
Сегодня мы запускаем Rekko Challenge 2019 — соревнование по машинному обучению от онлайн-кинотеатра Okko.
Мы предлагаем вам построить рекомендательную систему на реальных данных одного из крупнейших российских онлайн-кинотеатров. Уверены, что эта задача будет интересна и новичкам, и опытным специалистам. Мы постарались сохранить максимальный простор для творчества, при этом не перегружая вас гигабайтными датасетами с сотнями предварительно посчитанных признаков.
Подробнее про Okko, задачу, данные, призы и правила — ниже.
Задача
Вам доступны данные обо всех просмотрах, рейтингах и добавлениях в «Запомненное» фильмов и сериалов пользователем за некоторый период в N дней (N > 60), а также вся метаинформация о контенте. Необходимо предсказать, какие фильмы и сериалы пользователь купит или посмотрит по подписке за следующие 60 дней.
В следующем разделе мы попытались описать минимум того, что вам необходимо знать об онлайн-кинотеатрах, чтобы быстро разобраться в данных и приступить к их анализу. Если же эта информация для вас не актуальна, можете сразу переходить к описанию данных.
О нашем сервисе
Если пользователь хочет легально смотреть кино в интернете, у него есть три основных пути.
Первый путь — смотреть бесплатно, постоянно прерываясь на рекламные ролики (AVOD, Advertising Video On Demand). Второй — купить фильм к себе в коллекцию или арендовать (TVOD, Transactional Video On Demand). Третий — оформить подписку на определённый период (SVOD, Subscription Video On Demand).
Okko работает только по моделям TVOD и SVOD. В нашем сервисе совсем нет рекламы.
Всего в сервисе чуть больше 10 тысяч фильмов и сериалов, около 6 тысяч из них доступны по подписке, остальные только для покупки или аренды. При этом, почти любой подписной контент можно купить. Исключение составляют, например, сериалы Amediateka, их можно смотреть только по подписке.
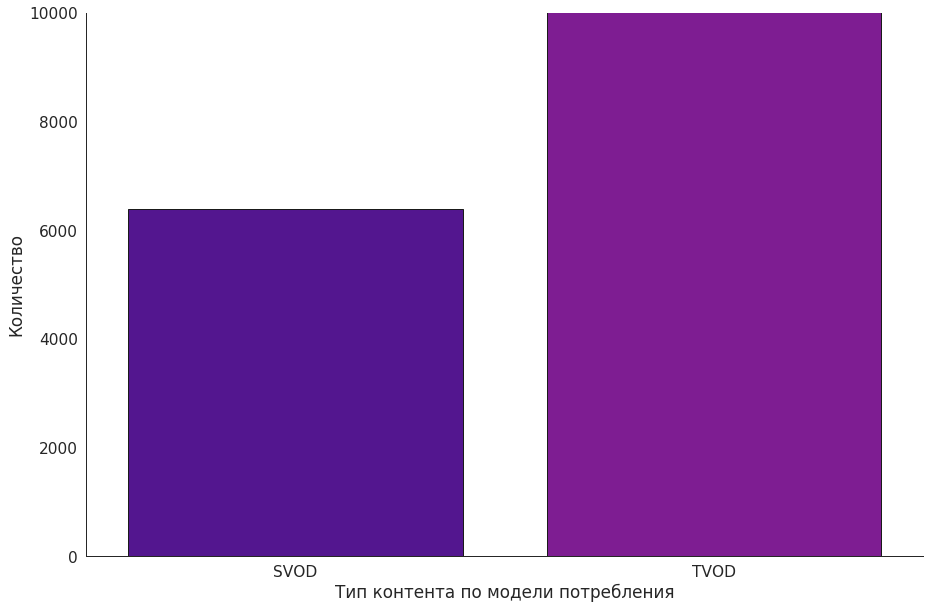
По какой модели будет доступен фильм, во многом зависит от студии, владеющей правами. Они заключают с онлайн-кинотеатрами контракт, в котором оговорено, в какие сроки и по каким правам фильм будет доступен. Как правило, условия одинаковы для всех игроков рынка, но иногда студии идут на уступки некоторым кинотеатрам или предлагают более выгодные условия за бо́льшие деньги. Так появляются эксклюзивы.
Например, крупные мировые новинки попадают в подписку не сразу, а только спустя 2-3 месяца после появления в сервисе. Более того, в первые несколько недель их нельзя даже взять в аренду, доступна только возможность покупки навсегда. А вот российские фильмы могут быть доступны по подписке сразу после выхода и иногда даже одновременно со стартом проката в оффлайн-кинотеатрах.
Когда контракт истекает, фильм становится недоступен — до пролонгирования истекшего контракта или заключения нового.
Периоды отсутствия прав на контент хорошо заметны на графиках количества просмотров. Ниже, например, представлен такой график для фильма «Джон Уик 2». Первым делом может показаться, что хадуп прилёг отдохнуть на пару месяцев, но нет: закончились права.
