
Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- Neural Ordinary Differential Equations (University of Toronto, 2018)
- Semi-Unsupervised Learning with Deep Generative Models: Clustering and Classifying using Ultra-Sparse Labels (University of Oxford, The Alan Turing Institute, London, 2019)
- Uncovering and Mitigating Algorithmic Bias through Learned Latent Structure (Massachusetts Institute of Technology, Harvard University, 2019)
- Deep reinforcement learning from human preferences (OpenAI, DeepMind, 2017)
- Exploring Randomly Wired Neural Networks for Image Recognition (Facebook AI Research, 2019)
- Photofeeler-D3: A Neural Network with Voter Modeling for Dating Photo Rating (Photofeeler Inc., 2019)
- MixMatch: A Holistic Approach to Semi-Supervised Learning (Google Reasearch, 2019)
- Divide and Conquer the Embedding Space for Metric Learning (Heidelberg University, 2019)
1. Neural Ordinary Differential Equations
Авторы статьи: Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, David Duvenaud (University of Toronto, 2018)
→ Оригинал статьи
Автор обзора: Георгий Игнатов (в слэке a2dy2n7okhtp)
NIPS Best Paper Award

Авторы статьи заметили, что ResNet-like сети очень похожи на метод Эйлера для решения дифференциальных уравнений. Если так, то почему бы сразу не довести идею до максимума: представим нейронную сеть в виде дифференциального уравнения и получим
- Сеть с произвольным количеством слоев, которое можно менять в любое время при тренировке и на инференсе. Больше слоев -> больше точность и плавность преобразований (и наоборот).
- Гораздо меньшее количество параметров, следовательно, меньшие затраты памяти.
NODE через аналогии:
 — так выглядит определение выхода со слоя n в resnet-like сети, W — параметры.
— так выглядит определение выхода со слоя n в resnet-like сети, W — параметры. — так могла бы выглядеть NODE-like сеть при условии, что n — дискретная величина.
— так могла бы выглядеть NODE-like сеть при условии, что n — дискретная величина. ,
,  — метод Эйлера.
— метод Эйлера. — ta-da! ODE-powered нейронная сеть.
— ta-da! ODE-powered нейронная сеть.
Решаем любым black-box ODEsolver'ом, прокидываем градиенты с помощью adjoint sensitivity method (Pontryagin et al., 1962). Благодаря полной дифференцируемости, NODE можно комбинировать с обычными нейронными сетями. Авторы выложили код на pytorch.
В статье рассматривается 3 применения:
- Сравнение с ResNet-like архитектурой (на MNIST). NODE работает практически не хуже, при этом используя в 3 раза меньше параметров.
- Переопределение normalized flows через NODE — Continous Normalized Flows (синтетический датасет). Новая модель снижает вычислительные затраты с O(n_hidden_units^3) до линейных.
- Моделирование временных событий с нерегулярными наблюдениями (синтетический датасет). Был сгенерирован датасет спиральных траекторий из которых рандомно насемплили точки посыпав :salt: гауссовским шумом для правдоподобности. На нем проверили обычную RNN и NODE, и вторая снова показала себя лучше.
Мелким шрифтом:
- Обучение минибатчами вызывает некоторый оверхед по вычислениям, но авторы утверждают, что на практике это почти незаметно.
- Появляются два новых гиперпараметра: глубина сети и error tolerance при решении ODE.
- Чтобы решение ODE оставалось уникальным, сеть должна иметь конечные веса и использовать Lipshitz nonlinearities, например, tanh или relu.
Ссылка на более детальный обзор на habr.
2. Semi-Unsupervised Learning with Deep Generative Models: Clustering and Classifying using Ultra-Sparse Labels
Авторы статьи: Matthew Willetts, Stephen Roberts and Christopher Holmes
(University of Oxford, The Alan Turing Institute, London, 2019)
→ Оригинал статьи
Автор обзора: Алекс Широн (в слэке shiron8bit)
Авторы рассматривают semi-unsupervised случай для задачи классификации, когда в разметке данных вследствие selection bias часть присутствующих классов вообще не была никак размечена, да и по известным классам данных размечено не так уж и много. Это создает дополнительные проблемы, поскольку большая часть моделей обычно работает либо в semi-supervised/supervised-режиме (классификация), либо в unsupervised (кластеризация), а в данном случае нам нужно учитывать оба варианта. При этом применение semi-supervised алгоритмов может привести к тому, что неразмеченные данные будут отнесены по некоторой метрике близости к неверным классам. Гипотетический пример таких данных — набор сканов опухолей. Мы взяли часть данных и разметили все присутствующие на этой части виды опухолей, но оказалось, что в оставшихся данных присутствуют и другие виды опухолей, да и вариативность известных видов в разметке была отражена не полностью.
