
Подход governance as a code обеспечивает контроль соблюдения архитектурных принципов как в части конфигураций инфраструктуры, так и в части программного кода. Правила проверки каждого артефакта, будь то конфигурация k8s, список библиотек или даже описание сценария CI/CD, описаны специальным кодом проверки правил, имеют свой жизненный цикл, могут тестироваться и ничем не отличаются от обычного программного продукта.
Александр Токарев (Сбербанк) расскажет, как и что можно проверять в процессе разработки программного обеспечения, чтобы разрабатывать более безопасные и качественные приложения, и почему Сбербанк решил не использовать такие очевидные решения как SonarQube, а разработать собственное решение на базе Open Policy Agent без дополнительных пакетов над ним. Также Александр покажет, когда выбирать admission controller, когда использовать «чистый» Open Policy Agent, а когда можно обойтись без какого-либо контроля.
Александр поговорит о том, нужны ли стандарты, что такое язык Rego и что за крутой продукт Open Policy Agent, а также рассмотрит нетиповые кейсы его применения, как с ним работать, и как его использовать для контроля. Email Александра.

Итак, представьте Сбербанк:
Все эти задачи решаются разными командами по-разному, что приводит к повышенным нагрузкам на системы контроля безопасности. Для создания стандартов по контейнеризации и разработке приложений в облачной архитектуре нужно проработать ограничения и рекомендации. Но как только появляется стандарт, его надо проверять вручную перед каждым накатом на продакшн и ПСИ. Конечно, скорость доставки изменений на продакшн замедляется.
Мы решили переложить все эти задачи на автоматизированный контроль и определили для себя следующие уровни зрелости автоматизированного контроля:
Уровни построены так, что, если вы не достигли предыдущего, на следующий не перейдете.
Google предлагает начать их с Kubernetes и приводит нас к абсолютно старым и неживым проектам:
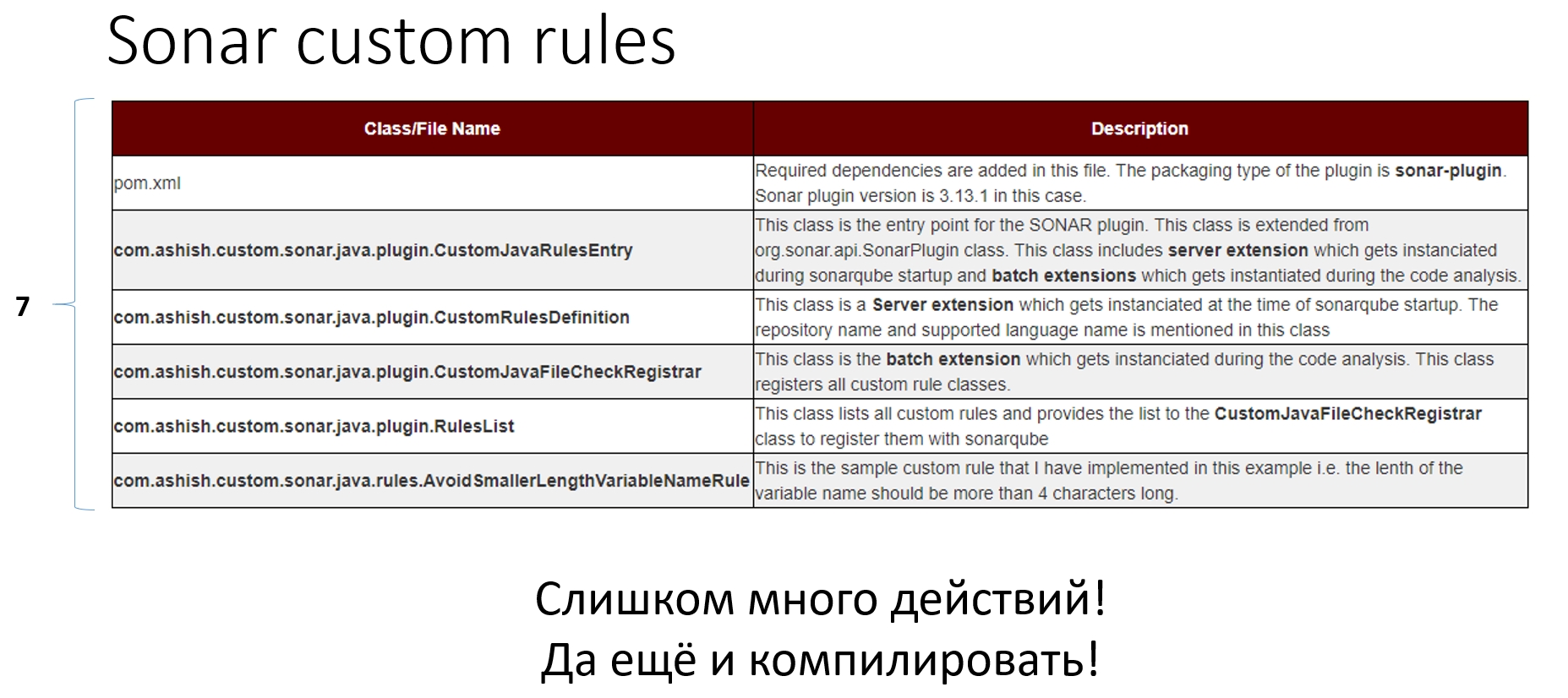
Можно обнаружить живые и развивающиеся проекты, но при их изучении понимаешь, что для результата надо написать очень много букв с точки зрения CRD, они жёстко прибиты к Kubernetes, у них нет DSL (потому что сложные проверки описываются через REGEXP), и при этом нет возможности дебага политик. Вот пример DSL такого продукта, который проверяет CPU и memory limit в кластере. Это абсолютно своя CRD, которая выводит обычное сообщение, и далее нужно много букв и REGEXP для того, чтобы это контролировать:
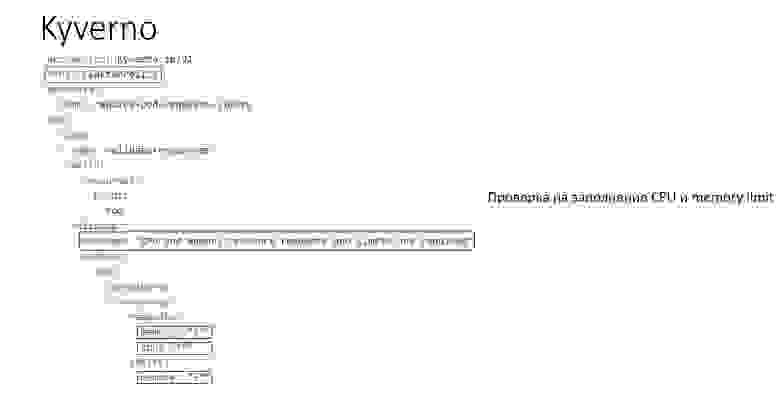
Можно взять Sonar, но мы поняли, что для создания в нём элементарного правила нужно минимум 7 артефактов, а это довольно сложно:

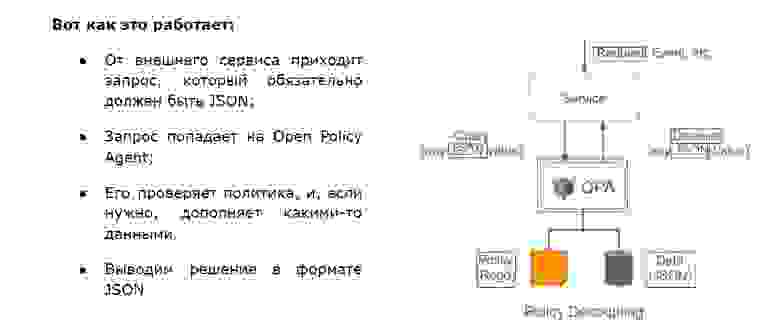
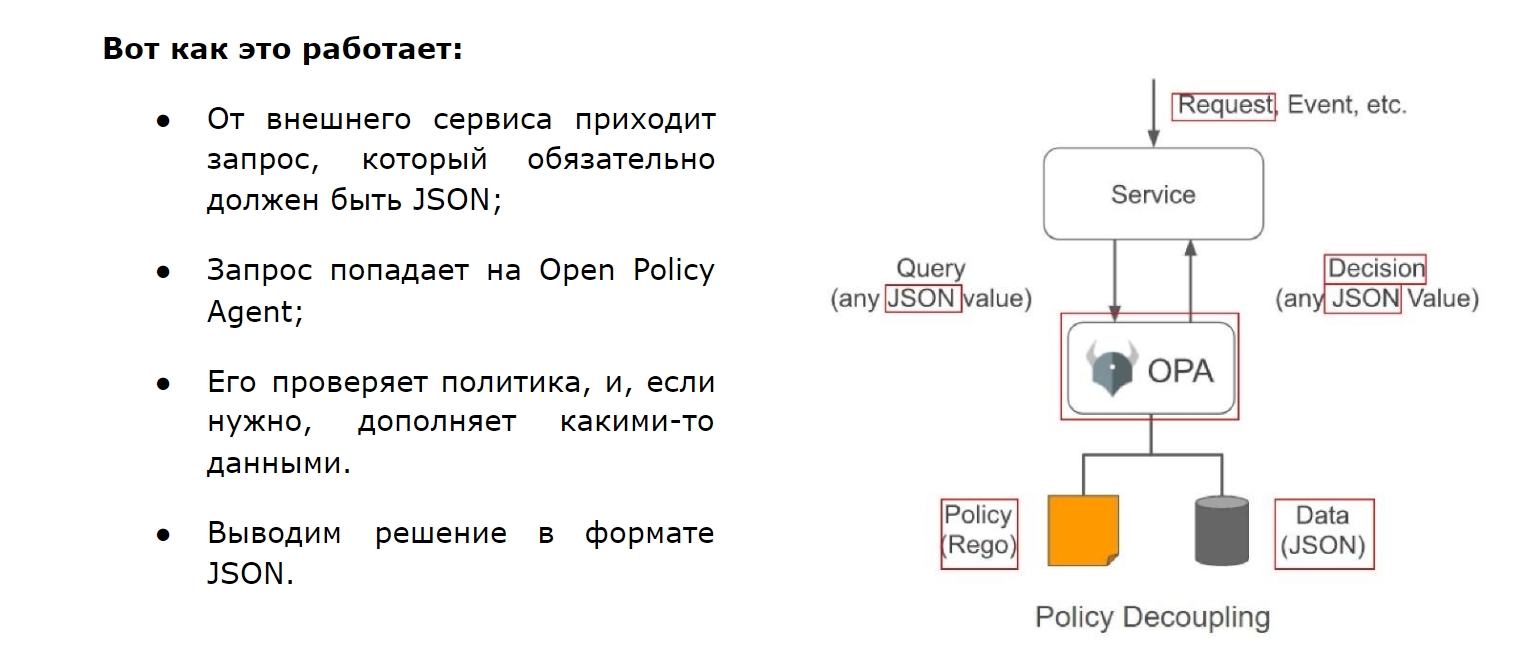
После долгих поисков мы обнаружили замечательный продукт — Open Policy Agent (OPA), который на самом деле движок политик, написанный на Go. Он очень быстрый, потому что inmemory. Им можно проверять всё что угодно с использованием собственного декларативного языка Rego, который не сложнее SQL. Можно использовать внешние данные и встраивать продукт куда угодно. Но самое главное — мы можем управлять форматом ответа, когда это не просто boolean true/false, а всё, что мы захотим увидеть.
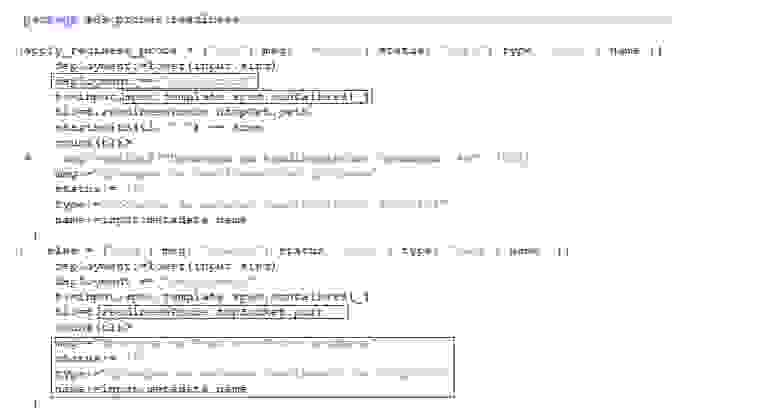
Простейшая проверка, проверяющая заполнение ревестов и лимитов, включает в себя получение всех контейнеров Kubernetes, которые объявлены в нашем YAML, их проверку на заполнение нужных полей (проходя по структуре YAML) и вывод сообщения (JSON). Если с проверкой всё хорошо, то в result не будет ничего. Три строчки кода — и у вас она работает:

