В последнее время все больше людей приходит к тому, чтобы не держать деньги под матрасом, а куда-то их инвестировать в надежде сохранить и преумножить свой капитал. Вариант с матрасом плох тем, что с повышением цен на товары и услуги (инфляция) покупательная способность денег падает и через какое-то время купить на них можно значительно меньше, чем раньше. Есть много вариантов, куда вложить деньги(недвижимость, банковский вклад, ценные металлы), но в последнее время популярным становится инвестирование в акции. Только у брокера Тинькофф Инвестиции за несколько лет число клиентов превысило 3.5 млн. В статье я постараюсь описать свой подход к выбору бумаг и поделюсь инструментами, которые для этого разрабатываю(https://github.com/fartuk/ml_investment)
Выбор компаний в портфель
Дисклеймер: у автора нет экономического образования и все выводы и суждения в статье делаются на основе житейского опыта и здравого смысла.
Ниже приведены некоторые базовые моменты, на которые можно обращать внимание при формировании решения о покупке какой-либо акции.
Деятельность компании

Можно смотреть на то, чем занимается компания. Если есть вера в будущее электромобилей, то, например, можно посмотреть в сторону Tesla (далее из статьи будет понятно, что это может быть не самый лучший выбор). Если есть вера в биомед, то можно купить бумаги из соответствующего сектора. При этом, на мой взгляд, важно понимать, что конкретно делает компания, на чем основан ее бизнес. Например, если взять нефтяные компании, то они могут заниматься совершенно разными вещами - одни добывают сырье, другие его перерабатывают, третьи только транспортируют. Из-за этого некоторые события, происходящие в мире, сильно влияют на одних, но совсем не влияют на других. Условно, закрыли какой-то морской канал, и танкеру, чтобы доставить нефть, приходится делать крюк, следовательно лишние затраты для транспортной компании. При этом какому-нибудь переработчику нефти все равно.
Это все к тому, что зачастую популярный подход с выбором только известных брендов может работать не очень хорошо. Часто бывает полезно понять, что конкретно делает компания и тогда желание её купить может само отпасть (например, деятельность явно устаревающая/новые технологии могут заместить необходимость в такой деятельности и т.п.).
Финансовые отчеты
Но помимо этого было бы неплохо знать - а как конкретно зарабатывает фирма? Откуда у нее основные источники дохода и как они распределены? К счастью, каждая компания, торгующаяся на бирже, обязана раз в квартал (четверть года) раскрывать информацию о своих финансах (так называемые финансовые отчеты). Чтобы найти такие отчеты, достаточно вбить в любом поисковике "company_name investor relations" и перейти на соответствующий раздел сайта компании. На картинке показан кусок такого отчета компании Apple за 4 квартал:
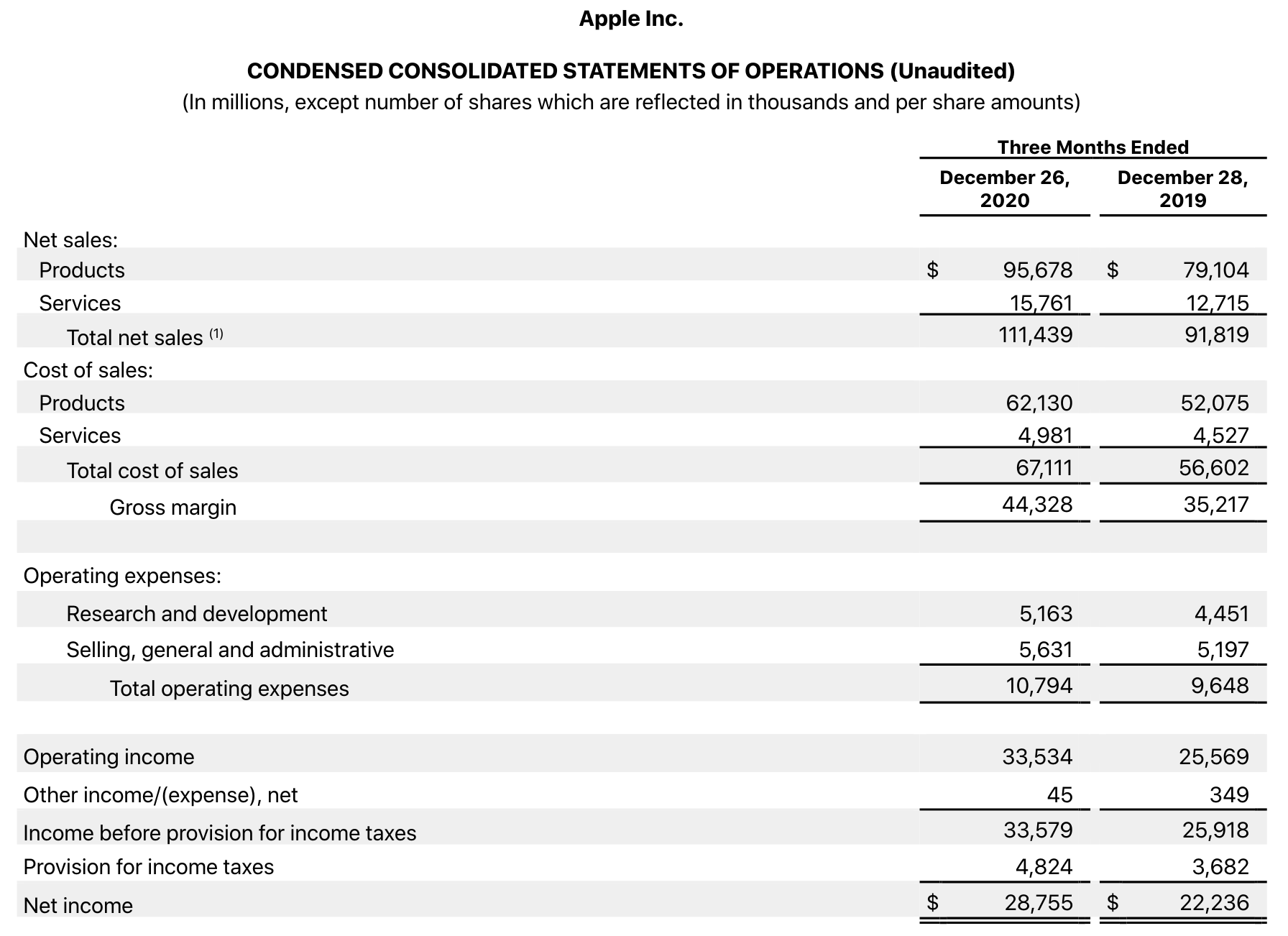
Из него можно понять, что выручка компании (net sales, часто её называют revenue) за квартал составила почти 111.5 миллиардов долларов, что больше, чем в аналогичном квартале год назад (91.8 млрд). Кроме того, 95.7 млрд из них приходится на продукцию компании (продажи iPhone, iPad и т.д.), а 15.7 - на сервисы (Apple Music, App Store и т.д.). Так же можно увидеть, что чистая прибыль компании составила 28.8 млрд, причем видно, как это число получилось :
Из net sales вычли cost of sales (непосредственные затраты на производство) и operating expenses (побочные затраты), а так же учли налоги (provision for income taxes). 111.4 - 67.1 - 10.8 - 4.8 = 28.7Если покопаться в отчете глубже, то можно увидеть, как распределена выручка между продуктами, сколько денег было потрачено на исследования и разработку, сколько на продажи и много другой полезной информации, которую, безусловно, можно исользовать при принятии инвестиционных решений.