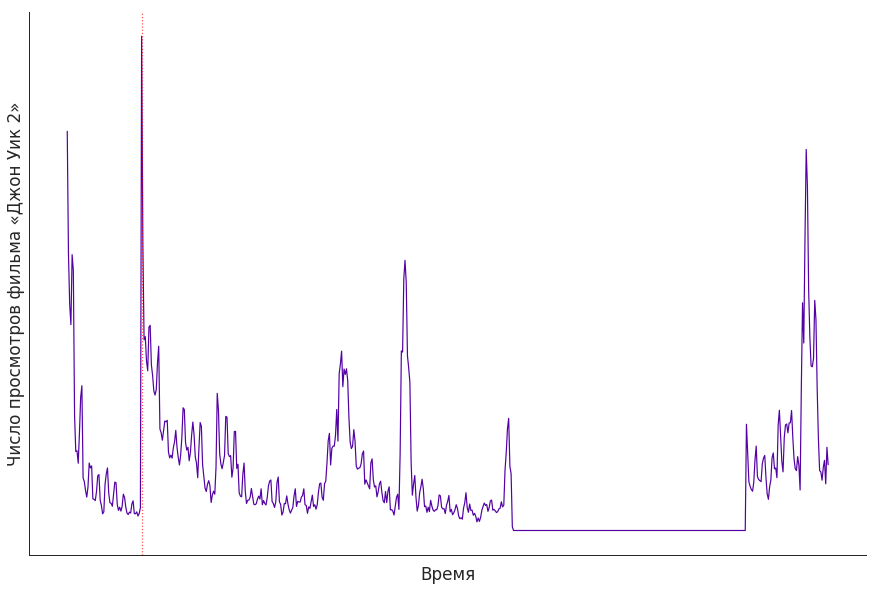
Самый высокий пик на графике выше (отмечен вертикальной линией) совпадает с датой добавления фильма в подписку: это весьма характерное поведение для громких новинок. В нашем сервисе 12 подписок:
- Восемь тематических,
- Сериалы Amediateka,
- Сериалы ABC,
- Российские фильмы и сериалы от сервиса «START»,
- Фильмы в 4K.
И два пакета подписок: «Оптимальный», который включает все тематические подписки, и «Оптимальный + Amediateka».
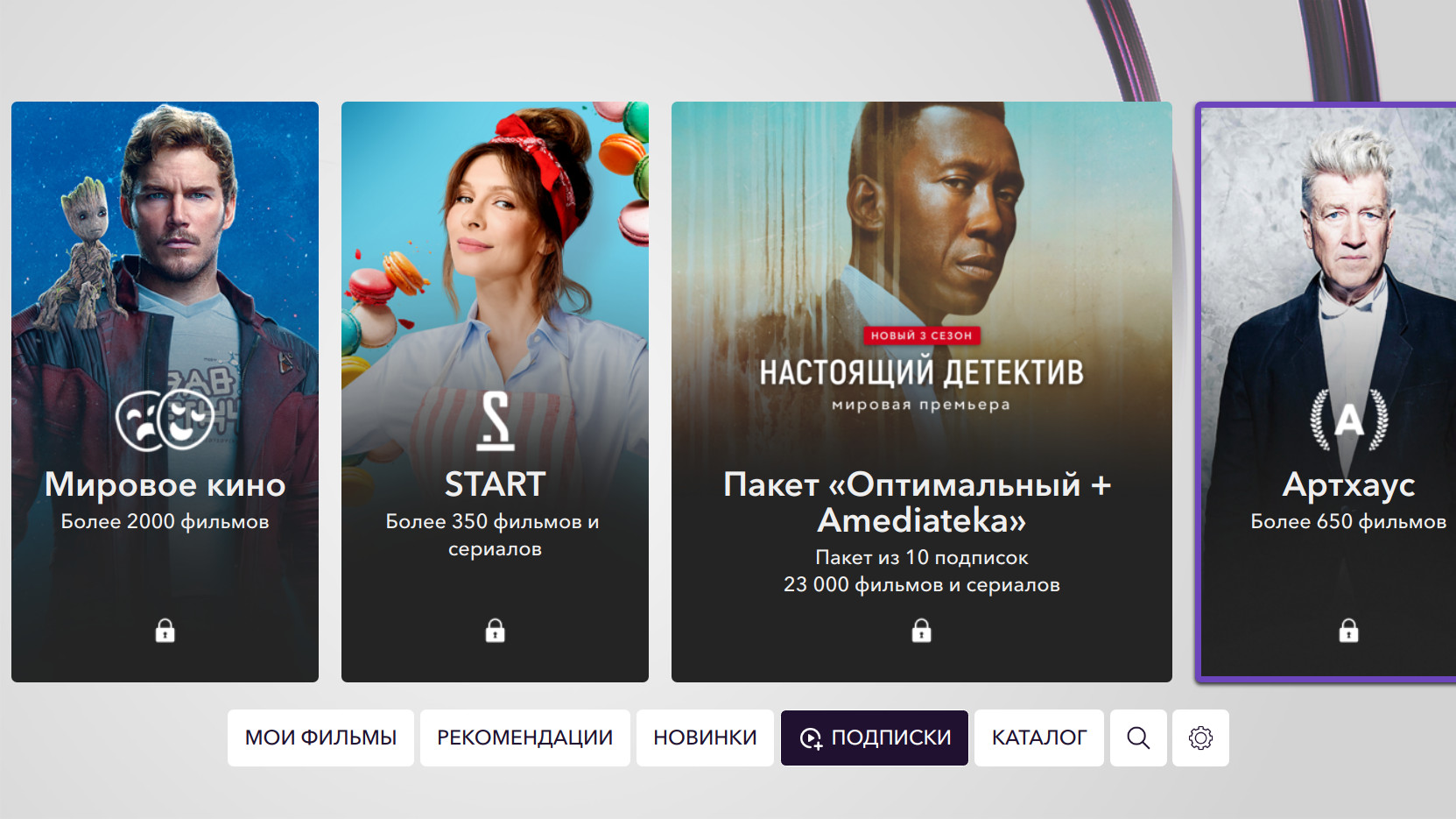
Самыми популярными, естественно, являются мета-пакеты. Из тематических подписок пользователи предпочитают «Мировое кино» и «Наше кино».

