Комментарии 68
Если вы делаете что-то с интеллектом кузнечика, то да. Если задача приблизиться к интеллекту человека (пусть и на ограниченном классе задач), то учитывать форму необходимо.
Я был бы рад что-то сделать даже с интеллектом кошки, которые, уверен способны различать формы и имеют в голове модель мира и объектов его населяющих пусть и не такую совершенную как у большинства людей. Роботы и дроны с интеллектуальными возможностями кошачих уже зрелищно решат большой спектр задач.
Кстати, свёрточные слои были вдохновлены экспериментами на мозгах как раз кошек. Может у них ещё что есть подсмотреть? Например, может не случайно правое полушарие обрабатывает детали образа, а левое полушарие отвечает за абстракции. Просто разговоры о том, чтобы сделать «интеллект как у людей» с середины прошлого века ещё шли и иногда заводили не совсем туда (экспертные системы, тот ещё механистический машинный перевод и тп.) излишне зацикливаясь на человеке. А «кошачий» deep learning «взлетел».
За всех говорить не надо, у разных людей разные задачи. У меня — понять как сделать общий искусственный интеллект.
Тогда вам не в современный deep learning (а возможно даже не в machine learning вообще).
Безусловно, современных ML и DL недостаточно, но возможности DL быстро расширяются. Например, ещё пару лет назад, синтез программ относился к конференциям по языкам программирования, а теперь всё больше переходит в NeurIPS. RL тоже развивается неожиданно хорошо. В целом, у меня нет оснований полагать, что DL не пригодится. Даже скорее наоборот, похоже, что DL в некоторой видоизменённой форме будет существенной частью AGI. И что ещё важно, чем больше всего можно скинуть на плечи DL, тем проще и гибче получится архитектура.
Решить задачу — значит находить закономерности, так? Т.е. создать некую предсказательную модель, которая «работает». Однако в статье речь идет как раз о том, что не смотря на то, что модель работает, она работает на определенной все-таки выборке (считающейся релевантной), и вот возникли сомнения, что она работает «правильно». И определенные эксперименты (с котом и пальцами) показали некоторые «особенности», которые не позволяют сказать, что сеть работает «правильно».
Это как с решением задач школьниками — иногда так получается, что неправильным способом можно получить правильный ответ. И нужно понять ход мысли, что бы вскрыть ошибку. Хотя можно было бы подойти формально — решил правильно? Молодец — пять. За это часто ругают испытания в виде тестов.
Так вот эта самая «баг нет» — это как бы способ посмотреть процесс решения, дабы понять ход мысли. И он показал, что сеть «ленится» и склонна выделять простейшие признаки для решения задачи не углубляясь слишком сильно! И по мне это шикарный результат! Мне кажется
учитывать форму необходимо
Если нужно учитывать форму, то надо строить сеть соответствующим образом и обучать её на специальном наборе данных, в котором большое значение имеет форма. Судя по данным из статьи, исходные нейросети обучены наилучшим образом распознавать примеры, на которых они обучались (совершенно неудивительно). Если они распознают текстуры, а не форму — это всего лишь значит, что для распознавания на обучающей выборке текстуры имеют большее значение, чем форма, и что той архитектуры нейросети достаточно для хорошего распознавания на обучающей выборке.
Вообще заголовки вида "Нейронные сети не умеют ..." истинны только при указании конкретной архитектуры сети и конкретной обучающей выборки. Наверняка можно предложить другую архитектуру сети, которая не делает конкретных глупых ошибок. Или даже переобучить существующую архитектуру на более актуальной в данном случае выборке.
задача приблизиться к интеллекту человека
Приблизиться в выполнении каких задач? Если каких-то конкретных задач — достаточно таких несложных и специализированных вещей, как упомянутые в статье архитектуры НС. Если "всех" задач, то с нейросетевым подходом как минимум нужна соответствующая обучающая выборка. И плюс какие-то ещё неизвестные алгоритмы для сильного ИИ.
Если они распознают текстуры, а не форму — это всего лишь значит
Это всего лишь значит, что разработчики архитектуры не знали, каким образом нейросеть распознает примеры (и это на самом деле так).
Другую архитектуру (или другую аугментацию изображений) можно предложить теперь, когда ответ есть. Вы же не считаете, что ответ был очевиден до этой работы?
Приблизиться в выполнении каких задач?
Потенциально в любых, конечно.
разработчики архитектуры не знали, каким образом нейросеть распознает примеры (и это на самом деле так).
Думаю, здесь будет более точной формулировка из статьи "не совсем ясен механизм, как нейронные сети принимают решения", чем "не знали". Частичное понимание было и есть.
