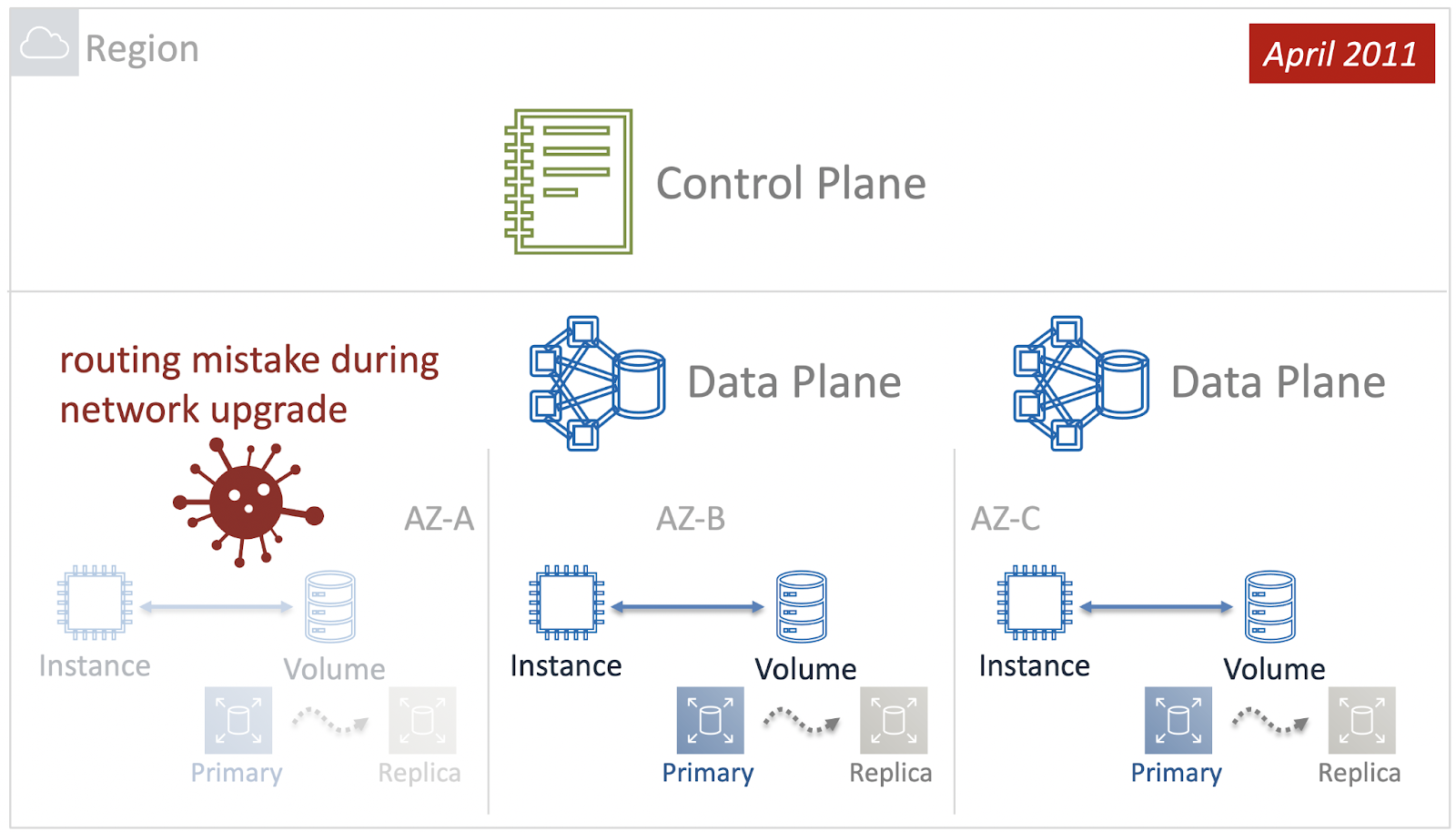
Как реакция на сбой, Control Plane постарался восстановить работоспособность EBS и вернуть обратно пары Primary-Replica. Однако, проблема была на уровне сети, и попытка оказалась неудачной. Дополнительно к этому, в связи с огромным количеством томов, которые нужно было восстановить, Control Plane истощил все свои ресурсы, а так как он был региональным, то не смог обрабатывать запросы из других Зон Доступности. И проблема каскадно опустилась на другие Availability Zones.
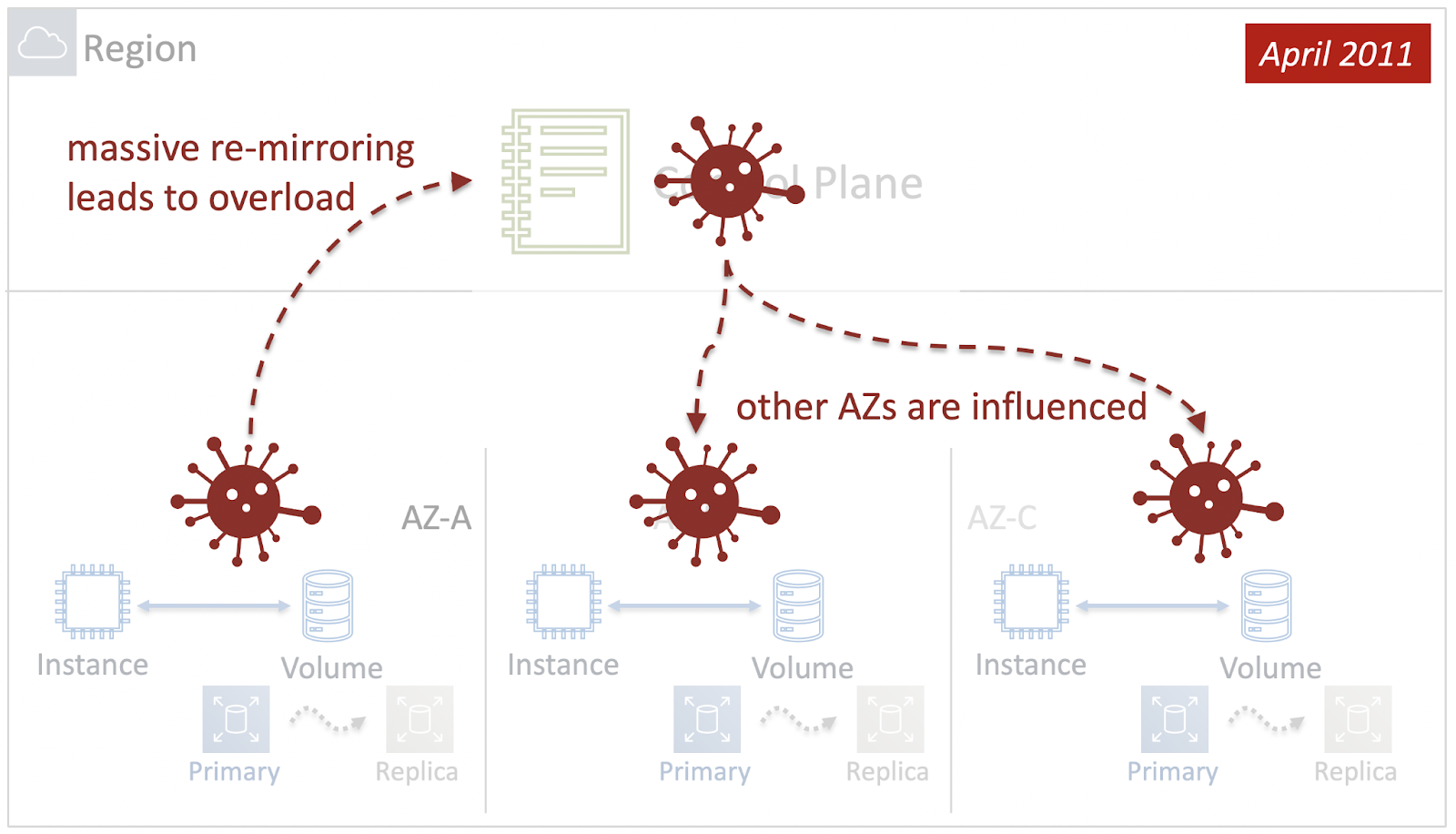
Тем самым, неприятности в одной Зоне Доступности привели к катастрофе на уровне всего Региона. Другими словами, в 2011 году Радиус Поражения (Blast Radius) сервиса EBS был равен Региону. Как это исправить? Первый и очевидный шаг — это сделать Control Plane сервиса не региональным, а зональным.
Мы разместили компоненты уровня управления в каждой Availability Zone и сделали их независимыми друг от друга. Так Blast Radius уменьшился до Зоны Доступности.
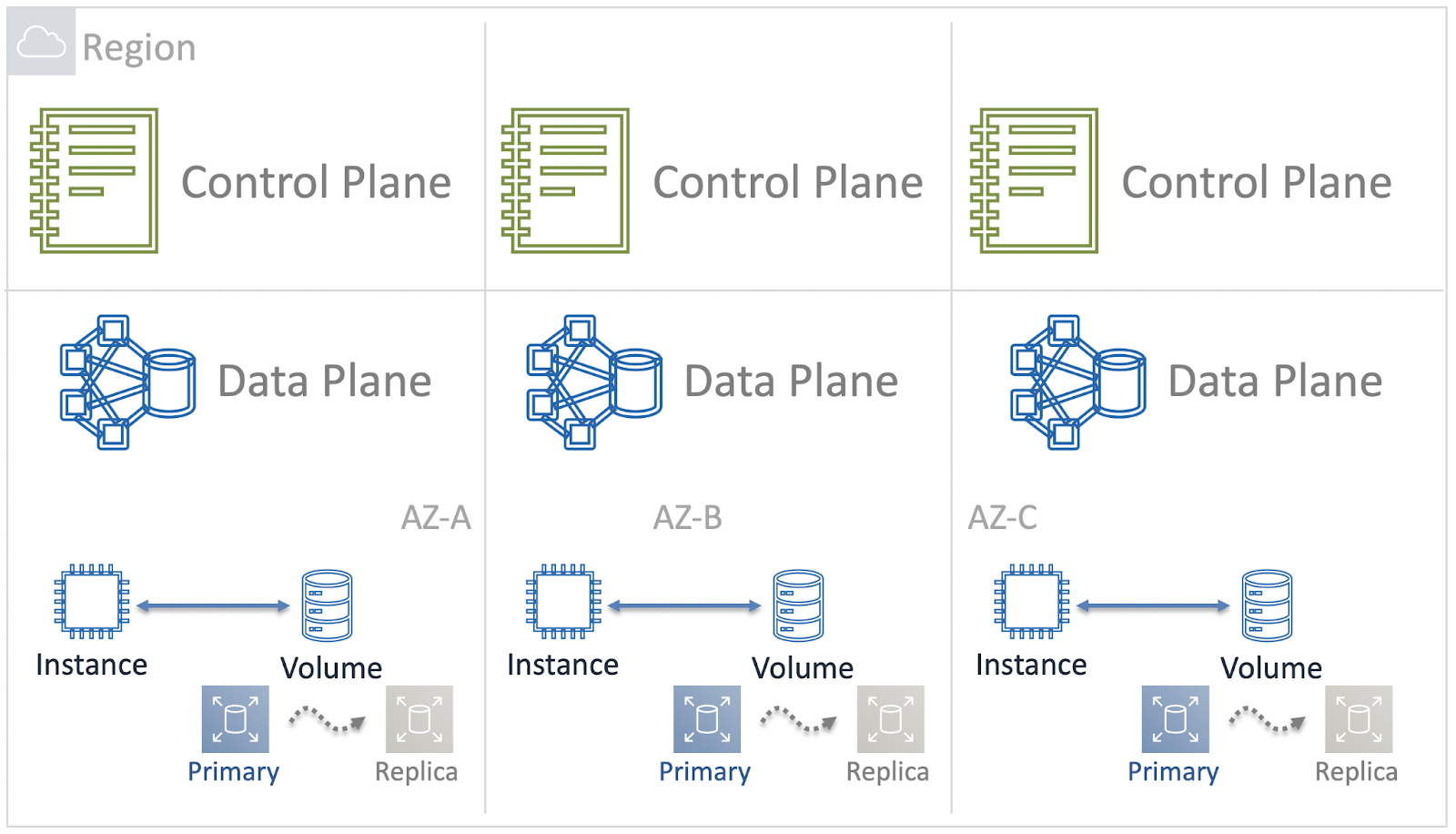
Но на этом мы не закончили. Как я уже говорил, в таких больших Регионах AWS как Северная Вирджиния, Зоны Доступности тоже огромные. И если что-то сломается даже в рамках одной AZ, это все равно будет очень неприятно для многих пользователей облака. Покажу нашу эволюцию улучшений.