Авторы вдохновились глубокими генеративными моделями (самый простой пример такой модели с единичной глубиной слоя скрытых переменных — вариационный автоэнкодер, он же VAE): в предыдущих работах такие модели успешно справлялись как с semi-supervised случаем (M2, ADGM), так и с кластеризацией (VaDE, GM-VAE).
Почему бы не решать 2 задачи одновременно (semi-supervised обучение на редко размеченных классах и unsupervised на неразмеченных), сохраняя общим пространство выучиваемых скрытых (latent) переменных и объединив идеи из вышеупомянутых моделей? Именно эта идея и лежит в основе предлагаемых в статье моделей GM-DGM/AGM-DGM.
Рассмотрим модель M2 в semi-supervised случае. Она так называется, потому что под M1 создатель подразумевал последовательное обучение VAE и какого-нибудь классификатора (svm) для получающихся латентных представлений z, а вот уже M2 получается из VAE добавлением к слою скрытых переменных переменной y, отвечающей за иногда наблюдаемый класс.
 ,
, 
где  ,
, 
Здесь q — энкодер, p — декодер, часть  — непосредственно тренируемый классификатор.
— непосредственно тренируемый классификатор.
Для unsupervised/semi-unsupervised случая M2 не работает — наступает posterior collapse, классификационная часть q_phi(y|x) коллапсирует к априорному распределению p(y). Автор GM-VAE в своей статье также показал неработоспособность M2 на практике и заметил, что зачастую при реализации M2 первый слой декодера h1 очень напоминает смесь гауссиан.
Исходя из этого наблюдения, в GM-VAE для кластеризации используется явный слой скрытых переменных для моделирования смеси гауссиан, что также повторяют и авторы обозреваемой статьи.Таким образом, модель GM-DGM, позволяющая успешно работать в semi-unsupervised режиме, представляет из себя модификацию VAE с использованием смеси гауссиан в скрытом слое, зависящей от переменной класса y, с описанной выше функцией из двух слагаемых для подсчета и максимизации ELBO.
Авторы статьи провели эксперимент на semi-unsupervised версии Fashion-MNIST: убрали лейблы первых 5 классов, у оставшихся 5 классов оставили по 5% лейблов, при этом получили итоговую точность 77.2% против 53% для M2. Также была показана возможность использования модели для кластеризации (что неудивительно, ведь это почти GM-VAE).
3. Uncovering and Mitigating Algorithmic Bias through Learned Latent Structure
Авторы статьи: Alexander Amini, Ava Soleimany, Wilko Schwarting, Sangeeta N. Bhatia, Daniela Rus (Massachusetts Institute of Technology, Harvard University, 2019)
→ Оригинал статьи
Автор обзора: Алекс Широн (в слэке shiron8bit)
В последнее время все чаще в медиа можно встретить новости, затрагивающие тему bias’ов в данных, особенно относительно алгоритмов, связанных с лицами — с ростом их применимости растет риск сильного негативного влияния на те категории и группы людей, которые недостаточным (или избыточным) образом представлены в датасете. Один из последних примеров — исследование, показавшее меньшую точность детекции пешеходов с темным цветом кожи (в контексте object detection на стандартных для данной задачи датасетах BDD100K и MSCOCO, ссылка).Основные подходы к устранению биасов:
- Балансировка классов при помощи ресэмплинга (требует априорного понимания скрытой структуры данных).
- Генерирование несмещенных данных (например, применение GAN для генерирования лиц с бОльшим разнообразием оттенков кожи).
- Кластеризация и последующий ресэмплинг.
- Можно еще подождать, когда на academictorrents завезут IBM Diversity in Faces dataset.
Авторы статьи же предлагают модификацию VAE и сэмплинг с учетом распределения латентной переменной z, позволяющие уменьшать влияние bias в данных на этапе тренировки.
Итак, основные идеи, стоящие за DB-VAE, таковы:
- Рассмотрим проблему классификации, в которой у нас есть обучающий датасет {(x,y)}, x — m-мерные фичи, y — d-мерные лейблы, а наша задача — аппроксимировать отображение X->Y.
