
В 2010 году у компании Wargaming было 50 серверов и простая сетевая модель: бэкенд, фронтенд и файрвол. Количество серверов росло, модель усложнялась: стейджинги, изолированные VLAN с ACL, потом VPN с VRF, VLAN c ACL на L2, VRF с ACL на L3. Закружилась голова? Дальше будет веселее.
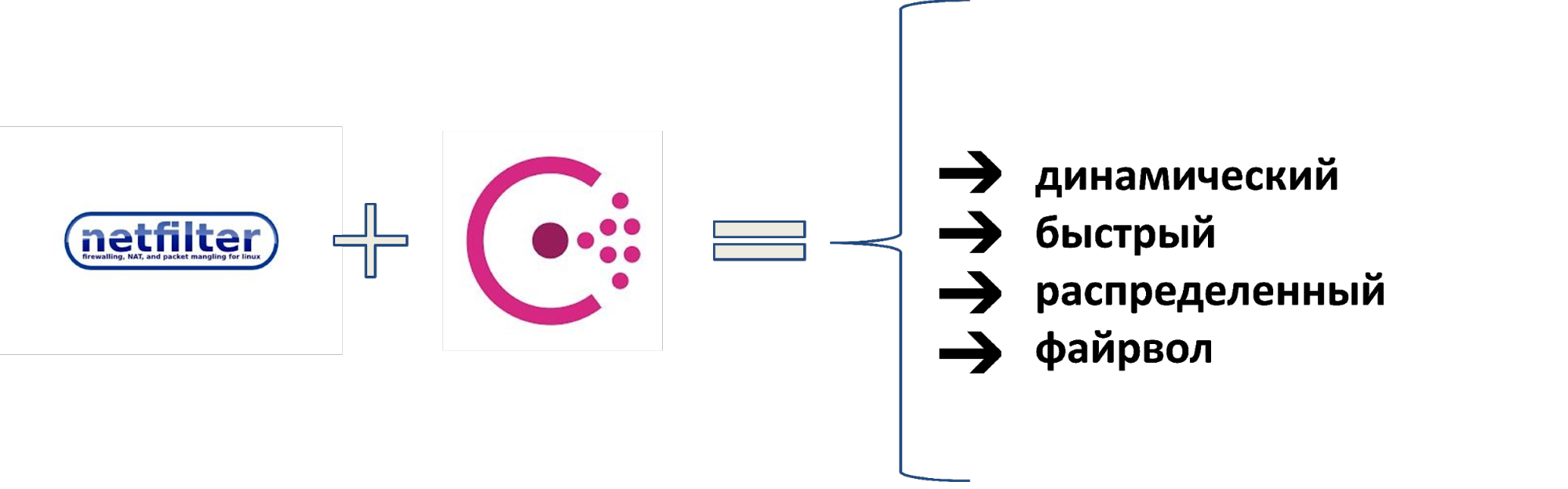
Когда серверов стало 16 000 работать без слез с таким количеством разнородных сегментов стало невозможно. Поэтому придумали другое решение. Взяли стек Netfilter, добавили к нему Consul как источник данных, получился быстрый распределенный файрвол. Им заменили ACL на роутерах и использовали как внешний и внутренний файрвол. Для динамического управления инструментом разработали систему BEFW, которую применили везде: от управления доступом пользователей в продуктовую сеть до изоляции сегментов сети друг от друга.
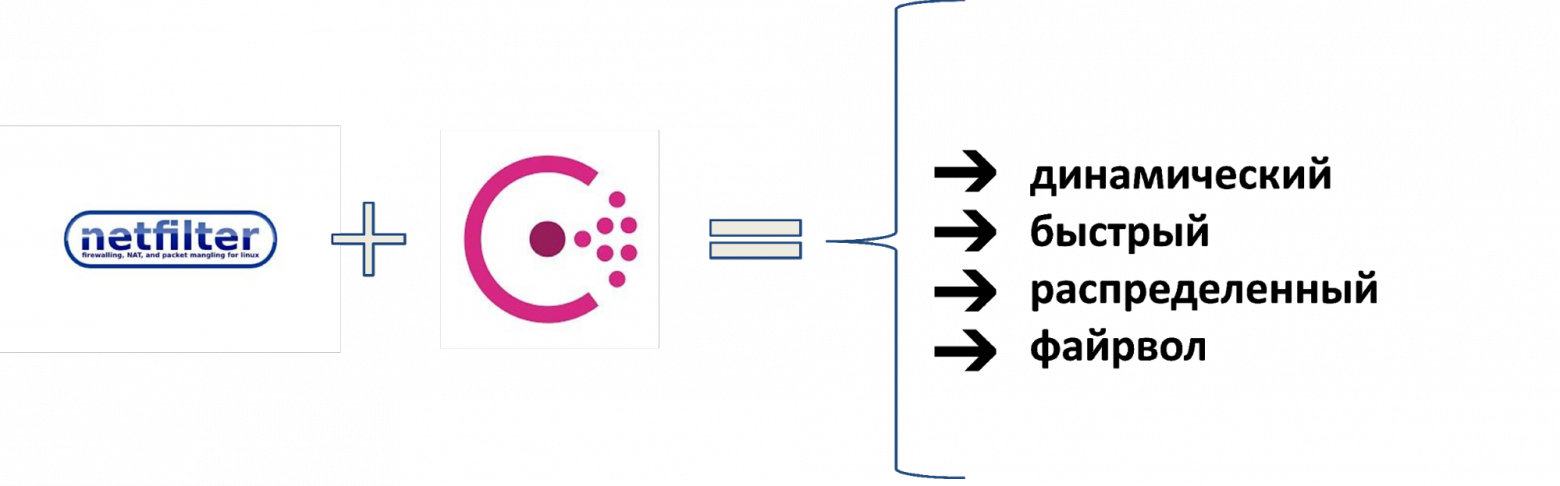
Как это все работает и почему вам стоит присмотреться к этой системе, расскажет Иван Агарков (annmuor) — руководитель группы инфраструктурной безопасности подразделения Maintenance в Минском центре разработки компании. Иван — фанат SELinux, любит Perl, пишет код. Как руководитель группы ИБ, регулярно работает с логами, бэкапами и R&D, чтобы защищать Wargaming от хакеров и обеспечивать работу всех игровых серверов в компании.