Мультипликаторы

Часто бывает так, что нужно сравнить компании, понять, какая из них лучше. Например, было решено, что в портфель необходимо добавить компанию, производящую потребительские товары. Но таких компаний огромное количество, и все они разных размеров, демонстрируют совершенно разные revenue, net income и т.д. На помощь приходят мультпликаторы - производные величины, которые можно непосредственно сравнить.
P/E (price to earnings) - цена-прибыль. Вычисляется как отношение капитализации компании к её годовой прибыли. Другими словами, данный показатель говорит о том, сколько лет компания будет окупаться, если ее купить сейчас. Например, у Apple сейчас P/E~30. Значит, если (в теории) мы целиком купим эту компанию по текущей цене, то через 30 лет эта покупка себя отобьет. Итак, чем ниже P/E, тем "дешевле" компания, что, разумеется, хорошо (лучше я куплю бизнес, который окупится за 10 лет, чем за 20). При этом важно понимать, что для разных секторов средние P/E могут сильно разниться. Это объясняется тем, что от одних секторов ожидания выше, чем от других. Например, продуктовому ритейлеру почти нереально увеличить выручку в 10 раз, а поставщик какого-нибудь интернет-сервиса спокойно может кратно наращивать количество пользователей от года к году. Вот и выходит, что технологические компании по P/E стоят "дороже", чем, например, сырьевые.
D/E (Debt to Equity) - долг к собственному капиталу. Данный мультипликатор показывает, насколько высокая долговая нагрузка у компании. Понятно, что если долг слишком высокий, то выше риски банкротства компании и меньше у неё возможностей. Иногда компании со слишком высоким D/E называют "зомби", потому что результат их деятельности целиком идет на обслуживание долга.
ROE (Return On Equity) - рентабельность собственного капитала. Вычисляется как отношение чистой прибыли к собственному капиталу компании. Мультипликатор показывает, как компания способна генерировать прибыль за счет собственных средств.
Есть еще много других мультипликаторов, но я в основном пользуюсь только этими.
Машинное обучение
По своему основному роду деятельности я - датасаентист, поэтому логично было бы использовать современные методы машинного обучения и анализа данных для оптимизации и упорядочивания процесса своих инвестиций. Стоит уточнить, что речь не идет про алгоритмический трейдинг, спекуляции и прочее. Я говорю лишь про инструменты, которые могут упростить инвестирование, сделать его более понятным и предсказуемым. Поскольку, думаю, что инвестировать я буду долгое время, то код решил писать чуть более аккуратно, чем обычно. Посмотреть все исходники можно тут https://github.com/fartuk/ml_investment . А если кому лень самостоятельно все запускать, то я сделал еще и веб-сервис http://fattakhov.site/ с основными моделями (их цели и значение можно понять дальше в статье).
Данные
Понятно, что для написания нужных мне алгоритмов необходимы данные по фундаментальным показателям компаний за предыдущие кварталы (как в отчетах, только в одном месте и единообразно). Для американского рынка я нашел несколько источников: бесплатный yahoo finance(доступно только 4 квартала) и недорогой (около 30$) поставщик довольно качественных данных с удобным API https://www.quandl.com/databases/SF1 Кроме того, в последнем есть и посуточные базовые свечные данные.
Для удобства скачивания написал даунлоэдеры, которые можно использовать следующим образом:
from ml_investment.download_scripts import download_sf1, download_yahoo
download_sf1.main()
download_yahoo.main()
Все дальнейшие подсчеты фичей, таргетов, а так же построение пайплайнов будут производиться на основе данных, источник которых со временем может поменяться, поэтому было решено придерживаться следующего интерфейса для загрузки данных в память:
class DataLoader:
def load(self) -> pd.DataFrame:
# returned pd.DataFrame with data
Соответственно, предполагается, что SF1BaseData будет загружать основные данные про компании, которые не меняются со временем, вроде сектора, индустрии и т.д.SF1QuarterlyData будет загружать поквартальные данные (revenue, netincome и т.д.), при этом каждая строчка - отдельный квартал.SF1DailyData грузит дневную дату (например, ценовые свечи, дневную капитализацию). Для новых типов данных можно писать аналогичные классы, реализующие указанный выше интерфейс.
