Комментарии 29
Но авторы вышеупомянутой работы [1] смогли решить эту проблему. Так что теперь и это ограничение снято.
Расскажите как, если не сложно.
Чтобы ответить вам на вопрос, нужно рассказать несколько дополнительных вещей:
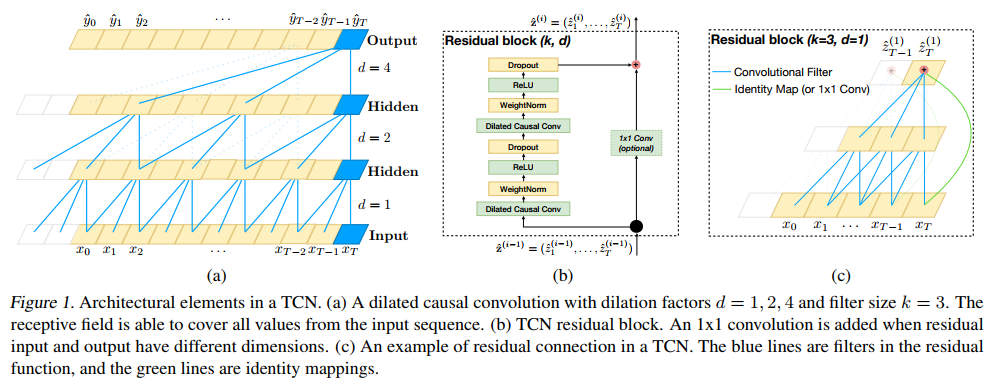
1) Residual connection — это способ проброса гридиентов в глубину, напрямую, когда мы «добавляем ко входу», то есть вход остается неизменным, а наш смысловой блок просто делает какую-то добавку. В сверточных нейронных сетях (типа ResNet) принято делать именно блоки, из которых строится сеть, а не отдельные сверточные слои.
2) Cвертка 1x1 — это специальный вид свертки, кторый интегрирует все каналы в одно значение, оставляя размер матрицы неизменным. Здесь он используется в качестве обработки входа, чтобы можно было совместить разное число каналов на входе и выходе residual-блока.
Авторы в своей сети используют так называемые fully-convolutional сети, т.е. размер матрицы, с которой они работают остается постоянным. Используя трюк с 1x1-conv и residual connection, они добиваются большой глубины, не теряя возможности варьировать обработку по ширине. Тут важно отметить, что они строят сеть так, чтобы нигде не делают изменения ширины матрицы, именно это позвояет им работать с матрицами переменной ширины.
Относительно convolutional seq2seq я бы еще добавил, что lua Torch имплементация устарела, лучше использовать PyTorch: github.com/facebookresearch/fairseq-py
Относительно ASR мое мнение, что даже интереснее TTS в виде более раннего WaveNet от DeepMind. Но тогда надо было бы рассказывать про padding, dilated convolutions и прочие более сложные вещи, которые для вводной статьи слишком сложны.
ссылки на оригинал.
Укажите пожалуйста, что это, хоть и обрезаный (с отступлениями, вытяжками со стороны и т.д.), но всё же перевод… А то не красиво как-то выходит.
Ну это как раз малая часть (и Denny Britz на её первоначальный вариант от 2014 года ссылается)…
Из статьи же Брица, той что на WildML за 2015 год, практически 70-80% (если не больше).
предыдущая мне недоступна
А WildML нынче в реестре? Поискал в блэклисте — говорит вроде нет… Если все же — сочувствую...
Вы серьёзно?.. Ну-ну.
When we hear about Convolutional Neural Network (CNNs), we typically think of Computer Vision. CNNs were responsible for major breakthroughs in Image Classification and are the core of most Computer Vision systems today…
Когда мы слышим о сверточных нейронных сетях (CNN), мы обычно думаем о компьютерном зрении. CNN лежали в основе прорывов в классификации изображений...
И т.д. и т.п.
Вы правда думаете, что изменением пары фраз и заместив 20-30% можно "обмануть" человека бегло читающего по английски?
Молодой человек, это называется — плагиат.
Но хоть мораль — дело общественное, совесть всё таки — дело каждого.
Так что я вам ничего доказывать не собираюсь, оставайтесь при своем мнении.
- Если нейросети применяют, значит, они выгоднее, чем разработанные вручную алгоритмы.
- Если вакансии на должности программиста-аналитика или data-scientist'а появляются, значит, ML используется в бизнесе.
- Ну, и система автоматического «развода лохов» (поиск заёмщиков, классификация потребителей рекламы) работает без перерывов, без выходных и никогда не уйдёт в декрет.
svboobnov лучше просто игнорить :)
Опечатка: смешение
И было б клёво в статье пояснение про суть one-hot к первому упоминанию перенести, а то пришлось сначала гуглить, а потом тут у второго упоминания увидел.
здесь я решил не загромождать не совсем релевантными пояснениями
model.add(Embedding(input_dim=max_words, output_dim=128, input_length=max_len))и пояснение
Первым слоем у нас идет Embedding, который переводит целые числа (на самом деле one-hot вектора, в которых место единицы соответствует номеру слова в словаре) в плотные вектора. В нашем примере размер embedding-пространства (длина вектора) составляет 128, количество слов в словаре max_words, и количество слов в последовательности — max_len, как мы уже знаем из кода выше.
что-то как-то они у меня друг с другом не сходятся ((
Пример кода из одного проекта:
K.set_value(model.get_layer('word_emb').embeddings,
emb_reader.get_emb_matrix_given_vocab(vocab, K.get_value(model.get_layer('word_emb').embeddings)))Дополнительно, можно еще «заморозить» веса этого слоя, чтобы эмбеддинги «не портились» в процессе тренировки (то есть они не будут тренироваться, но тем не менее останутся частью нашей сети):
model.get_layer('word_emb').trainable = FalseЗдесь и имеется в виду word2vec иле его родственники, с размерностью одного вектора output_dim=128.
Применение сверточных нейронных сетей для задач NLP