Прежде чем рассказать, как мы это делали, расскажу, как вообще к этому пришли и почему это понадобилось. Для этого перенесемся на 9 лет назад: 2010 год, только появились World of Tanks. У компании Wargaming было примерно 50 серверов.
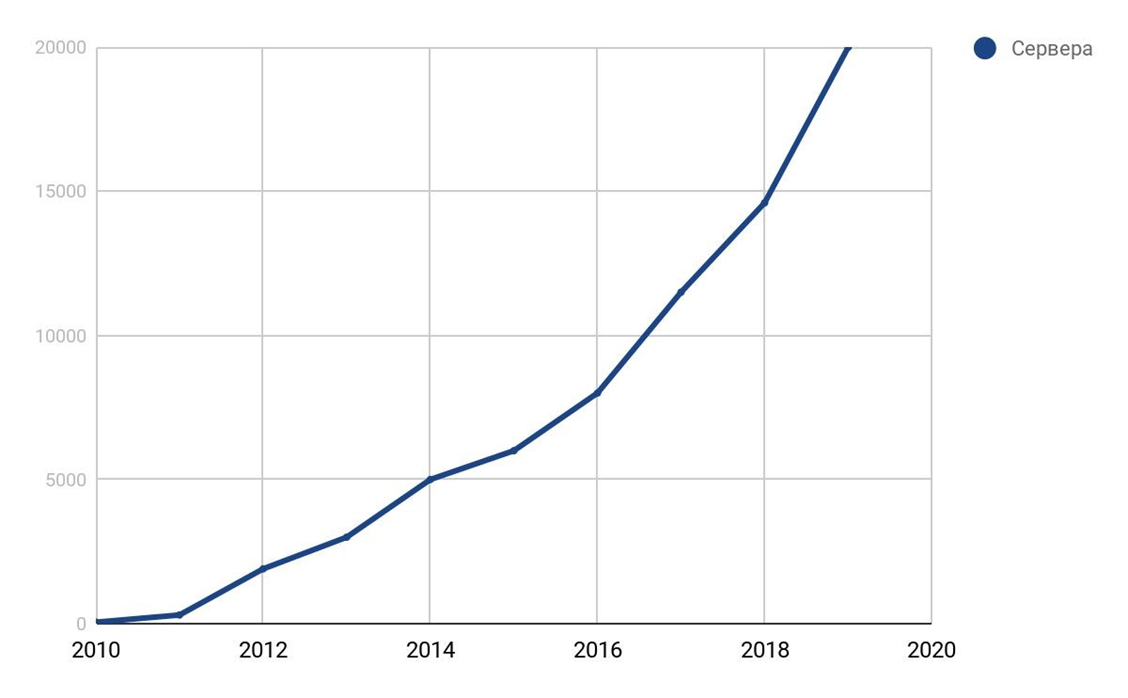
График роста серверов компании.
У нас была сетевая модель. Для того времени она была оптимальной.
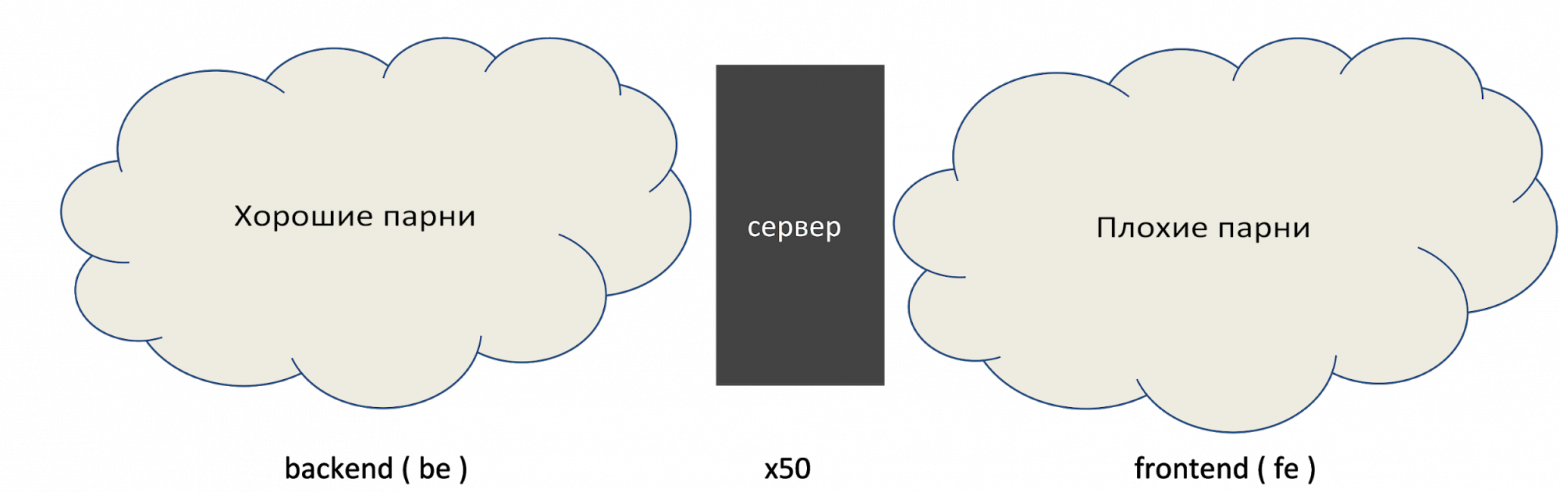
Сетевая модель в 2010.
На фронтенде живут плохие парни, которые хотят нас сломать, но в нем есть файрвол. На бэкенде файрвола нет, но там 50 серверов, мы их всех знаем. Все работает хорошо.
За 4 года парк серверов вырос в 100 раз, до 5000. Появились первые изолированные сети — стейджинги: они не могут ходить в продакшн, а там часто крутилось то, что могло быть опасным.
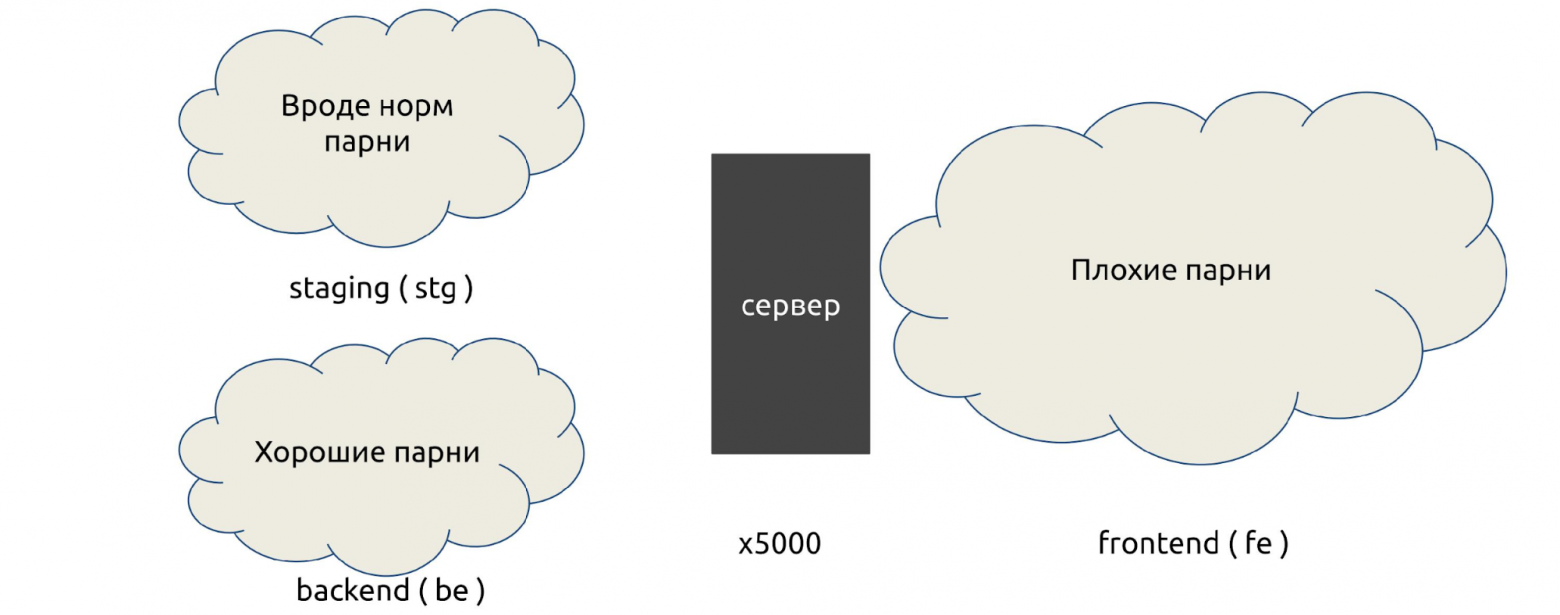
Сетевая модель в 2014.
По инерции использовали все те же железки, и вся работа велась на изолированных VLAN: к VLAN пишутся ACL, которые разрешают или запрещают какое-то соединение.
В 2016 количество серверов достигло 8000. Wargaming поглощал другие студии, появились дополнительные партнерские сети. Они вроде бы наши, но не совсем: для партнеров VLAN часто не работает, приходится использовать VPN с VRF, изоляции усложняются. Смесь изоляций ACL росла.