Немногие пользователи смотрят кино только по подписке, большинство либо только покупает фильмы, либо докупает в дополнение к подписке.
Чаще всего пользователи выбирают для покупки новинки текущего проката и крупные премьеры прошлого года.
Самый популярный источник покупок в приложении — раздел «Рекомендации», следом за ним идут «Поиск», «Новинки» и «Каталог». Часть фильмов пользователи покупают из «Похожих» и «Запомненных».

Одна из главных проблем, с которыми мы в Okko активно боремся, — проблема выбора пользователями контента. Если посмотреть на график вероятности совершения покупки от времени нахождения в сервисе (данные за прошлый год), станет видно, что пользователи готовы выбрать и купить фильм в течении первых 10 минут, затем вероятность покупки стремительно падает. При этом остаётся достаточно большая часть пользователей, которые проводят в сервисе от получаса до часа и не могут выбрать подходящий для себя контент.
10 минут — не так уж и много. За это время пользователь чисто физически не может подробно изучить каталог и выбрать тот контент, который ему по душе.
Тут в дело вступает Rekko — внутренняя рекомендательная система онлайн-кинотеатра Okko. Rekko в данный момент работает в двух разделах сервиса — «Рекомендации» и «Похожие».
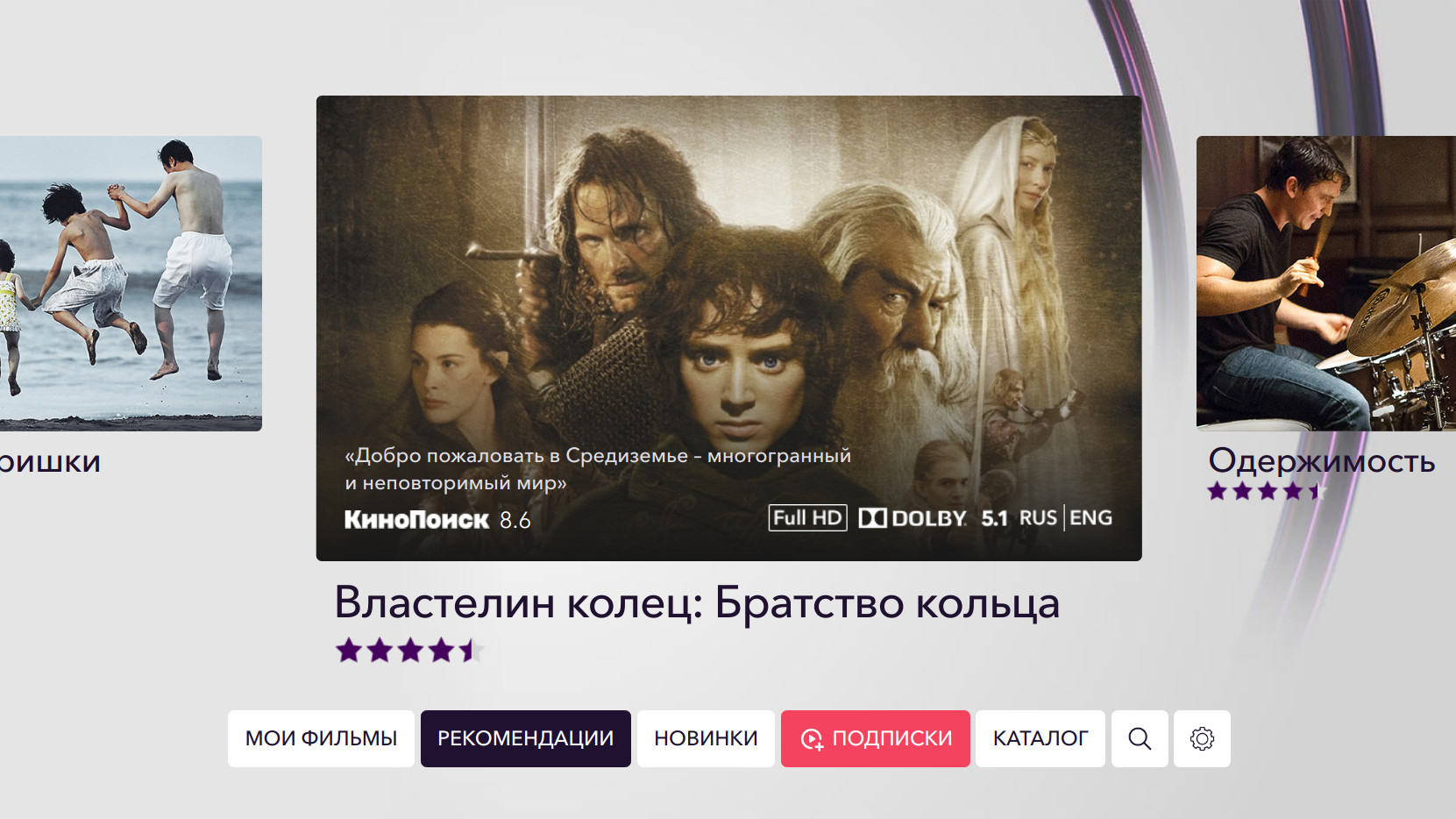
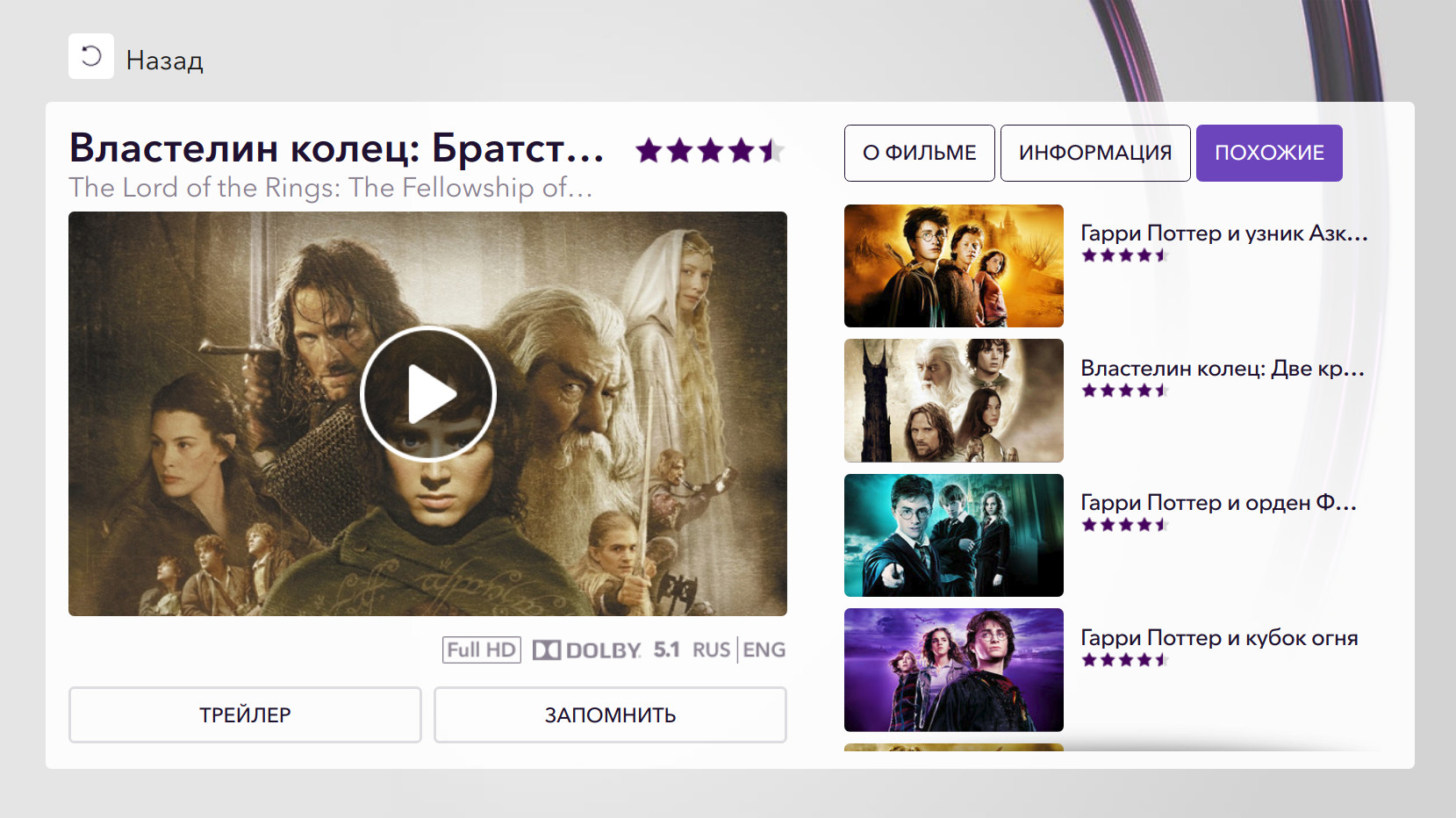
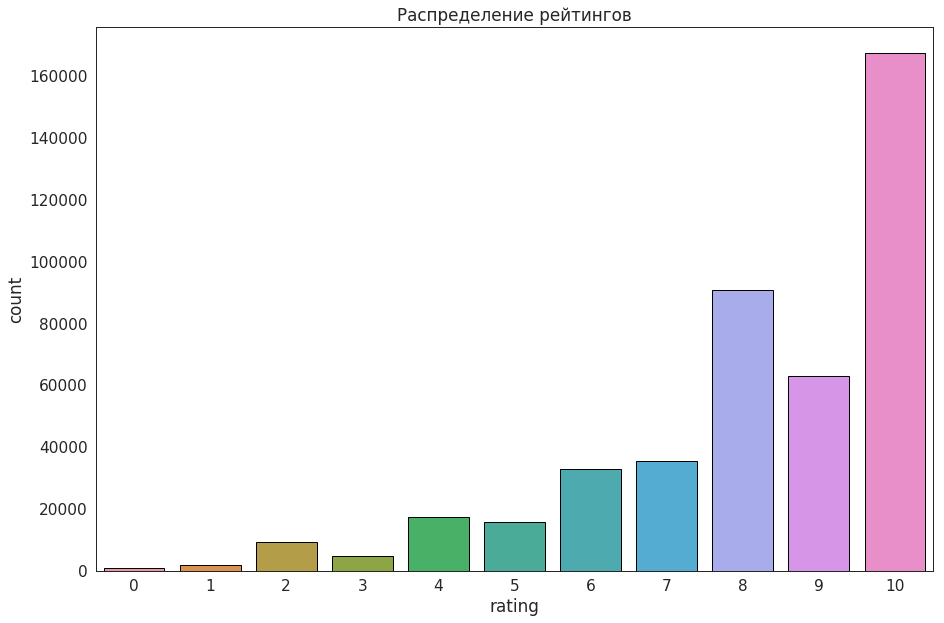
Чтобы оценить удовлетворенность пользователя контентом, мы анализируем факт покупки, просмотры по подписке, время просмотра, добавление в «Запомненные» и пользовательский рейтинг.