Шаг 1. Blast radius = AZ
Вернемся в 2011 год. Нашей задачей было уменьшение blast radius до Зоны Доступности. Поэтому мы задумались об архитектуре зонального Control Plane. Рассмотрим пример. Мы запускаем новую виртуальную машину и ей нужны тома для хранения данных — минимум один, на котором будет «жить» операционная система. Виртуалка должна кого-то спросить о том, какие Partitions выделены этому тому. Сами Primary и Replica тоже должны постоянно коммуницировать друг с другом. Это нужно, например, для избежания ситуации разделения кластера (Split-brain), когда в результате сетевых задержек или потерь пакетов Replica не знает о состоянии Primary.
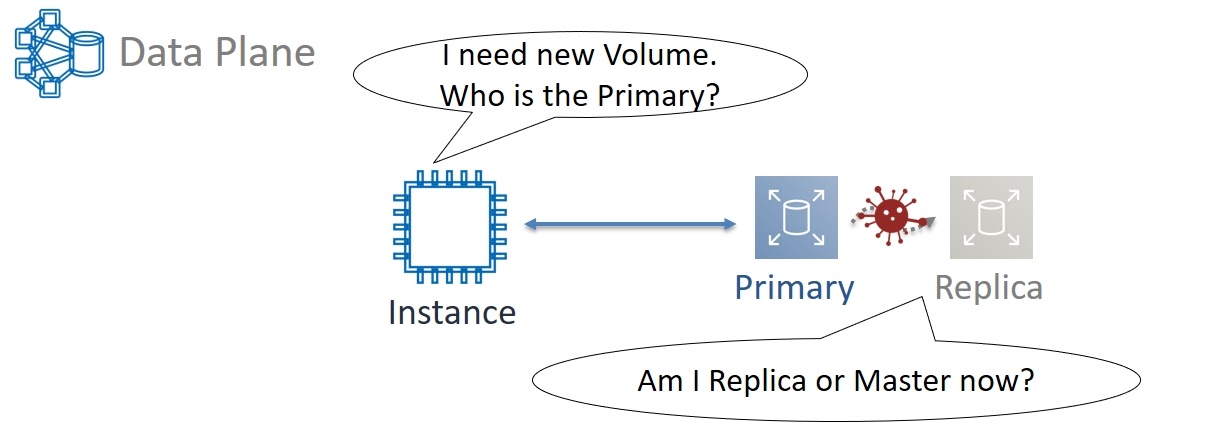
Если Primary живой, то нужно подождать восстановления связи с ним. А если Primary уже умер, то Replica сама должна стать новым Primary. Поэтому какой-то базе данных все время нужно отслеживать и помнить кто Primary, а кто — Replica. Задача важная, но по сути простая. В итоге для Primary/Replica DB мы решили не использовать хитрых реляционных баз и экзотических типов данных. Оптимальным решением стал простой Key-Value с поддержкой integer, string и boolean типов данных.
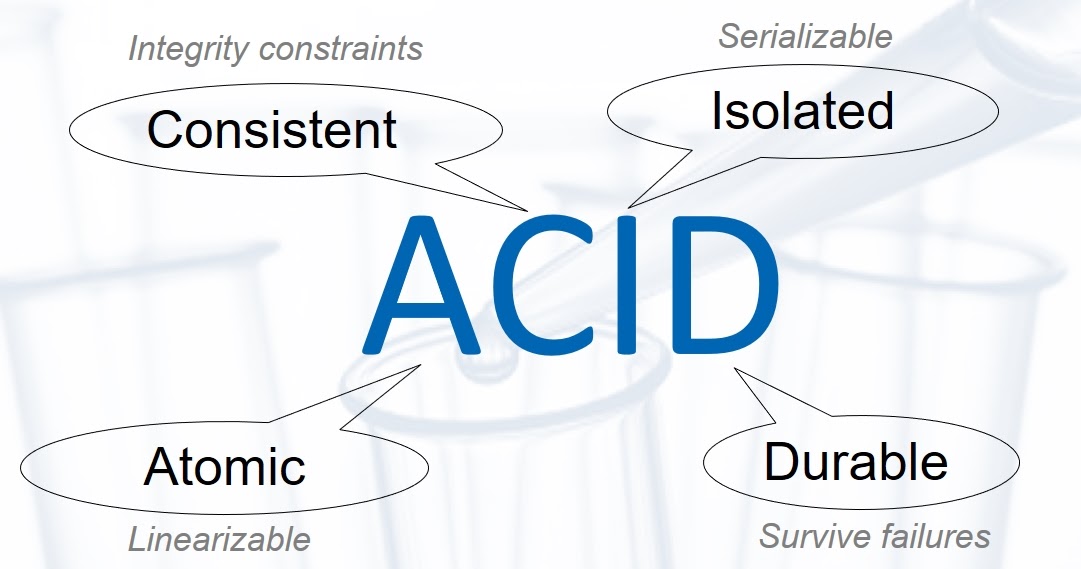
В то же время Primary/Replica DB критична для работоспособности всего сервиса. Поэтому она должна быть сверхнадежной и, как следствие — ACID (Atomic, Consistent, Isolated, Durable) в жестких требованиях Линеаризации (Linearizable Atomicity) и Сериализации (Serializable Isolation).
Высокие требования к масштабируемости, отказоустойчивости и доступности нас естественным образом заставляют реализовать такую базу данных распределенной. Но это проще сказать, чем сделать. Ведь нам нужно было решить вопрос согласованности данных между всеми компонентами. По сути — реализовать базу данных в виде distributed state machine (распределенного конечного автомата). А ноды такой системы должны всегда приходить к общему консенсусу, т. е. договариваться об одних и тех же значениях данных, которые они хранят.
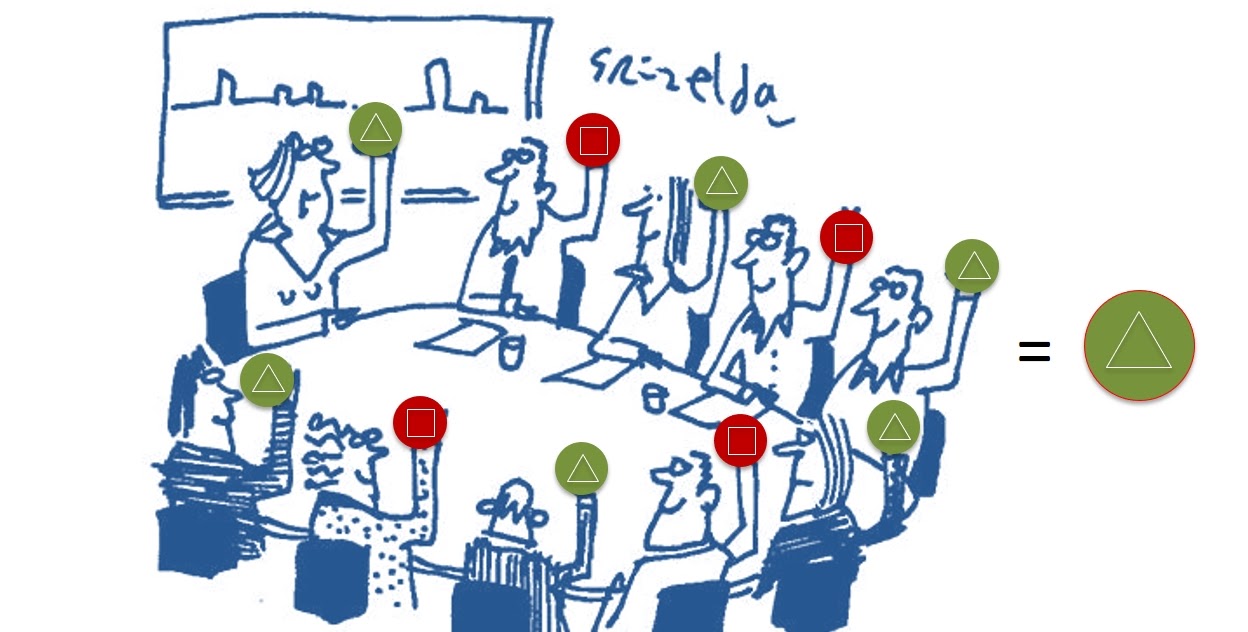
Конечно, можно просто проголосовать всем компонентам, а потом их пересчитать и принять решение, следуя большинству голосов (majority). Но в реальности такой подход не работает. Мы ведь говорим о масштабах облака AWS. Общее количество компонент огромно и, чисто статистически, они периодически ломаются, связь между ними иногда пропадает. Компоненты восстанавливаются после сбоя, но медленно и могут не успевать полноценно поучаствовать в «голосовании». Так что простой подход, основанный на majority, будет нестабильным.
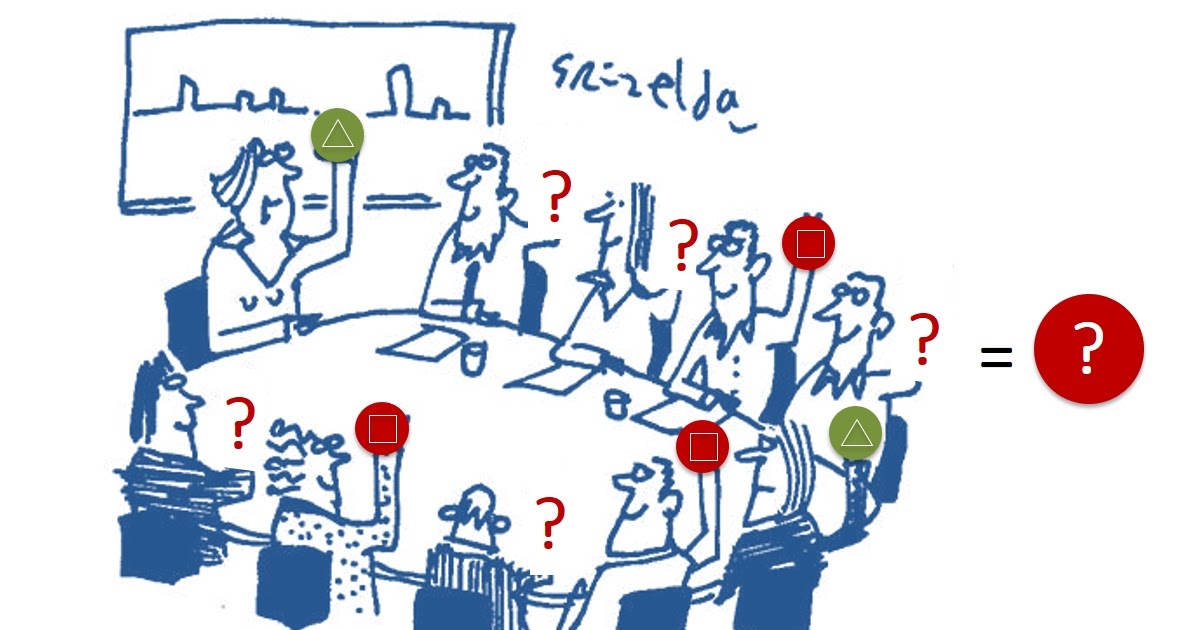
Но есть масса других протоколов для выработки консенсуса: это Paxos, Viewstamped Replication, Raft, Virtual Synchrony. Для нашего случая мы выбрали Paxos. Причин две:
Paxos уже использовался в других наших сервисах;
Это достаточно «взрослый» подход, про него написано много различных статей. Google, LinkedIn, Microsoft им пользуются уже давно и можно найти информацию о том, на какие грабли они наступили, и наоборот — какие плюсы получили.
В Control Plane сервиса EBS мы реализовали Paxos с нуля. В итоге получили простую распределенную ACID базу данных, blast radius которой равен Зоне Доступности. Но, как я уже упоминал, этого тоже было недостаточно. И для его уменьшения мы решили реализовать Primary/Replication DB в виде ячеек.