- Возьмем VAE, но заставим энкодер в дополнение к вектору скрытых переменных z размерности 2k (напомню, 2 тут потому что имеем дело со средними и дисперсиями) выучивать еще и вектор размерности d, отвечающий за вышеупомянутые лейблы. При этом декодер принимает на вход только вектор z. Таким образом, получаем подобие semi-supervised обучения, где часть модели выучивается реконструировать инпут, а часть — решать специфическую задачу (классификацию).
- Контролируем обучение модели за счет комбинированного лосса, сочетающего в себе стандартный для VAE лосс (реконструкция + KL-дивергенция) и лосс для вcпомогательной задачи (например, кросс-энтропию для задачи бинарной классификации).
- Особое внимание уделяется тому, что нужно контролировать обучение на данных, которые вы не хотите подвергать debiasing’у (то есть не делать на них backprop из декодера).
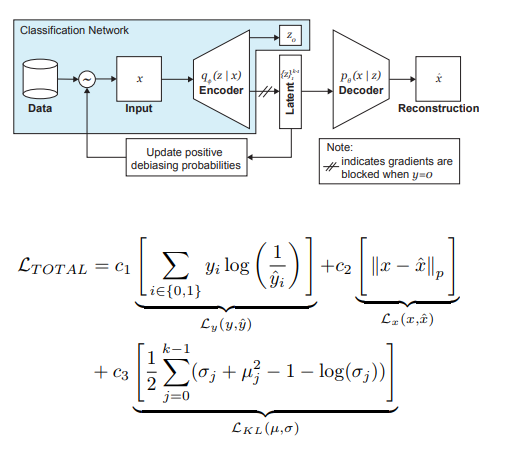
Наиважнейшую роль в устранении боли негров играет адаптивный сэмплинг на этапе обучения. Мы хотим выбирать редкие (с точки зрения каких-то скрытых, не выделенных явно факторов) сэмплы, поэтому обратимся к гистограммам по каждой из размерностей пространства скрытых переменных z, произведением которых можем аппроксимировать распределение Q(z|X) данных по всему пространству Z. При формировании нового батча будем учитывать ‘обратное’ к Q(z|X) распределение W(z(x)|X), определяющее вероятность выбрать пример в батч (alpha — гиперпараметр, определяющий степень debiasing’а), обновляя Q(z|X) на каждой эпохе. Как видим, debiasing не выбирается заранее, а производится на основании выучиваемых латентных переменных.
В качестве эксперимента авторы решали задачу бинарной классификации (нахождение лица на фото). Для обучения собрали датасет, который состоял из 200 тысяч лиц с CelebA и 200 тысяч не-лиц c Imagenet, ресайзили изображения до 64x64. Как и говорилось ранее, при обучении блокировался backpropagation из декодера для фотографий без лиц (y=0). После обучения валидировались на Pilot Parliaments Benchmark (PPB) (1270 фотографий людей из парламентов ЮАР, Руанды, Сенегала, Швеции, Финляндии, Исландии): для всех alpha>0 точность детекции по категориям dark male, dark female, light female возросла по сравнению с вариантом без debiasing.
4. Deep reinforcement learning from human preferences
Авторы статьи: Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei (OpenAI, DeepMind, 2017)
→ Оригинал статьи
Автор обзора: Дмитрий Никулин (в слэке dniku)
Статья про то, как реализовать старую идею в контексте deep reinforcement learning (RL). Идея: давайте будем просить человека оценивать поведение агента, и на основе этого выучим reward function. Проблема в том, что deep RL очень прожорлив, а время человека дорого. В статье приводится набор хаков, которые позволяют свести человекочасы до разумных значений.
Reward function — это функция на парах (observation, action). Она задаётся усреднением предсказания ансамбля нейросетей. Используемые RL-алгоритмы (в статье A2C для Atari и TRPO для Mujoco) считают, что это среднее является истинной наградой, и обучаются на него. Таким образом, статья фокусируется на вопросе обучения этого ансамбля.