Вы же не считаете, что ответ был очевиден до этой работы?
Предпосылки к этому ответу были. Например, были работы, в которых менялись несколько пикселей, чтобы "обмануть" НС. Уже тогда было ясно, что глубокие свёрточные сети могут ошибаться в некоторых случаях, что могут терять (а могут и не терять) пространственную информацию, что для "типичных" архитектур 4 собачьих глаза и 3 собачьих ноги в сумме могут дать собаку. Здесь же более чётко показано, что на "стандартных" датасетах пространственная информация скорей теряется, предпочтение отдаётся текстурам.
Судя по данным из статьи, исходные нейросети обучены наилучшим образом распознавать примеры, на которых они обучались (совершенно неудивительно).Вы абсолютно правы! Так об этом же и статья, не? Просто эти выборки (на основе ImageNet) — уже практически стандарт де факто! Все сети на них обучаются! Потому, что крайне сложно самостоятельно собрать релевантную базу изображений небольшого размера такого объема…
Авторы обращают внимание, что возможно выборка все-таки не так хороша, как ранее считалось… Особенно мне понравилось про пальцы и рыбу. ;)
А может и не так уж и плохо, на текстуры реагировать?
Надо от задач идти. В большинстве актуальных задач реагировать (только) на текстуры не просто плохо, а очень плохо. Кому нужен автопилот, который примет человека в нестандартной одежде за мусор, а рекламу на корме автобуса за перебегающего дорогу кота? Или face recognition, который не узнает лицо своего хозяина после драки?) Или еще пример, уверен, что очень хорошо детектить автомобиль по фрагменту номерного знака. Но что делать с автомобилем, который едет без номера, или с номером другой страны, где другой формат?
мы люди по 10 лет смотрим мультики про Тома и Джери, Кота Лепольда и Кота Матроскина. потом скармливаем сети набор фотографий с кошками и плачем что сеть принимает решения не так как мы. какой ужас — она ориентируется на шерсть и узоры, а не форму кошачьей мордахи и изгибов спины.
пардон, а с чего она должна вычленять котов по форме если в ее детстве не было 30 эпох котов Матроскиных и Леопольдов?
в том же тесте добавьте в датасет раскадровки мультфильмов с котами, и повторите эксперимент. вангую что результаты встанут на ожидаемое нами место
Но вот если у нас что-то близкое к натуральным картинкам и, допустим, мы заморозили все веса и обучаем только финальные слои — то в этом случае мы никак не сможем добиться от сети, чтобы она выучивала форму объектов.
Поэтому, собственно, лучше и иметь предобученные на Stylized ImageNet сети, чтобы всегда можно было сравнить.
Но это всё imho, на практике ещё не проверял.
https://upload.wikimedia.org/wikipedia/ru/5/57/CatDog.GIF
{kind=link}
Интересно, что это с т.з. нейросети, классифицирующей двухголовых котят ;)
Нет никакой "точки зрения", есть обучающая выборка, по которой определяются весовые коэффициенты, которые затем много раз перемножаются с пикселами картинки и много раз суммируются, затем определяется наибольшее среди результатов число, и на выход подается метка, соответствующая этому числу. Сеть выдаст те результаты из обучающей выборки, на которые наиболее похожа входная картинка.
Интуитивно потому, что оверфиттинг на внешнее — это плохо. Люди тысячелетия учатся обращать внимание на форму и содержание, а не только на цвет.
Математического доказательства, что это важно, не существует, но делать сети по принципу работы людей — это неплохой путь.
Те же самые свертки были подсказаны зрительной корой.
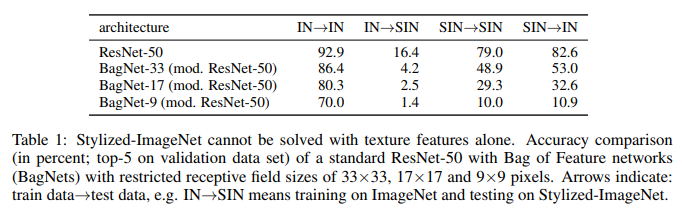
Во второй статье авторы тренировали BagNet на датасете без текстур — точность BagNet сильно просела. Вверху таблица есть.
33px: top-5 accuracy просела с 86.4% до 53.0%
17px: 80.3 -> 32.0
9px: 70.0 -> 10.9
habrastorage.org/webt/rm/bm/k7/rmbmk7uvvm9gigwy5xkh6fvfghm.png
{kind=link}
Я под сопоставимостью имел ввиду то, что сеть успешно распознала не 20% примеров, не 40%, а 86% — что лет пять назад считалось успехом и для CNN. Учитывая что в BagNet уменьшено количество параметров и сильно ограничен receptive field.