Конечно, объекты на продакшене гораздо более сложные, потому что надо что-то фильтровать, надо всё также получать списки контейнеров и работать с состоянием целого кластера. Дополнительно мы выводим диагностическое сообщение о том, пройдена или нет проверка, статус её прохождения, вид проверок (группа) и фактически тот объект, который тестировала проверка.
Может создаться ощущение, что Open Policy Agent используется только для Kubernetes, но это не так. Проверять можно всё что угодно, лишь бы это был JSON:
Таким образом мы приходим к Open Policy Agent в Сбербанке:
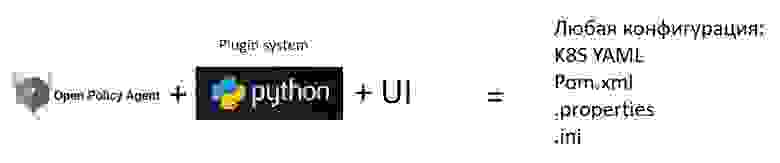
Есть Open Policy Agent и есть система плагинов на Python (потому что на нем элементарно написать преобразования) и конечно же пользовательский интерфейс. Таким образом проверка абсолютно любой конфигурации (K8S YAML, Pom.xml, .properties, .ini) работает просто.
Наш интерфейс при этом тоже очень простой и удобный: мы можем подать ему список данных для тестирования или список REGO проверок, выполнить проверку и легко увидеть, что выполнилось и что нет. Есть очевидные «вкусности» — фильтрация, сортировка, выгрузка. Абсолютно все просто, понятно и красиво:
Вернемся к примеру maven:
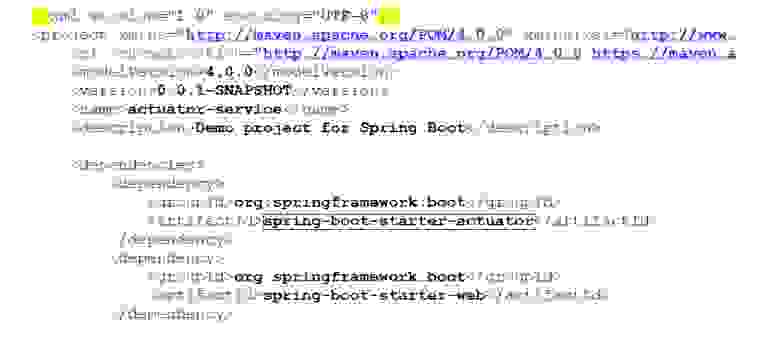
Предположим, мы хотим контролировать использование spring-boot-starter-actuator для написания тех самых readinessProbe. Живая проверка очень проста: мы получаем все dependency, а дальше смотрим, что библиотека — это spring-boot-starter-actuator. Как я уже говорил, большая часть проверок — это вывод диагностических сообщений об их прохождении/непрохождении:
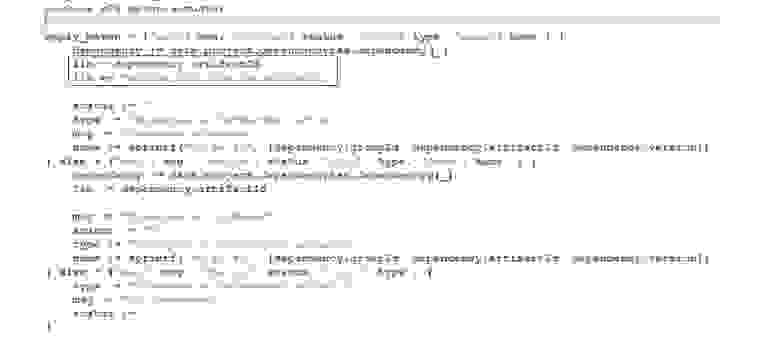
Однако бывают более сложные кейсы. Предположим, нам нужно проверить конфигурацию Kubernetes на наличие разрешённых image (fluentbit2, envoy3, nginx:1.7.9) и вывести имя запрещённого. Видим, что у нас есть валидная конфигурация с абстрактным nginx и есть конфигурация с запрещённым nginx:

Поищем в Google как это сделать. Само собой, первая ссылка приводит на сайт проекта, но, как принято в документации OPA, там нет информации о том, что нам надо:

Воспользуемся ссылкой от Amazon, они же профессионалы! Большой код, 19 строк букв — где та самая лаконичность, которую я вам рекламировал раньше? Какие-то непонятные команды, палки — что это? Долго-долго читаем документацию, понимаем, что это так называемый Object comprehension, и что на самом деле коллеги из Amazon транслируют массив как есть в список объектов. Почему? Потому, что из документации непонятно, что можно объявить объект таким элементарным и очевидным образом:

Тем не менее применяем и получаем результаты. Но всё равно очень много букв — 13 строк кода!
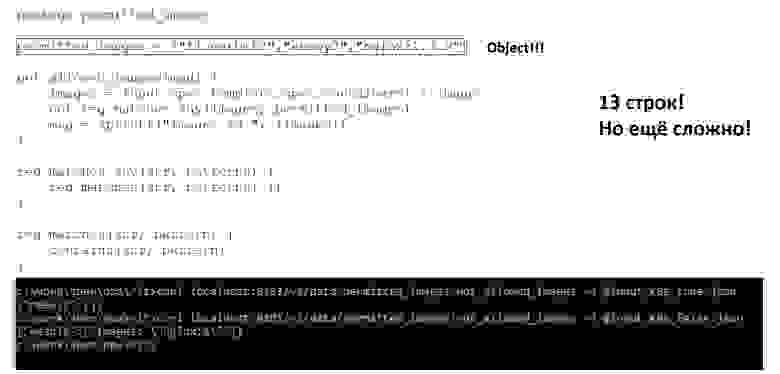
А как же написать, чтобы было красиво, и чтобы пользоваться всей мощностью декларативности? На самом деле все очень просто: получаем контейнер Kubernetes, а дальше представляем, что у нас SQL и фактически данными строчками пишем not in. Мыслите в терминах SQL, будет гораздо проще. За 7 строчек кода мы получаем действительно нужную нам информацию — все неразрешённые контейнеры name:

Где все это писать? Есть две тулзы:
Rego Playground
Она размещена в интернете авторами продукта и позволяет вести отладку онлайн. Она не всегда хорошо выполняет сложные проверки, но самое ценное её свойство для меня — готовая библиотека проверок, где можно подсмотреть какие-то идеи:

Плагин Visual Studio Code
Действительно прекраснейший плагин. В нем есть всё, что надо для средств разработки:
Теперь надо это всё интегрировать. Есть два пути интеграции в OPA:
Представьте, у вас есть Open Policy Agent сервер, есть bundle-сервер (который надо написать самостоятельно) и есть данные по вашим проверкам:
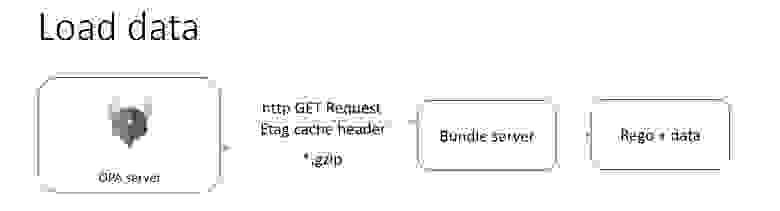
В соответствии с конфигурацией Open Policy Agent сервер умеет ходить в bundle-сервер по фиксированному урлу и забирать данные, если они ещё не подготовлены. Далее он ожидает их приема в .gzip формате, полностью поддерживая спецификации кэширования — если вы в bundle-сервере реализовали обработку тэга ETag, то Open Policy Agent сервер не будет протаскивать мегабайты ваших проверок через сеть в случае неизменения:

Выполняем проверку. Open Policy Agent имеет прекрасный resfull API — после загрузки наших данных мы получаем имя пакета, который мы создали при создании файла, и имя правила. Дальше мы подаём для проверки наш артефакт в виде JSON. Если вы долго читали документацию, то поняли, что наш артефакт надо обрамить в input:

Обрабатываем результат (возвращённый JSON) где угодно — в Jenkins, admission controller, UI, whatever… Чаще всего результат приходит в таком виде:

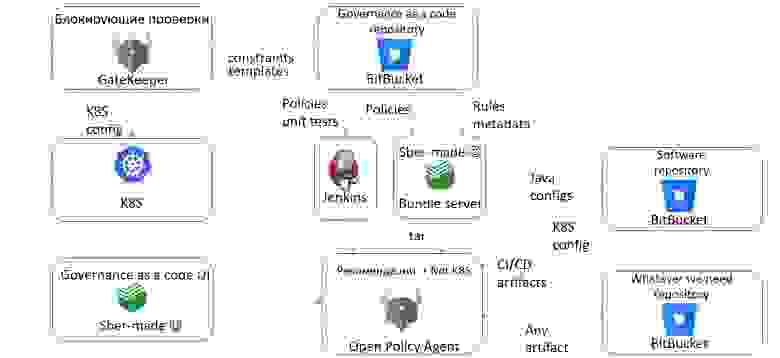
Политики OPA у нас разработаны для тех проверок, которые не связаны с Kubernetes, и тех, что связаны с Kubernetes, но рекомендуются. Они хранятся в гите и через наш Bundle server, как и метаданные, попадают в Open Policy Agent. Мы пользуемся встроенными механизмами Open Policy Agent для Unit-тестирования и тестируем все наши проверки.
То есть Open Policy Agent проверяет сторонние артефакты (Java configs, K8S config, артефакты CI/CD), а те, которые надо заблокировать для попадания на кластеры, проходят через Gatekeeper, и в итоге наш кластер в безопасности. В принципе мы можем проверять всё что угодно, и смотреть результаты проверок через наш пользовательский интерфейс:
Чего мы добились:
Конечно, стоит подумать об Opensource Bundle-сервера и пользовательского интерфейса, потому что это дженерик-решение, и они никак не связаны с инфраструктурой Сбербанка.
Приведу пример банка Goldman Sachs. У них большой облачный кластер из 1800 namespace (12 общих кластера Kubernetes на виртуалках, в каждом кластере по 150 namespace). Всё это управляется из централизованной системы под названием Inventory, где находится информация:
Коллеги используют такую архитектуру решения:
Всё состояние кластера синхронизируются в Bundle server с помощью плагина Kube-mgmt от разработчиков OPA. Bundle server через определенные периоды времени ходит в гит и забирает измененные политики.
Для самой системы Inventory процесс чуть-чуть другой. Она уведомляет Bundle server об изменениях, и он сразу же после этого идёт и забирает данные. Любое изменение вызывает запуск проверок, который вызывает создание JSON, а JSON переводится в YAML, прогоняется через Controller Manager и запускается на кластере.
Когда такая система стоит в продакшене, очень важно её мониторить. Коллеги мониторят 11 показателей, относящихся по большей части к garbage коллектору, Go и времени ответа от OPA-сервера:
Что же удалось создать коллегам:
Если мы хотим писать крутые, навороченные проверки, что же делать? Есть несколько способов — взять готовое или стать ещё более крутым.
Мы можем использовать Fugue, который представляет движок политик как сервис (governance as a code as a service). Он проверяет конфигурации облаков Amazon, Azure, GCP. Представляете, насколько там сложные политики, что ему надо проверять не только Kubernetes, но и relational database services, VPC и т.д.? Фактически каждый из продуктов каталога Amazon и прочих облаков может быть проверен готовыми политиками.
Fugue работает как admission controller. Ещё одна из очень его больших ценностей — это наборы пресетов под регуляторы — PSI DSS, HIPAA, SOC, etc. Фактически вы делаете нужную инфраструктуру в Amazon, запускаете продукт и говорите: «Проверь на PSI DSS», — и вуаля, вы получаете фактически аудит.
Очевидно, что Fugue реализован на OPA, но так как политики очень сложные, коллеги реализовали свой интерпретатор Rego для отладки продвинутых проверок. Выполнение происходит на Open Policy Agent, а отладка уже на своем интерпретаторе. Так как это облачный продукт, у него прекраснейший пользовательский интерфейс, который позволяет понять, какие проверки пройдены, какие нет и процент их соответствия:
Набор правил действительно самый разнообразный — есть элементарнейшие вещи в стиле «на машине с RDS, если она гарантирует высокую доступность, должны быть использованы multi availability zone deployment»:

И есть гораздо более сложные, например, «если используется Elasticsearch от Amazon, то его пользовательский интерфейс не должен быть выставлен наружу»:
С Fugue можно ознакомиться на их сайте. Но гораздо интереснее их интерпретатор Rego и набор примеров, которые у них реализованы.
Fregot — это очень живой продукт, который позволяет отлаживать проверки на Rego. За счет чего? У него упрощённый дебаг (breakpoints и watch variables) и расширенная диагностика по ошибкам, которая важна, когда вы будете пользоваться ванильной OPA — в этом случае чаще всего вы будете получать сообщение: var _ is unsafe, и вам будет абсолютно непонятно, что с этим делать:

Это утилита проверки, использующая Open Policy Agent. Она содержит в себе потрясающе огромный встроенный набор конвертеров, и сама выбирает конвертер, исходя из расширения файла:

Ещё раз обратите внимание, насколько выразительный язык Rego — всего одной строкой мы проверяем, что нельзя запускать контейнер из-под root:

Дальше мы говорим: «conftest test», и указываем имя того объекта, который нам надо протестировать. И все проверки, которые есть в директории утилиты, проверяются по файлам, а вы получаете результат.
Плюсы:
Минусы:
Сейчас это Admission controller, а в будущем он будет работать как Mutating admission controller, который не только проверяет на условие, но и в случае прохождения условий меняет команду так, как ему надо:
Admission controller встает между вашими командами и кластером Kubernetes. Вы отправляете команду, admission controller вызывает внешнюю проверку условий и, если условие выполнено, то команда запускается в кластере. Если не выполнено, то команда просто откатывается.
За счет чего обеспечивается повторное использование в продукте Gatekeeper? Есть два объекта:
Gatekeeper синхронизирует в течение жизненного цикла своей работы весь кластер кубера в себя, а дальше любое действие кластера вызывает Webhook, по нему команда (YAML объект, каким он будет после применения изменения) приходит в Open Policy Agent. Дальше результат проверки возвращается как пропущенная, либо как нет.
Пример проверки на Gatekeeper:
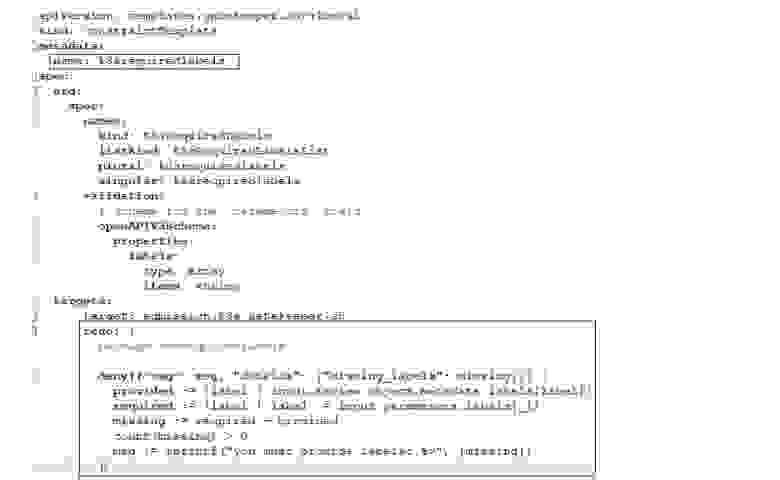
Это своя CRD, само собой. Мы даем ей имя и говорим, что входной параметр – это метки, которые представляют собой массив строк. Пишем на Rego нашу проверку, и в данном случае она проверяет, что для объектов заданы необходимые метки. Мы используем внутри Rego наши входные параметры — это тот самый template. А живая политика выглядит так: используй такой-то template и такие-то метки. Если у проекта не будет таких меток, то он просто в кластер не попадёт:
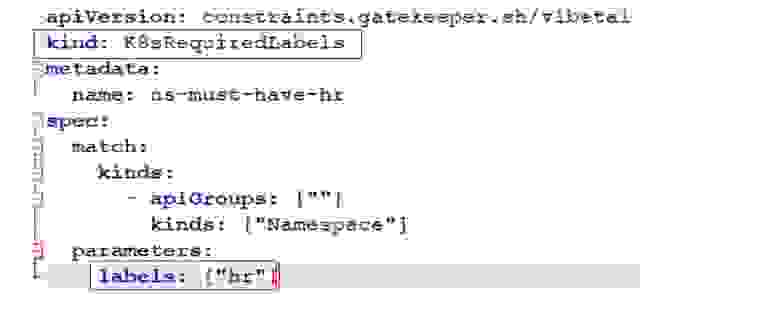
Плюсы:
В то же время эти плюсы становятся автоматически минусами:
Итак, фактически мы преобразовали уровни зрелости технологического контроля к готовому технологическому стеку:
Как мы увидели, Open Policy Agent решает задачи проверки любых структурированных данных, а также коррекции проверенных данных. Хотя на самом деле Open Policy Agent позволяет делать гораздо больше, например, помогает решать задачи авторизации, задачи database row level security (sql databases, ElasticSearch), а некоторые даже пишут на нём даже игры (Corrupting the Open Policy Agent to Run My Game).
Рассмотрим несколько примеров.
У коллег в Pinterest всё развернуто в Amazon, поэтому у них принят подход Zero-trust security и, само собой, все реализовано на OPA. Под его контролем находится всё, что связано с Kubernetes, с виртуальными машинами, авторизацией в Kafka, а также с авторизацией на Envoy.
Таким образом их нагрузка колеблется от 4.1M до 8.5M QPS в секунду. При этом имеется кэш с длительностью жизни 5 минут. В Open Policy Agent приходит от 204 до 437 тысяч в секунду запросов — действительно большие цифры. Если вы хотите работать с такими порядками, надо конечно думать о производительности.
Что я рекомендую в этой части:
Как же коллеги из Pinterest решили эти задачи? На каждом сервисе или каждом хосте, или ноде у них расположен Open Policy Agent как sidecar, и работают они с ним через библиотеку, а не напрямую через REST, как показывал я. В той самой библиотеке находится кэш с временем жизни 5 минут:
Очень интересно, как происходит у них доставка политик. Есть кластер, есть Bitbucket, а дальше данные из него хуками на коммит пробрасываются на S3. Так как запись в него асинхронна в принципе, то результат идет в Zookeeper, а он уведомляет Sidecar об изменениях. Sidecar забирает данные из S3, и всё прекрасно:
Задачи авторизации становятся все более актуальными, и все больше разработчиков получают запросы, чтобы включить Open Policy Agent в их продукты… Многие уже это сделали: например, Gloo в своей энтерпрайз-версии использует Open Policy Agent как движок для авторизации.

Но можно это сделать по-другому. Наверное, все знают, что такое Envoy. Это легковесный прокси, в котором есть цепочки фильтров. Envoy крут тем, что позволяет обеспечивать дистанционное управление конфигурацией. Собственно, отсюда и появился термин service mesh:
На Envoy мы можем опубликовать Open Policy Agent сервер снаружи и настроить так называемые фильтры внешней авторизации. Далее любой запрос от пользователя вначале попадает на Envoy, проверяется им, и только после этого отправляется наружу:
На самом деле авторизация — это всегда о безопасности. Поэтому в 2018 году было проведено Penetration-тестирование: 6 человек в течение 18 дней пытались взломать Open Policy Agent. Результаты тестирования говорят, что OPA — это действительно безопасное решение:

Конечно, были ошибки:
Но это были те ошибки, которые случаются по большей части от того, что есть проблемы с документацией:
Из того, что я сказал, может создаться ощущение, что Open Policy Agent – это странный, непонятный, никому не нужный продукт. На самом деле в Open Policy Agent полно фишек, которые еще никто не использует:
Есть только одна проблема — документация не объясняет, зачем это надо. В Google, скорее всего, вы тоже ничего не найдете. Например, мы хотим понять, как же работает политика изнутри:
Идем по первой же ссылке и попадаем всего лишь в функцию, которая выводит отладочную информацию, не имеющую никакого отношения к тому, как же политика выполняется:

Но если поковыряться с утилитой repl, которая входит в состав OPA, абсолютно случайно можно найти функцию trace, про которую, конечно же, ничего не сказано в документации. Именно она фактически показывает план выполнения проверки, с которым очень легко работать и отлаживаться:
Open Policy Agent находится под крылом CNCF, и он более чем живой. В итоге хотелось бы сказать, что да, по данному продукту сложно найти информацию даже в объемной и неоднозначной документации. Но продукт активно развивается, живет не только в контейнерах, его можно использовать в абсолютно разных кейсах. И он действительно безопасен, как показали Penetration-тесты.
Если вы хотите его использовать, вам придется создавать UI и научиться писать правила на языке, близком к естественному, а не на языке кода. Учите Rego и используйте Fregot для дебага.
Помните, что Гугл, скорее всего, вам не поможет.
Александр Токарев (Сбербанк) расскажет, как и что можно проверять в процессе разработки программного обеспечения, чтобы разрабатывать более безопасные и качественные приложения, и почему Сбербанк решил не использовать такие очевидные решения как SonarQube, а разработать собственное решение на базе Open Policy Agent без дополнительных пакетов над ним. Также Александр покажет, когда выбирать admission controller, когда использовать «чистый» Open Policy Agent, а когда можно обойтись без какого-либо контроля.
Александр поговорит о том, нужны ли стандарты, что такое язык Rego и что за крутой продукт Open Policy Agent, а также рассмотрит нетиповые кейсы его применения, как с ним работать, и как его использовать для контроля. Email Александра.