Шаг 2. Blast radius = Brick local
Ячеистый подход используется инженерами очень давно. Уже в Средневековом Китае корпус лодок-джонок перегородками был разделен на водонепроницаемые отсеки. В случае пробоины, затапливается только одна или несколько таких камер, но лодка остается на плаву. Сейчас же ячеистый подход используется повсеместно.

Но сколько нужно ячеек для Primary/Replica DB на одну Зону Доступности? Две, четыре, восемь?
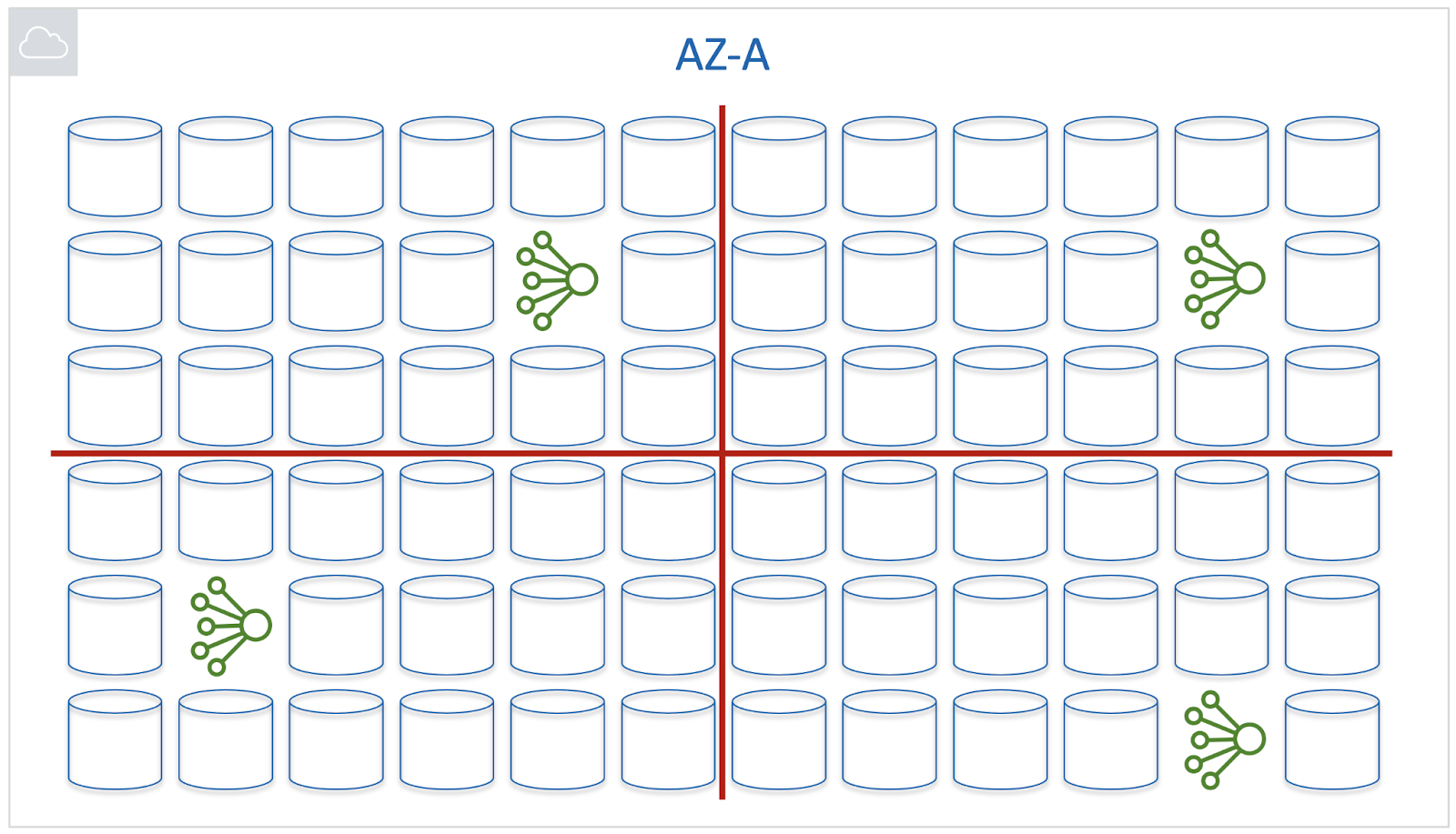
Если ячеек большого размера будет всего несколько, то проблемы, которые иногда возникают, будут масштабными. Большое количество маленьких ячеек сделает проблемы в них более частыми. Зато такие сбои будет легче локализовать и контролировать. И мы решили не просто следовать этим путем, но довести его до крайности, выделив Primary/Replica базу данных персонально каждому логическому тому EBS. И ему же в итоге должен быть равен blast radius.

Звучит классно, но как это реализовать на практике? Мы вдохновились одним интересным морским существом — Португальским корабликом или Physalia. Внешне он выглядит как медуза, но на самом деле это колония огромного количества полипов разных типов.

Мы решили, что мы будем строить свой сервис как колонию Physalia. Каждый из миллионов томов EBS в рамках одной Availability Zone будет управляться своей собственной Primary/Replica DB. А база данных, в свою очередь, представит ячейку (cell) состоящую из нескольких нод. Ячейка — это распределенная система под управлением Paxos. Эти ноды будут расположены на различных физических серверах. А для надежности мы будем следить, чтобы ноды одной cell никогда не попадали на общие для них серверы.
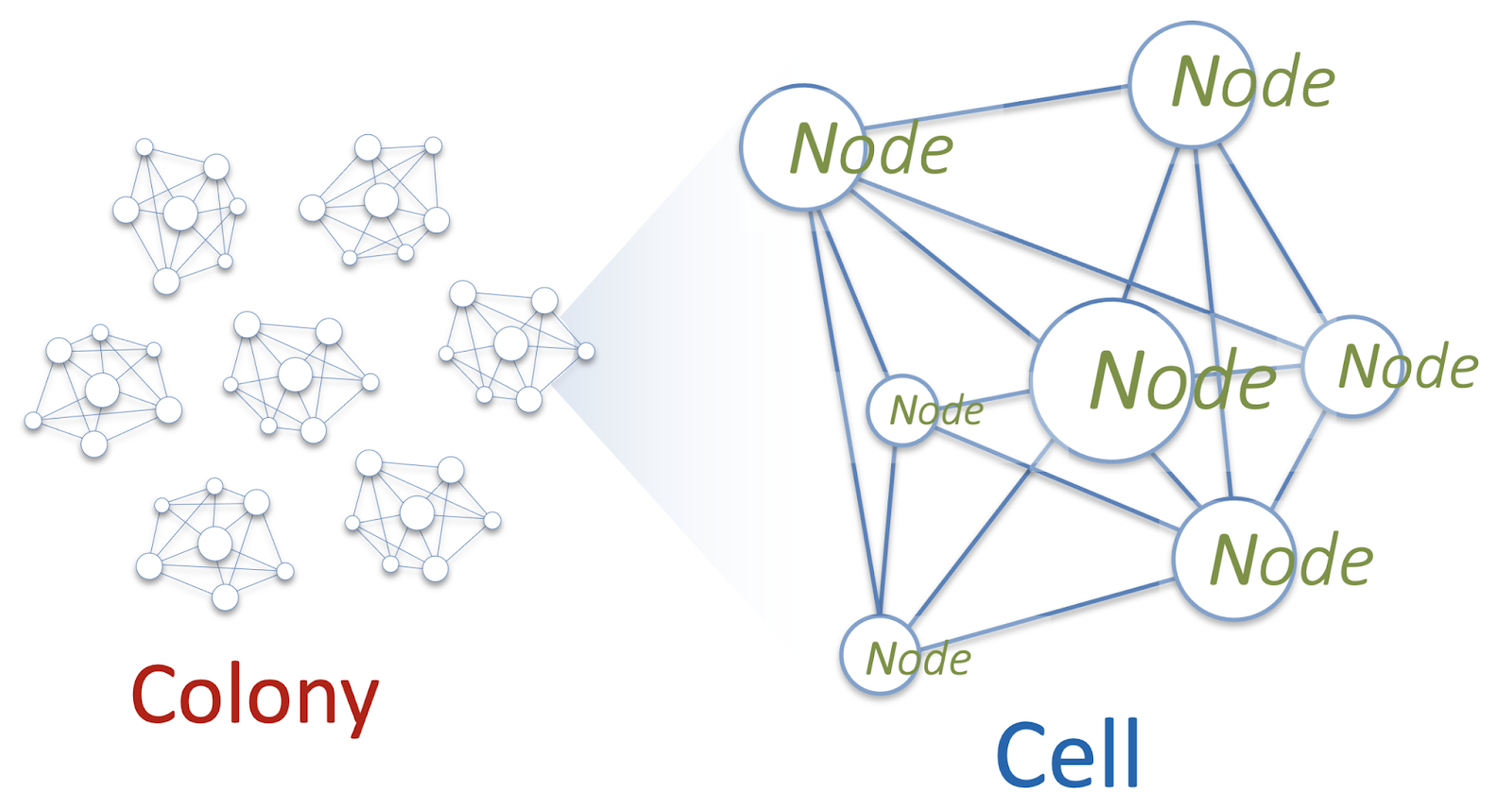
Задача ноды будет очень простой: участвовать в Paxos и хранить несколько десятков килобайт данных. Тогда потребление ею CPU и RAM будет минимальным. А для пущей экономии ресурсов на отдельном физическом сервере будут запускаться многие сотни нод разных ячеек Physalia. Архитектурно это выглядит как топология «многие к многим» (mesh).
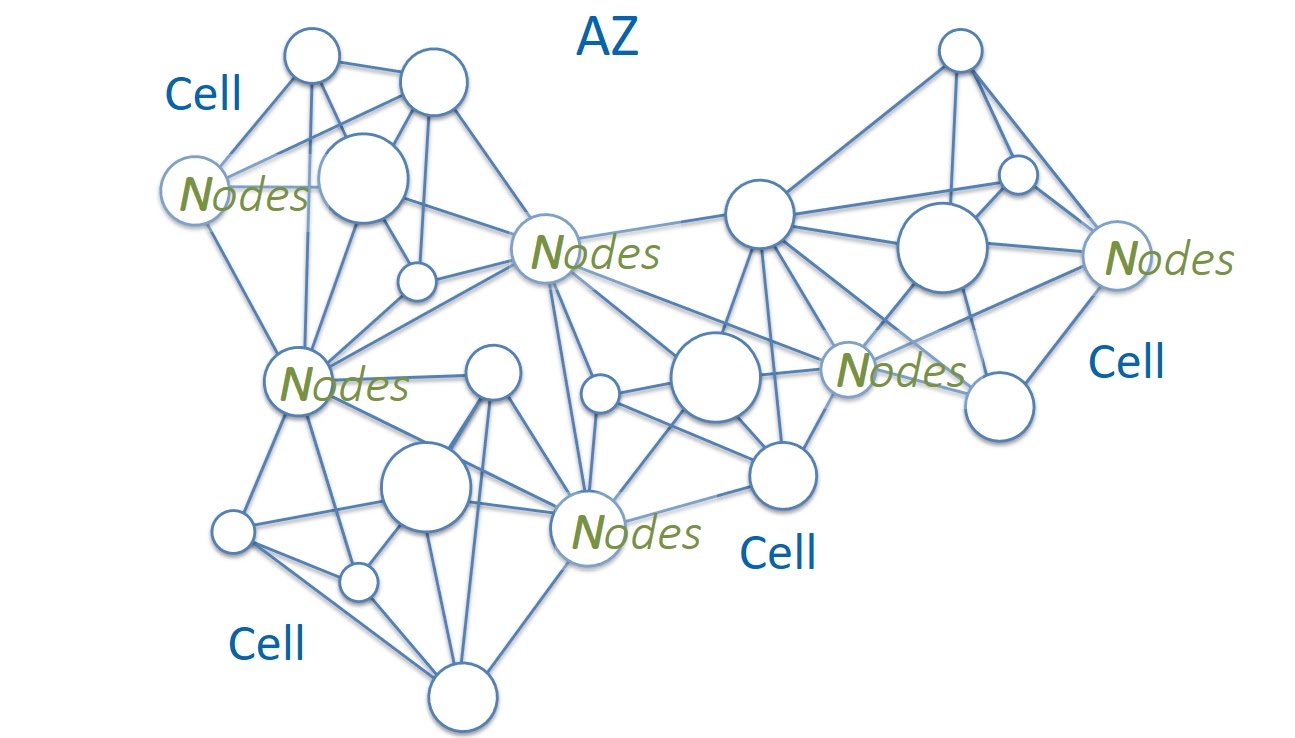
Какое количество нод будет оптимальным для одной ячейки? Много — плохо, мало — тоже плохо. Давайте сначала посмотрим на этот вопрос с точки зрения некоррелируемых ошибок. Например, такие ошибки возникают, когда выходит из строя физический сервер. Это влияет только на конкретные ноды отдельных ячеек. Такая ситуация является изолированной и сама по себе не вызывает поломок других серверов и нод.