Нет, статья не об этом. Статья о том, что классическая ResNet обучается на текстуры (а не на форму).
Во-первых, это утверждение не было очевидно.
Во-вторых, они его качественно подтвердили.
В-третьих, они проверили хороший способ аугментации и улучшили результаты для ResNet.
BagNet в данном случае нужна только для того, что бы подтвердить это утверждение (используется как лемма в доказательстве).
Разумеется они никак его не подтвердили, т.к. точность упала.
Они подтвердили это не повышением точности, а понижением при перекрёстном тестировании. Посмотрите Table 1. Генерализация полной сети, обученной на SIM очень не плоха. 82%. При этом в обратную сторону всего 16%. Почему?
Они объясняют это тем, что в случае SIM сеть обучается на форму. В датасете IN форма тоже есть, потому результат неплохой. А вот при обучении на IN сеть на форму НЕ обучается, поэтому в обратную сторону результат такой плохой.
Если вы не согласны с этим объяснением (даже после прочтения оригинала), то дайте свое. Если оно лучше, с удовольствием соглашусь с ним.
самую весомую характеристику оригинального датасета.
Какую? И почему без неё точность 79%? Она точно самая весомая?
Ничего подобного, она обучается на форму, но см. выше.
Увидел ваше, где вы пишете это же утверждение, но тоже никак его не подтверждаете. Почему вы считаете, что resnet обучается на форму?
можно было бы прийти к вашему выводу
Вот они к этому выводу и пришли. Текстуру они заменили на что-то, что не говорит ничего о классе изображения. Вы бы хотели заменить её на что-то серое + контуры? Если попробуете, будет интересно.
Ответ на этот вопрос содержится в моём сообщении верхнего уровня.
В верхнем сообщении речь про текстуры. Вы считаете текстуры самой весомой характеристикой оригинального датасета?
Если бы она не обучалась на форму
Это попытка докопаться лингвистически. Мол, пусть на 10%, но хоть немного формы resnet из датасета получает. Не надо так.
В рамках нашего разговора "не обучается на форму" и "обучается на форму незначительно" — одно и то же. Но вот вам переформулированный тезис.
Статья о том, что классическая ResNet обучается преимущественно на текстуры (а форму учитывает намного меньше).
Никакой разницы что я считаю весомой характеристикой.
Это важно для понимания ваших тезисов парой комментариев выше. Если эти ваши тезисы не важны, тогда согласен. То, что вы имеете ввиду под "самой весомой характеристикой" неважно.
Этот вывод нельзя сделать из данной работы по причинам, которые я описал выше.
Выше, это где про "весомую характеристику", которая оказалась неважна?
Извините, но связность ваших рассуждений недостаточна, что б разговор продолжал быть интересным. Слишком много ссылок на то, что "описано выше", а при попытке уточнить, что же вы имеете ввиду, опять ссылка на описание выше.
Этот вывод ещё можно допустить, в плане, что если представить сеть как (TextureClassifier(img) A + ShapeClassifier(img) B) / (A + B), то из работы следует A > B.
Благодарю и на этом.
Я не виноват
А при чем тут вина? Либо вы хотите что-то рассказать, либо не хотите. Если хотите, то ваш прямой интерес поменьше запутывать обсуждение перекрестными ссылками, не так ли?
то результат TC*A+SC*B = 16% не означает, что SC = 16% или даже вообще что SC < 80%, например?
SC может быть любым, тут важно, что В маленькое. Учтите, что В не задано изначально, это тоже результат обучения сети. То есть при стандартной ResNet, с обычными картинками обучение приводит к тому, что влияние форм маленькое.
Однако SC в данном случае — это не какой-то классификатор внутри сети, который мы потом умножаем на коэффициент, а просто абстракция, которую вы ввели для иллюстрации идеи. Нет оснований считать, что внутри сети на самом деле есть участок с высоким уровнем распознавания форм.
Основание считать наоборот — это научная статья, которую мы обсуждаем. Видно, что вы с ней не согласны, но серьезных доводов для её опровержения вы так и не предоставили.
А как написано в статье? Если я понял её превратно, буду рад пояснениям.
ACCURACY AND ROBUSTNESS:
«are biased towards texture» — «сдвинуто в сторону текстур»
«In the light of these findings, we believe that it is time to consider a second explanation, which we term the texture hypothesis: in contrast to the common assumption, object textures are more important than global object shapes for CNN object recognition.» — аналогично, «текстуры для сети более важны» (но из этого не следует «неумение» распознавать формы и контуры, т.е., по сути, речь лишь про принятие решения ближе к выходу сети).