Шкала оценок в Okko представлена пятью звездочками с половинными делениями: она принимает целые значения от 0 до 10.
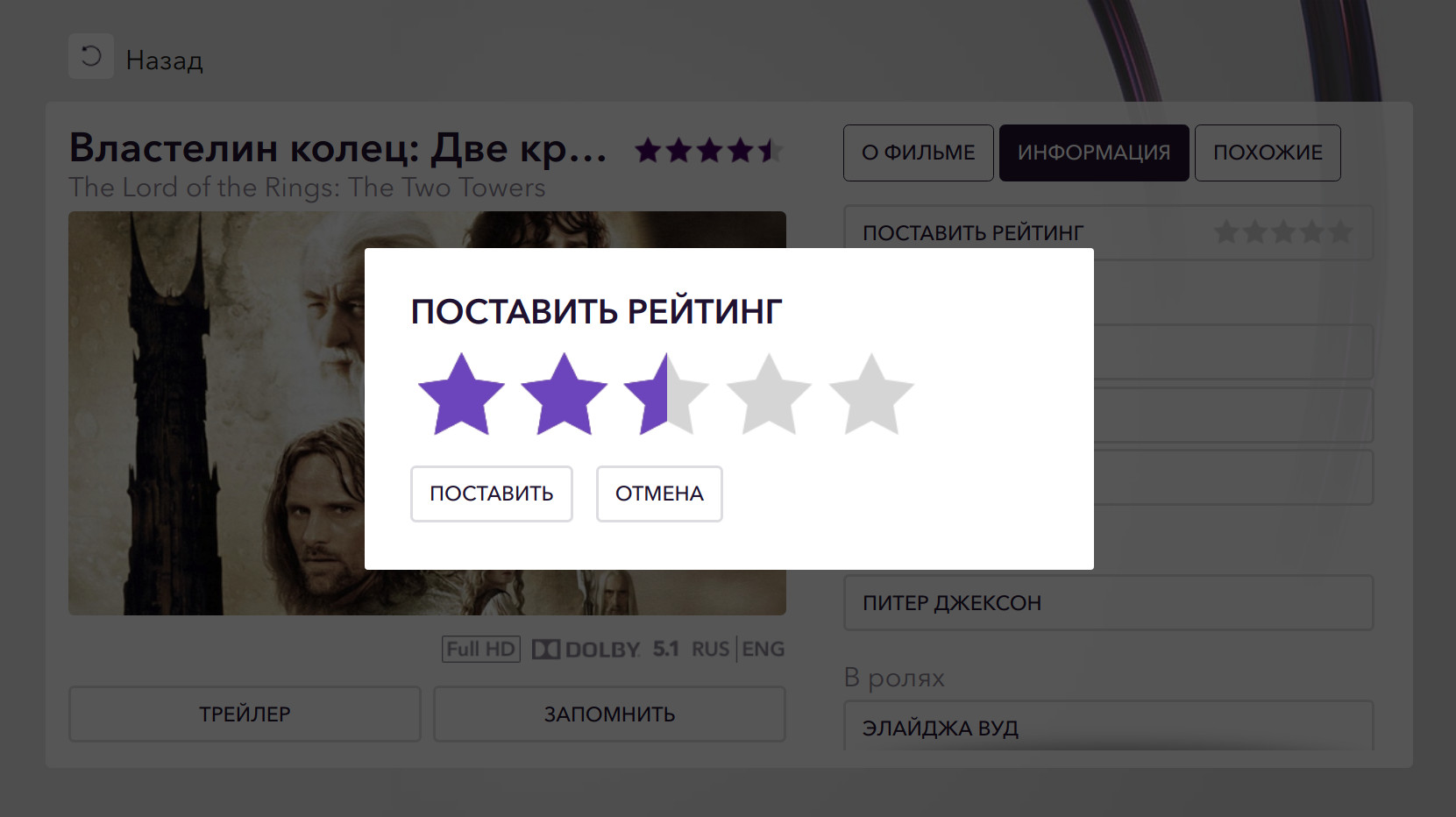
Пользователь может поставить фильму оценку в любой момент независимо от факта покупки или просмотра. Оценку можно изменить неограниченное число раз, но нельзя отменить.