Итак, представьте Сбербанк:
- Более 50 приложений в облачной платформе OpenShift в production;
- Релизы не реже двух раз в месяц, а порой и чаще;
- Ожидается не менее 20 новых приложений в год для перевода в Openshift;
- И все это на фоне микросервисной архитектуры.
Все эти задачи решаются разными командами по-разному, что приводит к повышенным нагрузкам на системы контроля безопасности. Для создания стандартов по контейнеризации и разработке приложений в облачной архитектуре нужно проработать ограничения и рекомендации. Но как только появляется стандарт, его надо проверять вручную перед каждым накатом на продакшн и ПСИ. Конечно, скорость доставки изменений на продакшн замедляется.
План перехода к автоматизации
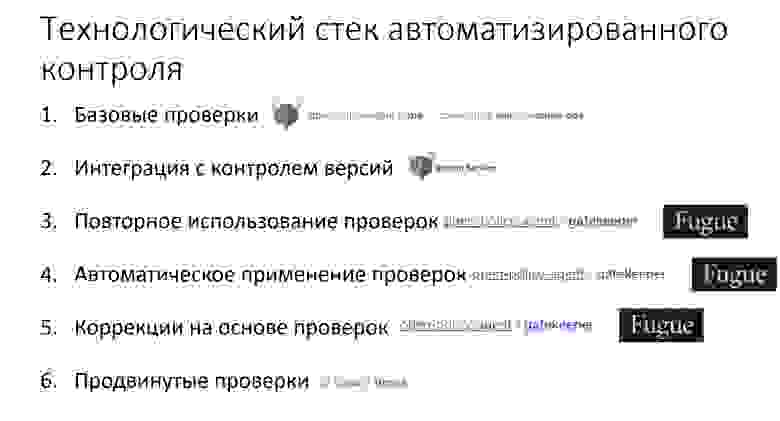
Мы решили переложить все эти задачи на автоматизированный контроль и определили для себя следующие уровни зрелости автоматизированного контроля:
- Базовые проверки;
- Интеграция с контролем версий;
- Повторное использование проверок;
- Автоматическое применение проверок;
- Коррекции на основе проверок;
- Продвинутые проверки – когда вы всему научились и можете писать очень крутые вещи.
Уровни построены так, что, если вы не достигли предыдущего, на следующий не перейдете.
Базовые проверки
Google предлагает начать их с Kubernetes и приводит нас к абсолютно старым и неживым проектам:
Можно обнаружить живые и развивающиеся проекты, но при их изучении понимаешь, что для результата надо написать очень много букв с точки зрения CRD, они жёстко прибиты к Kubernetes, у них нет DSL (потому что сложные проверки описываются через REGEXP), и при этом нет возможности дебага политик. Вот пример DSL такого продукта, который проверяет CPU и memory limit в кластере. Это абсолютно своя CRD, которая выводит обычное сообщение, и далее нужно много букв и REGEXP для того, чтобы это контролировать:
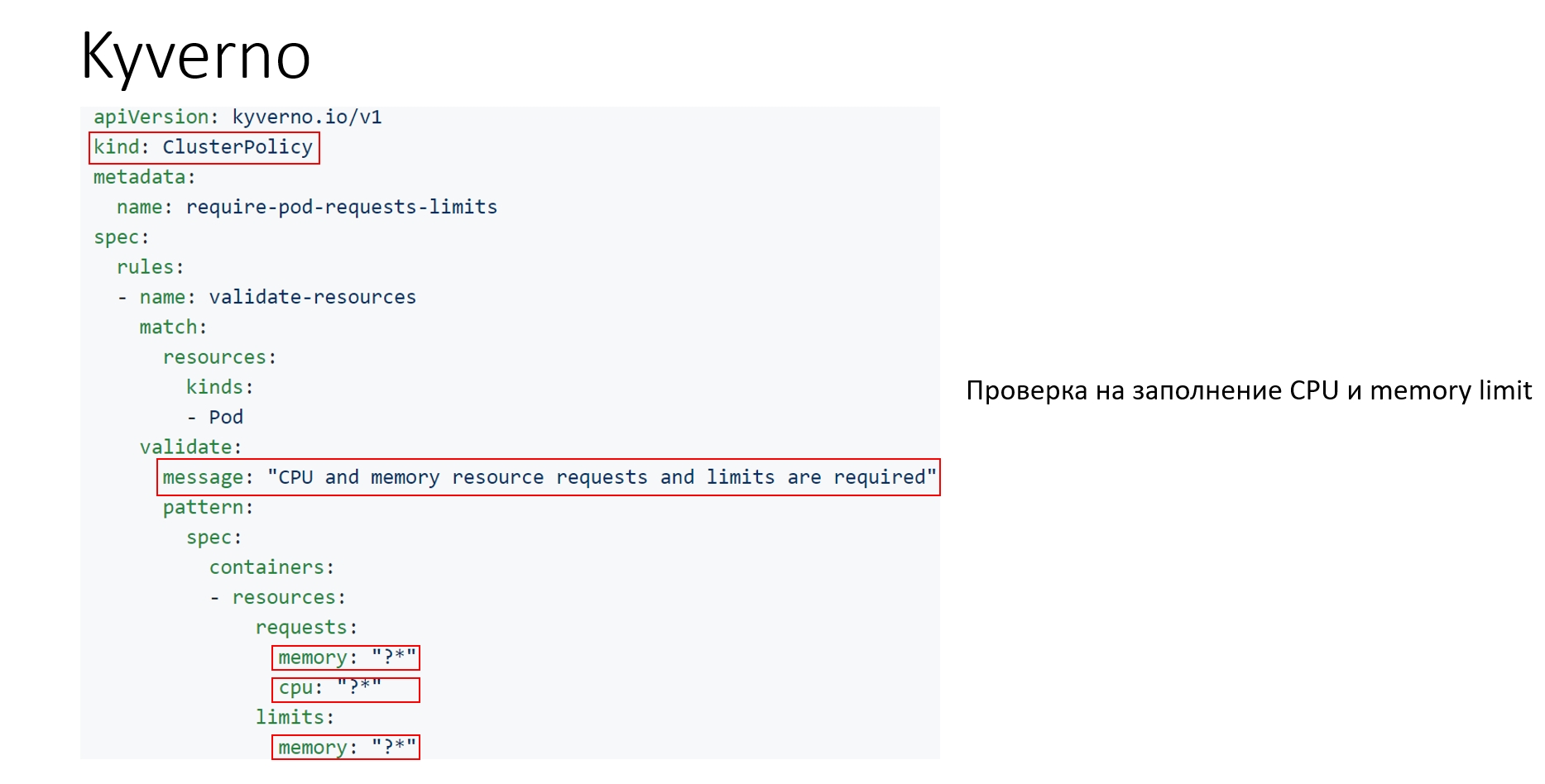
Можно взять Sonar, но мы поняли, что для создания в нём элементарного правила нужно минимум 7 артефактов, а это довольно сложно:
После долгих поисков мы обнаружили замечательный продукт — Open Policy Agent (OPA), который на самом деле движок политик, написанный на Go. Он очень быстрый, потому что inmemory. Им можно проверять всё что угодно с использованием собственного декларативного языка Rego, который не сложнее SQL. Можно использовать внешние данные и встраивать продукт куда угодно. Но самое главное — мы можем управлять форматом ответа, когда это не просто boolean true/false, а всё, что мы захотим увидеть.
Простейшая проверка, проверяющая заполнение ревестов и лимитов, включает в себя получение всех контейнеров Kubernetes, которые объявлены в нашем YAML, их проверку на заполнение нужных полей (проходя по структуре YAML) и вывод сообщения (JSON). Если с проверкой всё хорошо, то в result не будет ничего. Три строчки кода — и у вас она работает:

Конечно, объекты на продакшене гораздо более сложные, потому что надо что-то фильтровать, надо всё также получать списки контейнеров и работать с состоянием целого кластера. Дополнительно мы выводим диагностическое сообщение о том, пройдена или нет проверка, статус её прохождения, вид проверок (группа) и фактически тот объект, который тестировала проверка.
Примеры проверок K8S
Может создаться ощущение, что Open Policy Agent используется только для Kubernetes, но это не так. Проверять можно всё что угодно, лишь бы это был JSON:
- Maven;
- NPM;
- Terraform;
- Даже ER diagrams, потому что в том же Power Designer это XML.
Таким образом мы приходим к Open Policy Agent в Сбербанке:

Есть Open Policy Agent и есть система плагинов на Python (потому что на нем элементарно написать преобразования) и конечно же пользовательский интерфейс. Таким образом проверка абсолютно любой конфигурации (K8S YAML, Pom.xml, .properties, .ini) работает просто.
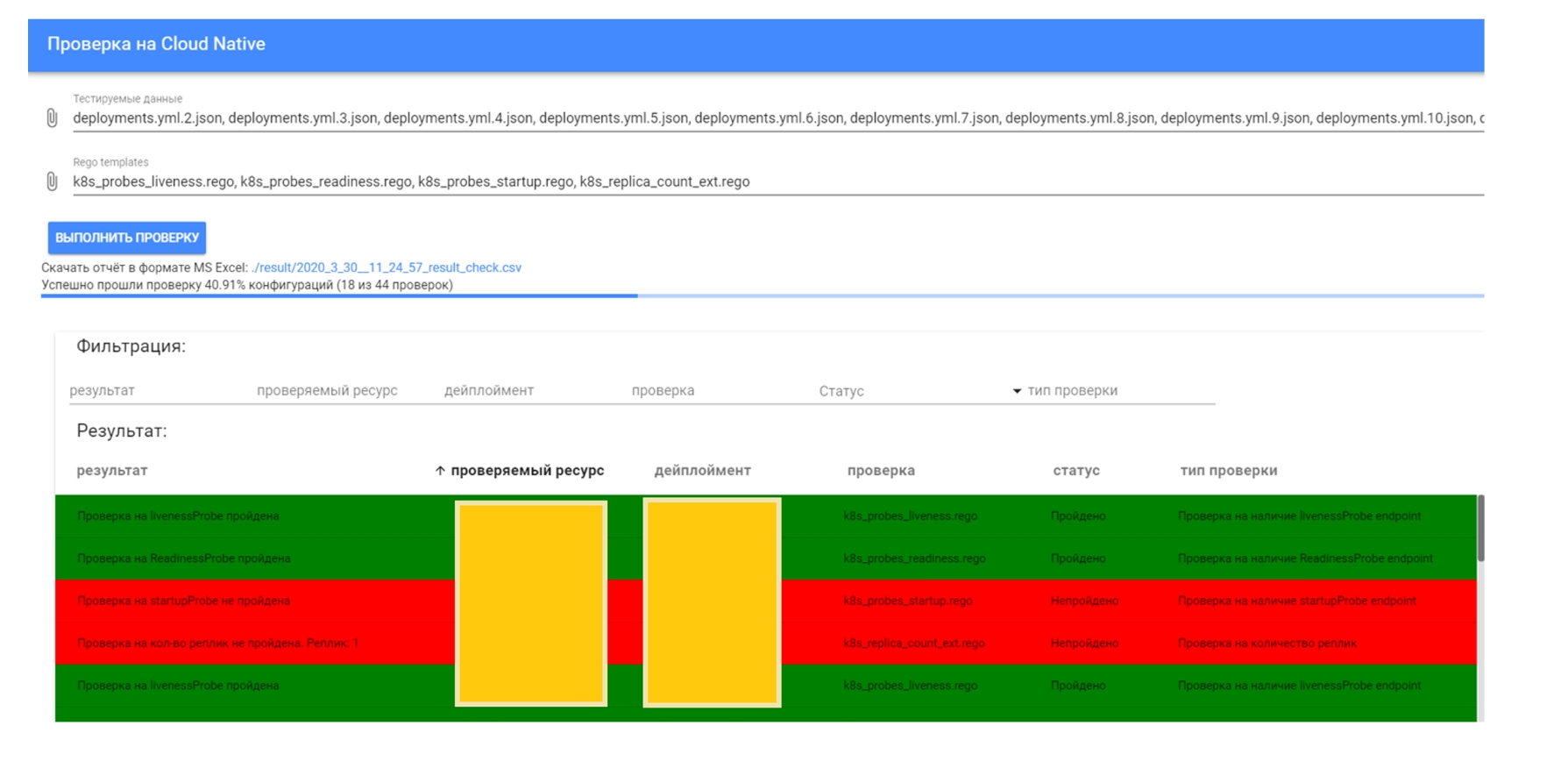
Наш интерфейс при этом тоже очень простой и удобный: мы можем подать ему список данных для тестирования или список REGO проверок, выполнить проверку и легко увидеть, что выполнилось и что нет. Есть очевидные «вкусности» — фильтрация, сортировка, выгрузка. Абсолютно все просто, понятно и красиво:
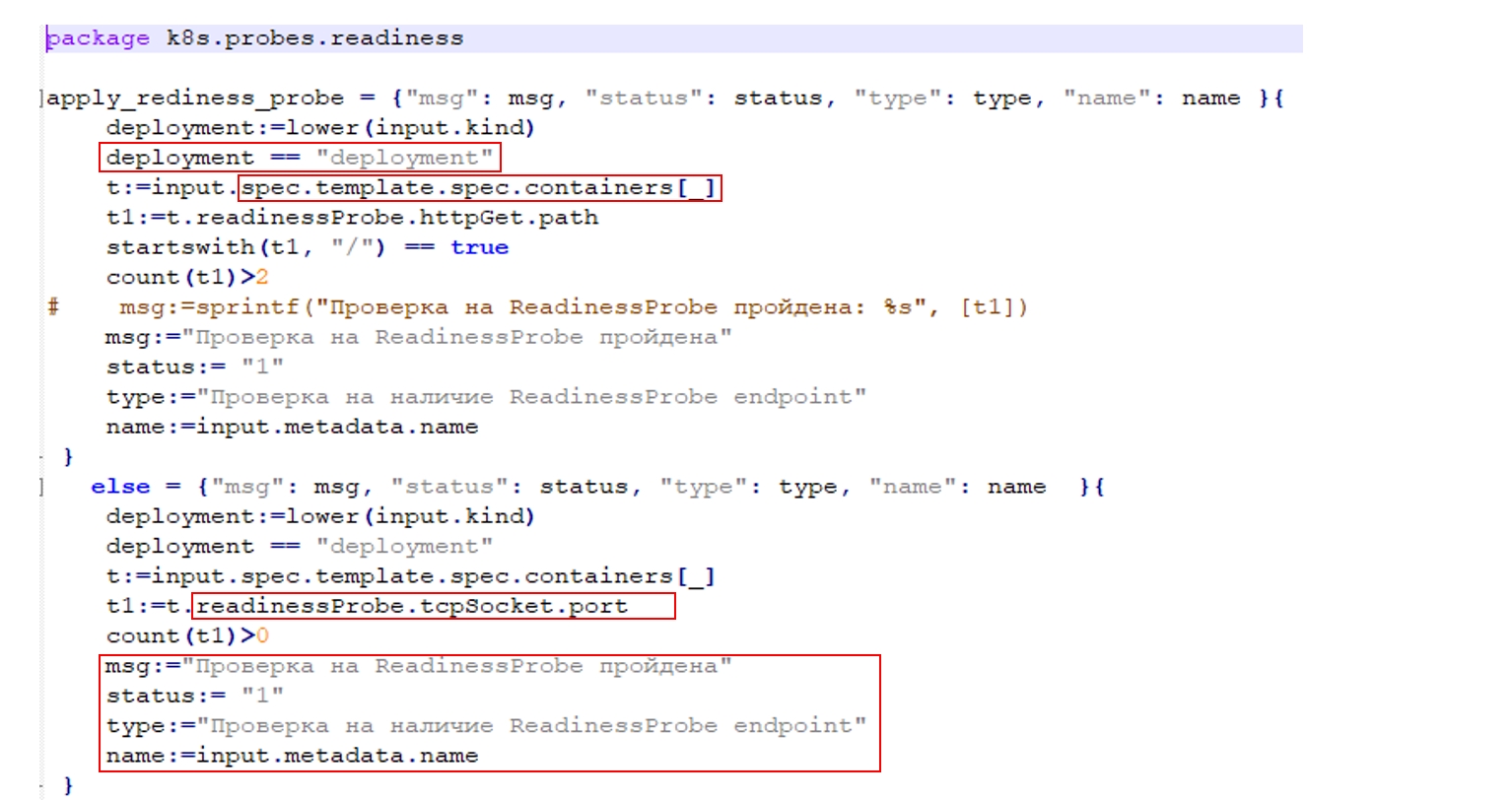
Вернемся к примеру maven:
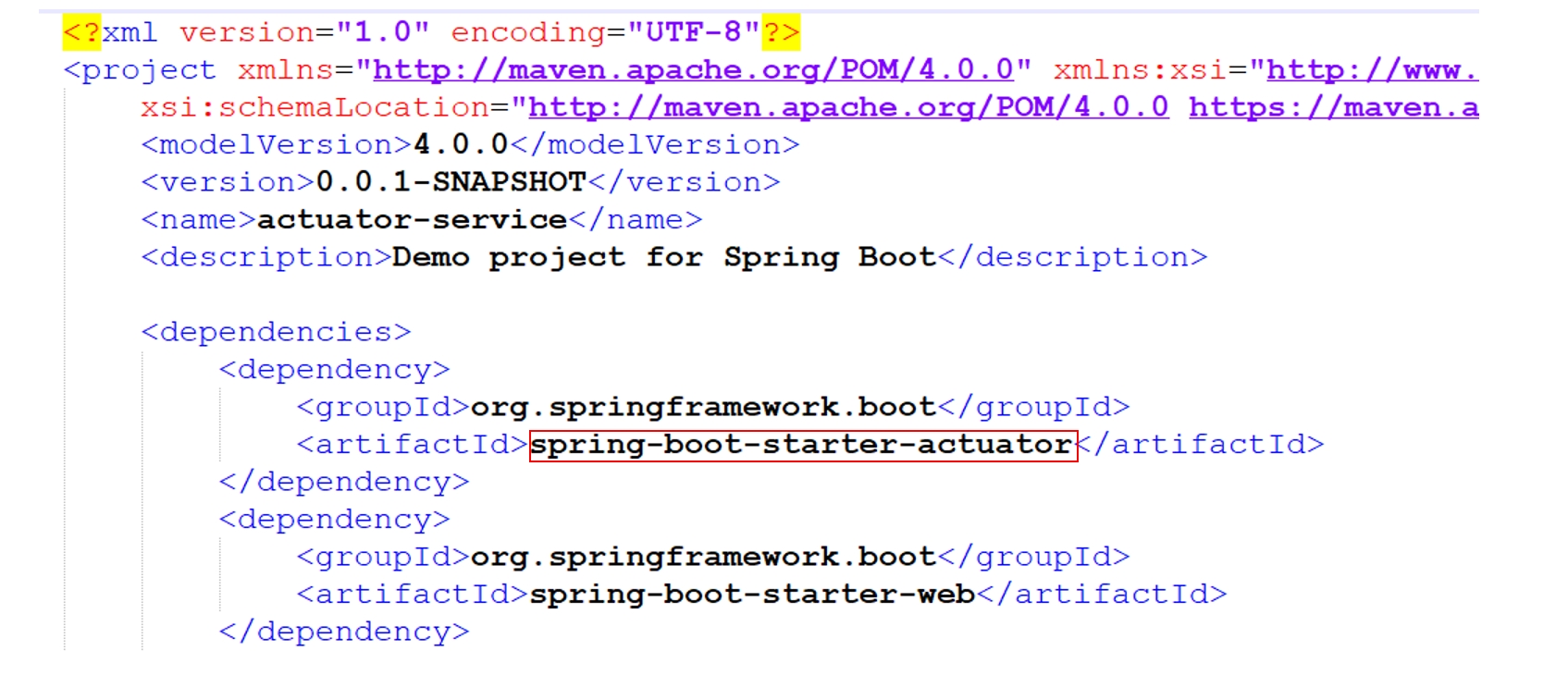
Предположим, мы хотим контролировать использование spring-boot-starter-actuator для написания тех самых readinessProbe. Живая проверка очень проста: мы получаем все dependency, а дальше смотрим, что библиотека — это spring-boot-starter-actuator. Как я уже говорил, большая часть проверок — это вывод диагностических сообщений об их прохождении/непрохождении:

Однако бывают более сложные кейсы. Предположим, нам нужно проверить конфигурацию Kubernetes на наличие разрешённых image (fluentbit2, envoy3, nginx:1.7.9) и вывести имя запрещённого. Видим, что у нас есть валидная конфигурация с абстрактным nginx и есть конфигурация с запрещённым nginx:
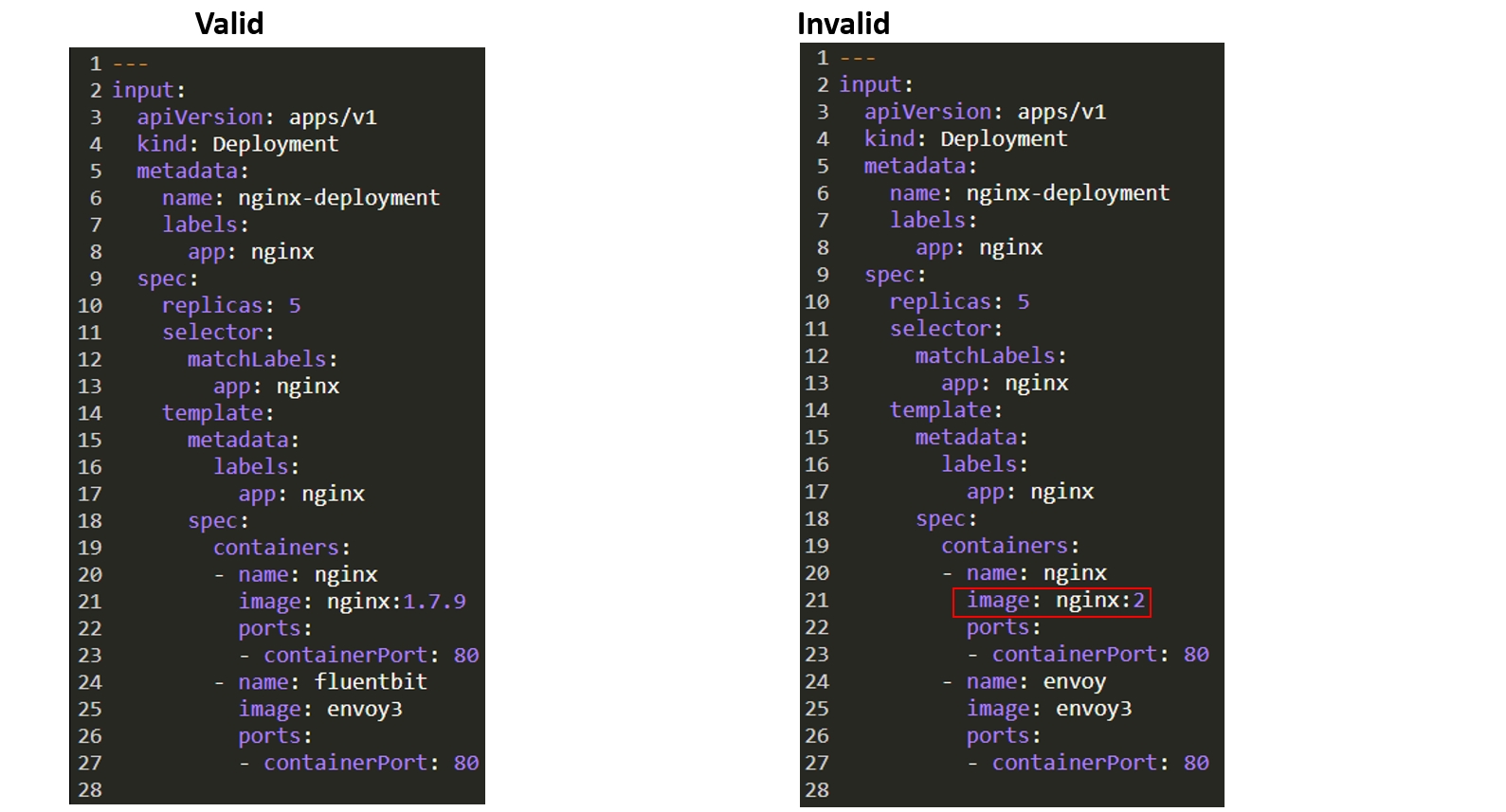
Поищем в Google как это сделать. Само собой, первая ссылка приводит на сайт проекта, но, как принято в документации OPA, там нет информации о том, что нам надо:

Воспользуемся ссылкой от Amazon, они же профессионалы! Большой код, 19 строк букв — где та самая лаконичность, которую я вам рекламировал раньше? Какие-то непонятные команды, палки — что это? Долго-долго читаем документацию, понимаем, что это так называемый Object comprehension, и что на самом деле коллеги из Amazon транслируют массив как есть в список объектов. Почему? Потому, что из документации непонятно, что можно объявить объект таким элементарным и очевидным образом:

Тем не менее применяем и получаем результаты. Но всё равно очень много букв — 13 строк кода!
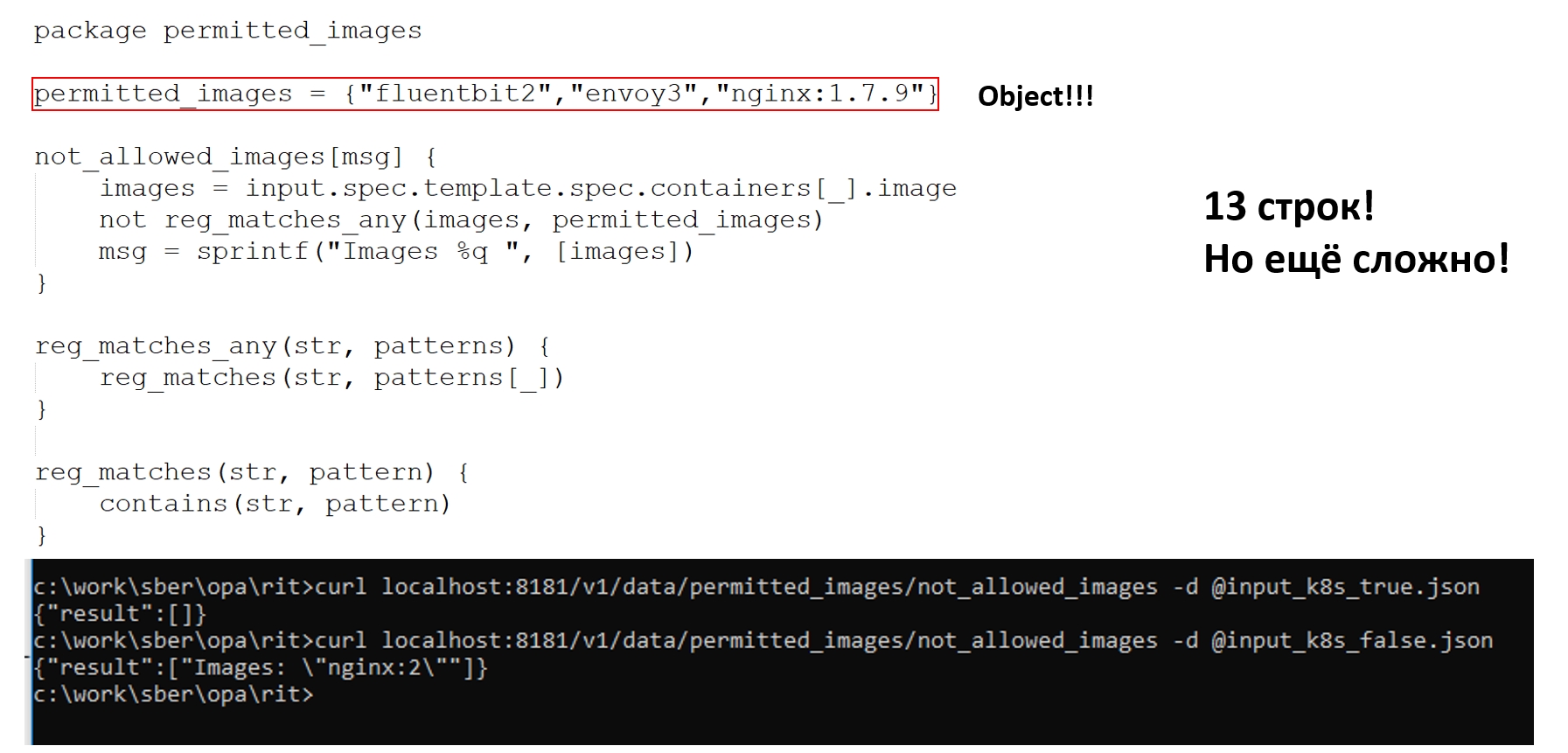
А как же написать, чтобы было красиво, и чтобы пользоваться всей мощностью декларативности? На самом деле все очень просто: получаем контейнер Kubernetes, а дальше представляем, что у нас SQL и фактически данными строчками пишем not in. Мыслите в терминах SQL, будет гораздо проще. За 7 строчек кода мы получаем действительно нужную нам информацию — все неразрешённые контейнеры name:

Где все это писать? Есть две тулзы:
Rego Playground
Она размещена в интернете авторами продукта и позволяет вести отладку онлайн. Она не всегда хорошо выполняет сложные проверки, но самое ценное её свойство для меня — готовая библиотека проверок, где можно подсмотреть какие-то идеи:

Плагин Visual Studio Code
Действительно прекраснейший плагин. В нем есть всё, что надо для средств разработки:
- Syntax check – проверка синтаксиса;
- Highlighting – подсветка;
- Evaluation – вычисления проверок;
- Trace – трассировка;
- Profile – профилирование;
- Unit tests – запуск юнит-тестов
Интеграция
Теперь надо это всё интегрировать. Есть два пути интеграции в OPA:
- Push-интеграция, когда через REST API помещаем наши проверки и внешние данные в Open Policy Agent:
curl -X PUT localhost:8181/v1/data/checks/ --data-binary @check_packages.rego
curl -X PUT localhost:8181/v1/data/checks/packages --data-binary @permitted_packages.json
- Pull-интеграция — OPA bundle server, которая мне очень нравится.
Представьте, у вас есть Open Policy Agent сервер, есть bundle-сервер (который надо написать самостоятельно) и есть данные по вашим проверкам:

В соответствии с конфигурацией Open Policy Agent сервер умеет ходить в bundle-сервер по фиксированному урлу и забирать данные, если они ещё не подготовлены. Далее он ожидает их приема в .gzip формате, полностью поддерживая спецификации кэширования — если вы в bundle-сервере реализовали обработку тэга ETag, то Open Policy Agent сервер не будет протаскивать мегабайты ваших проверок через сеть в случае неизменения:

Выполняем проверку. Open Policy Agent имеет прекрасный resfull API — после загрузки наших данных мы получаем имя пакета, который мы создали при создании файла, и имя правила. Дальше мы подаём для проверки наш артефакт в виде JSON. Если вы долго читали документацию, то поняли, что наш артефакт надо обрамить в input:

Обрабатываем результат (возвращённый JSON) где угодно — в Jenkins, admission controller, UI, whatever… Чаще всего результат приходит в таком виде:

Повторное и автоматическое использование проверок
Политики OPA у нас разработаны для тех проверок, которые не связаны с Kubernetes, и тех, что связаны с Kubernetes, но рекомендуются. Они хранятся в гите и через наш Bundle server, как и метаданные, попадают в Open Policy Agent. Мы пользуемся встроенными механизмами Open Policy Agent для Unit-тестирования и тестируем все наши проверки.
То есть Open Policy Agent проверяет сторонние артефакты (Java configs, K8S config, артефакты CI/CD), а те, которые надо заблокировать для попадания на кластеры, проходят через Gatekeeper, и в итоге наш кластер в безопасности. В принципе мы можем проверять всё что угодно, и смотреть результаты проверок через наш пользовательский интерфейс:

Чего мы добились:
- У нас есть 24 обязательных правила и 12 необязательных;
- 80 правил планируется к использованию в данном продукте;
- Автоматическая проверка одного проекта за 10-20 секунд.
Конечно, стоит подумать об Opensource Bundle-сервера и пользовательского интерфейса, потому что это дженерик-решение, и они никак не связаны с инфраструктурой Сбербанка.
Коррекции на основе проверок
Приведу пример банка Goldman Sachs. У них большой облачный кластер из 1800 namespace (12 общих кластера Kubernetes на виртуалках, в каждом кластере по 150 namespace). Всё это управляется из централизованной системы под названием Inventory, где находится информация:
- По безопасности (Security inventory): Roles, Rolebindings, Clusterroles, Clusterrolbindings;
- По управлению ресурсами (Capacity Inventory): cpu, memory через ResourceQuotas и LimitRange;
- По управлению дисками (NFS inventory): Persistent volumes и Persistent volume claims.
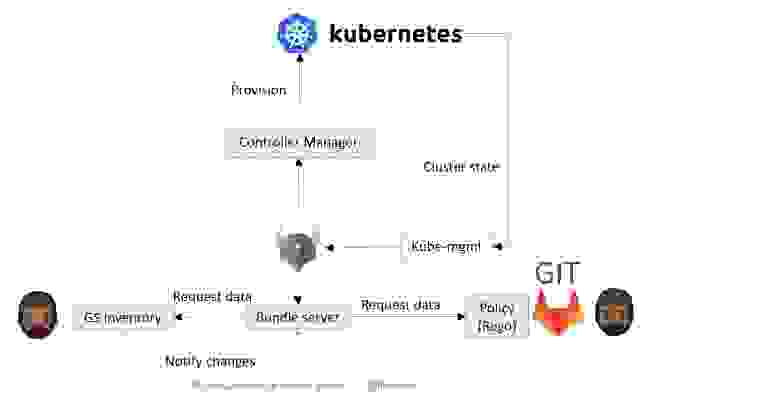
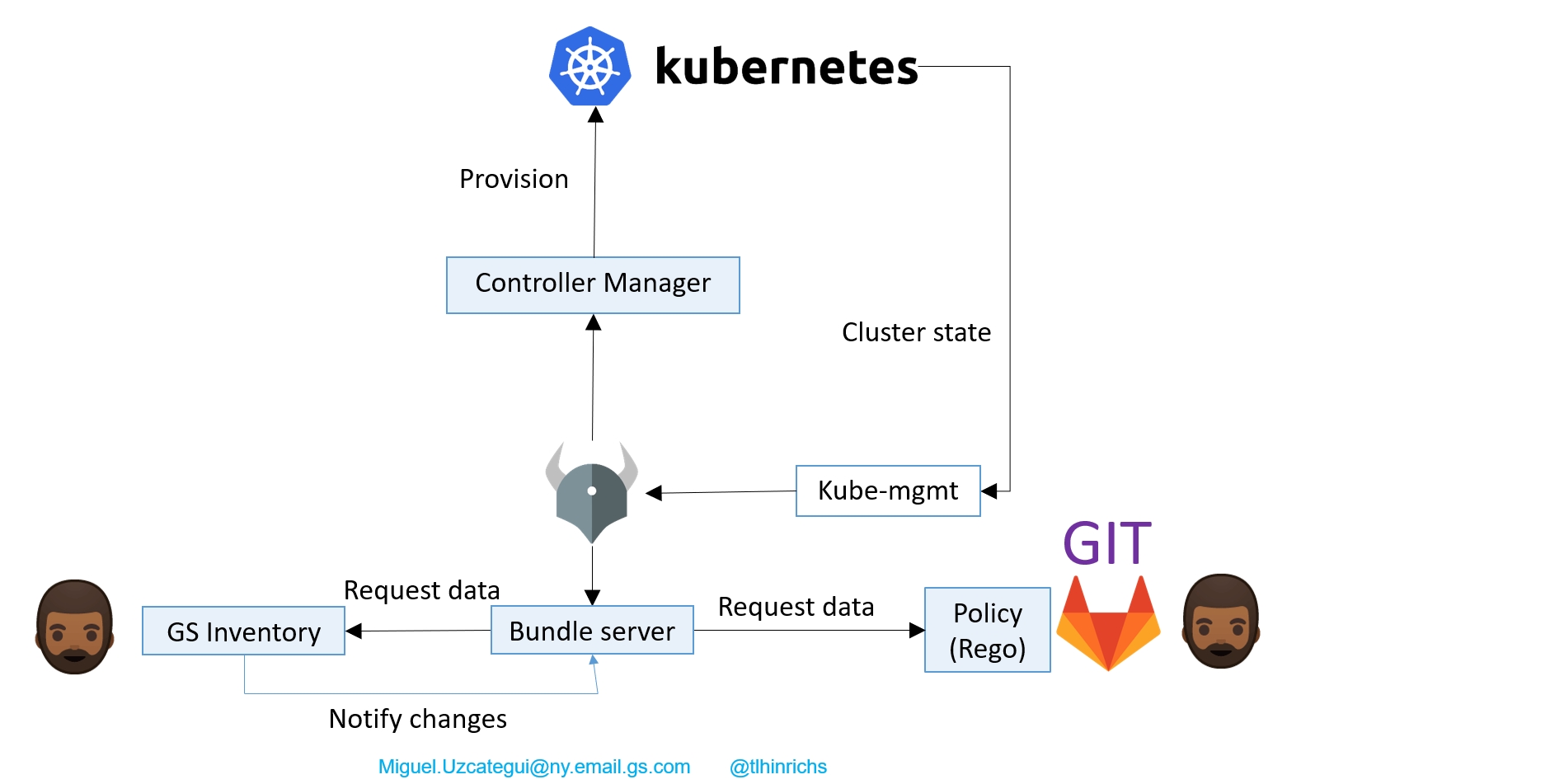
Коллеги используют такую архитектуру решения:
- Pull измененных политик и данных из гита и inventory через bundle-сервер;
- Создание объектов в K8S на основе данных, создаваемых OPA;
- Hand-made mutating admission controller — на основе JSON, возвращенного OPA, формируется YAML и прогоняется на кластере:
Всё состояние кластера синхронизируются в Bundle server с помощью плагина Kube-mgmt от разработчиков OPA. Bundle server через определенные периоды времени ходит в гит и забирает измененные политики.
Для самой системы Inventory процесс чуть-чуть другой. Она уведомляет Bundle server об изменениях, и он сразу же после этого идёт и забирает данные. Любое изменение вызывает запуск проверок, который вызывает создание JSON, а JSON переводится в YAML, прогоняется через Controller Manager и запускается на кластере.
Когда такая система стоит в продакшене, очень важно её мониторить. Коллеги мониторят 11 показателей, относящихся по большей части к garbage коллектору, Go и времени ответа от OPA-сервера:
- Go routine and thread counts;
- Memory in use (stack vs heap);
- Memory allocated (stack vs heap);
- GC stats;
- Pointer lookup count;
- Roundtrip time by http method;
- Percentage of requests under 500ms, 200ms, 50ms;
- Mean API request latency;
- Recommendations for alerting;
- Number of OPA instances up at any given time;
- OPA responding under 200ms for 95% of requests.
Что же удалось создать коллегам:
- 24 проверки;
- 1 Mb справочных данных по безопасности — 3500 правил;
- 2 Mb справочных данных по дискам и ресурсам — 8000 правил;
- Применение правила на кластере — от 2 до 5 минут — реально очень быстро.
Продвинутые проверки
Если мы хотим писать крутые, навороченные проверки, что же делать? Есть несколько способов — взять готовое или стать ещё более крутым.
Fugue
Мы можем использовать Fugue, который представляет движок политик как сервис (governance as a code as a service). Он проверяет конфигурации облаков Amazon, Azure, GCP. Представляете, насколько там сложные политики, что ему надо проверять не только Kubernetes, но и relational database services, VPC и т.д.? Фактически каждый из продуктов каталога Amazon и прочих облаков может быть проверен готовыми политиками.
Fugue работает как admission controller. Ещё одна из очень его больших ценностей — это наборы пресетов под регуляторы — PSI DSS, HIPAA, SOC, etc. Фактически вы делаете нужную инфраструктуру в Amazon, запускаете продукт и говорите: «Проверь на PSI DSS», — и вуаля, вы получаете фактически аудит.
Очевидно, что Fugue реализован на OPA, но так как политики очень сложные, коллеги реализовали свой интерпретатор Rego для отладки продвинутых проверок. Выполнение происходит на Open Policy Agent, а отладка уже на своем интерпретаторе. Так как это облачный продукт, у него прекраснейший пользовательский интерфейс, который позволяет понять, какие проверки пройдены, какие нет и процент их соответствия:

Набор правил действительно самый разнообразный — есть элементарнейшие вещи в стиле «на машине с RDS, если она гарантирует высокую доступность, должны быть использованы multi availability zone deployment»:

И есть гораздо более сложные, например, «если используется Elasticsearch от Amazon, то его пользовательский интерфейс не должен быть выставлен наружу»:

С Fugue можно ознакомиться на их сайте. Но гораздо интереснее их интерпретатор Rego и набор примеров, которые у них реализованы.
Fregot
Fregot — это очень живой продукт, который позволяет отлаживать проверки на Rego. За счет чего? У него упрощённый дебаг (breakpoints и watch variables) и расширенная диагностика по ошибкам, которая важна, когда вы будете пользоваться ванильной OPA — в этом случае чаще всего вы будете получать сообщение: var _ is unsafe, и вам будет абсолютно непонятно, что с этим делать:
Conftest
Это утилита проверки, использующая Open Policy Agent. Она содержит в себе потрясающе огромный встроенный набор конвертеров, и сама выбирает конвертер, исходя из расширения файла:

Ещё раз обратите внимание, насколько выразительный язык Rego — всего одной строкой мы проверяем, что нельзя запускать контейнер из-под root:

Дальше мы говорим: «conftest test», и указываем имя того объекта, который нам надо протестировать. И все проверки, которые есть в директории утилиты, проверяются по файлам, а вы получаете результат.
Плюсы:
- Большое количество конверторов файлов: YAML, INI, TOML, HOCON, HCL, HCL1, CUE, Dockerfile, EDN, VCL, XML.
- Много примеров проверок при работе с Open Policy Agent.
Минусы:
- Не могу сказать, что утилита стабильно работает
- Так как эта утилита командной строки, то она однопоточная, на продакшн ее не так круто применять.
Gatekeeper
Сейчас это Admission controller, а в будущем он будет работать как Mutating admission controller, который не только проверяет на условие, но и в случае прохождения условий меняет команду так, как ему надо:

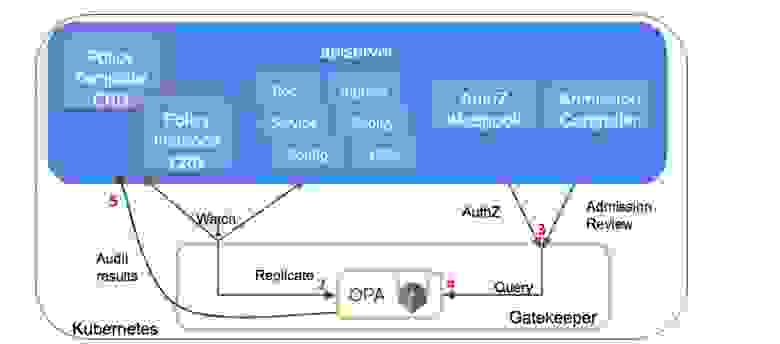
Admission controller встает между вашими командами и кластером Kubernetes. Вы отправляете команду, admission controller вызывает внешнюю проверку условий и, если условие выполнено, то команда запускается в кластере. Если не выполнено, то команда просто откатывается.
За счет чего обеспечивается повторное использование в продукте Gatekeeper? Есть два объекта:
- Policy Template – это механизм описания функций, где вы задаете текст проверки на Rego и набор входных параметров;
- Сама политика – это вызов функции с указанием значений параметров.
Gatekeeper синхронизирует в течение жизненного цикла своей работы весь кластер кубера в себя, а дальше любое действие кластера вызывает Webhook, по нему команда (YAML объект, каким он будет после применения изменения) приходит в Open Policy Agent. Дальше результат проверки возвращается как пропущенная, либо как нет.
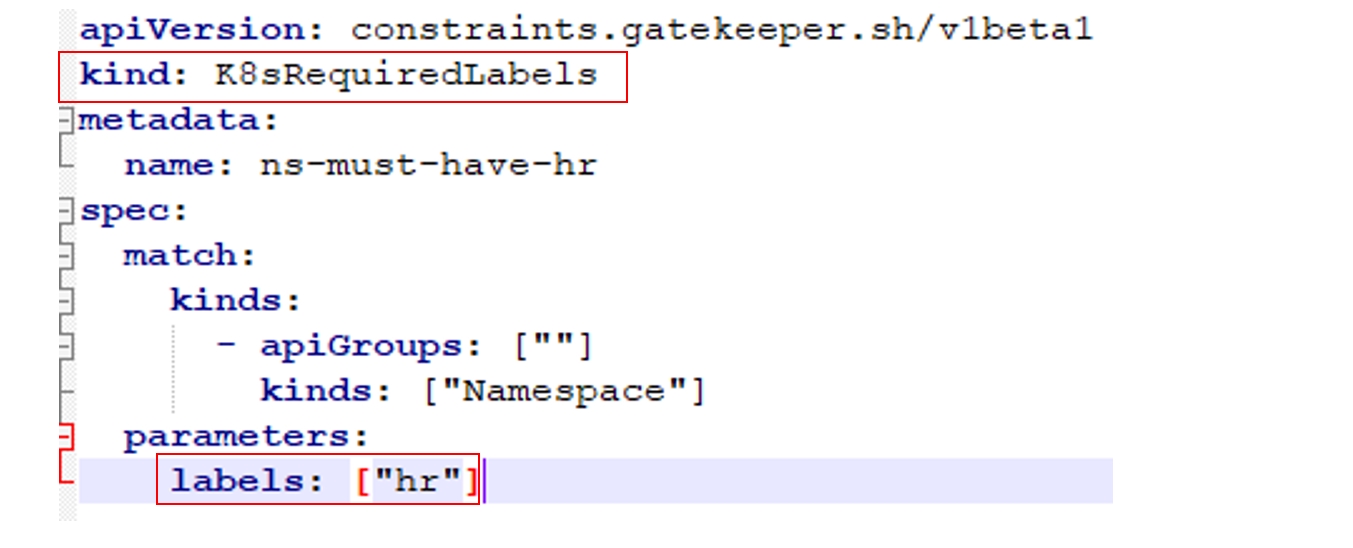
Пример проверки на Gatekeeper:

Это своя CRD, само собой. Мы даем ей имя и говорим, что входной параметр – это метки, которые представляют собой массив строк. Пишем на Rego нашу проверку, и в данном случае она проверяет, что для объектов заданы необходимые метки. Мы используем внутри Rego наши входные параметры — это тот самый template. А живая политика выглядит так: используй такой-то template и такие-то метки. Если у проекта не будет таких меток, то он просто в кластер не попадёт:
Плюсы:
- Великолепно работает повторное использование через template;
- Есть огромные готовые библиотеки проверок;
- Тесная интеграция с K8S.
В то же время эти плюсы становятся автоматически минусами:
- Нельзя запустить Gatekeeper без K8S;
- Нет юнит-тестов констрейнтов и темплейтов;
- Многословные CRD;
- Нет UI (пользовательского интерфейса);
- информацию для аналитики приходится получать через парсинг логов;
- Закрыта возможность вызова внешних сервисов;
- Нельзя использовать bundle server для помещения в него внешних данных;
- Функционал Mutation в процессе разработки, о чем регулярно напоминают разработчикам в их гите.
Что мы получили на выходе
Итак, фактически мы преобразовали уровни зрелости технологического контроля к готовому технологическому стеку:

OPA на практике — use cases
Как мы увидели, Open Policy Agent решает задачи проверки любых структурированных данных, а также коррекции проверенных данных. Хотя на самом деле Open Policy Agent позволяет делать гораздо больше, например, помогает решать задачи авторизации, задачи database row level security (sql databases, ElasticSearch), а некоторые даже пишут на нём даже игры (Corrupting the Open Policy Agent to Run My Game).
Рассмотрим несколько примеров.
OPA as a sidecar
У коллег в Pinterest всё развернуто в Amazon, поэтому у них принят подход Zero-trust security и, само собой, все реализовано на OPA. Под его контролем находится всё, что связано с Kubernetes, с виртуальными машинами, авторизацией в Kafka, а также с авторизацией на Envoy.
Таким образом их нагрузка колеблется от 4.1M до 8.5M QPS в секунду. При этом имеется кэш с длительностью жизни 5 минут. В Open Policy Agent приходит от 204 до 437 тысяч в секунду запросов — действительно большие цифры. Если вы хотите работать с такими порядками, надо конечно думать о производительности.
Что я рекомендую в этой части:
- Network footprint — подумать о тех нюансах, которые приносит сеть.
- OPA library single-thread — если вы используете Open Policy Agent не как сервер, а как библиотеку, то библиотека будет однопоточной.
- Use OPA server instead – multi-thread — вам придется делать многопоточность вручную.
- Memory for data – 20x from raw data — если у вас есть 10 МБ внешних данных каких-нибудь JSON-справочников, то они превратятся в 200 МБ на сервере.
- Partial evaluation – ms to ns — вам надо разобраться, как работает его фишка механизма предрасчета, фактически компилирование статической части проверок.
- Memory for partial evaluation cache — вам надо понимать, что для всего этого требуются кэши.
- Beware arrays — с массивами Open Policy Agent работает не так хорошо.
- Use objects instead — и именно поэтому коллеги с Amazon транслировали массивы в объекты.
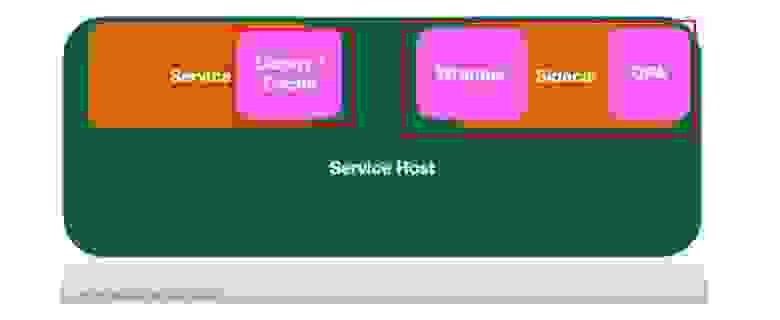
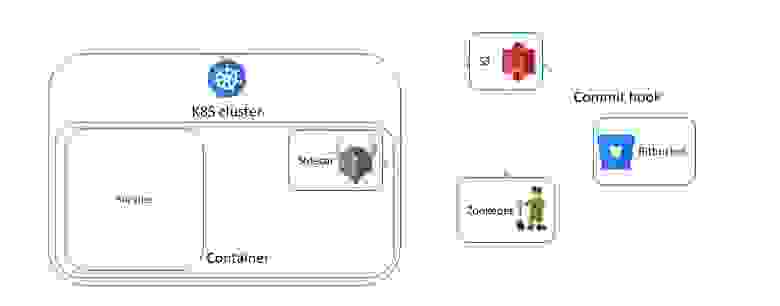
Как же коллеги из Pinterest решили эти задачи? На каждом сервисе или каждом хосте, или ноде у них расположен Open Policy Agent как sidecar, и работают они с ним через библиотеку, а не напрямую через REST, как показывал я. В той самой библиотеке находится кэш с временем жизни 5 минут:

Очень интересно, как происходит у них доставка политик. Есть кластер, есть Bitbucket, а дальше данные из него хуками на коммит пробрасываются на S3. Так как запись в него асинхронна в принципе, то результат идет в Zookeeper, а он уведомляет Sidecar об изменениях. Sidecar забирает данные из S3, и всё прекрасно:

OPA authorization
Задачи авторизации становятся все более актуальными, и все больше разработчиков получают запросы, чтобы включить Open Policy Agent в их продукты… Многие уже это сделали: например, Gloo в своей энтерпрайз-версии использует Open Policy Agent как движок для авторизации.

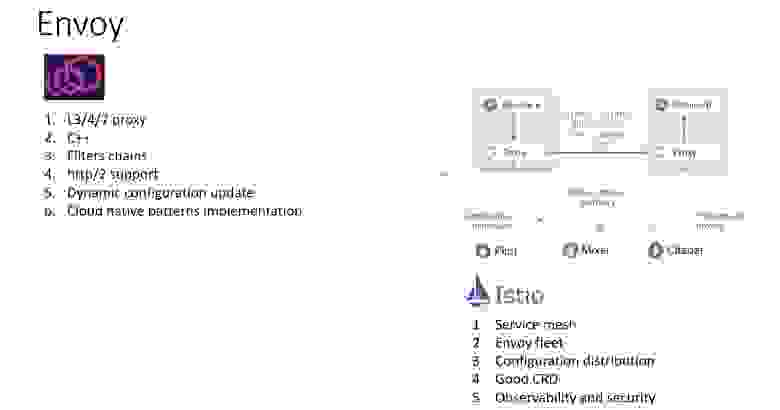
Но можно это сделать по-другому. Наверное, все знают, что такое Envoy. Это легковесный прокси, в котором есть цепочки фильтров. Envoy крут тем, что позволяет обеспечивать дистанционное управление конфигурацией. Собственно, отсюда и появился термин service mesh:

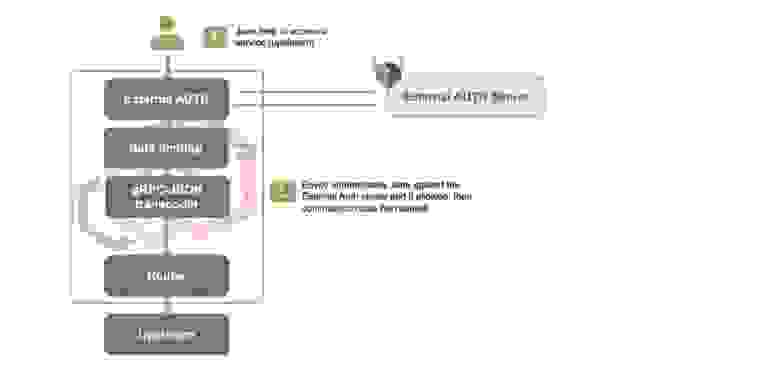
На Envoy мы можем опубликовать Open Policy Agent сервер снаружи и настроить так называемые фильтры внешней авторизации. Далее любой запрос от пользователя вначале попадает на Envoy, проверяется им, и только после этого отправляется наружу:

Penetration testing
На самом деле авторизация — это всегда о безопасности. Поэтому в 2018 году было проведено Penetration-тестирование: 6 человек в течение 18 дней пытались взломать Open Policy Agent. Результаты тестирования говорят, что OPA — это действительно безопасное решение:

Конечно, были ошибки:
Identified Vulnerabilities
OPA-01-001 Server: Insecure Default Config allows to bypass Policies (Medium)
OPA-01-005 Server: OPA Query Interface is vulnerable to XSS (High)
Miscellaneous Issues
OPA-01-002 Server: Query Interface can be abused for SSRF (Medium)
OPA-01-003 Server: Unintended Behavior due to unclear Documentation (Medium)
OPA-01-004 Server: Denial of Service via GZip Bomb in Bundle (Info)
OPA-01-006 Server: Path Mismatching via HTTP Redirects (Info) Conclusions Introduct
Но это были те ошибки, которые случаются по большей части от того, что есть проблемы с документацией:
What is more, the shared documentation was unclear and misleading at times (see OPA-01-001), so that arriving at a secure configuration and integration would require a user to have an extensive and nearly-internal-level of knowledge. As people normally cannot be expected “to know what to look for”, this poses a risk of insecure configurations.
OPA – не экзотика
Из того, что я сказал, может создаться ощущение, что Open Policy Agent – это странный, непонятный, никому не нужный продукт. На самом деле в Open Policy Agent полно фишек, которые еще никто не использует:
- Юнит-тестирование;
- Трейсинг, профайлинг и бенчмаркинг;
- Механизмы ускорения производительности Conditional evaluation;
- Возможность обращения к внешним http-сервисам;
- Работа с JWT-токенами.
Есть только одна проблема — документация не объясняет, зачем это надо. В Google, скорее всего, вы тоже ничего не найдете. Например, мы хотим понять, как же работает политика изнутри:

Идем по первой же ссылке и попадаем всего лишь в функцию, которая выводит отладочную информацию, не имеющую никакого отношения к тому, как же политика выполняется:

Но если поковыряться с утилитой repl, которая входит в состав OPA, абсолютно случайно можно найти функцию trace, про которую, конечно же, ничего не сказано в документации. Именно она фактически показывает план выполнения проверки, с которым очень легко работать и отлаживаться:
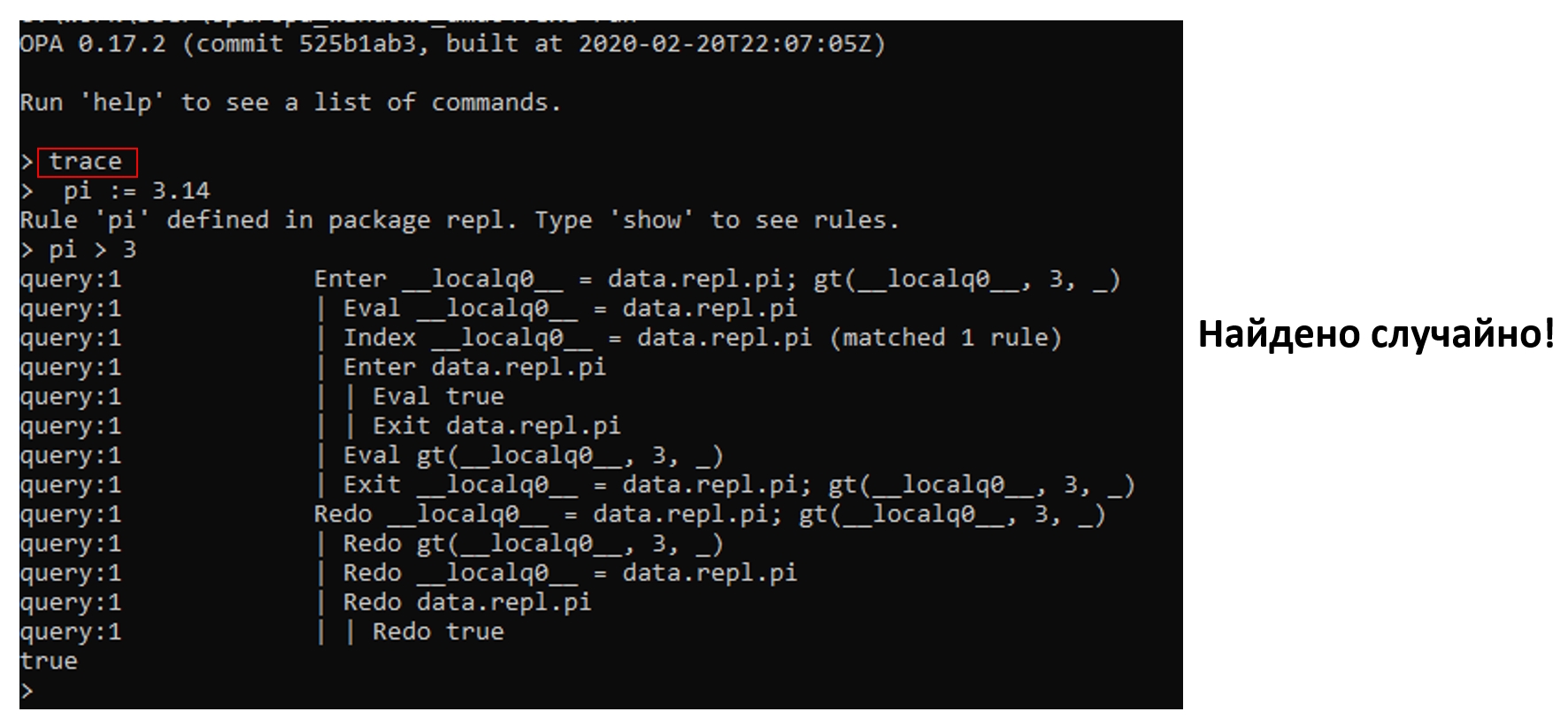
Open Policy Agent находится под крылом CNCF, и он более чем живой. В итоге хотелось бы сказать, что да, по данному продукту сложно найти информацию даже в объемной и неоднозначной документации. Но продукт активно развивается, живет не только в контейнерах, его можно использовать в абсолютно разных кейсах. И он действительно безопасен, как показали Penetration-тесты.
Если вы хотите его использовать, вам придется создавать UI и научиться писать правила на языке, близком к естественному, а не на языке кода. Учите Rego и используйте Fregot для дебага.
Помните, что Гугл, скорее всего, вам не поможет.
Тем временем мы готовимся к конференции HighLoad++, которая состоится офлайн 9 и 10 ноября в Москве (Сколково). Это будет наша первая очная встреча после 9 месяцев онлайнового общения.
HighLoad++ — это 3000 участников, 160 докладов, 16 параллельных треков докладов, мастер-классов и митапов. Единственная конференция, где за два дня можно узнать, как устроены Facebook, ВКонтакте, Одноклассники, Яндекс, Mail.ru, Amazon, Badoo, Авито, Alibaba и другие крупнейшие компании.
А в этом году главная задача HighLoad++ — выяснить пределы технологий. Как обычно, каждый доклад будет о решении конкретной задачи.Если есть что-то достойное в мире технологий, то это точно будет на HighLoad++ :)
Новости и подборки докладов мы публикуем в рассылке и в telegram-канале @HighLoadChannel — подпишитесь, чтобы быть в курсе обновлений.

