Сейчас существенная часть машинного обучения основана на решающих деревьях и их ансамблях, таких как CatBoost и XGBoost, но при этом не все имеют представление о том, как устроены эти алгоритмы "изнутри".
Данный обзор охватывает сразу несколько тем. Мы начнем с устройства решающего дерева и градиентного бустинга, затем подробно поговорим об XGBoost и CatBoost. Среди основных особенностей алгоритма CatBoost:
• Упорядоченное target-кодирование категориальных признаков
• Использование решающих таблиц
• Разделение ветвей по комбинациям признаков
• Упорядоченный бустинг
• Возможность работы с текстовыми признаками
• Возможность обучения на GPU
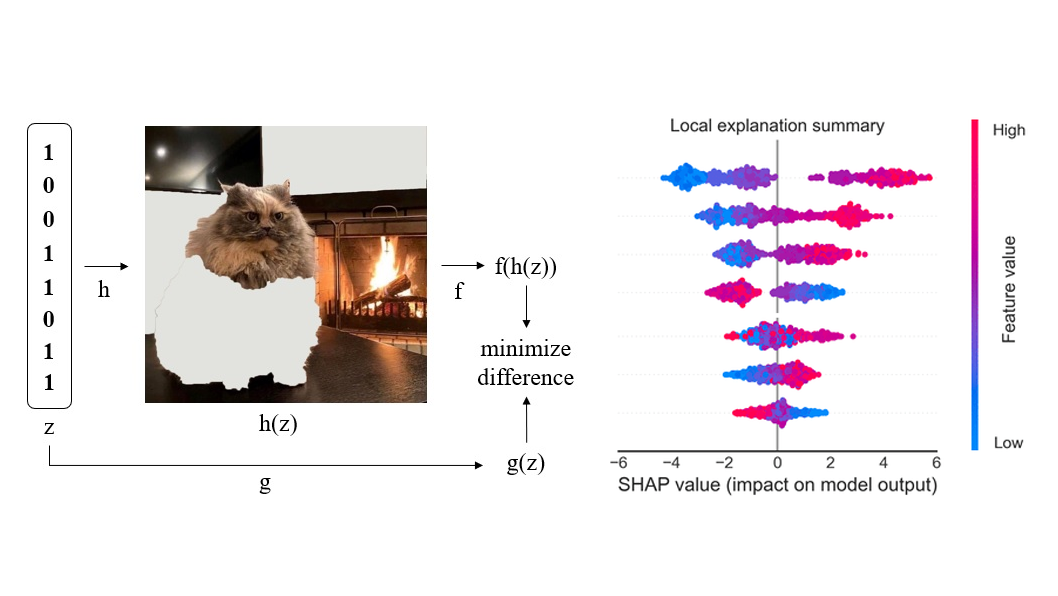
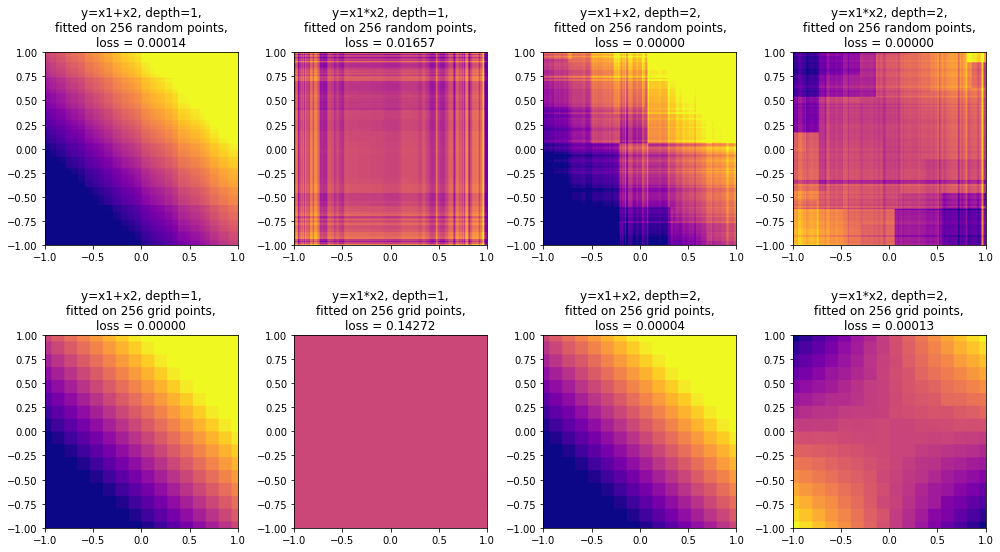
В конце обзора поговорим о методах интерпретации решающих деревьев (MDI, SHAP) и о выразительной способности решающих деревьев. Удивительно, но ансамбли деревьев ограниченной глубины, в том числе CatBoost, не являются универсальными аппроксиматорами: в данном обзоре приведено собственное исследование этого вопроса с доказательством (и экспериментальным подтверждением) того, что ансамбль деревьев глубины N не способен сколь угодно точно аппроксимировать функцию  . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.