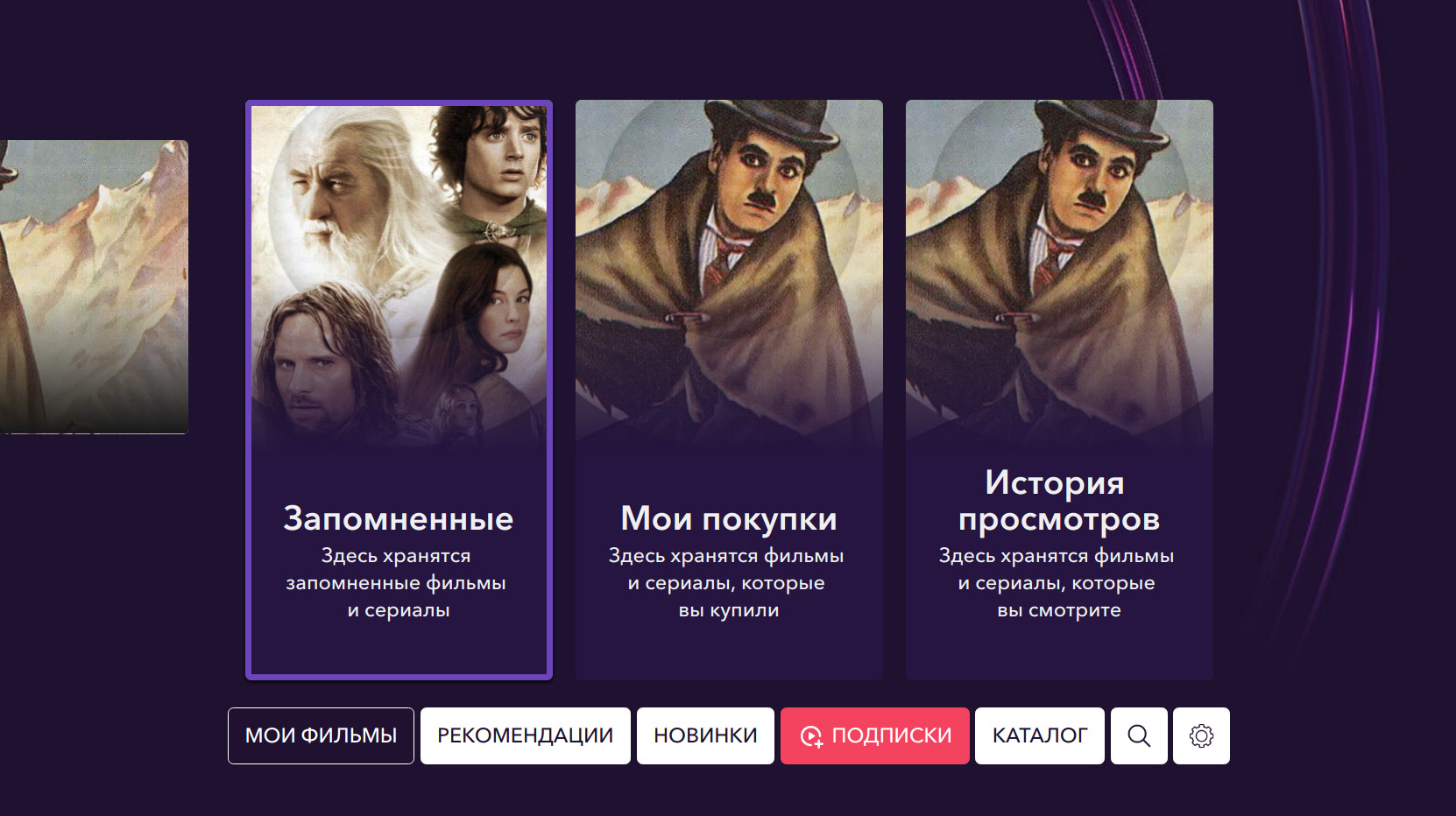
«Запомнить» фильм можно в любой момент, тогда он появится в «запомненных» в профиле пользователя. Точно так же его можно оттуда удалить.

Работы над Rekko начались ровно год назад и на данный момент по данным A/B тестов она позволила нам увеличить среднее число покупок на 4%, транзакционную выручку на 3%, конверсию в подписку на 5%, а пользователи стали выбирать фильмы на 18% быстрее.