Сетевая модель в 2016.
К началу 2018 года парк машин вырос до 16 000. Сегментов было 6, а остальные мы не считали, в том числе закрытые, в которых хранились финансовые данные. Появились контейнерные сети (Kubernetes), DevOps, облачные сети, подключенные по VPN, например, из ИВС. Правил было очень много — было больно.

Сетевая модель и способы изоляции в 2018.
Для изоляции мы использовали: VLAN с ACL на L2, VRF с ACL на L3, VPN и много всего другого. Слишком много.
Все живут с ACL и VLAN. Что вообще не так? На это вопрос ответит Гарольд, скрывающий боль.

Проблем было много, но массовых — пять.
Так выглядел сетевой инженер в 2018 году, когда он слышал: «Нужно еще немного ACL».

В начале 2018 года было решено что-то с этим делать.
Цена интеграций непрерывно растет. Отправной точкой стало то, что крупные дата-центры перестали поддерживать изолированные VLAN и ACL, потому что кончилась память на устройствах.
Решение: убрали человеческий фактор и по максимуму автоматизировали предоставление доступа.
Новые правила применяются долго. Решение: ускорить применение правил, сделать его распределенным и параллельным. Для этого нужна распределенная система, чтобы правила доставлялись сами, без rsync или SFTP на тысячу систем.
Отсутствие файрвола внутри сегментов. Файрвол внутри сегментов стал к нам прилетать, когда в рамках одной сети появлялись разные сервисы. Решение: использовать файрвол на уровне хоста — host-based firewalls. Практически везде у нас Linux, и везде есть iptables, это не проблема.
Сложности с аудитом правил. Решение: хранить все правила в едином месте для обзора и управления, так мы сможем все аудировать.
Низкий уровень контроля за инфраструктурой. Решение: провести инвентаризацию всех сервисов и доступов между ними.
Это больше административный процесс, чем технический. Иногда у нас бывает 200-300 новых релизов в неделю, особенно во время акций и в праздники. При этом это только для одной команды наших DevOps. С таким количеством релизов невозможно увидеть понять какие нужны порты, IP, интеграции. Поэтому нам понадобились специально обученные сервис-менеджеры, которые опрашивали команды: «Что вообще есть и зачем вы это подняли?»
После всего, что мы запустили, сетевой инженер в 2019 году стал выглядеть уже так.

Мы решили, что все, что мы нашли при помощи сервис-менеджеров, поместим в Consul и оттуда будем писать правила iptables.
Как мы решили это делать?
Consul это не удаленный API, он может работать на каждом узле и писать в iptables. Остается только придумать автоматические средства контроля, которые будут вычищать лишнее, и большая часть проблем будет решена! Остальное доработаем в процессе.
Хорошо себя зарекомендовал. В 2014-15 годах мы его использовали как бэкенд для Vault, в котором храним пароли.
Не теряет данные. За время использования Consul не терял данные ни при одной аварии. Это огромный плюс для системы управления файрволом.
P2P-связи ускоряют распространение изменений. С P2P все изменения приходят быстро, не нужно ждать часами.
Удобный REST API. Мы рассматривали также Apache ZooKeeper, но у него нет REST API, придется ставить костыли.
Работает как хранилище ключей (KV), так и как каталог (Service Discovery). Можно хранить сразу сервисы, каталоги, дата-центры. Это удобно не только нам, но и соседним командам, потому что строя глобальный сервис, мы думаем масштабно.
Написан на Go, который входит в стек Wargaming. Мы любим этот язык, у нас много Go-разработчиков.
Мощная система ACL. В Consul с помощью ACL можно управлять тем, кому и что писать. Мы гарантируем, что правила файрвола не будут пересекаться больше ни с чем и у нас не будет с этим проблем.
Но у Consul есть и недостатки.
Большую часть этих проблем мы решили во время эксплуатации Consul, поэтому его и выбрали. В компании есть планы об альтернативном бэкенде, но мы научились бороться с проблемами и пока живем с Consul.
В условный дата-центр установим серверы — от трех до пяти. Один или два сервера не подойдет: они не смогут организовать кворум и решить, кто прав, кто виноват, когда данные не совпадают. Больше пяти нет смысла, производительность упадет.

К серверам в любом порядке подключаются клиенты: те же агенты, только с флагом

После этого клиенты получают список P2P-соединений и строят между собой связи.

На глобальном уровне мы соединяем между собой несколько дата-центров. Они также соединяются P2P и общаются.
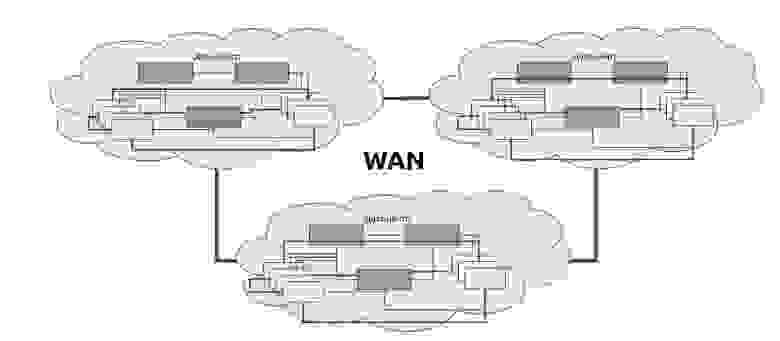
Когда мы хотим забрать данные от другого дата-центра, запрос идет от сервера к серверу. Такая схема называется протоколом Serf. Протокол Serf, как и Consul, разработка HashiCorp.
У Consul есть документация с описанием его работы. Я приведу только выборочные факты, которые стоит знать.
Consul-серверы выбирают мастера из числа голосующих. Consul выбирает мастера из списка серверов для каждого дата-центра, и все запросы идут только к нему, вне зависимости от количества серверов. Зависание мастера не приводит к перевыборам. Если мастер не выбран — запросы никем не обслуживаются.
Consul не копирует данные между дата-центрами. При сборе федерации у каждого сервера будут только свои данные. За другими он всегда обращается к кому-то другому.
Атомарность операций не гарантируется вне транзакции. Помните, что изменять что-то можете не только вы. Если хотите по-другому, проводите транзакцию с блокировкой.
Блокирующие операции не гарантируют блокировку. Запрос идет от мастера к мастеру, а не напрямую, поэтому нет гарантий, что блокировка сработает когда вы делаете блокировку, например, в другом дата-центре.
ACL тоже не гарантирует доступа (во многих случаях). ACL может не сработать, потому что хранится в одном дата-центре федерации — в ACL дата-центре (Primary DC). Если ДЦ вам не ответит, ACL работать не будет.
Один зависший мастер приведет к зависанию всей федерацию. Например, в федерации 10 дата-центров, а в одном плохая сеть, и один мастер падает. Все, кто с ним общается, зависнут по кругу: идет запрос, на него нет ответа, тред подвисает. Не получится узнать когда это произойдет, просто через час или два упадет вся федерация. Вы ничего не сможете с этим сделать.
Статус, кворум и выборы обрабатываются отдельным потоком. Перевыбора не произойдет, статус ничего не покажет. Вы думаете, что у вас живой Consul, запрашиваете, и ничего не происходит — ответа нет. При этом статус показывает, что все хорошо.
Мы сталкивались с этой проблемой, нам приходилось перестраивать конкретные части дата-центров, чтобы ее избежать.
В бизнес-версии Consul Enterprise нет некоторых недостатков выше. В нем много полезных функций: выбор голосующих, распределение, масштабирование. Есть только одно «но» — система лицензирования для распределенной системы стоит очень дорого.
Лайфхак:
Теперь поговорим о том, что мы добавили к Consul.
BEFW — это акроним от BackEndFireWall. Надо было как-то назвать продукт, когда я создавал репозиторий, чтобы в него положить первые тестовые коммиты. Такое название и осталось.
Правила написаны в синтаксисе iptables.
У нас все уходит в цепочку BEFW, кроме
Чем полезен BEFW?
У нас есть сервис, в нем всегда есть порт, нода, на которой он работает. Со своей ноды мы можем локально спросить агента и узнать, что у нас есть какой-то сервис. Также можно ставить тэги.