Далее будут показаны классы, реализующие подстчет фичей, таргетов и т.д, и некоторым из них могут понадобиться разные данные, поэтому все лоэдеры удобно положить в словарь и обращаться потом к ним по ключу:
data = {}
data['quarterly'] = SF1QuarterlyData('sf1/data/path')
data['base'] = SF1BaseData('sf1/data/path')
data['daily'] = SF1DailyData('sf1/data/path')Честная стоимость компании

Итак, первая задача, которая у меня постоянно возникала и которую я не знал как решить - оценка адекватной стоимости компании. То есть, часто можно слышать фразы "эта компания переоценена", "слишком дорогая" или наоборот "сильно недооцененная, дешевая". Но как численно понять, сколько по-хорошему должна стоить компания? Кто-то может сказать "а разве не для этого и существует мультипликатор P/E?" и будет отчасти прав. Но. Часть компаний (особенно на ранних этапах) являются убыточными и для них мультипликатор вообще не определен. Или для какой-то компании сейчас мультипликатор высокий, но это не значит, что компания плохая, просто на данном этапе она может вкладываться в рост. И для меня, как для инвестора, это хорошо - да, компания могла бы получить высокую прибыль (а, соответственно, низкий P/E), если бы сократила расходы на маркетинг, например. Но тогда она не заполучила бы новых клиентов, не открыла новые точки и т.д. В результате это привело бы к тому, что в будущем прибыль компании была бы не такая большая, как если бы сейчас полученная прибыль направилась в развитие.
Вернемся к определению адекватной стоимости компании. Известно, что часть торгующихся компаний имеют завышенную стоимость, а часть - заниженную. Из-за этого возникла мысль - что если обучить модель, которая чисто по показателям из отчетов компании будет предсказывать текущую капитализацию? Понятно, что модель не сможет учитывать какие-то настроения инвесторов и прочие спекулятивные моменты, а в качестве предсказания будет предлагаться что-то среднее. Но это среднее и можно интерпретировать как "честную стоимость", ведь алгоритм машинного обучения просмотрел все похожие по фундаментальным показателям компании и на основе их реальных рыночных каптиализаций сделал оценку.
Признаки
Первым делом нужно соорудить некоторое представление компании по ее фундаментальным показателям. Логично предположить, что если компания зарабатывает по 100 млрд последние 10 кварталов, то она никак не может стоить 1 млрд (должна стоить гораздо дороже). Аналогичная интуиция и с остальными показателями - если долг убывает со временем, значит дела в порядке (плюсик к капитализации). Если выручка растет за последние кварталы - значит компания развивается, это хорошо, и, соответственно, должно закладываться в цену. Все эти признаки легко покрываются с помощью подсчетов статистик вроде mean max min std и т.д. для последних, например, 2, 4, 10 кварталов. Кроме того, часто смотрят не только на то, растет выручка или нет, но и на темпы роста. Поэтому можно добавить статистики и по диффам - например, среднее значение того, на сколько процентов росла выручка. При этом логично, что все эти подсчеты можно делать для разных квартальных срезов компании: считать признаковое представление не только для текущего квартала, но и для предыдущих (параметр max_back_quarter), тем самым кратно увеличивая датасет. Ну и как результат, полученный класс для подсчета квартальных фичей и его использование:
fc1 = QuarterlyFeatures(
data_key='quarterly',
columns=['revenue', 'netinc', 'debt'],
quarter_counts=[2, 4, 10],
max_back_quarter=5)
fc1.calculate(data, ['AAPL', 'INTC', 'F'])Кроме того, при оценке стоимости компании важны и ее базовые характеристики. Например, как уже упоминал, технологические компании обычно оцениваются дороже. Аналогично, из разных индустрий средние оценки компаний тоже могут разниться. Поэтому был реализовал класс BaseCompanyFeatures, кодирующий подобные признаки с помощью лэйбл-энкодинга:
fc2 = BaseCompanyFeatures(data_key='base', cat_columns=['sector', 'sicindustry'])
fc2.calculate(data, ['AAPL', 'INTC', 'F'])Ещё одним моментом, который бы хотелось учитывать при оценке компании, является подневная динамика движения цены акции компании за последнее время. Интуиция в том, что если стоимость компании стабильно растет, то инвесторы охотнее будут её покупать. При этом динамика должна представляться в нормализованном виде, чтобы избежать лика(нечестно определять стоимость компании, основываясь на стоимости компании). Соответствующий класс DailyAggQuarterFeatures (так же работает с квартальными слайсами компании и параметром max_back_quarter):
fc3 = DailyAggQuarterFeatures(
daily_data_key='daily',
quarterly_data_key='quarterly',
columns=['marketcap'],
agg_day_counts=[100, 200, 400, 800],
max_back_quarter=5)
fc3.calculate(data, ['AAPL', 'INTC', 'F'])Для удобства комбинирования признаков был реализован класс FeatureMerger:
feature = FeatureMerger(fc1, fc2, on='ticker')
feature = FeatureMerger(feature, fc3, on=['ticker', 'date'])
feature.calculate(data, ['AAPL', 'INTC', 'F'])Таргет
С целевой переменной (той, что собираемся предсказывать) для этой модели более-менее понятно. Нужно просто взять капитализацию компании в момент отчета. Для согласования таргета и фичей было принято решение сделать следующий интерфейс подсчета таргета:
def calculate(self, data, index: pd.DataFrame) -> pd.DataFrame:
'''
index:
pd.DataFrame containing information of tickers and dates
to calculate targets for. Should have columns: ["ticker", "date"].
'''Ну и ниже сам класс QuarterlyTarget для подсчета таких квартальных таргетов. Его функционал чуть шире - данный класс позволяет брать значения переменных не только для нужного квартала, но и для соседних (например, если вдруг захотим предсказывать не текущую, а будущую капитализацию компании):
index = pd.DataFrame([{'ticker':'AAPL', 'date':'2020-10-30'}])
target = QuarterlyTarget(data_key='quarterly', col='marketcap', quarter_shift=0)
target.calculate(data, index)На самом деле, тут можно было бы сделать и другой таргет - сгладить капитализацию за будущие 30 дней, например. Интуиция в том, что непосредственно в день отчета цена может сильно скакать, а за месяц все более-менее устаканится и средняя капитализация будет более стабильной. Как раз для таких целей у меня написан DailyAggTarget класс таргета:
target = DailyAggTarget(
data_key='daily',
col='marketcap',
horizon=30,
foo=np.mean)
target.calculate(data, index)Модель
С подобными признаками, как известно, хорошо работают градиентные бустинги. Их и будем использовать. Единственный момент, что распределение нашего таргета не очень хорошее - одни компании стоят сотни миллиардов долларов, другие миллионы. А модель должна уметь адекватно предсказывать для всех. Воспользуемся классической фишкой - логарифмированием таргета.