Ансамбль обучается на человеческих оценках. Каждая оценка устроена так. Человеку показывают две видеозаписи агента длиной 1-2 секунды. Он может оценить такую пару 4 способами: left is better / right is better / too similar / uncomparable. Если человек сказал "uncomparable", то такая оценка выбрасывается. В противном случае запоминается тройка (σ¹, σ², μ), где σⁱ — траектория агента в соответствующем видео (т.е. список пар (obs, act)), а μ — это пара (1, 0), (0, 1) или (½, ½). Далее, считается, что предсказание награды за траекторию равно сумме предсказаний за каждую пару (obs, act). Наконец, мы просто оптимизируем softmax_cross_entropy_with_logits.
Считается, что человек с вероятностью 10% выбирает случайный ответ, и это учитывается при построении обучающей выборки. В разделе 2.2.3 статьи приведены ещё несколько трюков и выписаны все формулы.
Пары клипов для демонстрации человеку выбираются так: сэмплируется большое количество клипов, на них считается дисперсия ансамбля, и людям показываются случайные пары клипов с высокой дисперсией. Авторы говорят, что хотелось бы выбирать согласно ценности информации, но это future work.
Авторы гоняют тесты на Atari и Mujoco, с настоящими человеческими оценками (hired contractors) и синтетическими (оценки генерируются согласно истинной функции reward), и заодно сравниваются с обычным RL. При примерно равных количествах оценок синтетические и реальные тесты работают похоже. При этом, что удивительно, обычный RL (который видит истинную функцию reward) совсем не обязательно работает лучше.
Наконец, помимо попыток обучить агента получать много reward в обычном смысле, в статье также приводят примеры двух других задач: Hopper в Mujoco делает сальто назад, а машинка в Atari Enduro не обгоняет другие машины, а едет параллельно им. Обе задачи получилось решить.
В заключение: в примере описывается попытка воспроизвести эту статью. Попытка увенчалась успехом, но для этого потребовалось 8 месяцев работы в свободное время и 220 часов чистого времени, из которых половина ушла на отладку простейшей версии.
5. Exploring Randomly Wired Neural Networks for Image Recognition
Авторы статьи: Saining Xie, Alexander Kirillov, Ross Girshick, Kaiming He (Facebook AI Research, 2019)
→ Оригинал статьи
Автор обзора: Егор Панфилов (в слэке tutk1ja)
Введение:
В работе затрагивается вопрос генерации архитектуры нейросетей. На текущий момент известны многие архитектурные трюки (LSTM, Inception, ResNet, DenseNet), которые позволяют улучшить качество на многих задачах, но они же вносят в модель определённый сильный архитектурый prior. На смену упомянутым решениям google вовсю продвигает neural architecture search (NAS), где поиск архитектуры для конкретной задачи осуществляется из заранее заданных модулей посредством RL — NASNet, AmoebaNet.
Авторы утверждают, что и подходы, где дизайн определяется человеком, и NAS вводят слишком строгий prior на архитектуру. В попытке его снизить, они предпринимают попытку использования параметрического генеративного подхода нейросети, где wiring (соединение) элементов осуществляется случайно. Подходы со случайным wiring’ом, оказывается, исследовались еще с 1940х такими учёными, как А.Тюринг, М.Мински, Ф.Розенблатт. В качестве еще одного довода авторы напоминают, что в нейронаучных исследованях было выявлено, что структура нейрональных связей у организмов одного вида — разная (до определенного уровня детализации, разумеется). Это справедливо и для червей, и для человеческих младенцев.В целом, идея процедурной генерации нейросетей звучит интересной и перспективной, чему и посвящена работа.