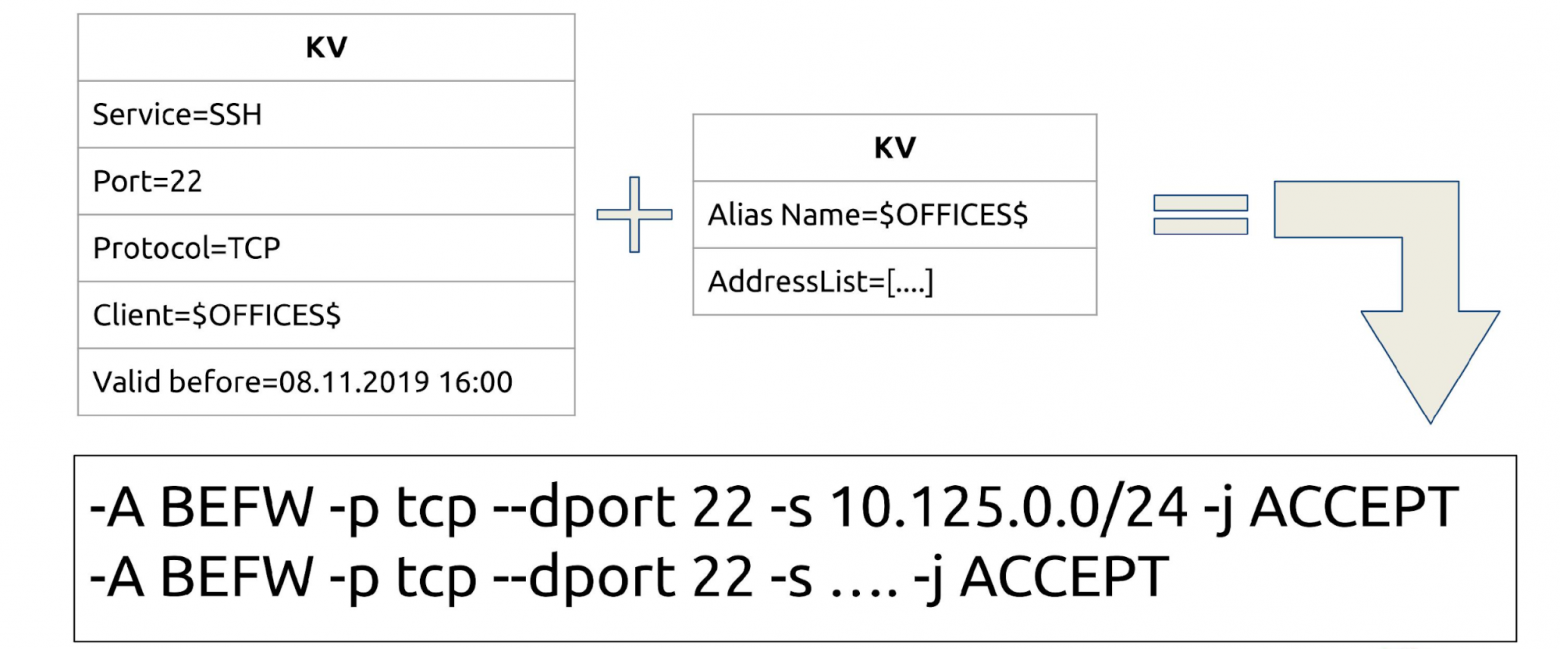
Любой сервис, который запущен и зарегистрирован в Consul, превращается в правило iptables. У нас есть SSH — открываем порт 22. Bash-скрипт простой: curl и iptables, больше ничего не нужно.
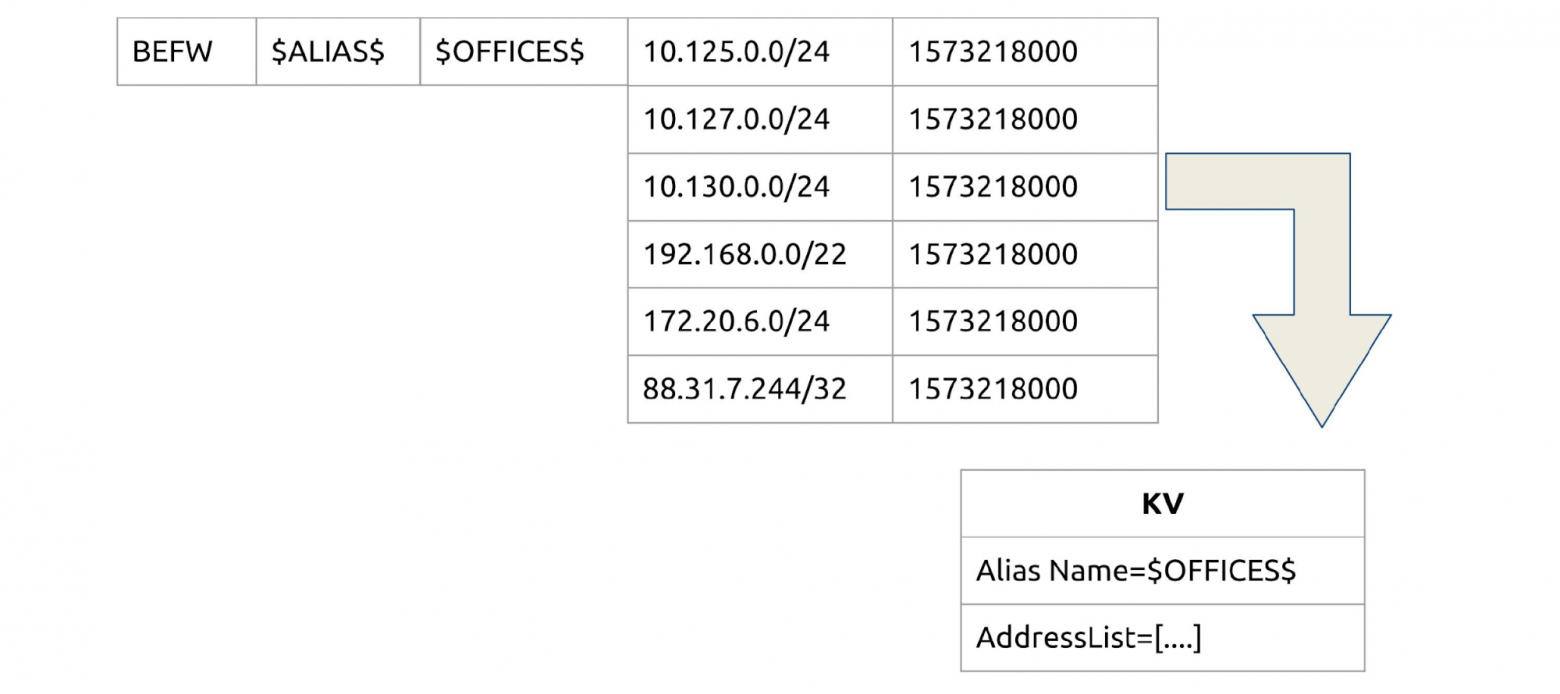
Как открывать доступ не всем, а выборочно? По имени сервиса складывать в KV-хранилище IP-списки.

Например, мы хотим, чтобы все из десятой сети могли обращаться к сервису SSH_TCP_22. Добавляем одно маленькое поле TTL? и теперь у нас есть временные разрешения, например, на сутки.
Соединяем сервисы и клиентов: у нас есть сервис, на каждый готово KV-хранилище. Теперь мы даем доступ не всем, а выборочно.

Если каждый раз будем писать тысячи IP для доступов, то устанем. Придумаем группировки — отдельный subset в KV. Назовем его Alias (или группы) и будем хранить там группы по тому же принципу.
Соединяем: теперь можем открыть SSH не конкретно на P2P, а на целую группу или несколько групп. Точно также есть TTL — можно добавлять в группу и удалять из группы временно.
Наша проблема — человеческий фактор и автоматизация. Пока мы решили ее так.

Мы работаем с Puppet, и переносим им все, что относится к системе (код приложений). В puppetdb (обычный PostgreSQL) хранится список сервисов, которые там запущены, их можно найти по типу ресурса. Там же можно найти, кто куда обращается. Также у нас есть система pull request и merge request для этого.
Мы написали befw-sync — простейшее решение, которое помогает переносить данные. Сначала sync cookies обращаются в puppetdb. Там настроен HTTP API: запрашиваем какие у нас есть сервисы, что нужно сделать. Потом делают запрос в Consul.
Интеграция есть? Есть: написали правила, разрешили принимать Pull Request. Нужен какой-то порт или добавить хост в какую-то группу? Pull Request, ревью — больше никаких «Найди 200 других ACL и попробуй что-нибудь с этим сделать».
Пинг localhost с пустой цепочкой правил занимает 0,075 мс.

Добавим в эту цепочку 10 000 адресов iptables. В результате пинг увеличится в 5 раз: iptables полностью линейный, обработка каждого адреса занимает какое-то время.

Для файрвола, в который мы мигрируем тысячи ACL, у нас много правил, и это вносит задержку. Для игровых протоколов это плохо.
Но если мы поместим 10 000 адресов в ipset пинг даже уменьшится.

Смысл в том, что «O» (сложность алгоритма) для ipset всегда равно 1, сколько бы там правил не было. Правда, там есть ограничение — правил не может быть больше 65535. Пока с этим живем: можно их комбинировать, расширять, делать два ipset в одном.
Логичное продолжение процесса итераций — хранение информации о клиентах для сервиса в ipset.

Теперь у нас есть тот же самый SSH, и мы не пишем сразу 100 IP, а задаем имя ipset, с которым надо пообщаться, и следующее правило
Теперь у нас есть правила и сеты. Главная задача — сделать сет до того, как написать правило, потому что иначе iptables не запишет правило.
В виде схемы все, что я рассказал, выглядит так.