Данные
Все данные, кроме времени просмотра и рейтингов, анонимизированны либо искажены. Время выражено в абстрактных единицах, для которых сохранены отношение порядка и расстояние.
transactions.csv
Записи обо всех транзакциях и просмотрах контента по ним за тренировочный период. Транзакцией здесь считается покупка фильма навсегда либо в аренду или инициация просмотра по подписке.
| element_uid | user_uid | consumption_mode | ts | watched_time | device_type | device_manufacturer |
|---|---|---|---|---|---|---|
| 3336 | 5177 | S | 44305181.2180206 | 4282 | 0 | 50 |
| 481 | 593316 | S | 44305180.606027626 | 2989 | 0 | 11 |
| 4128 | 262355 | S | 44305180.41444582 | 833 | 0 | 50 |
element_uid— идентификатор элементаuser_uid— идентификатор пользователяconsumption_mode— тип потребления (P— покупка,R— аренда,S— просмотр по подписке)ts— время совершения транзакцииwatched_time— число просмотренных пользователем по данной транзакции секундdevice_type— анонимизированный тип устройства, с которого была совершена транзакцияdevice_manufacturer— анонимизированный производитель устройства, с которого была совершена транзакция

ratings.csv
Сведения о поставленных пользователями оценках за тренировочный период. Информация агрегированная, т.е. если пользователь менял свою оценку, в таблице будет представлено только последнее значение.
| user_uid | element_uid | rating | ts |
|---|---|---|---|
| 571252 | 1364 | 10 | 44305174.26309871 |
| 63140 | 3037 | 10 | 44305139.28281821 |
| 443817 | 4363 | 8 | 44305136.20584908 |
element_uid— идентификатор элементаuser_uid— идентификатор пользователяrating— поставленный пользователем рейтинг (от0до10)ts— время постановки рейтинга
bookmarks.csv
Факты добавления пользователями фильма в «запомненные». Информация агрегированная, т.е. если пользователь удалил фильм из «Запомненных», записи о добавлении его туда в таблице не будет.
| user_uid | element_uid | ts |
|---|---|---|
| 301135 | 7185 | 44305161.30743926 |
| 301135 | 4083 | 44305160.01187332 |
| 301135 | 10158 | 44305157.74463292 |
element_uid— идентификатор элементаuser_uid— идентификатор пользователяts— время добавления фильма в «запомненные»
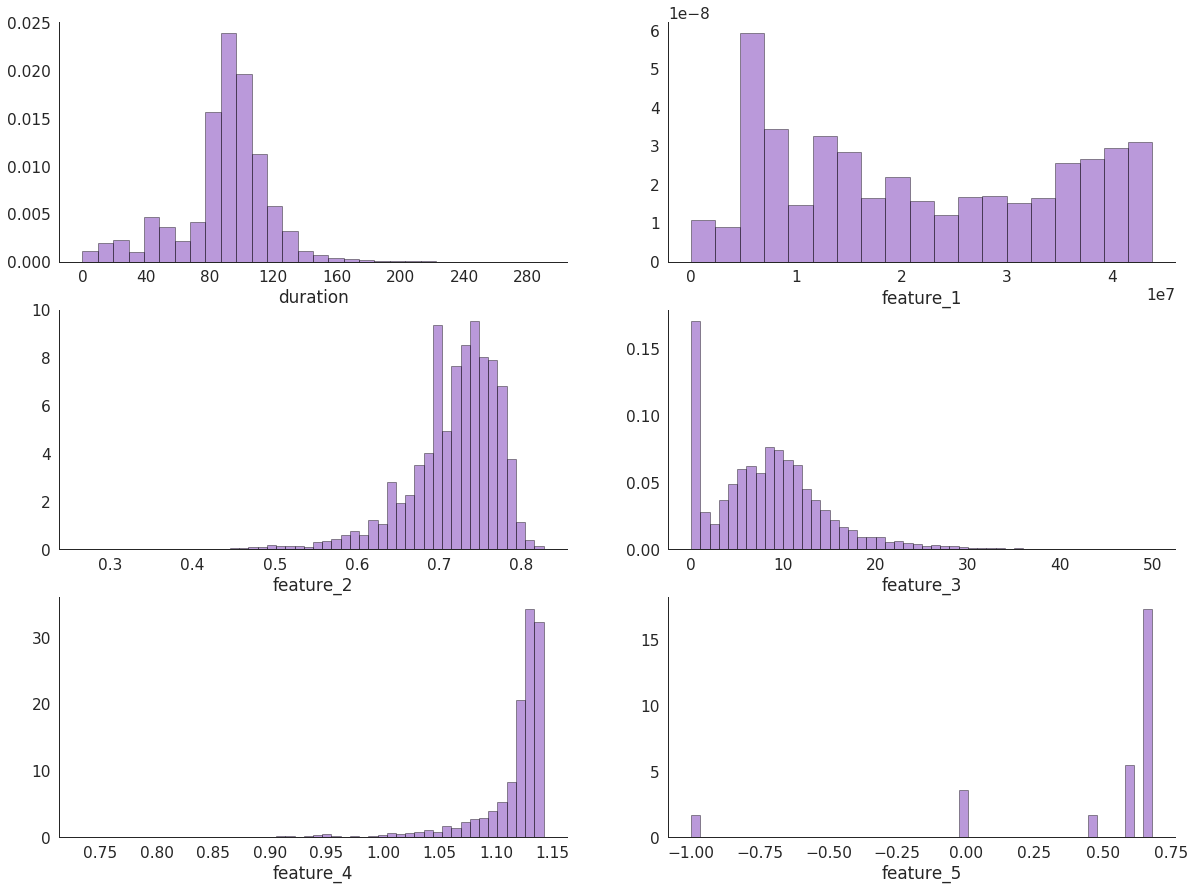
catalogue.json
Метаинформация обо всех рекомендуемых элементах: фильмах, сериалах и многосерийных фильмах.