Метод:
Попробуем модуляризовать процесс процедурной генерации архитектуры нейросетей через графовый подход. Начальные шаги следующие:
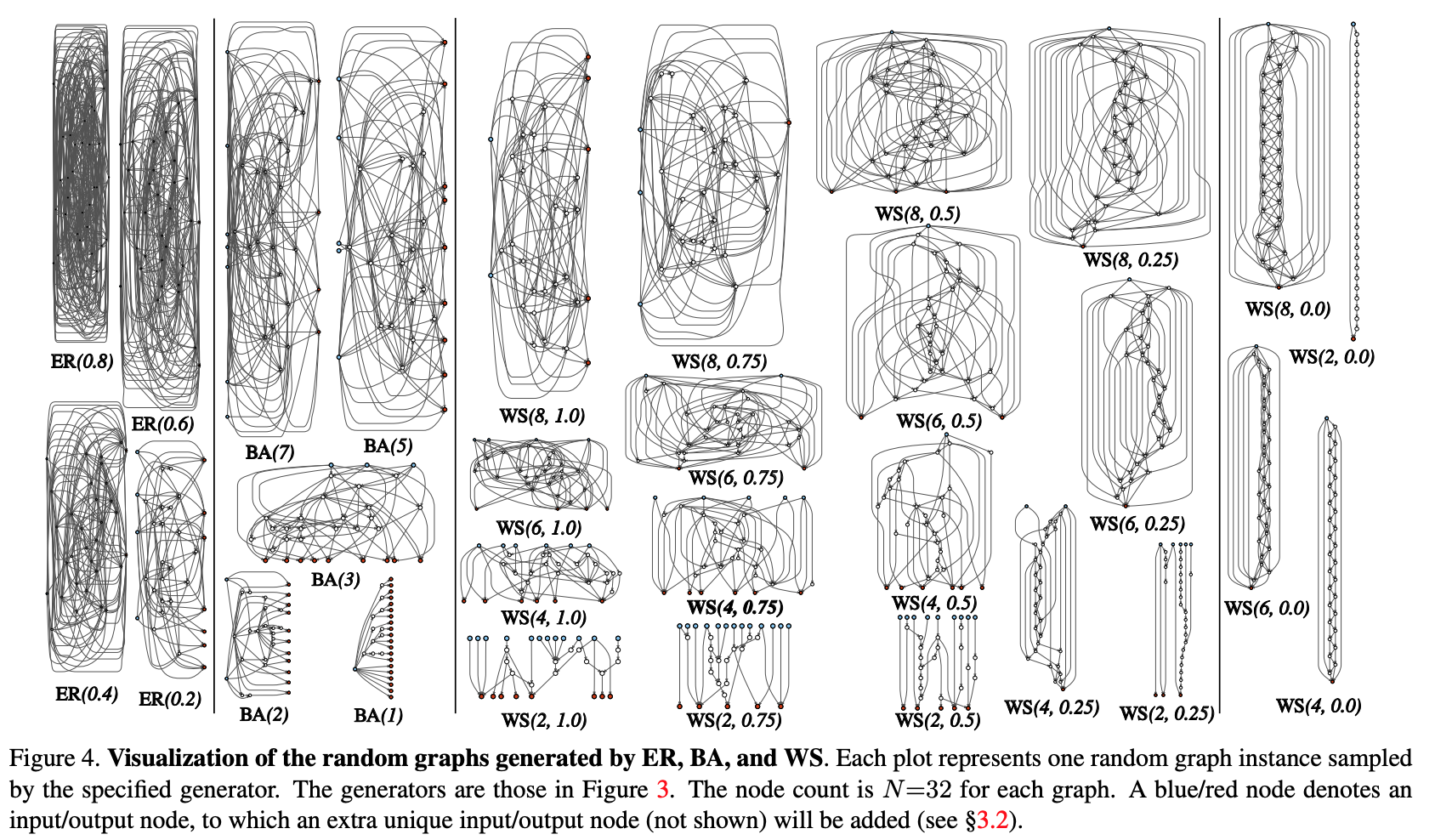
- Производится стохастическая генерация графа из параметризованного семейства. Используются классические методы: Erdos-Renyi (ER), Barabasi-Albert (BA), и Watts-Strogatz (WS).
- Граф конвертируется в нейросеть:
- всё рёбра графа предполагаются направленными носителями тензоров данных;
- для каждой вершины графа определяется тип операции, которую она осуществляет: (I) аггрегация путём сумимрования с обучаемыми весами, (II) трансформация — ReLU+свёртка+BN, (III) дистрибуция — передача тензора по каждому выходному ребру;
- по результатам предыдущего подпункта входных и выходных вершин может быть несколько, но хочется иметь 1 точку входа в граф и 1 — выхода. Такие ноды создаются отдельно. Входная — просто распространяет копию тензора на все входные вершины графа, выходная — считает невзвешенное среднее по всем выходным вершинам.В результате шагов 1 и 2 создаётся, на самом деле, не полная сеть, а лишь один из модулей (наподобие conv_1, … в популярных свёрточных энкодерах). Для того, чтобы получить нейросеть полностью:
- Cоздаются и последовательно соединяются несколько модулей. Чтобы уменьшить число параметров сети, трансформации во всех входных вершинах модулей осуществляются со stride’ом 2x2. Количество каналов при переходе к очередному модулю увеличивает в 2 раза.Чтобы провести эксперименты на конкретной задаче:
- На выход сети добавляется голова для классификации.