Можно подойти к вопросу также с точки зрения коррелируемых ошибок. Например, когда происходит массовый сбой по питанию и сразу много серверов — и соответственно, нод Physalia — становятся недоступными одновременно.
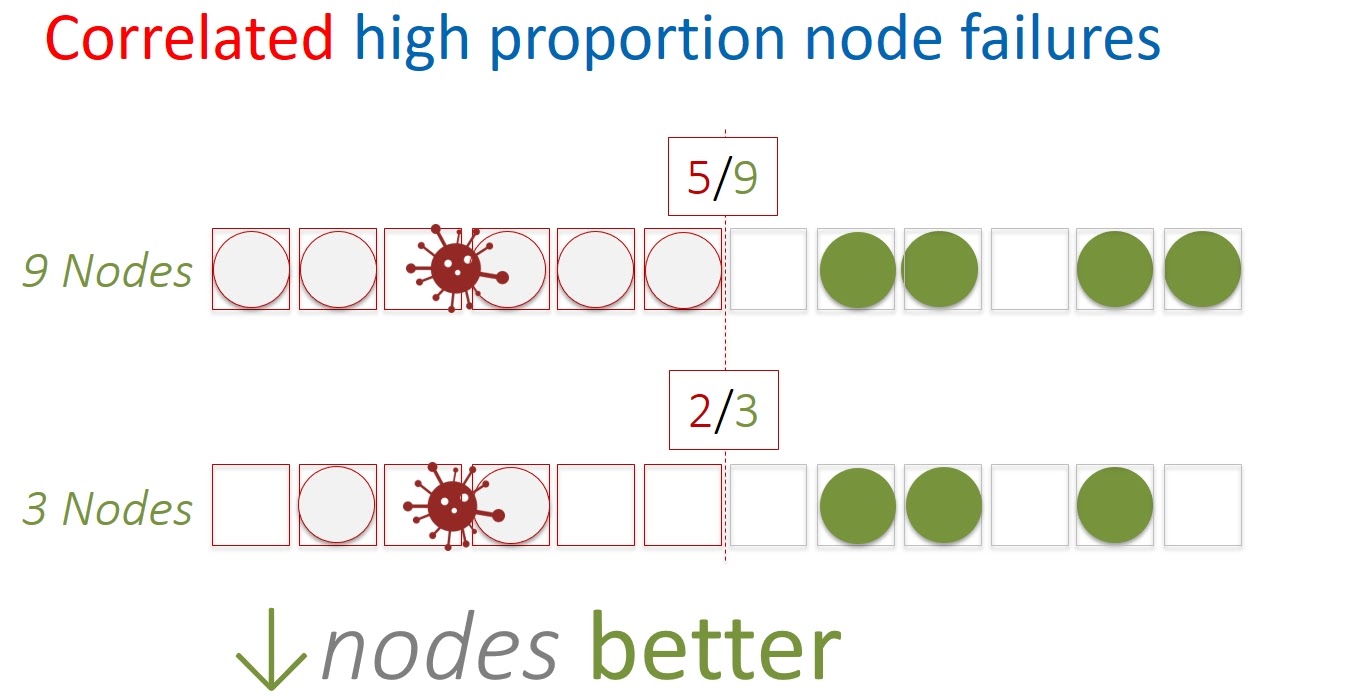
Если аккуратно посчитать, то получится, что при ограниченном количестве некоррелируемых ошибок, доступность распределенной системы будет лучше при бóльшем количестве нод. И наоборот, если у нас одновременно по каким-то причинам падает половина и более нод, то ячейки меньшего размера будут более отказоустойчивыми.
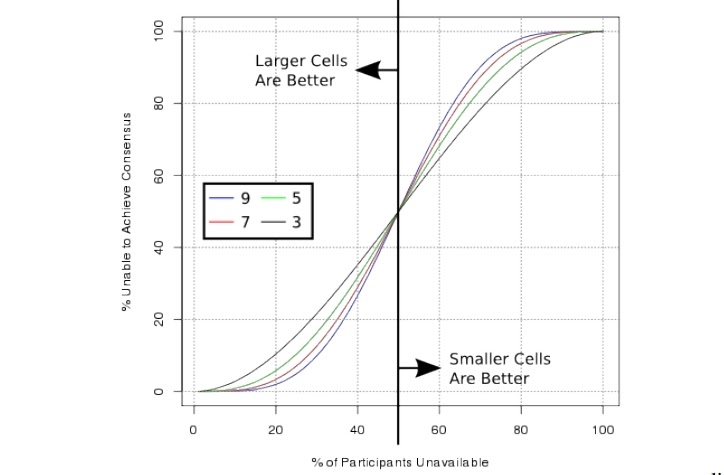
Также стоит принять во внимание, что Paxos сам по себе при множестве нод требует бóльшего количества ресурсов. В общем, разумный размер ячейки варьируется от 5 до 13. Мы в итоге выбрали 7.
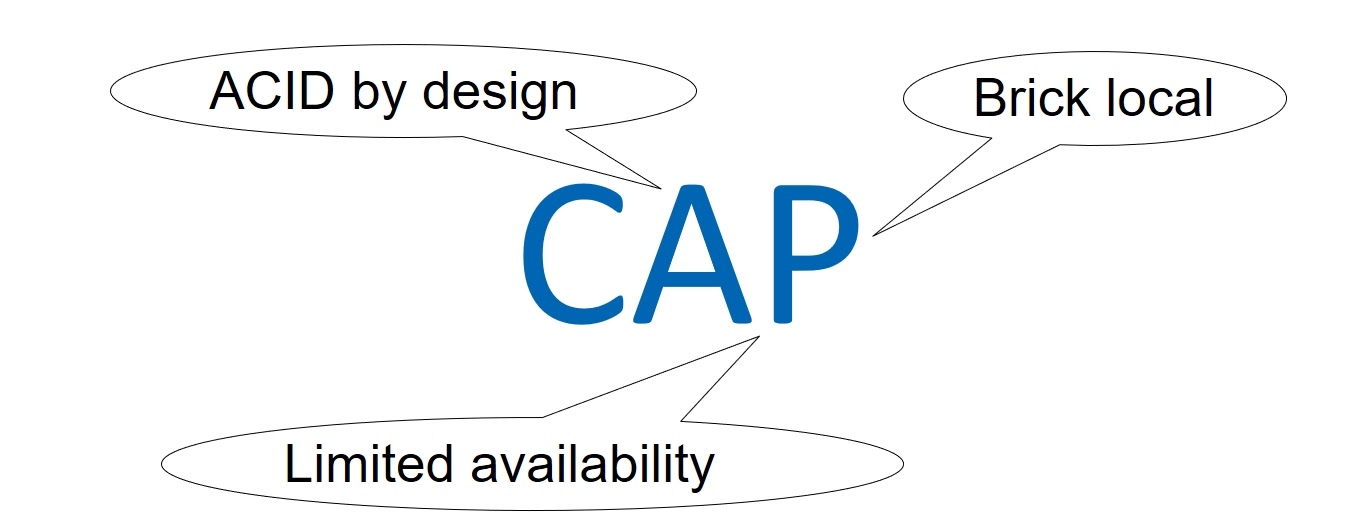
Конечно, наша Primary/Replication база данных должна быть также сбалансирована с точки зрения целостности, доступности и устойчивости к разделению. Да, здесь мы поговорим о CAP-теореме. Однако, я не буду даже пытаться обсуждать вопросы ее правильности и применимости, это дело неблагодарное. Просто CAP-подход мне сейчас позволит использовать уже всем понятные термины Consistency, Availability и Partition tolerance.
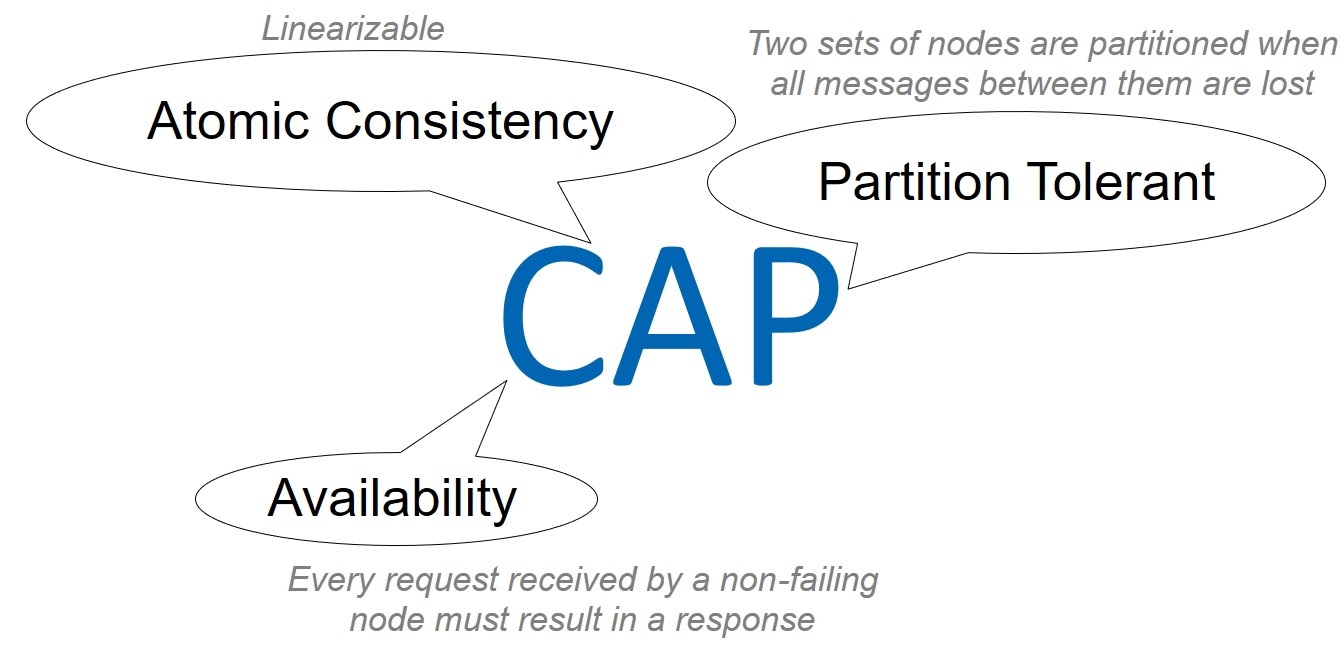
Итак, можем ли мы допустить слабую целостность данных (Consistency)? Однозначно, нет — мы уже решили, что наша база данных будет ACID, притом в строгих категориях сериализации и линеаризации.
Далее. Должна ли наша система быть высокоуступной (Available)? И да, и нет. База данных не обязана быть доступна всем клиентам, т. е. всем виртуальным машинам. В определенный момент времени ее использует конкретная виртуалка и соответствующая пара Primary/Replica. До всех остальных потенциальных потребителей нашей базе дела нет, поэтому доступность здесь трактуется не глобально на всю AZ, а в узком смысле.
И третий параметр — устойчивость к разделению сети. Можем ли мы работать со слабой Partition tolerance? Очевидно, нет. Внутренняя сеть облака AWS огромна. Даже если мы будем использовать максимально надежное сетевое оборудование и хитрые протоколы, в таких масштабах, чисто статистически, все-равно периодически будут теряться пакеты и возникать задержки. А значит, ноды в ячейках будут разделяться, переставая друг друга видеть.