Коммитим в Puppet, всё отправляется на хост, сервисы здесь, ipset там, а кто там не прописан, того не пускают.
Чтобы быстро спасать мир или быстро кого-то отключать, в начале всех цепочек мы сделали два ipset:
Например, кто-то ботами создает нагрузку на наш Web. Раньше нужно было найти по логам его IP, отнести сетевым инженерам, чтобы они нашли источник трафика и его забанили. Сейчас это выглядит иначе.

Отправляем в Consul, ждем 2,5 с, и готово. Поскольку Consul за счет P2P быстро распределяет, то работает везде, в любой части мира.
Однажды я как-то полностью остановил WOT, ошибившись с файрволом.
Можно добавлять любые другие сеты в пространстве

Зачем? Иногда кому-то нужны ipset, например, чтобы эмулировать отключение какой-то части кластера. Каждый может принести любые сеты, их назвать и они будут забираться из Consul. При этом сеты могут как участвовать в правилах iptables, так и быть как бы командой
Раньше было так: пользователь подключался к сети и через домен получал параметры. До появления файрволов нового поколения Cisco не умела понимать, где пользователь, а где IP. Поэтому доступ выдавался только через hostname-машины.
Что сделали мы? Вклинились в момент получения адреса. Обычно это dot1x, Wi-Fi или VPN — все идет через RADIUS. Для каждого пользователя создаем группу по имени пользователя и помещаем в нее IP с TTL, который равен его dhcp.lease — как только он истечет, правило исчезнет.
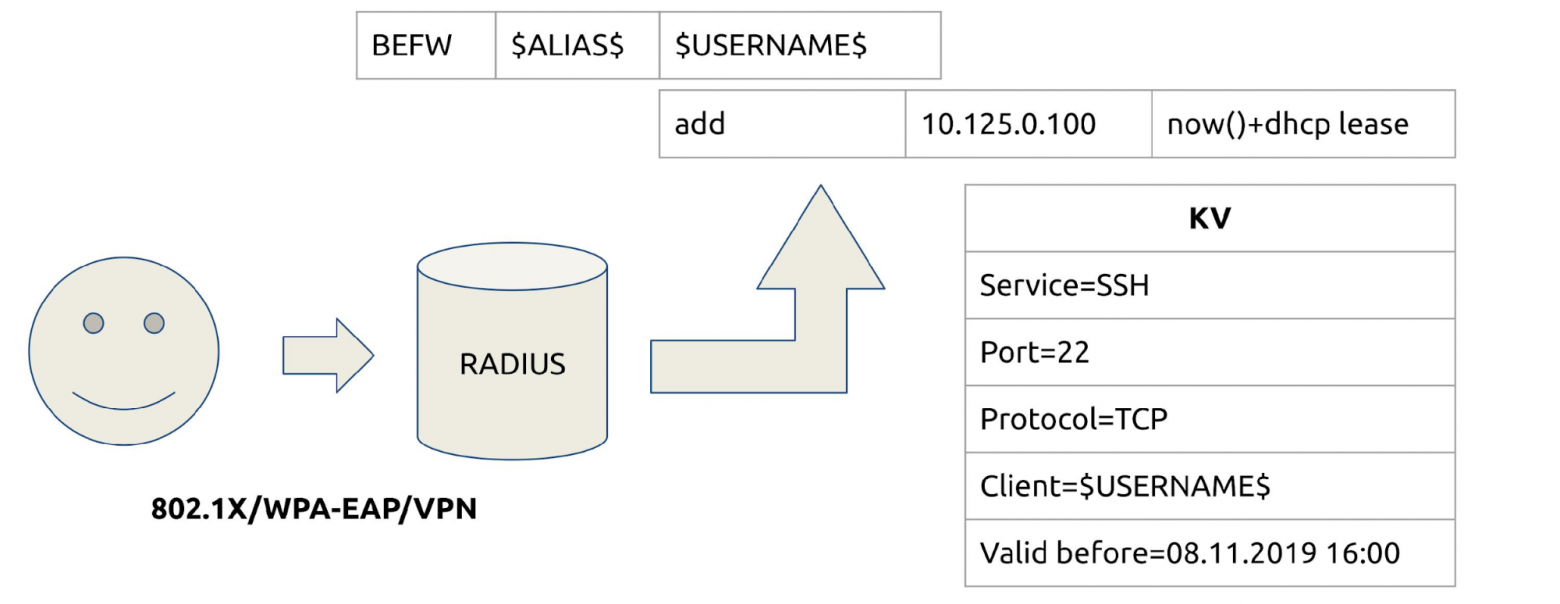
Теперь мы можем открывать доступ к сервисам, как и в другие группы, по username. Мы избавились от боли с hostname, когда они меняются, и сняли нагрузку с сетевых инженеров, потому что им больше не нужно Cisco. Теперь инженеры сами прописывают доступы на своих серверах.
Параллельно мы начали разбирать изоляцию. Сервис-менеджеры сделали инвентаризацию, а мы проанализировали все наши сети. Разложим их на такие же группы, а на нужных серверах группы добавили, например, в deny. Теперь та же самая изоляция стэйджинга попадает в rules_deny у продакшн, но не в сам продакшн.

Схема работает быстро и просто: снимаем все ACL с серверов, разгружаем железки, снижаем количество изолированных VLAN.
Раньше у нас работал специальный триггер, который сообщал, когда кто-то менял руками правило файрвола. Я писал огромный линтер проверки правил файрвола, это было сложно. Сейчас целостность контролирует BEFW. Он ревностно следит чтобы правила, которые он делает, не менялись. Если кто-то поменяет правила файрвола, он вернет все обратно. «Я тут быстро поднял прокси, чтобы из дома работать» — таких вариантов больше нет.
BEFW контролирует ipset из сервисов и списка в befw.conf, правила сервисов в цепочке BEFW. Но не следит за другими цепочками и правилами и другими ipset.
BEFW всегда сохраняет последнее удачное состояние прямо в бинарной структуре state.bin. Если что-то пошло не так, он всегда откатывается назад на этот state.bin.

Это страховка от нестабильной работы Consul, когда он не отправил данные или кто-то ошибся и использовал правила, которые не могут быть применены. Чтобы мы не остались без файрвола, BEFW откатится на последнее состояние, если на каком-то этапе произойдет ошибка.
В критических ситуациях это гарантия, что мы останемся с рабочим файрволом. Мы открываем все серые сети в надежде, что админ придет и починит. Когда-нибудь я это вынесу в конфиги, но сейчас у нас просто три серых сети: 10/8, 172/12 и 192.168/16. В рамках нашего Consul это важная особенность, которая помогает развиваться дальше.
Демо: во время доклада Иван демонстрирует демо-режим работы BEFW. Демонстрацию удобнее смотреть на видео. Исходный код демо доступен на GitHub.
Расскажу о багах, с которыми мы столкнулись.
ipset add set 0.0.0.0/0. Что случится, если добавить в ipset 0.0.0.0/0? Добавятся все IP? Откроется доступ в интернет?
Нет, мы получим баг, который стоил нам двух часов простоя. Причем баг не работает с 2016 года, лежит в RedHat Bugzilla под номером #1297092, а нашли мы его случайно — из отчета разработчика.
Теперь в BEFW стоит жесткое правило, что
ipset restore set < file. Что делает ipset, когда вы говорите ему
Ничего подобного — он делает merge, и старые адреса никуда не деваются, доступ вы не закрываете.
Баг мы нашли, когда тестировали изоляцию. Теперь там довольно сложная система — вместо
consul kv get -datacenter=other. Как я уже говорил, мы думаем, что запрашиваем какие-то данные, но получим либо данные, либо ошибку. Мы можем это делать через Consul локально, но и в этом случае зависнет и то, и другое.
Локальный Consul-клиент это обертка над HTTP API. Но он просто виснет и не отвечает ни на Ctrl+C, ни на Ctrl+Z, ни на что, только на
Consul leader не отвечает. У нас не отвечает мастер в дата-центре, мы думаем: «Наверное, сейчас сработает алгоритм перевыбора?»
Нет, не сработает, и мониторинг ничего не покажет: Consul скажет, что commitment index есть, лидер найден, все хорошо.
Как мы с этим боремся?
В итоге мы получили следующие преимущества:
Минусы: Consul, с которым нам теперь жить, и очень высокая цена ошибки. Как пример, один раз я в 6 вечера (прайм по России) что-то правил в списках сетей. Мы как раз тогда строили изоляцию на BEFW. Я где-то ошибся, кажется, указал не ту маску, но все упало за две секунды. Загорается мониторинг, прибегает дежурный поддержки: «У нас все лежит!» Начальник департамента поседел, когда объяснял бизнесу почему так произошло.
Цена ошибки так высока, что мы придумали собственную сложную процедуру профилактики. Если вы будете это внедрять на большом продакшн, не надо давать мастер-токен над Consul всем подряд. Это плохо закончится.
Стоимость. Я писал код 400 часов в одиночку. На поддержку моя команда из 4 человек тратит 10 часов в месяц на всех. По сравнению с ценой любого файрвола нового поколения, это бесплатно.
Планы. Долгосрочный план — это поиск альтернативного транспорта взамен или дополнительно к Consul. Возможно, это будет Kafka или что-то подобное. Но в ближайшие годы мы будем жить на Consul.
Ближайшие планы: интеграция с Fail2ban, с мониторингом, с nftables, возможно, с другими дистрибутивами, метрики, расширенный мониторинг, оптимизация. Поддержка Kubernetes тоже где-то в планах, потому что сейчас у нас есть несколько кластеров и желание.
Еще из планов:
Постоянно мы работаем над расширением конфигурации, увеличением метрик и оптимизацией.
Присоединяйтесь к проекту. Проект получился крутым, но, к сожалению, это пока проект одного человека. Приходите на GitHub и попробуйте что-то сделать: закоммитить, потестировать, что-то предложить, дать свою оценку.
Когда серверов стало 16 000 работать без слез с таким количеством разнородных сегментов стало невозможно. Поэтому придумали другое решение. Взяли стек Netfilter, добавили к нему Consul как источник данных, получился быстрый распределенный файрвол. Им заменили ACL на роутерах и использовали как внешний и внутренний файрвол. Для динамического управления инструментом разработали систему BEFW, которую применили везде: от управления доступом пользователей в продуктовую сеть до изоляции сегментов сети друг от друга.
Как это все работает и почему вам стоит присмотреться к этой системе, расскажет Иван Агарков (annmuor) — руководитель группы инфраструктурной безопасности подразделения Maintenance в Минском центре разработки компании. Иван — фанат SELinux, любит Perl, пишет код. Как руководитель группы ИБ, регулярно работает с логами, бэкапами и R&D, чтобы защищать Wargaming от хакеров и обеспечивать работу всех игровых серверов в компании.
Историческая справка
Прежде чем рассказать, как мы это делали, расскажу, как вообще к этому пришли и почему это понадобилось. Для этого перенесемся на 9 лет назад: 2010 год, только появились World of Tanks. У компании Wargaming было примерно 50 серверов.