{
"1983": {
"type": "movie",
"availability": ["purchase", "rent", "subscription"],
"duration": 140,
"feature_1": 1657223.396513469,
"feature_2": 0.7536096584,
"feature_3": 39,
"feature_4": 1.1194091265,
"feature_5": 0.0,
"attributes": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, ...]
},
"2166": {
"type": "movie",
"availability": ["purchase", "rent"],
"duration": 110,
"feature_1": 36764165.87817783,
"feature_2": 0.7360206399,
"feature_3": 11,
"feature_4": 1.1386044027,
"feature_5": 0.6547073468,
"attributes": [16738, 13697, 1066, 1089, 7, 5318, 308, 54, 170, 33, ...]
},
...
}type— принимает значенияmovie,multipart_movieилиseriesduration— длительность в минутах, округлённая до десятков (продолжительность серии для сериалов и многосерийных фильмов)availability— доступные права на контент (может содержать значенияpurchase,rentиsubscription)attributes— мешок некоторых анонимизированных атрибутовfeature_1..5— пять анонимизированных вещественных и порядковых признаков
Доступные права указаны на момент окончания тренировочного периода и начала тестового.
Важно: в json ключами словаря могут быть только строки, так что не забудьте привести их к числу, если считываете идентификаторы в таблицах как числа (делайте так для экономии памяти).
Метрика
В качестве метрики мы используем Mean Average Precision (MAP) для 20 элементов, но немного модифицированный. За тестовый период пользователь мог потребить меньше 20 фильмов. Если в таком случае считать честный MAP, верхняя граница метрики будет меньше единицы, а значения маленькие. Поэтому, если пользователь потребил меньше 20 элементов, нормируем мы на их количество, а не на 20.


 — находится ли
— находится ли  -ый предсказанный элемент в множестве потреблённых за тестовый период элементов пользователем
-ый предсказанный элемент в множестве потреблённых за тестовый период элементов пользователем  ,
,  — размер этого множества. Если вдруг подзабыли метрики качества ранжирования, на хабре про них есть отличная статья.
— размер этого множества. Если вдруг подзабыли метрики качества ранжирования, на хабре про них есть отличная статья.
def average_precision(
dict data_true,
dict data_predicted,
const unsigned long int k
) -> float:
cdef:
unsigned long int n_items_predicted
unsigned long int n_items_true
unsigned long int n_correct_items
unsigned long int item_idx
double average_precision_sum
double precision
set items_true
list items_predicted
if not data_true:
raise ValueError('data_true is empty')
average_precision_sum = 0.0
for key, items_true in data_true.items():
items_predicted = data_predicted.get(key, [])
n_items_true = len(items_true)
n_items_predicted = min(len(items_predicted), k)
if n_items_true == 0 or n_items_predicted == 0:
continue
n_correct_items = 0
precision = 0.0
for item_idx in range(n_items_predicted):
if items_predicted[item_idx] in items_true:
n_correct_items += 1
precision += <double>n_correct_items / <double>(item_idx + 1)
average_precision_sum += <double>precision / <double>min(n_items_true, k)
return average_precision_sum / <double>len(data_true)
def metric(true_data, predicted_data, k=20):
true_data_set = {k: set(v) for k, v in true_data.items()}
return average_precision(true_data_set, predicted_data, k=k)Призы и правила
Призовой фонд составляет 600 тысяч рублей:
- 300 тысяч получит победитель,
- 200 тысяч — участник на втором месте,
- 100 тысяч — участник на третьем месте.
Правила стандартные: не нарушать работу платформы, использовать только один аккаунт, избегать приватного обмена кодом с другими участниками и не быть сотрудником Okko и Rambler.
Как начать
Начать участвовать в соревновании может быть трудно даже для опытных специалистов: необходимо быстро разобраться в новой доменной области, понять и проанализировать данные, разобраться в новых библиотеках.
Надеемся, что в данной статье мы смогли погрузить вас в тематику онлайн-кинотеатра и достаточно подробно описать данные. В архиве с задачей вы найдёте файл baseline.ipynb, который содержит код для загрузки данных и пример простого решения с помощью алгоритма K ближайших соседей.
Если какие-то моменты из описания данных и доменной области остались непонятными, мы с радостью ответим на ваши вопросы в комментариях. Задать вопросы можно также в телеграм-канале @boosterspro — там будет проходить основное обсуждение соревнования.
Итак, как начать:
- Зарегистрируйтесь на boosters.pro и вступите в @boosterspro;
- Скачайте данные на странице соревнования или здесь;
- Откройте
baseline.ipynb, установите нужные пакеты, исполните весь код и загрузите ваше первое решение; - Попытайтесь изменить baseline, чтобы улучшить показатели;
- Экспериментируйте!
Rekko Challenge стартует сегодня, 18 февраля. Решения принимаются до 18 апреля 23:59:59 по московскому времени.
Ждём всех и желаем удачи!
Кстати, мы ищем сотрудников. В том числе и разработчика рекомендательных систем.
UPD 26.02.2019: Нашли баг в формировании тестовых данных, заменили их и файл test_users.json. Всем участникам предоставлены дополнительные попытки.