Результаты:
Проверка метода осуществлялась на задаче классификации на ImageNet. Качество сгенерированной нейросети оказалось на уровне с SotA архитектурами, немного проигрывая недавней AmoebaNet от Google DeepBrain: (при соизмеримом числе параметров).
Проверяли что будет если удалить случайную вершину/ребро из получившегося графа. Метрика — снижение качества в зависимости от смежных числа выходных ребёр/входных вершин соответственно. В целом, качество падает, но не критично.
Также авторы проверили, работает ли с данной архитектурой transfer learning. На задаче детекции на COCO, backbone Faster R-CNN c FPN’ом был заменен на сгенерированную и предобученую сеть. Результаты показали, что качество у модели не хуже, чем у ResNeXt-50/-101. Но даже и факт того, что transfer learning запускается, довольно занятный.
6. Photofeeler-D3: A Neural Network with Voter Modeling for Dating Photo Rating
Авторы статьи: Agastya Kalra and Ben Peterson (Photofeeler Inc., 2019)
→ Оригинал статьи
Автор обзора: Алекс Широн (в слэке shiron8bit)
Авторы предлагают Photofeeler-D3: архитектуру сети для оценки фотографий с сайтов знакомств по 3 направлениям/trait’ам — насколько человек кажется умным, заслуживающим доверия и привлекательным (эффектом ореола пренебречь!). Задача возникла исходя из опроса The Guardian, согласно которому 90% людей принимают решение о дальнейшем свидании исключительно на основании оценки фотографий потенциального спутника
Итак, сеть состоит из следующих блоков:
- Базовая сеть (желтая часть на картинке) — получаем эмбеддинг с предобученной классификационной сетки (GAP после сверточных слоев), затем пропускаем его через полносвязный слой с 10 выходами (и софтмакс) — получаем temporary output.
- Во втором блоке (синяя часть, voter model) выбирается какой-либо проголосовавший за изображение (voter), берется его эмбеддинг, конкатенируется с temporary output из базового блока, после чего получившийся вектор подается на вход небольшой полносвязной сети, на выходе которой получаем распределение по 10 классам v_ij ((распределение по 10 интервалам внутри [0;1]). Численная оценка получается скалярным произведением v_ij с вектором [0.05, 0.15, 0.25...0.95].
- Имеем оценку для изображения и конкретного голосующего, а усредняя ее по 200 произвольным голосующим, получим итоговую оценку.
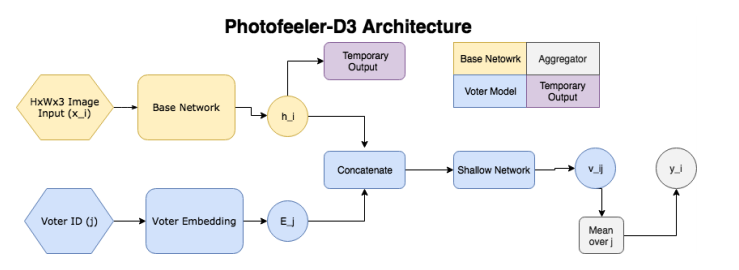
Моделирование голосующих означает, что мы не пытаемся предсказать потенциально шумную среднюю оценку, предсказываем лишь субъективное мнение конкретного избирателя, а значит количество голосов на изображение не так сильно влияет, да и шум от изображений с малым числом голосов влияет меньше.В литературе встречается схожая задача Facial Beauty Prediction (FBP) с открытыми датасетами SCUT-FBP и Hot-Or-Not, однако авторы для обучения использовали данные, полученные непосредственно с сайта Photofeeler, где каждого пользователя оценивают по вышеупомянутым параметрам другие пользователи. При этом данных много: на сайт прилетает +100k оценок каждый день, взяли 1.2 миллиона фотографий всего, из них миллион мужчин (200 тысяч уникальных персон) и 200 тысяч женщин (50 тысяч уникальных персон). Все фотографии с разным соотношением сторон, но не больше 600px. Для тестирования отделили 10000 фотографий мужчин и 8000 фотографий женщин.Отдельно следует отметить, что оригинальные оценки на сайте идут от 0 до 3, однако финальная оценка для обучения и тестирования нормировалась и приводилась к интервалу [0,1] усреднением по всем голосовавшим с весами (веса определялись, исходя из особенностей голосования конкретного человека).