График роста серверов компании.
У нас была сетевая модель. Для того времени она была оптимальной.

Сетевая модель в 2010.
На фронтенде живут плохие парни, которые хотят нас сломать, но в нем есть файрвол. На бэкенде файрвола нет, но там 50 серверов, мы их всех знаем. Все работает хорошо.
За 4 года парк серверов вырос в 100 раз, до 5000. Появились первые изолированные сети — стейджинги: они не могут ходить в продакшн, а там часто крутилось то, что могло быть опасным.

Сетевая модель в 2014.
По инерции использовали все те же железки, и вся работа велась на изолированных VLAN: к VLAN пишутся ACL, которые разрешают или запрещают какое-то соединение.
В 2016 количество серверов достигло 8000. Wargaming поглощал другие студии, появились дополнительные партнерские сети. Они вроде бы наши, но не совсем: для партнеров VLAN часто не работает, приходится использовать VPN с VRF, изоляции усложняются. Смесь изоляций ACL росла.

Сетевая модель в 2016.
К началу 2018 года парк машин вырос до 16 000. Сегментов было 6, а остальные мы не считали, в том числе закрытые, в которых хранились финансовые данные. Появились контейнерные сети (Kubernetes), DevOps, облачные сети, подключенные по VPN, например, из ИВС. Правил было очень много — было больно.

Сетевая модель и способы изоляции в 2018.
Для изоляции мы использовали: VLAN с ACL на L2, VRF с ACL на L3, VPN и много всего другого. Слишком много.
Проблемы
Все живут с ACL и VLAN. Что вообще не так? На это вопрос ответит Гарольд, скрывающий боль.

Проблем было много, но массовых — пять.
- Геометрический рост цены для новых правил. Каждое новое правило добавлялось дольше, чем предыдущее, потому что надо было сначала посмотреть нет ли уже такого правила.
- Нет файрвола внутри сегментов. Сегменты друг от друга как-то отделили, внутри уже ресурсов не хватает.
- Правила применялись долго. Руками одно локальное правило операторы могли написать за час. Глобальное занимало несколько дней.
- Сложности с аудитом правил. Точнее, он был не возможен. Первые правила писались еще в 2010 году, и большая часть их авторов уже не работала в компании.
- Низкий уровень контроля за инфраструктурой. Это главная проблема — мы плохо знали, что у нас вообще происходит.
Так выглядел сетевой инженер в 2018 году, когда он слышал: «Нужно еще немного ACL».

Решения
В начале 2018 года было решено что-то с этим делать.
Цена интеграций непрерывно растет. Отправной точкой стало то, что крупные дата-центры перестали поддерживать изолированные VLAN и ACL, потому что кончилась память на устройствах.
Решение: убрали человеческий фактор и по максимуму автоматизировали предоставление доступа.
Новые правила применяются долго. Решение: ускорить применение правил, сделать его распределенным и параллельным. Для этого нужна распределенная система, чтобы правила доставлялись сами, без rsync или SFTP на тысячу систем.
Отсутствие файрвола внутри сегментов. Файрвол внутри сегментов стал к нам прилетать, когда в рамках одной сети появлялись разные сервисы. Решение: использовать файрвол на уровне хоста — host-based firewalls. Практически везде у нас Linux, и везде есть iptables, это не проблема.
Сложности с аудитом правил. Решение: хранить все правила в едином месте для обзора и управления, так мы сможем все аудировать.
Низкий уровень контроля за инфраструктурой. Решение: провести инвентаризацию всех сервисов и доступов между ними.
Это больше административный процесс, чем технический. Иногда у нас бывает 200-300 новых релизов в неделю, особенно во время акций и в праздники. При этом это только для одной команды наших DevOps. С таким количеством релизов невозможно увидеть понять какие нужны порты, IP, интеграции. Поэтому нам понадобились специально обученные сервис-менеджеры, которые опрашивали команды: «Что вообще есть и зачем вы это подняли?»
После всего, что мы запустили, сетевой инженер в 2019 году стал выглядеть уже так.

Consul
Мы решили, что все, что мы нашли при помощи сервис-менеджеров, поместим в Consul и оттуда будем писать правила iptables.
Как мы решили это делать?
- Соберем все сервисы, сети и пользователей.
- Сделаем на их основе правила iptables.
- Автоматизируем контроль.
- ….
- PROFIT.
Consul это не удаленный API, он может работать на каждом узле и писать в iptables. Остается только придумать автоматические средства контроля, которые будут вычищать лишнее, и большая часть проблем будет решена! Остальное доработаем в процессе.
Почему Consul?
Хорошо себя зарекомендовал. В 2014-15 годах мы его использовали как бэкенд для Vault, в котором храним пароли.
Не теряет данные. За время использования Consul не терял данные ни при одной аварии. Это огромный плюс для системы управления файрволом.
P2P-связи ускоряют распространение изменений. С P2P все изменения приходят быстро, не нужно ждать часами.
Удобный REST API. Мы рассматривали также Apache ZooKeeper, но у него нет REST API, придется ставить костыли.
Работает как хранилище ключей (KV), так и как каталог (Service Discovery). Можно хранить сразу сервисы, каталоги, дата-центры. Это удобно не только нам, но и соседним командам, потому что строя глобальный сервис, мы думаем масштабно.
Написан на Go, который входит в стек Wargaming. Мы любим этот язык, у нас много Go-разработчиков.
Мощная система ACL. В Consul с помощью ACL можно управлять тем, кому и что писать. Мы гарантируем, что правила файрвола не будут пересекаться больше ни с чем и у нас не будет с этим проблем.
Но у Consul есть и недостатки.
- Не масштабируется в рамках дата-центра, если у вас не бизнес-версия. Он масштабируется только федерацией.
- Очень зависим от качества сети и загрузки серверов. Consul не будет нормально работать в роли сервера на загруженном сервере, если в сети какие-то лаги, например, неровная скорость. Связано это с P2P-соединениями и моделями распространения обновлений.
- Сложности с мониторингом доступности. В статусе Consul может говорить, что все хорошо, а он уже давно умер.
Большую часть этих проблем мы решили во время эксплуатации Consul, поэтому его и выбрали. В компании есть планы об альтернативном бэкенде, но мы научились бороться с проблемами и пока живем с Consul.
Как работает Consul
В условный дата-центр установим серверы — от трех до пяти. Один или два сервера не подойдет: они не смогут организовать кворум и решить, кто прав, кто виноват, когда данные не совпадают. Больше пяти нет смысла, производительность упадет.