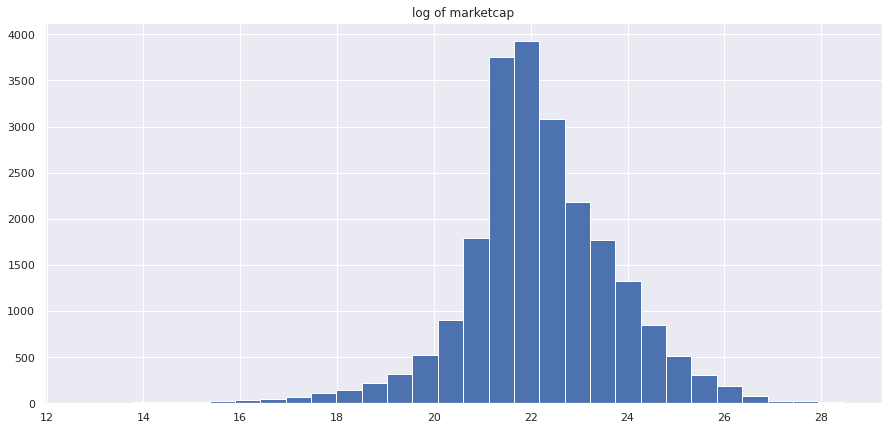
Теперь его распределение хоть как-то похоже на нормальное, что является комфортным для модели. Для удобства логарифмирование таргета и последующее возведение предсказаний в экспоненту были инкапсулированы в классе LogExpModel:
model = LogExpModel(lgbm.sklearn.LGBMRegressor())
model.fit(X, y)
model.predict(X)
Теперь главное - правильно построить валидацию. Дело в том, что если обучить модель на одном квартале, а валидировать на следующем, то модель просто запомнит эту компанию и возьмет капитализацию с предыдущего квартала, что не очень правильно. Модель должна по другим похожим компаниям понимать, сколько должна стоить текущая. Соответственно, нужно делать группировку по компаниям при валидации (разные квартальные срезы компании должны быть строго в одном фолде, т.е. не использоваться одновременно и для тренировки, и для валидации).

Для удобства процедура группировки по фолдам и предсказания была инкапсулирована в классе GroupedOOFModel. Т.е. можно вызывать методы обучения и предикта, при этом внутри класс будет хранить не одну модель, а целый набор и при предсказании для очередной компании будет использовать ту модель, при обучении которой данная компания не использовалась.
model = GroupedOOFModel(
base_model=lgbm.sklearn.LGBMRegressor(),
group_column='ticker',
fold_cnt=5)
model.fit(X, y) # X should contain 'ticker' column
model.predict(X)Кроме того, экспериментально было проверено, что одна модель ведет себя нестабильно при, например, дообучении на новых данных. Поэтому (и еще для увеличения итогового качества предсказаний) было решено использовать ансабль моделей. При этом в ансамбль входят как разные классы моделей, так и модели, обученные на разных сабсетах тренировочных данных (бэггинг). Во время инференса предсказания базовых моделей усредняются.
Данный ансамбль реализован с интерфейсом, типичным для всех моделей:
base_models = [lgbm.sklearn.LGBMRegressor(),
ctb.CatBoostRegressor()]
ensemble = EnsembleModel(
base_models=base_models,
bagging_fraction=0.7,
model_cnt=20)
ensemble.fit(X, y)
ensemble.predict(X)Итого, финальная модель, являющаяся комбинацией всех описанных выше классов:
base_models = [LogExpModel(lgbm.sklearn.LGBMRegressor()),
LogExpModel(ctb.CatBoostRegressor())]
ensemble = EnsembleModel(
base_models=base_models,
bagging_fraction=0.7,
model_cnt=20)
model = GroupedOOFModel(
ensemble,
group_column='ticker',
fold_cnt=5)Пайплайн
Итак, почти все готово для обучения:
data- словарь с даталоэдерамиfeature- класс, реализующий подсчет фичейtarget- класс, реализующий вычисление таргетаmodel- модель(в том числе инкапсулирующая в себе разделение для валидации)
Осталось собрать все это воедино и обучить, используя наши данные (а именно, класс SF1Data). Для данных целей был написан класс BasePipeline. Он скрывает в себе всю логику с расчетом фичей, таргетов, обучением модели и подсчетом метрики (кроме того, поддерживается режим с мульти-таргетом и мульти-метриками). При инференсе производит pd.DataFrame с результатом в колонке out_name.