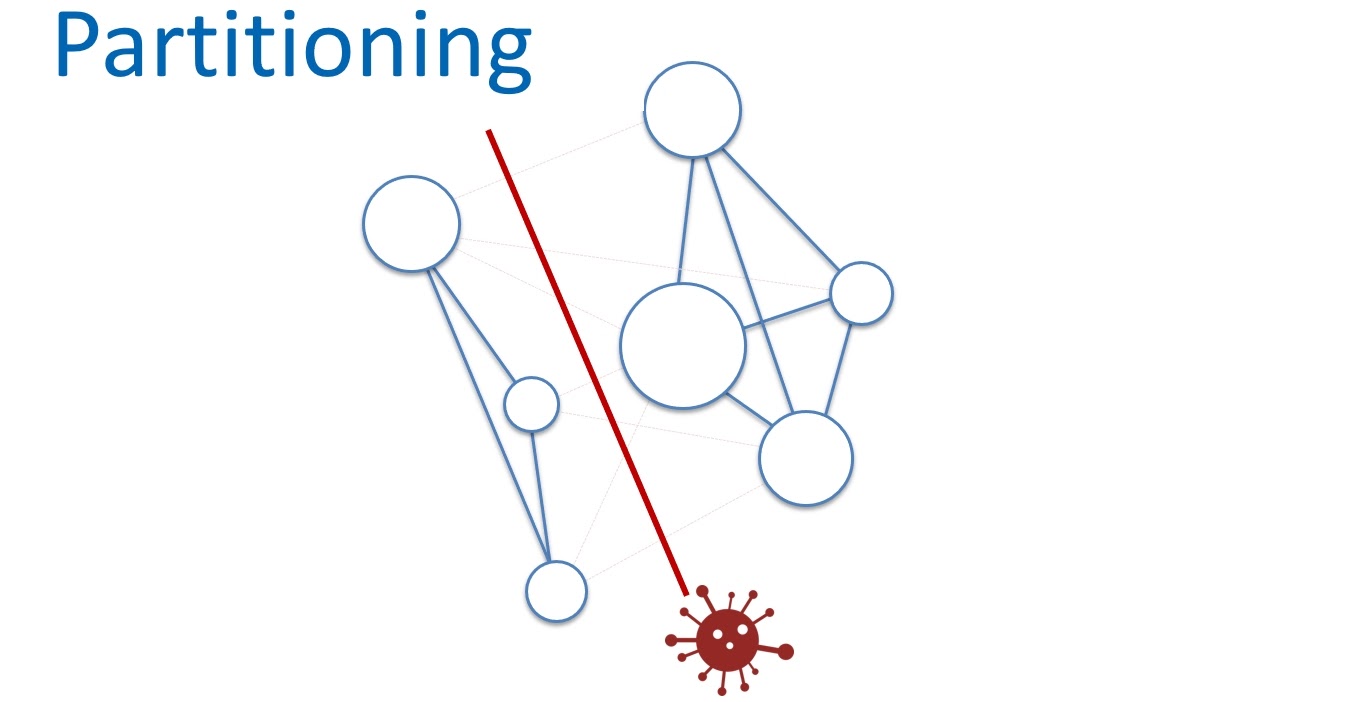
С этим ничего не поделать, нужно просто смириться и строить сервисы с высокой устойчивостью к разделению сети. Но при этом, нужно контролировать масштабы такого разделения.
Посмотрим теперь на упрощенную физическую схему сети. Оборудование смонтировано в серверные шкафы с ToR (Top of the Rack) коммутаторами. Эти коммутаторы агрегируются в группы, которые мы называем Brick. Такие группы подключаются к сети при помощи Brick-маршрутизаторов. За следующий уровень агрегации отвечают Spine-маршрутизаторы. Они соединяют между собой сетевые устройства уровня Brick, а также используются для подключения к другим Дата-центрам в рамках Зоны Доступности.
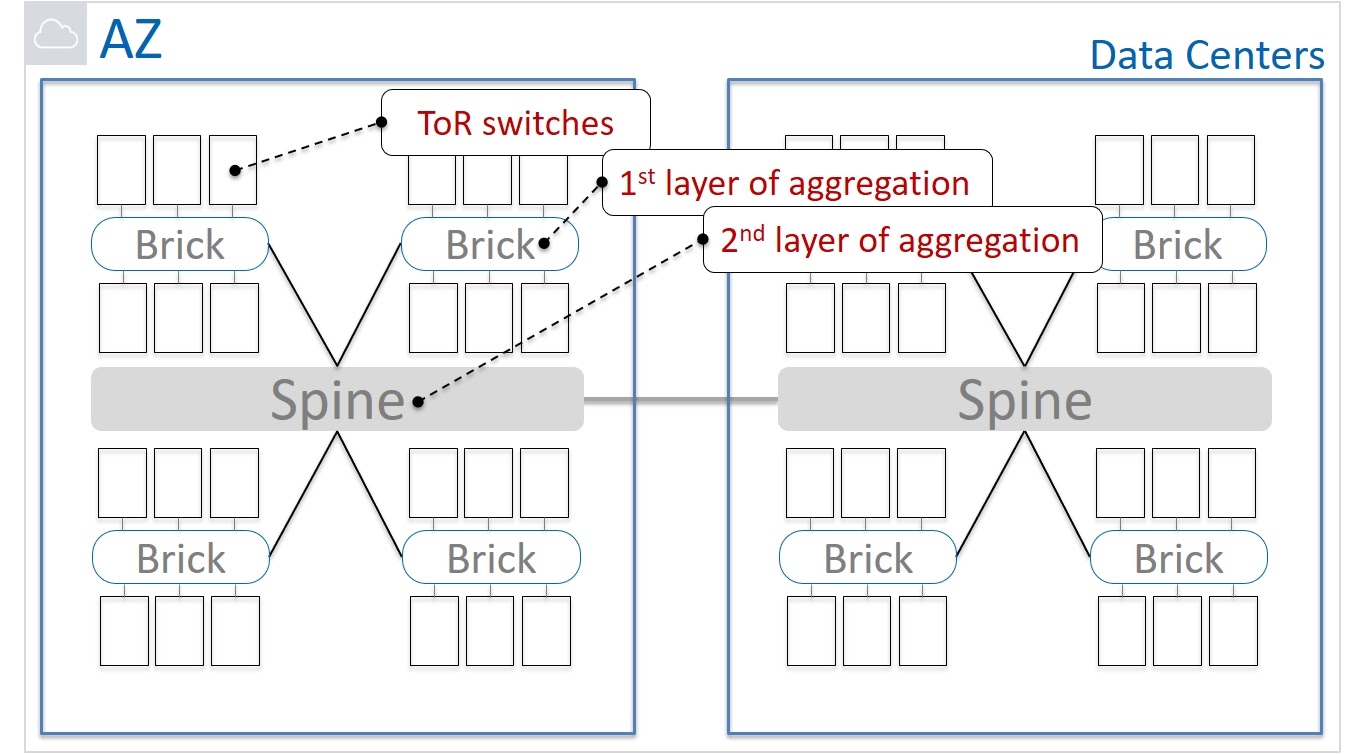
Как далеко могут друг от друга располагаться ноды одной ячейки? В рамках серверного шкафа? В одном Brick? Может в разных Дата-центрах?
С одной стороны, располагая ноды максимально близко, мы уменьшаем возможности разрыва связи между нодами. Зато увеличивается вероятность возникновения скоррелированных сбоев, которые затронут более половины нод в Paxos. С другой стороны, количество сетевых сегментов (hops) негативно влияет на устойчивость к разделению сети. Банально, больше элементов — выше вероятность, что в них что-то пойдет не так.
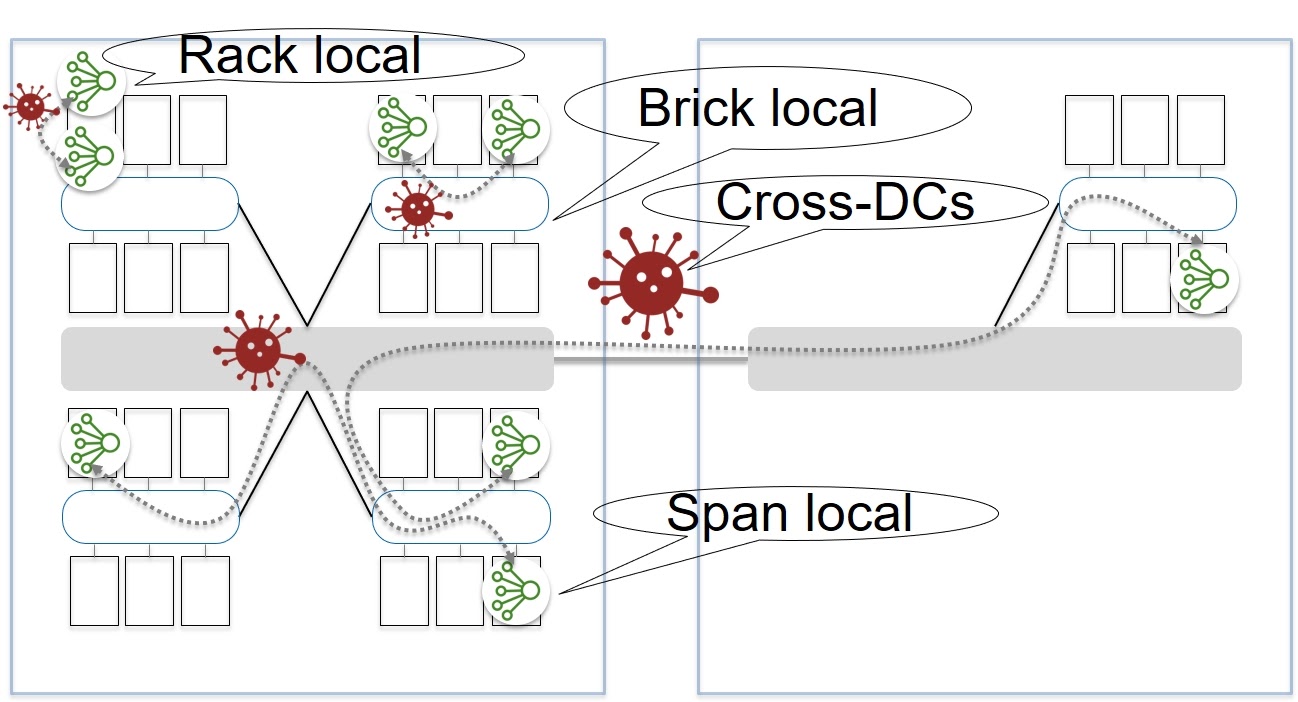
Мы решили, что оптимальным будет вариант, при котором ноды одной ячейки располагаются в рамках Brick. Тем самым, мы заложили в архитектуру не глобальную устойчивость к разделению сети, а Partition tolerance в рамках Brick. И в итоге мы можем говорить о CAP-балансе с учетом разумных ограничений Availability и Partition tolerance, определенных функциональностью самого сервиса EBS.