К серверам в любом порядке подключаются клиенты: те же агенты, только с флагом
server = false.
После этого клиенты получают список P2P-соединений и строят между собой связи.

На глобальном уровне мы соединяем между собой несколько дата-центров. Они также соединяются P2P и общаются.

Когда мы хотим забрать данные от другого дата-центра, запрос идет от сервера к серверу. Такая схема называется протоколом Serf. Протокол Serf, как и Consul, разработка HashiCorp.
Несколько важных фактов о Consul
У Consul есть документация с описанием его работы. Я приведу только выборочные факты, которые стоит знать.
Consul-серверы выбирают мастера из числа голосующих. Consul выбирает мастера из списка серверов для каждого дата-центра, и все запросы идут только к нему, вне зависимости от количества серверов. Зависание мастера не приводит к перевыборам. Если мастер не выбран — запросы никем не обслуживаются.
Вы хотели горизонтальное масштабирование? Извините, нет.Запрос в другой дата-центр идет от мастера к мастеру, независимо от того, на какой сервер он пришел. Выбранный мастер получает 100% нагрузки, кроме нагрузки на форвард запросов. Актуальная копия данных есть у всех серверов дата-центра, но отвечает только один.
Единственный способ масштабироваться — включить stale-режим на клиенте.В stale-режиме можно отвечать без кворума. Это режим, в котором мы отказываемся от консистентности данных, но читаем чуть быстрее, чем обычно, и отвечает любой сервер. Естественно, запись только через мастер.
Consul не копирует данные между дата-центрами. При сборе федерации у каждого сервера будут только свои данные. За другими он всегда обращается к кому-то другому.
Атомарность операций не гарантируется вне транзакции. Помните, что изменять что-то можете не только вы. Если хотите по-другому, проводите транзакцию с блокировкой.
Блокирующие операции не гарантируют блокировку. Запрос идет от мастера к мастеру, а не напрямую, поэтому нет гарантий, что блокировка сработает когда вы делаете блокировку, например, в другом дата-центре.
ACL тоже не гарантирует доступа (во многих случаях). ACL может не сработать, потому что хранится в одном дата-центре федерации — в ACL дата-центре (Primary DC). Если ДЦ вам не ответит, ACL работать не будет.
Один зависший мастер приведет к зависанию всей федерацию. Например, в федерации 10 дата-центров, а в одном плохая сеть, и один мастер падает. Все, кто с ним общается, зависнут по кругу: идет запрос, на него нет ответа, тред подвисает. Не получится узнать когда это произойдет, просто через час или два упадет вся федерация. Вы ничего не сможете с этим сделать.
Статус, кворум и выборы обрабатываются отдельным потоком. Перевыбора не произойдет, статус ничего не покажет. Вы думаете, что у вас живой Consul, запрашиваете, и ничего не происходит — ответа нет. При этом статус показывает, что все хорошо.
Мы сталкивались с этой проблемой, нам приходилось перестраивать конкретные части дата-центров, чтобы ее избежать.
В бизнес-версии Consul Enterprise нет некоторых недостатков выше. В нем много полезных функций: выбор голосующих, распределение, масштабирование. Есть только одно «но» — система лицензирования для распределенной системы стоит очень дорого.
Лайфхак:
rm -rf /var/lib/consul — лекарство от всех болезней агента. Если у вас что-то не работает, просто удалите свои данные и загрузите данные с копии. Скорее всего, Consul заработает.BEFW
Теперь поговорим о том, что мы добавили к Consul.
BEFW — это акроним от BackEndFireWall. Надо было как-то назвать продукт, когда я создавал репозиторий, чтобы в него положить первые тестовые коммиты. Такое название и осталось.
Шаблоны правил
Правила написаны в синтаксисе iptables.
- -N BEFW
- -P INPUT DROP
- -A INPUT -m state—state RELATED,ESTABLISHED -j ACCEPT
- -A INPUT -i lo -j ACCEPT
- -A INPUT -j BEFW
У нас все уходит в цепочку BEFW, кроме
ESTABLISHED, RELATED и localhost. Шаблон может быть любым, это просто пример.Чем полезен BEFW?
Сервисы
У нас есть сервис, в нем всегда есть порт, нода, на которой он работает. Со своей ноды мы можем локально спросить агента и узнать, что у нас есть какой-то сервис. Также можно ставить тэги.

Любой сервис, который запущен и зарегистрирован в Consul, превращается в правило iptables. У нас есть SSH — открываем порт 22. Bash-скрипт простой: curl и iptables, больше ничего не нужно.
Клиенты
Как открывать доступ не всем, а выборочно? По имени сервиса складывать в KV-хранилище IP-списки.

Например, мы хотим, чтобы все из десятой сети могли обращаться к сервису SSH_TCP_22. Добавляем одно маленькое поле TTL? и теперь у нас есть временные разрешения, например, на сутки.
Доступы
Соединяем сервисы и клиентов: у нас есть сервис, на каждый готово KV-хранилище. Теперь мы даем доступ не всем, а выборочно.

Группы
Если каждый раз будем писать тысячи IP для доступов, то устанем. Придумаем группировки — отдельный subset в KV. Назовем его Alias (или группы) и будем хранить там группы по тому же принципу.

Соединяем: теперь можем открыть SSH не конкретно на P2P, а на целую группу или несколько групп. Точно также есть TTL — можно добавлять в группу и удалять из группы временно.

Интеграция
Наша проблема — человеческий фактор и автоматизация. Пока мы решили ее так.

Мы работаем с Puppet, и переносим им все, что относится к системе (код приложений). В puppetdb (обычный PostgreSQL) хранится список сервисов, которые там запущены, их можно найти по типу ресурса. Там же можно найти, кто куда обращается. Также у нас есть система pull request и merge request для этого.
Мы написали befw-sync — простейшее решение, которое помогает переносить данные. Сначала sync cookies обращаются в puppetdb. Там настроен HTTP API: запрашиваем какие у нас есть сервисы, что нужно сделать. Потом делают запрос в Consul.
Интеграция есть? Есть: написали правила, разрешили принимать Pull Request. Нужен какой-то порт или добавить хост в какую-то группу? Pull Request, ревью — больше никаких «Найди 200 других ACL и попробуй что-нибудь с этим сделать».
Оптимизация
Пинг localhost с пустой цепочкой правил занимает 0,075 мс.

Добавим в эту цепочку 10 000 адресов iptables. В результате пинг увеличится в 5 раз: iptables полностью линейный, обработка каждого адреса занимает какое-то время.

Для файрвола, в который мы мигрируем тысячи ACL, у нас много правил, и это вносит задержку. Для игровых протоколов это плохо.
Но если мы поместим 10 000 адресов в ipset пинг даже уменьшится.

Смысл в том, что «O» (сложность алгоритма) для ipset всегда равно 1, сколько бы там правил не было. Правда, там есть ограничение — правил не может быть больше 65535. Пока с этим живем: можно их комбинировать, расширять, делать два ipset в одном.
Хранение
Логичное продолжение процесса итераций — хранение информации о клиентах для сервиса в ipset.

Теперь у нас есть тот же самый SSH, и мы не пишем сразу 100 IP, а задаем имя ipset, с которым надо пообщаться, и следующее правило
DROP. Можно переделать в одно правило «Кто не тут, тот DROP», но так наглядней.Теперь у нас есть правила и сеты. Главная задача — сделать сет до того, как написать правило, потому что иначе iptables не запишет правило.
Общая схема
В виде схемы все, что я рассказал, выглядит так.

Коммитим в Puppet, всё отправляется на хост, сервисы здесь, ipset там, а кто там не прописан, того не пускают.
Allow & deny
Чтобы быстро спасать мир или быстро кого-то отключать, в начале всех цепочек мы сделали два ipset:
rules_allow и rules_deny. Как это работает?Например, кто-то ботами создает нагрузку на наш Web. Раньше нужно было найти по логам его IP, отнести сетевым инженерам, чтобы они нашли источник трафика и его забанили. Сейчас это выглядит иначе.