pipeline = Pipeline(
data=data,
feature=feature,
target=target,
model=model,
out_name=['fair_marketcap'])
pipeline.fit(ticker_list, metric=median_absolute_relative_error)
pipeline.execute(['INTC'])Результат:
ticker | date | fair_marketcap |
|---|---|---|
INTC | 2021-01-22 | 4.363793e+11 |
INTC | 2020-10-23 | 2.924576e+11 |
INTC | 2020-07-24 | 3.738603e+11 |
INTC | 2020-04-24 | 3.766202e+11 |
INTC | 2020-01-24 | 4.175332e+11 |
Код всего пайплайна целиком можно посмотреть на гитхабе https://github.com/fartuk/ml_investment/blob/main/ml_investment/applications/fair_marketcap_sf1.py
Итак, удалось построить пайплайн, который выдает для квартальных срезов компаний оценки честной капитализации. Поиграться с результатами и посмотреть на fair marketcap для компаний американского рынка можно на странице http://fattakhov.site/company/AAPL . Для этого нужно ввести тикер интересующей компании и нажать кнопку Analyze. Ну и, собственно, как можно использовать полученный инструмент - смотреть на реальную капитализацию (синий график), на предсказанную честную капитализацию (оранжевый график) и считать компанию недооцененный, если оранжевый график лежит выше синего и переоцененной в противном случае. Сами точки, соответственно, находятся на датах выходов квартальных отчетов. Проверим модельку на некоторых примерах:
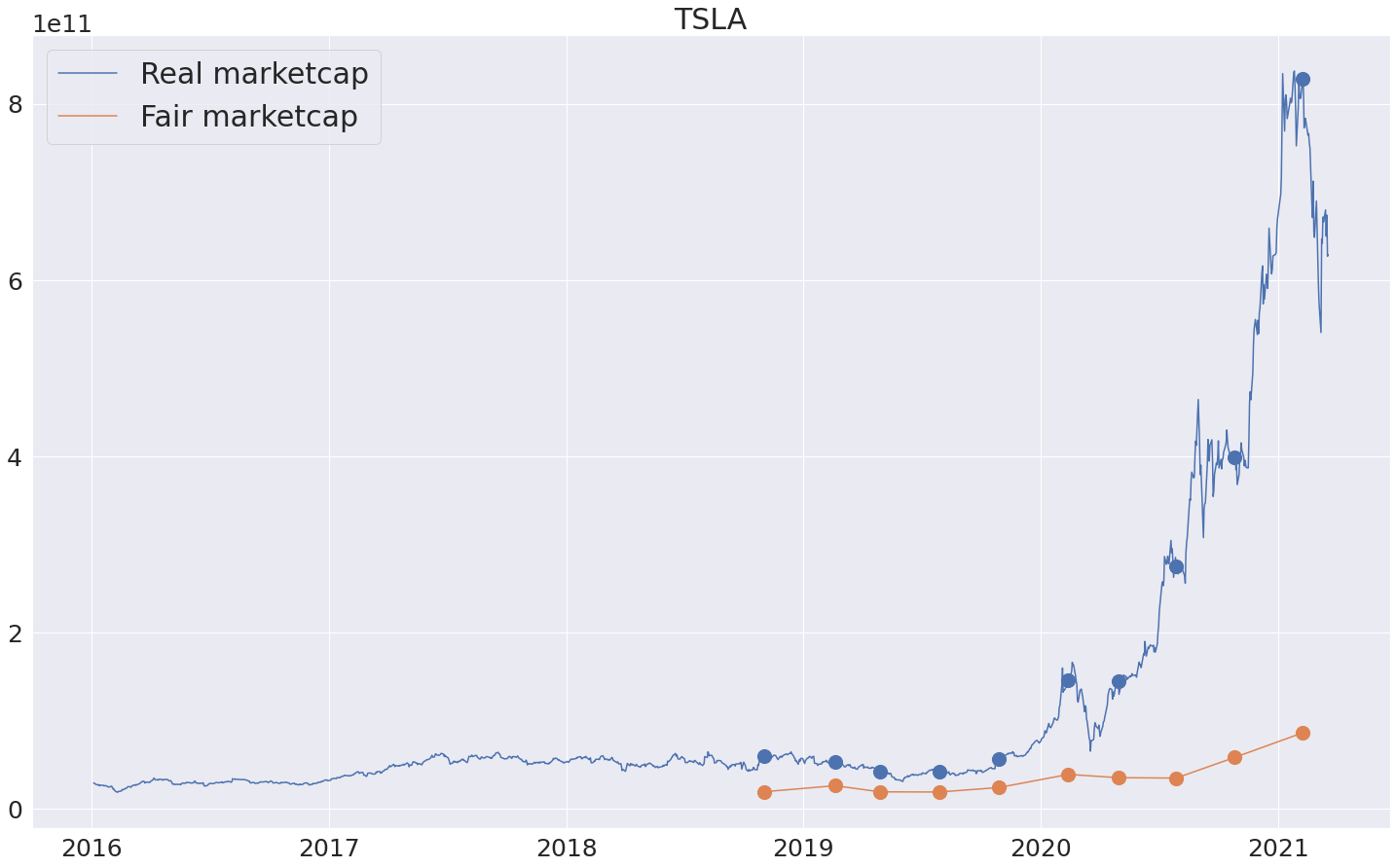
С теслой, как и ожидалось, модель говорит о сильной переоценке. И действительно, если глазами смотреть на показатели компании, то в данный момент цена кажется не очень оправданной.
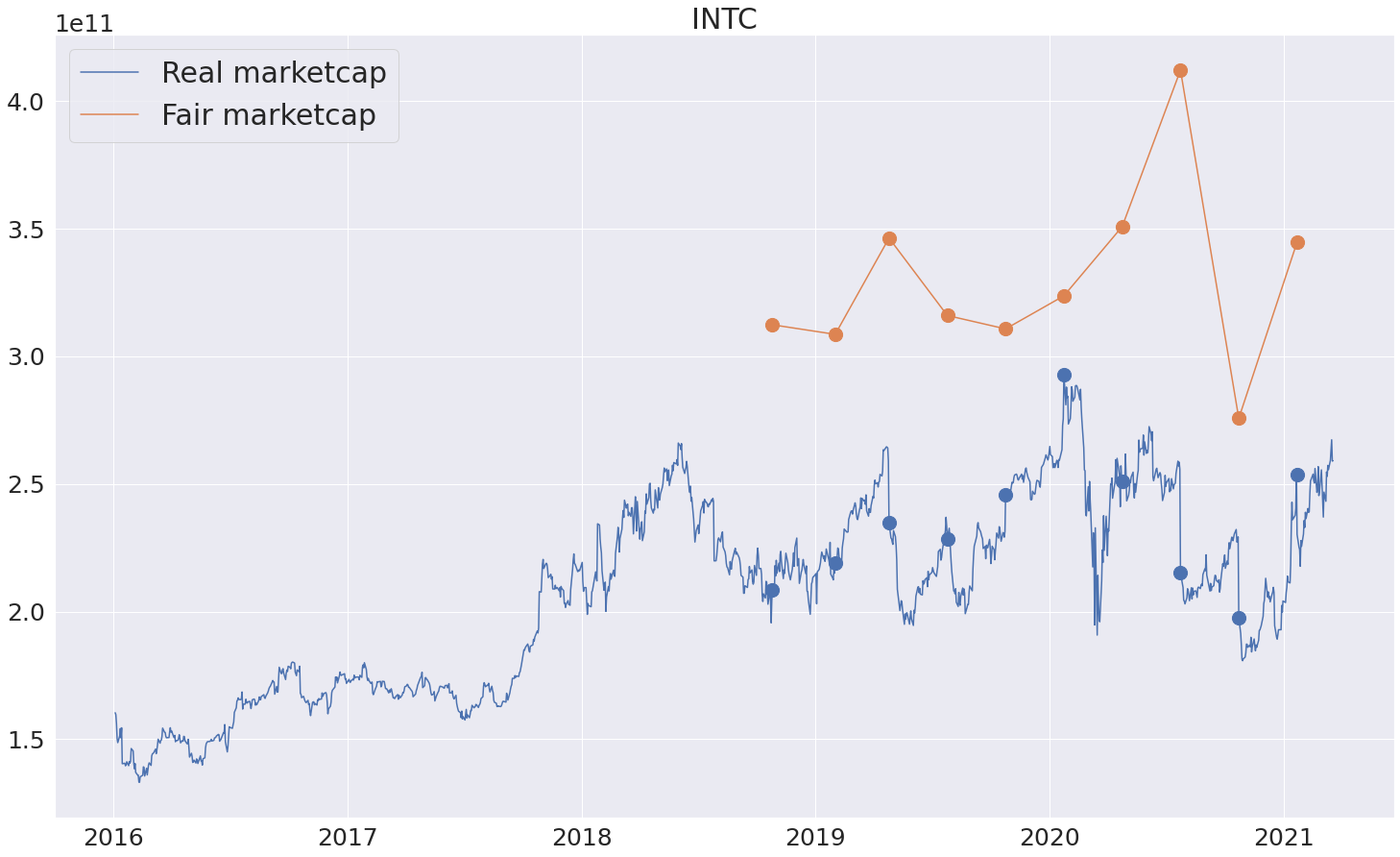
С интелом, наоборот, модель считает оценку рынка не очень справедливой. Возможно, подобные эффекты связаны с другими проблемами компании, которые модель пока не в состоянии учитывать (непонятно, как, например, обрабатывать новости про отсрочки выходов очередных продуктов, переходов на другие тех.процессы и т.д.).
Справедливое изменение капитализации после отчета

Идея следующего пайплайна, который я попробовал, заключается в следующем: пусть модель для честного определения капитализации может не учитывать некоторые скрытые причины того, почему та или иная компания стот столько, сколько она стоит. Но можно ли научить модель после выхода очередного отчета предсказывать, насколько должна была измениться стоимость компании? Кажется, что такая задача проще, потому что часто бывает, скрытые моменты, объясняющие рыночную стоимость, переходят из квартала в квартал. Ну вот нравится инвесторам покупать Теслу и ничего с этим не поделаешь.
Итак, вышел отчет компании, ее фундаментальные показатели как-то изменились (например, выручка выросла на 30%, прибыль выросла на 40% и т.д.). И по таким изменениям хотим предсказывать, а как по-хорошему должна была измениться капитализация.
Признаки
В принципе, все базовые фичи, которые были в первом пайплайне, можно оставить, они подходят и для текущей задачи. Но понятно, что нужно добавить и характеристики типа "изменение от квартала к кварталу". При этом стоит заметить, что важно сравнивать не только с предыдущим кварталом, но и кварталом год назад, потому что часто встречаются компании, например, с сезонными продажами. На графике ниже показана поквартальная выручка и прибыль компании Apple. Четко видны сезонные пики, связанные, думаю, с выходом новых моделей айфонов.