Шаг 3. Blast radius = Color in a Brick
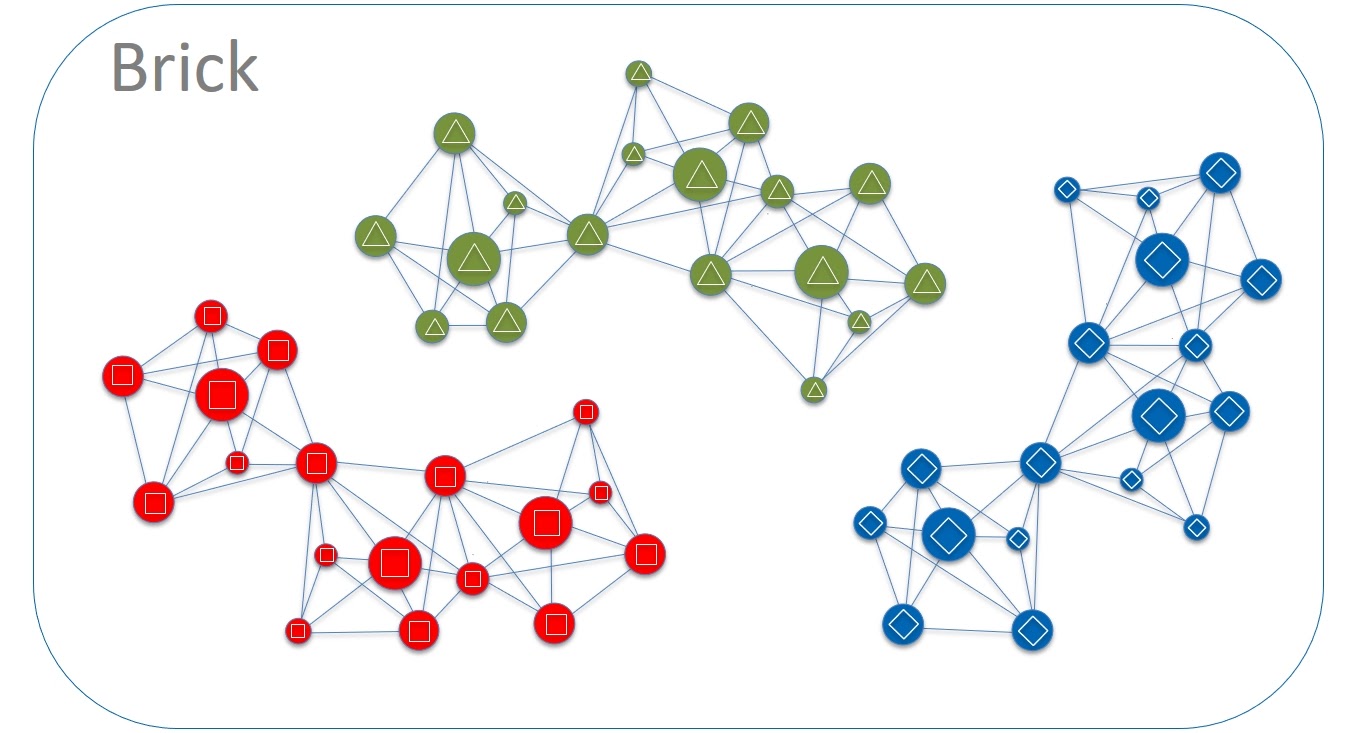
Мы стали ближе к идеалу, но все еще его не достигли. Давайте еще уменьшим blast radius нашей Primary/Replication базы данных. В рамках Brick на каждом сервере живут сотни нод разных ячеек, которые коммуницируют с тысячами других нод. Разделим серверы на группы и для простоты назовем их разными цветами — красный, зеленый, синий и т. д. Выбирать стоит небольшое количество цветов, скажем 4-6. И также определим два важных правила:
Ноды одной ячейки всегда выделяются в рамках того же цвета. Не бывает такого, что 4 ноды ячейки расположены на красных серверах и другие 3 — на зеленых.
Запрещено любое прямое взаимодействие между серверами различных цветов (Cross Colours Communication).
Такая изоляция позволит нам локализовать многие сбои. Например, потенциальные проблемы при обновлении кода. Апдейт всегда делается в рамках какого-то одного цвета, скажем, красного. Если обновление прошло хорошо, мы накатываем новое ПО на зеленые серверы. И так далее. Если проявляются какие-то баги, то они всегда изолируются в рамках ячеек, расположенных на серверах определенного цвета.
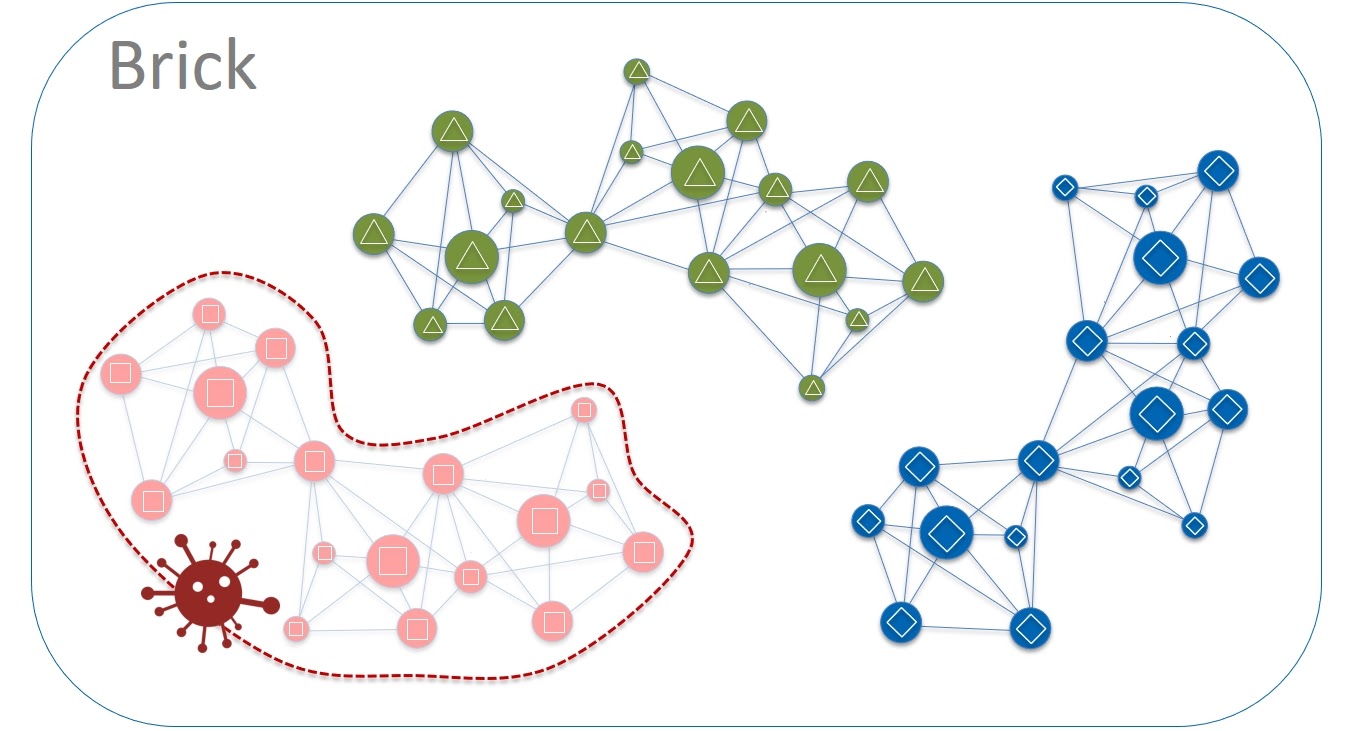
И вот теперь мы можем говорить, что наш blast radius равен одному цвету в группе серверных шкафов (Color in a Brick). Но систему можно улучшить и с другой стороны.
Шаг 4. Close placement = perfect latency
Сервисы виртуальных машин и хранения данных очень чувствительны к сетевым задержкам, которые, в свою очередь, зависят от физического и логического расстояния между элементами. Очевидно, чем ближе компоненты сервисов друг к другу, тем лучше.
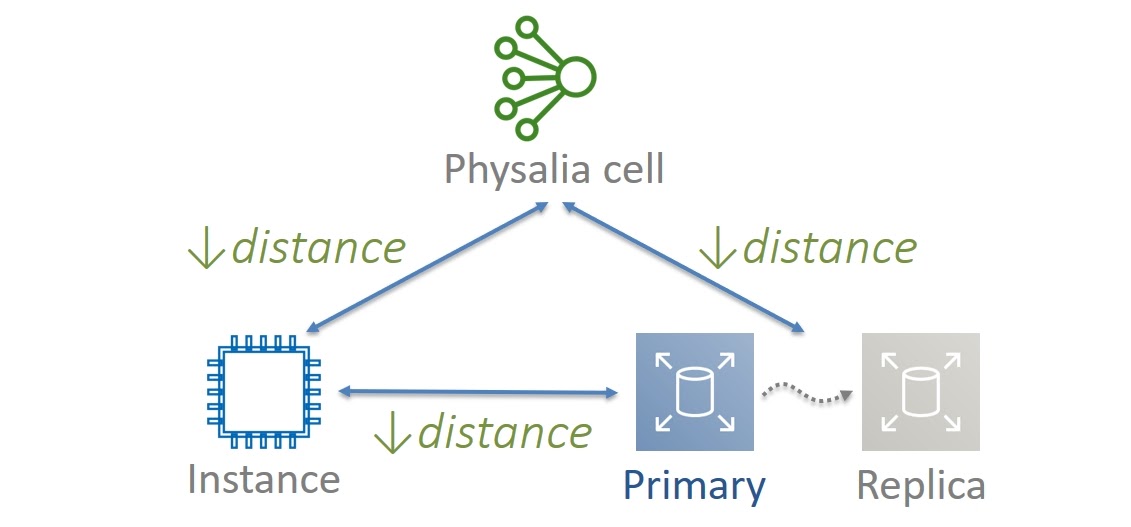
Для Physalia мы выбрали (и до сих пор его придерживаемся) принцип локальности. Виртуальная машина, копии данные Primary и Replica, а также ноды соответствующей ячейки Physalia мы стараемся расположить максимально близко друг к другу, т. е. на одних и тех же физических серверах. Обращаю внимание, именно пытаемся, так как есть разумные ограничения. Например, мы уже говорили, что для обеспечения отказоустойчивости, ноды Physalia должны обязательно быть на разных серверах. Replica тоже должна храниться отдельно от Primary данных. Но мы стараемся запустить виртуальную машину на том же сервере, где находится Primary данные и одна из нод Physalia.
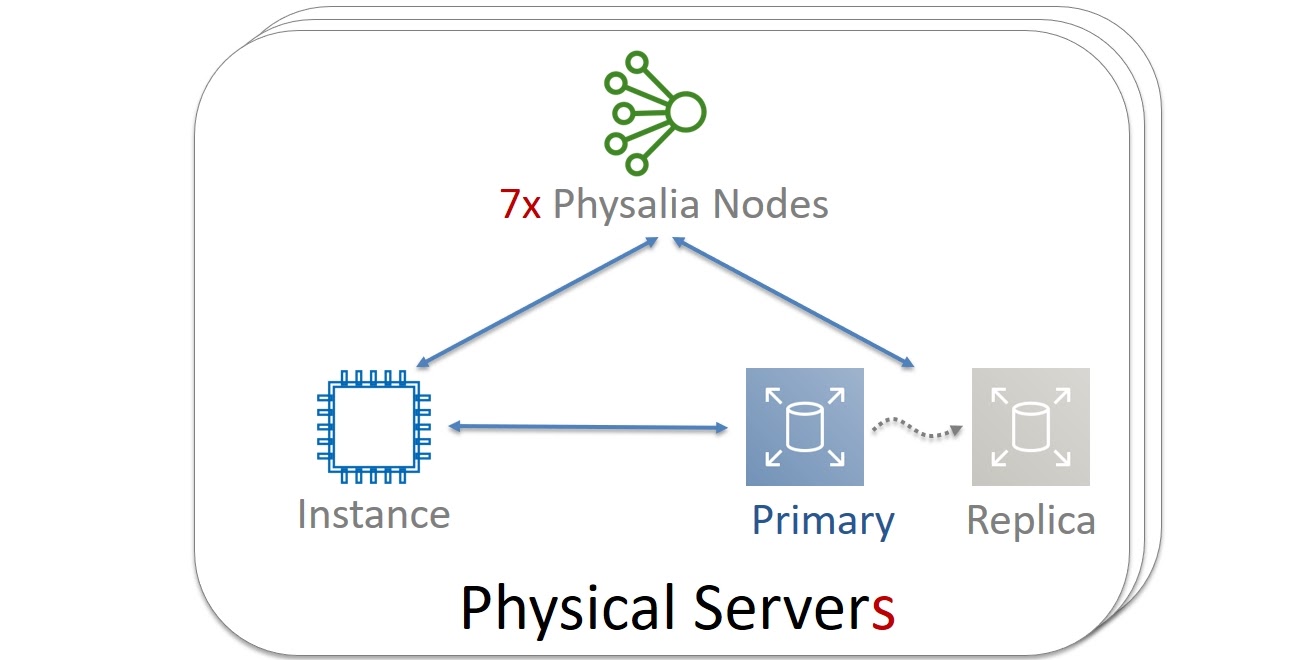
Другими словами, мы складываем яйца в максимально близкие корзинки. Это дает нам меньшие задержки, при этом, не ухудшая отказоустойчивости и надежности хранения (durability). Нет ничего страшного в том, что некоторые компоненты будут умирать вместе. Например, Primary-копия данных будет на короткое время недоступна вместе с виртуальной машиной и одной ячейкой Physalia. Пока восстанавливается виртуалка, мы воскресим остальных.
