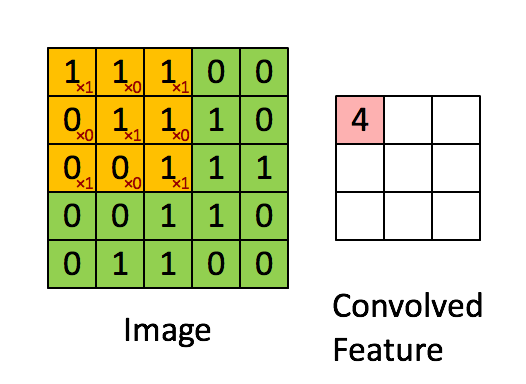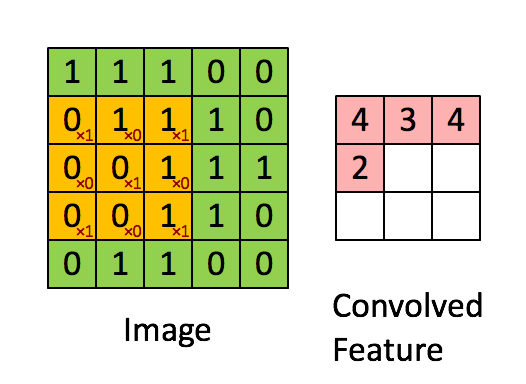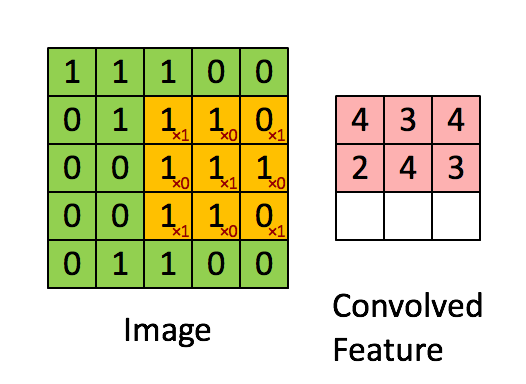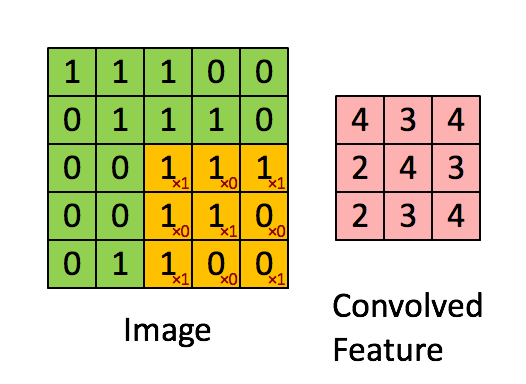
Главнокоммивояжер Аристарх поглядывал на Пророка, покручивая дубинкой от снежных троллей — ходовым сезонным товаром — 11% отклонение прогноза продаж на 10 дней в среднем (MAPE) впечатлило и, как у нас в чате говорят, зашло в роли baseline. Если он так же хорош, как и их Цукерберг, то сразу в прод — таков был первый порыв. Пророк поглядывал на главнокоммивояжера, прищурив правый глаз. Такой серьезный, в костюме, и верит в то, что инновации апплодисментами встретят и сразу же примут — мысль в голове вертелась, постепенно обретая форму. А Вы в курсе, юноша, скольким коллегам и контрагентам со своими нововведениями немилы станете? Они же Вас невзлюбят сразу, к гадалке не ходи! В общем, порыв жил обычным циклом инноваций.

В дисциплине управления проектами стейкхолдерами называют всех, кого проект коснется (а также тех, кто может оказать на него влияние). Люди они разные, со своими интересами, ожиданиями, и чаяниями. Закрыть глаза в надежде, что и проекта не заметят — весьма опрометчиво (вспоминается неприглашенная колдунья). Boston Consulting Group оценивает долю IT проектов, почивших по не-техническим причинам, в 75%. Последние две редакции свода знаний по управлению проектами (PMBOK) выделяют процессы по управлению стейкхолдерами в отдельную область знаний под счастливым номером 13 и настоятельно рекомендуют учитывать связи между ними, центры влияния, а также культуру общения для повышения шансов на успех.
Мы покажем, как оценить стейкхолдеров с помощью машинного обучения. Выделим группы похожих между собой людей и решим задачу кластеризации — сегментации клиентов в терминах маркетинга — в социальных структурах, которые построим из: 1) потоков сообщений и 2) эмоциональной окрашенности текста. Для этого заглянем в переписку, любезно предоставленную г-жей Клинтон, способом, предложенным в журнале Биоинформатика.