Реализовать подсчет нужных признаков можно с помощью класса QuarterlyDiffFeatures. В качестве параметра compare_quarter_idxs передаем [1, 4], так как хотим сравнить показатели с предыдущим кварталом и кварталом год назад. Класс посчитает относительные изменения показателей, находящихся в колонках columns:
fc = QuarterlyDiffFeatures(
data_key='quarterly',
columns=['revenue', 'netinc'],
compare_quarter_idxs=[1, 4],
max_back_quarter=5)
fc.calculate(data_loader, ['AAPL', 'INTC', 'F'])Таргет
С таргетом тут тоже вроде все понятно, просто берем и считаем, насколько изменилась рыночная капиталзизация и нормализуем для удобства:
target = QuarterlyDiffTarget(data_key='quarterly', col='marketcap', norm=True)
target.calculate(data_loader, info_df)Модель
Навороты с ансамблем, разумеется, можно оставить, но нужно решить вопрос с валидацией. В данном случае совсем не обязательно группировать по компаниям, ведь предсказания относительные, а что будет с компанией в будущем по ее истории из прошлого - совсем непонятно. Однако тут есть другой момент - предсказывая изменение на текущий квартал, модель не должна знать про то, как в аналогичном квартале (и в будущем) изменились капитализации других компаний. Например, если вдруг случился мощный кризис, на фоне всеобщей паники капитализации всех компаний попадали даже при хороших отчетах. И модель по косвенным признакам поняла, что в данный момент кризис и занизила предсказания. Но во время инференса такой информации не будет, поэтому приходим к тому, что нужно делать time-series валидацию. А именно, сортируем все данные во времени, делим на N фолдов, обучаем модель на первом, предсказываем на второй. Обучаем модель на первых двух фолдах, предсказываем на третий. И так далее. Таким образом, делая предсказание на очередной квартал, мы не заглядываем в будущее.

Как и в случае с группировкой по фолдам, релизация time series валидации скрыта в классе модели TimeSeriesOOFModel:
model = TimeSeriesOOFModel(
base_model=lgbm.sklearn.LGBMRegressor(),
time_column='date',
fold_cnt=20)
model.fit(X, y) # X should contain 'date' column
model.predict(X)Пайплайн
Пайплайн аналогичен тому, что был в прошлый раз. Посмотреть весь код можно на гитхабе https://github.com/fartuk/ml_investment/blob/main/ml_investment/applications/fair_marketcap_diff_sf1.py
Попробуем запустить полученный пайплайн на некоторых примерах. Опять же, посмотреть результат для других тикеров можно на странице http://fattakhov.site/company/AAPL (черный график). Итак, новый пайплайн выдет относительное предсказанное изменение для текущего квартала:
ticker | date | fair_marketcap_diff |
|---|---|---|
INTC | 2021-01-22 | 0.283852 |
INTC | 2020-10-23 | -0.021278 |
INTC | 2020-07-24 | -0.035124 |
INTC | 2020-04-24 | -0.098987 |
INTC | 2020-01-24 | 0.198822 |
Для удобства сделаем следующее: будем отображать посчитанное абсолютное изменение (беря информацию о реальной рыночной капитализации за предыдущий квартал). Т.е. новый график несет примерно такой же смысл, как и предыдущие - сколько по-хорошему должна стоить компания на текущий момент с учетом того, что известна стоимость за предыдущий квартал.