Чего мы этим в итоге добились? Предположим, мы запускаем новую виртуальную машину. В этом случае обновление данных в Primary/Replica базе данных проводится не более, чем за 60ms. Это само по себе неплохое значение, а учитывая, что под капотом на 7 нодах должен отработать Paxos, то вообще замечательное. Когда же мы, например, перезапускаем виртуальную машину и нужно уточнить данные тома, то чтение из базы данных происходит меньше, чем за 10ms.
Шаг 5. Разделяем Data Plane и Control Plane
В начале статьи мы обсудили, что любой сервис нужно строить таким образом, чтобы проблемы в Control Plane оказывали минимальное влияние на работоспособность Data Plane. Как мы это достигли в случае с Physalia? Вспомним, что мы уже знаем. Сервис хранения данных EBS имеет Control Plane изолированный на уровне каждой Зоны Доступности.
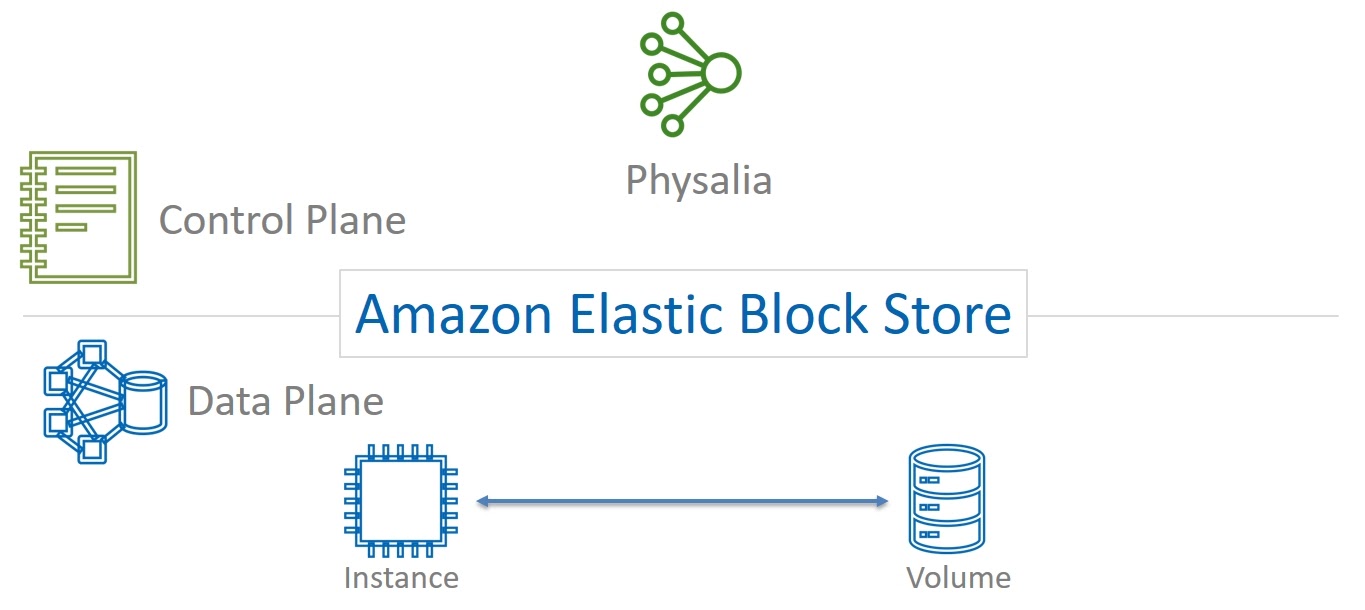
Physalia является частью Control Plane сервиса EBS. У нее, в свою очередь, тоже есть свой Data Plane и Control Plane. Data Plane — это колония ячеек, про нее мы уже говорили.
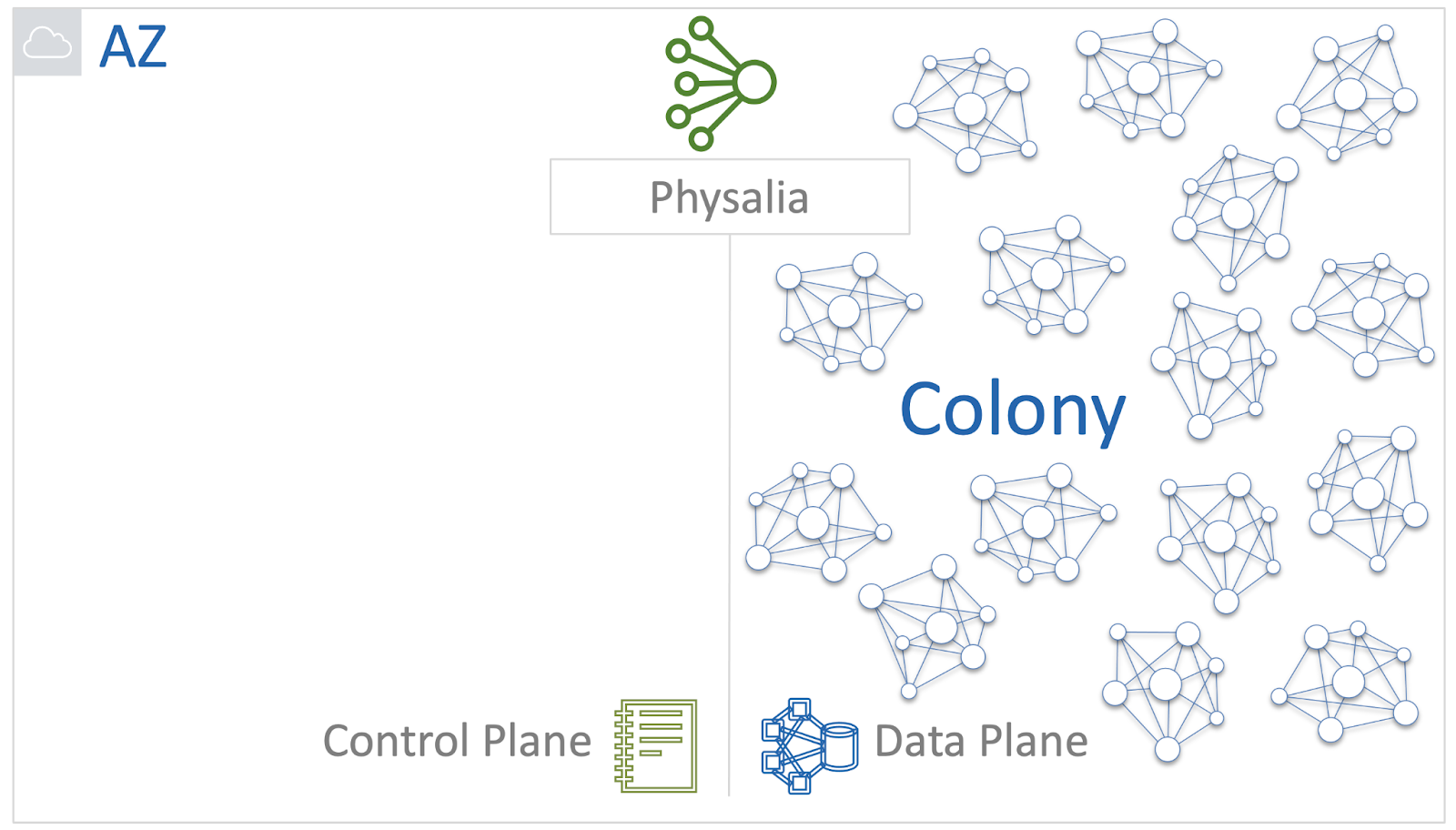
Control Plane баз данных Physalia — это набор внутренних сервисов которые отвечают за следующие функции:
Создавать и удалять ячейки;
Всегда знать, где находятся ячейки и соответствующие ноды;
Чинить, если что-то ломается.
В Physalia за это отвечают Lifecycle Manager, Discovery Cache и Health Tracker.
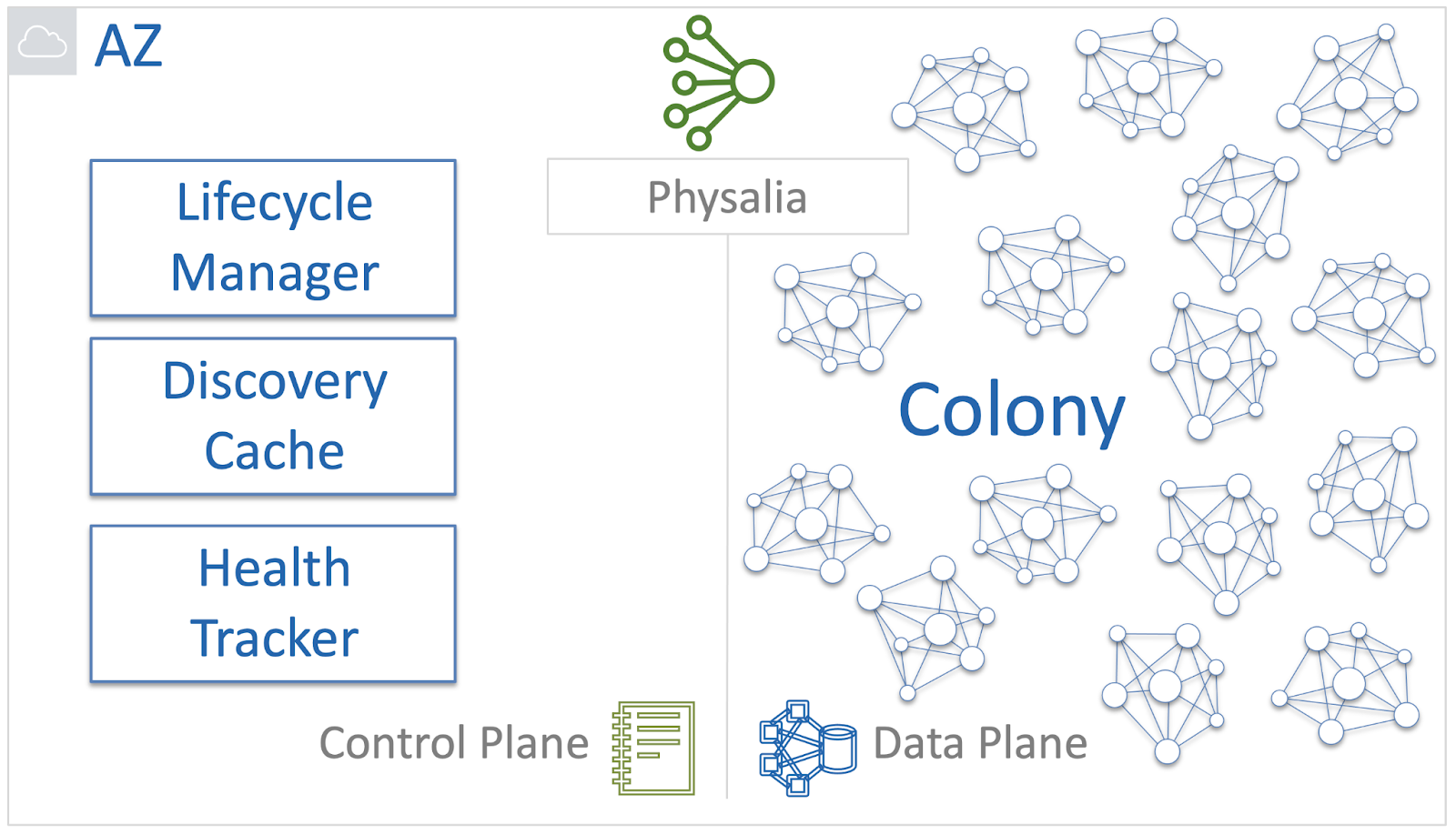
Когда нужен новый том данных, Lifecycle Manager создает Primary/Replica базу данных в виде ячейки Physalia. За удаление отвечает тоже он. Lifecycle Manager является авторитетным источником информации о состоянии ячеек. Его можно об этом спросить и полученная информация всегда считается правильной.

Что будет если Lifecycle Manager начнет сбоить?
Если проблемы не большие, Lifecycle Manager починит себя сам, это self healing система.
Если Lifecycle Manager упадет совсем, то ситуация тоже не будет смертельной. Все тома, которые уже работают, будут продолжать работать. Конечно на какой-то промежуток времени мы не сможем создавать и удалять тома. Но это короткое время, ведь Lifecycle Manager легковесный и восстанавливается очень быстро.