«ImageNet object recognition could, in principle, be achieved through texture recognition alone» — «в принципе, с помощью одних текстур можно неплохо распознавать ImageNet»
«This pattern is reversed for CNNs, which show a clear bias towards responding with the texture category (VGG-16: 17.2% shape vs. 82.8% texture; GoogLeNet: 31.2% vs. 68.8%; AlexNet: 42.9% vs. 57.1%; ResNet-50: 22.1% vs. 77.9%).» — что текстура важнее примерно в 80% случаев.
И т.п. Очень рекомендую часть 4 — DISCUSSION прочитать целиком. Одну выдержку приведу:
Intriguingly, this offers an explanation for a number of rather disconnected findings: CNNs match texture appearance for humans (Wallis et al., 2017), and their predictive power for neural responses along the human ventral stream appears to be largely due to human-like texture representations, but not human-like contour representations (Laskar et al., 2018; Long & Konkle, 2018). Furthermore, texture-based generative modelling approaches such as style transfer (Gatys et al., 2016), single image super-resolution (Gondal et al., 2018) as well as static and dynamic texture synthesis (Gatys et al., 2015; Funke et al., 2017) all produce excellent results using standard CNNs, while CNN-based shape transfer seems to be very difficult (Gokaslan et al., 2018). CNNs can still recognise images with scrambled shapes (Gatys et al., 2017; Brendel & Bethge, 2019), but they have much more difficulties recognising objects with missing texture information (Ballester & de Araújo, 2016; Yu et al., 2017).
Нужно провести простой эксперимент: научить на IN (взять обученную сетку), а потом немного дообучить на SIN, чтобы B успел измениться относительно А, а вот TC и SC не сильно поменялись. Вот тогда будет какая-то оценка точности, получше, чем диапазон 16%..80%
Сразу вспоминается диван леопардовой расцветки. :)
Интересные результаты. Радует, что на эту проблему стали обращать внимание, сначла капсульные сети, теперь вот это. А всё потому, что, грубо говоря, все production-ready архитектуры вообще не умеют в форму объектов. Человек чаще всего безошибочно и мгновенно распознает подавляющее большинство объектов, потому что знает, что это за объект, а не просто какое-то "серо-бурое образование в крапинку с контрастными границами", он знает, что это известный объект реального мира и зачем он нужен. И этот объект может обладать именно такой формой (или набором форм). Игнорирование формы — это большой изъян современных архитектур, который рано или поздно придётся исправлять. И вот почему-то мне кажется, что просто созданием синтетических абстракционистских датасетов тут не победить.
В этом плане было бы интересно совместить современные глубокие нейросети и статистический анализ и моделирование формы. Возможно, это могло бы дать лучшие результаты и новый толчок в этой области.
вот вопрос который меня тревожит — в ImageNet есть раскадровки из Диснеевских Короля-льва и Винни-Пуха? потому что если нет, самое время их туда добавить, чтобы «мотивировать» сети опираться на форму

Поэтому мы предпочитаем форму текстуре.
Обезьяны, не умеющие выделить на фоне ландшафта хищника — сдохли.верно
Поэтому мы предпочитаем форму текстуре.неверно
хищник чаще всего открывает кусочек своего тела и то по недоразумению. например ухо, хвост, часть спины. и все это обезьяна должна уметь распознать. даже если просто кусок текстуры тигра будет просвечивать сквозь траву нормальная обезьяна тут же запрыгнет на дерево.
так что предпочтение обезьянами формы текстурам еще требуется доказать. я склоняюсь думать что скорее окажется наоборот
Верхний ряд из 7 патчей взят из изображений только соответствующего класса, нижний – из всей выборки изображений.
Нижний ряд взят из остальных изображений, а не всех вообще, т.е. это куски, отзывающиеся на заданный класс, но всё изображение относится к другому классу.
Почему не тренируют?) У меня в одной сильно специфической задаче входные данные в виде карты глубин давали лучшие результаты, чем вход rgb.
А ещё есть масса вариантов наподобие "первым шагом делать 3D реконструкцию по стереоснимкам, а затем распознавать трёхмерные образы", или, скажем, обучать на снимках в ИК-диапазоне, на дополненной реальности и т.д. Пред- и пост-обработка данных может быть любой.
Скиньте ссылку на датасет и обязательно потренируем :)
Нейронные сети предпочитают текстуры и как с этим бороться