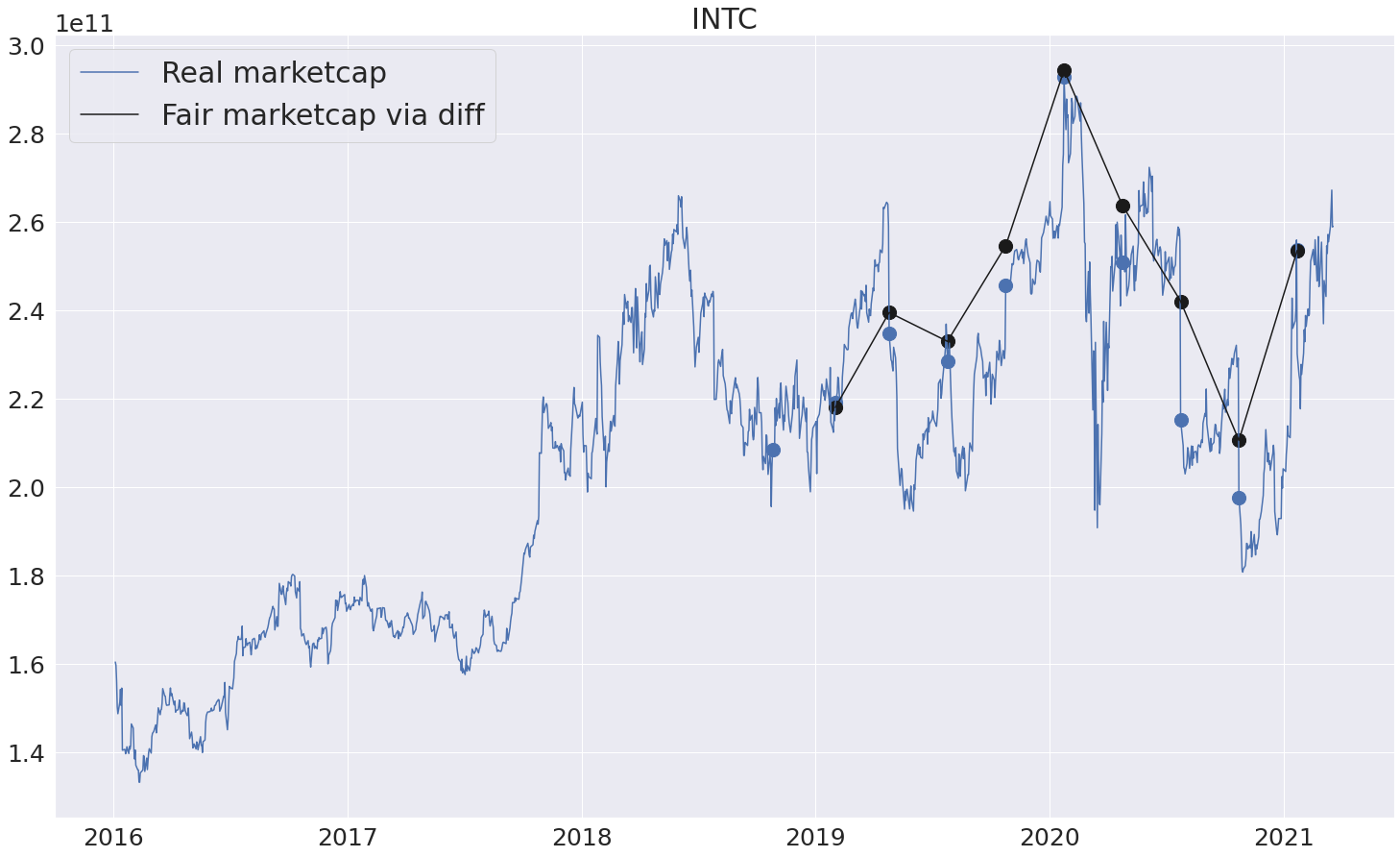
Видно, что получаются довольно точные предсказания (черный график), но расхождения все равно присутствуют, и как раз их и можно использовать при принятии решений о покупке/продажи очередной акции. То есть, например, вышел плохой отчет, компания сильно упала. Но модель говорит, что падение должно было быть не таким сильным -> потенциально хороший момент, чтобы купить.