Важные моменты при обучении:
- Гиперпараметры (backbone для эмбеддинга, размер картинки, etc) выбирались при обучении на меньшем наборе данных (20000 train, 3000 val, 2311 test), лучшие результаты получаются для архитектуры xception и картинок размером 600x600.
- Вначале обучается базовая сеть, выход которой (temporary output) сравнивается по KL-дивергенции с реальным распределением оценок для фотографии (как писал чуть ранее, сначала нормируем каждую оценку, потом строим распределение по 10 бинам на интервале [0,1]).
- Для обучения voter model конкретная оценка преобразуется в one-hot округлением до ближайших десятых.
- Эмбеддинги voter’ов скорее всего тоже обучаются, при этом базовая модель на 2 этапе заморожена.
- Модели для всех трех типов trait’ов и 2 гендеров обучались отдельно, использовались оценки только противоположного пола.Результаты:
- Для обоих полов модель показала корреляцию ~80% с человеческими оценками на их внутреннем датасете, при этом на London Faces архитектура показала куда более высокую корреляцию с людьми, чем сервисы prettyscale.com и hotness.ai (81 против 53 и 52).
- В задаче FBP на обоих датасетах (SCUT-FBP и Hot-Or-Not) были получены результаты, близкие к SOTA.
- Также тесты показывают, что модель ведет себя лучше, чем усреднение по 10 голосующим людям
7. MixMatch: A Holistic Approach to Semi-Supervised Learning
Авторы статьи: D. Berthelot, N. Carlini, I. J. Goodfellow, N. Papernot, A. Oliver and Colin Raffel (Google Reasearch, 2019)
→ Оригинал статьи
Автор обзора: Сергей Червонцев (в слэке JanRocketMan)
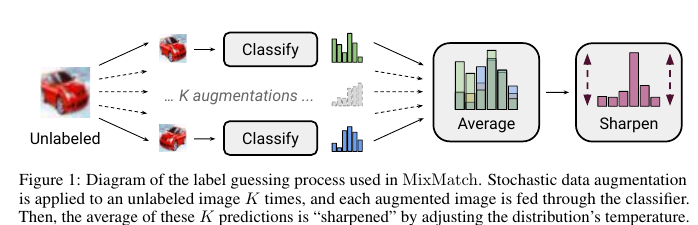
Смесь MeanTeacher и Mixup-а для новой SOT-ы в задаче Semi-Supervised Learning (SSL) классификации картинок. Напомню, самый рабочий SSL сейчас опирается на consistency regularization. Это значит, что помимо обычного лосса на трейне (которого мало и с которым всё оверфитится) на неразмеченных данных мы либо используем "шумные" метки, либо делаем локальные пертурбации и учим модель выдавать одинаковые предсказания независимо от них.Примером первого подхода является Mean Teacher (где шумные метки — это предсказания модели c EMA весами), примером второго — Mixup (хоть и докидывает он немного).Авторы предлагают нечто среднее, плюс докинуть несколько гиперпараметров чтобы лучше контроллировать происходящее. Работает это так:
- Пересемплируем unsupervised картинку с разными аугментациями несколько раз, и усредняем предсказания.
Получаем "шумную" метку p. - "Заостряем" получившееся распределение по классам, чтобы оно ближе было к one-hot. Предлагается такое преобразование:
 . Меняя T можно балансировать между тем, что распределение размазанное, но качество меток хорошее и тем, что распределение больше похоже на истинное (по форме), но качество меток проседает.
. Меняя T можно балансировать между тем, что распределение размазанное, но качество меток хорошее и тем, что распределение больше похоже на истинное (по форме), но качество меток проседает. - Миксапится всё со всем, разбиваясь случайно по парам.Несмотря на такие незначительные изменения, здорово привозят на SVHN, STL и CIFAR10.
На CIFAR10 у них примерно 90% accuracy используя всего 250 меток. Для сравнения второй по качеству — VAT, даёт лишь 60%. На SVHN где-то 96% тоже с 250-ю метками, когда VAT и Mean Teacher дают ближе к 90.
На STL10 90% с 1к меток, в сравнение ставят какой-то CCGAN, который даёт 80.В целом воодущевляющие результаты, показывающие что:
- Жирные модели хорошо, даже когда данных мало (но задача простая);
- С прямыми руками и GridSearch-ем и простой подходы дают значительный профит;
c. SSL можно уже вылезать из SVHN песочницы и работать с более сложными датасетами.