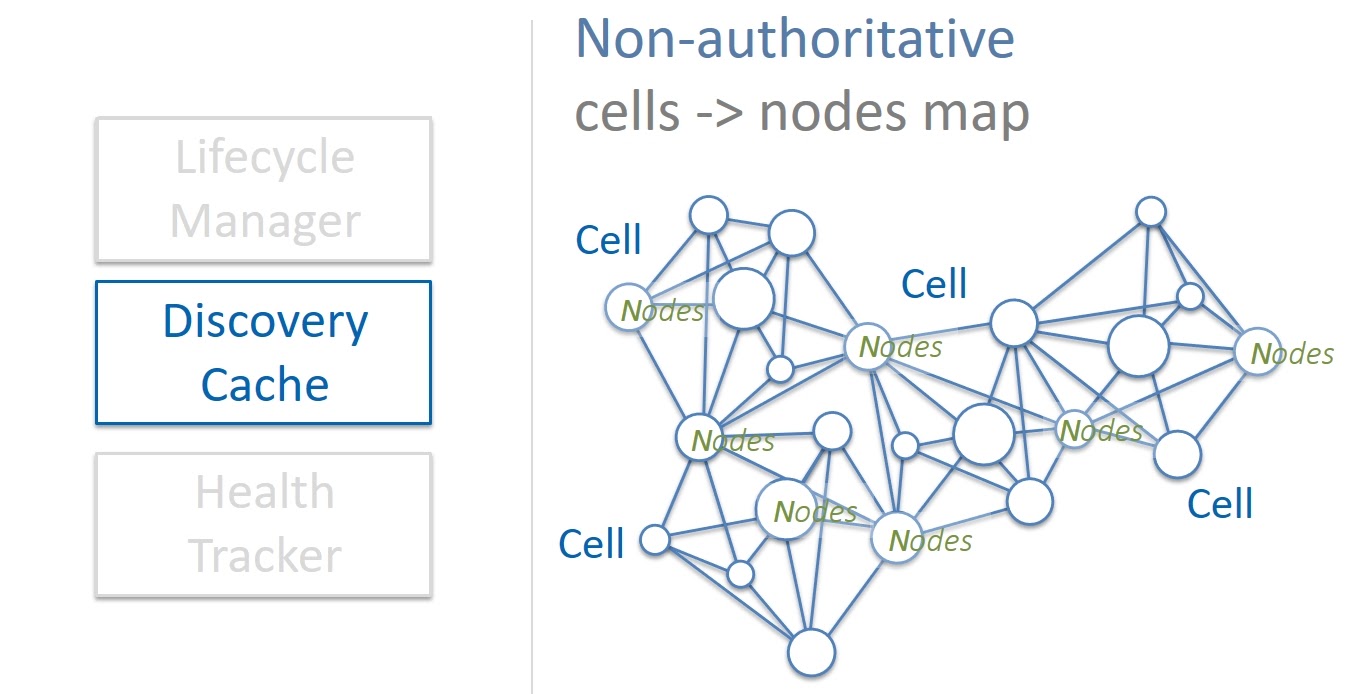
Discovery Cache — это кэш, который является источником информации о том, каким ячейкам соответствуют ноды и на каких серверах они расположены. Discovery Cache старается следить за этим маппингом, и большую часть времени он знает текущее состояние дел. Иногда, правда, бывает, что закэшированная информация устарела, либо по каким-то причинам неправильная. По этой причине Discovery Cache считается неавторитетным источником информации.
Но это не является проблемой. Во-первых, при изменении состояния, ячейки сами обновляют информацию в кэш. А во вторых, кэш сам периодически сканирует состояние всех ячеек в колонии и исправляет найденные несоответствия. Если происходит какой-то сбой, мы легко и быстро восстанавливаем данные в кэш. К тому же, ячейки Physalia очень маленькие по размеру и поэтому Discovery Cache требует небольших объемов памяти. Следовательно, мы запросто можем держать несколько копий кэш — если одна сломалась, то мы работаем с другой.
Health Tracker — это третий компонент, который отслеживает здоровье нод в ячейках. Physalia работает на Paxos из 7 нод. Поэтому ячейка остается работоспособной если живо большинство (majority) нод, т. е. четыре. Соответственно без влияния на целостность данных мы можем позволить себе выход из строя до трех нод.
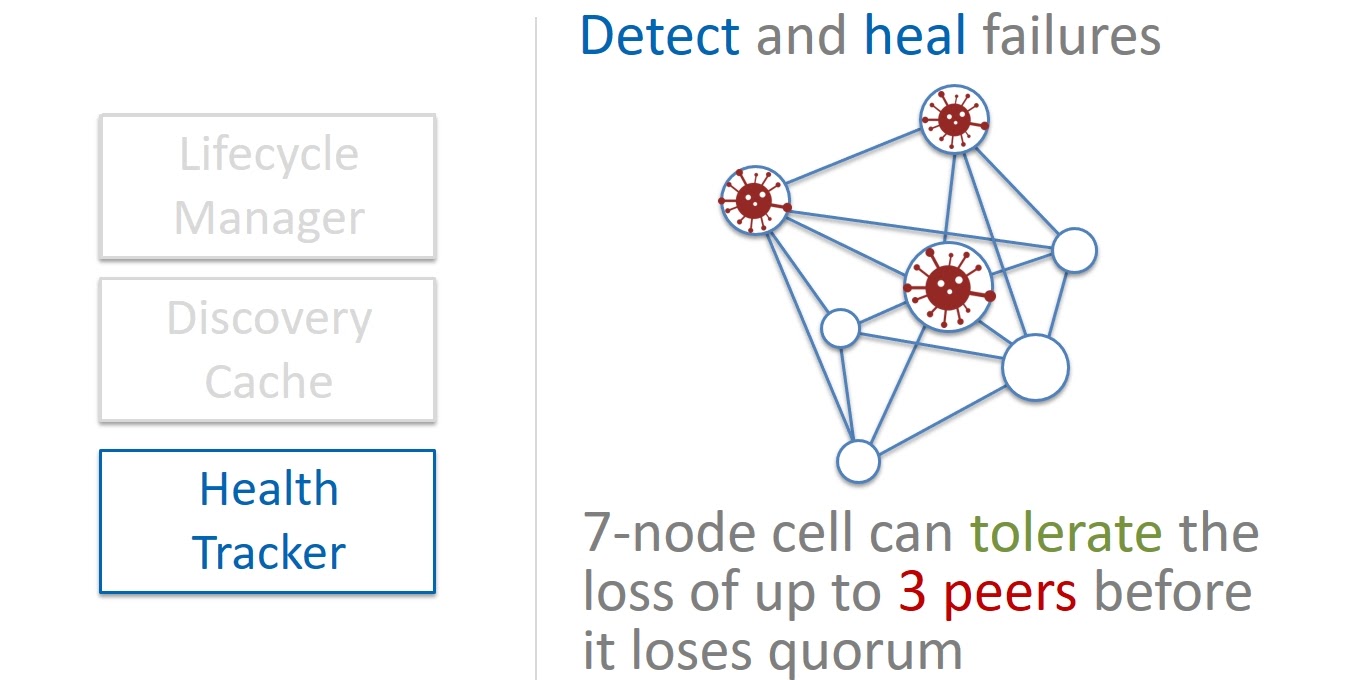
Мы придерживаемся сбалансированного подхода медленного восстановления (Slow Repair). С одной стороны, если какая-то нода перестанет отвечать и мы постараемся исправить ситуацию максимально быстро, то при массовых сбоях это потратит слишком большое количество наших ресурсов. А нехватка ресурсов, в свою очередь, может повлиять на саму возможность восстановления.
С другой стороны, доводить количество неисправных нод в ячейке до трех может быть опасным. Балансировать на грани неразумно. Поэтому когда перестает отвечать какая-то нода в ячейке, мы не сразу ее восстанавливаем, а ждем какое-то время, может она еще вернется. И только когда мы окончательно убеждаемся, что в ячейке уже две мертвые ноды, мы спешим делать замену.
Так мы построили архитектуру, в которой компоненты Lifecycle Manager, Discovery Cache и Health Tracker, т. е. Control Plane Physalia, слабо влияют на доступность и надежность самой колонии ячеек, нашей Data Plane.
Результаты
Внедрение Physalia принципиально повлияло на количество ошибок доступа к Primary/Replica DB. Это, в свою очередь, принципиально улучшило стабильность и отказоустойчивость работы всего сервиса хранения данных EBS.
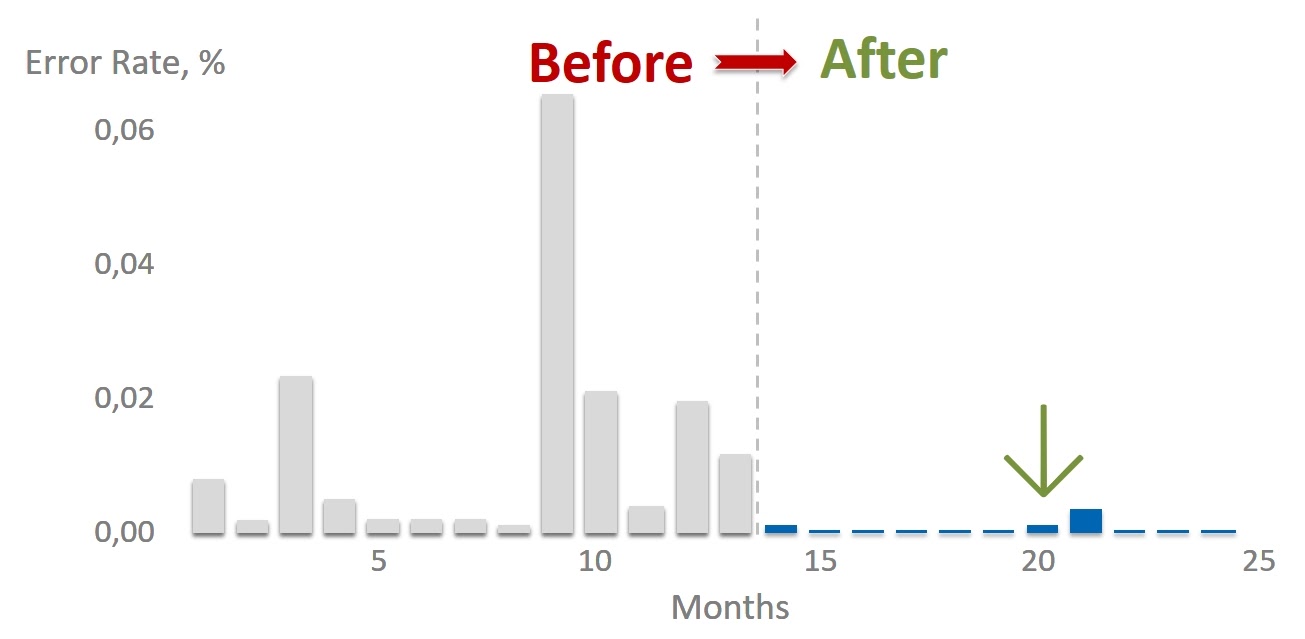
Конечно, построить систему, в которой сбоев вообще никогда не будет, невозможно. Всегда остаются ошибки людей, случаются незапланированные массовые отказы железа или коронавирус перегрыз провода. Поэтому в архитектуру своих систем мы закладываем постоянную готовность к неприятностям и возможность автоматического восстановления даже в случае экзотических и редких проблем.
В заключение, я хотел бы пожелать, чтобы в ваших системах поломок было мало, а ваши решения были стабильными и непотопляемыми by design. Как катамаран.

Конференция HighLoad++ Весна 2021 уже почти готова. 17 и 18 мая в Москве, в Крокус-экспо мы все встретимся и обсудим всё то, что невозможно было обсудить в наших чатиках. Расписание ждет вас, а в течение 2 дней концеренции будут 8 потоков выступлений, 6 мастер-класов даже пивная вечеринка.
Главный зал будет транслироваться все 2 дня бесплатно благодаря поддержке генерального партнёра — ECOMMPAY. Всего это 14 докладов. Присоединиться к этой трансляции вы можете после регистрации.
Билеты на конференцию можно купить здесь. А подписавшись на нашу рассылку, можно получить материалы мини-конференции Saint HighLoad++ 2020 :)