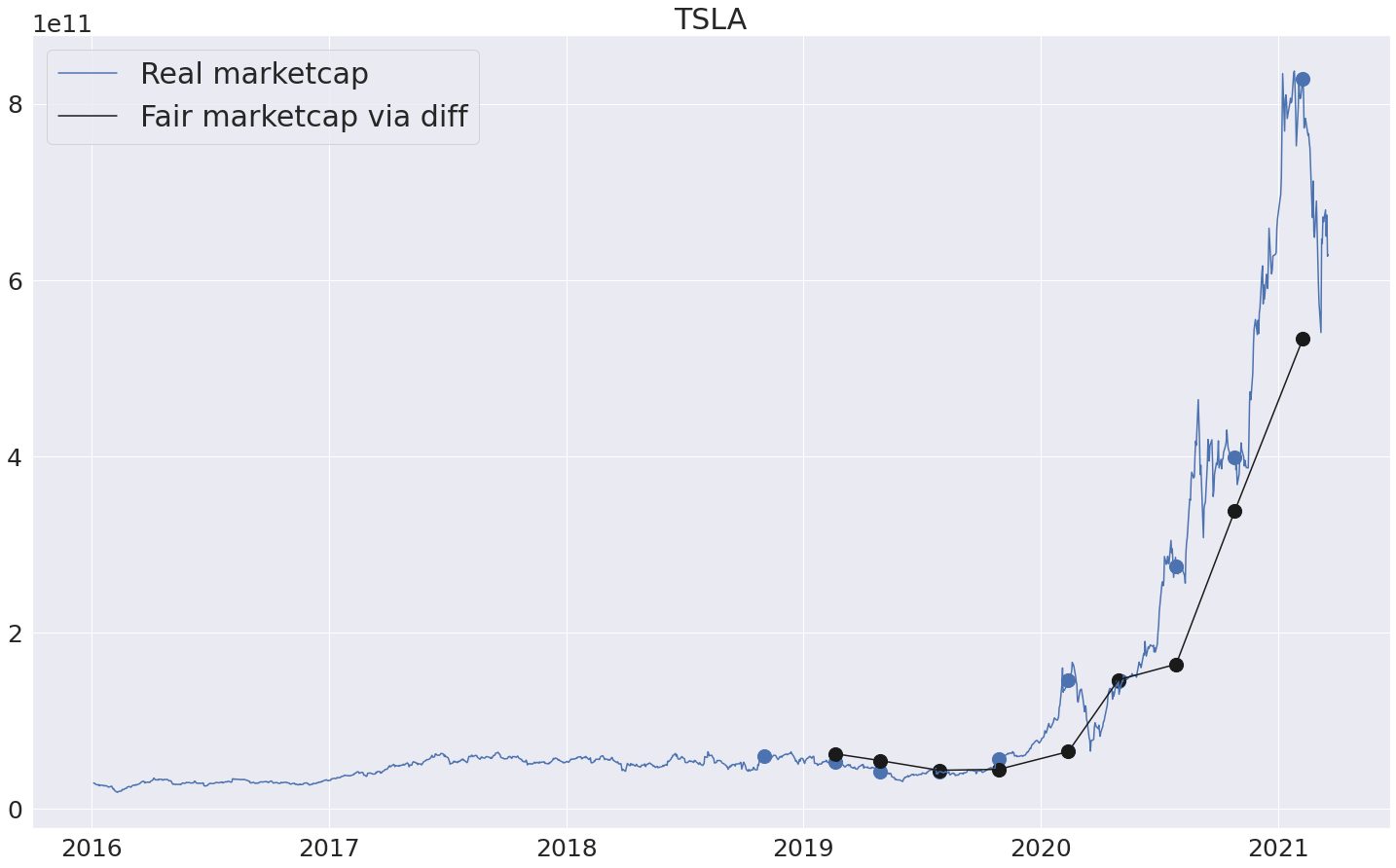
С теслой, однако, даже такая модель не может объяснить столь стремительный рост :)
Характеристика потенциальных рисков

Может быть случай, что все предыдущие модели в один голос говорят: "покупай, дёшево!", но из истории понятно, что стоимость данной акции сильно скачет вверх-вниз, что не совсем приятно. Совершая сделку, хочется понимать, а какой есть риск? До каких пределов может опуститься цена и с какой вероятностью? Можно было бы из истории сделать статистические оценки, но у нас же ML-тулы :) Поэтому сделаем еще один машинно-обученный пайплайн (в этом подходе есть надежда, что модель сможет самостоятельно детектировать неблагоприятные/сильно рискованные моменты)
Фичи
Не мелочимся и используем сразу все признаки, которые использовались ранее.
Таргет
С выбором таргета тут сложнее. Основная идея в том, что он должен показывать, насколько вероятно падение в ближайшее время и каким оно может быть по величине. В голову приходит что-то вроде стандартного отклонения, std-вниз, максимальной просадки и т.п. за какой-то будущий промежуток времени. Пока для примера можно ограничиться std-вниз. Формула расчета представлена ниже (x_down - все x, меньшие среднего):

Класс таргета для таких целей уже описывался ранее:
target = DailyAggTarget(
data_key='daily',
col='marketcap',
horizon=90,
foo=down_std_norm)Модель
С моделью все понятно, берем максимальный ансамбль. При этом так же, как и в предыдущем примере, нужно использовать time-series валидацию (более того, это первая модель, которая должна оценивать будущее).
Пайплайн
Все тот же класс Pipeline позволяет реализовать данный пайплайн (гитхаб версия https://github.com/fartuk/ml_investment/blob/main/ml_investment/applications/marketcap_down_std_sf1.py )
Итак, пайплайн готов и выдает на выход предсказанные std-вниз (нормированные):
ticker | date | marketcap_down_std | |
|---|---|---|---|
INTC | 2021-01-22 | 0.043619 | |
INTC | 2020-10-23 | 0.057673 | |
INTC | 2020-07-24 | 0.061062 | |
INTC | 2020-04-24 | 0.053481 | |
INTC | 2020-01-24 | 0.039370 |
Если считать предсказанное std верным, то можно посчитать различные доверительные интервалы и отобразить их в виде ступенчатого графика. Для примера возьмём компанию Carnival, так как она известна своими скачками.

В глаза бросается мартовское падение 2020го года, но модель явно не могла предугадать кризисную историю, а с остальными кварталами вроде все более-менее в порядке и предсказание действительно лежит ниже графика капитализации. Тем не менее, с пайплайном для оценки рисков еще можно поработать и сделать что-то более точное и интерпретируемое.
Заключение
В данной статье были описаны основные модели, которыми я пользуюсь при принятии своих инвестиционных решений. Понятно, что в таком виде - это всего лишь инструменты, которые могут как-то влиять на выбор той или иной акции, а не полноценные стратегии. Тем не менее, надеюсь, что основные идеи могли оказаться полезными для читателя, а так же жду советов/предложений по улучшению тулов.
Сам я завел отдельный портфель в котором совершаю сделки только на основании предсказаний от описанных выше моделей, за его результатами можно последить в Тинькофф Пульсе https://www.tinkoff.ru/invest/social/profile/fattakhov_artur?utm_source=share
Возможно, напишу продолжение про то, как я конкретно составляю портфель, диверсифицирую по секторам, подбираю веса бумаг и т.д.