Отправляем в Consul, ждем 2,5 с, и готово. Поскольку Consul за счет P2P быстро распределяет, то работает везде, в любой части мира.
Однажды я как-то полностью остановил WOT, ошибившись с файрволом.
rules_allow — это наша страховка от таких случаев. Если мы где-то ошиблись с файрволом, что-то где-то заблокируется, мы всегда можем отправить условный 0.0/0, чтобы быстро все поднять. Уже потом мы все починим руками.Другие сеты
Можно добавлять любые другие сеты в пространстве
$IPSETS$.
Зачем? Иногда кому-то нужны ipset, например, чтобы эмулировать отключение какой-то части кластера. Каждый может принести любые сеты, их назвать и они будут забираться из Consul. При этом сеты могут как участвовать в правилах iptables, так и быть как бы командой
NOOP: консистентность будет поддерживаться демоном.Пользователи
Раньше было так: пользователь подключался к сети и через домен получал параметры. До появления файрволов нового поколения Cisco не умела понимать, где пользователь, а где IP. Поэтому доступ выдавался только через hostname-машины.
Что сделали мы? Вклинились в момент получения адреса. Обычно это dot1x, Wi-Fi или VPN — все идет через RADIUS. Для каждого пользователя создаем группу по имени пользователя и помещаем в нее IP с TTL, который равен его dhcp.lease — как только он истечет, правило исчезнет.

Теперь мы можем открывать доступ к сервисам, как и в другие группы, по username. Мы избавились от боли с hostname, когда они меняются, и сняли нагрузку с сетевых инженеров, потому что им больше не нужно Cisco. Теперь инженеры сами прописывают доступы на своих серверах.
Изоляция
Параллельно мы начали разбирать изоляцию. Сервис-менеджеры сделали инвентаризацию, а мы проанализировали все наши сети. Разложим их на такие же группы, а на нужных серверах группы добавили, например, в deny. Теперь та же самая изоляция стэйджинга попадает в rules_deny у продакшн, но не в сам продакшн.

Схема работает быстро и просто: снимаем все ACL с серверов, разгружаем железки, снижаем количество изолированных VLAN.
Контроль целостности
Раньше у нас работал специальный триггер, который сообщал, когда кто-то менял руками правило файрвола. Я писал огромный линтер проверки правил файрвола, это было сложно. Сейчас целостность контролирует BEFW. Он ревностно следит чтобы правила, которые он делает, не менялись. Если кто-то поменяет правила файрвола, он вернет все обратно. «Я тут быстро поднял прокси, чтобы из дома работать» — таких вариантов больше нет.
BEFW контролирует ipset из сервисов и списка в befw.conf, правила сервисов в цепочке BEFW. Но не следит за другими цепочками и правилами и другими ipset.
Защита от аварий
BEFW всегда сохраняет последнее удачное состояние прямо в бинарной структуре state.bin. Если что-то пошло не так, он всегда откатывается назад на этот state.bin.

Это страховка от нестабильной работы Consul, когда он не отправил данные или кто-то ошибся и использовал правила, которые не могут быть применены. Чтобы мы не остались без файрвола, BEFW откатится на последнее состояние, если на каком-то этапе произойдет ошибка.
В критических ситуациях это гарантия, что мы останемся с рабочим файрволом. Мы открываем все серые сети в надежде, что админ придет и починит. Когда-нибудь я это вынесу в конфиги, но сейчас у нас просто три серых сети: 10/8, 172/12 и 192.168/16. В рамках нашего Consul это важная особенность, которая помогает развиваться дальше.
Демо: во время доклада Иван демонстрирует демо-режим работы BEFW. Демонстрацию удобнее смотреть на видео. Исходный код демо доступен на GitHub.
Подводные камни
Расскажу о багах, с которыми мы столкнулись.
ipset add set 0.0.0.0/0. Что случится, если добавить в ipset 0.0.0.0/0? Добавятся все IP? Откроется доступ в интернет?
Нет, мы получим баг, который стоил нам двух часов простоя. Причем баг не работает с 2016 года, лежит в RedHat Bugzilla под номером #1297092, а нашли мы его случайно — из отчета разработчика.
Теперь в BEFW стоит жесткое правило, что
0.0.0.0/0 превращается в два адреса: 0.0.0.0/1 и 128.0.0.0/1.ipset restore set < file. Что делает ipset, когда вы говорите ему
restore? Вы думаете, он работает также, как iptables? Восстановит данные?Ничего подобного — он делает merge, и старые адреса никуда не деваются, доступ вы не закрываете.
Баг мы нашли, когда тестировали изоляцию. Теперь там довольно сложная система — вместо
restore проводится create temp, потом restore flush temp и restore temp. В конце swap: для атомарности, потому что если сначала проводить flush и в этот момент придет какой-то пакет, то он будет отброшен и что-то пойдет не так. Поэтому там немного черной магии.consul kv get -datacenter=other. Как я уже говорил, мы думаем, что запрашиваем какие-то данные, но получим либо данные, либо ошибку. Мы можем это делать через Consul локально, но и в этом случае зависнет и то, и другое.
Локальный Consul-клиент это обертка над HTTP API. Но он просто виснет и не отвечает ни на Ctrl+C, ни на Ctrl+Z, ни на что, только на
kill -9 в соседней консоли. Мы столкнулись с этим, когда строили большой кластер. Но решения у нас пока нет, мы готовимся исправлять эту ошибку в Consul.Consul leader не отвечает. У нас не отвечает мастер в дата-центре, мы думаем: «Наверное, сейчас сработает алгоритм перевыбора?»
Нет, не сработает, и мониторинг ничего не покажет: Consul скажет, что commitment index есть, лидер найден, все хорошо.
Как мы с этим боремся?
service consul restart в cron каждый час. Если у вас 50 серверов — не страшно. Когда их будет 16 000, вы поймете, как это работает.Заключение
В итоге мы получили следующие преимущества:
- 100% покрытие всех Linux-машин.
- Скорость.
- Автоматизацию.
- Освободили железо и сетевых инженеров от рабства.
- Появились возможности по интеграции, которые практически безграничны: хоть с Kubernetes, хоть с Ansible, хоть с Python.
Минусы: Consul, с которым нам теперь жить, и очень высокая цена ошибки. Как пример, один раз я в 6 вечера (прайм по России) что-то правил в списках сетей. Мы как раз тогда строили изоляцию на BEFW. Я где-то ошибся, кажется, указал не ту маску, но все упало за две секунды. Загорается мониторинг, прибегает дежурный поддержки: «У нас все лежит!» Начальник департамента поседел, когда объяснял бизнесу почему так произошло.
Цена ошибки так высока, что мы придумали собственную сложную процедуру профилактики. Если вы будете это внедрять на большом продакшн, не надо давать мастер-токен над Consul всем подряд. Это плохо закончится.
Стоимость. Я писал код 400 часов в одиночку. На поддержку моя команда из 4 человек тратит 10 часов в месяц на всех. По сравнению с ценой любого файрвола нового поколения, это бесплатно.
Планы. Долгосрочный план — это поиск альтернативного транспорта взамен или дополнительно к Consul. Возможно, это будет Kafka или что-то подобное. Но в ближайшие годы мы будем жить на Consul.
Ближайшие планы: интеграция с Fail2ban, с мониторингом, с nftables, возможно, с другими дистрибутивами, метрики, расширенный мониторинг, оптимизация. Поддержка Kubernetes тоже где-то в планах, потому что сейчас у нас есть несколько кластеров и желание.
Еще из планов:
- поиск аномалий в трафике;
- управление картой сети;
- поддержка Kubernetes;
- сборка пакетов под все системы;
- Web-UI.
Постоянно мы работаем над расширением конфигурации, увеличением метрик и оптимизацией.
Присоединяйтесь к проекту. Проект получился крутым, но, к сожалению, это пока проект одного человека. Приходите на GitHub и попробуйте что-то сделать: закоммитить, потестировать, что-то предложить, дать свою оценку.
Тем временем мы готовимся к Saint HighLoad++, который состоится 6 и 7 апреля в Санкт-Петербурге, и приглашаем разработчиков высоконагруженных систем подать заявку на доклад. Опытные спикеры и так знают, что делать, а новичкам в выступлениях рекомендуем хотя бы попробовать. Участие в конференции в качестве спикера имеет ряд преимуществ. Каких, можно почитать, например, в конце этой статьи.