8. Divide and Conquer the Embedding Space for Metric Learning
Авторы статьи: Artsiom Sanakoyeu, Vadim Tschernezki, Uta Buchler and Bjorn Ommer (Heidelberg University, 2019)
→ Оригинал статьи
Автор обзора: Александр Денисенко (в слэке Alexander Denisenko)
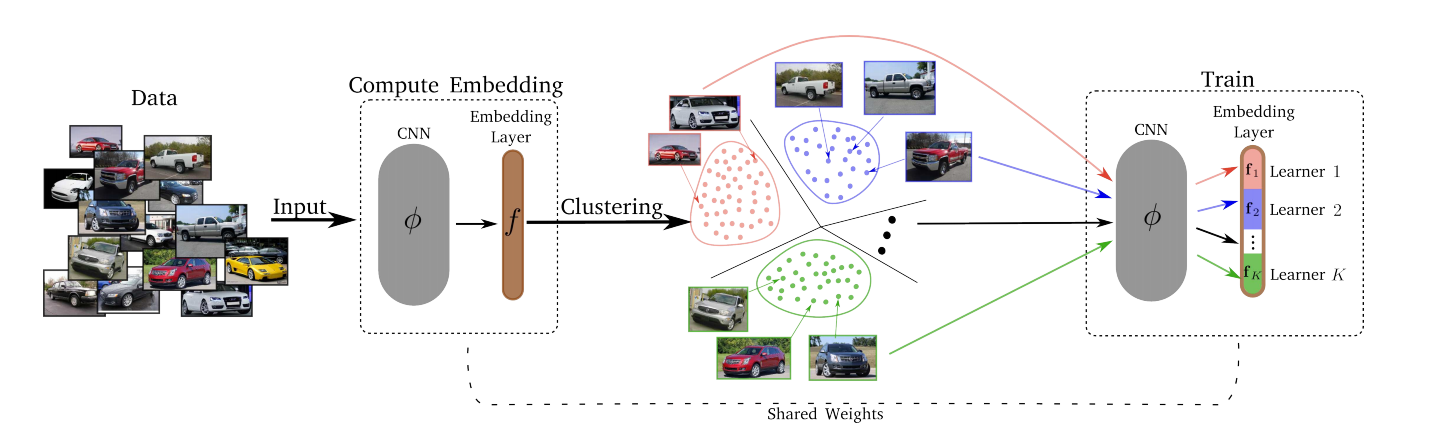
Стандартный вариант метрик лёрнинга — просто выучивать единую метрику, которая будет определять близость для любой пары картинок по их эмбеддингам. Это не очень хорошо, потому что эмбеддинги не распределены в пространстве равномерно, похожесть изображений может определяться разными вещами – цветом, формой, семантическим значением, т.д.
Подход, предлагаемый в статье:
- Обучаются эмбеддинги
- Divide.
Фиксируем какое-то число К и разбиваем данные на К кластеров с помощью k-means. Теперь будем решать К простых задач вместо одной исходной. Определяем К различных лёрнеров следующим образом. Embedding layer разбивается на K последовательных слайсов равной длины. Каждый из них – отдельный лёрнер. Он отображает инпут в подпространство размерности d/K (d – размерность всего пространства эмбеддингов). - Conquer.
После стадии Divide каждый из K кластеров сопоставляется одному из K лёрнеров. Лёрнеры тренируются поочерёдно, то есть в каждый конкретный момент у нас выбран кластер, на котором проходит обучение, из него сэмплится мини-батч, и соответствующий лёрнер минимизирует свой лосс, обновляя свои параметры. Пространство эмбеддингов со временем обновляется, так что каждые T эпох кластеризация (Divide) делается заново. - Мёрджим – конкатенируем всех лёрнеров (слайсы слоя эмбеддинга). Затем дообучаем слой эмбеддинга на всём датасете, чтобы подружить лёрнеров между собой.
Результаты экспериментов: всех победили на нескольких датасетах.
Лосс может быть любым – Triplet Loss, Margin Loss, Proxy-NCA, т.д.
Оптимальное количестов лёрнеров K вышло равным 8 (размерность всего пространства эмбеддингов была равна 128, так что каждый лёрнер решал свою подзадачу в 16-мерном пространстве).
Изменение T от 1 до 10 существенно ни на что не повлияло, так что использовали T=2.
